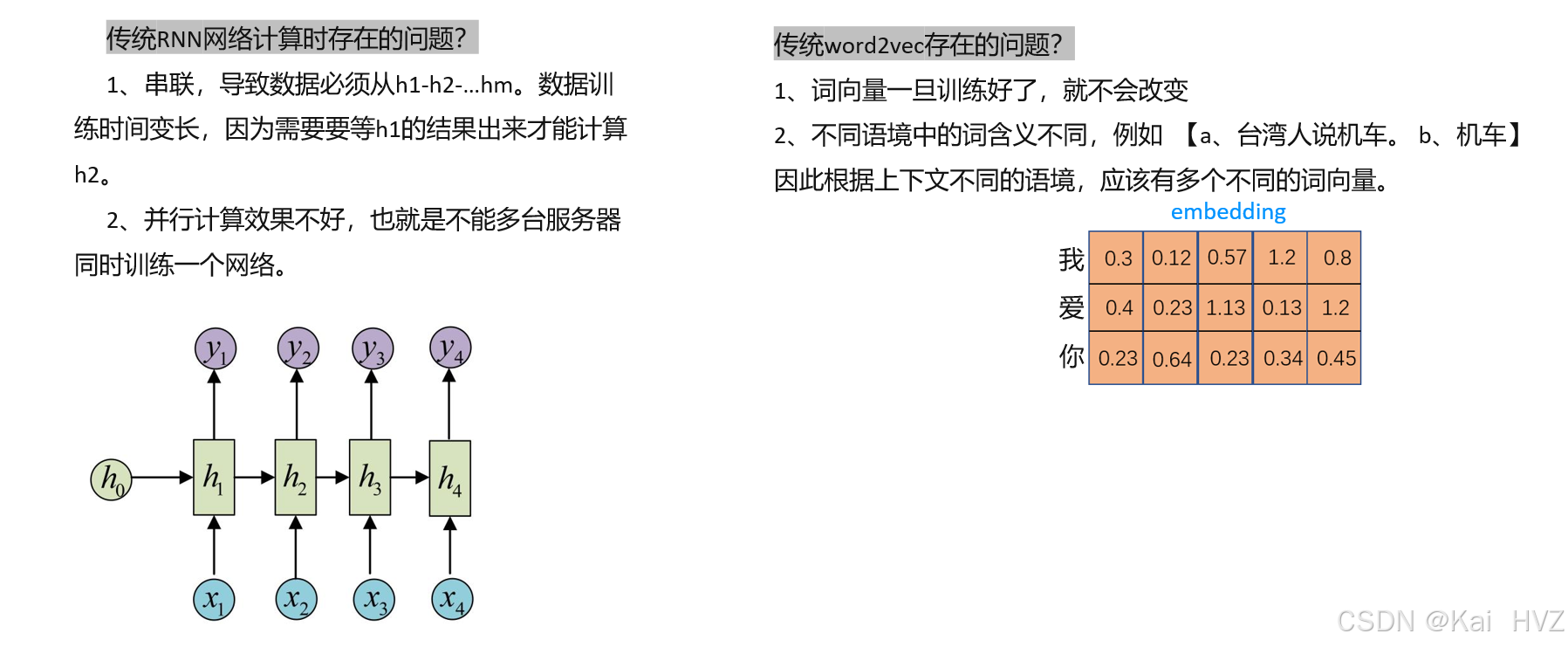
什么是bert框架?
BERT(Bidirectional Encoder Representations from Transformers)是由 Google 在 2018 年提出的预训练语言模型框架,其核心思想是通过双向 Transformer 编码器学习深层语言表征,在自然语言处理(NLP)领域具有里程碑意义。

bert核心特点
- 双向编码
- BERT 采用双向 Transformer 编码器,能够同时捕捉上下文信息(如 “苹果” 在 “我吃了一个苹果” 和 “苹果公司发布了新产品” 中的不同含义),解决了早期单向模型(如 GPT)的局限性。
- 预训练 + 微调范式
- 预训练:在大规模文本语料库(如 BooksCorpus、English Wikipedia)上通过两个自监督任务学习通用语言知识:
- 掩码语言模型(MLM):随机遮盖句子中的部分词汇,预测被遮盖词。
- 下一句预测(NSP):判断两个句子是否为上下文关系。
- 微调:将预训练模型参数迁移到下游任务(如分类、问答等),通过少量标注数据优化模型。
- 预训练:在大规模文本语料库(如 BooksCorpus、English Wikipedia)上通过两个自监督任务学习通用语言知识:
- 多层 Transformer 结构
- 基础版:12 层 Transformer,768 维隐藏层,12 个注意力头,约 1.1 亿参数。
- 大型版:24 层 Transformer,1024 维隐藏层,16 个注意力头,约 3.4 亿参数。
bert框架结构
bert架构
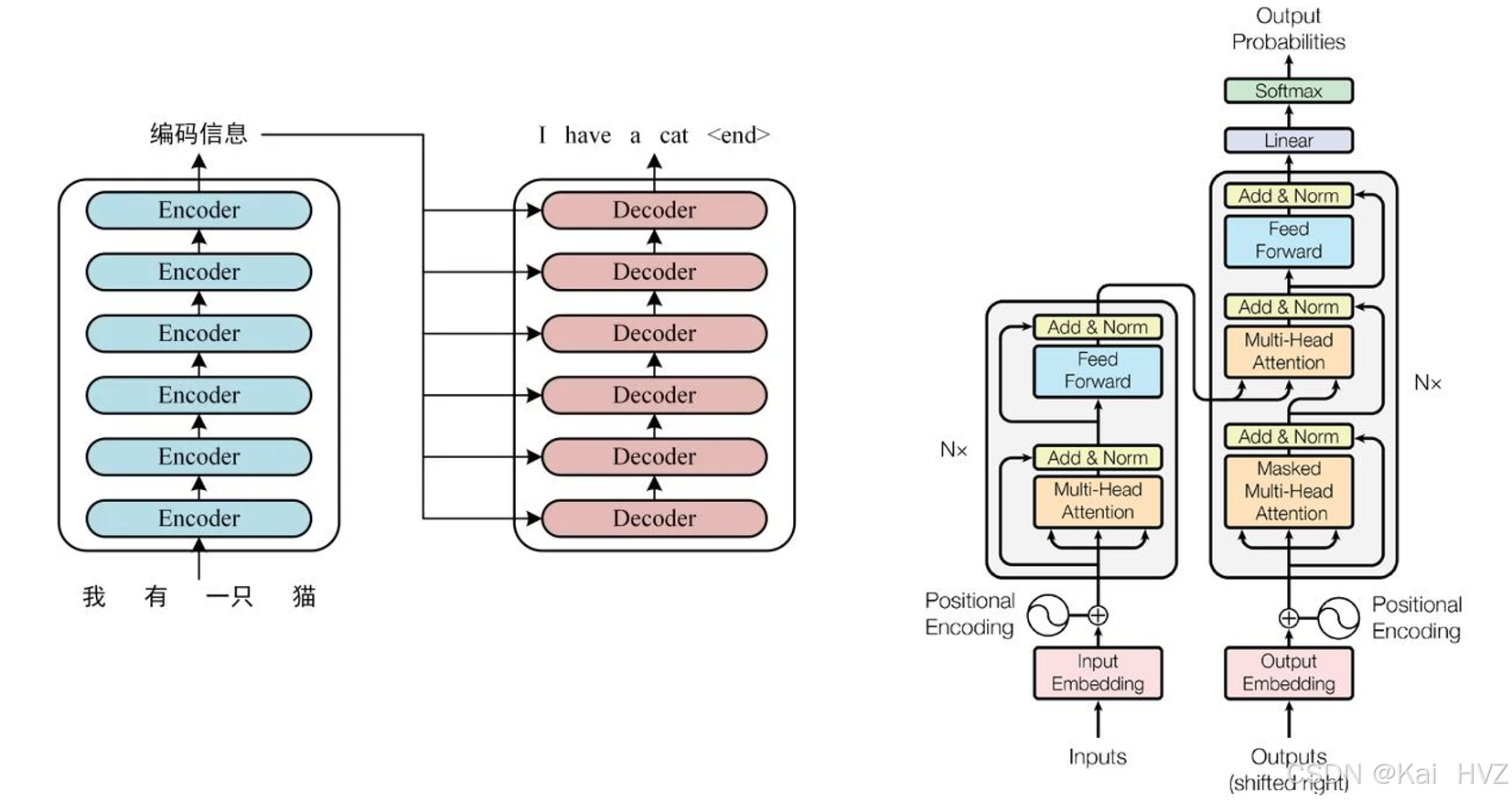
BERT 的结构主要基于 Transformer 架构:
输入表示
BERT 的输入由三部分组成,它们会被拼接在一起形成最终的输入向量。- 词嵌入(Token Embeddings):将输入的词转化为对应的向量表示。通常使用预训练的词向量,例如 Word2Vec 或 GloVe 得到的向量,也可以在模型训练过程中进行学习。
- 片段嵌入(Segment Embeddings):用于区分输入中的不同句子或片段。在处理两个句子的任务(如下一句预测)时,它可以帮助模型区分哪个词属于第一个句子,哪个词属于第二个句子。
- 位置嵌入(Position Embeddings):由于 Transformer 本身没有捕捉序列顺序的能力,位置嵌入用于为每个词添加位置信息,让模型能够感知词在序列中的位置。
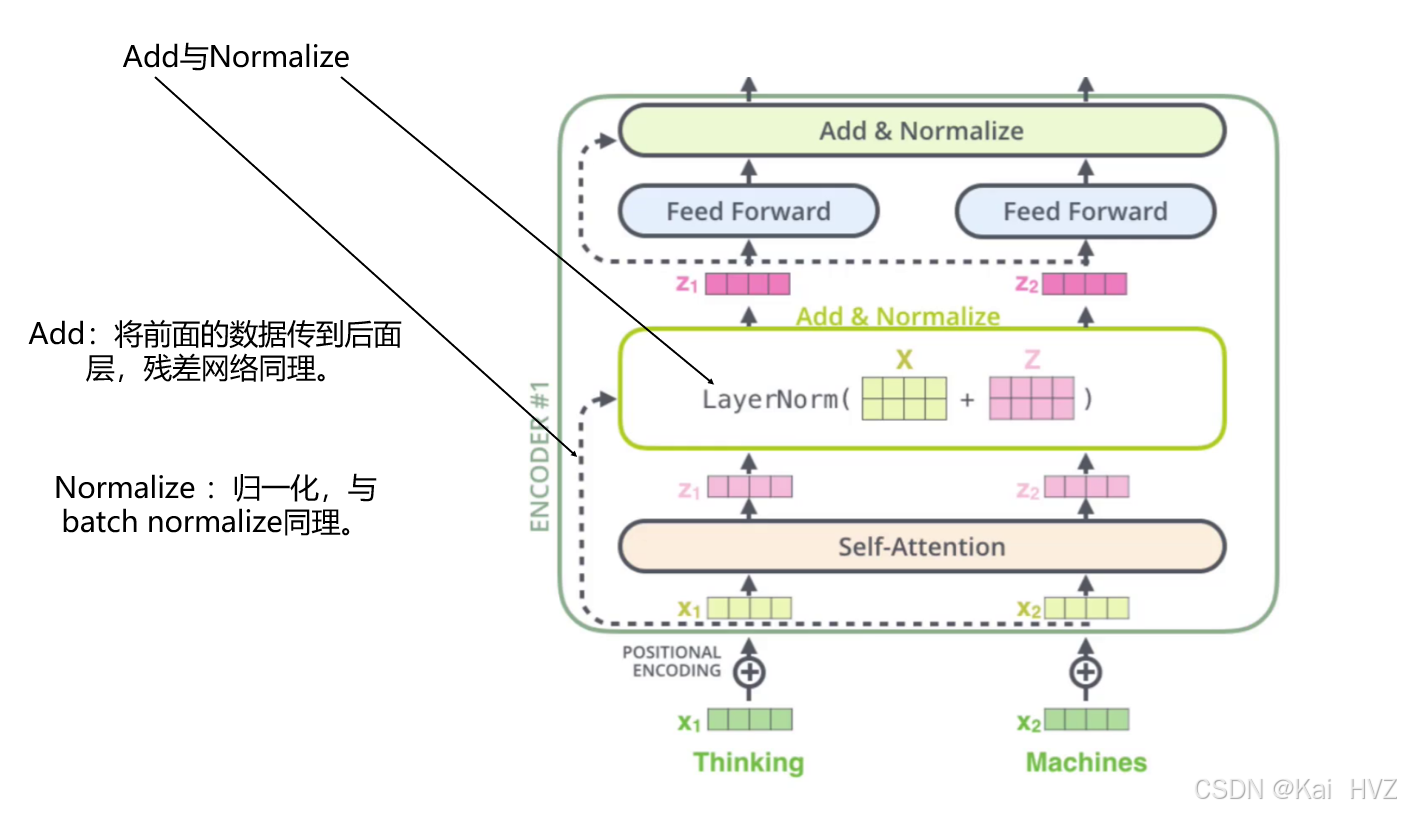
编码器(Transformer Encoder)
BERT 的核心是多层的 Transformer 编码器堆叠而成。每个编码器层包含两个子层:- 多头自注意力机制(Multi - Head Self - Attention):自注意力机制允许模型在处理某个词时,关注输入序列中的其他词,从而捕捉不同词之间的依赖关系。多头自注意力则是将自注意力机制并行应用多次,从不同的表示子空间中提取信息,增强模型的表达能力。
- 前馈神经网络(Feed - Forward Neural Network):在多头自注意力机制的输出上,应用一个两层的全连接前馈神经网络,对特征进行进一步的非线性变换。
输出层
BERT 的输出可以根据不同的任务进行灵活调整:- 分类任务:在输入序列的开头添加一个特殊的分类标记[CLS],其对应的输出向量可以作为整个序列的表示,用于后续的分类任务。例如,在情感分析任务中,这个向量可以被输入到一个全连接层,输出不同情感类别的概率。
- 序列标注任务:每个词对应的输出向量可以用于对该词进行标注,例如命名实体识别任务中,为每个词标注其所属的实体类型。
- 问答任务:在处理问答任务时,模型可以根据输入的问题和文本,输出答案的起始位置和结束位置。
框架
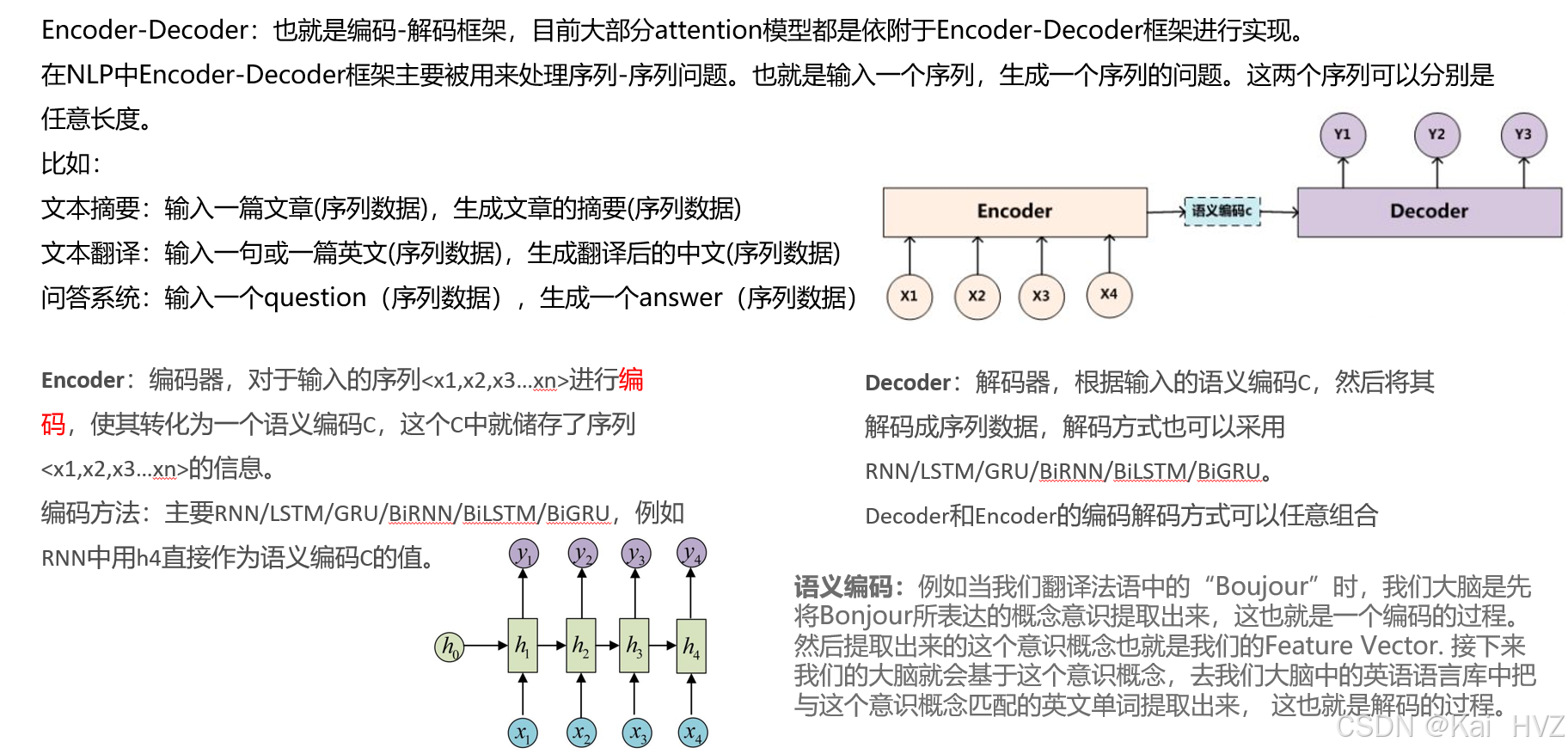


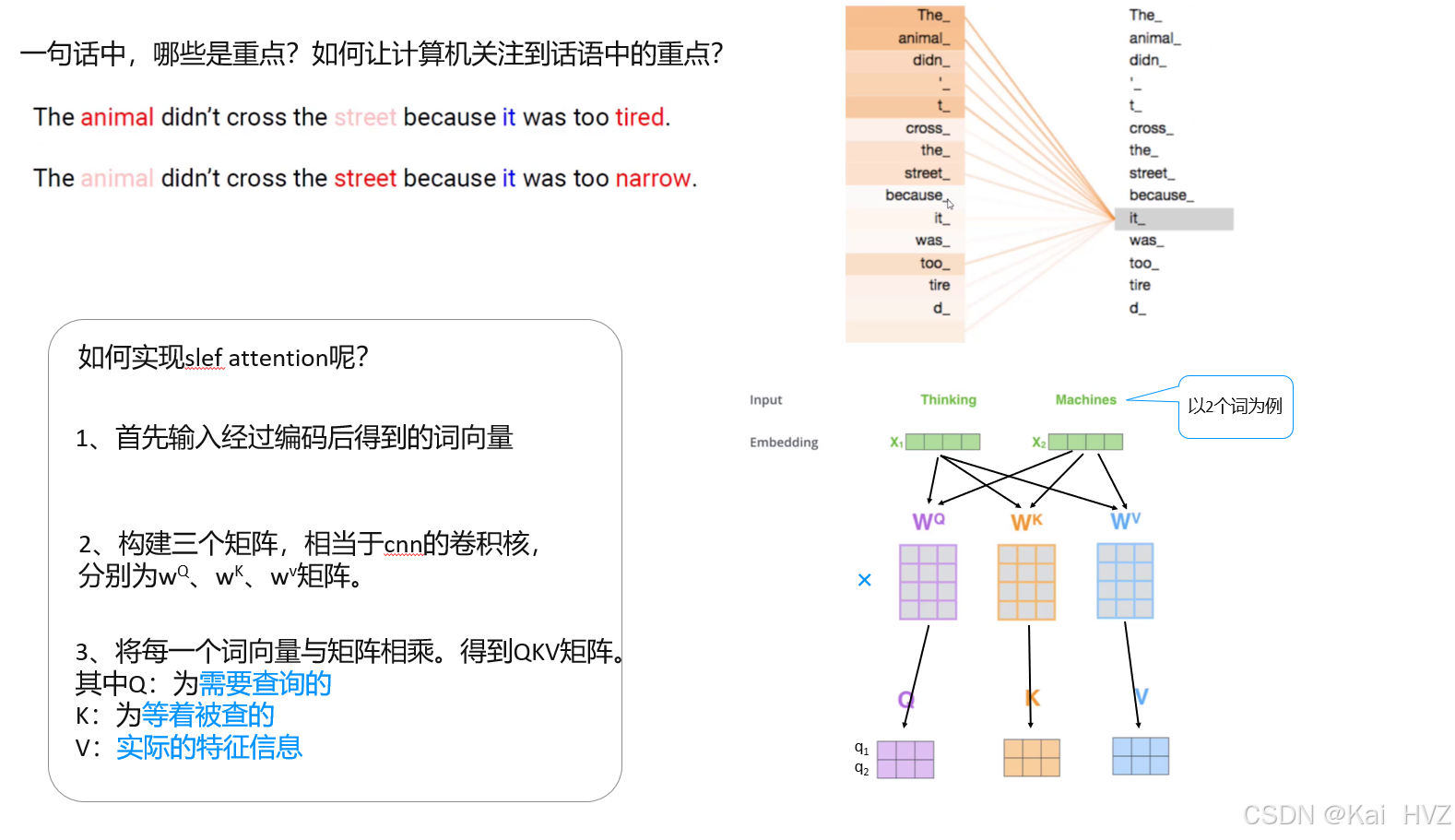
slef attention(自注意机制)
自注意力机制(Self - Attention)是 BERT 等 Transformer 架构的核心组件,它能够让模型在处理序列数据时,关注序列中不同位置元素之间的关系。
- 原理
自注意力机制的核心思想是通过计算序列中每个元素与其他元素之间的相关性,为每个元素分配不同的权重,从而使模型能够根据这些权重对序列中的信息进行聚合和表示。这种机制允许模型在处理某个元素时,动态地关注序列中其他相关元素的信息,从而更好地捕捉序列中的长距离依赖关系。
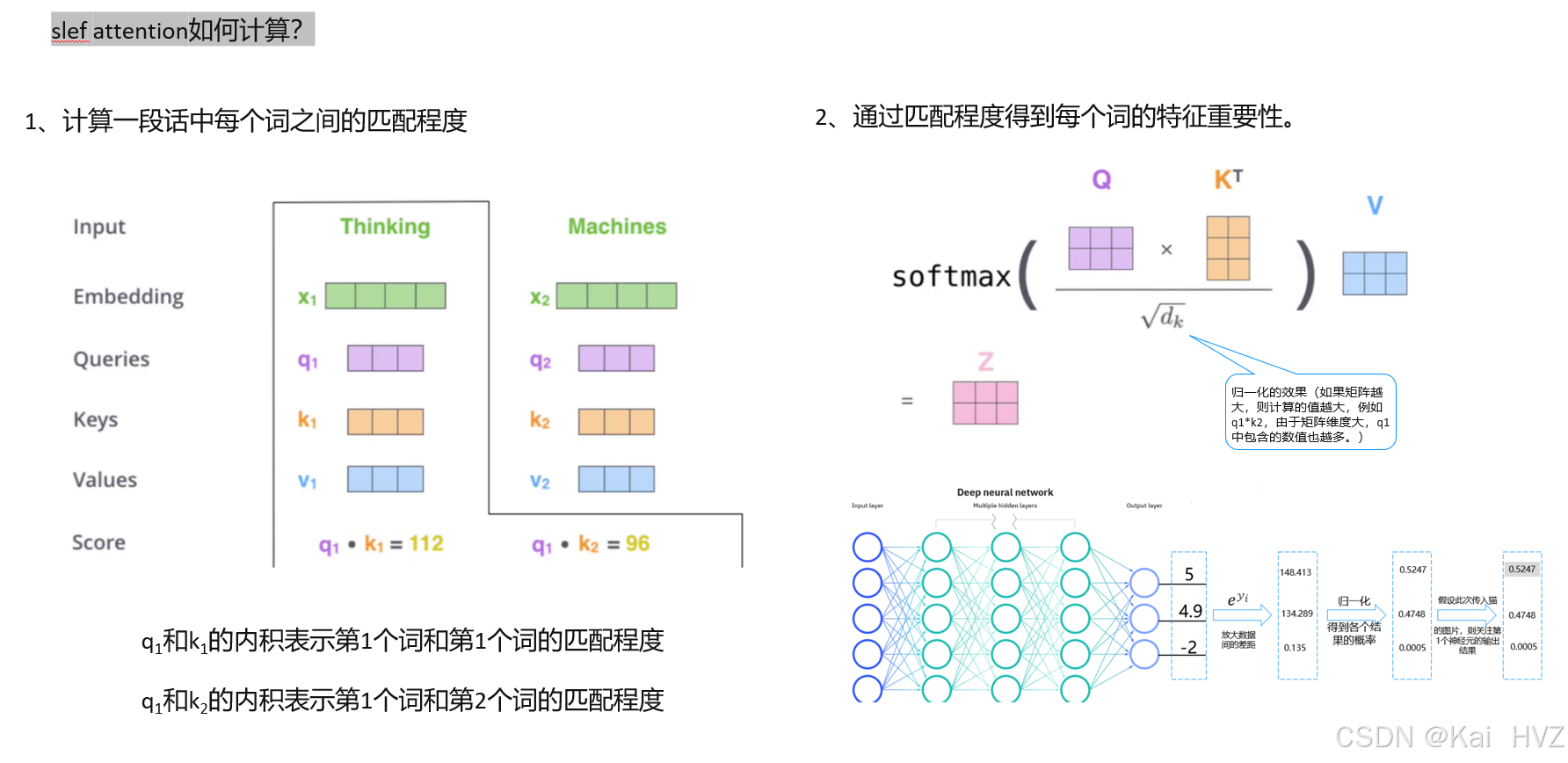

multi-headed机制
多头机制(Multi-headed Attention)是自注意力机制的重要扩展,由 Vaswani 等人在《Attention Is All You Need》中提出。它通过并行计算多个独立的注意力头,捕捉输入序列中不同子空间的依赖关系,显著提升了模型的表达能力。
- 核心思想
- 并行处理不同子空间:将输入向量投影到多个低维子空间(每个子空间对应一个 “头”),每个头独立计算注意力,捕捉不同的语义或语法关系。
- 整合多维度信息:将各头的注意力结果拼接后,通过线性层整合,形成最终的上下文表示。
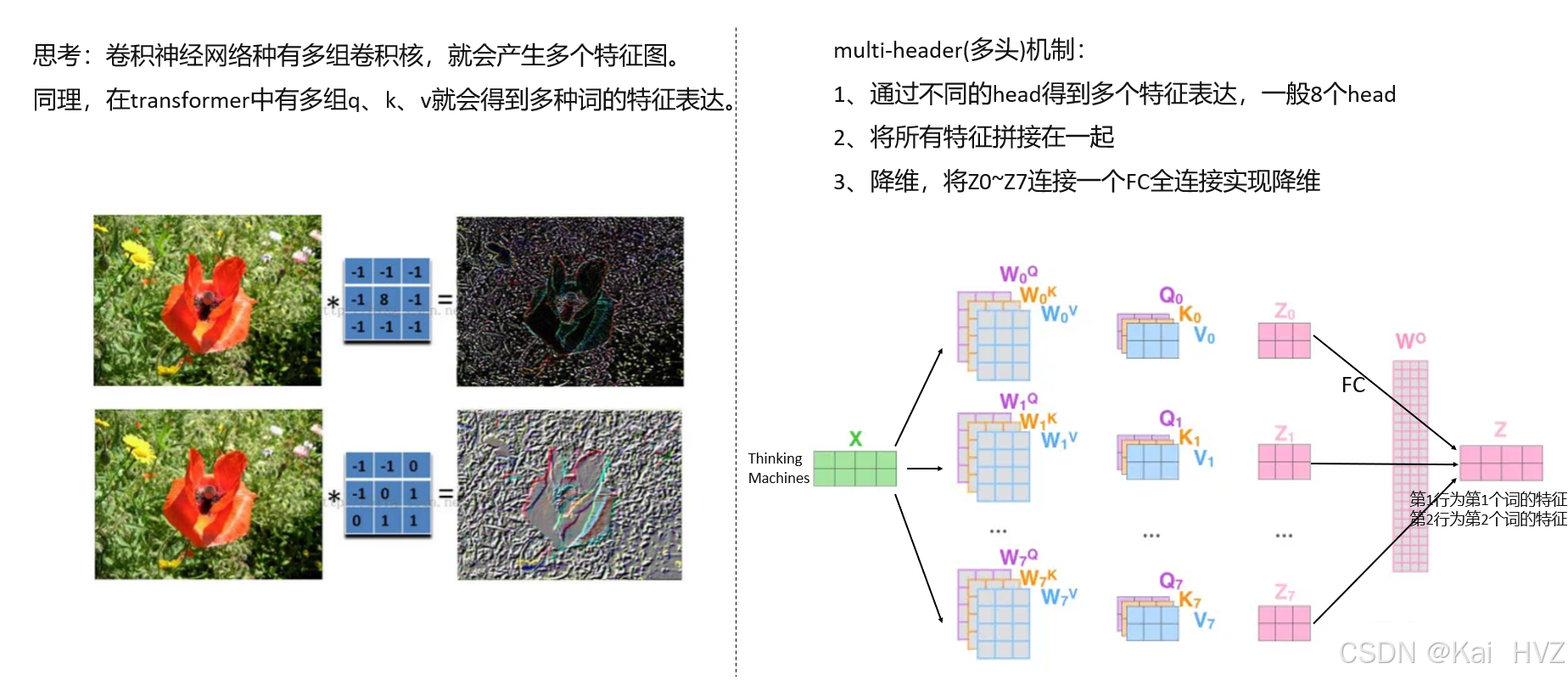
多层堆叠
多层 Transformer 编码器的堆叠。

位置编码
位置编码是解决序列数据中顺序信息丢失问题的核心机制。由于自注意力机制本身不依赖位置信息(所有词的交互是平等的),位置编码通过显式或隐式的方式为每个词的嵌入向量注入位置信息,帮助模型捕捉句子的结构和长距离依赖。
- 为什么需要位置编码?
- 自注意力的局限性:自注意力计算仅依赖词向量的相似性,无法区分相同词在不同位置的语义差异。例如:
- “猫追老鼠” 和 “老鼠追猫” 的自注意力矩阵相同,但语义完全相反。
- 序列建模的本质需求:自然语言的顺序(如主谓宾结构)对语义理解至关重要,位置编码是恢复这种顺序信息的关键。


- 自注意力的局限性:自注意力计算仅依赖词向量的相似性,无法区分相同词在不同位置的语义差异。例如:
训练数据
- BERT 的预训练数据主要包含两部分:
- BooksCorpus
- 规模:约 8 亿词,由 7000 多本未出版书籍组成。
- 特点:长文本、复杂句式、专业术语多,适合学习长距离依赖。
- English Wikipedia
- 规模:约 25 亿词,经过结构化处理(去除标记、表格等)。
- 特点:百科全书式语言,知识密集,适合构建通用语义表征。
- BooksCorpus
- 数据预处理流程
- 分词(Tokenization)
- 使用WordPiece分词器(如[CLS], [SEP]等特殊标记)。
- 示例:“unhappiness” → [“un”, “##happi”, “##ness”]。
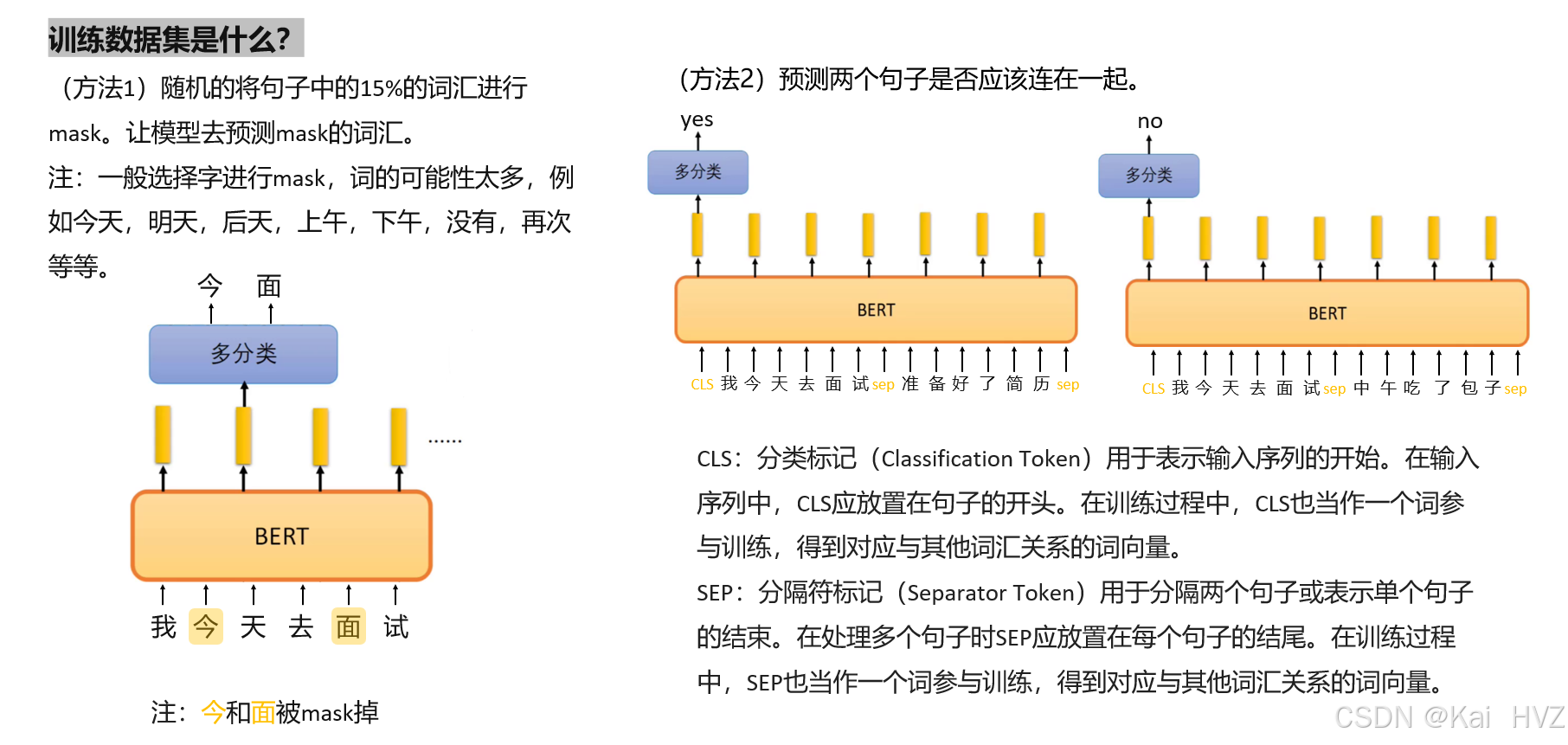
- 构建训练样本
- 掩码语言模型(MLM):随机掩盖 15% 的词,预测被掩盖的词。
- 掩盖策略:80% 替换为[MASK],10% 随机替换,10% 保持原样。
- 下一句预测(NSP):判断两个句子是否为连续文本(正样本)或随机组合(负样本)。
- 正样本占 50%,负样本占 50%。
- 序列截断与填充
- 最大序列长度固定为512,超长文本截断,不足补[PAD]
- 最大序列长度固定为512,超长文本截断,不足补[PAD]
- 分词(Tokenization)