GPT-4o作为OpenAI推出的一款多模态大型语言模型,代表了这一交互技术的重要发展方向。以下是GPT-4o的一些关键特点和原理,它们揭示了下一代人机交互技术的可能面貌:
多模态交互:GPT-4o支持文本、图像、音频和视频等多种输入模态,能够理解和生成跨模态的内容。这意味着用户可以通过语音、文字、图片或视频与系统交互,而系统也能够以相应的形式提供反馈34。
实时处理:GPT-4o能够实时处理语音、视觉和文本信息,响应速度接近人类自然对话的速度4。这为即时交互提供了可能,使得人机对话更加流畅和自然。
端到端训练:GPT-4o实现了多模态端到端训练,所有的输入和输出都由同一个神经网络处理。这种设计减少了信息在不同处理阶段之间的丢失,提高了交互的准确性和效率4。
性能和效率:GPT-4o在性能上取得了显著提升,运行速度是前代模型的两倍,同时成本减半3。这使得它能够被更广泛地应用于各种场景,包括客户服务、教育、娱乐等领域。
情绪识别与响应:GPT-4o能够检测和响应用户的情绪状态,调整其语气和响应方式,使得交互更加自然和有同理心3。
安全性:GPT-4o在设计时考虑了安全性,虽然语音模态带来了新的安全挑战,但OpenAI表示已将风险控制在中等水平以下4。
可扩展性:GPT-4o的API定价比前代产品便宜,速度更快,调用频率上限更高,这使得开发者和企业能够更容易地将GPT-4o集成到他们的应用程序中4。
特殊任务的token:GPT-4o可能采用了特殊的token来标记不同的任务,以便模型能够生成对应的内容,这有助于提高模型在特定任务上的表现4。
通过这些特点和原理,我们可以看到下一代人机交互技术正朝着更加智能、直观和个性化的方向发展。GPT-4o作为这一趋势的代表,展示了未来人机交互的潜力和可能性。下一代人机交互技术的核心在于实现更自然、更直观的交互方式,让机器能够更好地理解和响应人类的指令和需求。

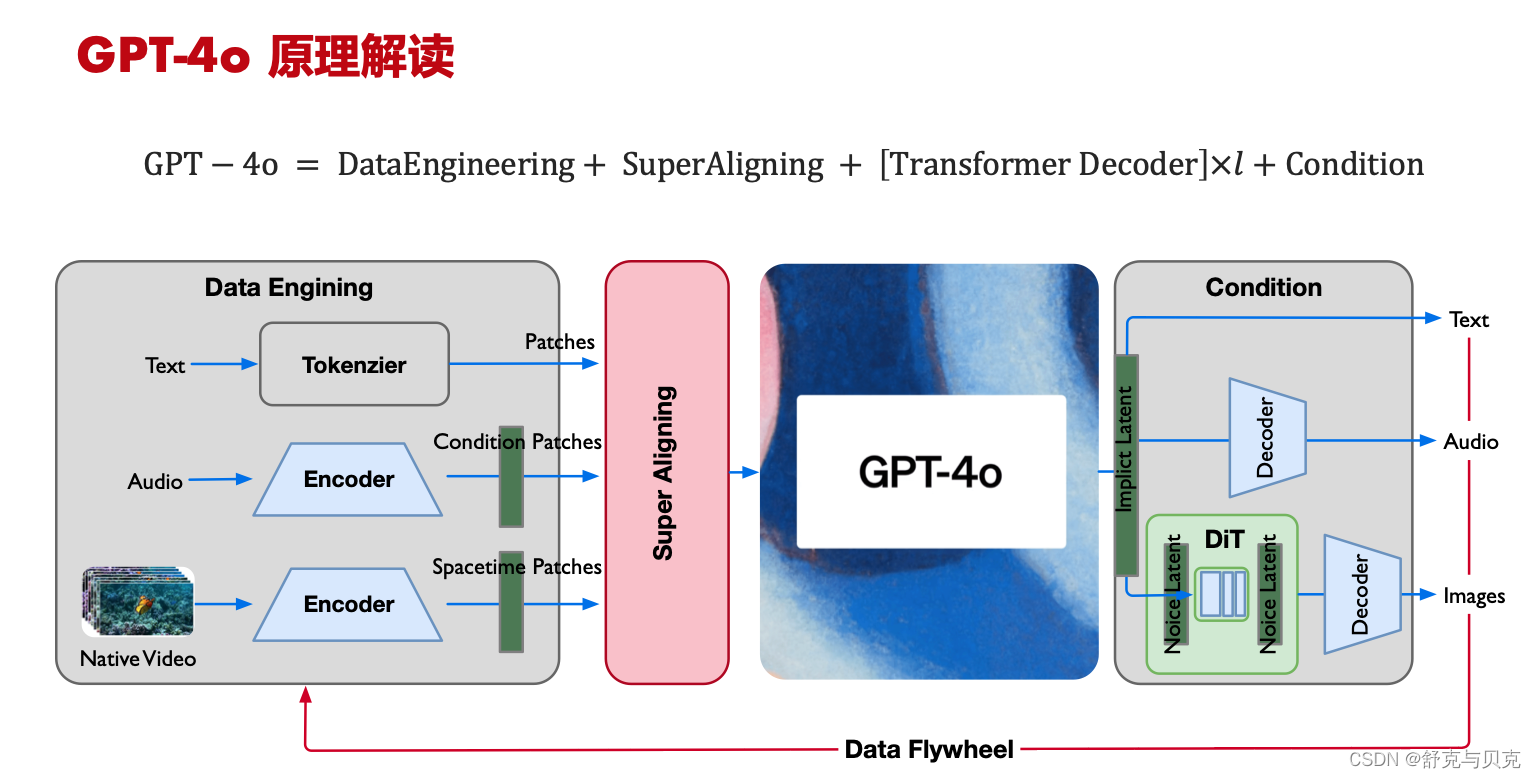
Data Engineering
- LLM 仍然是主战场,投入人力超1/2,新的 Tokenizer 新的 Vocab Size;
- Audio 参考 Whisper v3 与 Text 结合作为 Multitask training format 再编码;
- Video/Image 借鉴 Sora 的 Spacetime Patches 极致编码压缩;
Super Aligning
- 端到端 E2E 的 MLM 大模型,对齐不同模态的输入,统一作为 Transformer 结构的长序列输入;
- 让能力弱的大模型监督能力强的大模型(LLM supervise MLM);
- https://openai.com/index/introducing-superalignment/?utm_source=tldrai
Transformer Decoder
- 纯 Transformer Decoder 架构,更加方便训练进行千卡、万卡规模的并行;
- 推理使用大融合算子(Flash Attention)进行极致加速;
- 符合 OpenAI 一贯 Everything Scaling Law 的方式;
Outputs
- 输出可配置、可选择 text/audio/images,因此是 Conducting 的case,统一 Transformers Tokens 输入可实现;
- Images 依然借鉴 SORA 使用 DiT 作为生成,但此处生成的为 Images not Videos;
- Audio 与 Text 应该会有对齐,保持同声传译;
多模态数据工程:
1.LLM tokens 减少,让大模型的输入序列 Tokens 结合多模态统一为 Signal 长序列;
2.词表增大 Token 减少, 分词从 100K 到 200K,LLM 编码率进一步增强;
3.Video 借鉴 SORA 对 spacetime patch 对时序极高编码率;
模型训练:
1.弱监督/自监督为主,否则多模态对齐进行统一模式训练非常难;
模型结构与训练:
1.通过 Super Aligning 对 Text、Audio、Video 三种模态进行对齐;
2.仍然以 LLM(GPT4) 能力为主,加入多模态维度 Tokens 形成一个大模型;