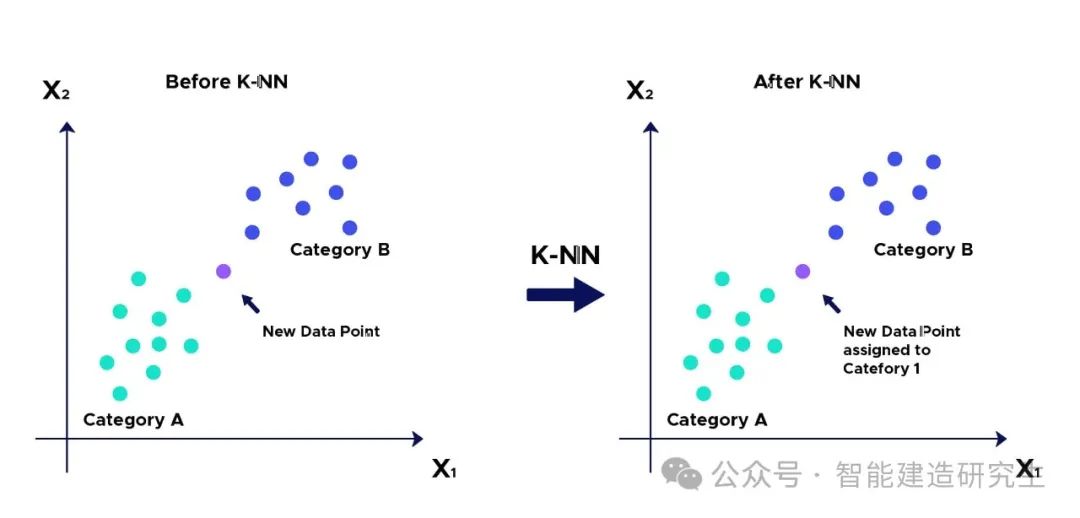
KNN(K-Nearest Neighbors)算法是一种常用的机器学习算法,主要用于分类和回归问题。
1. KNN算法的基本概念
KNN算法是一种基于实例的学习算法,也称为惰性学习(Lazy Learning)算法,因为它在训练阶段并不进行显式的模型训练,而是将所有的训练数据存储起来,直到需要进行预测时才进行计算。KNN的基本思想是:如果一个样本在特征空间中的k个最相似(即特征空间距离最小)的样本中的多数属于某一个类别,则该样本也属于这个类别。
2. KNN算法的工作原理
KNN算法的工作原理可以分为以下几个步骤:
选择参数k:选择一个正整数k,表示在进行预测时需要考虑的最近邻居的数量。
计算距离:使用距离度量方法(如欧氏距离、曼哈顿距离等)计算待分类样本与训练集中所有样本之间的距离。
找到k个最近邻居:根据计算的距离从小到大排序,选取前k个距离最近的样本。
投票或平均:
分类问题:对k个最近邻居的类别进行投票,选择票数最多的类别作为预测类别。
回归问题:对k个最近邻居的值进行平均,作为预测值。
3. 距离度量方法
常用的距离度量方法有:
欧氏距离(Euclidean Distance):适用于连续变量。计算公式为:
曼哈顿距离(Manhattan Distance):适用于高维空间。计算公式为:
明氏距离(Minkowski Distance):欧氏距离和曼哈顿距离的泛化形式。计算公式为:
其中,当p=2时为欧氏距离,当p=1时为曼哈顿距离。
4. KNN算法的优缺点
优点:
简单易懂,易于实现。
无需显式训练,适用于在线学习。
缺点:
计算复杂度高,存储开销大,特别是在大规模数据集上。
对于高维数据,距离度量可能失效(即“维度灾难”问题)。
受噪声数据和不相关特征的影响较大,需要数据标准化。
5. KNN算法的改进
为了提升KNN算法的性能,常用的改进方法包括:
数据标准化:在计算距离前对数据进行标准化处理,使得每个特征对距离的影响相等。
权重KNN:给不同的邻居分配不同的权重,距离越近的邻居权重越大。
快速近邻搜索:利用KD树、球树等数据结构加速最近邻搜索。
6. 应用领域
KNN算法广泛应用于各种领域,包括:
文本分类:如垃圾邮件检测、文档分类。
图像识别:如手写数字识别、人脸识别。
推荐系统:如用户兴趣预测、商品推荐。
7. KNN的python实现
以下是一个使用Python的scikit-learn库实现KNN分类的示例:
import matplotlib.pyplot as plt # 导入Matplotlib库,用于数据可视化
from sklearn.datasets import make_moons # 从scikit-learn库导入make_moons数据集生成函数
from sklearn.model_selection import train_test_split # 从scikit-learn库导入数据集拆分函数
from sklearn.neighbors import KNeighborsClassifier # 从scikit-learn库导入KNN分类器
from sklearn.metrics import accuracy_score, ConfusionMatrixDisplay # 从scikit-learn库导入计算准确率和显示混淆矩阵的函数
# 生成数据集
X, y = make_moons(n_samples=300, noise=0.3, random_state=42) # 生成一个包含300个样本的make_moons数据集,添加噪声0.3,随机种子42
# 数据集拆分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42) # 将数据集拆分为训练集和测试集,测试集占30%,随机种子设为42
# 创建KNN分类器,选择K=5
knn = KNeighborsClassifier(n_neighbors=5) # 实例化一个KNN分类器对象,K值设为5
# 训练模型
knn.fit(X_train, y_train) # 使用训练集数据训练KNN模型
# 进行预测
y_pred = knn.predict(X_test) # 使用训练好的模型对测试集进行预测
# 计算准确率
accuracy = accuracy_score(y_test, y_pred) # 计算预测结果的准确率
print(f"Accuracy: {accuracy:.2f}") # 输出准确率,保留两位小数
# 混淆矩阵可视化
disp = ConfusionMatrixDisplay.from_estimator(knn, X_test, y_test, display_labels=["Class 0", "Class 1"], cmap=plt.cm.Blues)
# 创建混淆矩阵显示对象,并使用测试集的预测结果和真实结果,设置类别标签为“Class 0”和“Class 1”,颜色图为蓝色渐变
plt.title("Confusion Matrix") # 设置图表标题
plt.show() # 显示混淆矩阵图表
# 绘制特征空间中的决策边界
def plot_decision_boundaries(X, y, model, title="Decision Boundaries"):
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1 # 计算第一个特征的取值范围,并扩展边界
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1 # 计算第二个特征的取值范围,并扩展边界
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.1), np.arange(y_min, y_max, 0.1)) # 创建网格坐标,步长为0.1
Z = model.predict(np.c_[xx.ravel(), yy.ravel()]) # 对网格上的每个点进行预测
Z = Z.reshape(xx.shape) # 将预测结果的形状重塑为与网格相同
plt.contourf(xx, yy, Z, alpha=0.3) # 绘制决策边界,用颜色表示不同的类别区域,alpha设置透明度
plt.scatter(X[:, 0], X[:, 1], c=y, s=30, edgecolor='k') # 绘制样本点,c=y表示点的颜色由标签决定,s=30设置点的大小,edgecolor='k'设置点的边缘颜色为黑色
plt.title(title) # 设置图表标题
plt.xlabel('Feature 1') # 设置x轴标签
plt.ylabel('Feature 2') # 设置y轴标签
plt.show() # 显示图表
# 使用训练好的模型绘制决策边界
plot_decision_boundaries(X, y, knn, title="KNN Decision Boundaries with K=5") # 调用函数绘制决策边界,传入数据、标签和模型,设置标题
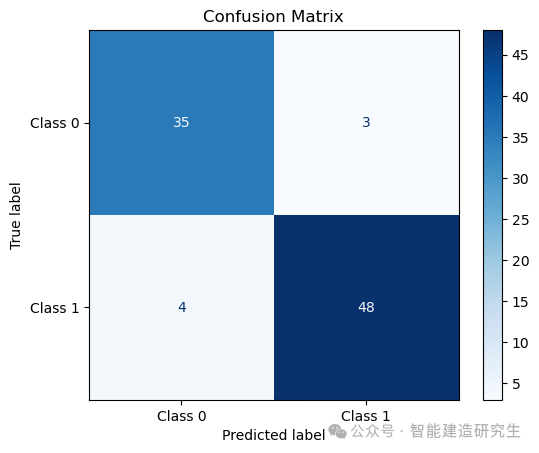
混淆矩阵是一种特殊的矩阵,用于评估分类模型的性能。它展示了实际类别与预测类别之间的对应关系。混淆矩阵的每一行代表实际类别,每一列代表预测类别。通过混淆矩阵,可以直观地看出模型在哪些类别上表现良好,在哪些类别上存在误差。混淆矩阵还可以用来计算各种性能指标,如准确率(Accuracy)、精确率(Precision)、召回率(Recall)和F1分数(F1 Score)。
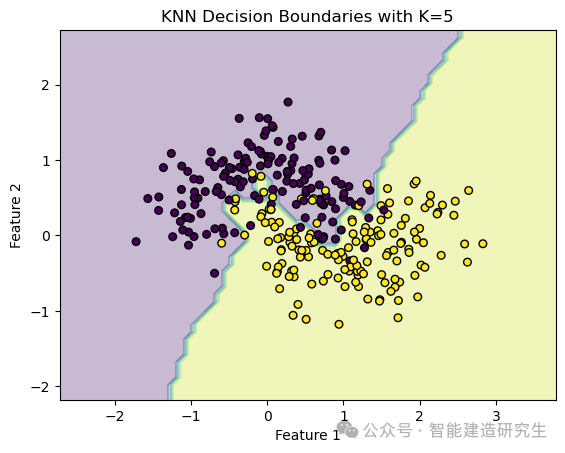
决策边界图展示了模型如何在不同的特征区域内进行分类,通常用于可视化二分类或多分类问题。通过类别决策图,可以直观地看出模型的决策边界,以及各类别在特征空间中的分布情况。决策边界是不同类别之间的分界线,模型在这条线的两侧做出不同的分类决策。类别决策图可以帮助识别模型在不同特征区域内的分类表现,观察是否存在决策边界过于复杂或过于简单的情况。
以上内容总结自网络,如有帮助欢迎转发,我们下次再见!