《 软件测试基础持续更新中》
最近大家总是催更……,我也是百忙之中给大家详细总结了白盒测试的重点内容!
知识点+题型+答案,让你用最短的时间,学到最高效的知识!
整理不易,求个三连 ₍ᐢ..ᐢ₎ ♡
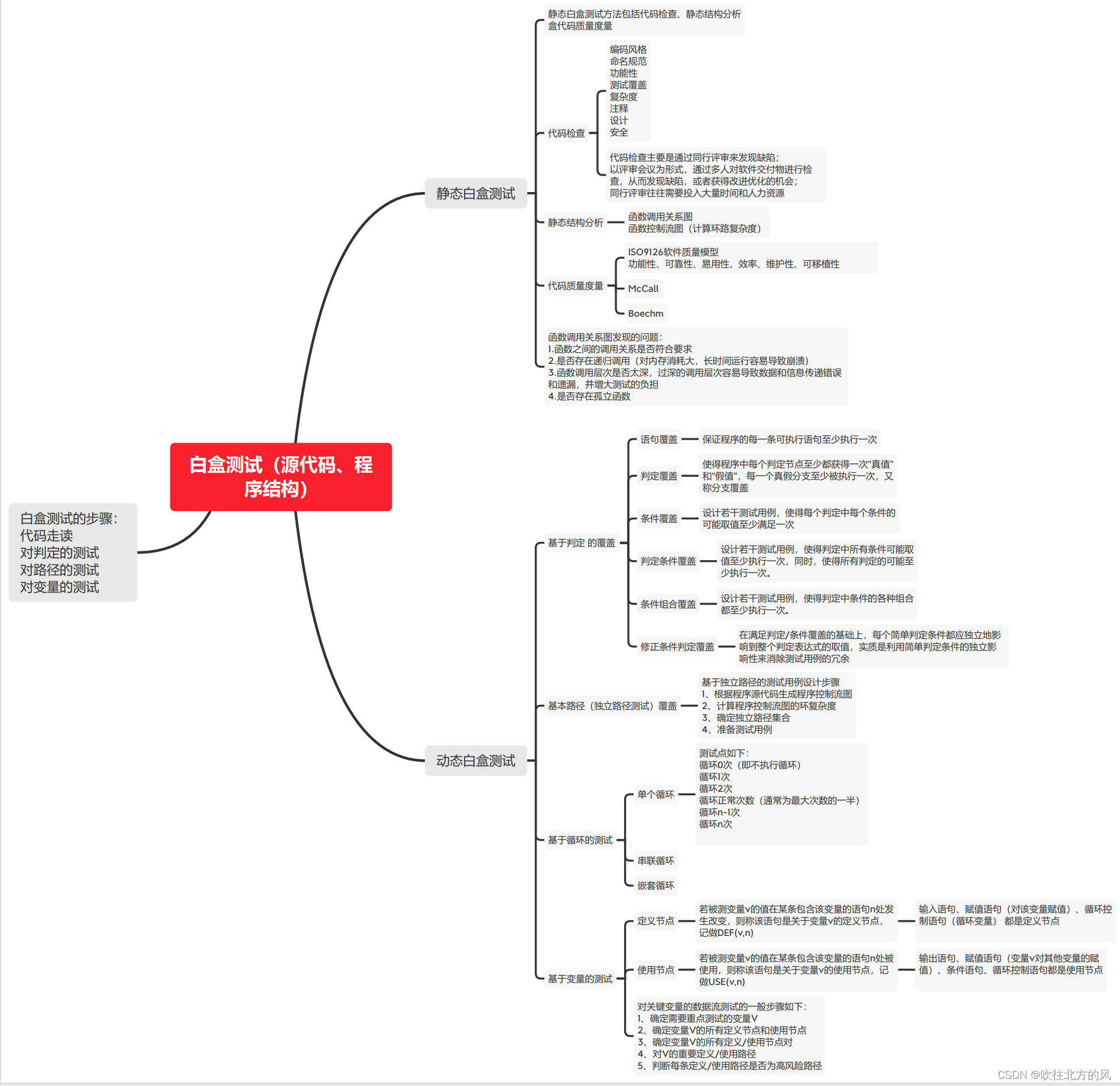
目录
白盒测试关注的对象:
- 源代码:阅读源代码,检查代码规范性,并对照函数功能查找代码的逻辑缺陷、内存管理缺陷、数据定义和使用缺陷等
- 程序结构:使用与程序设计相关的图表,找到程序设计的缺陷,或评价程序的执行效率
白盒测试与黑盒测试比较:
- 黑盒测试:功能级别
- 白盒测试:函数级别
一、静态白盒测试
对系统静态检查,这种检查通常不需要运行被测软件,而是直接对软件形式和结构进行分析。 静态白盒测试的内容主要包括三种:
- 代码检查
- 静态结构分析
- 代码质量度量
【1】 代码检查:
代码检查主要是通过同行评审来发现缺陷; 以评审会议为形式,通过多人对软件交付物进行检 查,从而发现缺陷,或者获得改进优化的机会; 同行评审往往需要投入大量时间和人力资源。
注重:编码风格 、命名规范、 功能性、 测试覆盖 、复杂度 、注释 、设计 、安全。
【2】静态结构分析:
1、函数调用关系图 :
- 函数之间的调用关系是否符合要求
- 是否存在递归调用(对内存消耗大,长时间运行容易导致崩溃)
- 函数调用层次是否太深,过深的调用层次容易导致数据和信息传递错误和遗漏,并增大测试的负担
- 是否存在孤立函数
2、函数控制流图(计算环路复杂度):
程序控制流图:程序控制流图简称流图,本质上是一种“退化”了的程序流程图,用于突出表示程序的控制结构。流图只呈现程序的控制流程,完全不表现具体的语句以及选择或循环的具体条件。
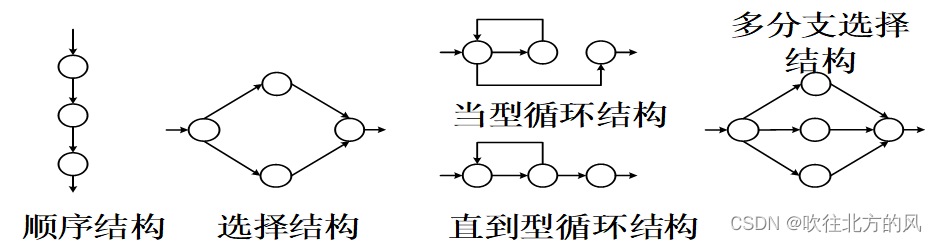
控制流图是一种有向图,由结点和边构成,其含义分别为:
结点:用圆表示。一个结点代表一条或多条顺序执行的语句。程序流程图中的一个顺序的处理框序列和一个菱形判定框,可以映射成流图中的一个结点。
边:用箭头线表示。边代表控制流,一条边必须终止于一个结点,即使这个结点并不代表任何语句。
程序流程图与控制流图的对比:
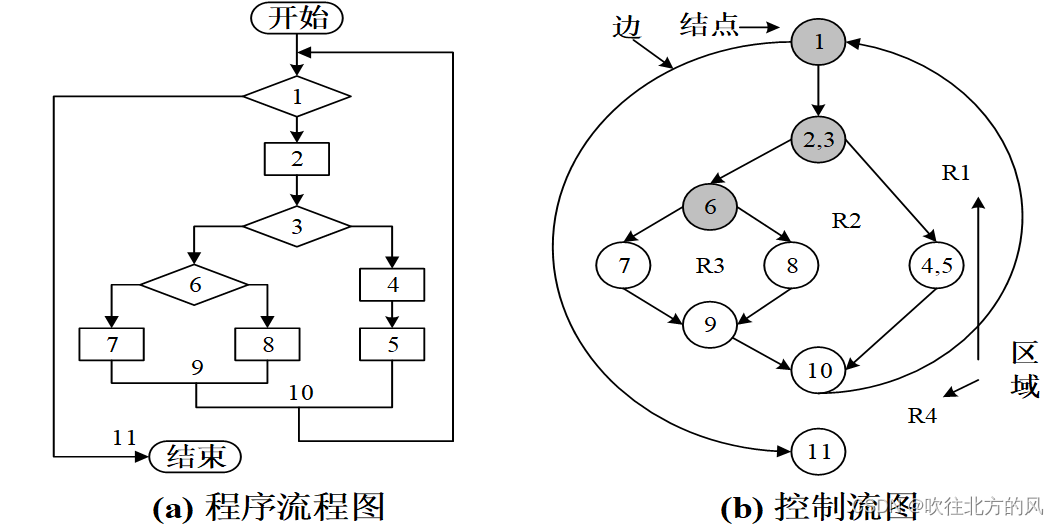
对函数控制流图进行分析时,可以得出:
- 是否存在多出口情况,多出口容易导致空指针,内存未释放这类缺陷
- 是否存在孤立语句
- 环复杂度是否太大(不应该超过10)
- 是否存在非结构化设计
其中计算环复杂度V(G)是考试的重中之重!!!
通常计算环复杂度三种方式(直观观察法、公式计算法、判定节点法),这里我只介绍判定结点法:
- 利用代码中判定节点的数目来计算环复杂度
- V(G)=P + 1(p代表独立判定节点的数目)
- 独立判定结点就是:该结点有且只有两条“出边”。
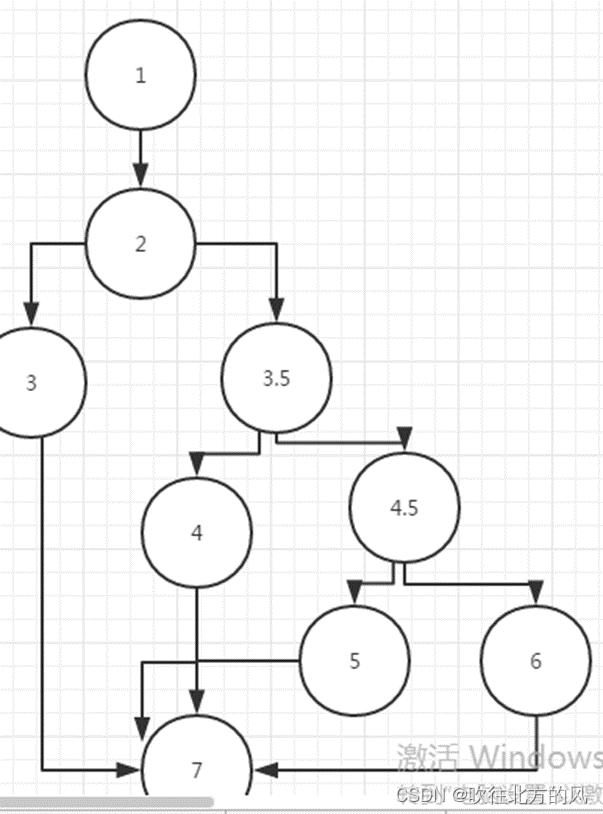
【例题】针对coverage2(),要求:画出控制流图、计算V(G)。
public void coverage2(int tag, int i, int j) {
int x = 0;
int y = 0;
while (tag > 0) {
x = x + 1;
if (i > 0 && j > 0) {
y = y + 1;
tag = 0;
} else {
if (i > -5 || j > -5)
y = y - 1;
else
x = x - 2;
tag--;
}
}
System.out.println("x=" + x + ";y=" + y);
}答案:

V(G)= 5 + 1 = 6
遇到switch语句怎么做?此时结点的出边数可能大于2,如下图:
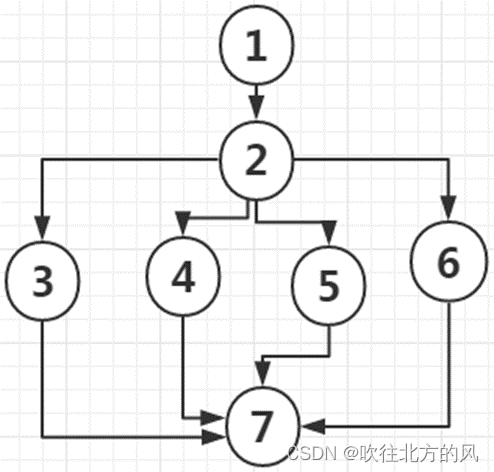
你可以想象3和4、5、6间可以细分,4和5、6间可以细分……,就等价于下图,那么就可以轻松看出独立判定结点了!
【3】代码质量度量:
- ISO9126软件质量模型 功能性、可靠性、易用性、效率、维护性、可移植性
- McCall
- Boechm
质量度量元定义和计算:
- 通过对每个度量元规定上、下限,并将其转化为数字,当被测代码关于该度量元的实际取值落在规定的上下限范围内时,就认为被测代码关于该项度量元是合格的,并赋值为“1”,否则赋值为“0”
- 例如V(G),上下限分别为10和1,若某段代码V(G)=11,则被测代码关于环复杂度不合格
- 通常质量度量元由各单位自行规定
二、动态白盒测试
定义:主要是按一定步骤和方法生成测试用例,并驱动相关模块去执行程序并发现软件中的错误和缺陷。
【1】基于判定的覆盖
(1)语句覆盖:
语句覆盖的基本思想:保证程序的每一条可执行语句至少执行一次。
例如 :
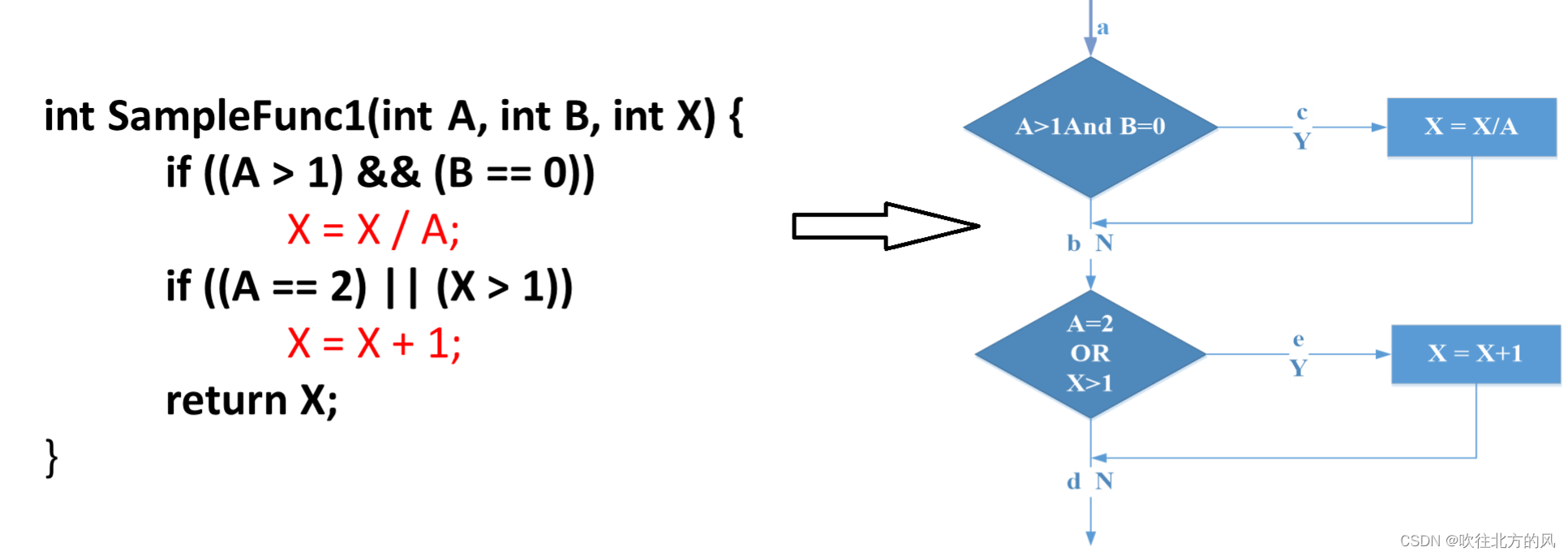 使程序中每个语句至少执行一次,那么设计一个能通过路径ace的例子就可以了。
使程序中每个语句至少执行一次,那么设计一个能通过路径ace的例子就可以了。
测试用例输入数据: A=2,B=0,X=3
(2)判定覆盖
判定覆盖:使得程序中每个判定节点至少都获得一次“真值”和“假值”,每一个真假分支至少被执行一次,又称分支覆盖。是一个比“语句覆盖”稍强的测试标准。
用例设计:
- 路径acd:输入用例数据,A= 3 B=0 X=1
- 路径abe:输入用例数据,A= 2 B=1 X=3
当然还可以是:
- 路径abd
- 路径ace
从上面不难看出:只要满足了判定覆盖就一定满足语句覆盖,反之则不然。
(3)条件覆盖
条件覆盖:设计若干测试用例,使得每个判定中每个条件的可能取值至少满足一次。
从上图看出,条件项分别为:
- 1:A > 1
- 2:B = 0
- 3:A = 2
- 4:X > 1
当取用例数据为:
- A = 2 ,B = 0 , X = 1 ,那么条件项的结果分别为:T T T F(分别对应1~4)
- A = 1 ,B = 1 , X = 2 ,那么条件项的结果分别为:F F F T(分别对应1~4)
从条件覆盖的测试用例可知,使用2个测试用例就达到了使每个逻辑条件取真值与取假值都至少出现了一次,但从测试用例的执行路径来看,条件分支覆盖的状态下仍旧不能满足判定覆盖,即没有覆盖 d 这条路径(该判定结点对应的假分支)。相比于语句覆盖与判定覆盖,条件覆盖达到了逻辑条件的最大覆盖率,但却不能保证判定覆盖。
(4)条件判定覆盖
条件判定覆盖:设计若干测试用例,使得判定中所有条件可能取值至少执行一次,同时,使得所有判定的可能至少执行一次。
例如,对于判定语句 if(a>1 AND c<1) ,该判定语句有 a>1、c<1 两个条件,则在设计测试用例时,要保证 a>1、c<1 两个条件取“真”、“假”值至少一次,同时,判定语句 if(a>1 AND c<1) 取“真”、“假”也至少出现一次。
为满足判定-条件覆盖原则,我们可以构造以下测试用例:
①输入: A = 2 , B = 0 , X = 2
- 判定结点分别为:T T
- 4个条件分别为:T T T T
②输入:A = 1 , B = 2 , X = 1
- 判定结点分别为:F F
- 4个条件分别为:F F F F
判定-条件覆盖的缺点: 没有考虑条件的组合情况。
注意: 条件覆盖和条件判定覆盖从表面来看,测试了所有条件的取值,但是实际上某些条件掩盖了另一些条件。
- 例如:对于表达式(A>1)&&(B=0),必须2个条件都满足才能确定表达式为真,如果(A>1)为假,则一般的编译器不再判断是否(B=0)了
- 对于表达式(A=2) || (X>1),若A=2的测试结果为真,就认为表达式的结果为真,不会再检查(X>1)条件了。因此采用条件覆盖和条件判定覆盖逻辑表达式中的错误不一定能够检查出来。
如果题意要求考虑这种条件屏蔽的现象(大部分考试都会要求),就必须要多设个测试用例满足被屏蔽的条件,例如下面这道题:
e.g:针对coverage1() 根据判定条件覆盖设计用例 ,完成以下表格,需要考虑条件屏蔽。
public void coverage1( int i, int j) {
int x = 0;
int y = 0;
if (i > 0 && j > 0) {
y = y + 1;
} else {
if (i > -5 || j > -5)
y = y - 1;
else
x = x - 2;
}
System.out.println("x=" + x + ";y=" + y);
}
答案: (测试用例我就不写了,照着表格写用例就行了)
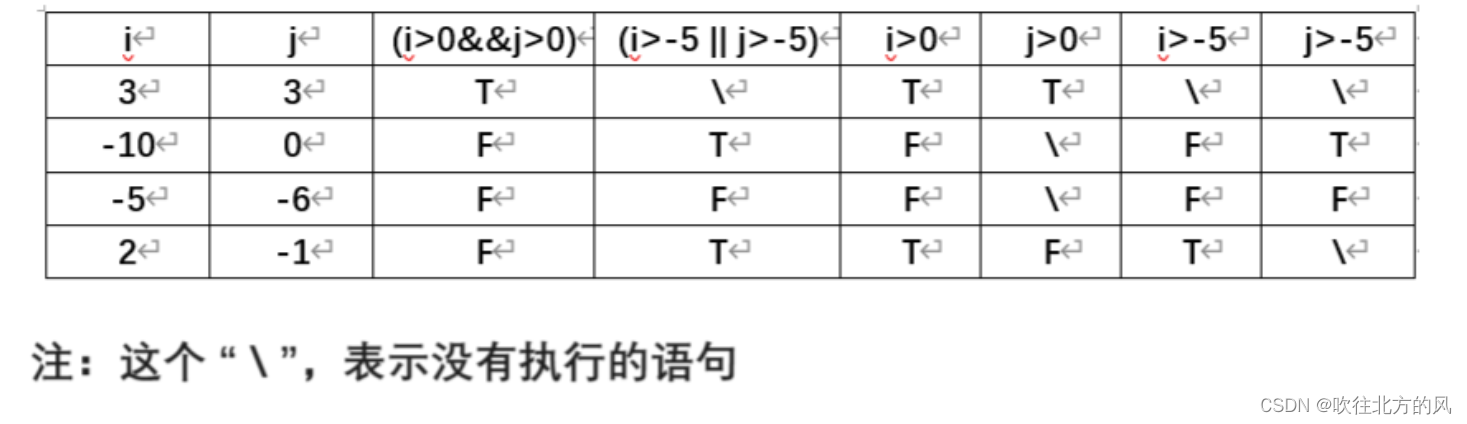 这个 “ \ ” 没有执行的原因就是条件屏蔽的现象!
这个 “ \ ” 没有执行的原因就是条件屏蔽的现象!
(5)条件组合覆盖
条件组合覆盖:设计若干测试用例,使得每个判定中条件的各种可能组合都至少执行一次。 满足了判定覆盖、条件覆盖、判定-条件覆盖准则。
注意:是每个判定中的条件的各种组合,如果有两个或多个判定,只需满足各自判定中条件的组合就行。
为满足条件组合覆盖原则,我们可以构造以下测试用例:
输入:① A=2,B=0,X=4 ,覆盖路径: ace (条件的结果分别为:TTTT )
输入: ② A=2,B=1,X=1,覆盖路径: abe (条件的结果分别为:TFTF )
输入:③ A=1,B=0,X=2 ,覆盖路径: abe (条件的结果分别为:FTFT )
输入: ④ A=1,B=1,X=1,覆盖路径: abd (条件的结果分别为:FFFF )
只要满足条件组合覆盖就一定满足语句覆盖,判定覆盖,条件覆盖,判定条件覆盖,
但是可能不会覆盖所有的路径,如上面测试用例就有 acd 路径没有执行。
(6)修正的判定/条件覆盖
在满足判定/条件覆盖的基础上,每个简单判定条件都应独立地影响到整个判定表达式的取值,实质是利用简单判定条件的独立影响性来消除测试用例的冗余。
步骤:
注意: 若有n条简单判定条件,最后得出的独立影响对个数一定在:[ n + 1 , 2n ]的区间内!!
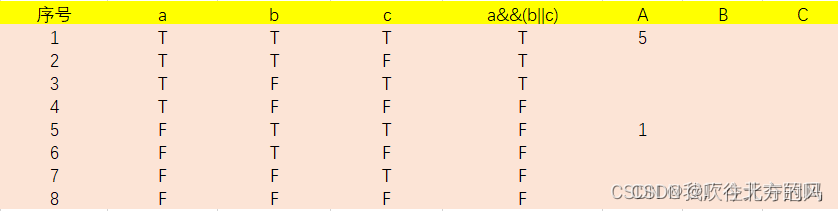
e.g1:由含有3个简单判定条件的判定结点: a && (b || c),得出其独立影响对的测试用例集合。
构建真值表如下:

可以看到b与c相同的情况下,①b、c同为真,此时a取T、F会对a&&(b||c)的结果产生影响也就是说a这个值对结果有了独立的影响,将结果纪录下来(这个结果正是a条件的独立影响对) 。
以此类推,能独立影响结果的都记录下来:
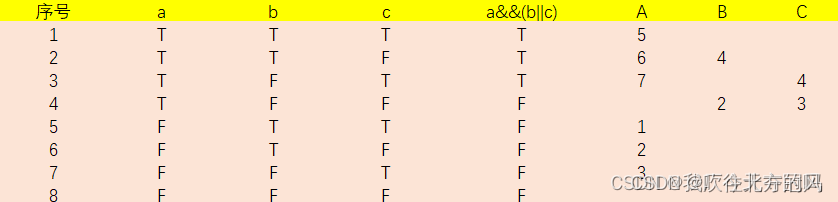
这样测试a的影响可以使用{1,5}、{2,6}、{3,7}
测试b的影响使用{2,4}
c的影响{3,4}
因为最后得出的独立影响对个数一定在:[ n + 1 , 2n ]的区间内!!,这里的话就是 [4 , 6]
所以可以取测试用例为: {2,3,4,6} (因为都包含了 a、b、c的独立影响对)
同理也可以取测试用例为: {2,3,4,7},这并不唯一
优点:综合具备条件组合覆盖的优点。有效控制了测试用例数量,消除了测试冗余。
缺点:分析过程较为繁琐,测试用例设计较为困难。
如上讲述的例子节选于修正的判定/条件覆盖
e.g2:
【2】基于路径的测试
对路径覆盖进行穷举测试可以吗? ----不可以
比如下面这个的流程图,其中包括了一个执行达20次的循环。那么它所包含的不同执行路径数高达5^20条,若要对它进行穷举测试,覆盖所有的路径。假使测试程序对每一条路径进行测试需要1毫秒,同样假定一天工作24小时,一年工作365 天, 那么要想把如图所示的小程序的所有路径测试完,则需要3170年。
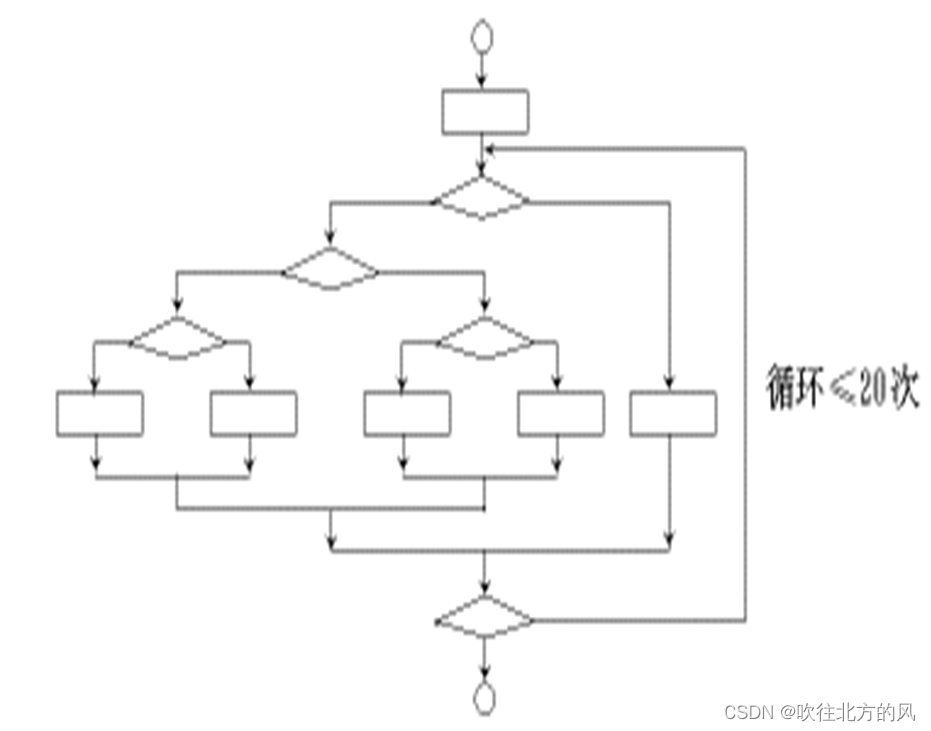
对路径完全测试不可能,为了降低测试的风险,找到一批典型的路径,通过测试这些典型的路径,达到对全部可执行路径的测试覆盖。
什么是路径?
程序从起始执行到程序结束经过的所有节点和连接线。
什么是独立路径?
从全路径集合中抽取一组线性无关的路径,实际上就是指至少引入一个新处理语句或一条新判断的程序通路。
独立路径测试的目标:
测试的完备性:通过对独立路径的测试达到对所有路径的测试覆盖、
测试的无冗余性:每条路径都是独立的
基于独立路径的测试用例设计步骤:
- 程序源代码生成程序控制流图
- 计算程序控制流图的环复杂度,程序的环路复杂度计算结果给出了程序独立路径集合中的独立路径条数,这是保证程序中每个可执行语句至少被执行一次所必需的测试用例数量的上限,也就是说,我们只要最多V(G)个测试用例就可以满足基本路径覆盖要求
- 确定独立路径集合
- 准备测试用例
内容回顾:环复杂度计算
- 使用判定节点法:V(G) = P + 1
- P代表独立判定节点,即两分支的判定
- 如果判定节点是n分支(n>2),该判定节点应视为(n-1)个独立判定节点
e.g:独立路径测试实例

(1) 画程序控制流图:
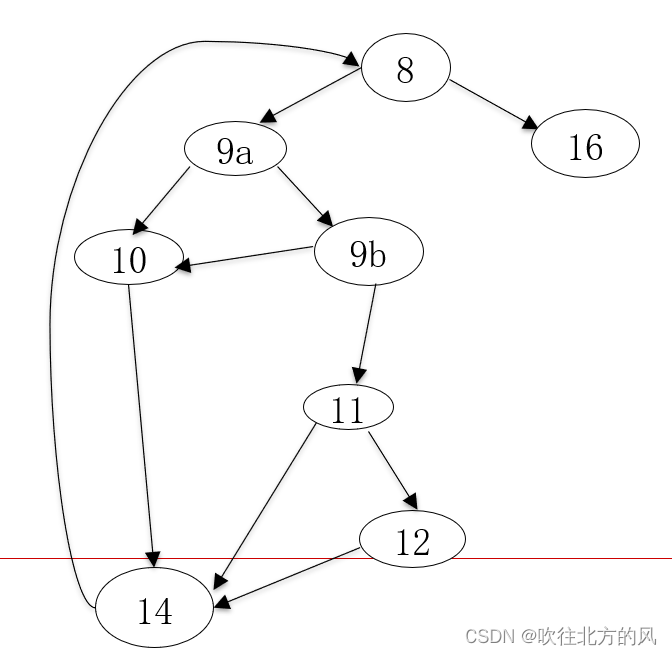
(2)计算程序控制流图的环复杂度
从图中可以看出独立判定结点为:8、9a、9b、11,总共四个。
那么环复杂度等于:V(G) = P + 1 = 4 + 1 = 5
程序环路复杂度是5。因此,只要最多5个测试用例就可以达到基本路径覆盖。
(3)确定独立路径集合
Path1: 8,9a,9b,11,12,14,8,16
Path2: 8,9a,9b,11,14,8a,16
Path3: 8,9a,9b,10,14,8,16
Path4: 8,9a,10,14,8,16
Path5: 8,16
(4)准备测试用例
当然下面还要加一列预期输出值,我就偷工减料了哈。
独立路径 |
测试用例 |
Path1 |
i=9,j=1 |
Path2 |
i=9,j=3 |
Path3 |
i=9,j=2 |
Path4 |
i=9,j=0 |
Path5 |
i=11,j=0 |
路径覆盖就是设计足够多的测试用例,使得被测试程序中的每一条路径至少被覆盖一次。
注意:
- 路径测试不一定满足条件覆盖,一定满足判定覆盖
- 程序的环路复杂度表示的是最多的测试用例个数,是测试用例数量的上界,实际用例数不一定要达到这个上界。
- 测试用例数量越简化,测试的充分性就越低。
- 需要根据实际情况来确定测试用例数量简化的程度。
【3】基于循环的测试
对循环结构进行测试的重要关注点:
- 循环过程的正确性
- 循环的边界和界限内对循环体的执行过程
针对不同类型的循环结构,测试难点如下:
- 单个循环节点,如何结合测试循环的边界进行测试
- 单个循环节点,如何设计测试用例来保证循环的完整性
- 串联的循环节点,如何保证测试的全面性
- 对于非结构化的循环,如何进行测试
(1) 单个循环结点的测试分析

针对单个循环节点循环次数的测试(假设循环N次) ,那么测试点如下:
- 循环0次(即不执行循环)
- 循环1次
- 循环2次
- 循环正常次数(通常为最大次数的一半)
- 循环n-1次
- 循环n次
(2)串联循环结构:
- 非关联循环节点:按单个循环节点依次测试;
- 关联循环节点:结合测试
(3)循环节点嵌套测试分析
 当循环节点为嵌套形式,且判定节点相互独立时:
当循环节点为嵌套形式,且判定节点相互独立时:
- 先测试最内层循环体,然后逐步外推,直至测试到最外层的循环体
- 测试每层循环体时,仍根据单个循环体的测试原则进行测试(按从内向外的次序)
(4)非结构化循环结构测试
首先:建议修改代码
其次:如果不能修改代码,则先对单次循环体进行测试;兼顾嵌套循环条件下对循环次数的多种特殊组合
对于循环的测试,我们学校讲解的也是一笔带过,所以有不足的地方还望海涵。
【4】基于变量的测试
重点关注计算结果对函数返回值影响最大的变量,即最可能出错的变量。
变量常见的3种缺陷:
- 变量在使用前从未定义过(在编译时,会有提示,不需人工查找)
- 变量被定义,但从未使用过
- 变量在使用前,被多次定义(寻找这种错误的过程,是一种静态分析的过程,不需要设计测试用例)
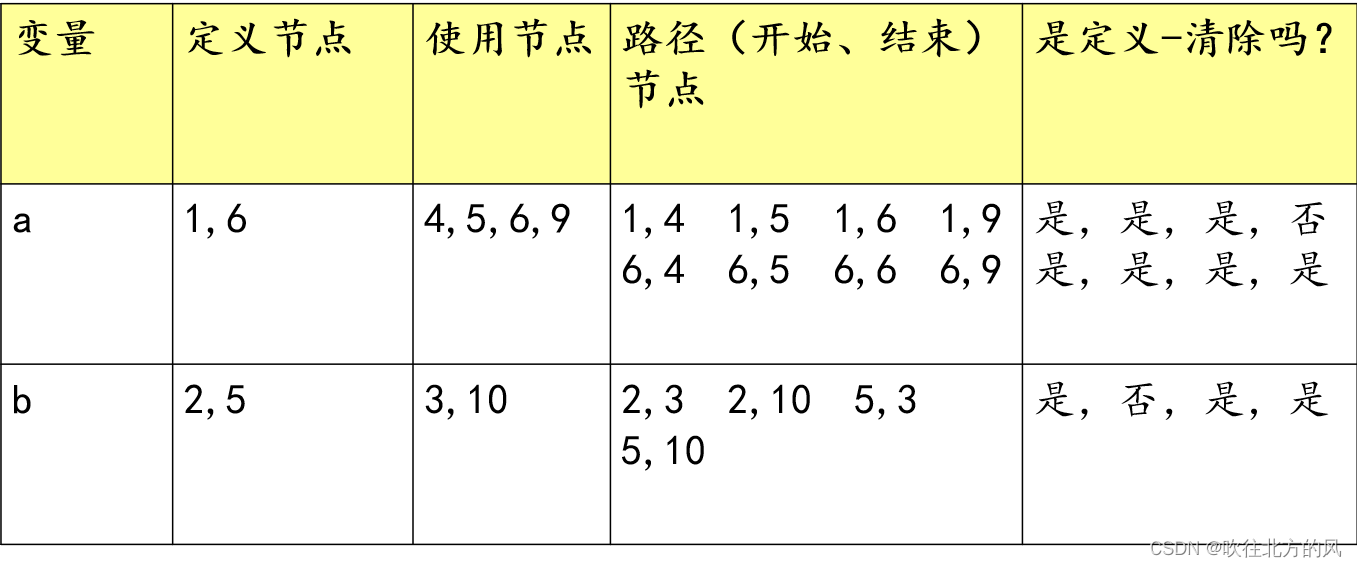
数据流测试的基本原理是以被测变量为中心,关注该变量的每条定义、使用路径,若该路径存在定义/引用异常缺陷,则该路径是一条高风险路径,需要重点进行测试。
(1)定义节点:
若被测变量v的值在某条包含该变量的语句n处发生改变,则称该语句是关于变量v的定义节点,记做DEF(v,n)
- 输入语句、赋值语句(对该变量赋值)、循环控制语句(循环变量)都是定义节点
(2)使用节点
若被测变量v的值在某条包含该变量的语句n处被使用,则称该语句是关于变量v的使用节点,记做USE(v,n)
- 输出语句、赋值语句(变量v对其他变量的赋值)、条件语句、循环控制语句都是使用节点
(3)定义 / 使用节点对
由被测变量v的一对定义节点和使用节点构成的一个二元组称为该变量的定义/使用节点对。
(4)定义 / 使用路径
从被测变量v的一个定义节点开始执行,到该变量的某个使用节点结束的一条路径称为该变量的一条定义/使用路径,记做du-path
(5)定义/清除路径
若被测变量v的一条定义/使用路径中不包含该变量的其他定义节点,则该路径称为定义清除路径,记做dc-path
对关键变量的数据流测试的一般步骤如下:
例题:

三、结尾
好了,到目前为止你就复习完了白盒测试,是不是非常通俗易懂啊,如果有什么建议,欢迎在评论区下方讨论,后续我还会更新……
期待您的点赞、收藏、关注,你的支持是我最大的动力 ₍ᐢ..ᐢ₎ ♡