爬虫网站:All products | Books to Scrape - Sandbox
豆瓣网:豆瓣电影 Top 250
我们需要安装一个第三方库来解析爬取到的html内容,终端输入pip install bs4,安装成功后引入需要的模块
我们先爬取所有的价格

import requests
from bs4 import BeautifulSoup
response1=requests.get("http://books.toscrape.com/").text
soup =BeautifulSoup(response1,"html.parser")#需要解析html
all_price=soup.findAll("p",attrs={"class":"price_color"})#找到要提取内容的标签共同属性
for price in all_price:
# print(price)
print(price.string[2:])#只需要字符串第三的一个开始的内容
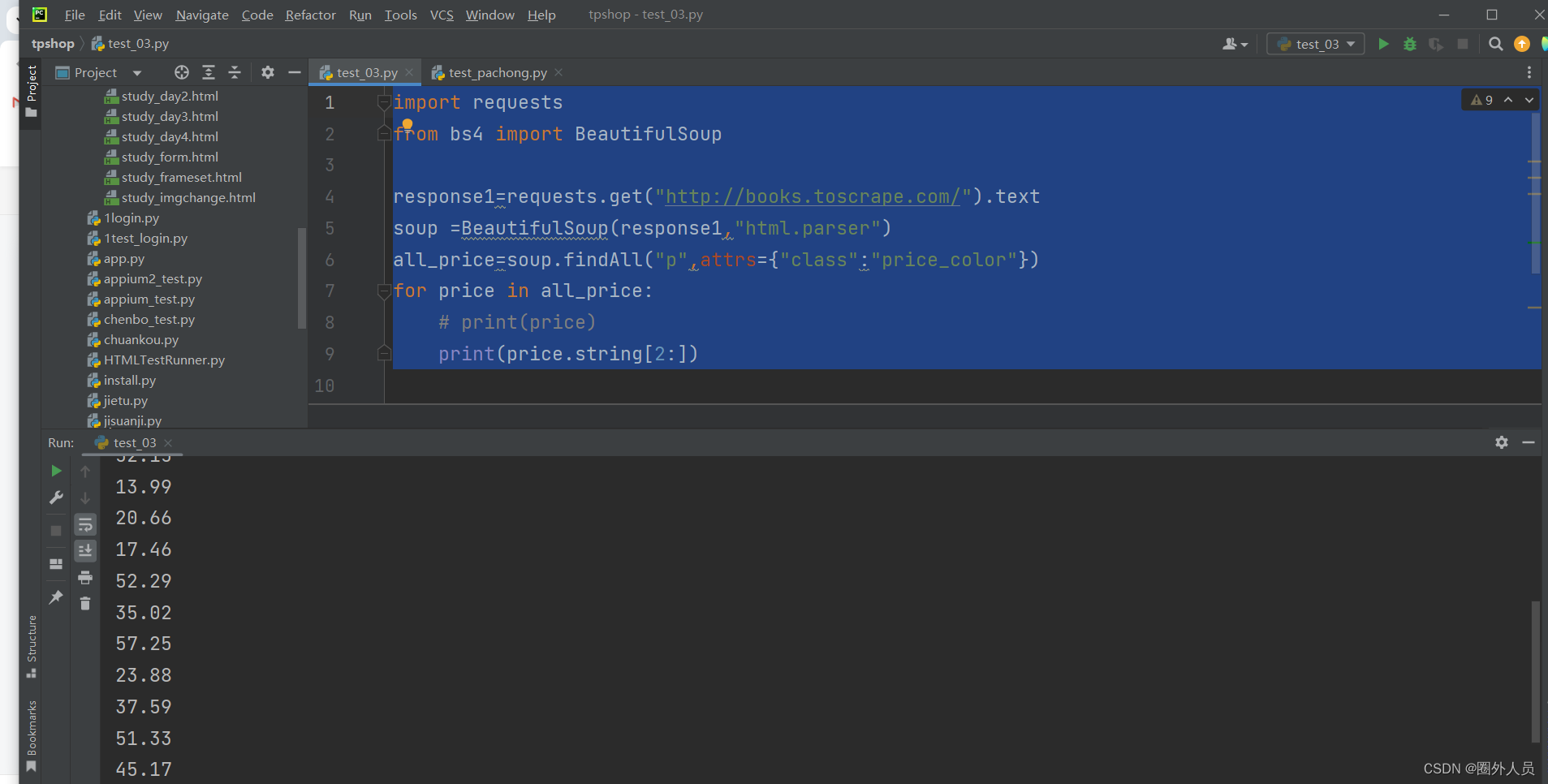 提取书名
提取书名

import requests
from bs4 import BeautifulSoup
response1=requests.get("http://books.toscrape.com/").text
soup =BeautifulSoup(response1,"html.parser")
all_name=soup.findAll("h3")
for name in all_name:
print(name.string)
下面是如果h3标签找不到的话,就需要先找到h3标签再找h3里面的a标签
import requests
from bs4 import BeautifulSoup
response1=requests.get("http://books.toscrape.com/").text
soup =BeautifulSoup(response1,"html.parser")
all_name=soup.findAll("h3")
for name in all_name:
name1=name.findAll("a")
for name2 in name1:
print(name2.string)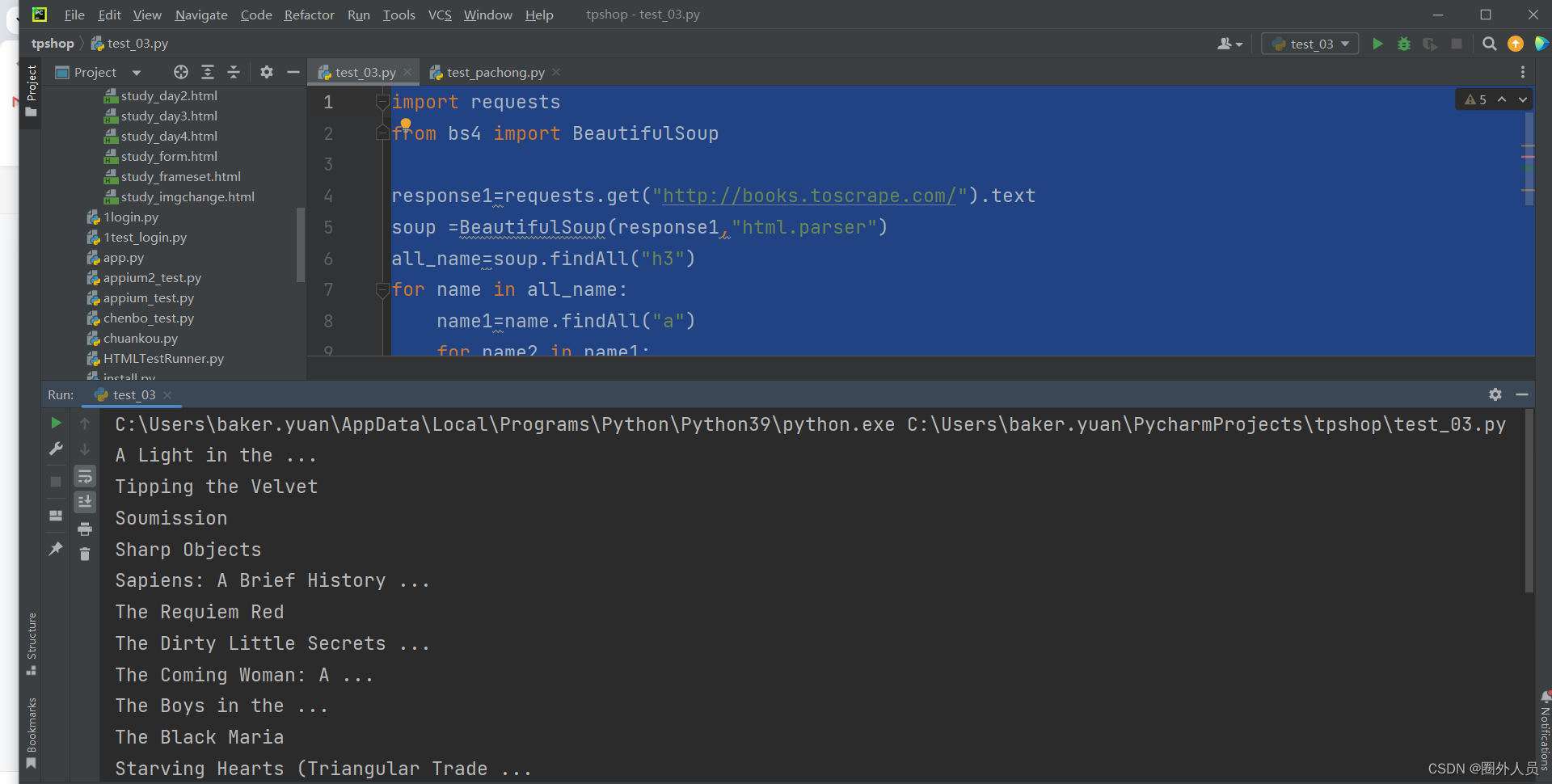
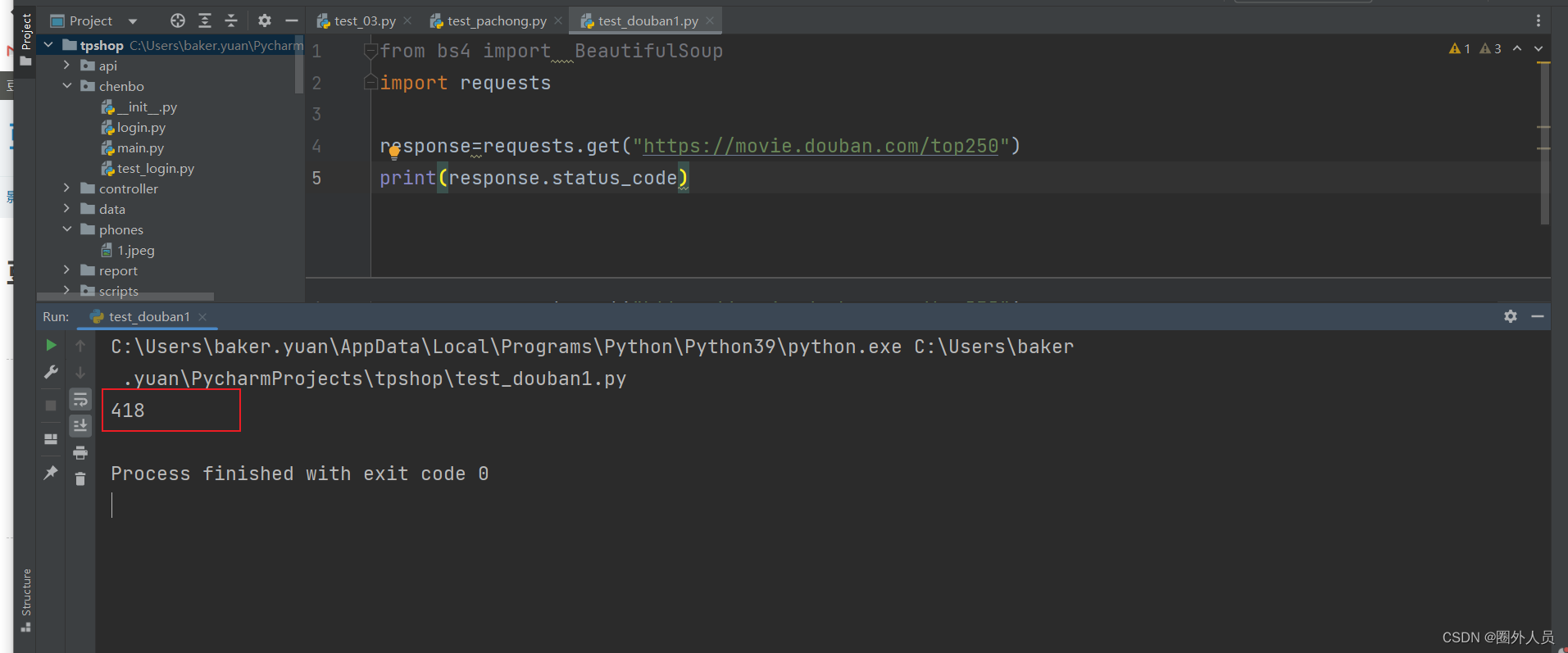
爬取豆瓣网上的所有电影名
请求豆瓣的网站,发现返回的状态码为418
HTTP状态码418是一个非标准的HTTP状态码,被定义为"I’m a teapot"(我是一个茶壶)。这个状态码源自1998年的一个愚人节笑话,被写入了RFC 2324,Hyper Text Coffee Pot Control Protocol(超文本咖啡壶控制协议)。
在实际的Web开发中,有些网站可能会使用这个状态码作为反爬虫策略的一部分。当服务器返回418状态码时,可能是因为服务器认为你的请求是一个爬虫,而不是一个正常的用户请求。
 我们需要模拟正式场景下需要传的header,定义一个确定的User-Agent
我们需要模拟正式场景下需要传的header,定义一个确定的User-Agent
那我们开始抓包
from bs4 import BeautifulSoup
import requests
headers={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36"
}
response=requests.get("https://movie.douban.com/top250",headers=headers).text
soup=BeautifulSoup(response,"html.parser")
all_title=soup.findAll("span",attrs={"class":"title"})
for title in all_title:
title=title.string #将提取到的内容的string部分,赋值给一个新的title,但是会出现的是中文名和别名都打印出来
if "/" not in title:#加个if条件,只打印出来中文名
print(title) 这样的话就,提取到当前页面的25个电影名,无法提取全部,但是我们可以观察url里面有个值是控制页码的
这样的话就,提取到当前页面的25个电影名,无法提取全部,但是我们可以观察url里面有个值是控制页码的

from bs4 import BeautifulSoup
import requests
headers={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36"
}
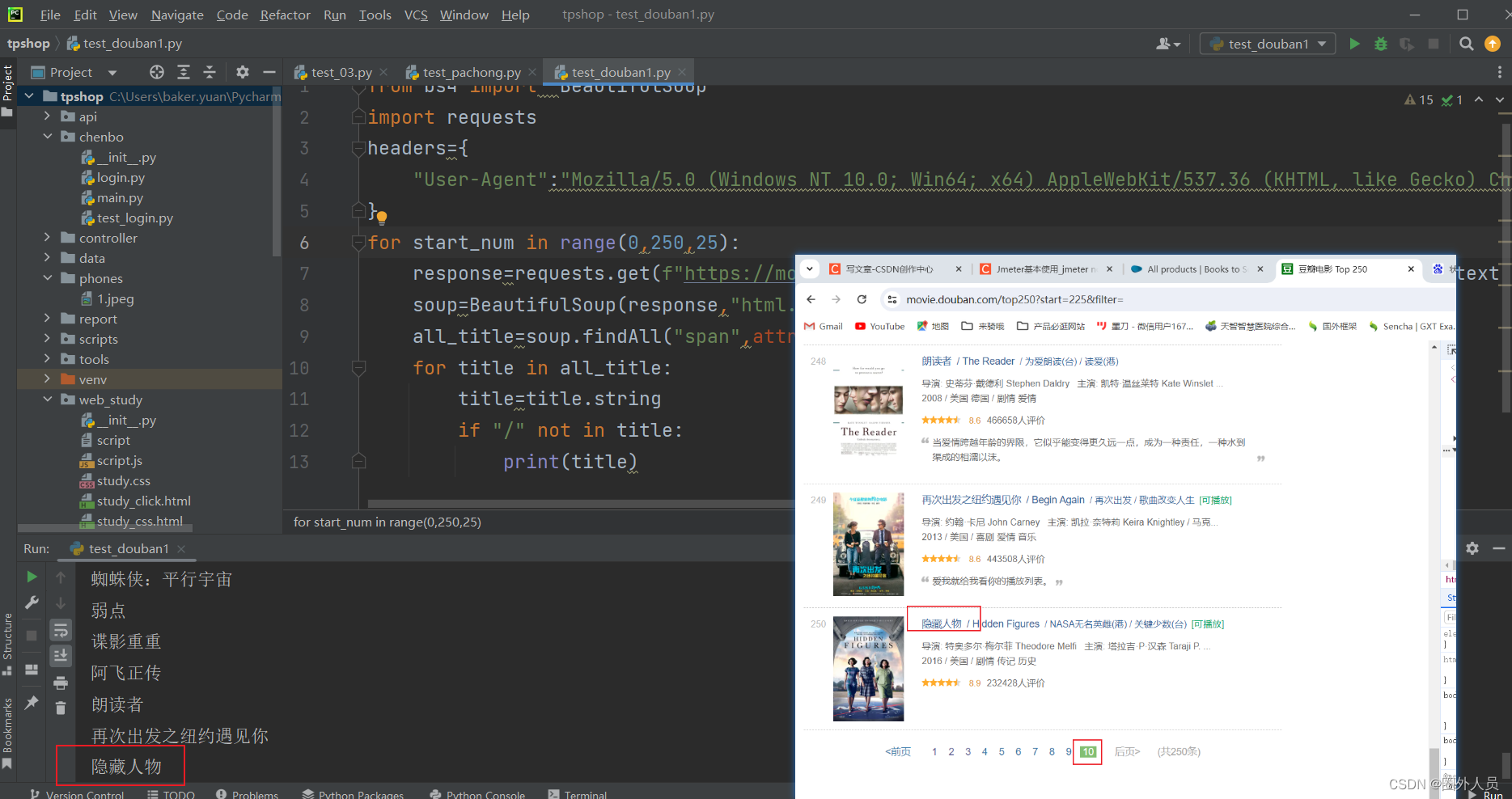
for start_num in range(0,250,25):
response=requests.get(f"https://movie.douban.com/top250?start={start_num}",headers=headers).text
soup=BeautifulSoup(response,"html.parser")
all_title=soup.findAll("span",attrs={"class":"title"})
for title in all_title:
title=title.string
if "/" not in title:
print(title)