在这篇博客文章中,我们将探讨pgvector如何帮助PostgreSQL中的基于AI的工作负载,使您的数据库向量操作更快、更高效。
pgvector:在PostgreSQL中存储和查询向量
pgvector 是一个PostgreSQL扩展,允许您存储、查询和索引向量。
截至PostgreSQL 16,PostgreSQL还没有原生的向量功能,pgvector旨在填补这一空白。您可以将向量数据与PostgreSQL中的其余数据一起存储,并同时利用PostgreSQL提供的所有出色功能进行向量相似性搜索。
什么时候需要向量相似性搜索?
在处理高维数据时,尤其是在推荐引擎、图像搜索和自然语言处理等应用中,向量相似性搜索是一个关键能力。许多AI应用涉及基于用户行为或内容相似性的查找相似项或推荐。pgvector可以高效地执行向量相似性搜索,使其适用于推荐系统、基于内容的过滤和基于相似性的AI任务。
pgvector扩展与PostgreSQL无缝集成——允许用户在现有的数据库基础设施内利用其能力。这简化了AI应用的部署和管理,因为没有单独的数据存储或复杂的数据传输过程的需要。
向量究竟是什么?
简而言之,向量是数字列表,如【1,2,4,7】。如果您曾经上过线性代数课程,现在是时候收获好处了,因为相似性搜索本质上就是在进行一系列向量操作!
在几何学中,向量代表了一个n维空间中的坐标,其中n是维度的数量。在下面的图像中,有一个二维向量(n=2)。在机器学习中,我们使用高维向量,它不像下面简单展示的向量那么容易想象。
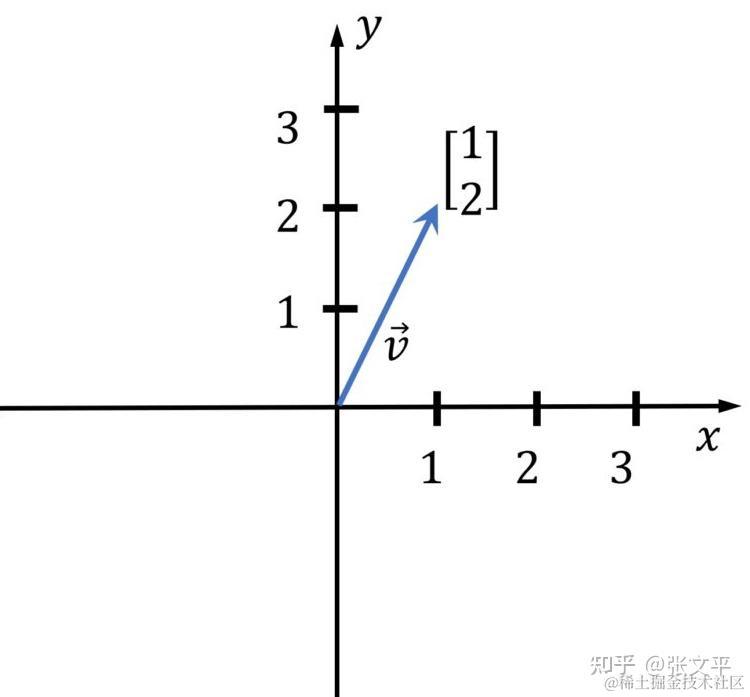
让我们来看一个例子:
在这个例子中,我们将存储一些文档,生成向量嵌入并将它们存储在PostgreSQL中。我们将对嵌入数据建立索引,并在我们的嵌入上运行相似性查询。
环境准备
- 已安装PostgreSQL(pgvector支持PostgreSQL 11+)
- 安装了pgvector扩展(参见安装说明),或者直接使用免安装的服务MemFire Cloud
- 拥有OpenAPI账户并有一些余额,国内有一些相关的服务。
一旦安装了pgvector,您可以通过创建扩展来在您的PostgreSQL数据库中启用它:
postgres=# Create extension vector;
CREATE EXTENSION
步骤1:为文档创建表
让我们创建一个简单的表来存储文档。这个表中的每行代表一个文档,我们存储了文档的标题和内容。
创建文档表:
CREATE TABLE documents (
id int PRIMARY KEY,
title text NOT NULL,
content TEXT NOT NULL
);
对于我们存储的每个文档,我们将生成一个嵌入,并且在这里我们创建了一个document_embeddings表来存储这些嵌入。您可以看到嵌入向量的大小为1536,这是因为我们使用的OpenAI模型具有1536维。
-- 创建document_embeddings表
CREATE TABLE document_embeddings (
id int PRIMARY KEY,
embedding vector(1536) NOT NULL
);
让我们使用HNSW索引对我们的数据建立索引。
CREATE INDEX document_embeddings_embedding_idx ON document_embeddings USING hnsw (embedding vector_l2_ops);
HNSW比IVFFlat具有更好的查询性能,对于IVFFlat索引,建议在表中有一些数据后创建索引,但HNSW索引没有像IVFFlat那样的训练步骤,所以可以在没有数据的表中创建索引。您可能注意到我是在插入数据之前创建索引的。
现在我们可以向表中插入一些示例数据。在这个例子中,我选择了PostgreSQL扩展及其简短描述。
-- 向文档表中插入文档
INSERT INTO documents VALUES ('1', 'pgvector', 'pgvector是一个PostgreSQL扩展,提供了SQL中向量相似性搜索和最近邻搜索的支持。');
INSERT INTO documents VALUES ('2', 'pg_similarity', 'pg_similarity是一个PostgreSQL扩展,为向量列提供了相似性和距离运算符。');
INSERT INTO documents VALUES ('3', 'pg_trgm', 'pg_trgm是一个PostgreSQL扩展,提供了基于三gram匹配确定字母数字文本相似性的功能和运算符。');
INSERT INTO documents VALUES ('4', 'pg_prewarm', 'pg_prewarm是一个PostgreSQL扩展,提供了将关系数据预热到PostgreSQL缓冲缓存中的函数。');
步骤2:生成嵌入
现在我们已经存储了文档,我们将使用嵌入模型将文档转换为嵌入。
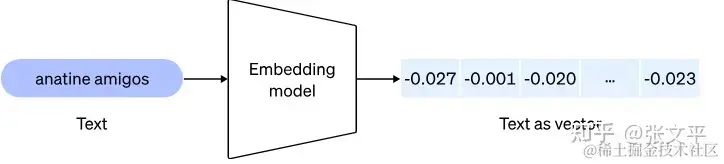
但首先,让我们谈谈嵌入。我最喜欢OpenAI文档中的定义,因为它简单明了:
“嵌入是一个浮点数向量(列表)。两个向量之间的距离衡量它们的相关性。小距离表示高相关性,大距离表示低相关性。”
因此,如果我们想比较两个文档在语义上的相关性,那么我们就需要将这些文档转换为嵌入,并对它们进行相似性搜索。
在这个例子中,我使用了OpenAI API和Python。有多种API提供商可供选择,您可以使用这些API从您选择的任何语言中使用。由于其简单性以及我对它的先前经验,我选择了OpenAI API,而Python是我的首选语言。示例中使用的嵌入模型是“text-embedding-ada-002”,它将为我们的用例很好地工作,因为它既便宜又简单易用。在实际应用中使用时,您可能需要根据您的具体用例评估不同的模型。
让我们开始。对于下面的Python代码,您需要获取您的OpenAI API密钥,并填写连接到您的PostgreSQL数据库的连接字符串。
# Python代码以预处理和嵌入文档
import openai
import psycopg2
# 加载OpenAI API密钥
openai.api_key = "sk-..." #您自己的API密钥
# 选择嵌入模型
model_id = "text-embedding-ada-002"
# 连接到PostgreSQL数据库
conn = psycopg2.connect(database="postgres", user="gulcin.jelinek", host="localhost", port="5432")
# 从数据库中获取文档
cur = conn.cursor()
cur.execute("SELECT id, content FROM documents")
documents = cur.fetchall()
# 处理并将嵌入存储在数据库中
for doc_id, doc_content in documents:
embedding = openai.Embedding.create(input=doc_content, model=model_id)['data'][0]['embedding']
cur.execute("INSERT INTO document_embeddings (id, embedding) VALUES (%s, %s);", (doc_id, embedding))
conn.commit()
# 提交并关闭数据库连接
conn.commit()
这段代码简单地从数据库中获取文档内容,并使用OpenAI API生成嵌入,然后将它们存储回数据库。这对于我们的小数据库来说是可以的,但在现实世界的场景中,您可能希望对现有数据使用批处理,并可能使用某种事件触发器或更改流来随着数据库的变化保持向量更新。
步骤3:查询嵌入
现在我们已经在数据库中存储了嵌入,我们可以使用pgvector查询它们。下面的代码展示了如何执行相似性搜索以查找与给定查询文档相似的文档。
# Python代码以预处理和嵌入文档
import psycopg2
# 连接到PostgreSQL数据库
conn = psycopg2.connect(database="postgres", user="gulcin.jelinek", host="localhost", port="5432")
cur = conn.cursor()
# 基于它们的描述查找与pgvector相似的扩展
query = """
WITH pgv AS (
SELECT embedding
FROM document_embeddings JOIN documents USING (id)
WHERE title = 'pgvector'
)
SELECT title, content
FROM document_embeddings
JOIN documents USING (id)
WHERE embedding <-> (SELECT embedding FROM pgv) < 0.5;"""
cur.execute(query)
# Fetch results
results = cur.fetchall()
# Print results in a nice format
for doc_title, doc_content in results:
print(f"Document title: {doc_title}")
print(f"Document text: {doc_content}")
print()
查询首先获取标题为“pgvector”的文档的嵌入向量,然后使用相似性搜索获取内容相似的文档。注意<->运算符,那就是所有pgvector魔法发生的地方。它是我们使用HNSW索引获取两个向量之间相似性的方式。0.5是一个相似性阈值,这将高度依赖于用例,并需要在实际应用中进行微调。
当我们在导入的数据上运行我们的查询脚本时,我们看到相似性搜索找到了两个与pgvector相似的文档,其中一个就是pgvector本身。
❯ python3 query.py
Document title: pgvector
Document text: pgvector是一个PostgreSQL扩展,提供了SQL中向量相似性搜索和最近邻搜索的支持。
Document title: pg_similarity
Document text: pg_similarity是一个PostgreSQL扩展,为向量列提供了相似性和距离运算符。
原文:https://zhuanlan.zhihu.com/p/690423202