- cross_entropy计算误差方式,输入向量z为[1,2,3],预测y为[1],选择数为2,计算出一大坨e的式子为3.405,再用-2+3.405计算得到1.405
- MSE计算误差方式,输入z为[1,2,3],预测向量应该是[1,0,0],和输入向量维度相同
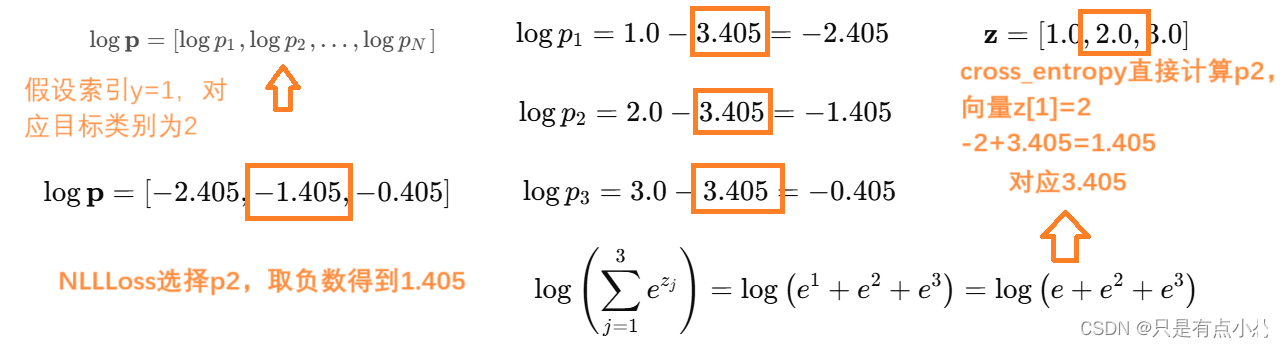
将cross_entropy直接替换成mse_loss报错RuntimeError: The size of tensor a (7) must match the size of tensor b (140) at non-singleton dimension 1
将 cross_entropy 换成 mse_loss 会报错的原因是,这两个损失函数的输入和输出形状要求不同。cross_entropy 是一个分类损失函数,它期望输入是未归一化的logits(形状为 [batch_size, num_classes]),而标签是整数类别(形状为 [batch_size])。mse_loss 是一个回归损失函数,它期望输入和标签的形状相同。
如果你想使用 mse_loss 来替代 cross_entropy,你需要对标签进行one-hot编码,使它们与模型的输出形状匹配。下面是如何修改代码以使用 mse_loss 的示例:
修改代码以使用 mse_loss
加载必要的库:
你需要一个工具来将标签转换为one-hot编码。这里我们使用torch.nn.functional.one_hot。修改训练函数:
在训练函数中,将标签转换为one-hot编码,然后计算mse_loss。
核心测试代码讲解
out=model(data)模型输出形状为torch.Size([140, 7])
data.y中测试数据输出形状为torch.Size([140]),打印第一个数据为3,7个类别中的第4个类别
将3转化为7位置独热码计算MSE,对应train_labels_one_hot第一个数据[0., 0., 0., 1., 0., 0., 0.]为4
out形状为torch.Size([140, 7]),train_labels_one_hot的形状为[140, 7]
torch.Size([140, 7]) torch.Size([140])
tensor([-0.0166, 0.0191, -0.0036, -0.0053, -0.0160, 0.0071, -0.0042],
device='cuda:0', grad_fn=<SelectBackward0>) tensor(3, device='cuda:0')
tensor([[0., 0., 0., 1., 0., 0., 0.],
...
[0., 1., 0., 0., 0., 0., 0.]], device='cuda:0')
train_labels_one_hot shape torch.Size([140, 7])
test out torch.Size([2708, 7])
train_labels_one_hot = F.one_hot(data.y[data.train_mask], num_classes=dataset.num_classes).float()
print(out[data.train_mask].shape, data.y[data.train_mask].shape)
print(out[data.train_mask][0], data.y[data.train_mask][0])
print(train_labels_one_hot)
print(f"train_labels_one_hot shape {train_labels_one_hot.shape}")
loss = F.mse_loss(out[data.train_mask], train_labels_one_hot)
解释
- 加载库:我们使用
torch.nn.functional.one_hot将标签转换为one-hot编码。 - 修改训练函数:
- 将标签
train_labels转换为one-hot编码,train_labels_one_hot = F.one_hot(train_labels, num_classes=dataset.num_classes).float()。 - 使用
mse_loss计算均方误差损失loss = F.mse_loss(train_out, train_labels_one_hot)。
- 将标签
- 保持评估函数不变:评估函数仍然使用
argmax提取预测类别,并计算准确性。
魔改完整代码
import torch
import torch.nn.functional as F
from torch_geometric.nn import GCNConv
from torch_geometric.datasets import Planetoid
from torch_geometric.transforms import NormalizeFeatures
# 加载Cora数据集
dataset = Planetoid(root='/tmp/Cora', name='Cora', transform=NormalizeFeatures())
data = dataset[0]
# 定义GCN模型
class GCN(torch.nn.Module):
def __init__(self):
super(GCN, self).__init__()
self.conv1 = GCNConv(dataset.num_node_features, 16)
self.conv2 = GCNConv(16, dataset.num_classes)
def forward(self, data):
x, edge_index = data.x, data.edge_index
x = self.conv1(x, edge_index)
x = F.relu(x)
x = F.dropout(x, training=self.training)
x = self.conv2(x, edge_index)
return x
# return F.log_softmax(x, dim=1)
# 初始化模型和优化器
model = GCN()
print(model)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=5e-4)
data = data.to('cuda')
model = model.to('cuda')
# 打印归一化后的特征
print(data.x[0])
print(f"data.train_mask{data.train_mask}")
# 训练模型
def train():
model.train()
optimizer.zero_grad()
out = model(data)
# print(f"out[data.train_mask] {data.train_mask.shape} {out[data.train_mask].shape} {out[data.train_mask]}")
# loss = F.nll_loss(out[data.train_mask], data.y[data.train_mask])
train_labels_one_hot = F.one_hot(data.y[data.train_mask], num_classes=dataset.num_classes).float()
print(out[data.train_mask].shape, data.y[data.train_mask].shape)
print(out[data.train_mask][0], data.y[data.train_mask][0])
print(train_labels_one_hot)
print(f"train_labels_one_hot shape {train_labels_one_hot.shape}")
loss = F.mse_loss(out[data.train_mask], train_labels_one_hot)
loss.backward()
optimizer.step()
return loss.item()
# 评估模型
def test():
model.eval()
out = model(data)
print(f"test out {out.shape}")
print(f"test out[0] {out[0].shape} {out[0]}")
print(f"test out[0:1,:] {out[0:1,:].shape} {out[0:1,:]}")
print(f"test out[0:1,:].argmax(dim=1) {out[0:1,:].argmax(dim=1)}")
pred = out.argmax(dim=1)
print(f"test pred {pred[data.test_mask].shape} {pred[data.test_mask]}")
print(f"data {data.y[data.test_mask].shape} {data.y[data.test_mask]}")
correct = (pred[data.test_mask] == data.y[data.test_mask]).sum()
acc = int(correct) / int(data.test_mask.sum())
return acc
for epoch in range(1):
loss = train()
acc = test()
print(f'Epoch {epoch+1}, Loss: {loss:.4f}, Accuracy: {acc:.4f}')
原始代码
import torch
import torch.nn.functional as F
from torch_geometric.nn import GCNConv
from torch_geometric.datasets import Planetoid
from torch_geometric.transforms import NormalizeFeatures
# 加载Cora数据集,并应用NormalizeFeatures变换
dataset = Planetoid(root='/tmp/Cora', name='Cora', transform=NormalizeFeatures())
data = dataset[0]
# 计算训练、验证和测试集的大小
num_train = data.train_mask.sum().item()
num_val = data.val_mask.sum().item()
num_test = data.test_mask.sum().item()
print(f'Number of training nodes: {num_train}')
print(f'Number of validation nodes: {num_val}')
print(f'Number of test nodes: {num_test}')
# 定义GCN模型
class GCN(torch.nn.Module):
def __init__(self):
super(GCN, self).__init__()
self.conv1 = GCNConv(dataset.num_node_features, 16)
self.conv2 = GCNConv(16, dataset.num_classes)
def forward(self, data):
x, edge_index = data.x, data.edge_index
x = self.conv1(x, edge_index)
x = F.relu(x)
x = F.dropout(x, training=self.training)
x = self.conv2(x, edge_index)
return x # 返回未归一化的logits
# 初始化模型和优化器
model = GCN()
optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=5e-4)
data = data.to('cuda')
model = model.to('cuda')
# 训练模型
def train():
model.train()
optimizer.zero_grad()
out = model(data) # out 的形状是 [num_nodes, num_classes]
train_out = out[data.train_mask] # 选择训练集节点的输出
train_labels = data.y[data.train_mask] # 选择训练集节点的标签
# 将标签转换为one-hot编码
train_labels_one_hot = F.one_hot(train_labels, num_classes=dataset.num_classes).float()
# 计算均方误差损失
loss = F.mse_loss(train_out, train_labels_one_hot)
loss.backward()
optimizer.step()
return loss.item()
# 评估模型
def test():
model.eval()
out = model(data)
pred = out.argmax(dim=1) # 提取预测类别
correct = (pred[data.test_mask] == data.y[data.test_mask]).sum()
acc = int(correct) / int(data.test_mask.sum())
return acc
for epoch in range(200):
loss = train()
acc = test()
print(f'Epoch {epoch+1}, Loss: {loss:.4f}, Accuracy: {acc:.4f}')
通过这些修改,你可以将交叉熵损失函数替换为均方误差损失函数,并确保输入和标签的形状匹配,从而避免报错。
- 简单版本的的答案
Cross Entropy vs. MSE Loss
Cross Entropy Loss:
- 输入:模型的logits,形状为 ([N, C]),其中 (N) 是批次大小,(C) 是类别数量。
- 目标:目标类别的索引,形状为 ([N])。
MSE Loss:
- 输入:模型的预测值,形状为 ([N, C])。
- 目标:实际值,形状为 ([N, C])(通常是 one-hot 编码)。
要将 cross_entropy 换成 mse_loss,需要确保输入和目标的形状匹配。具体来说,你需要将目标类别索引转换为 one-hot 编码。
示例代码
假设你有一个分类任务,其中模型输出的是 logits,目标是类别索引。我们将这个设置转换为使用 MSE Loss。
import torch
import torch.nn.functional as F
# 假设有一个批次的模型输出和目标标签
logits = torch.tensor([[1.0, 2.0, 3.0], [1.0, 2.0, 3.0]], requires_grad=True) # 模型输出
target = torch.tensor([0, 2]) # 目标类别
# 使用 cross_entropy
cross_entropy_loss = F.cross_entropy(logits, target)
print("Cross-Entropy Loss:")
print(cross_entropy_loss)
# 转换目标类别为 one-hot 编码
target_one_hot = F.one_hot(target, num_classes=logits.size(1)).float()
print("One-Hot Encoded Targets:")
print(target_one_hot)
# 计算 MSE Loss
mse_loss = F.mse_loss(F.softmax(logits, dim=1), target_one_hot)
print("MSE Loss:")
print(mse_loss)
输出
Cross-Entropy Loss:
tensor(1.4076, grad_fn=<NllLossBackward>)
One-Hot Encoded Targets:
tensor([[1., 0., 0.],
[0., 0., 1.]])
MSE Loss:
tensor(0.2181, grad_fn=<MseLossBackward>)
解释
logits: 模型的原始输出,形状为 ([N, C])。target: 原始目标类别索引,形状为 ([N])。target_one_hot: 将目标类别索引转换为 one-hot 编码,形状为 ([N, C])。F.mse_loss: 使用F.softmax(logits, dim=1)计算模型的概率分布,然后与target_one_hot计算 MSE 损失。
通过将目标类别转换为 one-hot 编码并确保输入和目标的形状匹配,可以成功地将 cross_entropy 换成 mse_loss。