一、sort
作用:以行为单位,对文件内容进行排序
格式:
sort 【选项】 参数
常用选项:
| -n | 按照数字进行排序 |
| -r | 反向排序 |
| -u | 等同于uniq,表示相同的数据仅显示一行 |
| -t | 指定字段分隔符,默认使用[Tab]键分隔 |
| -k | 指定排序字段 |
| -o | <输出文件>将排序后的结果转存至指定文件 |
| -f | 忽略大小写,会将小写字母都转换为大写字母来进行比较 |
| -b | 忽略每行前面的空格 |
示例1
将文件中的内容按数字正向或反向排序
sort -n 文件
sort -nr 文件

示例2
格式:sort -t ‘字段分割符’ -k '字段号'
解析:根据-t指定的分割符的第k个字段进行排序
sort -t ':' -k 3 -n /etc/passwd #将/etc/passwd中的文件的第三个字段按照数字排序
sort -t ':' -k 3 -n /etc/passwd > /opt/passwd.txt #将结果保存到passwd.txt中
sort -t ':' -k 3 -n /etc/passwd -o /opt/passwd.txt #将结果保存到passwd.txt中
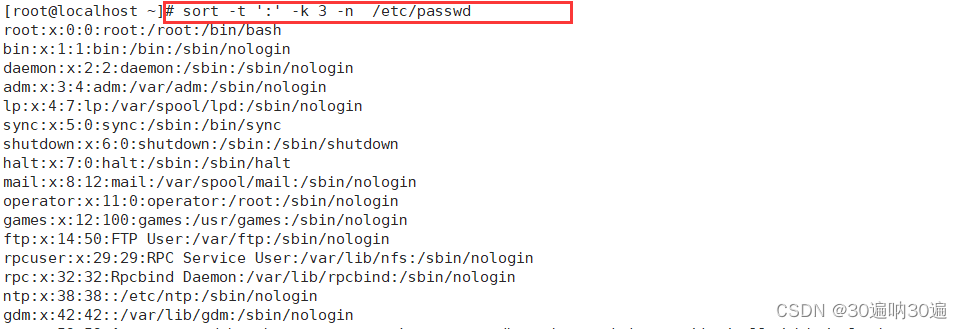
示例3:
通过sort命令查找大文件
du -a /var/log | sort -nr

二、uniq
作用:用于报告或者忽略文件中连续的重复行,常与 sort 命令结合使用
语法格式:
uniq [选项] 参数
cat file | uniq 选项
常用选项:
| -c | 进行计数,并删除文件中重复出现的行 |
| -d | 仅显示连续的重复行 |
| -u | 仅显示出现一次的行 |
uniq 1.txt #合并相同的行,且不连续的行不删除

sort -n 1.txt | uniq -c #排序并计数重输出

典型示例:
在 /var/log/secure 记录ssh登录信息,若密码输入失败超过6次,则禁用该用户(即放入到 /etc/hosts.deny)
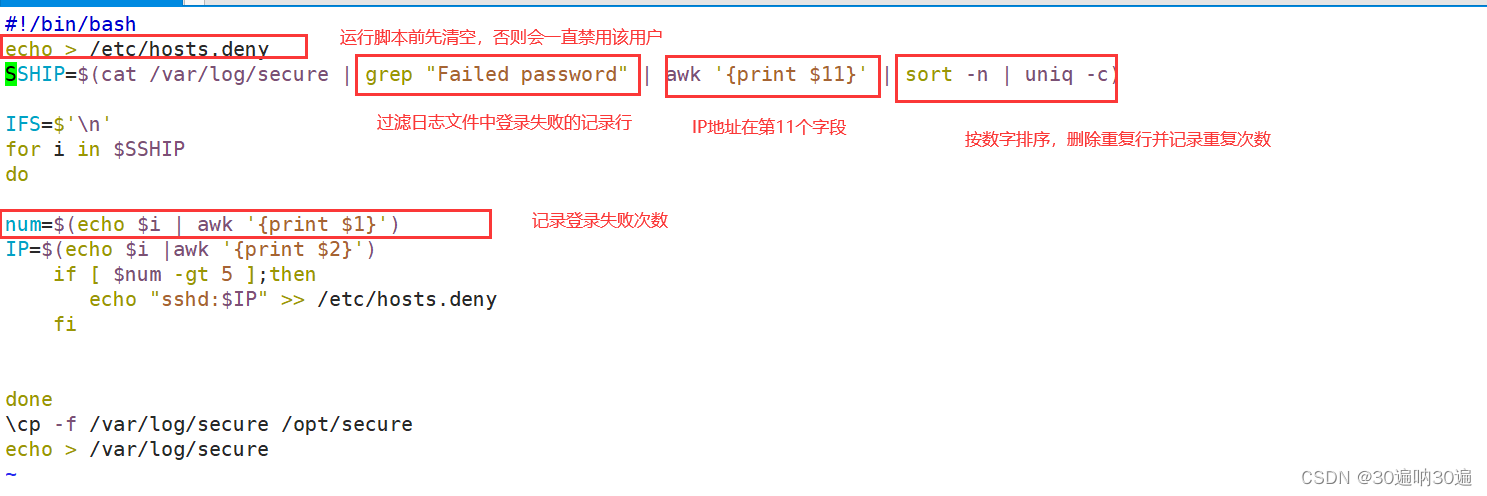
三、tr命令
作用:替换、压缩、删除
格式: tr 【选项】 【参数】
常用选项:
| -c | 保留字符集1的字符,其他的字符(包括换行符\n)用字符集2替换 |
| -d | 删除所有属于字符集1的字符 |
| -s | 将重复出现的字符串压缩为一个字符;用字符集2 替换 字符集1 |
| -t | 字符集2 替换 字符集1,不加选项同结果。 |
基本用法:
[root@localhost ~]# echo abcdefg | tr "ab" "00" #将ab替换成00
00cdefg
[root@localhost ~]# echo '192.168.10.106'| tr '.' ' ' #将. 替换成空格
192 168 10 106
[root@localhost ~]# echo abcd | tr -c "abc" "6" #将除了abc以外的字符替换成6,末尾的换行符也换成6
abc66[root@localhost ~]# echo abcd | tr -d "d" #将d删除
abc
[root@localhost ~]# cat 1.txt
11
22
33
44
33
22
11
66
55
44
33
99
22
33
[root@localhost ~]# sort -n 1.txt | tr -s '\n' 将空行压缩成一个
11
11
22
22
22
33
33
33
33
44
44
55
66
99删除空行 :
echo -e "aa\n\n\n\n\nbb" | tr -s "\n"
cat testfile5 | tr -s "\n"
不用算法实现排序
[root@localhost ~]# array=(20 50 10 40 60 30)
[root@localhost ~]# echo ${array[@] | tr ' ' '\n' | sort -n | tr '\n' ''}
20 50 10 40 60 30四、cut命令
作用:显示行中指定的部分,删除文中指定的字段
| -d '分隔符' -f 字段序号 | 根据 -d 指定的分隔符的截取显示 -f 指定的字段 |
| --complement | 取反,不显示 -f 指定的字段 |
| --output-delimiter '分隔符' | 指定输出的字段分隔符 |
字符串分片
echo ${变量:下标:长度} #下标起始从0开始
echo $变量 | cut -b 起始下标-终止下标 #下标起始从1开始expr substr $变量 起始下标 长度 #下标起始从1开始
例:i='abcdefg' 输出cd
1、echo $i | cut -b 3-4 下标从1开始
2、echo ${i:2:2} 下标从0开始
3、expr substr $i 3 2 下标从1开始
四、split命令
作用:按照格式拆分文件
| -l | 根据行数分割文件 |
| -b | 根据大小分割文件 |
| -d | 输出的目标文件后缀用数字替代 |
示例:
如何将一个10G文件分割为10个1G的文件 split -b 1G -d 原文件 目标文件名前缀
如何将一个100行文件分割为10个10行的文件 split -l 10 -d 原文件 目标文件名前缀
五、paste命令
作用:文件列合并
| -d '分隔符' | 指定输出的字段分隔符 |
| -s | 将每个列横向输出 |
格式:
合并文件的行 cat 文件1 文件2 ... > 新文件
合并文件的列 paste -d '分隔符' 文件1 文件2 ... > 新文件
合并列:
[root@localhost ~]# cat b.txt
1
2
3
4
[root@localhost ~]# cat a.txt
a:zhangsan
b:lisi
c:wangwu
d:zhaoliu
[root@localhost ~]# paste -d ':' b.txt c.txt
1:zhangsan
2:lisi
3:wangwu
4:zhaoliu
合并行:
[root@localhost ~]# paste -d ':' -s b.txt c.txt
1:2:3:4
zhangsan :lisi:wangwu:zhaoliu
六:正则表达式
基础元字符
| \ | 转义字符,将一些特殊符号转义成普通字符 \? \! \\ 将一些普遍字母字符转义成特殊字符 \n \t \r |
| ^ | 匹配以指定字符串开头的 ^XXX |
| $ | 匹配以指定字符串结尾的 XXX$ ^$ |
| . | 代表除了 \n 以外的任意字符 |
| [XXX] | 匹配中括号里的列表中的任意一个字符 [.\n] [0-9] [a-zA-Z0-9] |
| [^XXX] | 匹配除了中括号里的列表中的任何字符 [^0-9]匹配所有非数字的字符 [^a-zA-Z]匹配所有非大小字母的字符 |
| * | 匹配*前面的字符或表达式任意次数(包括0次 1次或多次) .* [0-9]* |
| \{n\} | 匹配前面的子表达式n次,例:go\{2\}d、'[0-9]\{2\}'匹配两位数字 |
| \{n,m\} | 匹配前面的子表达式n到m次,例:go\{2,3\}d、'[0-9]\{2,3\}'匹配两位到三位数字 注:egrep、awk使用{n}、{n,}、{n,m}匹配时“{}”前不用加“\” |
| \w | 匹配包括下划线的任何单词字符。\W :匹配任何非单词字符。等价于“[^A-Za-z0-9_]”。 |
| \d | 匹配一个数字字符。\D :匹配一个非数字字符。等价于 [^0-9]。 grep -P |
| \s | 空白符。\S :非空白符 |
(注:grep sed 使用时 {} 前面要加 \ ;egep awk grep -E sed -r 使用时 {} 前面不用加 \)
扩展正则表达式元字符
| + | 匹配前面子表达式1次以上,例:go+d,将匹配至少一个o,如god、good、goood等 |
| ? | 匹配前面子表达式0次或者1次,例:go?d,将匹配gd或god |
| () | 将括号中的字符串作为一个整体,例:g(oo)+d,将匹配oo整体1次以上,如good、gooood等 |
| | | 以或的方式匹配字符串,例:g(oo|la)d,将匹配good或者glad |
正则表达式匹配E-mail地址
用户名@ :^([a-zA-Z0-9_\-\.\+]+)@
子域名 :([a-zA-Z0-9_\-\.]+)
.顶级域名(字符串长度一般在2到5) :\.([a-zA-Z]{2,5})$
例1:
输出iphone.txt中区号025开头,号码与区号之间可以是空格、-、或者没有,且号码必须是5或8开头的八位数。
cat iphone.txt | egrep "^(025)[ -]?[58][0-9]{7}$"
例2:
电子邮箱:用户名@子域名【.二级域名】
用户名@:长度要求在6-18位,任意大小写英文,任意数字,处理@符号和空格以外的任意符号字符,开题只能是_或字母。
^[a-zA-Z_][^@]{5,17}@
子域名:长度任意,符号只能包含-_
([a-zA-Z0-9_\-\.]+)
.顶级域名:长度在2-5,任意大小写英文
(\.[a-zA-Z]{2,5})$
完整匹配
^[a-zA-Z_][^@]{5,17}@([a-zA-Z0-9_\-\.]+)(\.[a-zA-Z]{2,5})$