前言
Hello,大家好,我是cv君,最近开始在空闲之余,经常更新文章啦!除目标检测、分类、分隔、姿态估计等任务外,还会涵盖图像增强领域,如超分辨率、画质增强、降噪、夜视增强、去雾去雨、ISP、海思高通成像ISP等、AI-ISP、还会有多模态、文本nlp领域、视觉语言大模型、lora、chatgpt等理论与实践文章更新,更新将变成一周2-3更,一个月争取10篇,重回创作巅峰,之前cv君曾在csdn排行前90名总榜,感谢大家观看点赞和收藏;有任何问题可以文末微信联系或私聊我。
本文章涵盖v8的全解,以及各版本亮点介绍,以及如何进行训练,以及如何优化,附带20多个多个独家魔改技巧,v8 v9通用。
v8优化简言
Backbone:使用的依旧是CSP的思想,不过YOLOv5中的C3模块被替换成了C2f模块,实现了进一步的轻量化,同时YOLOv8依旧使用了YOLOv5等架构中使用的SPPF模块;
骨干网络和 Neck 部分可能参考了 YOLOv7 ELAN 设计思想,将 YOLOv5 的 C3 结构换成了梯度流更丰富的 C2f 结构,并对不同尺度模型调整了不同的通道数,属于对模型结构精心微调,不再是无脑一套参数应用所有模型,大幅提升了模型性能。不过这个 C2f 模块中存在 Split 等操作对特定硬件部署没有之前那么友好了
PAN-FPN:毫无疑问YOLOv8依旧使用了PAN的思想,不过通过对比YOLOv5与YOLOv8的结构图可以看到,YOLOv8将YOLOv5中PAN-FPN上采样阶段中的卷积结构删除了,同时也将C3模块替换为了C2f模块;
Decoupled-Head:Head 部分相比 YOLOv5 改动较大,换成了目前主流的解耦头结构,将分类和检测头分离,同时也从 Anchor-Based 换成了 Anchor-Free,YOLOv8走向了Decoupled-Head;
Anchor-Free:YOLOv8抛弃了以往的Anchor-Base,使用了Anchor-Free的思想;
损失函数:YOLOv8使用VFL Loss作为分类损失,使用DFL Loss+CIOU Loss作为分类损失;Loss 计算方面采用了 TaskAlignedAssigner 正样本分配策略,并引入了 Distribution Focal Loss
样本匹配:YOLOv8抛弃了以往的IOU匹配或者单边比例的分配方式,而是使用了Task-Aligned Assigner匹配方式。
训练的数据增强部分引入了 YOLOX 中的最后 10 epoch 关闭 Mosiac 增强的操作,可以有效地提升精度

下面将按照模型结构设计、Loss 计算、训练数据增强、训练策略和模型推理过程共 5 个部分详细介绍 YOLOv8 目标检测的各种改进,实例分割部分暂时不进行描述。

对比 YOLOv5 和 YOLOv8 的 yaml 配置文件可以发现改动较小。


骨干网络和 Neck 的具体变化
- 第一个卷积层的 kernel 从 6x6 变成了 3x3
- 所有的 C3 模块换成 C2f,结构如下所示,可以发现多了更多的跳层连接和额外的 Split 操作

- 去掉了 Neck 模块中的 2 个卷积连接层
- Backbone 中 C2f 的block 数从 3-6-9-3 改成了 3-6-6-3
- 查看 N/S/M/L/X 等不同大小模型,可以发现 N/S 和 L/X 两组模型只是改了缩放系数,但是 S/M/L 等骨干网络的通道数设置不一样,没有遵循同一套缩放系数。如此设计的原因应该是同一套缩放系数下的通道设置不是最优设计,YOLOv7 网络设计时也没有遵循一套缩放系数作用于所有模型
Head 部分变化最大,从原先的耦合头变成了解耦头,并且从 YOLOv5 的 Anchor-Based 变成了 Anchor-Free。其结构如下所示:

可以看出,不再有之前的 objectness 分支,只有解耦的分类和回归分支,并且其回归分支使用了 Distribution Focal Loss 中提出的积分形式表示法

C2f模块
C2f模块是什么?与C3有什么区别呢,我们先看一下C3模块的结构图,然后再对比与C2f的具体的区别。针对C3模块,其主要是借助CSPNet提取分流的思想,同时结合残差结构的思想,设计了所谓的C3 Block,这里的CSP主分支梯度模块为BottleNeck模块,也就是所谓的残差模块。同时堆叠的个数由参数n来进行控制,也就是说不同规模的模型,n的值是有变化的。

其实这里的梯度流主分支,可以是任何之前你学习过的模块,比如,美团提出的YOLOv6中就是用来重参模块RepVGGBlock来替换BottleNeck Block来作为主要的梯度流分支,而百度提出的PP-YOLOE则是使用了RepResNet-Block来替换BottleNeck Block来作为主要的梯度流分支。而YOLOv7则是使用了ELAN Block来替换BottleNeck Block来作为主要的梯度流分支。
C2f模块介绍,通过C3模块的代码以及结构图可以看到,C3模块和名字思路一致,在模块中使用了3个卷积模块(Conv+BN+SiLU),以及n个BottleNeck。
通过C3代码可以看出,对于cv1卷积和cv2卷积的通道数是一致的,而cv3的输入通道数是前者的2倍,因为cv3的输入是由主梯度流分支(BottleNeck分支)依旧次梯度流分支(CBS,cv2分支)cat得到的,因此是2倍的通道数,而输出则是一样的。
不妨我们再看一下YOLOv7中的模块

YOLOv7通过并行更多的梯度流分支,放ELAN模块可以获得更丰富的梯度信息,进而或者更高的精度和更合理的延迟。
C2f模块的结构图如下:
我们可以很容易的看出,C2f模块就是参考了C3模块以及ELAN的思想进行的设计,让YOLOv8可以在保证轻量化的同时获得更加丰富的梯度流信息。
C3模块以及RepBlock替换为了C2f,同时细心可以发现,相对于YOLOv5和YOLOv6,YOLOv8选择将上采样之前的1×1卷积去除了,将Backbone不同阶段输出的特征直接送入了上采样操作。

yolov8是将C3替换为C2F网络结构,我们先不要着急看C2F,我们先介绍一下chunk函数,因为在C2F中会用到该函数,如果你对该函数很了解那么可以略去该函数的讲解。chunk函数,就是可以将张量A沿着某个维度dim,分割成指定的张量块。可以看个示例:
假设我的输入张量x的shape为[1,3,640,640],经过一个1x1的卷积后,输出shape为[1,16,640,640],如下:

可以看到通过chunk函数将输出通道为16,平均分成了2份后,每个tensor的shape均为[1,8,640,640]。这里只是补充了一下torch.chunk函数的知识~
接下来我们继续看C2F模块。结构图如下:我这里是参考C2F代码来绘制的。
C2F就是由两个卷积层和n个Bottleneck层组成。与yolov5 C3结构很像,只不过C3中的Feat1和Feat2是通过两个卷积实现的,而C2F中通过chunk函数将一个卷积的输出进行分块得到,这样的一个好处就是减少参数和计算量。
SPPF

上图中,左边是SPP,右边是SPPF。
Head
yolov8的head和yolov5的区别是,v5采用的是耦合头,v8采用的解耦头。什么叫耦合头呢?其实就是在网络最终输出的时候是把bbox、obj、cls三个部分耦合在一起(比如coco数据集,我们知道输出的其中有一个维度是85=5+80,比如有个特征层的shape为【bs,80,80,3,85】,80x80是特征图的高和宽,3是三种anchors,85就是),而v8是将head做了拆分,解耦成了box和cls。
def forward(self, x):
z = [] # inference output
for i in range(self.nl):
x[i] = self.m[i](x[i]) # conv
bs, _, ny, nx = x[i].shape
# x(bs,255,20,20) to x(bs,3,20,20,85)
# self.no = nc + 5
x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
self.cv2 = nn.ModuleList(
nn.Sequential(Conv(x, c2, 3), Conv(c2, c2, 3), nn.Conv2d(c2, 4 * self.reg_max, 1)) for x in ch)
# cv3最后一个卷积out_channels是类别的数量
self.cv3 = nn.ModuleList(nn.Sequential(Conv(x, c3, 3), Conv(c3, c3, 3), nn.Conv2d(c3, self.nc, 1)) for x in ch)
self.dfl = DFL(self.reg_max) if self.reg_max > 1 else nn.Identity()
def forward(self, x):
"""Concatenates and returns predicted bounding boxes and class probabilities."""
shape = x[0].shape # BCHW
for i in range(self.nl): # self.nl=3
x[i] = torch.cat((self.cv2[i](x[i]), self.cv3[i](x[i])), 1)
if self.training:
return x
elif self.dynamic or self.shape != shape:
self.anchors, self.strides = (x.transpose(0, 1) for x in make_anchors(x, self.stride, 0.5))
self.shape = shape
x_cat = torch.cat([xi.view(shape[0], self.no, -1) for xi in x], 2)
box, cls = x_cat.split((self.reg_max * 4, self.nc), 1)yolov5 head解码部分代码和对应结构图:


先看一下YOLOv5本身的Head(Coupled-Head):

而YOLOv8则是使用了Decoupled-Head,同时由于使用了DFL 的思想,因此回归头的通道数也变成了4*reg_max的形式:

损失函数

分类回归
这里的分类回归损失函数采用的是VFL。这里的损失其实还是在BCE上面进行的改进,代码如下:
# 分类loss
class VarifocalLoss(nn.Module):
"""
Varifocal loss by Zhang et al.
https://arxiv.org/abs/2008.13367.
"""
def __init__(self):
"""Initialize the VarifocalLoss class."""
super().__init__()
@staticmethod
def forward(pred_score, gt_score, label, alpha=0.75, gamma=2.0):
"""Computes varfocal loss."""
weight = alpha * pred_score.sigmoid().pow(gamma) * (1 - label) + gt_score * label
with torch.cuda.amp.autocast(enabled=False):
loss = (F.binary_cross_entropy_with_logits(pred_score.float(), gt_score.float(), reduction='none') *
weight).mean(1).sum()
return loss位置回归
位置回归采用ciou+dfl,代码如下:
# 位置回归loss
class BboxLoss(nn.Module):
"""Criterion class for computing training losses during training."""
def __init__(self, reg_max, use_dfl=False):
"""Initialize the BboxLoss module with regularization maximum and DFL settings."""
super().__init__()
self.reg_max = reg_max
self.use_dfl = use_dfl
def forward(self, pred_dist, pred_bboxes, anchor_points, target_bboxes, target_scores, target_scores_sum, fg_mask):
"""IoU loss."""
weight = target_scores.sum(-1)[fg_mask].unsqueeze(-1)
iou = bbox_iou(pred_bboxes[fg_mask], target_bboxes[fg_mask], xywh=False, CIoU=True)
loss_iou = ((1.0 - iou) * weight).sum() / target_scores_sum
# DFL loss
if self.use_dfl:
target_ltrb = bbox2dist(anchor_points, target_bboxes, self.reg_max)
loss_dfl = self._df_loss(pred_dist[fg_mask].view(-1, self.reg_max + 1), target_ltrb[fg_mask]) * weight
loss_dfl = loss_dfl.sum() / target_scores_sum
else:
loss_dfl = torch.tensor(0.0).to(pred_dist.device)
return loss_iou, loss_dfl样本的匹配
标签分配是目标检测非常重要的一环,在YOLOv5的早期版本中使用了MaxIOU作为标签分配方法。然而,在实践中发现直接使用边长比也可以达到一阿姨你的效果。而YOLOv8则是抛弃了Anchor-Base方法使用Anchor-Free方法,找到了一个替代边长比例的匹配方法,TaskAligned。
为与NMS搭配,训练样例的Anchor分配需要满足以下两个规则:
正常对齐的Anchor应当可以预测高分类得分,同时具有精确定位;
不对齐的Anchor应当具有低分类得分,并在NMS阶段被抑制。基于上述两个目标,TaskAligned设计了一个新的Anchor alignment metric 来在Anchor level 衡量Task-Alignment的水平。并且,Alignment metric 被集成在了 sample 分配和 loss function里来动态的优化每个 Anchor 的预测。
特征图可视化
MMYOLO 中提供了一套完善的特征图可视化工具,可以帮助用户可视化特征的分布情况。
以 YOLOv8-s 模型为例,第一步需要下载官方权重,然后将该权重通过https://github.com/open-mmlab/mmyolo/blob/dev/tools/model_converters/yolov8_to_mmyolo.py 脚本将去转换到 MMYOLO 中,注意必须要将脚本置于官方仓库下才能正确运行,假设得到的权重名字为 mmyolov8s.pth
假设想可视化 backbone 输出的 3 个特征图效果,则只需要
cd mmyolo # dev 分支
python demo/featmap_vis_demo.py demo/demo.jpg configs/yolov8/yolov8_s_syncbn_fast_8xb16-500e_coco.py mmyolov8s.pth --channel-reductio squeeze_mean
需要特别注意,为了确保特征图和图片叠加显示能对齐效果,需要先将原先的 test_pipeline 替换为如下:
test_pipeline = [
dict(
type='LoadImageFromFile',
file_client_args=_base_.file_client_args),
dict(type='mmdet.Resize', scale=img_scale, keep_ratio=False), # 这里将 LetterResize 修改成 mmdet.Resize
dict(type='LoadAnnotations', with_bbox=True, _scope_='mmdet'),
dict(
type='mmdet.PackDetInputs',
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
'scale_factor'))
]
从上图可以看出不同输出特征图层主要负责预测不同尺度的物体。
我们也可以可视化 Neck 层的 3 个输出层特征图:
cd mmyolo # dev 分支
python demo/featmap_vis_demo.py demo/demo.jpg configs/yolov8/yolov8_s_syncbn_fast_8xb16-500e_coco.py mmyolov8s.pth --channel-reductio squeeze_mean --target-layers neck
从上图可以发现物体处的特征更加聚焦。
魔改技巧
除了常见的调参外,cv君提供几个优质的魔改方法和独家秘方
1、Yolov8独家优化:CoordAttention
CoordAttention 简称CA,已经有点年头了,还是比较高效,是一种注意力机制,在计算机视觉中被广泛应用。它可以捕捉特定位置的空间关系,并在注意力计算中加以利用。与常规的注意力机制不同,CoordAttention在计算注意力时,不仅会考虑输入的特征信息,还会考虑每个像素点的位置信息,从而更好地捕捉空间上的局部关系和全局关系。这种注意力机制可以应用于许多计算机视觉任务,如图像分类、目标检测和语义分割等。


效果较好。
基于Yolov8的CoordAttention实现
加入yolov8 modules.py中
###################### CoordAtt #### start by AI&CV ###############################
import torch
import torch.nn as nn
import torch.nn.functional as F
class h_sigmoid(nn.Module):
def __init__(self, inplace=True):
super(h_sigmoid, self).__init__()
self.relu = nn.ReLU6(inplace=inplace)
def forward(self, x):
return self.relu(x + 3) / 6
class h_swish(nn.Module):
def __init__(self, inplace=True):
super(h_swish, self).__init__()
self.sigmoid = h_sigmoid(inplace=inplace)
def forward(self, x):
return x * self.sigmoid(x)
class CoordAtt(nn.Module):
def __init__(self, inp, reduction=32):
super(CoordAtt, self).__init__()
self.pool_h = nn.AdaptiveAvgPool2d((None, 1))
self.pool_w = nn.AdaptiveAvgPool2d((1, None))
mip = max(8, inp // reduction)
self.conv1 = nn.Conv2d(inp, mip, kernel_size=1, stride=1, padding=0)
self.bn1 = nn.BatchNorm2d(mip)
self.act = h_swish()
self.conv_h = nn.Conv2d(mip, inp, kernel_size=1, stride=1, padding=0)
self.conv_w = nn.Conv2d(mip, inp, kernel_size=1, stride=1, padding=0)
def forward(self, x):
identity = x
n, c, h, w = x.size()
x_h = self.pool_h(x)
x_w = self.pool_w(x).permute(0, 1, 3, 2)
y = torch.cat([x_h, x_w], dim=2)
y = self.conv1(y)
y = self.bn1(y)
y = self.act(y)
x_h, x_w = torch.split(y, [h, w], dim=2)
x_w = x_w.permute(0, 1, 3, 2)
a_h = self.conv_h(x_h).sigmoid()
a_w = self.conv_w(x_w).sigmoid()
out = identity * a_w * a_h
return out
###################### CoordAtt #### end by AI&CV ###############################2.2 yolov8_coordAtt.yaml
# Ultralytics YOLO , GPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 4 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 3, CoordAtt, [256]]
- [-1, 1, Conv, [512, 3, 2]] # 6-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 3, CoordAtt, [512]]
- [-1, 1, Conv, [1024, 3, 2]] # 9-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 3, CoordAtt, [1024]]
- [-1, 1, SPPF, [1024, 5]] # 12
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 7], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 15
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 18 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 15], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 21 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 24 (P5/32-large)
- [[18, 21, 24], 1, Detect, [nc]] # Detect(P3, P4, P5)
V8没有modules.py了 自己新建一个,然后在tasks.py进行定义注册使用
2、Yolov8独家优化:DoubleAttention
双重注意力网络(Double Attention Networks)是一种用于计算机视觉任务的神经网络架构,旨在有效地捕获图像中的全局和局部信息,以提高任务的性能。它是建立在注意力机制的基础上的,通过两个注意力模块来分别关注全局和局部信息。以下是关于Double Attention Networks的详细解释
注意力机制: 注意力机制是一种模仿人类视觉系统的方法,它允许神经网络在处理输入数据时集中注意力在最相关的部分上。在计算机视觉中,这意味着网络可以动态地选择关注图像的不同部分,从而提高任务的性能。
双重注意力: 双重注意力网络引入了两个注意力模块,分别用于全局和局部信息。这两个模块分别关注图像的整体结构和局部细节,从而充分利用了图像中的各种信息。
全局注意力模块: 全局注意力模块负责捕获图像中的全局信息。它通常采用全局池化(global pooling)操作,将整个特征图进行压缩,然后通过一系列的神经网络层来学习全局上下文信息。这个模块能够帮助网络理解图像的整体语义结构。
局注意力模块: 局部注意力模块专注于捕获图像中的局部信息。它通常采用一种局部感知机制(local perception),通过对图像进行分块或者使用卷积操作来提取局部特征,并且通过注意力机制来选择最相关的局部信息。这个模块有助于网络在处理具有局部结构的图像时更加准确。
特征融合: 在双重注意力网络中,全局和局部注意力模块学习到的特征需要被合并起来以供最终任务使用。这通常通过简单地将两个模块的输出进行融合,例如连接或者加权求和操作。这种特征融合使得网络能够综合利用全局和局部信息来完成任务。
通过以上的双重注意力网络架构,神经网络可以更有效地利用图像中的全局和局部信息,从而在各种计算机视觉任务中取得更好的性能。
将DoubleAttention添加到YOLOv8中
关键步骤一:将下面代码粘贴到在/ultralytics/ultralytics/nn/modules/conv.py中,并在该文件的all中添加“DoubleAttentionLayer”
from torch import nn
import torch
from torch.autograd import Variable
import torch.nn.functional as F
class DoubleAttentionLayer(nn.Module):
"""
Implementation of Double Attention Network. NIPS 2018
"""
def __init__(self, in_channels: int, c_m: int, c_n: int, reconstruct=False):
"""
Parameters
----------
in_channels
c_m
c_n
reconstruct: `bool` whether to re-construct output to have shape (B, in_channels, L, R)
"""
super(DoubleAttentionLayer, self).__init__()
self.c_m = c_m
self.c_n = c_n
self.in_channels = in_channels
self.reconstruct = reconstruct
self.convA = nn.Conv2d(in_channels, c_m, kernel_size=1)
self.convB = nn.Conv2d(in_channels, c_n, kernel_size=1)
self.convV = nn.Conv2d(in_channels, c_n, kernel_size=1)
if self.reconstruct:
self.conv_reconstruct = nn.Conv2d(c_m, in_channels, kernel_size=1)
def forward(self, x: torch.Tensor):
"""
Parameters
----------
x: `torch.Tensor` of shape (B, C, H, W)
Returns
-------
"""
batch_size, c, h, w = x.size()
assert c == self.in_channels, 'input channel not equal!'
A = self.convA(x) # (B, c_m, h, w) because kernel size is 1
B = self.convB(x) # (B, c_n, h, w)
V = self.convV(x) # (B, c_n, h, w)
tmpA = A.view(batch_size, self.c_m, h * w)
attention_maps = B.view(batch_size, self.c_n, h * w)
attention_vectors = V.view(batch_size, self.c_n, h * w)双重注意力网络的主要过程涉及以下几个关键步骤:
输入图像的特征提取: 首先,输入的图像经过一个预训练的卷积神经网络(CNN)模型,例如ResNet、VGG等,以提取图像的特征。这些特征通常是一个高维度的张量,表示了图像在不同层次上的抽象特征信息。
全局注意力模块: 对于提取的图像特征,首先通过全局注意力模块进行处理。这个模块通常包括以下几个步骤:
使用全局池化操作(如全局平均池化)将特征图进行降维,得到全局上下文信息。
将降维后的全局特征通过一个全连接网络(FCN)进行处理,以学习全局信息的表示。
使用激活函数(如ReLU)来增加网络的非线性表示能力。
局部注意力模块: 接下来,提取的特征经过局部注意力模块的处理。这个模块主要负责捕获图像中的局部信息,并结合全局信息进行处理。其主要步骤包括:
将特征图分成不同的区域或者使用卷积操作来提取局部特征。
对每个局部特征使用注意力机制,计算其与全局信息的相关程度,以得到局部的重要性权重。
使用得到的权重对局部特征进行加权合并,以得到最终的局部表示。
更改init.py文件
关键步骤二:修改modules文件夹下的__init__.py文件,先导入函数
然后在下面的__all__中声明函数
在task.py中进行注册
关键步骤三:在parse_model函数中进行注册,添加DoubleAttentionLayer,
添加yaml文件
关键步骤四:在/ultralytics/ultralytics/cfg/models/v8下面新建文件yolov8_DANet.yaml文件,粘贴下面的内容
# Ultralytics YOLO , AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see Detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, DoubleAttentionLayer, [128,1]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 15 (P3/8-small)温馨提示:因为本文只是对yolov8n基础上添加模块,如果要对yolov8n/l/m/x进行添加则只需要指定对应的depth_multiple 和 width_multiple。或者指定某个模型即可
# YOLOv8n
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple
# YOLOv8s
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
# YOLOv8l
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
# YOLOv8m
depth_multiple: 0.67 # model depth multiple
width_multiple: 0.75 # layer channel multiple
# YOLOv8x
depth_multiple: 1.33 # model depth multiple
width_multiple: 1.25 # layer channel multiple2.5 执行程序
关键步骤五:在ultralytics文件中新建train.py,将model的参数路径设置为yolov8_DANet.yaml的路径即可
from ultralytics import YOLO
# Load a model
# model = YOLO('yolov8n.yaml') # build a new model from YAML
# model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
model = YOLO(r'/projects/ultralytics/ultralytics/cfg/models/v8/yolov8_DANet.yaml') # build from YAML and transfer weights
# Train the model
model.train(device = [3], batch=16)建议大家写绝对路径,确保一定能找到
运行程序,如果出现下面的内容则说明添加成功
双重注意力网络是一种用于计算机视觉任务的神经网络架构,旨在通过注意力机制有效地捕获图像中的全局和局部信息,从而提高任务性能。该网络引入了两个关键的注意力模块,分别用于全局和局部信息的关注,全局模块通过全局池化操作学习图像的整体语义结构,而局部模块则专注于提取图像的局部特征并通过局部感知机制选择最相关的信息。这两个模块学习到的特征最终被融合起来以供任务使用,通常通过连接或加权求和的方式进行特征融合。双重注意力网络通过端到端的训练和优化,使用适当的损失函数和正则化技术来提高模型的泛化能力和训练稳定性。这种架构使得神经网络能够更全面地利用图像中的全局和局部信息,从而在各种计算机视觉任务中取得更好的性能表现。
3、Yolov8独家优化:EMA
本文提出了一种新的跨空间学习方法,并设计了一个多尺度并行子网络来建立短和长依赖关系。小目标涨点明显

EMA加入yolov8
论文地址:https://arxiv.org/abs/2305.13563v1
模型讲解和代码实现,即插即用提升性能
概述
通过通道降维来建模跨通道关系可能会给提取深度视觉带来副作用。因此提出了一种新的高效的多尺度注意力(EMA)模块。以保留每个通道上的信息和降低计算开销为目标,将部分通道重塑为批量维度,并将通道维度分组为多个子特征,使空间语义特征在每个特征组中均匀分布。
左图为CA注意力机制模型图,右图为EMA注意力机制模型图
模型优点
(1) 我们考虑一种通用方法,将部分通道维度重塑为批量维度,以避免通过通用卷积进行某种形式的降维。
(2) 除了在不进行通道降维的情况下在每个并行子网络中构建局部的跨通道交互外,我们还通过跨空间学习方法融合两个并行子网络的输出特征图。
(3) 与CBAM、NAM[16]、SA、ECA和CA相比,EMA不仅取得了更好的结果,而且在所需参数方面效率更高。
代码实现
在ultralytics-8.2.0\ultralytics\nn\文件夹下新建attention.py
import torch
from torch import nn
class EMA(nn.Module):
def __init__(self, channels, c2=None, factor=32):
super(EMA, self).__init__()
self.groups = factor
assert channels // self.groups > 0
self.softmax = nn.Softmax(-1)
self.agp = nn.AdaptiveAvgPool2d((1, 1))
self.pool_h = nn.AdaptiveAvgPool2d((None, 1))
self.pool_w = nn.AdaptiveAvgPool2d((1, None))
self.gn = nn.GroupNorm(channels // self.groups, channels // self.groups)
self.conv1x1 = nn.Conv2d(channels // self.groups, channels // self.groups, kernel_size=1, stride=1, padding=0)
self.conv3x3 = nn.Conv2d(channels // self.groups, channels // self.groups, kernel_size=3, stride=1, padding=1)
def forward(self, x):
b, c, h, w = x.size()
group_x = x.reshape(b * self.groups, -1, h, w) # b*g,c//g,h,w
x_h = self.pool_h(group_x)
x_w = self.pool_w(group_x).permute(0, 1, 3, 2)
hw = self.conv1x1(torch.cat([x_h, x_w], dim=2))
x_h, x_w = torch.split(hw, [h, w], dim=2)
x1 = self.gn(group_x * x_h.sigmoid() * x_w.permute(0, 1, 3, 2).sigmoid())
x2 = self.conv3x3(group_x)
x11 = self.softmax(self.agp(x1).reshape(b * self.groups, -1, 1).permute(0, 2, 1))
x12 = x2.reshape(b * self.groups, c // self.groups, -1) # b*g, c//g, hw
x21 = self.softmax(self.agp(x2).reshape(b * self.groups, -1, 1).permute(0, 2, 1))
x22 = x1.reshape(b * self.groups, c // self.groups, -1) # b*g, c//g, hw
weights = (torch.matmul(x11, x12) + torch.matmul(x21, x22)).reshape(b * self.groups, 1, h, w)
return (group_x * weights.sigmoid()).reshape(b, c, h, w)
在ultralytics-8.2.0\ultralytics\nn\tasks.py文件的parse_model()函数中添加如下代码
在ultralytics-8.2.0\ultralytics\cfg\models\v8目录下新建yolov8_EMA.yaml,代码如下
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
# n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
# s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
# l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
# x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 12
- [-1, 1, EMA, [8]] #13
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 15 (P3/8-small)
- [-1, 1, EMA, [8]] #16
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 13], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 19 (P4/16-medium)
- [-1, 1, EMA, [8]] # 20
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 23 (P5/32-large)
- [-1, 1, EMA, [8]] #24
- [[17, 21, 25], 1, Detect, [nc]] # Detect(P3, P4, P5)
在主目录下新建main.py文件
我使用yolov8的yolov8m加载权重,main.py代码如下
from ultralytics import YOLO
def train_model():
model = YOLO("yolov8_EMA.yaml").load('yolov8m.pt')
model.train(data="rail_defects.yaml", epochs=300)
if __name__ == '__main__':
train_model()
运行结果
from n params module arguments
0 -1 1 1392 ultralytics.nn.modules.conv.Conv [3, 48, 3, 2]
1 -1 1 41664 ultralytics.nn.modules.conv.Conv [48, 96, 3, 2]
2 -1 2 111360 ultralytics.nn.modules.block.C2f [96, 96, 2, True]
3 -1 1 166272 ultralytics.nn.modules.conv.Conv [96, 192, 3, 2]
4 -1 4 813312 ultralytics.nn.modules.block.C2f [192, 192, 4, True]
5 -1 1 664320 ultralytics.nn.modules.conv.Conv [192, 384, 3, 2]
6 -1 4 3248640 ultralytics.nn.modules.block.C2f [384, 384, 4, True]
7 -1 1 1991808 ultralytics.nn.modules.conv.Conv [384, 576, 3, 2]
8 -1 2 3985920 ultralytics.nn.modules.block.C2f [576, 576, 2, True]
9 -1 1 831168 ultralytics.nn.modules.block.SPPF [576, 576, 5]
10 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
11 [-1, 6] 1 0 ultralytics.nn.modules.conv.Concat [1]
12 -1 2 1993728 ultralytics.nn.modules.block.C2f [960, 384, 2]
13 -1 1 1488 ultralytics.nn.attention.EMA [384, 8]
14 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
15 [-1, 4] 1 0 ultralytics.nn.modules.conv.Concat [1]
16 -1 2 517632 ultralytics.nn.modules.block.C2f [576, 192, 2]
17 -1 1 384 ultralytics.nn.attention.EMA [192, 8]
18 -1 1 332160 ultralytics.nn.modules.conv.Conv [192, 192, 3, 2]
19 [-1, 13] 1 0 ultralytics.nn.modules.conv.Concat [1]
20 -1 2 1846272 ultralytics.nn.modules.block.C2f [576, 384, 2]
21 -1 1 1488 ultralytics.nn.attention.EMA [384, 8]
22 -1 1 1327872 ultralytics.nn.modules.conv.Conv [384, 384, 3, 2]
23 [-1, 9] 1 0 ultralytics.nn.modules.conv.Concat [1]
24 -1 2 4207104 ultralytics.nn.modules.block.C2f [960, 576, 2]
25 -1 1 3312 ultralytics.nn.attention.EMA [576, 8]
26 [17, 21, 25] 1 3776854 ultralytics.nn.modules.head.Detect [2, [192, 384, 576]]
YOLOv8_EMA summary: 327 layers, 25864150 parameters, 25864134 gradients, 79.6 GFLOPs4、Yolov8独家优化+transformer改进: BiFormer
背景:注意力机制是Vision Transformer的核心构建模块之一,可以捕捉长程依赖关系。然而,由于需要计算所有空间位置之间的成对令牌交互,这种强大的功能会带来巨大的计算负担和内存开销。为了减轻这个问题,一系列工作尝试通过引入手工制作和内容无关的稀疏性到关注力中来解决这个问题,如限制关注操作在局部窗口、轴向条纹或扩张窗口内。
本文方法:本文提出一种动态稀疏注意力的双层路由方法。对于一个查询,首先在粗略的区域级别上过滤掉不相关的键值对,然后在剩余候选区域(即路由区域)的并集中应用细粒度的令牌对令牌关注力。所提出的双层路由注意力具有简单而有效的实现方式,利用稀疏性来节省计算和内存,只涉及GPU友好的密集矩阵乘法。在此基础上构建了一种新的通用Vision Transformer,称为BiFormer。
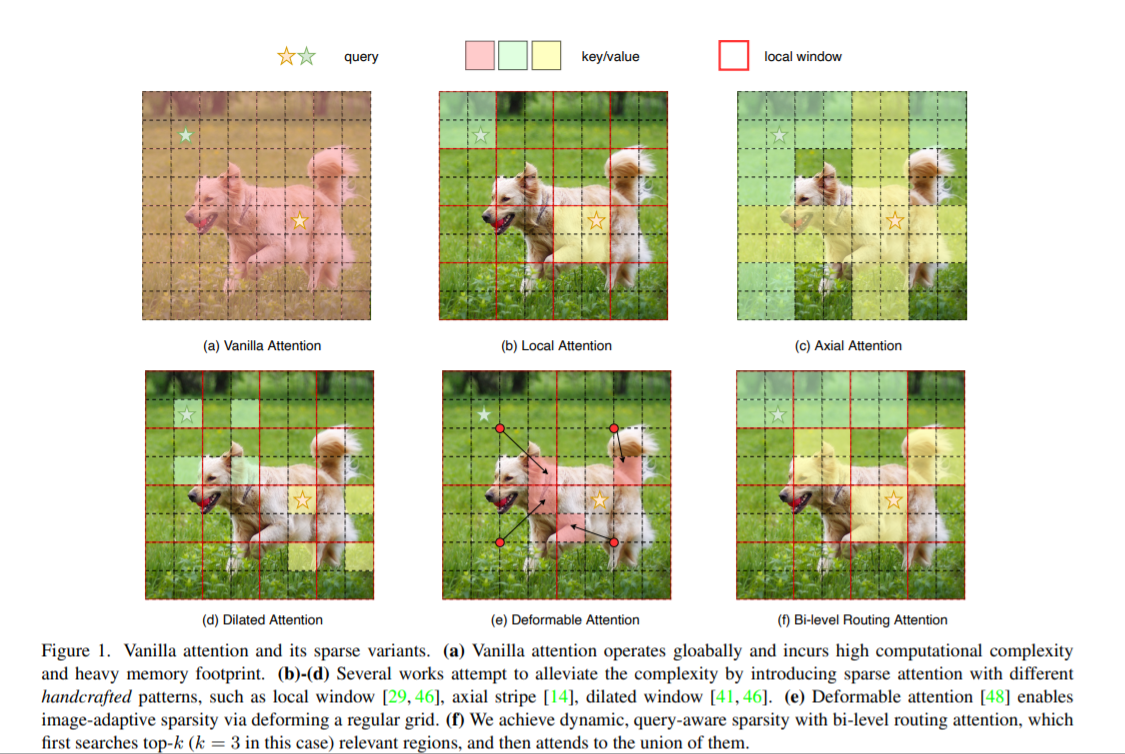
其中图(a)是原始的注意力实现,其直接在全局范围内操作,导致高计算复杂性和大量内存占用;而对于图(b)-(d),这些方法通过引入具有不同手工模式的稀疏注意力来减轻复杂性,例如局部窗口、轴向条纹和扩张窗口等;而图(e)则是基于可变形注意力通过不规则网格来实现图像自适应稀疏性;作者认为以上这些方法大都是通过将 手工制作 和 与内容无关 的稀疏性引入到注意力机制来试图缓解这个问题。因此,本文通过双层路由(bi-level routing)提出了一种新颖的动态稀疏注意力(dynamic sparse attention ),以实现更灵活的计算分配和内容感知,使其具备动态的查询感知稀疏性,如图(f)所示。
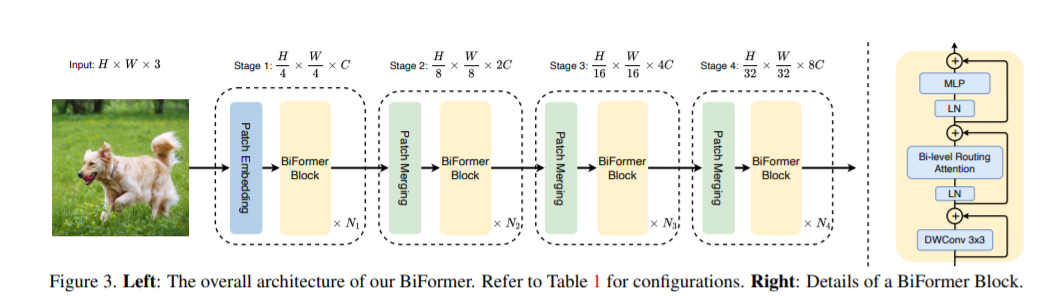
基于BRA模块,本文构建了一种新颖的通用视觉转换器BiFormer。如上图所示,其遵循大多数的vision transformer架构设计,也是采用四级金字塔结构,即下采样32倍。
具体来说,BiFormer在第一阶段使用重叠块嵌入,在第二到第四阶段使用块合并模块来降低输入空间分辨率,同时增加通道数,然后是采用连续的BiFormer块做特征变换。需要注意的是,在每个块的开始均是使用 的深度卷积来隐式编码相对位置信息。随后依次应用BRA模块和扩展率为 的 2 层 多层感知机(Multi-Layer Perceptron, MLP)模块,分别用于交叉位置关系建模和每个位置嵌

本文方法对小目标检测效果比较好。可能是因为BRA模块是基于稀疏采样而不是下采样,一来可以保留细粒度的细节信息,二来同样可以达到节省计算量的目的。
C2f_BiLevelRoutingAttention、C3_BiLevelRoutingAttention、BiFormer加入modules.py中
class BiLevelRoutingAttention(nn.Module):
"""
n_win: number of windows in one side (so the actual number of windows is n_win*n_win)
kv_per_win: for kv_downsample_mode='ada_xxxpool' only, number of key/values per window. Similar to n_win, the actual number is kv_per_win*kv_per_win.
topk: topk for window filtering
param_attention: 'qkvo'-linear for q,k,v and o, 'none': param free attention
param_routing: extra linear for routing
diff_routing: wether to set routing differentiable
soft_routing: wether to multiply soft routing weights
"""
def __init__(self, dim, num_heads=8, n_win=7, qk_dim=None, qk_scale=None,
kv_per_win=4, kv_downsample_ratio=4, kv_downsample_kernel='ada_avgpool', kv_downsample_mode='identity',
topk=4, param_attention="qkv", param_routing=False, diff_routing=False, soft_routing=False,
side_dwconv=5,
auto_pad=True):
super().__init__()
# local attention setting
self.dim = dim
self.n_win = n_win # Wh, Ww
self.num_heads = num_heads
self.qk_dim = qk_dim or dim
assert self.qk_dim % num_heads == 0 and self.dim % num_heads == 0, 'qk_dim and dim must be divisible by num_heads!'
self.scale = qk_scale or self.qk_dim ** -0.5
################side_dwconv (i.e. LCE in ShuntedTransformer)###########
self.lepe = nn.Conv2d(dim, dim, kernel_size=side_dwconv, stride=1, padding=side_dwconv // 2,
groups=dim) if side_dwconv > 0 else \
lambda x: torch.zeros_like(x)
################ global routing setting #################
self.topk = topk
self.param_routing = param_routing
self.diff_routing = diff_routing
self.soft_routing = soft_routing
# router
assert not (self.param_routing and not self.diff_routing) # cannot be with_param=True and diff_routing=False
self.router = TopkRouting(qk_dim=self.qk_dim,
qk_scale=self.scale,
topk=self.topk,
diff_routing=self.diff_routing,
param_routing=self.param_routing)
if self.soft_routing: # soft routing, always diffrentiable (if no detach)
mul_weight = 'soft'
elif self.diff_routing: # hard differentiable routing
mul_weight = 'hard'
else: # hard non-differentiable routing
mul_weight = 'none'
self.kv_gather = KVGather(mul_weight=mul_weight)
# qkv mapping (shared by both global routing and local attention)
self.param_attention = param_attention
if self.param_attention == 'qkvo':
self.qkv = QKVLinear(self.dim, self.qk_dim)
self.wo = nn.Linear(dim, dim)
elif self.param_attention == 'qkv':
self.qkv = QKVLinear(self.dim, self.qk_dim)
self.wo = nn.Identity()
else:
raise ValueError(f'param_attention mode {self.param_attention} is not surpported!')
self.kv_downsample_mode = kv_downsample_mode
self.kv_per_win = kv_per_win
self.kv_downsample_ratio = kv_downsample_ratio
self.kv_downsample_kenel = kv_downsample_kernel
if self.kv_downsample_mode == 'ada_avgpool':
assert self.kv_per_win is not None
self.kv_down = nn.AdaptiveAvgPool2d(self.kv_per_win)
elif self.kv_downsample_mode == 'ada_maxpool':
assert self.kv_per_win is not None
self.kv_down = nn.AdaptiveMaxPool2d(self.kv_per_win)
elif self.kv_downsample_mode == 'maxpool':
assert self.kv_downsample_ratio is not None
self.kv_down = nn.MaxPool2d(self.kv_downsample_ratio) if self.kv_downsample_ratio > 1 else nn.Identity()
elif self.kv_downsample_mode == 'avgpool':
assert self.kv_downsample_ratio is not None
self.kv_down = nn.AvgPool2d(self.kv_downsample_ratio) if self.kv_downsample_ratio > 1 else nn.Identity()
elif self.kv_downsample_mode == 'identity': # no kv downsampling
self.kv_down = nn.Identity()
elif self.kv_downsample_mode == 'fracpool':
# assert self.kv_downsample_ratio is not None
# assert self.kv_downsample_kenel is not None
# TODO: fracpool
# 1. kernel size should be input size dependent
# 2. there is a random factor, need to avoid independent sampling for k and v
raise NotImplementedError('fracpool policy is not implemented yet!')
elif kv_downsample_mode == 'conv':
# TODO: need to consider the case where k != v so that need two downsample modules
raise NotImplementedError('conv policy is not implemented yet!')
else:
raise ValueError(f'kv_down_sample_mode {self.kv_downsaple_mode} is not surpported!')
# softmax for local attention
self.attn_act = nn.Softmax(dim=-1)
self.auto_pad = auto_pad
def forward(self, x, ret_attn_mask=False):
"""
x: NHWC tensor
Return:
NHWC tensor
"""
# NOTE: use padding for semantic segmentation
###################################################
if self.auto_pad:
N, H_in, W_in, C = x.size()
pad_l = pad_t = 0
pad_r = (self.n_win - W_in % self.n_win) % self.n_win
pad_b = (self.n_win - H_in % self.n_win) % self.n_win
x = F.pad(x, (0, 0, # dim=-1
pad_l, pad_r, # dim=-2
pad_t, pad_b)) # dim=-3
_, H, W, _ = x.size() # padded size
else:
N, H, W, C = x.size()
#print(N)
# print(H)
# print(W)
# print(self.n_win)
assert H % self.n_win == 0 and W % self.n_win == 0 #
###################################################
# patchify, (n, p^2, w, w, c), keep 2d window as we need 2d pooling to reduce kv size
x = rearrange(x, "n (j h) (i w) c -> n (j i) h w c", j=self.n_win, i=self.n_win)
#################qkv projection###################
# q: (n, p^2, w, w, c_qk)
# kv: (n, p^2, w, w, c_qk+c_v)
# NOTE: separte kv if there were memory leak issue caused by gather
q, kv = self.qkv(x)
# pixel-wise qkv
# q_pix: (n, p^2, w^2, c_qk)
# kv_pix: (n, p^2, h_kv*w_kv, c_qk+c_v)
q_pix = rearrange(q, 'n p2 h w c -> n p2 (h w) c')
kv_pix = self.kv_down(rearrange(kv, 'n p2 h w c -> (n p2) c h w'))
kv_pix = rearrange(kv_pix, '(n j i) c h w -> n (j i) (h w) c', j=self.n_win, i=self.n_win)
q_win, k_win = q.mean([2, 3]), kv[..., 0:self.qk_dim].mean(
[2, 3]) # window-wise qk, (n, p^2, c_qk), (n, p^2, c_qk)
##################side_dwconv(lepe)##################
# NOTE: call contiguous to avoid gradient warning when using ddp
lepe = self.lepe(rearrange(kv[..., self.qk_dim:], 'n (j i) h w c -> n c (j h) (i w)', j=self.n_win,
i=self.n_win).contiguous())
lepe = rearrange(lepe, 'n c (j h) (i w) -> n (j h) (i w) c', j=self.n_win, i=self.n_win)
############ gather q dependent k/v #################
r_weight, r_idx = self.router(q_win, k_win) # both are (n, p^2, topk) tensors
kv_pix_sel = self.kv_gather(r_idx=r_idx, r_weight=r_weight, kv=kv_pix) # (n, p^2, topk, h_kv*w_kv, c_qk+c_v)
k_pix_sel, v_pix_sel = kv_pix_sel.split([self.qk_dim, self.dim], dim=-1)
# kv_pix_sel: (n, p^2, topk, h_kv*w_kv, c_qk)
# v_pix_sel: (n, p^2, topk, h_kv*w_kv, c_v)
######### do attention as normal ####################
k_pix_sel = rearrange(k_pix_sel, 'n p2 k w2 (m c) -> (n p2) m c (k w2)',
m=self.num_heads) # flatten to BMLC, (n*p^2, m, topk*h_kv*w_kv, c_kq//m) transpose here?
v_pix_sel = rearrange(v_pix_sel, 'n p2 k w2 (m c) -> (n p2) m (k w2) c',
m=self.num_heads) # flatten to BMLC, (n*p^2, m, topk*h_kv*w_kv, c_v//m)
q_pix = rearrange(q_pix, 'n p2 w2 (m c) -> (n p2) m w2 c',
m=self.num_heads) # to BMLC tensor (n*p^2, m, w^2, c_qk//m)
# param-free multihead attention
attn_weight = (
q_pix * self.scale) @ k_pix_sel # (n*p^2, m, w^2, c) @ (n*p^2, m, c, topk*h_kv*w_kv) -> (n*p^2, m, w^2, topk*h_kv*w_kv)
attn_weight = self.attn_act(attn_weight)
out = attn_weight @ v_pix_sel # (n*p^2, m, w^2, topk*h_kv*w_kv) @ (n*p^2, m, topk*h_kv*w_kv, c) -> (n*p^2, m, w^2, c)
out = rearrange(out, '(n j i) m (h w) c -> n (j h) (i w) (m c)', j=self.n_win, i=self.n_win,
h=H // self.n_win, w=W // self.n_win)
out = out + lepe
# output linear
out = self.wo(out)
# NOTE: use padding for semantic segmentation
# crop padded region
if self.auto_pad and (pad_r > 0 or pad_b > 0):
out = out[:, :H_in, :W_in, :].contiguous()
if ret_attn_mask:
return out, r_weight, r_idx, attn_weight
else:
return outyolov8_C2f_BiLevelRoutingAttention.yaml
# Ultralytics YOLO , GPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 1 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f_BiLevelRoutingAttention, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f_BiLevelRoutingAttention, [256]] # 15 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f_BiLevelRoutingAttention, [512]] # 18 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f_BiLevelRoutingAttention, [1024]] # 21 (P5/32-large)
- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)5、Yolov8独家优化:MobileNetV4
创新点:轻量化之王MobileNetV4 开源 | Top-1 精度 87%,手机推理速度 3.8ms,原地起飞!
MobileNetV4(MNv4),其特点是针对移动设备设计的通用高效架构。创新1):引入了通用倒瓶颈(UIB)搜索块,这是一个统一且灵活的结构,它融合了倒瓶颈(IB)、ConvNext、前馈网络(FFN)以及一种新颖的额外深度可分(ExtraDW)变体;创新2):一种优化的神经结构搜索(NAS)配方,提高了MNv4的搜索效率;创新3):为了进一步提升准确度,引入了一种新颖的蒸馏技术。

如何跟YOLOv8结合:替代YOLOv8的backbone
1.原理介绍

论文: https://arxiv.org/pdf/2404.10518
摘要:我们介绍了最新一代的mobilenet,被称为MobileNetV4 (MNv4),具有普遍有效的移动设备架构设计。在其核心,我们引入了通用倒瓶颈(UIB)搜索块,这是一个统一而灵活的结构,它融合了倒瓶颈(IB), ConvNext,前馈网络(FFN)和一个新的Extra depth(引渡)变体。除了UIB之外,我们还推出了Mobile MQA,这是一款专为移动加速器量身定制的注意力块,可显著提高39%的速度。介绍了一种优化的神经结构搜索(NAS)配方,提高了MNv4的搜索效率。UIB, Mobile MQA和精致的NAS配方的集成产生了一套新的MNv4模型,这些模型在移动cpu, dsp, gpu以及专用加速器(如Apple Neural Engine和Google Pixel EdgeTPU)上大多是最优的,这是任何其他模型测试中没有发现的特征。最后,为了进一步提高精度,我们介绍了一种新的蒸馏技术。通过这种技术的增强,我们的MNv4-Hybrid-Large模型提供了87%的ImageNet-1K精度,Pixel 8 EdgeTPU运行时间仅为3.8ms。
2. mobilenetv4加入YOLOv8
核心代码
class InvertedResidual(nn.Module):
def __init__(self, inp, oup, stride, expand_ratio, act=False):
super(InvertedResidual, self).__init__()
self.stride = stride
assert stride in [1, 2]
hidden_dim = int(round(inp * expand_ratio))
self.block = nn.Sequential()
if expand_ratio != 1:
self.block.add_module('exp_1x1', conv_2d(inp, hidden_dim, kernel_size=1, stride=1))
self.block.add_module('conv_3x3', conv_2d(hidden_dim, hidden_dim, kernel_size=3, stride=stride, groups=hidden_dim))
self.block.add_module('red_1x1', conv_2d(hidden_dim, oup, kernel_size=1, stride=1, act=act))
self.use_res_connect = self.stride == 1 and inp == oup
def forward(self, x):
if self.use_res_connect:
return x + self.block(x)
else:
return self.block(x)
class UniversalInvertedBottleneckBlock(nn.Module):
def __init__(self,
inp,
oup,
start_dw_kernel_size,
middle_dw_kernel_size,
middle_dw_downsample,
stride,
expand_ratio
):
super().__init__()
# Starting depthwise conv.
self.start_dw_kernel_size = start_dw_kernel_size
if self.start_dw_kernel_size:
stride_ = stride if not middle_dw_downsample else 1
self._start_dw_ = conv_2d(inp, inp, kernel_size=start_dw_kernel_size, stride=stride_, groups=inp, act=False)
# Expansion with 1x1 convs.
expand_filters = make_divisible(inp * expand_ratio, 8)
self._expand_conv = conv_2d(inp, expand_filters, kernel_size=1)
# Middle depthwise conv.
self.middle_dw_kernel_size = middle_dw_kernel_size
if self.middle_dw_kernel_size:
stride_ = stride if middle_dw_downsample else 1
self._middle_dw = conv_2d(expand_filters, expand_filters, kernel_size=middle_dw_kernel_size, stride=stride_, groups=expand_filters)
# Projection with 1x1 convs.
self._proj_conv = conv_2d(expand_filters, oup, kernel_size=1, stride=1, act=False)
# Ending depthwise conv.
# this not used
# _end_dw_kernel_size = 0
# self._end_dw = conv_2d(oup, oup, kernel_size=_end_dw_kernel_size, stride=stride, groups=inp, act=False)
def forward(self, x):
if self.start_dw_kernel_size:
x = self._start_dw_(x)
# print("_start_dw_", x.shape)
x = self._expand_conv(x)
# print("_expand_conv", x.shape)
if self.middle_dw_kernel_size:
x = self._middle_dw(x)
# print("_middle_dw", x.shape)
x = self._proj_conv(x)
# print("_proj_conv", x.shape)
return x
2.1 yolov8-mobilenetv4.yaml
# Ultralytics YOLO , AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# 0-P1/2
# 1-P2/4
# 2-P3/8
# 3-P4/16
# 4-P5/32
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, MobileNetV4ConvSmall, []] # 4
- [-1, 1, SPPF, [1024, 5]] # 5
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']] # 6
- [[-1, 3], 1, Concat, [1]] # 7 cat backbone P4
- [-1, 3, C2f, [512]] # 8
- [-1, 1, nn.Upsample, [None, 2, 'nearest']] # 9
- [[-1, 2], 1, Concat, [1]] # 10 cat backbone P3
- [-1, 3, C2f, [256]] # 11 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]] # 12
- [[-1, 8], 1, Concat, [1]] # 13 cat head P4
- [-1, 3, C2f, [512]] # 14 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]] # 15
- [[-1, 5], 1, Concat, [1]] # 16 cat head P5
- [-1, 3, C2f, [1024]] # 17 (P5/32-large)
- [[11, 14, 17], 1, Detect, [nc]] # Detect(P3, P4, P5)
6、Yolov8独家优化:Starnet
创新点:star operation(元素乘法)在无需加宽网络下,将输入映射到高维非线性特征空间的能力,这就是StarNet的核心创新,在紧凑的网络结构和较低的能耗下展示了令人印象深刻的性能和低延迟

如何跟YOLOv8结合:替代YOLOv8的backbone
1.原理介绍

论文:https://arxiv.org/pdf/2403.19967
摘要:最近的研究引起了人们对网络设计中尚未开发的“星型操作”(元素智能乘法)潜力的关注。虽然有很多直观的解释,但其应用背后的基本原理在很大程度上仍未被探索。我们的研究试图将输入映射到高维、非线性特征空间的能力——类似于核技巧——无需扩大网络。我们进一步介绍了StarNet,一个简单而强大的原型,在紧凑的网络结构和高效的预算下展示了令人印象深刻的性能和低延迟。就像天上的星星一样,星星的运作看起来不起眼,但却蕴藏着巨大的潜力。
为了便于说明,构建了一个用于图像分类的demo block,如图 1 左侧所示。通过在stem层后堆叠多个demo block,论文构建了一个名为DemoNet的简单模型。保持所有其他因素不变,论文观察到逐元素乘法(star operation)在性能上始终优于求和,如图 1 右侧所示。

通过元素乘法融合不同的子空间特征的学习范式越来越受到关注,论文将这种范例称为star operation(由于元素乘法符号类似于星形)。

2. starnet加入YOLOv8
2.1 新建ultralytics/nn/backbone/starnet.py
核心代码
"""
Implementation of Prof-of-Concept Network: StarNet.
We make StarNet as simple as possible [to show the key contribution of element-wise multiplication]:
- like NO layer-scale in network design,
- and NO EMA during training,
- which would improve the performance further.
Created by: Xu Ma (Email: ma.xu1@northeastern.edu)
Modified Date: Mar/29/2024
"""
import torch
import torch.nn as nn
from timm.models.layers import DropPath, trunc_normal_
from timm.models.registry import register_model
from ultralytics.nn.modules import (Conv, Bottleneck,C2f)
model_urls = {
"starnet_s1": "https://github.com/ma-xu/Rewrite-the-Stars/releases/download/checkpoints_v1/starnet_s1.pth.tar",
"starnet_s2": "https://github.com/ma-xu/Rewrite-the-Stars/releases/download/checkpoints_v1/starnet_s2.pth.tar",
"starnet_s3": "https://github.com/ma-xu/Rewrite-the-Stars/releases/download/checkpoints_v1/starnet_s3.pth.tar",
"starnet_s4": "https://github.com/ma-xu/Rewrite-the-Stars/releases/download/checkpoints_v1/starnet_s4.pth.tar",
}
class ConvBN(torch.nn.Sequential):
def __init__(self, in_planes, out_planes, kernel_size=1, stride=1, padding=0, dilation=1, groups=1, with_bn=True):
super().__init__()
self.add_module('conv', torch.nn.Conv2d(in_planes, out_planes, kernel_size, stride, padding, dilation, groups))
if with_bn:
self.add_module('bn', torch.nn.BatchNorm2d(out_planes))
torch.nn.init.constant_(self.bn.weight, 1)
torch.nn.init.constant_(self.bn.bias, 0)
class StarNetBlock(nn.Module):
def __init__(self, dim, mlp_ratio=3, drop_path=0.):
super().__init__()
self.dwconv = ConvBN(dim, dim, 7, 1, (7 - 1) // 2, groups=dim, with_bn=True)
self.f1 = ConvBN(dim, mlp_ratio * dim, 1, with_bn=False)
self.f2 = ConvBN(dim, mlp_ratio * dim, 1, with_bn=False)
self.g = ConvBN(mlp_ratio * dim, dim, 1, with_bn=True)
self.dwconv2 = ConvBN(dim, dim, 7, 1, (7 - 1) // 2, groups=dim, with_bn=False)
self.act = nn.ReLU6()
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
def forward(self, x):
input = x
x = self.dwconv(x)
x1, x2 = self.f1(x), self.f2(x)
x = self.act(x1) * x2
x = self.dwconv2(self.g(x))
x = input + self.drop_path(x)
return x7、Yolov8独家优化:ShuffleAttention

论文:https://arxiv.org/pdf/2102.00240.pdf
提出了一个有效的Shuffle Attention(SA)模块来解决此问题,该模块采用Shuffle单元有效地结合了两种类型的注意力机制。具体而言,SA首先将通道维分组为多个子特征,然后再并行处理它们。然后,对于每个子特征,SA利用Shuffle Unit在空间和通道维度上描绘特征依赖性。之后,将所有子特征汇总在一起,并采用“channel shuffle”运算符来启用不同子特征之间的信息通信。

SA的设计思想结合了组卷积(为了降低计算量),空间注意力机制(使用GN实现),通道注意力机制(类似SENet),ShuffleNetV2(使用Channel Shuffle融合不同组之间的信息)

可以看到,要比ECA-Net等模型效果更好,并且要比baseline ResNet50的top1高出1.34%。同样的在ResNet-101为基础添加SA模块,也要比baseline 的top1要高出了0.76%。

1.1 加入 modules.py中
###################### ShuffleAttention #### start by AI&CV ###############################
import torch
from torch import nn
from torch.nn import init
from torch.nn.parameter import Parameter
class ShuffleAttention(nn.Module):
def __init__(self, channel=512, reduction=16, G=8):
super().__init__()
self.G = G
self.channel = channel
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.gn = nn.GroupNorm(channel // (2 * G), channel // (2 * G))
self.cweight = Parameter(torch.zeros(1, channel // (2 * G), 1, 1))
self.cbias = Parameter(torch.ones(1, channel // (2 * G), 1, 1))
self.sweight = Parameter(torch.zeros(1, channel // (2 * G), 1, 1))
self.sbias = Parameter(torch.ones(1, channel // (2 * G), 1, 1))
self.sigmoid = nn.Sigmoid()
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
@staticmethod
def channel_shuffle(x, groups):
b, c, h, w = x.shape
x = x.reshape(b, groups, -1, h, w)
x = x.permute(0, 2, 1, 3, 4)
# flatten
x = x.reshape(b, -1, h, w)
return x
def forward(self, x):
b, c, h, w = x.size()
# group into subfeatures
x = x.view(b * self.G, -1, h, w) # bs*G,c//G,h,w
# channel_split
x_0, x_1 = x.chunk(2, dim=1) # bs*G,c//(2*G),h,w
# channel attention
x_channel = self.avg_pool(x_0) # bs*G,c//(2*G),1,1
x_channel = self.cweight * x_channel + self.cbias # bs*G,c//(2*G),1,1
x_channel = x_0 * self.sigmoid(x_channel)
# spatial attention
x_spatial = self.gn(x_1) # bs*G,c//(2*G),h,w
x_spatial = self.sweight * x_spatial + self.sbias # bs*G,c//(2*G),h,w
x_spatial = x_1 * self.sigmoid(x_spatial) # bs*G,c//(2*G),h,w
# concatenate along channel axis
out = torch.cat([x_channel, x_spatial], dim=1) # bs*G,c//G,h,w
out = out.contiguous().view(b, -1, h, w)
# channel shuffle
out = self.channel_shuffle(out, 2)
return out
###################### ShuffleAttention #### end by AI&CV ###############################1.2 加入tasks.py中:
from ultralytics.nn.modules import (C1, C2, C3, C3TR, SPP, SPPF, Bottleneck, BottleneckCSP, C2f, C3Ghost, C3x, Classify,Concat, Conv, ConvTranspose, Detect, DWConv, DWConvTranspose2d, Ensemble, Focus, GhostBottleneck, GhostConv, Segment, ShuffleAttention)def parse_model(d, ch, verbose=True): 加入以下代码
elif m is ShuffleAttention:
c1, c2 = ch[f], args[0]
if c2 != nc:
c2 = make_divisible(min(c2, max_channels) * width, 8)
args = [c1, *args[1:]]1.3 yolov8_ShuffleAttention.yaml
# Ultralytics YOLO , GPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 4 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 15 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 18 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 21 (P5/32-large)
- [-1, 3, ShuffleAttention, [1024]]
- [[15, 18, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)
8、Yolov8独家优化:ECA

论文:https://arxiv.org/pdf/1910.03151.pdf
本文的贡献总结如下:
- 对SE模块进行了剖析,并分别证明了避免降维和适当的跨通道交互对于学习高性能和高效率的通道注意力是重要的。
- 在以上分析的基础上,提出了一种高效通道注意模块(ECA),在CNN网络上提出了一种极轻量的通道注意力模块,该模块增加的模型复杂度小,提升效果显著。
- 在ImageNet-1K和MS COCO上的实验结果表明,本文提出的方法具有比目前最先进的CNN模型更低的模型复杂度,与此同时,本文方法却取得了非常有竞争力的结果。
作者设计了一个高效的channel attention机制,该方法保留了原有的通道一对一权重更新,并且通过local cross-channel interaction来提升结果。此外作者还设计了一个自动调节kernel size的机制来决定交叉学习的覆盖率。通过该ECA模块,作者在几乎一样的参数上获得了分类top-1 acc 2%的提升

比较了不同的注意力方法在ImageNet数据集上的网络参数(param),浮点运算每秒(FLOPs),训练或推理速度(帧每秒,FPS), Top-1/Top-5的准确性(%)。

2.1 加入 modules.py中
###################### ECAAttention #### start by AI&CV ###############################
class ECAAttention(nn.Module):
"""Constructs a ECA module.
Args:
channel: Number of channels of the input feature map
k_size: Adaptive selection of kernel size
"""
def __init__(self, c1, k_size=3):
super(ECAAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv = nn.Conv1d(1, 1, kernel_size=k_size, padding=(k_size - 1) // 2, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# feature descriptor on the global spatial information
y = self.avg_pool(x)
y = self.conv(y.squeeze(-1).transpose(-1, -2)).transpose(-1, -2).unsqueeze(-1)
# Multi-scale information fusion
y = self.sigmoid(y)
return x * y.expand_as(x)
###################### ECAAttention #### end by AI&CV ###############################2.2 加入tasks.py中:
from ultralytics.nn.modules import (C1, C2, C3, C3TR, SPP, SPPF, Bottleneck, BottleneckCSP, C2f, C3Ghost, C3x, Classify,Concat, Conv, ConvTranspose, Detect, DWConv, DWConvTranspose2d, Ensemble, Focus,GhostBottleneck, GhostConv, Segment, ECAAttention)def parse_model(d, ch, verbose=True): 加入以下代码
elif m is ECAAttention:
c1, c2 = ch[f], args[0]
if c2 != nc:
c2 = make_divisible(min(c2, max_channels) * width, 8)
args = [c1, *args[1:]]2.3 yolov8_ECAAttention.yaml
# Ultralytics YOLO , GPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 4 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 15 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 18 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 21 (P5/32-large)
- [-1, 1, ECAAttention, [1024]]
- [[15, 18, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)
9、Yolov8独家优化:SENet

Squeeze-and-Excitation Networks(SENet)是由自动驾驶公司Momenta在2017年公布的一种全新的图像识别结构,它通过对特征通道间的相关性进行建模,把重要的特征进行强化来提升准确率。这个结构是2017 ILSVR竞赛的冠军,top5的错误率达到了2.251%,比2016年的第一名还要低25%,可谓提升巨大。
通过引入SE模块,CNN可以自适应地学习每个通道的重要性,从而提高模型的表现能力。SE网络在多个图像分类任务中取得了很好的效果,并被广泛应用于各种视觉任务中。


3.1 加入 modules.py中
###################### SENet #### start by AI&CV ###############################
import numpy as np
import torch
from torch import nn
from torch.nn import init
class SEAttention(nn.Module):
def __init__(self, channel=512,reduction=16):
super().__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel, bias=False),
nn.Sigmoid()
)
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y.expand_as(x)
###################### SENet #### end by AI&CV ###############################
3.2 加入tasks.py中:
from ultralytics.nn.modules import (C1, C2, C3, C3TR, SPP, SPPF, Bottleneck, BottleneckCSP, C2f, C3Ghost, C3x, Classify, Concat, Conv, ConvTranspose, Detect, DWConv, DWConvTranspose2d, Ensemble, Focus,GhostBottleneck, GhostConv, Segment,SEAttention)def parse_model(d, ch, verbose=True): 加入以下代码
if m in (Classify, Conv, ConvTranspose, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, Focus,BottleneckCSP, C1, C2, C2f, C3, C3TR, C3Ghost, nn.ConvTranspose2d, DWConvTranspose2d, C3x,EffectiveSE):3.3 yolov8_SEAttention.yaml
# Ultralytics YOLO , GPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 4 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 15 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 18 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 21 (P5/32-large)
- [-1, 3, SEAttention, [1024]]
- [[15, 18, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)
10、Yolov8独家优化:EffectiveSE

论文: https://arxiv.org/pdf/1911.06667.pdf

EffectiveSE是一种用于图像分类的卷积神经网络结构,它是SENet(Squeeze-and-Excitation Networks)的改进版本。EffectiveSE借鉴了SENet的思想,通过学习一种“通道注意力”,来自适应地调整每个通道的权重,以提高网络的性能。
4.1 加入 modules.py中
###################### EffectiveSE #### end by AI&CV ###############################
import torch
from torch import nn as nn
from timm.models.layers.create_act import create_act_layer
class EffectiveSE(nn.Module):
def __init__(self, channels, add_maxpool=False, gate_layer='hard_sigmoid'):
super(EffectiveSE, self).__init__()
self.add_maxpool = add_maxpool
self.fc = nn.Conv2d(channels, channels, kernel_size=1, padding=0)
self.gate = create_act_layer(gate_layer)
def forward(self, x):
x_se = x.mean((2, 3), keepdim=True)
if self.add_maxpool:
# experimental codepath, may remove or change
x_se = 0.5 * x_se + 0.5 * x.amax((2, 3), keepdim=True)
x_se = self.fc(x_se)
return x * self.gate(x_se)
###################### EffectiveSE #### end by AI&CV ###############################4.2 加入tasks.py中:
from ultralytics.nn.modules import (C1, C2, C3, C3TR, SPP, SPPF, Bottleneck, BottleneckCSP, C2f, C3Ghost, C3x, Classify,Concat, Conv, ConvTranspose, Detect, DWConv, DWConvTranspose2d, Ensemble, Focus,GhostBottleneck, GhostConv, Segment, EffectiveSE)def parse_model(d, ch, verbose=True): 加入以下代码
if m in (Classify, Conv, ConvTranspose, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, Focus, BottleneckCSP, C1, C2, C2f, C3, C3TR, C3Ghost, nn.ConvTranspose2d,DWConvTranspose2d, C3x,EffectiveSE):4.3 yolov8_EffectiveSE.yaml
# Ultralytics YOLO , GPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 4 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 15 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 18 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 21 (P5/32-large)
- [-1, 3, EffectiveSE, [1024]]
- [[15, 18, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)这四种注意力机制,分别是:ShuffleAttention、ECA、EffectiveSE、SE,并最终引入到Yolov8。同时在数据集下测试,均能涨点,涨点幅度为ShuffleAttention>ECA>EffectiveSE>SE
11、Yolov8改进实战例子
1)DCNv4结合SPPELAN:mAP从原始的0.923 提升至0.935
2)自适应阈值焦点损失: mAP从原始的0.923 提升至0.930
3)自研独家创新BSAM注意力:mAP从原始的0.923 提升至0.933
4)极简的神经网络VanillaBlock :mAP从原始的0.923 提升至0.962
1.道路缺陷数据集介绍
缺陷类型:crack
数据集数量:195张

1.1数据增强,扩充数据集
通过扩充得到390张图片
按照train、val、test进行8:1:1进行划分
1.1.1 通过split_train_val.py得到trainval.txt、val.txt、test.txt
# coding:utf-8
import os
import random
import argparse
parser = argparse.ArgumentParser()
#xml文件的地址,根据自己的数据进行修改 xml一般存放在Annotations下
parser.add_argument('--xml_path', default='Annotations', type=str, help='input xml label path')
#数据集的划分,地址选择自己数据下的ImageSets/Main
parser.add_argument('--txt_path', default='ImageSets/Main', type=str, help='output txt label path')
opt = parser.parse_args()
trainval_percent = 0.9
train_percent = 0.8
xmlfilepath = opt.xml_path
txtsavepath = opt.txt_path
total_xml = os.listdir(xmlfilepath)
if not os.path.exists(txtsavepath):
os.makedirs(txtsavepath)
num = len(total_xml)
list_index = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list_index, tv)
train = random.sample(trainval, tr)
file_trainval = open(txtsavepath + '/trainval.txt', 'w')
file_test = open(txtsavepath + '/test.txt', 'w')
file_train = open(txtsavepath + '/train.txt', 'w')
file_val = open(txtsavepath + '/val.txt', 'w')
for i in list_index:
name = total_xml[i][:-4] + '\n'
if i in trainval:
file_trainval.write(name)
if i in train:
file_train.write(name)
else:
file_val.write(name)
else:
file_test.write(name)
file_trainval.close()
file_train.close()
file_val.close()
file_test.close()1.1.2 通过voc_label.py得到适合yolov9训练需要的
# -*- coding: utf-8 -*-
import xml.etree.ElementTree as ET
import os
from os import getcwd
sets = ['train', 'val', 'test']
classes = ["crack"] # 改成自己的类别
abs_path = os.getcwd()
print(abs_path)
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return x, y, w, h
def convert_annotation(image_id):
in_file = open('Annotations/%s.xml' % (image_id), encoding='UTF-8')
out_file = open('labels/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
#difficult = obj.find('Difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
b1, b2, b3, b4 = b
# 标注越界修正
if b2 > w:
b2 = w
if b4 > h:
b4 = h
b = (b1, b2, b3, b4)
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for image_set in sets:
if not os.path.exists('labels/'):
os.makedirs('labels/')
image_ids = open('ImageSets/Main/%s.txt' % (image_set)).read().strip().split()
list_file = open('%s.txt' % (image_set), 'w')
for image_id in image_ids:
list_file.write(abs_path + '/images/%s.jpg\n' % (image_id))
convert_annotation(image_id)
list_file.close()2.基于YOLOv8的道路缺陷识别
2.1 原始结果
yolov9-c mAP为0.923

预测结果:

2.2 DCNv4结合SPPELAN
SPPELAN优化 | 新一代高效可形变卷积DCNv4如何做二次创新?高效结合SPPELAN| CVPR2024
原文链接:
YOLOv9改进策略:SPPELAN优化 | 新一代高效可形变卷积DCNv4如何做二次创新?高效结合SPPELAN| CVPR2024_dcnv4 改进-CSDN博客

论文: https://arxiv.org/pdf/2401.06197.pdf
摘要:我们介绍了可变形卷积v4 (DCNv4),这是一种高效的算子,专为广泛的视觉应用而设计。DCNv4通过两个关键增强解决了其前身DCNv3的局限性:去除空间聚合中的softmax归一化,增强空间聚合的动态性和表现力;优化内存访问以最小化冗余操作以提高速度。与DCNv3相比,这些改进显著加快了收敛速度,并大幅提高了处理速度,其中DCNv4的转发速度是DCNv3的三倍以上。DCNv4在各种任务中表现出卓越的性能,包括图像分类、实例和语义分割,尤其是图像生成。当在潜在扩散模型中与U-Net等生成模型集成时,DCNv4的性能优于其基线,强调了其增强生成模型的可能性。在实际应用中,将InternImage模型中的DCNv3替换为DCNv4来创建FlashInternImage,无需进一步修改即可使速度提高80%,并进一步提高性能。DCNv4在速度和效率方面的进步,以及它在不同视觉任务中的强大性能,显示了它作为未来视觉模型基础构建块的潜力。
图1所示。(a)我们以DCNv3为基准显示相对运行时间。DCNv4比DCNv3有明显的加速,并且超过了其他常见的视觉算子。(b)在相同的网络架构下,DCNv4收敛速度快于其他视觉算子,而DCNv3在初始训练阶段落后于视觉算子。

mAP从原始的0.923 提升至0.935

2.3 自适应阈值焦点损失函数
首先,我们注意到红外图像中目标与背景之间存在极大的不平衡,这使得模型更加关注背景特征而不是目标特征。为了解决这一问题,我们提出了一种新的自适应阈值焦点损失(ATFL)函数,该函数将目标和背景解耦,并利用自适应机制来调整损失权重,迫使模型将更多的注意力分配给目标特征。

mAP从原始的0.923 提升至0.930

2.4 自研独家创新BSAM注意力
本文改进内容: 提出新颖的注意力BSAM(BiLevel Spatial Attention Module),创新度极佳,适合科研创新,效果秒杀CBAM,Channel Attention+Spartial Attention升级为新颖的 BiLevel Attention+Spartial Attention
1)作为注意力BSAM使用;
推荐指数:五星
BSAM | 亲测在多个数据集能够实现涨点,多尺度特性在小目标检测表现也十分出色。


mAP从原始的0.923 提升至0.933
2.5 极简的神经网络VanillaBlock
原文链接:
YOLOv9改进策略 :主干优化 | 极简的神经网络VanillaBlock 实现涨点 |华为诺亚 VanillaNet-CSDN博客

论文:https://arxiv.org/pdf/2305.12972.pdf
来自华为诺亚、悉尼大学的研究者们提出了一种极简的神经网络模型 VanillaNet,以极简主义的设计为理念,网络中仅仅包含最简单的卷积计算,去掉了残差和注意力模块,在计算机视觉中的各种任务上都取得了不俗的效果。
VanillaNet,这是一种设计优雅的神经网络架构。 通过避免高深度、shortcuts和自注意力等复杂操作,VanillaNet 简洁明了但功能强大。

mAP从原始的0.923 提升至0.962

12、Yolov8独家优化:PConv结合C2f cvpr2023
为了设计快速神经网络,许多工作都集中在减少浮点运算(FLOPs)的数量上。然而,作者观察到FLOPs的这种减少不一定会带来延迟的类似程度的减少。这主要源于每秒低浮点运算(FLOPS)效率低下。为了实现更快的网络,作者重新回顾了FLOPs的运算符,并证明了如此低的FLOPS主要是由于运算符的频繁内存访问,尤其是深度卷积。因此,本文提出了一种新的partial convolution(PConv),通过同时减少冗余计算和内存访问可以更有效地提取空间特征。
基于PConv进一步提出FasterNet,这是一个新的神经网络家族,它在广泛的设备上实现了比其他网络高得多的运行速度,而不影响各种视觉任务的准确性。例如,在ImageNet-1k上小型FasterNet-T0在GPU、CPU和ARM处理器上分别比MobileVitXXS快3.1倍、3.1倍和2.5倍,同时准确度提高2.9%。
又快又好!本文提出新的Partial卷积(PConv),同时减少冗余计算和内存访问,并进一步提出FasterNet:新的神经网络家族,在多个处理平台上运行速度更快,优于MobileVit等网络;
论文地址:https://arxiv.org/abs/2303.03667
github:GitHub - JierunChen/FasterNet: Code release for PConv and FasterNet
1.1 Partial Convolution
我们提出了一种新的partial卷积(PConv),通过同时减少冗余计算和内存访问,可以更有效地提取空间特征。

2. PConv3加入到Yolov8
2.1 修改ultralytics\nn\modules\block.py
核心代码:
class PConv(nn.Module):
def __init__(self, dim, ouc, n_div=4, forward='split_cat'):
super().__init__()
self.dim_conv3 = dim // n_div
self.dim_untouched = dim - self.dim_conv3
self.partial_conv3 = nn.Conv2d(self.dim_conv3, self.dim_conv3, 3, 1, 1, bias=False)
self.conv = Conv(dim, ouc, k=1)
if forward == 'slicing':
self.forward = self.forward_slicing
elif forward == 'split_cat':
self.forward = self.forward_split_cat
else:
raise NotImplementedError
def forward_slicing(self, x):
# only for inference
x = x.clone() # !!! Keep the original input intact for the residual connection later
x[:, :self.dim_conv3, :, :] = self.partial_conv3(x[:, :self.dim_conv3, :, :])
x = self.conv(x)
return x
def forward_split_cat(self, x):
# for training/inference
x1, x2 = torch.split(x, [self.dim_conv3, self.dim_untouched], dim=1)
x1 = self.partial_conv3(x1)
x = torch.cat((x1, x2), 1)
x = self.conv(x)
return x13、Yolov8独家优化:Dual-ViT

论文:Dual Vision Transformer | IEEE Journals & Magazine | IEEE Xplore
摘要:以前的工作已经提出了几种降低自注意力机制计算成本的策略。其中许多工作考虑将自注意力过程分解为区域和局部特征提取过程,每个过程产生的计算复杂度要小得多。然而,区域信息通常仅以由于下采样而丢失的不希望的信息为代价。在本文中,作者提出了一种旨在缓解成本问题的新型Transformer架构,称为双视觉Transformer(Dual ViT)。新架构结合了一个关键的语义路径,可以更有效地将token向量压缩为全局语义,并降低复杂性。这种压缩的全局语义通过另一个构建的像素路径,作为学习内部像素级细节的有用先验信息。然后将语义路径和像素路径整合在一起,并进行联合训练,通过这两条路径并行传播增强的自注意力信息。因此,双ViT能够在不影响精度的情况下降低计算复杂度。实证证明,双ViT比SOTA Transformer架构提供了更高的精度,同时降低了训练复杂度。

在本文中,我们提出了一种新颖的 Transformer 架构,它优雅地利用全局语义进行自注意力学习,即双视觉 Transformer (Dual-ViT)。

1.DualAttention引入到yolov8
2新建加入ultralytics/nn/attention/dualvit.py
class DWConv(nn.Module):
def __init__(self, dim=768):
super(DWConv, self).__init__()
self.dwconv = nn.Conv2d(dim, dim, 3, 1, 1, bias=True, groups=dim)
def forward(self, x, H, W):
B, N, C = x.shape
x = x.transpose(1, 2).view(B, C, H, W)
x = self.dwconv(x)
x = x.flatten(2).transpose(1, 2)
return x
class PVT2FFN(nn.Module):
def __init__(self, in_features, hidden_features):
super().__init__()
self.fc1 = nn.Linear(in_features, hidden_features)
self.dwconv = DWConv(hidden_features)
self.act = nn.GELU()
self.fc2 = nn.Linear(hidden_features, in_features)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
if m.bias is not None:
nn.init.constant_(m.bias, 0)
if m.weight is not None:
nn.init.constant_(m.weight, 1.0)
elif isinstance(m, nn.Conv2d):
fan_out = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
fan_out //= m.groups
m.weight.data.normal_(0, math.sqrt(2.0 / fan_out))
if m.bias is not None:
m.bias.data.zero_()
def forward(self, x, H, W):
x = self.fc1(x)
x = self.dwconv(x, H, W)
x = self.act(x)
x = self.fc2(x)
return x14、Yolov8独家优化: AKConv(可改变核卷积),效果优异
可改变核卷积(AKConv),赋予卷积核任意数量的参数和任意采样形状,为网络开销和性能之间的权衡提供更丰富的选择,解决具有固定样本形状和正方形的卷积核不能很好地适应不断变化的目标的问题点,效果秒殺DSConv
1)AKConv替代标准卷积进行使用;
推荐指数:五星
1.AKConv原理介绍

论文:https://arxiv.org/pdf/2311.11587.pdf
摘要:基于卷积运算的神经网络在深度学习领域取得了令人瞩目的成果,但标准卷积运算存在两个固有的缺陷。一方面,卷积运算仅限于局部窗口,无法捕获其他位置的信息, 并且它的采样形状是固定的。 另一方面,卷积核的大小固定为k×k,是一个固定的正方形,参数的数量往往随大小呈平方增长。 很明显,不同数据集和不同位置的目标的形状和大小是不同的。 具有固定样本形状和正方形的卷积核不能很好地适应不断变化的目标。 针对上述问题,本工作探索了可改变核卷积(AKConv),它赋予卷积核任意数量的参数和任意采样形状,为网络开销和性能之间的权衡提供更丰富的选择。 在 AKConv 中,我们通过新的坐标生成算法定义任意大小的卷积核的初始位置。 为了适应目标的变化,我们引入了偏移量来调整每个位置的样本形状。 此外,我们通过使用具有相同大小和不同初始采样形状的 AKConv 来探索神经网络的效果。 AKConv 通过不规则卷积运算完成高效特征提取的过程,为卷积采样形状带来更多探索选择。 在代表性数据集 COCO2017、VOC 7+12 和 VisDrone-DET2021 上进行的物体检测实验充分展示了 AKConv 的优势。 AKConv可以作为即插即用的卷积运算来替代卷积运算来提高网络性能。
很明显,与 Deformabled 和标准 Conv 相比,AKConv 有更多的选择,并且卷积参数的数量随着卷积核大小呈线性增加。 注意:为了清楚地描述 AKConv 的优点,在 AKConv 和 Deformable Conv 中我们忽略了学习偏移量的参数数量,因为它远小于特征提取中涉及的卷积参数数量。
作者认为 AKConv 的设计是一种新颖的设计,它实现了从不规则和任意采样形状的卷积核中提取特征的壮举。 即使不使用 Deformable Conv 中的偏移思想,AKConv 仍然可以做出多种卷积核形状。 因为,AKConv可以用初始坐标重新采样来呈现多种变化。 如图4所示,我们为大小为5的卷积设计了各种初始采样形状。在图4中,我们只显示了大小为5的一些示例。但是,AKConv的大小可以是任意的,因此随着大小的增加,初始采样形状会随着大小的增加而变化。 AKConv 的卷积采样形状变得更加丰富甚至无限。 鉴于不同数据集的目标形状各不相同,设计与采样形状相对应的卷积运算至关重要。 AKConv完全是通过根据特定相位域设计相应形状的卷积运算来实现的。 它还可以类似于 Deformable Conv,通过添加可学习的偏移来动态适应对象的变化。 对于特定任务,卷积核初始采样位置的设计很重要,因为它是先验知识。 正如齐等人所言。 [27],他们为细长管状结构分割任务提出了具有相应形状的采样坐标,但他们的形状选择仅适用于细长管状结构。
展示核大小为5的初始样本形状。AKConv可以通过设计不同的初始采样形状来实现任意采样形状。
实验结果,数据集 COCO2017、VOC 7+12 和 VisDrone-DET2021 上进行的物体检测实验充分展示了 AKConv 的优势
2. AKConv加入YOLOv8
2.1 新建ultralytics/nn/Conv/AKConv.py
核心源码
class AKConv(nn.Module):
def __init__(self, inc, outc, num_param, stride=1, bias=None):
super(AKConv, self).__init__()
self.num_param = num_param
self.stride = stride
self.conv = nn.Sequential(nn.Conv2d(inc, outc, kernel_size=(num_param, 1), stride=(num_param, 1), bias=bias),nn.BatchNorm2d(outc),nn.SiLU()) # the conv adds the BN and SiLU to compare original Conv in YOLOv5.
self.p_conv = nn.Conv2d(inc, 2 * num_param, kernel_size=3, padding=1, stride=stride)
nn.init.constant_(self.p_conv.weight, 0)
self.p_conv.register_full_backward_hook(self._set_lr)
#https://blog.csdn.net/m0_63774211/category_12289773.html?spm=1001.2014.3001.5482
@staticmethod
def _set_lr(module, grad_input, grad_output):
grad_input = (grad_input[i] * 0.1 for i in range(len(grad_input)))
grad_output = (grad_output[i] * 0.1 for i in range(len(grad_output)))
def forward(self, x):
# N is num_param.
offset = self.p_conv(x)
dtype = offset.data.type()
N = offset.size(1) // 2
# (b, 2N, h, w)
p = self._get_p(offset, dtype)
# (b, h, w, 2N)
p = p.contiguous().permute(0, 2, 3, 1)
q_lt = p.detach().floor()
q_rb = q_lt + 1
q_lt = torch.cat([torch.clamp(q_lt[..., :N], 0, x.size(2) - 1), torch.clamp(q_lt[..., N:], 0, x.size(3) - 1)],
dim=-1).long()
q_rb = torch.cat([torch.clamp(q_rb[..., :N], 0, x.size(2) - 1), torch.clamp(q_rb[..., N:], 0, x.size(3) - 1)],
dim=-1).long()
q_lb = torch.cat([q_lt[..., :N], q_rb[..., N:]], dim=-1)
q_rt = torch.cat([q_rb[..., :N], q_lt[..., N:]], dim=-1)
# clip p
p = torch.cat([torch.clamp(p[..., :N], 0, x.size(2) - 1), torch.clamp(p[..., N:], 0, x.size(3) - 1)], dim=-1)
# bilinear kernel (b, h, w, N)
g_lt = (1 + (q_lt[..., :N].type_as(p) - p[..., :N])) * (1 + (q_lt[..., N:].type_as(p) - p[..., N:]))
g_rb = (1 - (q_rb[..., :N].type_as(p) - p[..., :N])) * (1 - (q_rb[..., N:].type_as(p) - p[..., N:]))
g_lb = (1 + (q_lb[..., :N].type_as(p) - p[..., :N])) * (1 - (q_lb[..., N:].type_as(p) - p[..., N:]))
g_rt = (1 - (q_rt[..., :N].type_as(p) - p[..., :N])) * (1 + (q_rt[..., N:].type_as(p) - p[..., N:]))
# resampling the features based on the modified coordinates.
x_q_lt = self._get_x_q(x, q_lt, N)
x_q_rb = self._get_x_q(x, q_rb, N)
x_q_lb = self._get_x_q(x, q_lb, N)
x_q_rt = self._get_x_q(x, q_rt, N)
# bilinear
x_offset = g_lt.unsqueeze(dim=1) * x_q_lt + \
g_rb.unsqueeze(dim=1) * x_q_rb + \
g_lb.unsqueeze(dim=1) * x_q_lb + \
g_rt.unsqueeze(dim=1) * x_q_rt
x_offset = self._reshape_x_offset(x_offset, self.num_param)
out = self.conv(x_offset)
return out
#https://blog.csdn.net/m0_63774211/category_12289773.html?spm=1001.2014.3001.5482
# generating the inital sampled shapes for the AKConv with different sizes.
def _get_p_n(self, N, dtype):
base_int = round(math.sqrt(self.num_param))
row_number = self.num_param // base_int
mod_number = self.num_param % base_int
p_n_x,p_n_y = torch.meshgrid(
torch.arange(0, row_number),
torch.arange(0,base_int))
p_n_x = torch.flatten(p_n_x)
p_n_y = torch.flatten(p_n_y)
if mod_number > 0:
mod_p_n_x,mod_p_n_y = torch.meshgrid(
torch.arange(row_number,row_number+1),
torch.arange(0,mod_number))
mod_p_n_x = torch.flatten(mod_p_n_x)
mod_p_n_y = torch.flatten(mod_p_n_y)
p_n_x,p_n_y = torch.cat((p_n_x,mod_p_n_x)),torch.cat((p_n_y,mod_p_n_y))
p_n = torch.cat([p_n_x,p_n_y], 0)
p_n = p_n.view(1, 2 * N, 1, 1).type(dtype)
return p_n
# no zero-padding
def _get_p_0(self, h, w, N, dtype):
p_0_x, p_0_y = torch.meshgrid(
torch.arange(0, h * self.stride, self.stride),
torch.arange(0, w * self.stride, self.stride))
p_0_x = torch.flatten(p_0_x).view(1, 1, h, w).repeat(1, N, 1, 1)
p_0_y = torch.flatten(p_0_y).view(1, 1, h, w).repeat(1, N, 1, 1)
p_0 = torch.cat([p_0_x, p_0_y], 1).type(dtype)
return p_0
def _get_p(self, offset, dtype):
N, h, w = offset.size(1) // 2, offset.size(2), offset.size(3)
# (1, 2N, 1, 1)
p_n = self._get_p_n(N, dtype)
# (1, 2N, h, w)
p_0 = self._get_p_0(h, w, N, dtype)
p = p_0 + p_n + offset
return p
def _get_x_q(self, x, q, N):
b, h, w, _ = q.size()
padded_w = x.size(3)
c = x.size(1)
# (b, c, h*w)
x = x.contiguous().view(b, c, -1)
# (b, h, w, N)
index = q[..., :N] * padded_w + q[..., N:] # offset_x*w + offset_y
# (b, c, h*w*N)
index = index.contiguous().unsqueeze(dim=1).expand(-1, c, -1, -1, -1).contiguous().view(b, c, -1)
x_offset = x.gather(dim=-1, index=index).contiguous().view(b, c, h, w, N)
return x_offset
# https://blog.csdn.net/m0_63774211/category_12289773.html?spm=1001.2014.3001.5482
# Stacking resampled features in the row direction.
@staticmethod
def _reshape_x_offset(x_offset, num_param):
b, c, h, w, n = x_offset.size()
# using Conv3d
# x_offset = x_offset.permute(0,1,4,2,3), then Conv3d(c,c_out, kernel_size =(num_param,1,1),stride=(num_param,1,1),bias= False)
# using 1 × 1 Conv
# x_offset = x_offset.permute(0,1,4,2,3), then, x_offset.view(b,c×num_param,h,w) finally, Conv2d(c×num_param,c_out, kernel_size =1,stride=1,bias= False)
# using the column conv as follow, then, Conv2d(inc, outc, kernel_size=(num_param, 1), stride=(num_param, 1), bias=bias)
x_offset = rearrange(x_offset, 'b c h w n -> b c (h n) w')
return x_offset2.2 yolov8_AKConv.yaml
# Ultralytics YOLO 🚀, GPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # scales module repeats
width_multiple: 0.25 # scales convolution channels
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, AKConv, [128, 6, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, AKConv, [256, 6, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, AKConv, [512, 6, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, AKConv, [1024, 6, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 15 (P3/8-small)
- [-1, 1, AKConv, [256, 6, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 18 (P4/16-medium)
- [-1, 1, AKConv, [512, 6, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 21 (P5/32-large)
- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)15、Yolov8 Loss改进大全
IoU损失函数 改进 大全集
1.1 IoULoss损失函数改进 说明
可能有同学好奇,为什么是yaml的形式 来改进IoU Loss
这是博主提出的一种比较新颖的改进方式,关于使用不同IoU Loss训练 现在集成了直接在yaml网络配置文件中修改不同loss进行训练,只需要将 loss:XIoU 字段 改为对应的IoU损失函数名称, 即可进行不同Loss的一个训练 比如 添加 loss:SIoU
即表示使用SIoU损失函数训练,非常方便,应该是目前第一个项目采用这种方式,很方便,且很容易记录实验情况。代码展示可展开,详情
# Ultralytics YOLO , AGPL-3.0 license
# YOLOv8 object detection model. More improvement points for YOLOv8, please see https://github.com/iscyy/ultralyticsPro
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
loss: 'XIoU' # 举例,如果使用XIoU损失函数的话, 即修改对应的名称
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 15 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 18 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 21 (P5/32-large)
- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)以上超过 100种 二次改进/ 自研结构 的 IoU损失函数 均包含在 UltralyticsPro 项目中,点击链接即可 GitHub - iscyy/ultralyticsPro: 专注于改进YOLOv8模型,NEW - YOLOv8 RT-DETR in PyTorch >, Support to improve backbone, neck, head, loss, IoU, NMS and other modules
2.2 YOLOv8改进IoU损失函数目录
IoU损失函数分为 核心类(10+种) 和 增强类,大全集具体如下 包含140+种组合 损失函数
核心IoU损失函数:可以直接单独使用 增强类损失函数:顾名思义在A核心损失函数的基础上进行增强改进,可以无缝和以上的 一类A核心IoU损失函数 一起使用
| YOLOv8改进IoU | 对应的yaml配置文件在 项目中均能找到 | 改进类型 |
|---|---|---|
| IoU 篇 | 网络结构配置文件yaml | |
| 一类A核心IoU损失函数 | ||
| RepulsionLoss | YOLOv8.RepulsionLoss.yaml | 用于小目标遮挡函数,首发改进 |
| NWDLoss | YOLOv8-NWDLoss.yaml | |
| XIoU | YOLOv8-XIoU.yaml | 自研结构 |
| EfficIoU | YOLOv8-EfficIoU.yaml | 自研结构 |
| MPDIoU | YOLOv8-MPDIoU.yaml | |
| Shape-IoU | YOLOv8-Shape-IoU.yaml | |
| SIoU | YOLOv8-SIoU.yaml | |
| PIoU | YOLOv8-PIoU.yaml | 支持PIoU、PIoUv2 |
| WIoU | YOLOv8-WIoU.yaml | 支持WIoU、WIoUv2、WIoUv3 |
| EIoU | YOLOv8-EIoU.yaml | |
| CIoU | YOLOv8-CIoU.yaml | 官方默认使用CIoU |
| DIoU | YOLOv8-DIoU.yaml | |
| GIoU | YOLOv8-GIoU.yaml | |
| 持续更新最新IoU、原创IoU损失函数 | 同步在该项目/文档中更新 | |

| 针对小目标检测,进行损失函数改进 NWDLoss + 以上 72 种损失函数 一起使用(最全大合集) 由于改进配置太多,不一一赘述,具体举个例子 | | | | --- | --- | --- | | NWDLoss | | | | NWDLoss + Focal_Inner_XIoU 组合 | YOLOv8-NWDLoss-Focal_Inner_XIoU.yaml | 自研结构 | | NWDLoss + Focal_Focaler_XIoU 组合 | YOLOv8-NWDLoss-Focal_Focaler_XIoU.yaml | 自研结构 | | NWDLoss + XIoU 组合 | YOLOv8-NWDLoss-XIoU.yaml | 自研结构 | | 支持NWDLoss + 72 种损失函数 组合
| Focal增强类 + 结合 一类A核心 组成新的损失函数 | ||
|---|---|---|
| Focal增强类 + 结合 一类A核心 组成新的损失函数 | 一类A核心IoU损失函数 指的是 SIoU EIoU这种损失函数 | |
| Focal_XIoU | YOLOv8-Focal_XIoU.yaml | 自研结构 |
| Focal_EfficIoU | YOLOv8-Focal_EfficIoU.yaml | 自研结构 |
| Focal_MPDIoU | YOLOv8-Focal_MPDIoU.yaml | 自研结构 |
| Focal_Shape-IoU | YOLOv8-Focal_Shape-IoU.yaml | 自研结构 |
| Focal_PIoU | YOLOv8-Focal_PIoU.yaml | 自研结构 |
| Focal_PIoUv2 | YOLOv8-Focal_PIoUv2.yaml | 自研结构 |
| Focal_WIoU | YOLOv8-Focal_WIoU.yaml | 自研结构 |
| Focal_SIoU | YOLOv8-Focal_SIoU.yaml | 自研结构 |
| Focal_EIoU | YOLOv8-Focal_EIoU.yaml | 自研结构 |
| Focal_CIoU | YOLOv8-Focal_CIoU.yaml | 自研结构 |
| Focal_DIoU | YOLOv8-Focal_DIoU.yaml | 自研结构 |
| Focal_GIoU | YOLOv8-Focaler_GIoU.yaml | 自研结构 |
| 持续更新最新IoU、原创IoU损失函数 | 同步在该项目/文档中更新 | |

16、Yolov8 独家方法Shape IoU Loss
种新的Shape IoU方法,该方法可以通过关注边界框本身的形状和尺度来计算损失,解决边界盒的形状和规模等固有属性对边界盒回归的影响。
💡💡💡对小目标检测涨点明显,在VisDrone2019、PASCAL VOC均有涨点
1.Shape-IoU介绍

论文:https://arxiv.org/pdf/2312.17663.pdf
摘要:边界盒回归损失作为检测器定位分支的重要组成部分,在目标检测任务中起着重要的作用。现有的边界盒回归方法通常考虑GT盒与预测盒之间的几何关系,利用边界盒的相对位置和形状来计算损失,而忽略了边界盒的形状和规模等固有属性对边界盒回归的影响。为了弥补已有研究的不足,本文提出了一种关注边界盒本身形状和尺度的边界盒回归方法。首先,我们分析了边界框的回归特征,发现边界框本身的形状和尺度因素都会对回归结果产生影响。基于以上结论,我们提出了Shape IoU方法,该方法可以通过关注边界框本身的形状和尺度来计算损失,从而使边界框回归更加准确。最后,我们通过大量的对比实验验证了我们的方法,结果表明,我们的方法可以有效地提高检测性能,并且优于现有的方法,在不同的检测任务中达到了最先进的性能。
本文贡献:
1.我们分析了边界盒回归的特点,得出边界盒回归过程中,边界盒回归样本本身的形状和尺度因素都会对回归结果产生影响。
2.在已有的边界盒回归损失函数的基础上,考虑到边界盒回归样本本身的形状和尺度对边界盒回归的影响,提出了shape- iou损失函数,针对微小目标检测任务提出了 the shape-dotdistance and shape-nwd loss
3.我们使用最先进的单级探测器对不同的检测任务进行了一系列的对比实验,实验结果证明本文方法的检测效果优于现有的方法来实现sota。
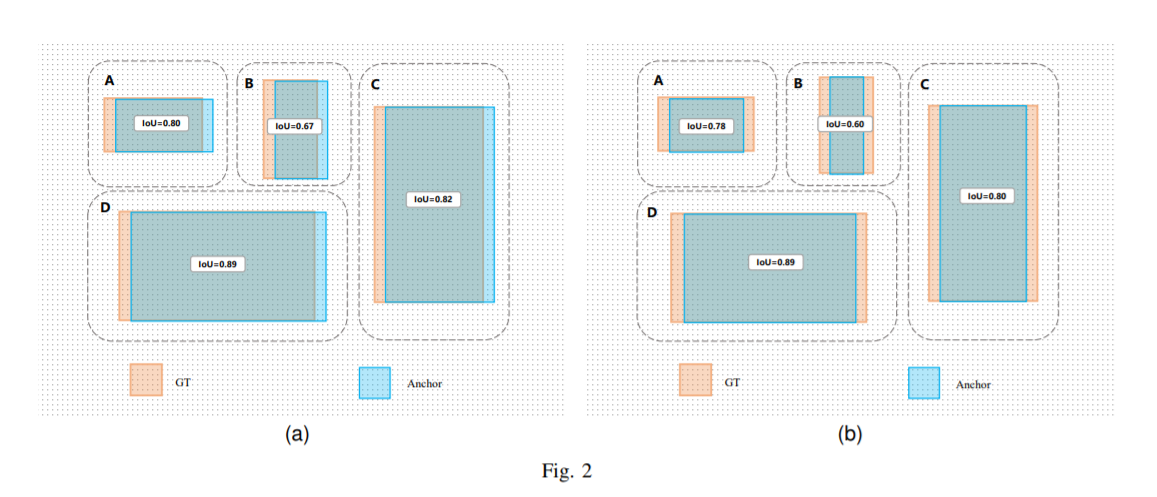


2.如何添加在YOLOv8
2.1 Shape-IoU加入 ultralytics/utils/metrics.py
def shape_iou(box1, box2, xywh=True, scale=0, eps= 1e-7):
(x1, y1, w1, h1), (x2, y2, w2, h2) = box1.chunk(4, -1), box2.chunk(4, -1)
w1_, h1_, w2_, h2_ = w1 / 2, h1 / 2, w2 / 2, h2 / 2
b1_x1, b1_x2, b1_y1, b1_y2 = x1 - w1_, x1 + w1_, y1 - h1_, y1 + h1_
b2_x1, b2_x2, b2_y1, b2_y2 = x2 - w2_, x2 + w2_, y2 - h2_, y2 + h2_
# Intersection area
inter = (torch.min(b1_x2, b2_x2) - torch.max(b1_x1, b2_x1)).clamp(0) * \
(torch.min(b1_y2, b2_y2) - torch.max(b1_y1, b2_y1)).clamp(0)
# Union Area
union = w1 * h1 + w2 * h2 - inter + eps
# IoU
iou = inter / union
# Shape-Distance #Shape-Distance #Shape-Distance #Shape-Distance #Shape-Distance #Shape-Distance #Shape-Distance
ww = 2 * torch.pow(w2, scale) / (torch.pow(w2, scale) + torch.pow(h2, scale))
hh = 2 * torch.pow(h2, scale) / (torch.pow(w2, scale) + torch.pow(h2, scale))
cw = torch.max(b1_x2, b2_x2) - torch.min(b1_x1, b2_x1) # convex width
ch = torch.max(b1_y2, b2_y2) - torch.min(b1_y1, b2_y1) # convex height
c2 = cw ** 2 + ch ** 2 + eps # convex diagonal squared
center_distance_x = ((b2_x1 + b2_x2 - b1_x1 - b1_x2) ** 2) / 4
center_distance_y = ((b2_y1 + b2_y2 - b1_y1 - b1_y2) ** 2) / 4
center_distance = hh * center_distance_x + ww * center_distance_y
distance = center_distance / c2
# Shape-Shape #Shape-Shape #Shape-Shape #Shape-Shape #Shape-Shape #Shape-Shape #Shape-Shape #Shape-Shape
omiga_w = hh * torch.abs(w1 - w2) / torch.max(w1, w2)
omiga_h = ww * torch.abs(h1 - h2) / torch.max(h1, h2)
shape_cost = torch.pow(1 - torch.exp(-1 * omiga_w), 4) + torch.pow(1 - torch.exp(-1 * omiga_h), 4)
# Shape-IoU #Shape-IoU #Shape-IoU #Shape-IoU #Shape-IoU #Shape-IoU #Shape-IoU #Shape-IoU #Shape-IoU
iou = iou - distance - 0.5 * (shape_cost)
return iou # IoU 17、YOLOv8独家改进:backbone改进 | 最新大卷积核CNN架构UniRepLKNet

加入YOLOv8
新建ultralytics/nn/backbone/UniRepLKNet.py
核心代码:
class UniRepLKNetBlock(nn.Module):
def __init__(self,
dim,
kernel_size,
drop_path=0.,
layer_scale_init_value=1e-6,
deploy=False,
attempt_use_lk_impl=True,
with_cp=False,
use_sync_bn=False,
ffn_factor=4):
super().__init__()
self.with_cp = with_cp
# if deploy:
# print('------------------------------- Note: deploy mode')
# if self.with_cp:
# print('****** note with_cp = True, reduce memory consumption but may slow down training ******')
self.need_contiguous = (not deploy) or kernel_size >= 7
if kernel_size == 0:
self.dwconv = nn.Identity()
self.norm = nn.Identity()
elif deploy:
self.dwconv = get_conv2d(dim, dim, kernel_size=kernel_size, stride=1, padding=kernel_size // 2,
dilation=1, groups=dim, bias=True,
attempt_use_lk_impl=attempt_use_lk_impl)
self.norm = nn.Identity()
elif kernel_size >= 7:
self.dwconv = DilatedReparamBlock(dim, kernel_size, deploy=deploy,
use_sync_bn=use_sync_bn,
attempt_use_lk_impl=attempt_use_lk_impl)
self.norm = get_bn(dim, use_sync_bn=use_sync_bn)
elif kernel_size == 1:
self.dwconv = nn.Conv2d(dim, dim, kernel_size=kernel_size, stride=1, padding=kernel_size // 2,
dilation=1, groups=1, bias=deploy)
self.norm = get_bn(dim, use_sync_bn=use_sync_bn)
else:
assert kernel_size in [3, 5]
self.dwconv = nn.Conv2d(dim, dim, kernel_size=kernel_size, stride=1, padding=kernel_size // 2,
dilation=1, groups=dim, bias=deploy)
self.norm = get_bn(dim, use_sync_bn=use_sync_bn)
self.se = SEBlock(dim, dim // 4)
ffn_dim = int(ffn_factor * dim)
self.pwconv1 = nn.Sequential(
NCHWtoNHWC(),
nn.Linear(dim, ffn_dim))
self.act = nn.Sequential(
nn.GELU(),
GRNwithNHWC(ffn_dim, use_bias=not deploy))
if deploy:
self.pwconv2 = nn.Sequential(
nn.Linear(ffn_dim, dim),
NHWCtoNCHW())
else:
self.pwconv2 = nn.Sequential(
nn.Linear(ffn_dim, dim, bias=False),
NHWCtoNCHW(),
get_bn(dim, use_sync_bn=use_sync_bn))
self.gamma = nn.Parameter(layer_scale_init_value * torch.ones(dim),
requires_grad=True) if (not deploy) and layer_scale_init_value is not None \
and layer_scale_init_value > 0 else None
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
def forward(self, inputs):
def _f(x):
if self.need_contiguous:
x = x.contiguous()
y = self.se(self.norm(self.dwconv(x)))
y = self.pwconv2(self.act(self.pwconv1(y)))
if self.gamma is not None:
y = self.gamma.view(1, -1, 1, 1) * y
return self.drop_path(y) + x
if self.with_cp and inputs.requires_grad:
return checkpoint.checkpoint(_f, inputs)
else:
return _f(inputs)
def reparameterize(self):
if hasattr(self.dwconv, 'merge_dilated_branches'):
self.dwconv.merge_dilated_branches()
if hasattr(self.norm, 'running_var') and hasattr(self.dwconv, 'lk_origin'):
std = (self.norm.running_var + self.norm.eps).sqrt()
self.dwconv.lk_origin.weight.data *= (self.norm.weight / std).view(-1, 1, 1, 1)
self.dwconv.lk_origin.bias.data = self.norm.bias + (self.dwconv.lk_origin.bias - self.norm.running_mean) * self.norm.weight / std
self.norm = nn.Identity()
if self.gamma is not None:
final_scale = self.gamma.data
self.gamma = None
else:
final_scale = 1
if self.act[1].use_bias and len(self.pwconv2) == 3:
grn_bias = self.act[1].beta.data
self.act[1].__delattr__('beta')
self.act[1].use_bias = False
linear = self.pwconv2[0]
grn_bias_projected_bias = (linear.weight.data @ grn_bias.view(-1, 1)).squeeze()
bn = self.pwconv2[2]
std = (bn.running_var + bn.eps).sqrt()
new_linear = nn.Linear(linear.in_features, linear.out_features, bias=True)
new_linear.weight.data = linear.weight * (bn.weight / std * final_scale).view(-1, 1)
linear_bias = 0 if linear.bias is None else linear.bias.data
linear_bias += grn_bias_projected_bias
new_linear.bias.data = (bn.bias + (linear_bias - bn.running_mean) * bn.weight / std) * final_scale
self.pwconv2 = nn.Sequential(new_linear, self.pwconv2[1])
yolov8-unireplknet.yaml
# Ultralytics YOLO , AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# 0-P1/2
# 1-P2/4
# 2-P3/8
# 3-P4/16
# 4-P5/32
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, unireplknet_a, []] # 4
- [-1, 1, SPPF, [1024, 5]] # 5
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']] # 6
- [[-1, 3], 1, Concat, [1]] # 7 cat backbone P4
- [-1, 3, C2f, [512]] # 8
- [-1, 1, nn.Upsample, [None, 2, 'nearest']] # 9
- [[-1, 2], 1, Concat, [1]] # 10 cat backbone P3
- [-1, 3, C2f, [256]] # 11 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]] # 12
- [[-1, 8], 1, Concat, [1]] # 13 cat head P4
- [-1, 3, C2f, [512]] # 14 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]] # 15
- [[-1, 5], 1, Concat, [1]] # 16 cat head P5
- [-1, 3, C2f, [1024]] # 17 (P5/32-large)
- [[11, 14, 17], 1, Detect, [nc]] # Detect(P3, P4, P5)
18、YOLOv8改进:新颖的可扩张残差(DWR)模块,助力小目标检测

DWR加入ultralytics/nn/attention/DWR.py
核心代码:
class DWR(nn.Module):
def __init__(self, dim) -> None:
super().__init__()
self.conv_3x3 = Conv(dim, dim // 2, 3)
self.conv_3x3_d1 = Conv(dim // 2, dim, 3, d=1)
self.conv_3x3_d3 = Conv(dim // 2, dim // 2, 3, d=3)
self.conv_3x3_d5 = Conv(dim // 2, dim // 2, 3, d=5)
self.conv_1x1 = Conv(dim * 2, dim, k=1)
def forward(self, x):
conv_3x3 = self.conv_3x3(x)
x1, x2, x3 = self.conv_3x3_d1(conv_3x3), self.conv_3x3_d3(conv_3x3), self.conv_3x3_d5(conv_3x3)
x_out = torch.cat([x1, x2, x3], dim=1)
x_out = self.conv_1x1(x_out) + x
return x_out19、YOLOv8改进策略:全新的聚焦线性注意力模块(Focused Linear Attention)助力 ViT

如下图所示,本文基于DeiT-tiny模型给出了注意力权重分布的可视化结果。可以看到,Softmax注意力能够产生较为集中、尖锐的注意力权重分布,能够更好地聚焦于前景物体;而线性注意力的分布则十分平均,这使得输出的特征接近所有特征的平均值,无法聚焦于更有信息量的特征。

该方法在ImageNet上使DeiT、PVT、PVT-v2、Swin Transformer、CSwin Transformer等模型架构取得了显著的性能提升,能够将模型在CPU端加速约2.0倍,在GPU端加速约1.5倍。

1.FocusedLinearAttention引入到YOLOv8
2 新建FocusedLinearAttention加入ultralytics/nn/attention/FocusedLinearAttention.py
核心代码:
class FocusedLinearAttention(nn.Module):
r""" Window based multi-head self attention (W-MSA) module with relative position bias.
It supports both of shifted and non-shifted window.
Args:
dim (int): Number of input channels.
window_size (tuple[int]): The height and width of the window.
num_heads (int): Number of attention heads.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set
attn_drop (float, optional): Dropout ratio of attention weight. Default: 0.0
proj_drop (float, optional): Dropout ratio of output. Default: 0.0
"""
def __init__(self, dim, window_size=[20, 20], num_heads=8, qkv_bias=True, qk_scale=None, attn_drop=0., proj_drop=0.,
focusing_factor=3, kernel_size=5):
super().__init__()
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
self.dim = dim
self.num_heads = num_heads
head_dim = dim // num_heads
self.focusing_factor = focusing_factor
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
self.window_size = window_size
self.positional_encoding = nn.Parameter(torch.zeros(size=(1, window_size[0] * window_size[1], dim)))
self.softmax = nn.Softmax(dim=-1)
self.dwc = nn.Conv2d(in_channels=head_dim, out_channels=head_dim, kernel_size=kernel_size,
groups=head_dim, padding=kernel_size // 2)
self.scale = nn.Parameter(torch.zeros(size=(1, 1, dim)))
def forward(self, x, mask=None):
"""
Args:
x: input features with shape of (num_windows*B, N, C)
mask: (0/-inf) mask with shape of (num_windows, Wh*Ww, Wh*Ww) or None
"""
# flatten: [B, C, H, W] -> [B, C, HW]
# transpose: [B, C, HW] -> [B, HW, C]
x = x.flatten(2).transpose(1, 2)
B, N, C = x.shape
qkv = self.qkv(x).reshape(B, N, 3, C).permute(2, 0, 1, 3)
q, k, v = qkv.unbind(0)
k = k + self.positional_encoding[:, :k.shape[1], :]
focusing_factor = self.focusing_factor
kernel_function = nn.ReLU()
q = kernel_function(q) + 1e-6
k = kernel_function(k) + 1e-6
scale = nn.Softplus()(self.scale)
q = q / scale
k = k / scale
q_norm = q.norm(dim=-1, keepdim=True)
k_norm = k.norm(dim=-1, keepdim=True)
if float(focusing_factor) <= 6:
q = q ** focusing_factor
k = k ** focusing_factor
else:
q = (q / q.max(dim=-1, keepdim=True)[0]) ** focusing_factor
k = (k / k.max(dim=-1, keepdim=True)[0]) ** focusing_factor
q = (q / q.norm(dim=-1, keepdim=True)) * q_norm
k = (k / k.norm(dim=-1, keepdim=True)) * k_norm
q, k, v = (rearrange(x, "b n (h c) -> (b h) n c", h=self.num_heads) for x in [q, k, v])
i, j, c, d = q.shape[-2], k.shape[-2], k.shape[-1], v.shape[-1]
z = 1 / (torch.einsum("b i c, b c -> b i", q, k.sum(dim=1)) + 1e-6)
if i * j * (c + d) > c * d * (i + j):
kv = torch.einsum("b j c, b j d -> b c d", k, v)
x = torch.einsum("b i c, b c d, b i -> b i d", q, kv, z)
else:
qk = torch.einsum("b i c, b j c -> b i j", q, k)
x = torch.einsum("b i j, b j d, b i -> b i d", qk, v, z)
num = int(v.shape[1] ** 0.5)
feature_map = rearrange(v, "b (w h) c -> b c w h", w=num, h=num)
feature_map = rearrange(self.dwc(feature_map), "b c w h -> b (w h) c")
x = x + feature_map
x = rearrange(x, "(b h) n c -> b n (h c)", h=self.num_heads)
x = self.proj(x)
x = self.proj_drop(x)
x = rearrange(x, "b (w h) c -> b c w h", b=B, c=self.dim, w=num, h=num)
return x20、YOLOv8改进:感受野注意力卷积运算(RFAConv),效果秒杀CBAM和CA等 | 即插即用系列
本文改进:感受野注意力卷积运算(RFAConv),解决卷积块注意力模块(CBAM)和协调注意力模块(CA)只关注空间特征,不能完全解决卷积核参数共享的问题
RFAConv| 亲测在多个数据集能够实现大幅涨点,有的数据集达到3个点以上
1.RFAConv介绍

论文:https://arxiv.org/pdf/2304.03198.pdf
摘要:空间注意力已被广泛用于提高卷积神经网络的性能。 然而,它有一定的局限性。 在本文中,我们提出了空间注意力有效性的新视角,即空间注意力机制本质上解决了卷积核参数共享的问题。 然而,空间注意力生成的注意力图中包含的信息对于大尺寸的卷积核来说是不够的。 因此,我们提出了一种新颖的注意力机制,称为感受野注意力(RFA)。 现有的空间注意力,例如卷积块注意力模块(CBAM)和协调注意力(CA)仅关注空间特征,并没有完全解决卷积核参数共享的问题。 相比之下,RFA 不仅关注感受野空间特征,还为大尺寸卷积核提供有效的注意力权重。 RFA 开发的感受野注意力卷积运算(RFAConv)代表了一种替代标准卷积运算的新方法。 它提供的计算成本和参数增量几乎可以忽略不计,同时显着提高了网络性能。 我们在 ImageNet-1k、COCO 和 VOC 数据集上进行了一系列实验,以证明我们方法的优越性。 特别重要的是,我们认为现在是时候将当前空间注意机制的焦点从空间特征转移到感受野空间特征了。 这样,我们就可以进一步提升网络性能,取得更好的效果。
关于感受野空间特征,我们提出感受野注意(RFA)。 这种方法不仅强调感受野滑块内不同特征的重要性,而且优先考虑感受野空间特征。 通过这种方法,彻底解决了卷积核参数共享的问题。 感受野空间特征是根据卷积核的大小动态生成的,因此,RFA是卷积的固定组合,离不开卷积运算的帮助,同时依靠RFA来提高性能,所以我们 提出感受野注意卷积(RFAConv)。 具有3×3尺寸卷积核的RFAConv的整体结构如图2所示。
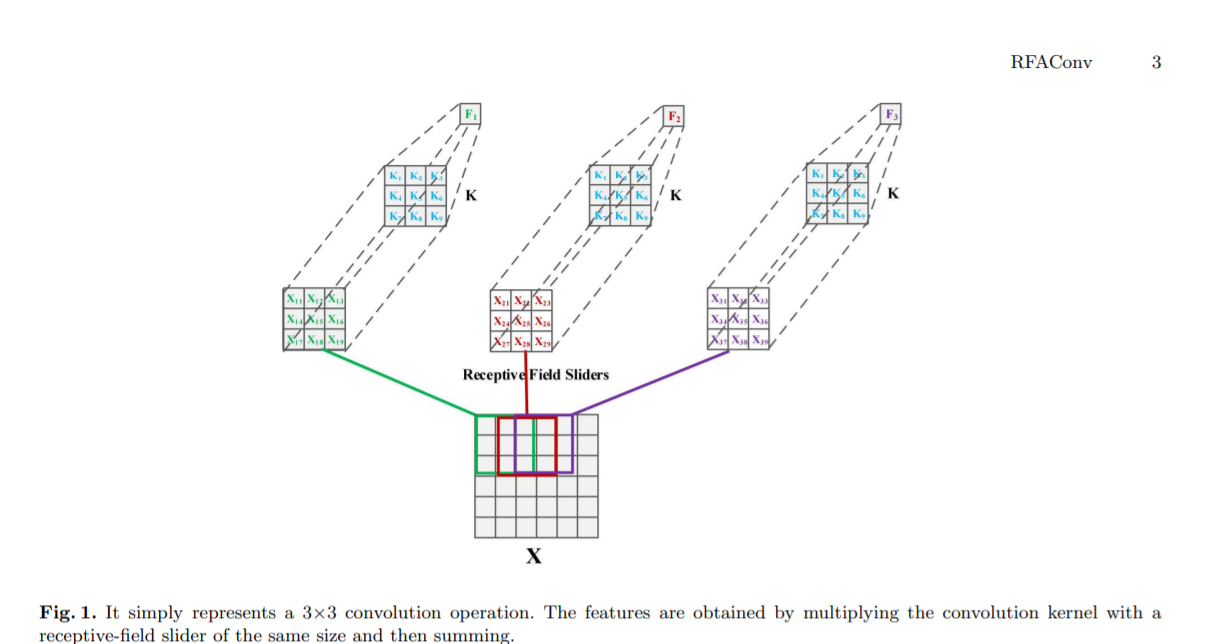
作者设计了一种新的CBAM和CA,称为RFACBAM和RFACA,它专注于感受野的空间特征。与RFA类似,使用stride为k的k×k的最终卷积运算来提取特征信息,具体结构如图4和图5所示,将这2种新的卷积方法称为RFCBAMConv和RFCAConv。比较原始的CBAM,使用SE注意力来代替RFCBAM中的CAM。因为这样可以减少计算开销。
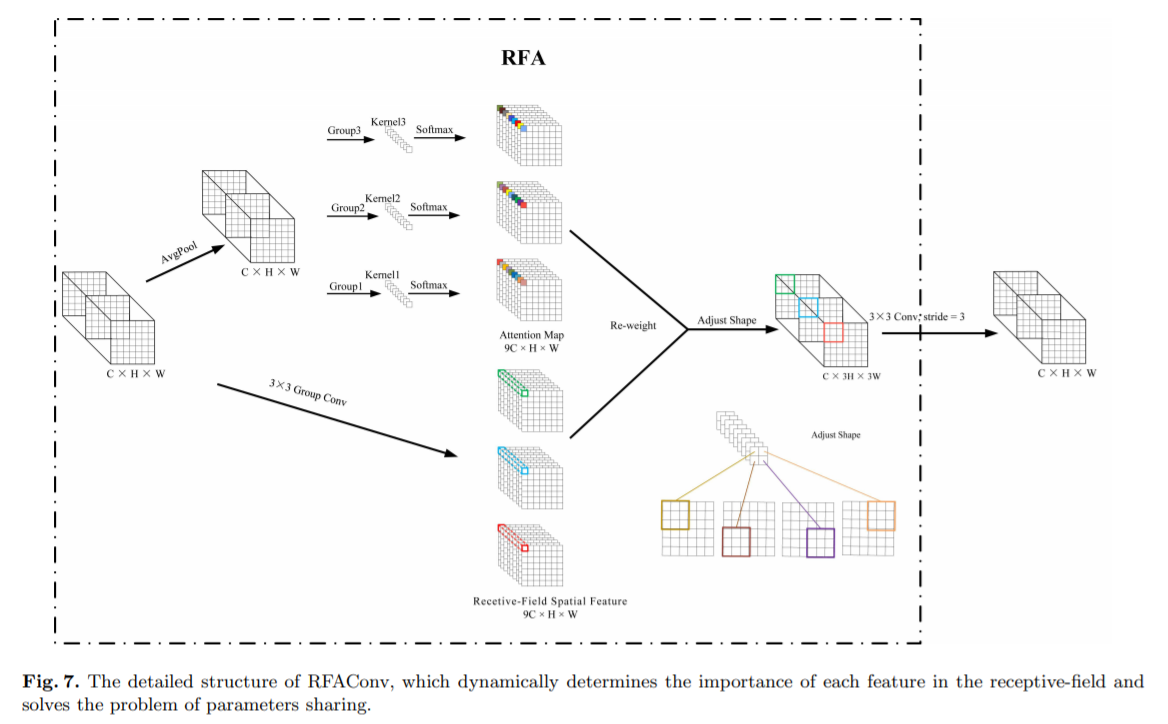
实验结果
分类
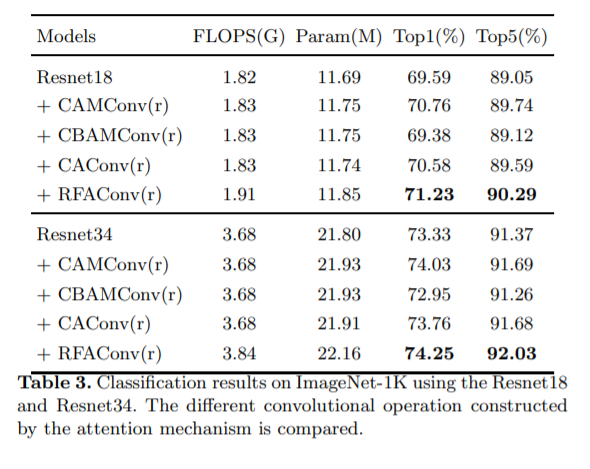
目标检测
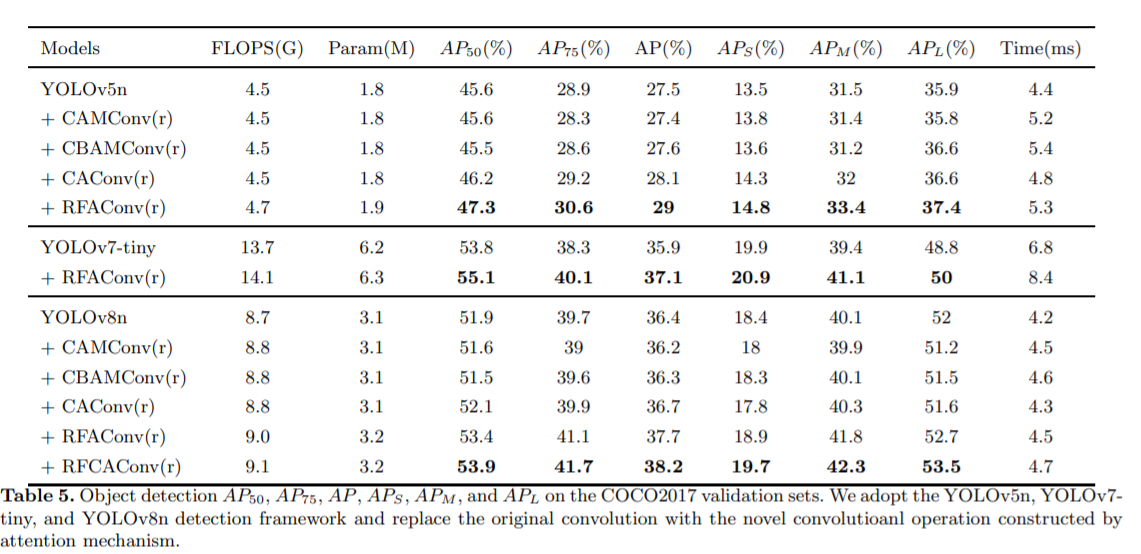
2.RFA加入到yolov8
2.1 新建ultralytics/nn/Conv/RFA.py
class DyCAConv(nn.Module):
def __init__(self, inp, oup, kernel_size, stride, reduction=32):
super(DyCAConv, self).__init__()
self.pool_h = nn.AdaptiveAvgPool2d((None, 1))
self.pool_w = nn.AdaptiveAvgPool2d((1, None))
mip = max(8, inp // reduction)
self.conv1 = nn.Conv2d(inp, mip, kernel_size=1, stride=1, padding=0)
self.bn1 = nn.BatchNorm2d(mip)
self.act = h_swish()
self.conv_h = nn.Conv2d(mip, inp, kernel_size=1, stride=1, padding=0)
self.conv_w = nn.Conv2d(mip, inp, kernel_size=1, stride=1, padding=0)
self.conv = nn.Sequential(nn.Conv2d(inp, oup, kernel_size, padding=kernel_size // 2, stride=stride),
nn.BatchNorm2d(oup),
nn.SiLU())
self.dynamic_weight_fc = nn.Sequential(
nn.Linear(inp, 2),
nn.Softmax(dim=1)
)
def forward(self, x):
identity = x
n, c, h, w = x.size()
x_h = self.pool_h(x)
x_w = self.pool_w(x).permute(0, 1, 3, 2)
y = torch.cat([x_h, x_w], dim=2)
y = self.conv1(y)
y = self.bn1(y)
y = self.act(y)
x_h, x_w = torch.split(y, [h, w], dim=2)
x_w = x_w.permute(0, 1, 3, 2)
a_h = self.conv_h(x_h).sigmoid()
a_w = self.conv_w(x_w).sigmoid()
# Compute dynamic weights
x_avg_pool = nn.AdaptiveAvgPool2d(1)(x)
x_avg_pool = x_avg_pool.view(x.size(0), -1)
dynamic_weights = self.dynamic_weight_fc(x_avg_pool)
out = identity * (dynamic_weights[:, 0].view(-1, 1, 1, 1) * a_w +
dynamic_weights[:, 1].view(-1, 1, 1, 1) * a_h)
return self.conv(out)未完待续~继续更新
总结
写到这,cv君都还有很多公开的技巧和独家的优化技巧没写完,大家欢迎点赞关注收藏,以后优化到了很好的效果,和实战例子,我会继续更新,感谢大家。
最近开始在空闲之余,经常更新文章啦!除目标检测、分类、分隔、姿态估计等任务外,还会涵盖图像增强领域,如超分辨率、画质增强、降噪、夜视增强、去雾去雨、ISP、海思高通成像ISP等、AI-ISP、还会有多模态、文本nlp领域、视觉语言大模型、lora、chatgpt等理论与实践文章更新,更新将变成一周2-3更,一个月争取10篇,重回创作巅峰,之前cv君曾在csdn排行前90名总榜,感谢大家观看点赞和收藏;有任何问题可以文末微信联系或私聊我,微信:zxx15277368495z。