key-value数据库,,nosql非关系数据库
https://github.com/tporadowski/redis/releases
值可以是字符串、哈希、列表、集合和有序集合等类型
开启服务器
redis-server.exe redis.windows.conf
开启客户端
redis-cli.exe
设置ip 端口
redis-cli.exe -h 127.0.0.1 -p 6379
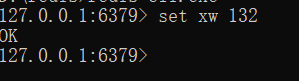
插入数据
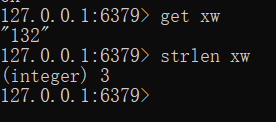
set xw 132
xw为键 132为值
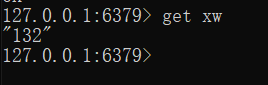
获取值
获取程度
strlen xw
追加长度
append xw 1222

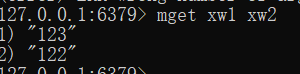
同时设置多个 获取多个
mset xw1 123 xw2 122
mget xw1 xw2

列表类型
列表能够让一个键对应多个值
左端插入
lpush key v1 v2 [v2,v1]
右端插入
rpush key v1 v2 [v1,v2]
中间插入
linsert key after v1 v3
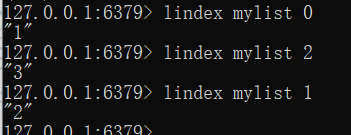
rpush mylist 1 2 5
获取内容
lindex mylist 0
lindex mylist 1
lindex mylist 2
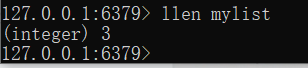
获取长度
llen mylist
获取指定范围内容
lrange key start stop
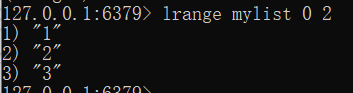
lrange mylist 0 2
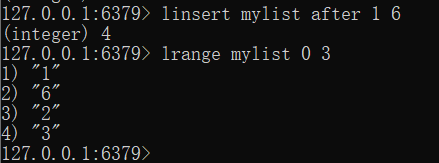
中间插入
linsert key after v1 v3
linsert mylist after 0 55

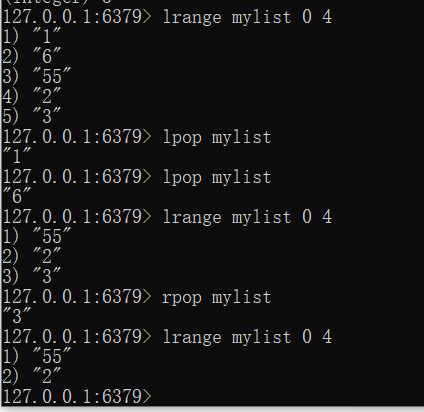
弹出内容
lpop
rpop
弹出内容-阻塞版本
blpop key timeout
brpop ket timeout
brpop mylist 10

内容为空时 等待10秒
哈希类型
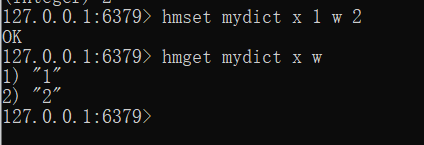
hmset name key value key value
hmget name key key..
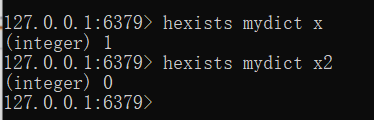
判断是否存在某字段
hexists name key
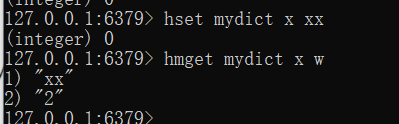
修改或添加
hset name key value
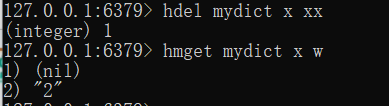
删除字段
hdel name key value
集合类型-去重
集合成员是唯一的,不能出现重复的数据
添加数据
sadd key v1 v2 v3

获取长度
scard key

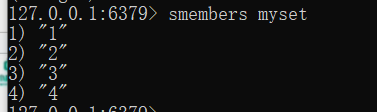
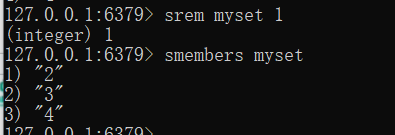
列出成员
smembers key
删除数据
srem key v1
判断存在
sismember key v1

redis设置过期时间
自动过期时间
lpush "spider cache" "baidu" "google"
expire "spider cache" 60*10
查看剩余过期时间
TTL "spider cache"
判断存在
exists "spider cache"

redis事务
启动事务 multi
放弃事务 discard
提交事务 exec
监控键 watch(如果在事务exec之前修改了键,则取消事务)

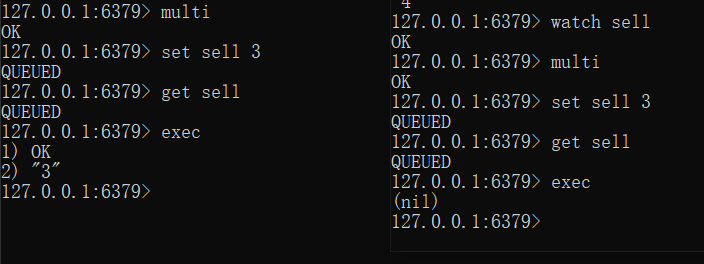
redis和关系型数据库的事务区别
redis没有回滚
- 如果语法错误,exec不会被执行–原子性
- 如果执行过程错误,发生错误之后的命令继续执行-打破原子性
redis消息发布订阅机制
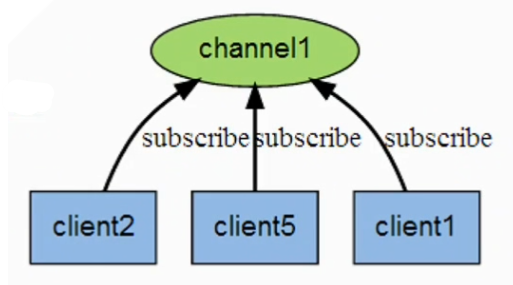
发布订阅模式Pubsub
经典消息传递机制,即频道把数据发送出去
订阅了该频道的用户会受到消息
kafka和zeroMQ这些消息中间件就使用了这个模式构建消息投递
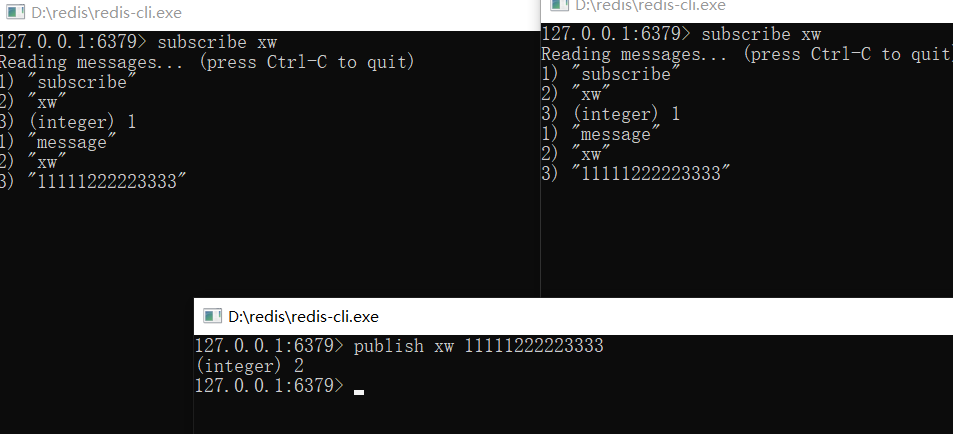
subscribe 用于订阅
publish 用于发布
pubsub channels 用于展示频道
unsubscribe 用于退订
当频道无订阅时会自动销毁,而且订阅消息不支持持久化
订阅

发布消息
redis持久化-RDB
因为redis数据存储在内存中,重启后所有数据会清空
为了将数据弄到磁盘上,redis提供了两种持久化类型RDB和AOF
RDB可以看做是redis的快照,非常适合备份,恢复可直接读入内存
默认自动RDB,手动写入:
save:同步方式,会阻塞
bgsave:异步方式,fork子进程处理
数据恢复:config get dir
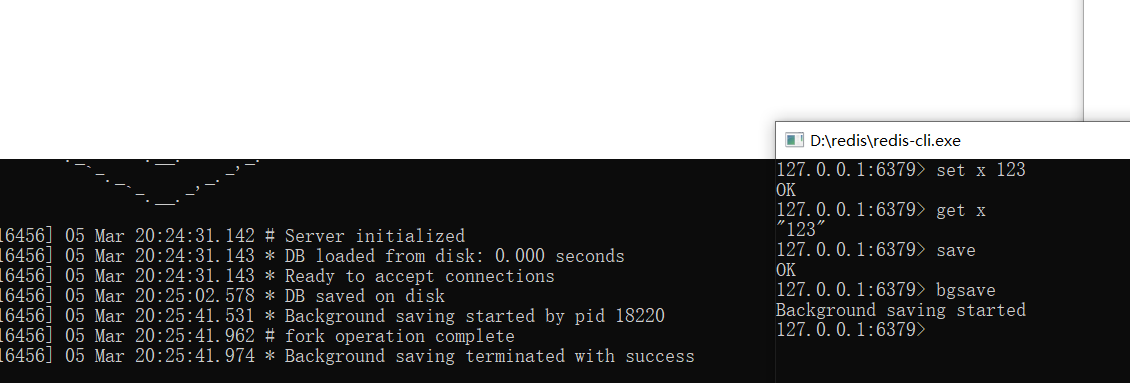
关闭服务 重新开启 自动数据恢复
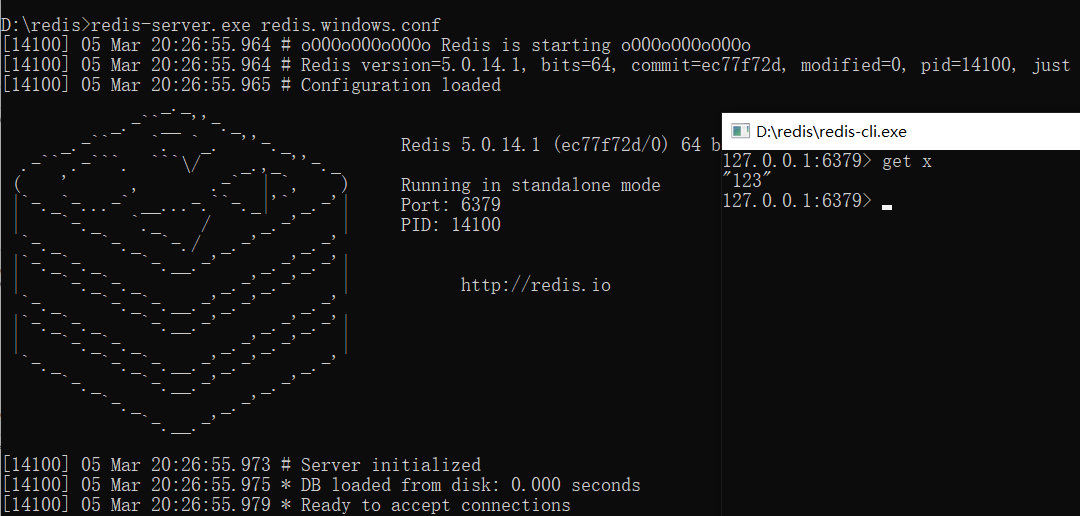
自动RDB机制
save 900 1:表示900 秒内如果至少有 1个 key 的值变化,则保存
save 300 10:表示300 秒内如果至少有10 个 key 的值变化,则保存
save 60 10000:表示60 秒内如果至少有10000 个 key 的值变化,则保存
其他配置:
stop-writes-on-bgsave-error :当启用了RDB且最后一次后台保存数据失败,Redis是否停止接收数据
rdbcompression:对于存储到磁盘中的快照,可以设置是否进行压缩存储
rdbchecksum:在存储快照后,我们还可以让redis使用CRC64算法来进行数据校验但是这样做会增加大约10%的性能消耗
dbfilename:设置快照的文件名,默认是 dump.rdb
dir:设置快照文件的存放路径,这个配置项一定是个目录,而不能是文件名。默认是和当前配置文件保存在同一目录。
AOF
记录写入命令的追加模式,每个写入都会被记录
config set appendonly yes
原理:redis先把写入数据写入缓冲区,缓冲区的数据被fsync()之后刷到磁盘。redis关闭的时候,自动调用一次fsync
bgrewriteaof:重写会创建一个当前 AOF 文件的体积优化版本。
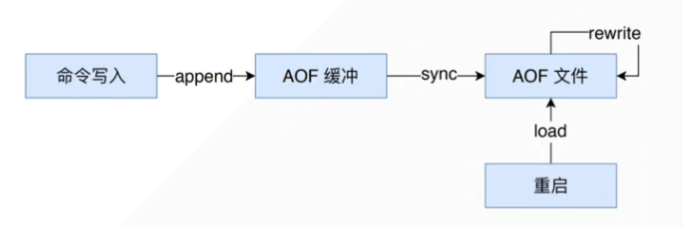
配置
appendfsync always:每个写入都fsync
appendfsync everysec:每一秒一次fsync
appendfsync no:用于fsync,由系统决定时间,linux为30s
auto-aof-rewrite-percentage 100
#当前AOF文件大小和上一次重写时AOF文件大小的比值
auto-aof-rewrite-min-size 64mb
#文件的最小体积
如果只配置 AOF ,重启时加载 AOF 文件恢复数据
如果同时配置了 RDB 和 AOF,启动是只加载 AOF 文件恢复数据
如果只配置 RDB,启动是将加载 dump 文件恢复数据
Python操作redis连接池
import redis
import threading
pool = redis.ConnectionPool(host='127.0.0.1',port=6379)
r = redis.Redis(connection_pool=pool)
#操作
def get_set():
r.set(threading.currentThread().getName(),threading.currentThread().getName())
print(r.get(threading.currentThread().getName()))
ts=[]
for i in range(10):
ts.append(threading.Thread(target=get_set))
for t in ts:
t.start()
t.join()
Python操作pipeline事务
import redis
pool = redis.ConnectionPool(host='127.0.0.1',port=6379)
r = redis.Redis(connection_pool=pool)
#管道通信 QUEUED
#代码写错了 get-got 执行时候报错
try:
pipe=r.pipeline()
pipe.set("hello2","world2")
pipe.execute()
except Exception as err:
print(err)
print(r.get("hello2"))
redis主从复制
生产环境中,单个服务器往往存在崩溃、宕机,网络故障等原因。
为了提高容错能力,redis提供了主从复制,能够将一个服务器的数据,同时同步到多个备份服务器当中。
如果开发的应用是重读取的,我们可以增加多个redis实例减轻主机压力
- 复制一份redis.windows.conf
- 修改部分配置
port 6380
dir ./slave
slaveof 127.0.0.1 6379
输入info replications可以查看当前角色
Python实现redis发布订阅
当你有一个耗时的任务要执行
但是结果不需要马上返回
那就可以把任务分派出去,去慢慢执行
即便发布端关闭,依旧可以收到消息
发布订阅
import redis
pool = redis.ConnectionPool(host='127.0.0.1',port=6379)
r = redis.Redis(connection_pool=pool)
while True:
data=input('>>>')
r.publish("test",data)
订阅客户端
import redis
pool = redis.ConnectionPool(host='127.0.0.1',port=6379)
r = redis.Redis(connection.pool)
pub = r.pubsub()
pub.subscribe('test')
pub.parse_response()
while True:
print('监听开始')
meaaage = pub.parse_response()
print(meaaage)
print(meaaage[2].decode('utf-8))
if meaaage[2].decode('utf-8)=='exit':
m=pub.unsubscribe('test')
print(m)
print('取消订阅成功')
break