2018年OpenAI提出, 在BERT之前
GPT全称Generative Pre-Training, 属于生成式模型
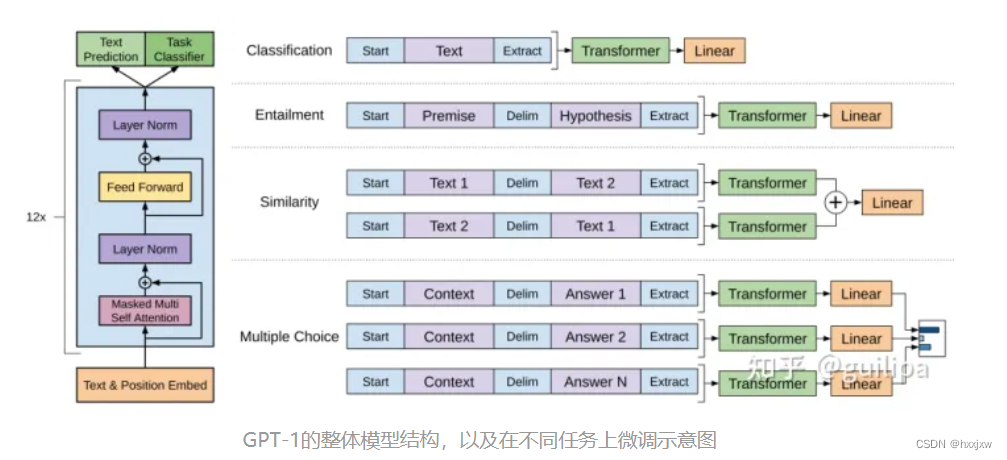
- GPT把Transformer的解码器拿出来,然后再没有标号的大量的文本数据上预训练,然后在下游任务finetune
- BERT把Transformer的编码器拿出来,然后在一个更大的数据集上预训练,取得了比GPT更好的结果
- T5是编码器解码器都用
GPT用的训练任务是给定k个连续的词,预测下一个词。这个任务要比BERT的完形填空要难。但是如果把模型做大做好之后的到的效果也比BERT惊艳。
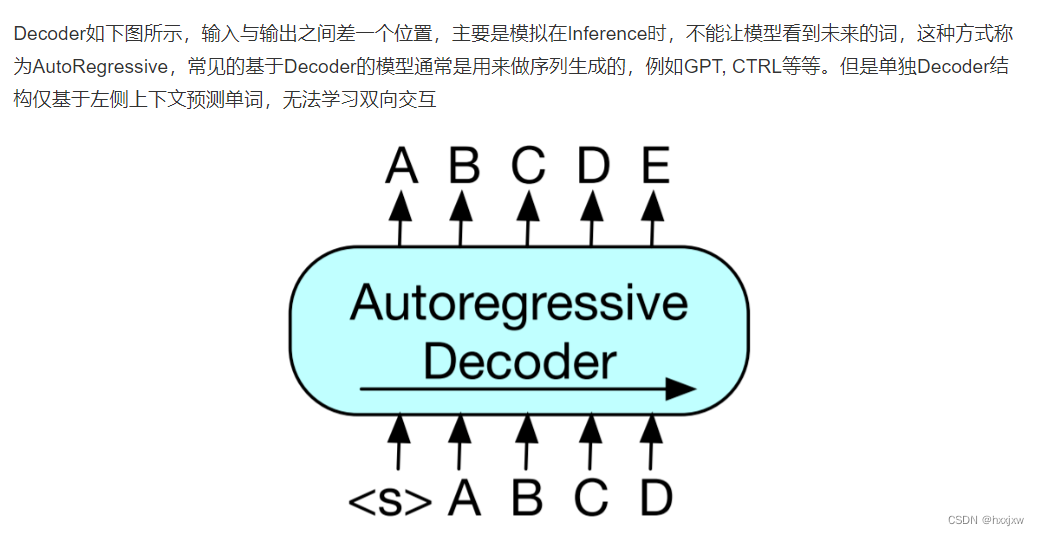
GPT用decoder和BERT用encoder最大的不同在于,decoder是有attention mask的,在对第i个元素抽特征的时候,只会看到当前元素和之前的这些元素。
也是因为GPT的训练任务,必须要用decoder,盖住后面的才行
与BERT的双向掩码语言模型不同,GPT是自回归语言模型
什么是自回归模型
GPT 训练过程分为两个部分,无监督预训练语言模型和有监督的下游任务 fine-tuning。
GPT-2
BERT-base 模型大小跟GPT一样,110M参数量(1亿)
BERT-large 340M(3亿)
GPT-2 模型大小 1.5B(15亿), 比GPT大了十几倍
GPT-2用的就是zero-shot,prompt的范式了
新做的WebText数据集
GPT-3
GPT-3拥有1750亿训练参数(700G训练数据),比GPT-2大了100倍,是一个完全由大数据堆出来的模型
模型结构和GPT-2差不多,也即和GPT差不多
不是做zero-shot了,而是做few-shot(在现实生活中人类要学习的时候也是需要通过一些样本来学习)
但是应用到下游任务的时候,仍然是不会训练模型, few-shot的样本直接作为prompt放在输入
GPT-3使用V100集群训的
GPT-3跟很多深度学习模型一样,都是无法解释的。模型得到一个不错的结果,我们并不知道模型中哪些权重是在真正起作用,整个决策是怎么做的。所以,大力出奇迹
