目录
三维重建是计算机视觉中的一个高层任务,包含了很多底层的计算机视觉技术。传统的三维重建,如SFM(structure from motion),就像是一个系列的pipeline工程,包含了关键点提取、本质矩阵计算、三角化、相机位姿估计、稀疏重建、稠密重建等。
一.Dust3r
1.简述
传统的三维重建将任务拆解为了多个子问题,作者认为这样的设定,存在几个问题:
- 前一个子任务会把误差累进到后一个子任务中,比如匹配的误差就不可避免会给三角化带来影响
- 后一个子任务的信息很难前馈到前一个子任务中,比如相机估计出来的位姿能够用于重建,但重建后的结果却很难前馈到估计位姿过程中去
而DUSt3R则完全不划分任何子任务,输入两张图像就直接通过网络模型来端到端地计算3D点云。
DUSt3R(Dense Unconstrained Stereo 3D Reconstruction),在非标定、不含位姿信息的图像上进行稠密三维重建。如下图,相比传统方法,DUSt3R从非约束的图像集合中直接恢复出对应的相机坐标系下面的三维点位置信息。然后在三维点信息基础上进行相机标定、深度估计、相机位姿估计、稠密三维重建等。DUSt3R利用数据驱动的方式,采用神经网络的方法,直接从2D图像对中估计3D点云信息,从而跳过了传统三维重建方法中的提取特征点、特征点匹配、点云三角化等步骤。使得整个三维重建pipeline变得简洁,仅仅包含了3D点云估计、全局对齐两个步骤。

从2D图像直接估计出3D点云信息,这让重建技术有了新的角度。传统的SFM,会先去构建图像和图像的2D对应关系,然后三角化获得空间点云,然后利用其他图像和已知图像的2D-2D匹配关系,转化为2D-3D匹配关系,使用PnP的方式进行求解。而现在,我们直接拥有了2D图像对应的3D点云信息(相机坐标系下面),剩下的问题就是如何让这些在各自相机坐标系下面的3D点云形成一个完整的场景表达。这就是Global Alignment需要完成的事情。
2.PointMap与ConfidenceMap
先来看一下DUSt3R的输出格式,对于H*W*3的RGB图像而言,最终会输出一个H*W*3的PointMap和一个H*W的ConfidenceMap。其中ConfidenceMap非常好理解,就是每个像素对应的PointMap的置信度,一共有H*W个像素,所以ConfidenceMap的维度是H*W。
而PointMap则是每个RGB图像的像素点对应的三维空间坐标,因为每个空间点是三维坐标,一共有H*W个像素,所以PointMap的维度是H*W*3。
PointMap的物理含义是,从光心与对应像素的组成的射线,遇到的最近的空间结构在相机坐标系中的坐标。但需要注意,这实际上隐含了所有被相机观测的物体都是不透明物体这一假设。如下图,在存在透明/半透明结构时,这时最近的3D点应该是半透玻璃,但实际上因为被半透玻璃遮蔽的物体有更显著的特征,因为基于PointMap大概率无法很好的重建出这类结构。

3.模型结构

USt3R的功能是从2D图像中恢复出相机坐标系下面的三维点。其输入是两张图像,采用的是孪生网络结构。首先,两张图像分别经过参数共享的ViT encoder,然后分别经过transformer decoder(利用cross attention来进行特征交互),随后利用各自的head分别输出点云和置信度。针对图像1分支,输出包括了图像相同大小的置信度特征和图像大小的点云![]() ,其坐标是在图像1代表的camera的相机坐标系。而图像2分支,输出包括了图像相同大小的置信度特征和图像大小的点云
,其坐标是在图像1代表的camera的相机坐标系。而图像2分支,输出包括了图像相同大小的置信度特征和图像大小的点云 ![]() ,其坐标同样是图像1代表的camera的相机坐标系。
,其坐标同样是图像1代表的camera的相机坐标系。
DUSt3R输出的点云是从2D图像中获取的,因为单目相机的深度是不具有唯一性的,因此从两张图像中恢复出来的3D点云是不具备尺度信息的,也就是![]() 不具备实际的物理尺寸。
不具备实际的物理尺寸。
简单来说,输入的两张图像I1、I2会用同一个ViT模型进行编码得到对应的F1、F2,然后基于transformer和cross-attention来融合两帧的信息进行解码,最后把所有解码器的输出用DPT head来融合并输出最终每一帧图像的PointMap与ConfidenceMap。(代码里的head有linear和dpt两种,先用linear进行低分辨率训练,然后dpt在更高分辨率上训练从而节省时间)

简要模型概览
4.损失函数
损失函数由两部分组成,第一部分是3D点空间距离,第二部分是置信度。
3D点距离损失
DUSt3R的损失函数包含两个部分,一个是置信度得分,一个预测点云和真值点云在欧式空间的距离。这里值得一提的是真值点云的获取。因为真值点云是在相机坐标下面,因此当我们有图像对应的深度图和相机的内参以后,我们可以采用公式![]() 获取,其中 i,j 是图像像素坐标值。而为了获取到图像2在camera1的像素坐标系下的点云真值,则需要借助camera1和camera2的位姿信息。也就是利用公式
获取,其中 i,j 是图像像素坐标值。而为了获取到图像2在camera1的像素坐标系下的点云真值,则需要借助camera1和camera2的位姿信息。也就是利用公式![]() 来获取,其中 Pm,Pn 都是世界坐标系到相机坐标系的变换矩阵, h 是普通坐标转化为齐次坐标。因此,在构建训练集的时候,我们就需要获得图像对应的相机内参、以及相机位姿信息,方便构建图像对应的相机坐标系下的点云和在其他相机坐标系下的点云。
来获取,其中 Pm,Pn 都是世界坐标系到相机坐标系的变换矩阵, h 是普通坐标转化为齐次坐标。因此,在构建训练集的时候,我们就需要获得图像对应的相机内参、以及相机位姿信息,方便构建图像对应的相机坐标系下的点云和在其他相机坐标系下的点云。
假设第j张图像(只有两张图,所以j=1或2)的第i个像素在基准坐标系对应的真实空间点为![]() ,而预测出来的为
,而预测出来的为![]() ,那么计算3D回归损失:
,那么计算3D回归损失:

其中![]() 是归一化因子,表示3D点到原点的平均距离。上述loss只衡量了PointMap的3D点与真实3D点之间的误差,但网络还会输出一个ConfidenceMap,还需要把置信度融合进loss里:
是归一化因子,表示3D点到原点的平均距离。上述loss只衡量了PointMap的3D点与真实3D点之间的误差,但网络还会输出一个ConfidenceMap,还需要把置信度融合进loss里:

训练损失函数
下图是网络的输出结果,从左往右依次是原图、深度图、置信图、重建结果。

网络输出结果
5.全局对齐
输入了一个图像集合,两两图像能够构建出很多图像对,利用上面的DUSt3R网络,能够获得对应的置信度和点云,通过置信度信息,能够剔除那些两张图像重合度不够的图像对。
全局对齐的目标就是将所有的预测点云都统一到一个坐标系下面。因为网络一次输出的一对点云是在同一个相机坐标系下面,因此全局对齐部分需要去估计 N 个相机位姿和 N 个尺度因子, N 表示图像对的对数。通过优化公式可以看出,优化的目标是让每个点云转化到世界坐标系中的点云具有一致性,也就是欧式距离最小。
利用全局对齐获得了世界坐标系下面的点云,进一步,通过公式![]() 可以估计出相机的位姿、内参、深度图等信息。其中
可以估计出相机的位姿、内参、深度图等信息。其中
![]() 表示第 n 张图上的第 i,j 像素点对应的点云(世界坐标系下面)。以下是重建结果图:从左往右依次是原图、深度图、置信图、重建结果。
表示第 n 张图上的第 i,j 像素点对应的点云(世界坐标系下面)。以下是重建结果图:从左往右依次是原图、深度图、置信图、重建结果。
作者指出,相比于传统的BA(Bundle Adjustment)利用重投影,在2D图像上进行误差优化,本文的全局对齐是在3D空间中进行优化的,采用了标准的梯度下降法,能够快速地收敛。
二.Mast3r
1.简述
MASt3R是对DUSt3R的改进,MASt3R其实分为了两篇文章,一篇是MASt3R matching,基于DUSt3R的网络主体结构,多了一些模块用于两帧之间的匹配;还有一篇是MASt3R sfm,这篇是基于MASt3R matching做的一个用于多图sfm。因为MASt3R sfm是基于MASt3R matching的网络结构并用到了里面一些NN算法,所以我们先来看MASt3R matching。
2.MASt3R matching
matching的网络结构跟DUSt3R基本保持一致,蓝色的部分是新增的模块。比较明显的是新增了一个head用来提取local feature,然后是多了两个最邻近匹配模块用来构建匹配。

对于H*W*3的输入图像而言,最终除了会输出一个H*W*3的PointMap和一个H*W的ConfidenceMap外,还会为每个像素生成一个长度为d的特征,也就是H*W*3的LocalFeature,也就是用神经网络来提取特征。剩余的网络部分与DUSt3R保持一致。
关于loss部分,MASt3R matching对DUStER的![]() 做了一点小改动,然后新增了匹配loss。
做了一点小改动,然后新增了匹配loss。
具体而言,MASt3R matching取消了不同的深度正则化项,直接用gt的平均深度![]()

然后因为新增了一个用于匹配的head输出,而希望每个像素点最多和另一张图的一个像素点匹配,作者将这部分描述为infoNCE loss,假设gt的匹配点为![]() ,并记
,并记![]() 的输出:
的输出:

有了上述模型与Loss就可以训练了,但是网络的输出还需要经过一些处理,才能得到需要的匹配关系。注意,网络只输出了PointMap和每个像素的LocalFeature,而期望得到的是两个图像之间的像素点级别的匹配,匹配相关的部分就是图中新增的NN模块。
作者在匹配时设计了一个新算法,先对两个图像对应的特征点进行降采样,先得到图像1的特征点对于图像2的正向NN匹配,在从已经匹配上的图像2特征点反向NN匹配到图像1,能够形成闭环的NN匹配关系便成为最终的匹配。一次迭代同时包含正向和反向NN匹配,通过这样就能快速收敛。

到这matching还没结束,还有一步优化,因为之前不是降采样了嘛,降采样之后的最邻近不一定是真的最邻近,所以还要回到原分辨率的图像上去,重新分块再来一遍匹配(无论是分块还是降采样肯定都比直接全局NN快得多)。这样就得到了最终的匹配关系。

3.MASt3R sfm
看总览下pipeline:

虽然看起来MASt3R sfm直接在pipeline里集成了多帧输入,但是因为网络从DUSt3R一脉相承仍然只能一次处理两张图像,只是MASt3R sfm确实在多帧输入的处理方式上存在很多改进,效果也确实好很多。
MASt3R sfm是基于MASt3R matching的网络结构来开展的,MASt3R sfm只用了MASt3R matching里encoder的输出作为tokenFeature(注意不是head输出的LocalFeature),而不需要像素级别的匹配关系。
MASt3R sfm也是像DUSt3R那样,先基于重叠视角构建一个Graph,具体做法如下:
- 根据encoder输出的tokenFeature,使用最远点采样算法(farthest point sampling, FPS)来选出N个关键帧(或控制帧,理解成聚类算法的中心点一样东西),然后把这N个关键帧两两相连,构成
条边
- 剩余的普通帧连接到最近的关键帧上,然后还会通过NN算法连接到最近的k个普通帧上去
在上述过程中计算特征的距离完全是基于tokenFeature,对tokenFeature白化(feature whitening)后计算二进制距离来实现的。而由于一个图像不止一个特征,所以会采用ASMK算法计算相似度来描述两张图像重叠视野,也就是用ASMK相似度来描述两张图像是否接近。
这里使用encoder输出而不是head的输出作为feature的好处是显而易见的:encoder的输入只要一张图像,所以每张图像都过一遍encoder就行了,而encoder又是不可缺少的步骤,相当于提取特征没有开销。
也就是构建pair时用encoder输出作为tokenFeature,而后续的匹配和优化则使用head输出的LocalFeature。
匹配与标准点图
通过上述共视图计算两两pair的PointMap、ConfidenceMap和LocalFeature后,会首先使用MASt3R matching中提到NN算法来匹配一个pair中的2D-3D点(分别得到![]()
![]() ,其中
,其中![]() 表示一个pair中第i张到第j张图的2D-3D匹配点对)。
表示一个pair中第i张到第j张图的2D-3D匹配点对)。
但是从构建共视图中就可以看出来,同一张图像肯定不止参与一个pair的运算,这样相当于一张图像同时有好几个PointMap,每个PointMap都可能有一定误差,而且一对多这样子也不方便后面计算,所以作者将一张图像的所有PointMap合成为一个Canonical PointMap(姑且翻译成标准点图),其实就是PointMap对于置信度的加权平均(这里![]() 表示每个pair,
表示每个pair,![]() 是对应的置信度):
是对应的置信度):

BA优化
回想一下,我们期望得到的输出是3D点云,使用Canonical PointMap作为点云可以吗?显然不可以,首先多帧之间的Canonical PointMap不一定对齐,其次每帧估计出来的Canonical PointMap也不一定准确(比如不满足针孔相机模型,所有2D-3D连线不一定能过光心)。
在DUSt3R里是仅对共视图的连接关系进行多帧优化,相对而言确实比较粗糙。而在MASt3R里,首先会先固定Canonical PointMap来优化出一个尽可能满足针孔相机模型约束的焦距,从而恢复出一个比较接近的相机内参矩阵,这个优化仅涉及自身的Canonical PointMap,所以跟pair什么的没关系,如果图片是不同相机拍的也可以为每个相机做单独的优化:

然后来优化Canonical PointMap对于像素的重投影误差,这会同时优化相机内参K和共视图中pair连接的相对位姿(外参),这是使用3D点误差来优化的。这里的
![]()
是把3D点投影到2D点映射,![]()

这里的c指的是pair中的匹配像素,qc是匹配置信度,可以由MASt3R对应的置信度加权得到。注意这个优化是把所有匹配作为内点来优化对应的Sim3变换,但是实际上不可能所有的匹配都是内点,所以作者又引入了一个用置信度加权的重投影误差优化来尽量消除外点影响,这里的ρ(⋅)是一个鲁棒核函数:
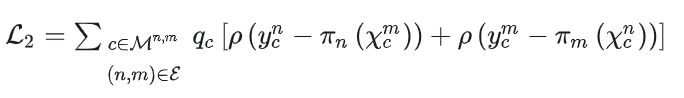

三.Fast3r
1.简述
DUSt3R通过将成对重建问题转化为点图的回归问题能够直接从RGB图像中预测三维结构。这代表了三维重建领域的一次根本性转变,因为端到端可学习的解决方案不仅减少了流程中误差的累积,还显著简化了操作。
然而, DUSt3R的根本是重建两幅图像输入的场景。为了处理多于两幅图像,DUSt3R需要计算O(N²)对点图并执行全局对齐优化过程。这一过程计算成本高昂,随着图像数量的增加,其扩展性较差。 例如,在A100 GPU上仅处理48个视角就可能导致内存溢出(OOM)。另外,两两重建这一过程限制了模型的上下文信息,既影响了训练期间的学习效果,也限制了推理阶段的最终精度。从这个意义上说,DUSt3R与传统SfM和MVS方法一样,面临着成对处理的瓶颈问题。
Fast3R是一种新型的多视图重建框架,旨在克服上面提到的局限性。 FAST3R在Dust3R的基础上,利用Transformer-based架构并行处理多个图像,允许在单个前向传递中重建N个图像。通过消除对顺序或成对处理的需要,每个帧可以在重建期间同时关注输入集中的所有其他帧,从而显著减少错误累积 并且Fast3R推理的时间也大大减少。总的来说,Fast3R是一种基于Transformer的多视角点图估计模型,无需全局后处理,在速度、计算开销和可扩展性方面实现了显著提升。模型性能随着视角数量的增加而提升。
2.模型结构
如图,输入N个无序无pose的RGB图像![]() ,Fast3R预测对应的pointmap
,Fast3R预测对应的pointmap![]() (
(![]() )以及confidence map
)以及confidence map
![]() 来重建场景,不过这里的
来重建场景,不过这里的 ![]() 有两类,一种是全局pointmap
有两类,一种是全局pointmap ![]() ,另一种是局部pointmap
,另一种是局部pointmap ![]() ,confidence map也一样,全局置信图
,confidence map也一样,全局置信图 ![]() ,局部置信图
,局部置信图 ![]() ,比如,在MASt3R中,
,比如,在MASt3R中, ![]() 是在视角1的坐标系下,
是在视角1的坐标系下, ![]() 就是当前相机坐标系:
就是当前相机坐标系:

Fast3R的结构设计来源于DUSt3R,包括三部分:image encoding, fusion transformer,
and pointmap decoding,并且处理图片的方式是 并行 的。
(1)Image encoder
与DUST3R一样,对于任意的图片 ![]() ,encoder部分使用CroCo ViT里面的
,encoder部分使用CroCo ViT里面的 ![]() ,即分成patch提取特征,最后得到
,即分成patch提取特征,最后得到 ![]() ,其中
,其中 ![]() ,记作:
,记作:
![]()
然后,在fusion transformer之前,往patch 特征H里面添加一维的索引嵌入(image index positional embeddings),索引嵌入帮助融合Transformer确定哪些补丁来自同一图像,并且是识别 ![]() 的机制,而
的机制,而 ![]() 定义了全局坐标系。使模型能够从原本排列不变的标记集中隐式地联合推理所有图像的相机pose。
定义了全局坐标系。使模型能够从原本排列不变的标记集中隐式地联合推理所有图像的相机pose。
(2)Fusion transformer
Fast3R 主要的计算在Fusion transformer过程中,我们使用的是与ViTB或 BERT类似的12层transformer,还可以按照比例放大,在此过程中,直接执行all-to-all的自注意力,这样,Fast3R获得了包含整个数据集的场景信息。
(3)pointmap decoding
Fast3R的位置编码细节也很讲究,这个细节大家感兴趣可以仔细看看,可以达到训练20张图,推理1000张图的效果。最后,使用DPT-Large的decoder得到点图 ![]() 以及置信图
以及置信图 ![]() ,下面简单介绍一下DPT-L。
,下面简单介绍一下DPT-L。
DPT探讨了如何将视觉Transformer应用于密集预测任务(如语义分割、深度估计等)。通过引入层次化特征提取、多尺度特征融合以及专门的密集预测头,改进了ViT架构,使其能够有效处理高分辨率输入并生成像素级预测。

3.损失函数
Fast3R的预测 ![]() 与GT的loss是DUST3R的一个广义版本,即归一化 3D 逐点回归损失的置信加权:
与GT的loss是DUST3R的一个广义版本,即归一化 3D 逐点回归损失的置信加权:
![]()
首先,我们回顾DUST3R的点图loss:

在此基础上,使用confidence-ajusted loss:

我们的直觉是置信度加权有助于模型处理标签噪声。与DUST3R类似,我们在真实世界的扫描数据上进行训练,这些数据通常包含底层点图标签中的系统性误差。例如,在真实激光扫描中,玻璃或薄结构通常无法正确重建,而相机配准中的误差会导致图像与点图标签之间的错位。
参考链接:
Dust3r:
https://zhuanlan.zhihu.com/p/686078541
https://zhuanlan.zhihu.com/p/28169401009
Mast3r:
https://zhuanlan.zhihu.com/p/17982445115
Fast3r: