1.1 请求和响应的格式
http协议和前边学过的传输层、网络层协议不同,它是“一问一答”形式的,所以要分为请求和响应两部分看待,同时,请求和响应的格式是不同的,我们来具体介绍一下。
1.1.1 请求
在介绍请求之前,先来看一个具体的http使用案例:
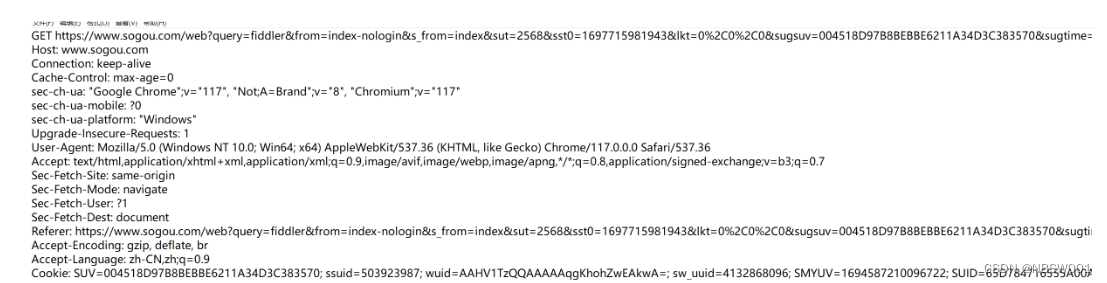
首先我们能看到的是,http的内容是能够直接看懂的,说明http是文本形式的,不同于TCP、IP协议的二进制形式,http的响应也是文本形式的,但是我们查看时会发现是二进制形式,这是因为响应在网络传输过程中会被压缩为二进制形式,用来提高传输效率,节省网络带宽。
请求分为以下几个部分:
1、首行
![]()
这是http的第一行 分为三个部分,用空格分隔
1)GET:http请求的方法(method),还有其它很多方法,之后介绍
2)URL:唯一资源定位符,描述了一个资源在网络中的位置
3)版本号:![]()
2、请求头
请求头是很多键值对结构的数据,每个键值对都是独占一行的,要注意的是,这里的键值对都是属于“标准规定的”,即key和value都有固定的东西,不可以程序员自己随便定义
3、空行
请求头的结束标记
4、正文(请求体)
有的http请求有,有的没有,后边详细介绍
1.1.2 响应

响应也是由四部分构成的:
1、首行
1)版本号:HTTP/1.1
2) 状态码:200
3)状态码描述:OK
2、响应头
响应头的格式和请求头是一样的,也是键值对形式的,但是具体的键和值不同,后边会详细介绍
3、空行
响应头的结束标记
4、正文(响应体)
正文里的内容可能会很长,有很多中形式,HTML、CSS、JS、JSON、图片、视频.....
1.2 请求(详细版)
1.2.1 首行
请求方法:

请求方法有上图中那么多种,在这里我们只介绍最常用的GET和POST方法。
GET:通常会把要传给服务器的数据放在URL的查询字符串中(query string)
POST:通常会把要传给服务器的数据放在请求体中
这是GET和POST最本质的区别,接下来介绍的一些特点均是基于这个区别的:
注意:GET请求和POST请求的区别是面试中的常考题,但是由于技术的发展,这些区别已经属于“历史遗留”问题了,现在二者已经可以相互替换,差别不大了,所以了解即可:
1、GET请求能传递的数据量有上限,POST请求能传递的数据量没有上限
这种说法产生的原因是因为GET请求携带数据是放在query string中的,而POST请求携带数据是放在请求体中的,有一定的道理,但是随着技术的进步,现在的URL甚至可以携带图片资源,所以这种说法应该会逐渐消失
2、GET请求传递数据不安全,POST请求传递数据安全
举个例子,在我们登录账号时,如果使用GET请求,账号和密码都会直接携带在URL中,可以直接被看到,而POST的账号和密码是隐藏在请求体中的,不会被看到,所以有更安全这个说法,但是!!!这个说法是不正确的,上述的例子骗一个不懂计算机的小白或许还可以的,但是对于一个黑客,无论你的数据放在哪里,他都能拿到,所以,想要数据安全,要采取别的方法,比如加密措施....
3、GET只能给服务器传文本数据,POST可以给服务器传文本和二进制数据
这种说法也是不正确的:
1)GET请求也可以把数据放在请求体中(只是通常不这样做)
2)GET也可以把二进制数据进行base64转码,放在URL的query string中
4、GET请求是幂等的,POST请求是不幂等的
幂等:输入相同的数据,输出是稳定的
比如奶牛产奶,吃草之后,奶牛一定产的是牛奶,而不是别的东西,这就是幂等的。
但是这种说法也不完全正确,当我们使用GET请求访问一些广告页面时,输入的请求相同,但是输入的广告常常是不相同的,所以这种说法也不完全正常
5、GET请求可以被浏览器缓存,POST不可以被缓存
这个说法其实是基于第4个说法的,如果每次输出稳定,当然可以将数据缓存在浏览器中,反正每次请求的输出都一样,那直接在缓存中拿来使用不就好了
6、GET请求可以被浏览器收藏夹收藏,POST不可以被收藏
这种说法的主要原因是认为收藏的时候可能会丢失请求的body
URL:

这是请求首行中URL的具体划分:
- 协议方案名:指出用到的协议是什么
- 登录信息(认证):现在大多数请求已经没有了
- 服务器地址:服务器在网络中的位置,也就是IP 地址,此处用域名表示
- 服务器端口号:指明了具体要访问服务器中的哪个程序
- 带层次的文件路径:指明了具体要访问程序中的哪个资源
- 查询字符串:是一种键值对结构的数据,以?开头,这里的键值对都是程序猿自定义的,相当于对这次请求的一些补充说明
- 片段标识符:有的网页内容比较长,就需要划分为多个“片段”,通过片段标识符,能够实现页面内部的跳转(技术文档中十分常见)
对于URL,给大家举个具体的例子:
http://小淘气食堂:80/包子/猪肉大葱包子?葱=少放&辣椒=微辣
对于上述这个例子,小淘气食堂就是域名,也就是要访问的网络资源的地址,80是这个食堂中具体的窗口,也就是我们要访问的具体的程序,包子/猪肉大葱包子是在这个窗口中具体想要访问的资源,?葱=少放&辣椒=微辣就是我们说的查询字符串,是对于这次请求的一个补充说明。
1.2.2 请求头
请求头里的键值对很多,这里介绍几个比较重要的:
1、HOST:这是请求的域名,在URL中也有,即服务器的网络地址
2、Content-Length:body中数据的长度
3、Content-type:body中数据的类型
请求中有body才会有以上两种请求头键值对,GET请求通常没有body,所以通常没有,POST请求有body,所以请求头中会包含以上两种键值对
Content-type是有很多类型的,例如:
- json
- form表单的格式
- form-data的格式
后续给服务器提交请求时,不同的Content-type,服务器处理数据的逻辑是不同的,服务器返回数据给浏览器,也需要设置合适的Content-type,浏览器也会根据不同的Content-type做出不同的处理。
4、User-Agent

5、Referer:Referer描述了当前页面是从哪个页面跳转过来的

6、Cookie:Cookie可以认为是浏览器在本地存储数据的一种机制(即直接把数据保存在浏览器中)
浏览器的数据都来自服务器,之后的操作也会将数据提交给服务器,但是在程序运行过程中,也有一些数据需要存储在浏览器本地(例如上次登陆时间、用户的身份信息...),这些数据是需要在下次传给服务器数据时一并发送过去的,这些临时性的数据,就存储在浏览器比较合适。以下是一些Cookie在日常应用中的例子: