why预训练+finetune
目前在nlp领域,比较流行的一种方式就是“pretrain+finetune”
为什么是这种模式呢?
- 在nlp领域大量数据是无标签的,只有小量数据是有标签的,而大量数据可以帮助模型获得更好的效果(泛化能力),所以在pretrain阶段采用大量无标签的数据无监督学习(在此阶段模型没有明确的下游任务目标,学习的是普适的文本特征),而再在finetune阶段再根据不同具体任务使用小量有标签的数据有监督微调;
- 在nlp领域任务种类并不只有一种,也就是说上面提到的finetune阶段任务是各种各样的,这样如果没有pretrain,只能像之前word2vec那样给finetune提供单个词的特征向量,而无法关注整体上下文(这里顺便提一下上周的ELMO是第一个“pretrain+finetune”方式的,就是在pretrain阶段获取了上下文信息)
各种预训练模型的区别
上周提到的ELMO是采用了加入双层双向LSTM的方式进行预训练,获得词的上下文信息,本文要提及的BERT和GPT则是使用transformer替代LSTM,相对而言,transformer鲁棒性更好,可以叠加计算的层数更多,在长距离的表现也更好。(另外,GPT和BERT与ELMO还有一个最本质的区别,就是ELMO pretrain的结果是fintune模型的一个特征输入,而GPT和BERT就是在fintune模型上做pretrain)

GPT和BERT之间的区别则是:GPT选择了transformer中decoder阶段结构作为预训练结构;而BERT选择了transformer中encoder阶段结构作为预训练结构。
这样首先需要知道encoder结构和decoder结构之间的利弊:
| encoder | decoder |
|---|---|
| 双向网络 | 单向网络 |
| 没有天然的预测目标(Bert自己构造mask) | 有天然的预测目标(天然mask+预测下一个词) |
| 能看到所有词(更适合做语言理解) | 只能看到一个词前面的词(更适合做语言预测) |
上述这些优缺点其实也就是GPT和BERT的主要区别。
GPT
GPT-整体架构

如上面所说,GPT使用了transformer的decoder部分,每层Trms构成了一个自左向右单层的transformer,总共堆叠了12层Trms。
GPT去掉了原先decoder中使用encoder进行attention的部分(因为没使用encoder啊),每层Trms只有一个 Masked Multi Self-Attention(768 维向量+12个Attention Head)和一个 Feed Forward,如下图所示:

GPT-pretrain
训练目标:给定一个无监督的标记语料库U={u1,u2…un} ,我们使用一个标准的语言建模目标来最大化以下可能性:
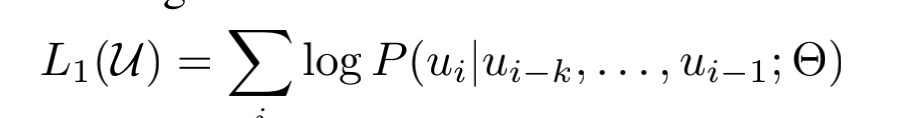
具体训练方式如前面所说,将token的词嵌入和位置嵌入作为输入h0(0表示第一层),然后叠加12层transformer,最后通过softmax获得预测的下一个单词的概率。

其中U=(u-k,……,u-1)是当前token前的k个tokens,n是模型层数(12层),We是tokens词嵌入的embedding矩阵(句子长度embed纬度),Wp是位置嵌入的embedding矩阵(语料库词汇大小embed纬度)。(两个embedding均为随机初始化)。
GPT-finetune
我们假设一个有标记的数据集C,由一组输入tokens序列x1,……,xm,还有一个标签y组成,
将这些tokens输入pretrain的模型获得最终层transformer的输出hlm,
然后将其输入到一个附加的线性输出层,通过参数Wy来预测标签y:
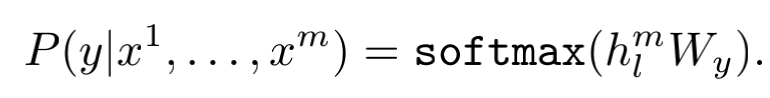
最终有监督finetune期望的目标是,最大化以下目标:
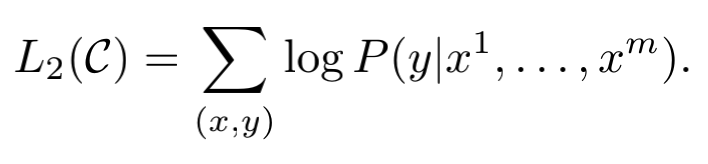
在实验中发现,将pretrain中的目标L1一起加入进来可以更好的范化监督模型,而且可以加速收敛,所以最终finetune阶段的目标为:
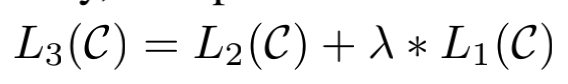
总的来说,在finetune阶段,我们需要的唯一额外参数是Wy和分隔符标记的tokens。
GPT- Task-specific input transformations
对于文本分类任务,直接使用上述的finetune即可,但对于其他任务,如文本蕴含、文本相似度、问答等,由于我们的pretrain模型是在连续的文本序列上进行训练的,所以我们需要进行一些修改来将其应用于这些任务。
为了防止模型有比较大的改动,主要对输入进行了改动,如下图所示,这些改动包括增加了新的linear层,以及为tokens之间增加了start、delim、extract这些分隔符、标识位。

下面为三种任务的输入改动:
- 文本蕴含任务:(文本蕴含是指当一个句子p为前提时,可以推断出另一个句子h假设为真)输入改动为:将前提句子p和假设句子h的tokens序列连接起来,中间有一个分隔符标记(delim)。
- 文本相似任务:对于相似任务,被比较的两个句子没有固有的排序。为了反映这一点,论文修改了输入序列,让两种可能的句子顺序进行拼接(在两个句子中间加分隔符delim ),分别独立过transformer,生成两个序列的表示hml,然后按位相加,再过线性层和softmax层。
- 问答、推理:对于这些任务,存在一个上下文文档z、一个问题q和一组可能的答案{ak}。论文将文档上下文和问题与每个可能的答案连接起来,并添加一个分隔符$在中间得到t [z; q; $; ak].。这些序列中的每个都用GPT模型独立处理,然后通过一个softmax层进行归一化,以产生可能答案的输出概率分布。