摘要
我们提出了HI-SLAM2,一个几何感知的高斯SLAM系统,仅使用RGB输入即可实现快速准确的单目场景重建。现有的神经SLAM或基于3dgs的SLAM方法经常在渲染质量和几何精度之间进行权衡,我们的研究表明,单独使用RGB输入可以同时实现这两者。我们的方法的关键思想是通过将易于获得的单目先验与基于学习的密集SLAM相结合,然后使用3D Gaussian splating作为我们的核心地图表示来有效地建模场景,从而增强几何估计的能力。在回环检测后,我们的方法通过有效的姿态图BA和基于锚定关键帧更新的三维高斯单元显式变形来确保实时的全局一致性。此外,我们引入了一种基于网格的尺度对齐策略,以保持先前深度的尺度一致性,以获得更精细的深度细节。通过在Replica, ScanNet和ScanNet上的大量实验,我们证明了对现有Neural SLAM方法的显着改进,甚至在重建和渲染质量方面超过了基于rgb - d的方法。项目页面和源代码将在https://hislam2.github.io/上提供。
III. METHODS
我们的系统旨在实现快速准确的摄像机跟踪和单目RGB输入的场景重建。
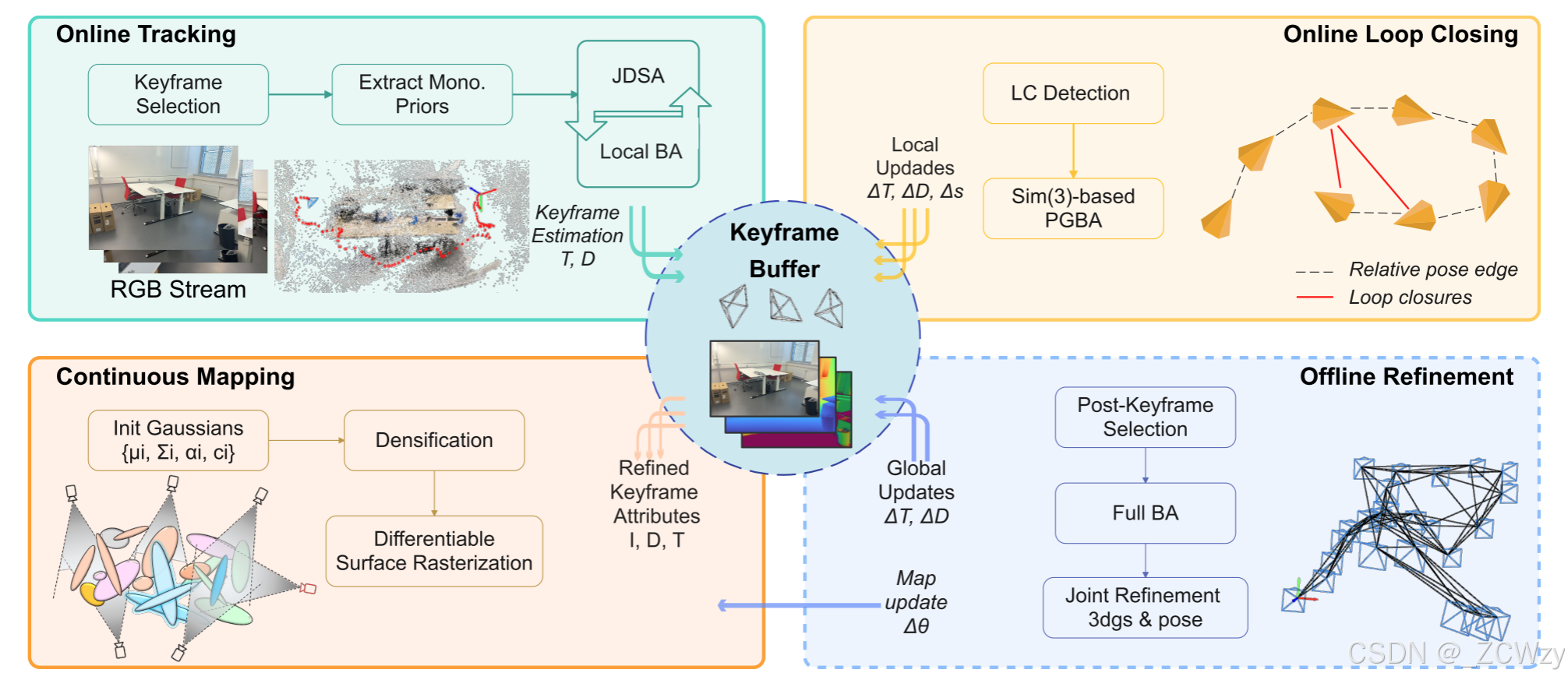
图3:系统概述:我们的框架由四个关键阶段组成:在线相机跟踪,在线回环检测,在线映射,连续映射和离线优化。相机跟踪使用基于循环网络的方法来估计相机姿势并从RGB输入生成深度图。对于3D场景表示,我们使用3DGS对场景几何建模,从而实现高效的在线地图更新。这些更新与姿态图BA集成,用于在线回环检测,实现快速更新和高质量渲染。在离线优化阶段,对相机姿态和场景几何进行充分的BA,然后对高斯基元和相机姿态进行联合优化,进一步增强全局一致性。
如图3所示,该系统包括四个关键组件:在线跟踪器、在线闭环模块、连续建图器和离线优化阶段。在线相机跟踪器(第III-A节)利用基于学习的密集SLAM前端来估计相机姿势和深度图。通过在线环闭合模块(第III-B节)实现全局一致性和实时性,该模块将环闭合检测与高效的姿态图束调整(PGBA)相结合。对于场景表示,我们采用3D高斯喷溅(3DGS)(章节III-C),实现高效的在线地图构建,更新和高质量渲染。离线细化阶段(section III-D)通过全BA增强重建质量,高斯图和相机姿态的联合优化确保了最优的全局一致性。最终的网格是通过TSDF融合融合渲染深度图生成的。
A. Online Tracking
在线跟踪模块建立在基于学习的密集视觉SLAM方法(DROID-SLAM)上,以估计关键帧的相机姿势和深度图。通过循环光流网络利用密集的逐像素信息,我们的系统可以在具有挑战性的场景中稳健地跟踪相机,例如低纹理环境和快速运动。为了匹配所有重叠帧之间的逐像素对应关系,我们构建了一个关键帧图,它表示每对关键帧之间的共视关系。图节点
对应关键帧,每个关键帧包含一个姿态T∈SE(3)和一个估计深度图d。图边E连接有足够重叠的关键帧,由它们的光流对应关系决定。为了使估计的状态与其他模块同步,帮助连续映射和在线闭环,维护一个关键帧缓冲区来存储所有关键帧及其各自的状态信息。
追踪器从关键帧选择开始,对每一输入帧进行评估,以确定它是否应被选作关键帧。这一决策基于通过单次运行光流网络 [21] 计算出的相对于上一关键帧的平均光流距离,以及一个预设的阈值。对于选定的关键帧,我们通过预训练的神经网络[24]提取单目先验,包括深度先验和正常先验。当深度先验被跟踪器模块直接用于深度估计时,法线先验被场景表示映射器用于3D高斯地图优化作为额外的几何线索。
根据DROID-SLAM,我们在收集了个关键帧后初始化系统状态。初始化过程是在关键帧图上进行BA,其中边连接索引距离在3以内的关键帧,以确保有足够的重叠来实现可靠的收敛。由于单目系统没有绝对尺度,我们通过将所有关键帧深度的均值设为1来对尺度进行归一化。在后续的BA优化中,通过固定前两个关键帧的位姿来保持该尺度作为系统尺度。之后,每当添加一个新的关键帧时,我们都会进行局部光束法平差来估计当前关键帧图中关键帧的相机位姿和深度图。新关键帧与有足够重叠的相邻关键帧之间的边会被添加到图中。利用光流预测
,通过使用由光流预测得到的目标点
来最小化重投影误差,其中相机位姿和深度作为源数据。局部光束法平差优化问题可表述为:
---公式(1)
其中表示从关键帧
到关键帧
的刚体变换,
指关键帧
在逆深度参数化下的深度图,
和
分别表示相机投影和反投影函数。
是一个对角元素表示来自光流网络的预测置信度的权重矩阵。该置信度通过减少由遮挡或低纹理区域导致的异常值的影响,有效地确保了优化的稳健性。在置信度不足的区域(即无法准确估计深度的区域)中的深度估计将在后续步骤中使用单目深度先验进一步优化。
结合单目深度先验:为了克服在低纹理或遮挡区域等困难区域进行深度估计的挑战,我们将易于获取的单目深度先验[24]纳入在线跟踪过程。在(DROID-SLAM)的RGB - D模式下,深度观测值在光束法平差(BA)优化过程中直接用于计算均方误差。然而,我们不能直接采用这种方式,因为预测的单目深度先验存在尺度不一致的问题。为了解决这个问题,[36]提出将每个深度先验的深度尺度和偏移量作为优化参数进行估计。尽管这种方法有助于校准整体先验尺度,但我们发现它不足以完全校正单目深度先验中固有的尺度畸变。
为了进一步改进这一点,我们提议为每个深度先验估计一个具有
维系数
的二维深度尺度网格。每个像素处的深度尺度可以通过基于其周围四个网格系数的双线性插值
在网格上获得。这种空间变化的尺度公式使先验深度与通过光束法平差(BA)估计的深度更灵活地对齐,并有助于减少深度先验中的噪声影响。利用采样的深度尺度,可以得到尺度对齐的深度先验为
。然后我们将深度先验因子
表述如下:
正如[36]中所报道的,直接将深度先验因子纳入光束法平差(BA)优化中,即联合优化相机位姿、深度和尺度系数,会使系统容易出现尺度漂移并阻碍收敛。为了解决这个问题,与[36]中的方法类似,我们引入了一个联合深度和尺度对齐(JDSA)模块,用以下目标来分别估计先验尺度:
通过将联合深度和尺度对齐(JDSA)优化与局部光束法平差(BA)优化交错进行,我们确保系统尺度保持稳定且深度先验得到很好的对齐,从而提供具有更好初始猜测的深度估计。我们使用阻尼高斯 - 牛顿算法来解决优化问题。为了优化效率,我们将尺度和深度变量分离如下:
其中是海森矩阵(Hessian matrix)的分块,
和
是线性化系统的梯度向量。由于矩阵
的维度比
小得多,我们可以通过先求解
,然后利用舒尔补(Schur complement)求解
来高效地求解该系统。
矩阵是对角矩阵,因为深度变量相互独立,并且它可以高效地求逆,即
。

Fig. 4: Example of scale alignment of monocular depth.
图4展示了单目深度先验的尺度对齐示例。请注意,估计出的空间变化尺度使得单目深度先验与真实深度很好地对齐。
B. Online Loop Closing
虽然我们的在线追踪器能够稳健地估计相机位姿,但测量噪声不可避免地会随着时间和移动距离的增加而累积,这会导致位姿漂移。此外,由于单目系统本身无法观测尺度,所以容易出现尺度漂移。为了校正位姿和尺度漂移并增强三维地图的全局一致性,我们的在线闭环模块会搜索潜在的闭环,并使用[36]中首次提出的基于的渐进式全局光束法平差(PGBA)对所有关键帧的历史数据进行全局优化。
闭环检测:闭环检测与在线跟踪并行执行。对于每个选定的新关键帧,我们计算新关键帧与所有先前关键帧之间的光流距离。 我们定义了三个标准来选择闭环候选帧。首先,
必须低于预定义的阈值
,以确保在循环流更新时具有足够的共视性以实现可靠收敛。其次,基于当前位姿估计的方向差异应保持在阈值
内。最后,帧索引差异必须超过当前局部光束法平差(BA)窗口之外的最小阈值
。当所有标准都满足时,我们在关键帧图中添加连接关键帧对的正向和反向重投影方向的边。
基于Sim(3)的位姿图光束法平差:当识别出闭环候选帧时,受[58]、[36]中提出的光束法平差(PGBA)效率的启发,我们选择位姿图光束法平差而非全光束法平差,以平衡计算效率和精度。 为了解决尺度漂移问题,我们采用表示关键帧位姿,从而实现如[59]中所提出的逐关键帧尺度校正。在每次优化运行之前,我们将最新的位姿估计从
转换为
组,并将尺度初始化为1。像素扭曲步骤遵循公式(1),其中
变换被
变换所取代。
构建位姿图需要通过相对位姿边来连接位姿。根据[58]、[36],我们从密集对应关系中推导出相对位姿,这些密集对应关系来自于非活动重投影边,当它们相关的关键帧离开局部光束法平差(BA)的滑动窗口时,这些非活动重投影边会被保留下来。这些密集对应关系为计算相对位姿提供了可靠的基础,因为它们在滑动窗口中处于活动状态时已经经过多次迭代优化。使用了来自公式(1)的重投影误差项,但在这里,在假设深度估计是准确的前提下,优化仅关注相对位姿。为了考虑不确定性,我们根据平差理论[60]估计相对位姿的方差
如下:
其中、
和
分别是雅可比矩阵、重投影残差和上一次迭代的相对位姿更新量。这些方差在渐进式全局光束法平差(PGBA)中用作权重。PGBA的最终目标是最小化相对位姿因子和重投影因子的总和:
其中表示检测到的回路闭包,
表示相对姿态因子的集合。为了保证优化的收敛性,并考虑到相对位姿因素中可能存在的异常值,我们采用阻尼版的高斯-牛顿算法求最优解如下:
其中\(H\)表示海森矩阵(Hessian matrix)。阻尼因子和正则化因子
起到两个关键作用:防止收敛到局部最小值和改善数值条件,同时保持快速收敛。优化后,我们将优化后的位姿转换回
以便后续跟踪。深度图根据相应的
位姿变换进行缩放。此外,如在章节Ⅲ - C中详细描述的那样,我们根据其锚关键帧(anchor keyframes)的位姿更新来更新3D高斯基元。
C. 3D Scene Representation
采用3DGS作为我们的场景表示模型来对场景外观和几何形状进行建模。与诸如NeRF等隐式神经表示不同,3DGS提供了一种显式表示,能够实现高效的在线地图更新和高质量渲染。场景由一组3D各向异性高斯分布表示,其中每个3D高斯单元定义为:
其中表示高斯均值,
表示世界坐标中的协方差矩阵。协方差矩阵
分解为方向
和尺度
,即
。每个高斯分布还具有不透明度
和颜色
的属性。与原始的3DGS不同,我们通过使用直接的RGB值而非球谐函数来简化颜色表示,从而降低了优化复杂度。为了处理依赖于视角的颜色变化,我们在离线细化阶段(第Ⅲ - D节)采用了曝光补偿。
渲染过程使用透视变换将这些3D高斯投影到图像平面上:
其中表示透视变换的雅可比矩阵,
表示关键帧姿态
的旋转矩阵。 在对投影后的2D高斯进行基于深度的排序后,沿着每条射线从近到远通过α混合计算像素颜色和深度:
其中表示与射线相交的高斯集合,
是第
个高斯的颜色,
是通过评估第
个高斯在交点处的不透明度计算得到的像素透明度。
无偏深度:先前的研究直接使用高斯均值处的深度,当光线在远离高斯均值的点与高斯相交时,这会引入估计偏差。按照[34]中的方法,我们通过确定沿光线方向实际的光线 - 高斯交点来计算无偏深度。该深度是通过求解光线与高斯曲面相交处的平面方程来计算的。由于来自同一视点且与给定高斯相交的所有光线共面,因此每个高斯只需求解一次相交方程。这种方法在保持基于离散点渲染(splat - based rasterization)的计算效率的同时,显著提高了深度精度。我们将在第四节G部分通过消融研究展示这种无偏深度计算的优势。
地图更新:地图更新过程根据关键帧位姿的更新来调整3D高斯单元,以确保3D地图的全局一致性。这种更新既在基于的渐进式光束法平差(PGBA)在线过程中发生,也在全局全光束法平差(BA)离线过程中发生。为了能够对3D场景表示进行快速且灵活的更新,我们对每个高斯单元的均值、方向和尺度进行变形。具体而言,均值和方向根据之前和更新后的关键帧之间的相对
位姿变化进行变换,而尺度则使用从
位姿表示中导出的尺度因子进行调整。 每个高斯单元的更新方程如下:
其中 ,
和
分别表示第
个高斯的更新后均值、方向和尺度。这种变换确保了在适应精细的关键帧位姿时高斯之间的几何关系得以保留,维持了3D重建的准确性和完整性。
曝光补偿:由于光照变化和依赖于视角的反射,现实世界中的拍摄在不同视角下会呈现出不同的曝光。这些变化会导致颜色不一致,从而显著影响重建质量。按照[32]、[61]的方法,我们通过优化每关键帧的曝光参数(通过一个3×4仿射变换矩阵)来解决这一问题。对于渲染图像,曝光校正公式如下:
其中表示 3×3 颜色变换矩阵,
表示 3×1 偏差向量。在离线细化阶段,这些曝光参数会与相机位姿和场景几何形状一起联合优化,详见第三章D节。
地图管理:为确保新观测到的区域能得到很好的表示,将每个新关键帧的估计深度图反投影到三维空间来添加高斯分布。为保持地图的紧凑性并防止冗余,我们在对三维位置进行下采样之前,应用因子为的随机下采样来初始化新的高斯分布。为了控制地图增长,我们实施了一种剪枝策略,移除不透明度低的高斯分布。我们每500次迭代重置一次不透明度值,并且每150次迭代进行交错的密集化和剪枝操作,以平衡地图大小和质量。关于地图大小演变的详细分析在第四节H部分呈现。
优化损失:3DGS 表示通过结合光度、几何和正则化损失进行优化。光度损失度量曝光补偿后的渲染图像
与观测图像
之间的
差异。深度损失
计算渲染深度与通过交错 BA 和 JDSA 优化得到的估计深度之间的
差异:
其中表示在线映射期间局部窗口中的关键帧或离线细化时的所有关键帧。
为了增强几何监督,我们将法线先验纳入优化中。估计的法线是从渲染深度图中使用沿图像平面轴的深度梯度叉积得到的。法线损失定义为余弦嵌入损失:
为了防止由于过度细长的高斯分布产生的伪影,我们对 3D 高斯分布的尺度应用正则化项:
其中表示第
个高斯分布的平均尺度,用于惩罚椭圆拉伸。最终损失结合这些项并赋予适当权重如下:
D. Offline Refinement
在线处理之后,我们实施三个顺序的离线优化阶段来增强全局一致性和地图质量:关键帧后插入、全光束法平差(BA),以及联合位姿和地图优化。
Post-keyframe insertion:第一个优化阶段是识别视图覆盖不足的区域,特别是在视锥边界附近的区域。这些区域通常出现在相机向前移动后紧接着向后旋转时,如图5所示。

图5:两种场景下的视图覆盖分析:(a) 最佳情况,连续关键帧保持足够的重叠,确保了适当的多视图覆盖。(b) 次优情况,关键帧Kt中的新观测区域缺乏足够的观测。我们的系统通过插入额外的关键帧后帧(以蓝色显示)来解决这个问题,以增强视图覆盖。
在线处理过程中,关键帧的选择依赖于相邻帧之间的平均光流,因为如果没有未来的轨迹信息,视图覆盖情况无法得到充分评估。为了在离线阶段识别观察不足的区域,我们将每个关键帧的像素投影到其相邻关键帧上,并量化落在相邻关键帧视野之外的像素百分比。当这个百分比超过预定阈值时,我们将该区域标记为观察不足。然后在这些位置插入额外的关键帧,以实现更完整的场景重建,并保留场景边界处的关键细节。
Full Bundle Adjustment :虽然我们的在线闭环模块通过基于的高效渐进式全局光束法平差(PGBA)实现了全局一致性,但全光束法平差(full BA)进一步提高了系统精度。与全光束法平差相比,PGBA具有更高的计算效率,但在将密集对应关系抽象为相对位姿边时会引入轻微的近似误差。具体来说,PGBA仅对闭环边计算重投影因子,而全光束法平差通过对所有重叠关键帧对(包括相邻帧和闭环帧)重新计算公式(1)中的重投影因子来进行全面优化。如第四节G部分所示,这以更精细的粒度提高了相机位姿和场景几何的全局一致性。
联合位姿与地图优化:最后一个优化阶段根据全光束法平差(full BA)的结果联合优化高斯地图和相机位姿。在线建图阶段为了保持实时性能会限制每个关键帧的优化迭代次数,而离线优化则能够对所有关键帧进行全面优化。为了便于联合位姿优化,我们在基于光栅化的渲染过程中计算位姿雅可比矩阵。此外,我们还优化每个关键帧的曝光补偿参数,以确保更好的全局色彩一致性。与采用高斯 - 牛顿算法的全光束法平差阶段不同,这个联合优化步骤利用一阶梯度下降的Adam优化器,并利用我们现有的建图管道。