在网上随便找两个网络URL入参
{
"fileUrls": [
"url1",
"url2",
"url3"
"zipName":"xxxx"
}
@Override
public void getUrlsToZip(UrlDownLoadFileParam urlDownLoadFileParam,HttpServletResponse response ) throws Exception {
String zipName = StringUtil.isEmpty(urlDownLoadFileParam.getZipName())?(new Date().getTime()+""):urlDownLoadFileParam.getZipName();
response.setHeader("content-type", "application/octet-stream");
response.setHeader("Content-Disposition","attachment;filename=" + URLEncoder.encode(zipName+".zip", "UTF-8"));
response.setCharacterEncoding("utf-8");
ZipOutputStream zipOut = new ZipOutputStream(response.getOutputStream());
try {
//处理文件
for (String iUrl : urlDownLoadFileParam.getFileUrls()) {
String pathDecodehttps = URLDecoder.decode(iUrl, "UTF-8");//解码
String pathDecode = pathDecodehttps.replaceAll("^https://", "http://");
URL url = new URL(pathDecode);// 读取url信息
zipOut.putNextEntry(new ZipEntry(FilenameUtils.getName(pathDecode)));// 创建url文件
InputStream in = new BufferedInputStream(url.openStream());// 读取url文件信息
zipOut.write(readInputStream(in));//把url文件写入zip中
zipOut.closeEntry();// 关闭入口
in.close(); // 关闭连接
}
} catch (IOException e) {
throw new Exception("导出压缩包失败");
}finally {
response.getOutputStream().flush();
//response.getOutputStream().close();
// 注释response.getOutputStream().close(); 是因为 java.io.IOException: UT010029: Stream is closed 这个错误是由于这个流被关闭了,
// 而在其他地方又用到了这个流,所以获取不到流就会报错了由于对输出流进行了关闭操作,
// 这个流是从response中拿到的,不是自己创建的将它关闭的话,Spring MVC框架中可能会使用流进行编码处理等操作,由于拿不到流从而导致的报错。
}
}
//根据文件链接把文件下载下来并且转成字节码
public byte[] readInputStream(InputStream is) {
ByteArrayOutputStream baos = new ByteArrayOutputStream();
byte[] buffer = new byte[1024];
int length = -1;
try {
while ((length = is.read(buffer)) != -1) {
baos.write(buffer, 0, length);
}
baos.flush();
} catch (Exception e) {
e.printStackTrace();
}
byte[] data = baos.toByteArray();
try {
is.close();
baos.close();
} catch (Exception e) {
e.printStackTrace();
}
return data;
} //根据文件链接把文件下载下来并且转成字节码
public byte[] readInputStream(InputStream is) {
ByteArrayOutputStream baos = new ByteArrayOutputStream();
byte[] buffer = new byte[1024];
int length = -1;
try {
while ((length = is.read(buffer)) != -1) {
baos.write(buffer, 0, length);
}
baos.flush();
} catch (Exception e) {
e.printStackTrace();
}
byte[] data = baos.toByteArray();
try {
is.close();
baos.close();
} catch (Exception e) {
e.printStackTrace();
}
return data;
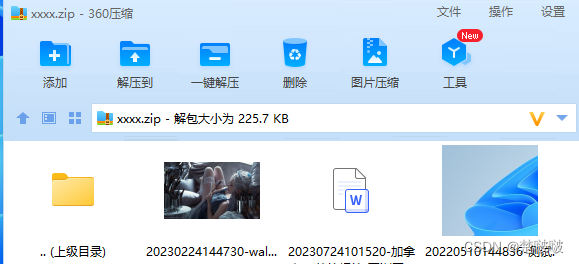
}结果图:支持图片 word pdf等文件
本文含有隐藏内容,请 开通VIP 后查看