文章目录
Elasticsearch 中的一些概念
elasticsearch中有很多独有的概念,与mysql中略有差别,但也有相似之处。
我们要先学习Elasticsearch 区别于mysql中的知识才能去进行操作:
文档和字段
elasticsearch是面向**文档(Document)**存储的,可以是数据库中的一条商品数据,一个订单信息。文档数据会被序列化为json格式后存储在elasticsearch中:
例如下面的例子,左侧的每一条数据存储到elasticsearch,都是一个文档

而Json文档中往往包含很多的字段(Field),类似于数据库中的列。
例如上图中每一个文档的字段,”id“、”title“都是数据库中的列
索引和映射
索引(Index),就是相同类型的文档的集合。
也就是索引里面的每个文档的字段都是相同类型的
例如下面的例子:
- 所有用户文档,就可以组织在一起,称为用户的索引;
- 所有商品的文档,可以组织在一起,称为商品的索引;
- 所有订单的文档,可以组织在一起,称为订单的索引;

因此,我们可以把索引当做是数据库中的表。
数据库的表会有约束信息,用来定义表的结构、字段的名称、类型等信息。
因此,索引库中就有映射(mapping),是索引中文档的字段约束信息,类似表的结构约束。
mysql与elasticsearch的联系
我们统一的把mysql与elasticsearch的概念做一下对比:
| MySQL | Elasticsearch | 说明 |
|---|---|---|
| Table | Index | 索引(index),就是文档的集合,类似数据库的表(table) |
| Row | Document | 文档(Document),就是一条条的数据,类似数据库中的行(Row),文档都是JSON格式 |
| Column | Field | 字段(Field),就是JSON文档中的字段,类似数据库中的列(Column) |
| Schema | Mapping | Mapping(映射)是索引中文档的约束,例如字段类型约束。类似数据库的表结构(Schema) |
| SQL | DSL | DSL是elasticsearch提供的JSON风格的请求语句,用来操作elasticsearch,实现CRUD |
那么两者这不是很相像吗?我们学了MySQL为什么还要学Elasticsearch?
虽然两者在很多地方相似,但是两者各自有自己的擅长支出:
Mysql:擅长事务类型操作,可以确保数据的安全和一致性
Elasticsearch:擅长海量数据的搜索、分析、计算
因此在企业中,往往是两者结合使用:
- 对安全性要求较高的写操作,使用mysql实现
- 对查询性能要求较高的搜索需求,使用elasticsearch实现
- 两者再基于某种方式,实现数据的同步,保证一致性
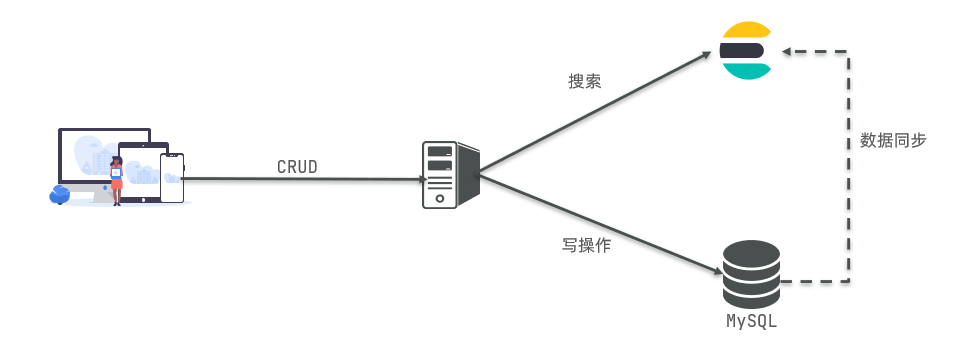
例如下面实现Mysql与Elasticsearch结合使用的流程图:
应用前端向后端发送数据的CRUD请求,当进行事务类型操作的时,服务器与MySQL服务器进行数据持久化交互,保证数据操作的安全性,统一后端数据;当进行数据搜索与分析操作时,单纯的MySQL服务已经不能支撑完备的海量数据分析的操作,此时服务器往往是与Elasticsearch服务进行数据搜索、分析交互,得到最后数据计算的结果。
索引库操作
Elasticsearch 索引库就类似数据库表,mapping映射就类似表的结构。
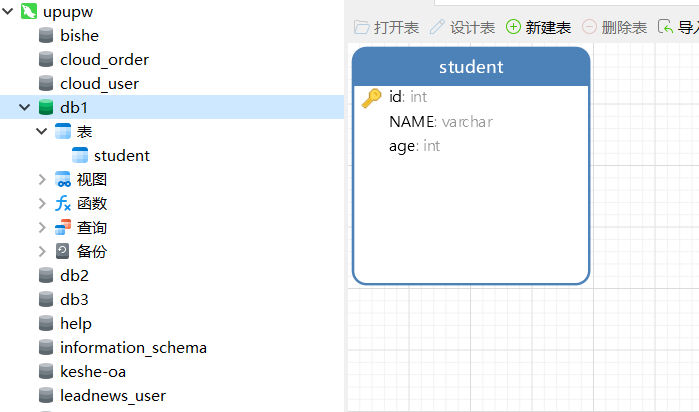
我们要向es中存储数据,必须先创建“库”和“表”。
类似于mysql的创建库和表,如下图所示为MySQL的库表
1.mapping映射属性
mapping是对索引库中文档的约束,常见的mapping属性包括:
- type:字段数据类型,常见的简单类型有:
- 字符串:text(可分词的文本)、keyword(精确值,例如:品牌、国家、ip地址)
- 数值:long、integer、short、byte、double、float、
- 布尔:boolean
- 日期:date
- 对象:object
- index:是否创建索引,默认为true
- analyzer:使用哪种分词器
- properties:该字段的子字段
例如下面的json文档:
{
"age": 21,
"weight": 52.1,
"isMarried": false,
"info": "精灵世界Java大师",
"email": "yyl@jingling.cn",
"score": [99.1, 99.5, 98.9],
"name": {
"firstName": "开",
"lastName": "杨"
}
}
对应的每个字段映射(mapping):
- age:类型为 integer;参与搜索,因此需要index为true;无需分词器
- weight:类型为float;参与搜索,因此需要index为true;无需分词器
- isMarried:类型为boolean;参与搜索,因此需要index为true;无需分词器
- info:类型为字符串,需要分词,因此是text;参与搜索,因此需要index为true;分词器可以用ik_smart
- email:类型为字符串,但是不需要分词,因此是keyword;不参与搜索,因此需要index为false;无需分词器
- score:虽然是数组,但是我们只看元素的类型,类型为float;参与搜索,因此需要index为true;无需分词器
- name:类型为object,需要定义多个子属性
- name.firstName;类型为字符串,但是不需要分词,因此是keyword;参与搜索,因此需要index为true;无需分词器
- name.lastName;类型为字符串,但是不需要分词,因此是keyword;参与搜索,因此需要index为true;无需分词器
2.索引库的CRUD
这里我们统一使用Kibana编写DSL的方式来演示。
2.1.创建索引库和映射
基本语法:
- 请求方式:PUT
- 请求路径:/索引库名,可以自定义
- 请求参数:mapping映射
格式:
PUT /索引库名称
{
"mappings": {
"properties": {
"字段名":{
"type": "text",
"analyzer": "ik_smart"
},
"字段名2":{
"type": "keyword",
"index": "false"
},
"字段名3":{
"properties": {
"子字段": {
"type": "keyword"
}
}
},
// ...略
}
}
}
例如
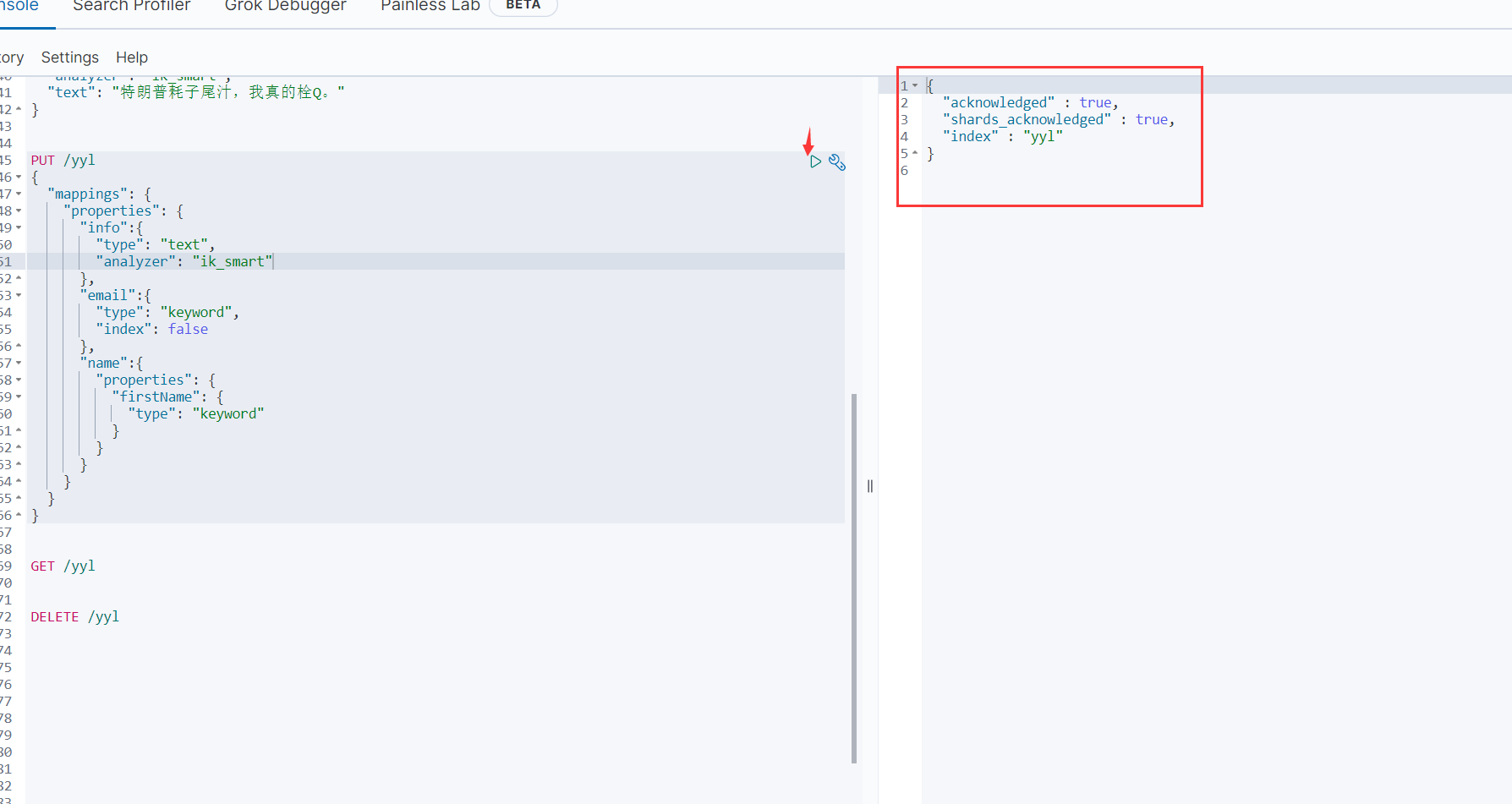
PUT /yyl
{
"mappings":{
}
}
示例:
PUT /yyl
{
"mappings": {
"properties": {
"info":{
"type": "text",
"analyzer": "ik_smart"
},
"email":{
"type": "keyword",
"index": false
},
"name":{
"properties": {
"firstName": {
"type": "keyword"
}
}
},
// 略...
}
}
}
运行,可以看到添加成功了
2.2.查询索引库
基本语法:
请求方式:GET
请求路径:/索引库名
请求参数:无
格式:
GET /索引库名
示例:
GET /yyl
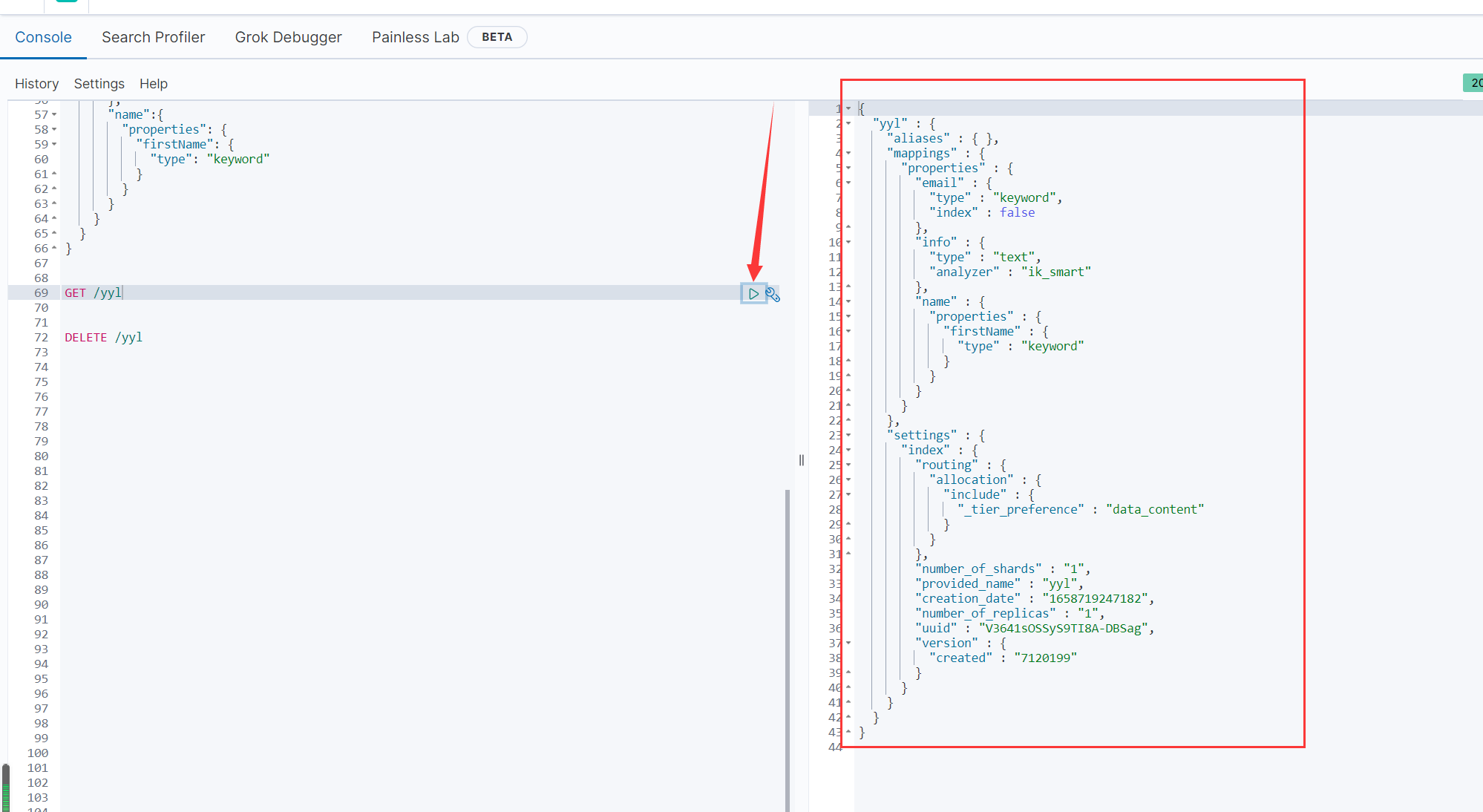
2.3.修改索引库
倒排索引结构虽然不复杂,但是一旦数据结构改变(比如改变了分词器),就需要重新创建倒排索引,这简直是灾难。

因此索引库一旦创建,无法修改mapping。
虽然无法修改mapping中已有的字段,但是却允许添加新的字段到mapping中,因为不会对倒排索引产生影响。
语法说明:
PUT /索引库名/_mapping
{
"properties": {
"新字段名":{
"type": "integer"
}
}
}
示例:
PUT /yyl/_mapping
{
"properties":{
"age":{
"type": "integer"
}
}
}

2.4.删除索引库
语法:
请求方式:DELETE
请求路径:/索引库名
请求参数:无
格式:
DELETE /索引库名
在kibana中测试:

再查就查不到了:

文档操作
1.新增文档
语法:
POST /索引库名/_doc/文档id
{
"字段1": "值1",
"字段2": "值2",
"字段3": {
"子属性1": "值3",
"子属性2": "值4"
},
// ...
}
示例:
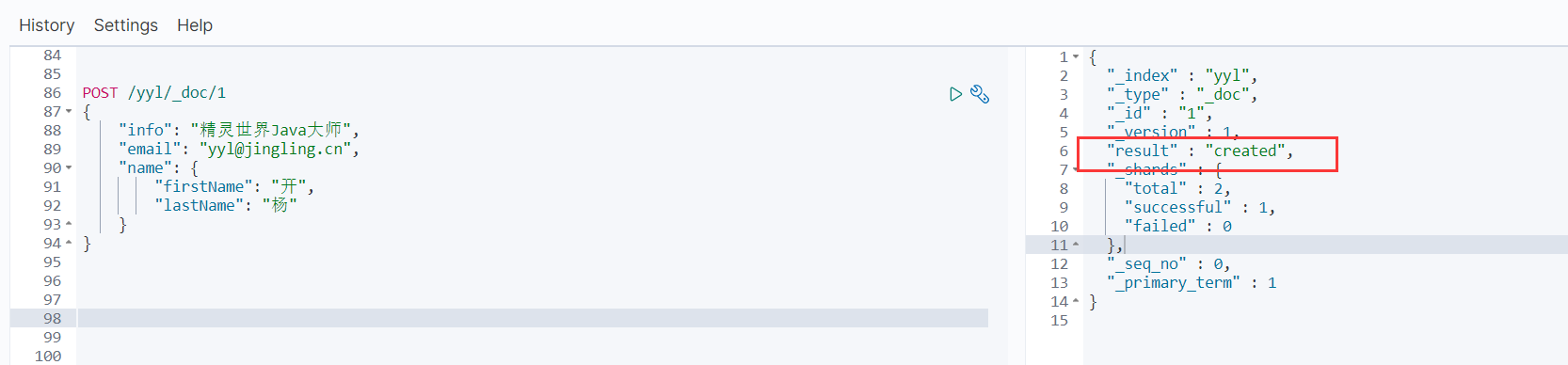
POST /yyl/_doc/1
{
"info": "精灵世界Java大师",
"email": "yyl@jingling.cn",
"name": {
"firstName": "开",
"lastName": "杨"
}
}
响应:
2.查询文档
根据rest风格,新增是post,查询应该是get,不过查询一般都需要条件,这里我们把文档id带上。
语法:
GET /{索引库名称}/_doc/{id}
通过kibana查看数据:
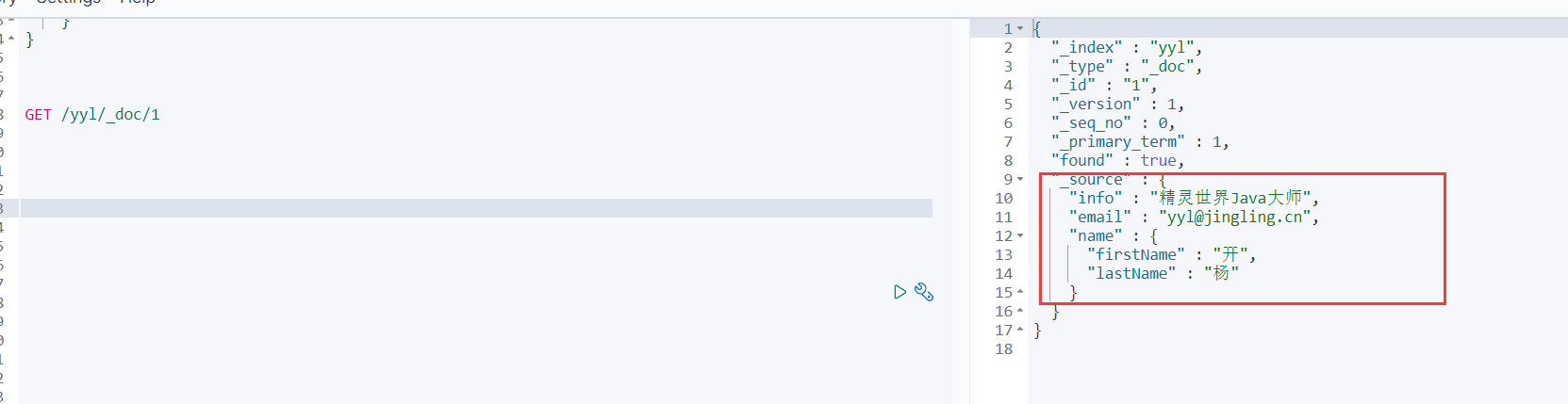
GET /yyl/_doc/1
查看结果:
在_source字段中存储这我们插入的文档信息
3.删除文档
删除使用DELETE请求,同样,需要根据id进行删除:
语法:
DELETE /{索引库名}/_doc/id值
示例:
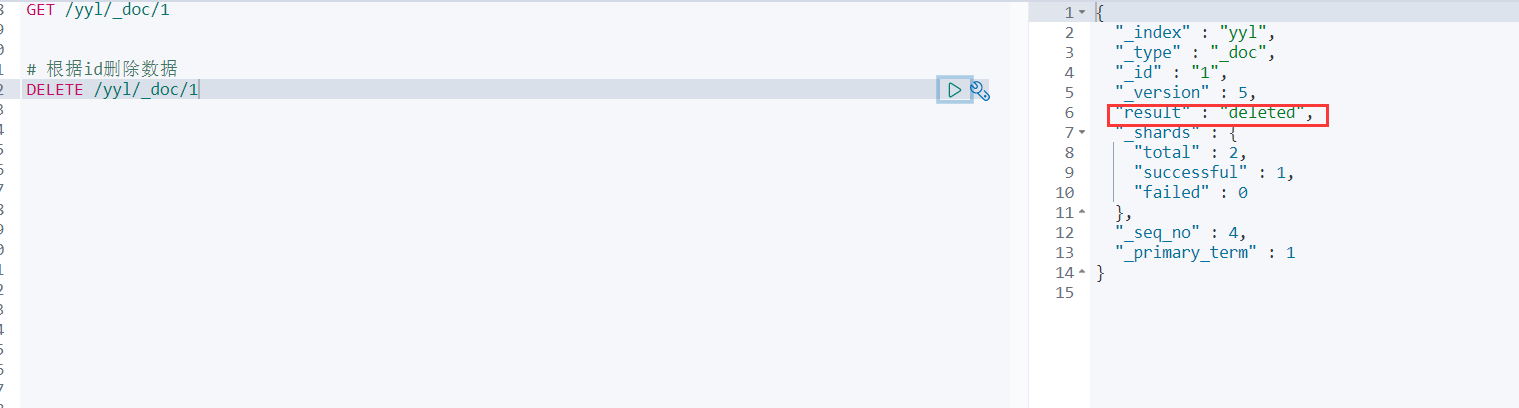
# 根据id删除数据
DELETE /yyl/_doc/1
结果:
4.修改文档
修改有两种方式:
| 修改方式 | 说明 |
|---|---|
| 全量修改 | 直接覆盖原来的文档 |
| 增量修改 | 修改文档中的部分字段 |
4.1.全量修改
全量修改是覆盖原来的文档,其本质是:
- 根据指定的id删除文档
- 新增一个相同id的文档
注意:如果根据id删除时,id不存在,第二步的新增也会执行,也就从修改变成了新增操作了。
语法:
PUT /{索引库名}/_doc/文档id
{
"字段1": "值1",
"字段2": "值2",
// ... 略
}
示例:
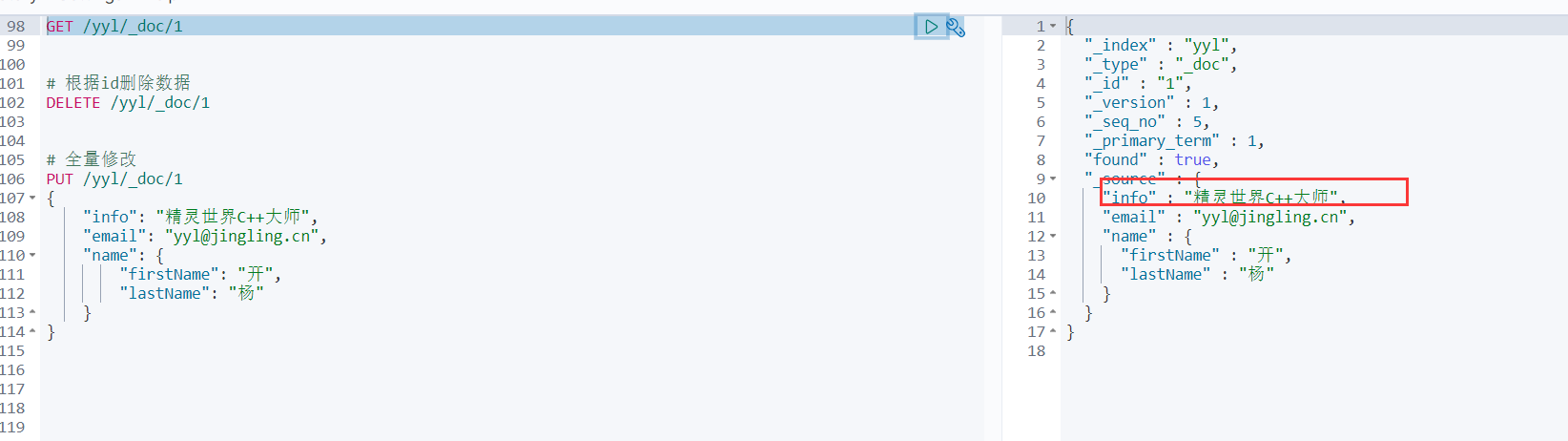
PUT /yyl/_doc/1
{
"info": "精灵世界C++大师",
"email": "yyl@jingling.cn",
"name": {
"firstName": "开",
"lastName": "杨"
}
}
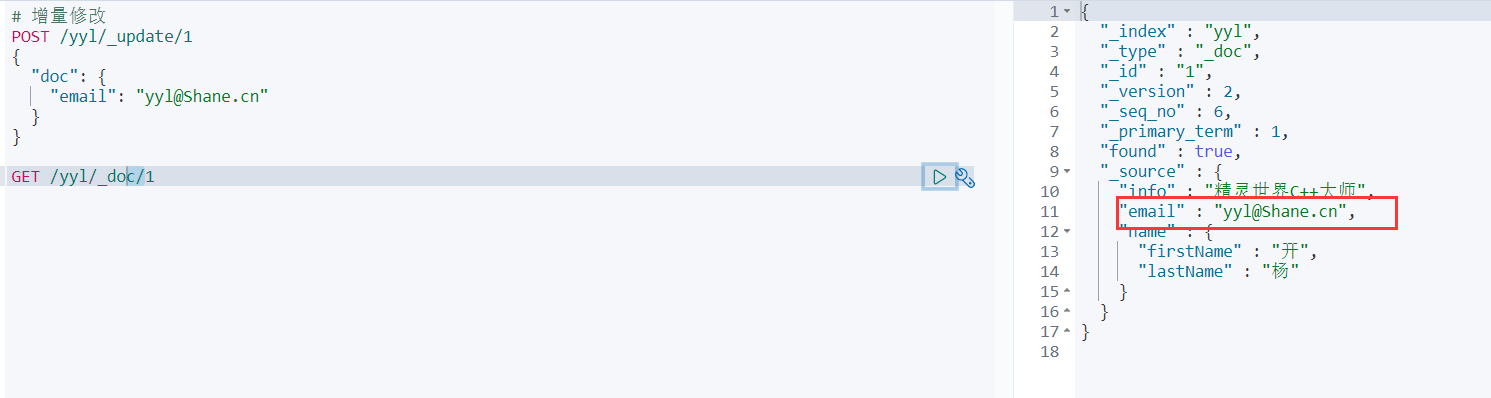
再get下,可以看到已经修改:
4.2.增量修改
增量修改是只修改指定id匹配的文档中的部分字段。
语法:
POST /{索引库名}/_update/文档id
{
"doc": {
"字段名": "新的值",
}
}
示例:
POST /yyl/_update/1
{
"doc": {
"email": "yyl@Shane.cn"
}
}
再get下,可以看到已经修改: