1、贪婪量词和懒惰量词
贪婪量词:也就是尽可能多的匹配字符
懒惰量词:尽可能少的匹配字符(在现在的计算机语言中大多默认为贪婪量词若想要使用 懒惰量词就需要在后面加上?即可)
代码示例:
import re
p = r'\d{5,8}'
p_1 = r'\d{5,8}?'
i = '8765411'
m = re.search(p, i)
print(m)
m_1 = re.search(p_1, i)
print(m_1)
结果:

这里就能看出在懒惰量词的作用下,匹配最少次,而贪婪会匹配最多
2、re模块
1、search()和match函数、
这两个函数十分相似但是又有一点不同,其中search返回的是第一个匹配内容,而match函数是匹配全部内容
下面是代码示例
import re p= r'\w+@zhang\.com' te = "chengxian shi guoduyinyong@zhang.com" m = re.match(p,te) print(m) m_1 = re.search(p,te) print(m_1)
代码结果如下:

2、findall()和finditer()函数
这两个函数也是十分相似,两个函数最大差别在于返回对象的差别
下面是代码示例:
import re
p = r'\w+@zhang\.com'
te = "chengxian shi guoduyinyong@zhang.com"
m = re.findall(p, te)
print(m)
m_1 = re.finditer(p, te)
print(m_1)
for i in m_1:
print(i.group())
代码结果如下:

从结果来看,两个函数最大区别就是返回对象的类型的问题,所谓findall是直接返回一个列表对象,而finditer是返回了一个可迭代的对象
3、字符串分割
split()函数这里返回的是列表对象
常见的用法有
re.split()和input().split()
下面是示例
def jia(a, b):
return a / b
p = input().split(',')
print(jia(*map(int, p)))
import re p = r'\w+@zhang\.com' te = "chengxian shi guoduyinyong@zhang.com" m = re.split(p, te, maxsplit=0) print(m)
代码结果分别为:
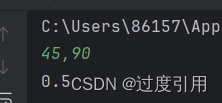
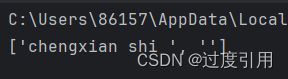
从这里也能看出split这个函数使用范围是很大的也是很有用的