Linux文本处理常用的3个命令,脚本或者文本处理任务中会用到。这里做个整理。
三者的功能都是处理文本,但侧重点各不相同,grep更适合单纯的查找或匹配文本,sed更适合编辑匹配到的文本,awk更适合格式化文本,对文本进行较复杂格式处理。
1、grep
grep的全称是Global Regular Expression Print,全局正则表达式打印。用于文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来(就是只要一行里有对应的字符被匹配到,这一行都会被打印出来)。
grep加上正则匹配会有很多功能,但我目前只常用一些简单的:
- xxx | grep AA 在命令的输出后提取AA关键词并显示。可以过滤其他不关心的输出
- grep -r “xxx” . 在当前目录及其中所有文件中查找包含xxx的文件和语句。我在找不到某句话出自哪个文件时会用
2、sed
linux下输入sed会显示他的用法:
-n:静默模式,仅打印由 p 命令指定的行。
-e script:直接在命令行模式中添加 sed 脚本。
-f script-file:从文件中读取 sed 脚本。
-i:直接编辑文件。
注意只有-i才会直接修改文件,其余的都是打印到终端,或者可以输出到另一个文本中。
常见命令
- 匹配行,打印 ( p ):打印指定行或匹配的行。
注意想只输出其中的几行只用’20,40p’不行,必须加上-n,否则会打印所有行 - 增加(a)/插入(i),删除 (d),替换(s)
替换匹配行的关键字(s/regexp/replacement/flags):
s 代表替换命令
regexp 是一个正则表达式,用于匹配要替换的文本。
replacement 是用来替换匹配文本的新文本。
flags 是可选的标志,用于修改替换行为。 g表示全局替换,不加的话只替换匹配到的第一行
sed -n '20,40p' input.txt 只打印txt中的20到40行
sed '5,10d' input.txt 删除5-10行
sed -n '/aaaa/'p test.txt 显示包含关键字的所有行
sed 's/foo/bar/g' input.txt 将所有 foo 替换为 bar
sed -i '4s/a/A/g' test.txt -i 直接修改文件内容 ,替换修改会保存到源文件中。
4s指的是进行第四行替换, g代指的全局替换 将a替换成A。并保存文件。
3、awk
sed对行进行操作,awk适合对列进行操作。awk就是把文件逐行的读入,以空格为默认分隔符(分隔符也可以自己选定,可以用多个分隔符,用 -F指定)将每行切片,切开的部分再进行各种分析处理。
设置pattern:
awk '/^This/' test 打印开头是This的行
设置options: {}中写要做什么操作
awk '{print $1,$4}' test 最常用的命令,打印以空格分隔的第一列和第三列。$0是打印整行
awk -F',' '{print $1, $2}' file 以逗号为分隔
awk -F '[ ,]' '{print $1,$2,$5}' test []中的是正则表达式,表示以空格和逗号做分隔
awk '{sum += $1} END {print sum}' file 求列的总和
(1)内建变量
其中awk还有很多内建变量:
| 变量 | 描述 |
|---|---|
| $n | 当前记录的第n个字段,字段间由FS分隔 |
| $0 | 完整的输入记录 |
| ARGC | 命令行参数的数目 |
| ARGIND | 命令行中当前文件的位置(从0开始算) |
| ARGV | 包含命令行参数的数组 |
| CONVFMT | 数字转换格式(默认值为%.6g)ENVIRON环境变量关联数组 |
| ERRNO | 最后一个系统错误的描述 |
| FIELDWIDTHS | 字段宽度列表(用空格键分隔) |
| FILENAME | 当前文件名 |
| FNR | 各文件分别计数的行号 |
| FS | 字段分隔符(默认是任何空格) |
| IGNORECASE | 如果为真,则进行忽略大小写的匹配 |
| NF | 一条记录的字段的数目 |
| NR | 已经读出的记录数,就是行号,从1开始 |
| OFMT | 数字的输出格式(默认值是%.6g) |
| OFS | 输出字段分隔符,默认值与输入字段分隔符一致。 |
| ORS | 输出记录分隔符(默认值是一个换行符) |
| RLENGTH | 由match函数所匹配的字符串的长度 |
| RS | 记录分隔符(默认是一个换行符) |
| RSTART | 由match函数所匹配的字符串的第一个位置 |
| SUBSEP | 数组下标分隔符(默认值是/034) |
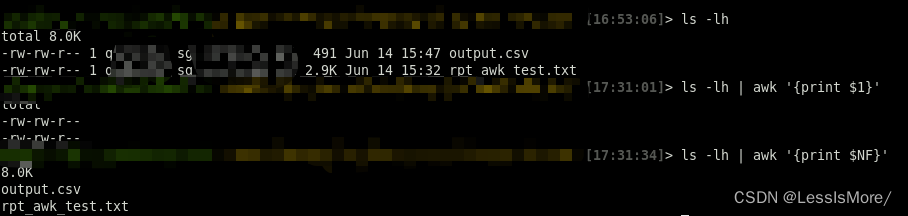
awk '{print $NF}' test 取每行的最后一个匹配到的字符($NF代表的是分割后的字段数量)
awk也可以配合管道符一起,平头哥笔试中有考过awk的使用,提取最后一列
(2)内建函数
可以参考AWK 内置函数|菜鸟教程
这里只说一个split( String, array, fieldsep)
参数分别是:要拆分的字符串;拆分后保存结果的数组;用于拆分的分隔符,可以是正则表达式
sed -n '10,1000p' timing.rpt | awk '{split($1,a,"/");print a[1],$5}' > output.csv
时序分析总结报告的每一行都是 AA/BB/CC 1.2 4.6 0.0 -0.13 xxxx之类的形式,我希望提取AA来确定是哪个大模块,-0.13表示对应的slack,就可以用上面的表达式
$1是以空格分隔的第一列字符串,要将他继续用/进行拆分,并且把结果存到数组a中;之后打印数组a的第一个元素和原本空格为分解的第5列.
这样就可以实现先用一个元素分界,之后再细分其中的结果。 其实直接用awk -F ‘[ /]'也可以分开,但是这个例子就适用于先用空格分,之后再对分出来的列做处理,因为一开始就用/分的话,因为路径长度不一致,后面slack的个数就不确定了,不过应该也可以倒着往回数
结果为:
AA1 -0.13
AA2 -0.12
…
4、正则表达式
正则表达式(Regular Expressions,简称 regex 或 regexp)引擎是一个用于匹配字符串的模式匹配工具。它是一种强大的工具,用于在文本中搜索、匹配和操作复杂的字符串模式。
1、正则表达式引擎
正则表达式引擎是一个程序或库,能够解析和执行正则表达式语法。它接受一个正则表达式和一个输入字符串,然后根据正则表达式的模式在字符串中查找匹配项。正则表达式引擎通常内置于编程语言或文本编辑器中,如 Perl、Python、JavaScript、Java、.NET、Vim、grep 等。
2、正则表达式的基本组成部分
正则表达式由元字符和普通字符组成。元字符具有特殊意义,可以表示位置、数量、分组等操作。以下是一些常见的元字符及其含义:
(1)格式
. 匹配任意单个字符,不能匹配空行
[] 匹配指定范围内的任意单个字符
[^] 取反
[:alnum:] 或 [0-9a-zA-Z]
[:alpha:] 或 [a-zA-Z]
[:upper:] 或 [A-Z]
[:lower:] 或 [a-z]
[:blank:] 空白字符(空格和制表符)
[:space:] 水平和垂直的空白字符(比[:blank:]包含的范围广)
[:cntrl:] 不可打印的控制字符(退格、删除、警铃…)
[:digit:] 十进制数字 或[0-9]
[:xdigit:]十六进制数字
[:graph:] 可打印的非空白字符
[:print:] 可打印字符
[:punct:] 标点符号
(1)字符类:
[abc]:匹配 a、b 或 c 中的任意一个字符。
[^abc]:匹配除 a、b 或 c 之外的任意一个字符。
[a-z]:匹配从 a 到 z 的任意一个小写字母。
预定义字符类:
.:匹配除换行符外的任意字符。
\d:匹配任何数字,相当于 [0-9]。
\w:匹配任何字母、数字或下划线,相当于 [a-zA-Z0-9_]。
\s:匹配任何空白字符,包括空格、制表符等。
(2)量词:
*:匹配前面的元素零次或多次。
+:匹配前面的元素一次或多次。
?:匹配前面的元素零次或一次。
{n}:匹配前面的元素恰好 n 次。
{n,}:匹配前面的元素至少 n 次。
{n,m}:匹配前面的元素至少 n 次,至多 m 次。
(3)锚点:
^:匹配字符串的开始。
$:匹配字符串的结束。
(4)分组和捕获:
(…):将模式分组并捕获匹配的文本。
(?:…):将模式分组但不捕获匹配的文本。
(5)转义字符:
\:用于转义元字符,使其失去特殊意义。
参考:
Linux 文本处理三剑客:grep、sed 和 awk(有例子,易懂)
Linux文本三剑客超详细教程—grep、sed、awk(写的很详细)