文章目录
概要
Redis有 两种不同的持久化方式, Redis 服务器通过持久化,把 Redis 内存中持久化到硬盘当中,当Redis 宕机时,我们重启 Redis 服务器时,可以由 RDB 文件或 AOF 文件恢复内存中的数据。
此时单机Redis存在以下问题:
- 硬件发生故障时如何快速恢复数据?
- 单机存在容量瓶颈问题
针对这些问题,redis提供了 复制(replication) 的功能, 通过"主从(一主多从)"和"集群(多主多从)"的方式对redis的服务进行水平扩展,用多台redis服务器共同构建一个高可用的redis服务系统。
主从复制
主从复制,是指将一台Redis服务器的数据,复制到其他的Redis服务器。前者称为主节点(master),后者称为从节点(slave),数据的复制是单向的,只能由主节点到从节点。
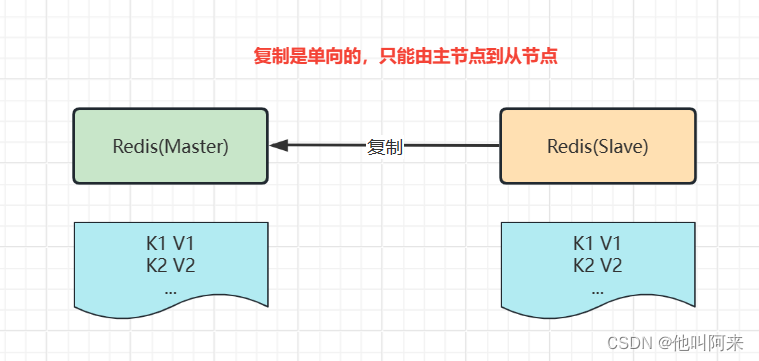
常用策略
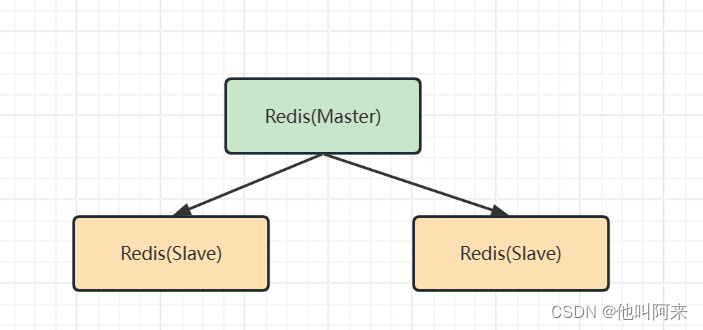
策略一:一主多从 主机(写),从机(读)
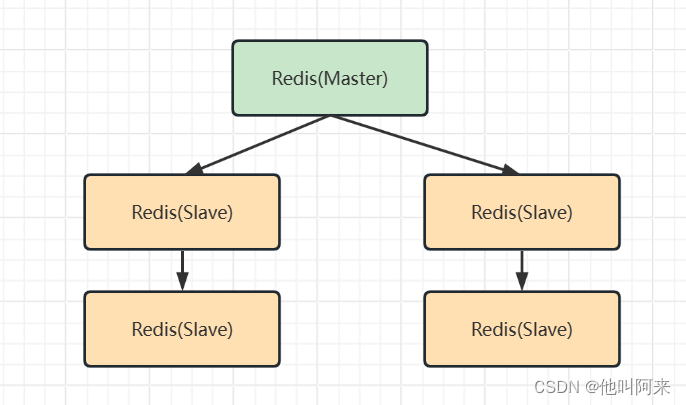
策略二:薪火相传
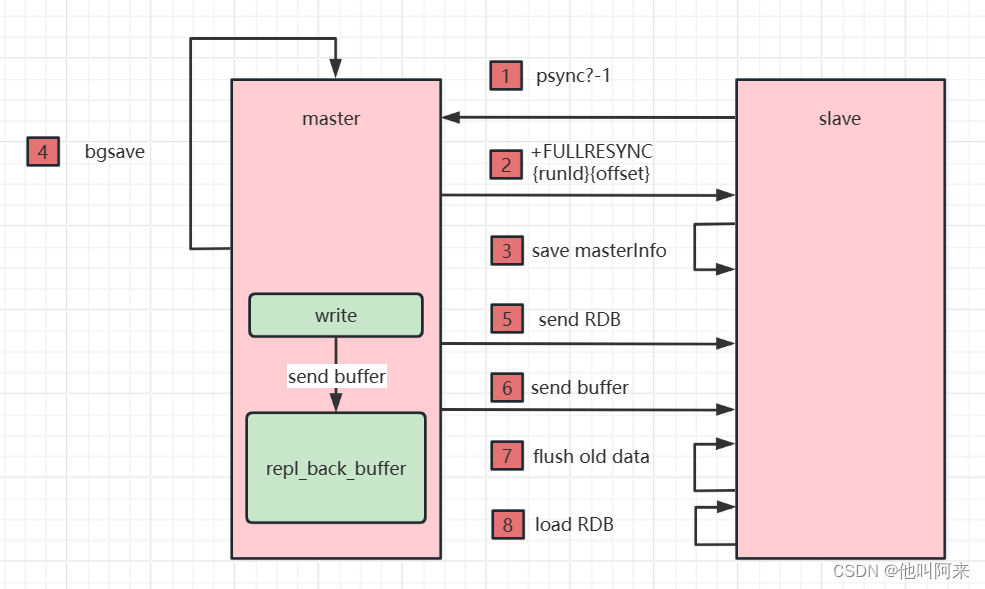
主从复制原理
Redis 的主从复制是异步复制,异步分为两个方面,一个是 master 服务器在将数据同步到 slave 时是
异步的,因此master服务器在这里仍然可以接收其他请求,一个是slave在接收同步数据也是异步的。
复制方式:
- 全量复制
master 服务器会将自己的 rdb 文件发送给 slave 服务器进行数据同步,并记录同步期间的其他写入,再发送给 slave 服务器,以达到完全同步的目的,这种方式称为全量复制。
- 增量复制
因为各种原因 master 服务器与 slave 服务器断开后, slave 服务器在重新连上 maste r服务器时会尝试重新获取断开后未同步的数据即部分同步,或者称为部分复制。
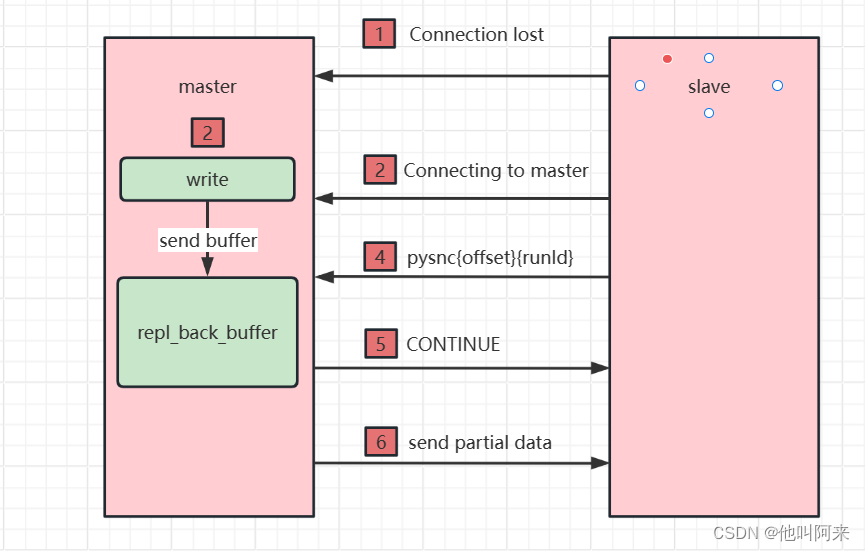
工作原理:
master服务器会记录一个replicationId的伪随机字符串,用于标识当前的数据集版本,还会记录一个当数据集的偏移量offset,不管master是否有配置slave服务器,replication Id和offset会一直记录并成对存在,我们可以通过以下命令查看replication Id和offset:
> info repliaction
通过客户端在master或者slave上执行,可以看到以下信息(不同服务器看到的结果会不一样)
connected_slaves:1
slave0:ip=127.0.0.1,port=6380,state=online,offset=9472,lag=1
master_replid:2cbd65f847c0acd608c69f93010dcaa6dd551cee
master_repl_offset:9472
当master与slave正常连接时,slave使用PSYNC命令向master发送自己记录的旧master的replication id和offset,而master会计算与slave之间的数据偏移量,并将缓冲区中的偏移数量同步到slave,此时master和slave的数据一致。
而如果slave引用的replication太旧了,master与slave之间的数据差异太大,则master与slave之间会使用全量复制的进行数据同步。
哨兵模式
主节点如果只有一个,一旦主节点挂掉之后,从节点没法担起主节点的任务,那么整个系统也无法运行。
如果主节点挂掉之后,从节点能够自动变成主节点,那么问题就解决了,于是哨兵模式诞生了。
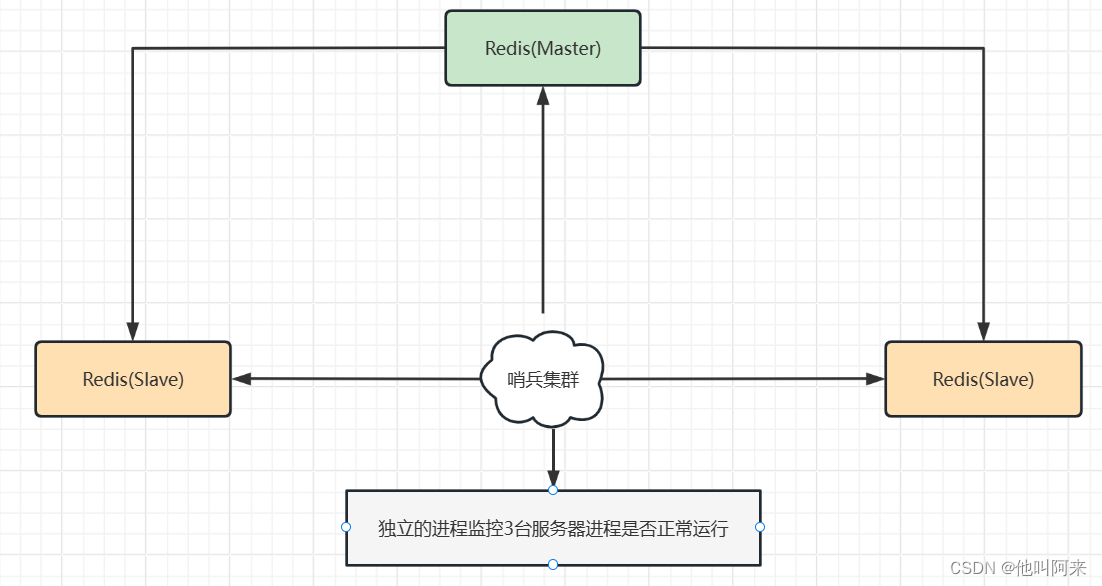
哨兵模式是一种特殊的模式,首先Redis提供了哨兵的命令,哨兵是一个独立的进程,作为进程,它会独立运行。其原理是哨兵通过发送命令,等待Redis服务器响应,从而监控运行的多个Redis实例。
哨兵的功能:
- 集群监控:负责监控Redis master和slave进程是否正常工作
- 消息通知:如果某个Redis实例有故障,那么哨兵负责发送消息作为报警通知给管理员
- 故障转移:如果master node挂掉了,会自动转移到slave node上
- 配置中心:如果故障转移发生了,通知client客户端新的master地址
哨兵模式也存在单点故障问题,如果哨兵机器挂了,那么就无法进行监控了,解决办法是哨兵也建立集群,Redis哨兵模式是支持集群的。
Redis Cluster
在主从 + 哨兵模式中,仍然只有一个Master节点。当并发写请求较大时,哨兵模式并不能缓解写压力
另外在Redis Sentinel模式中,每个节点需要保存全量数据,冗余比较多。
从3.0版本之后,官方推出了Redis Cluster,它的主要用途是实现数据分片(Data Sharding),不过同样可以实现HA,是官方当前推荐的方案。
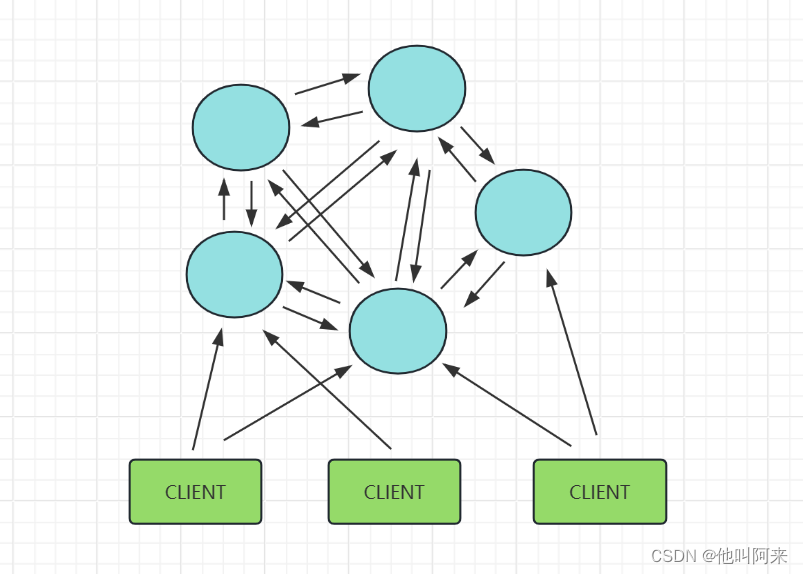
1.Redis-Cluster采用无中心结构
2.只有当集群中的大多数节点同时fail整个集群才fail。
3.整个集群有16384个slot,当需要在 Redis 集群中放置一个 key-value 时,根据 CRC16(key) mod16384的值,决定将一个key放到哪个桶中。读取一个key时也是相同的算法。
4.当主节点fail时从节点会升级为主节点,fail的主节点online之后自动变成了从节点
故障转移
Redis集群的主节点内置了类似Redis Sentinel的节点故障检测和自动故障转移功能,当集群中的某个主节点下线时,集群中的其他在线主节点会注意到这一点,并对已下线的主节点进行故障转移
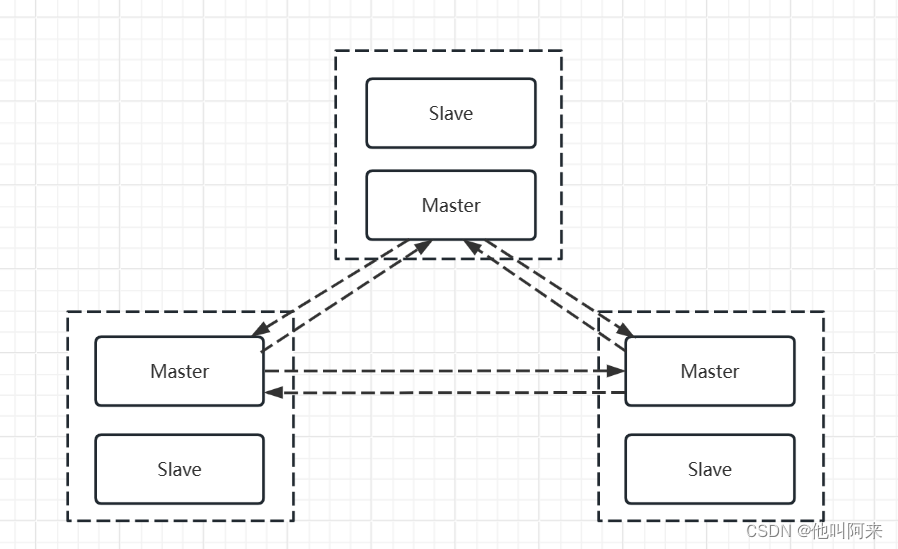
集群分片策略
Redis-cluster分片策略,是用来解决key存储位置的
常见的数据分布的方式:顺序分布、哈希分布、节点取余哈希、一致性哈希。
Redis 集群没有使用一致性hash, 而是引入了 哈希槽的概念.
预设虚拟槽,每个槽就相当于一个数字,有一定范围
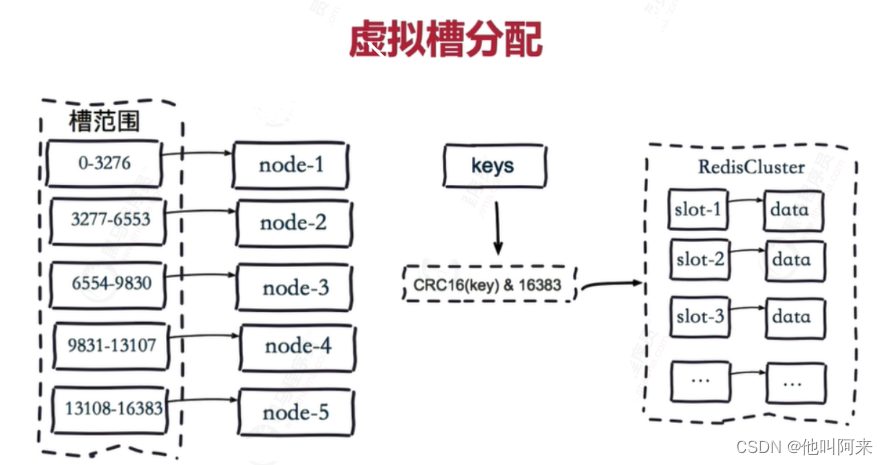
分配步骤如下:
- 把16384槽按照节点数量进行平均分配,由节点进行管理
- 对每个key按照CRC16规则进行hash运算
- 把hash结果对16383进行取余
- 把余数发送给Redis节点
- 节点接收到数据,验证是否在自己管理的槽编号的范围
- 如果在自己管理的槽编号范围内,则把数据保存到数据槽中,然后返回执行结果
- 如果在自己管理的槽编号范围外,则会把数据发送给正确的节点,由正确的节点来把数据保存在对应的槽中
需要注意的是:Redis Cluster的节点之间会共享消息,每个节点都会知道是哪个节点负责哪个范围内的数据槽
虚拟槽分布方式中,由于每个节点管理一部分数据槽,数据保存到数据槽中。当节点扩容或者缩容时,对数据槽进行重新分配迁移即可,数据不会丢失。