研究背景
大规模语言模型(LLMs)在许多自然语言处理(NLP)任务中取得了显著进展,特别是在零样本/少样本学习(In-Context Learning, ICL)方面。ICL不需要更新模型参数,只需利用几个标注示例就可以生成预测。然而,现有的ICL和链式思维(Chain-of-Thought, CoT)方法在复杂推理任务上仍存在生成的推理链常常伴随错误的问题,导致不真实和不可靠的推理结果。
研究目标
本研究提出了一种新的链式知识(Chain-of-Knowledge, CoK)提示方法,通过引导LLMs生成明确的知识证据来提高推理能力。具体来说,CoK提示由证据三元组(CoK-ET)和解释提示(CoK-EH)组成,旨在生成明确的知识证据和解释,以支持逐步思考过程。同时,引入了F2验证方法来评估推理链的真实性和可靠性。
相关工作
在上下文学习(ICL)方面,已有研究探索了多种影响ICL效果的因素,如输入输出映射和模板格式。链式思维(CoT)提示方法被提出用于增强推理,通过生成中间推理步骤来指导LLMs生成可靠的响应。为了进一步提高推理能力,研究人员提出了多种基于CoT的方法,包括自一致性、思维程序和验证方法等。
方法论
数据处理
在示例构建过程中,首先随机选择多个带标签的示例,并使用零样本CoT方法生成文本推理链。然后,从预构建的知识库中检索相关的知识三元组,并邀请专家对其进行人工注释,以形成结构化的证据三元组。
解决方案
提出的CoK提示方法包括两部分:证据三元组(CoK-ET)和解释提示(CoK-EH)。CoK-ET表示多个三元组的列表,每个三元组代表从LLM中提取的知识证据,支持逐步思考过程。CoK-EH表示推理链的解释,与传统的CoT相似。此外,设计了F2验证策略,用于评估推理链的真实性和可靠性,并通过重新思考过程来修正错误的证据。
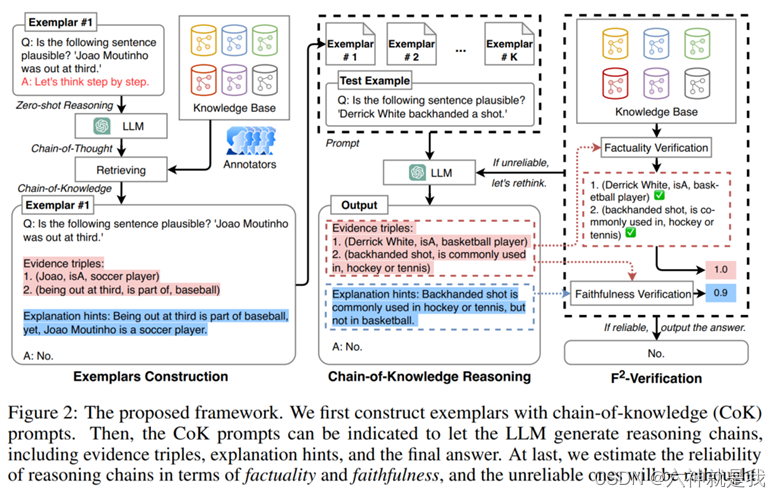
举个例子:
用户输入:下面这句话有道理吗?“德里克·怀特反手击球“。
Cok思考链路:
先生成证据三元组:
证据1:(德里克·怀特,职业,篮球运动员)
证据2: (反手击球,常用于,曲棍球或网球)
再生成解释提示:
反手击球通常用于曲棍球或网球,而不是篮球。
根据证据三元组和解释提示,生成初步答案:
A: “No.”
F2验证:
事实性验证(Factuality Verification):
验证生成的证据三元组是否与真实知识库(KB)中的知识匹配。
例如,验证(德里克·怀特,职业,篮球运动员)、(反手击球,常用于,曲棍球或网球)是否在知识库中存在。
忠实性验证(Faithfulness Verification):验证推理过程和最终答案的解释是否一致。
使用预构建的句子编码器(例如SimCSE)计算解释提示和推理过程的相似性分数。
重新思考:
如果初步答案的可靠性分数低于阈值(θ),则通过重新生成和修正错误的证据三元组来提高答案的可靠性。
例如,错误的证据三元组会被标记并替换为正确的知识三元组,再次生成新的解释提示和答案。
最终,模型输出经过F2验证和重新思考过程后,生成的最终答案为:
A: “No.”
实验
实验设计
实验选择了五种不同类型的任务来评估方法的性能,包括常识与事实推理、算术推理和符号推理。具体任务包括CommonsenseQA(CSQA)、StrategyQA、OpenBookQA、AI2推理挑战(ARC-c)、体育理解和BoolQ等。
对比模型包括zero-shot、few-shot、Chain of thought、Zero-shot-CoT、Mannual-shot-Cot、Auto-CoT等多个。
实验结论
实验结果表明,CoK提示方法在多个任务上显著优于标准的ICL和CoT提示方法,特别是在常识和事实推理、符号推理和算术推理任务上。通过F2验证和重新思考过程,进一步提高了推理链的可靠性和准确性。这表明,明确的证据三元组和解释提示能够显著提升LLMs的推理能力。