前言
本文主要研究场景为工业场景下,在工控机与工业相机环境中运行的视觉缺陷检测系统,因此本文主要目的为实现c++环境下,将yolov8已训练好的检测模型使用onnxruntime 部署通过cpu或gpu cuda加速进行检测运算
一、导出yolov8模型为onnx文件
Yolo官方支持onnx的使用,直接使用yolo的官方库即可
配置好训练权重文件路径,输出参数按自己需求查手册配置
from ultralytics import YOLO
# Load a model
#model = YOLO("yolov8n.pt") # Load an official model
model = YOLO(r"D:\deep_learning\YOLOv8.2\runs\train\exp9\weights\best.pt") # Load a custom trained model
# Export the model
success = model.export(format="onnx", opset=11, simplify=True)
输出成功的文件会在权重文件同目录下

这里生成的文件为11.6MB,过小的onnx文件可能是生成失败产生的

获取了onnx文件后接下来配置调用onnx文件的部分
二、VS2019中环境配置
上篇文章中详细介绍了opencv在vs2019中的配置方法,这里就不再重复写了
opencv的配置见【Yolov8部署】 VS2019+opencv-dnn CPU环境下部署目标检测模型
YOLO官方提供的onnxruntime示例源码如下
https://github.com/ultralytics/ultralytics/tree/main/examples/YOLOv8-ONNXRuntime-CPP
可按需下载使用,本文提供另一种使用方法,下文会附上源码
首先需要下载ONNX Runtime gpu版本库
下载链接如下:
https://github.com/microsoft/onnxruntime/releases/tag/v1.21.0
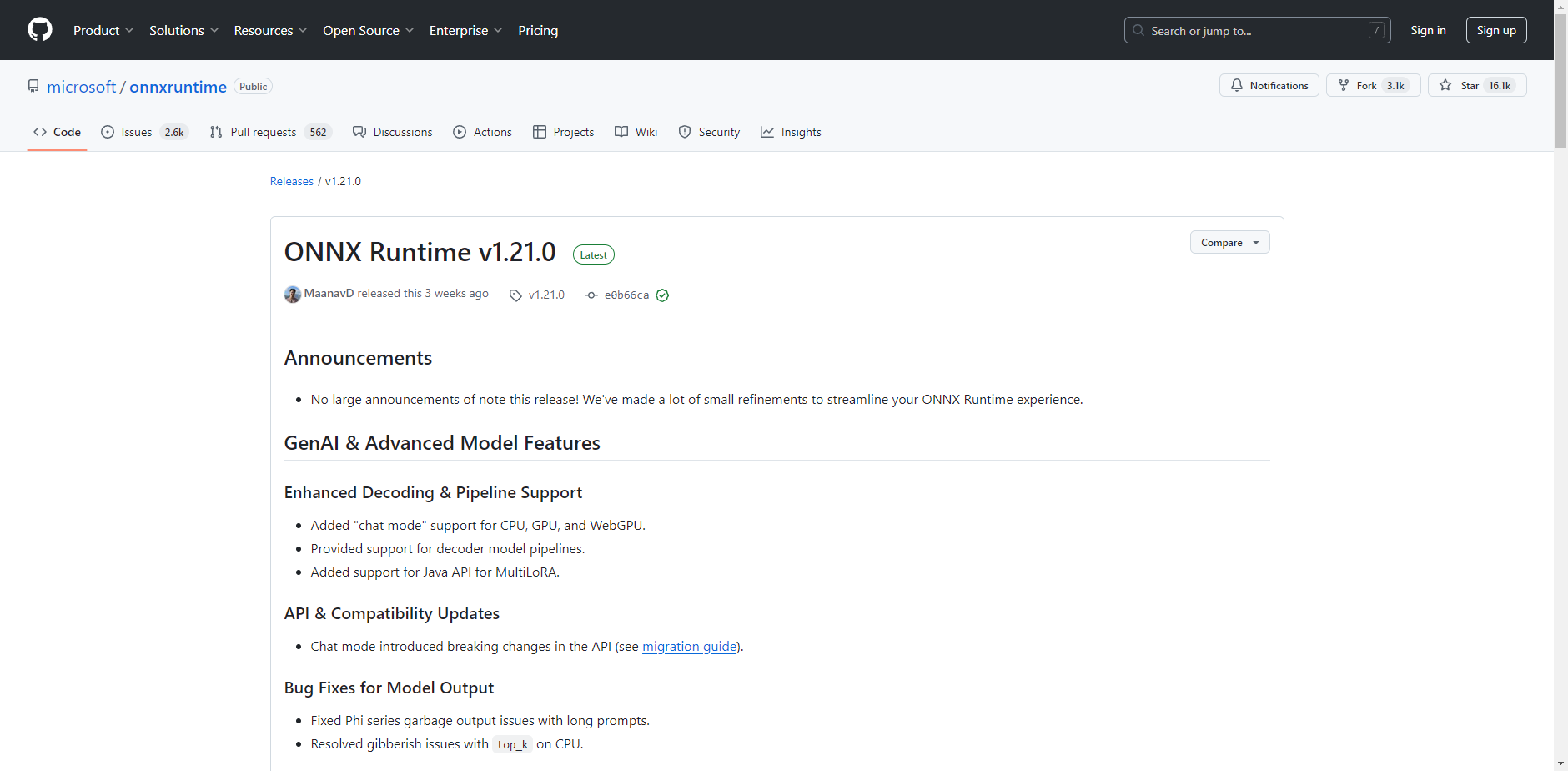
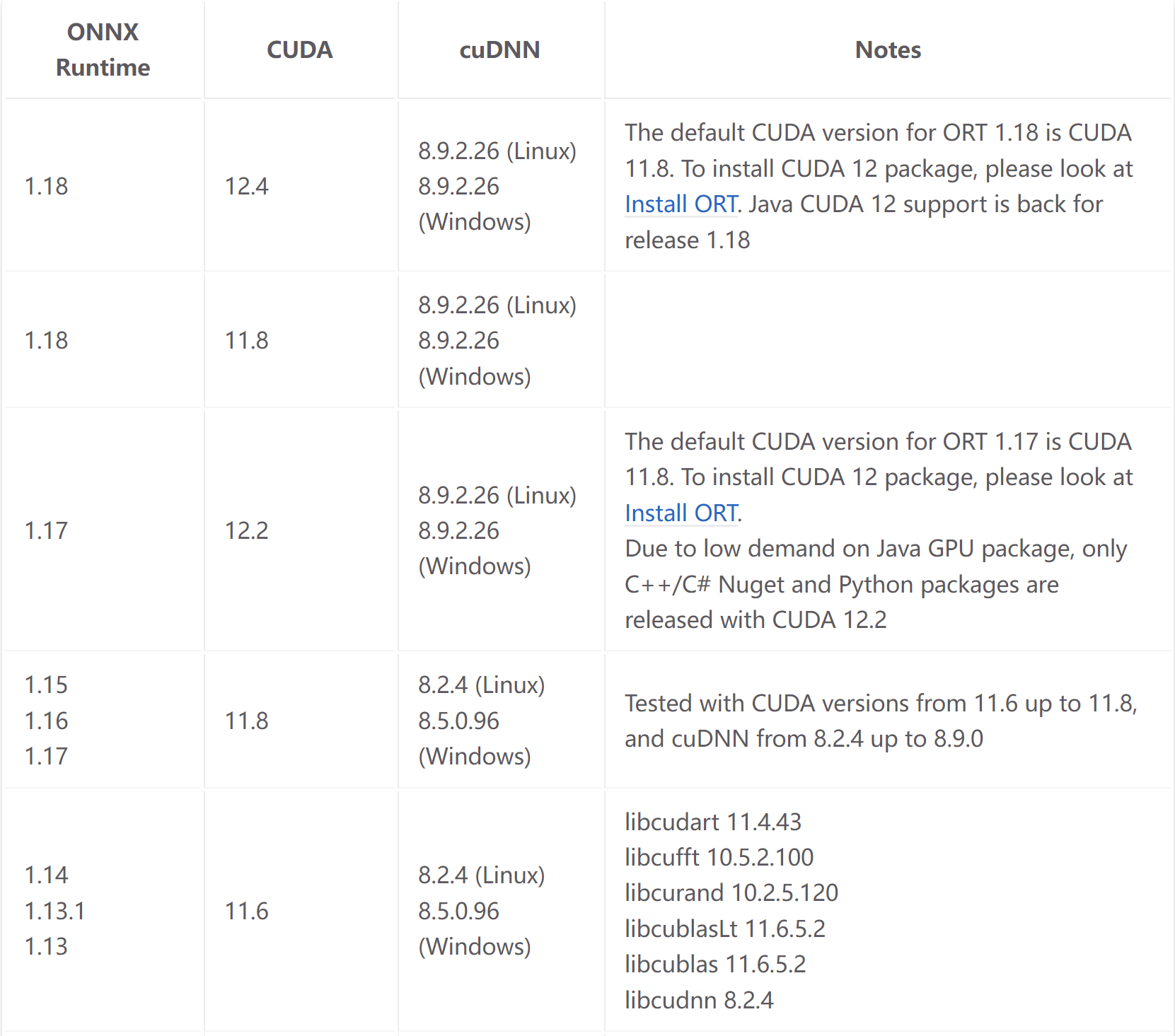
ONNX Runtime的版本需要注意与cuda版本对应
我的cuda版本装的是11.6,这里选用1.15版本的ONNX Runtime
使用onnxruntime推理不需要额外用opencv_gpu版本,cpu版本的opencv就可以满足要求
VS主要需要配置的是包含目录和三个动态库
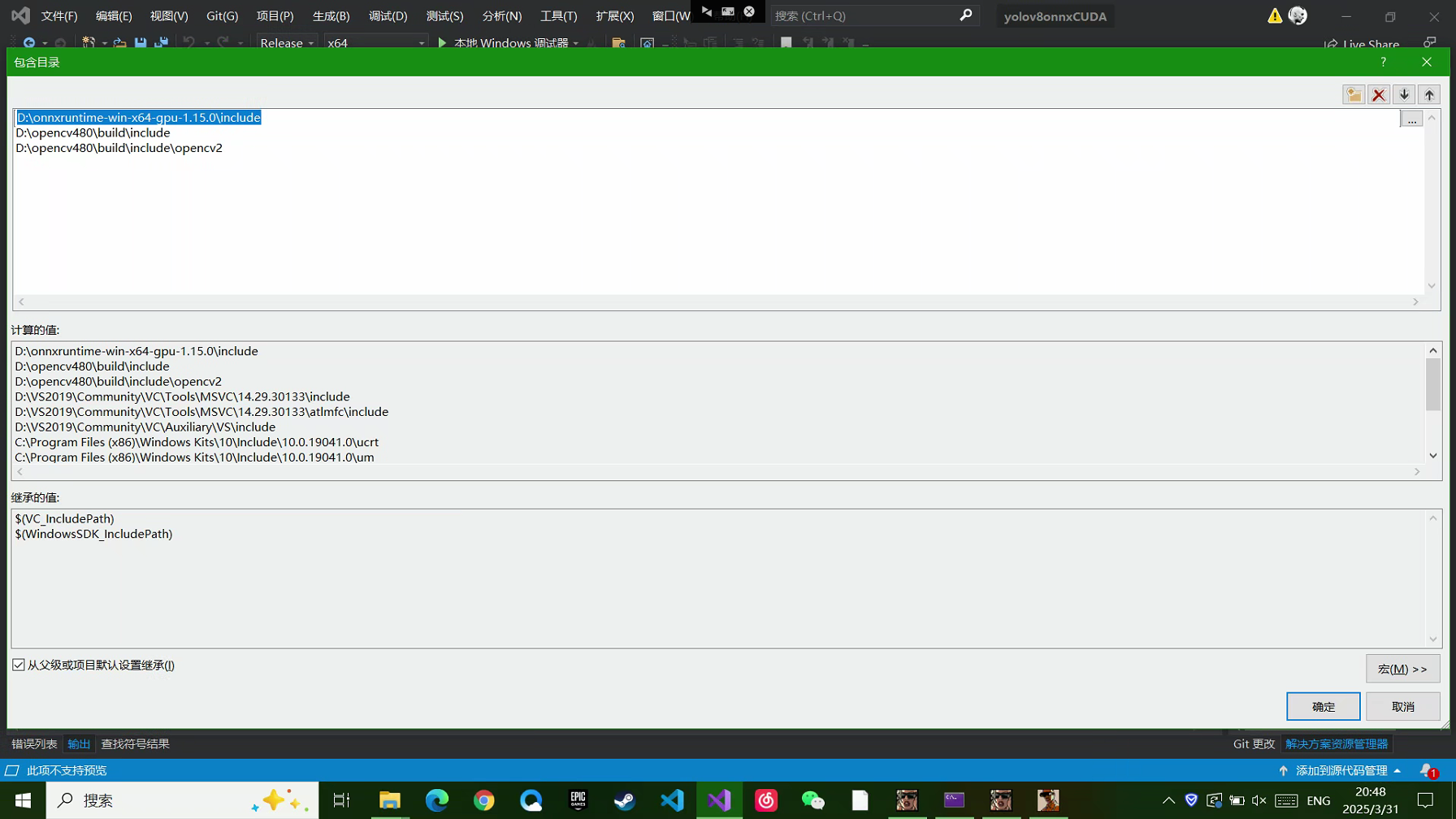
库目录配置
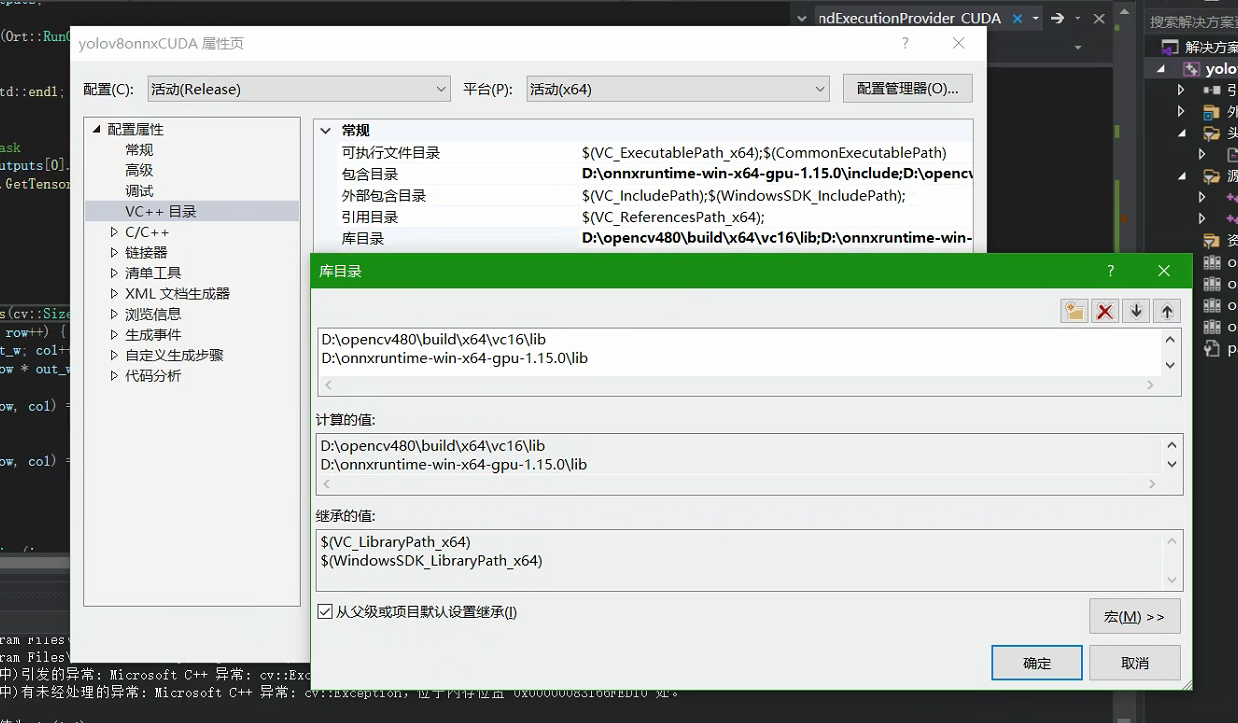
附加依赖项配置,将三个lib动态库都配置上

三、源码与实际运行
以下是调用推理源码
main.cpp
#include <opencv2/opencv.hpp>
#include "onnxruntime_cxx_api.h"
int main()
{
// 预测的目标标签数
std::vector<std::string> labels;
labels.push_back("bright_collision");
labels.push_back("dark_collision");
std::filesystem::path current_path = std::filesystem::current_path();
std::filesystem::path imgs_path = current_path / "images";
for (auto& i : std::filesystem::directory_iterator(imgs_path))
{
if (i.path().extension() == ".jpg" || i.path().extension() == ".png" || i.path().extension() == ".jpeg")
{
std::string img_path = i.path().string();
cv::Mat img = cv::imread(img_path);
}
}
// 测试图片
cv::Mat image = cv::imread("D:\\VsEnvironment\\yolov8onnxCUDA\\yolov8onnxCUDA\\images\\Image_20241126165712899.jpg");
cv::imshow("输入图", image);
// ******************* 1.初始化ONNXRuntime环境 *******************
Ort::Env env = Ort::Env(ORT_LOGGING_LEVEL_ERROR, "D:\\VsEnvironment\\dataSet\\best.onnx");
// ***************************************************************
// ******************* 2.设置会话选项 *******************
// 创建会话
Ort::SessionOptions session_options;
// 优化器级别:基本的图优化级别
session_options.SetGraphOptimizationLevel(ORT_ENABLE_BASIC);
// 线程数:4
session_options.SetIntraOpNumThreads(4);
// 设备使用优先使用GPU而是才是CPU
OrtSessionOptionsAppendExecutionProvider_CUDA(session_options, 0);//此条屏蔽则使用为cpu
//OrtSessionOptionsAppendExecutionProvider_CPU(session_options, 1);
std::cout << "onnxruntime inference try to use GPU Device" << std::endl;
// ******************************************************
// ******************* 3.加载模型并创建会话 *******************
// onnx训练模型文件
std::string onnxpath = "D:\\VsEnvironment\\dataSet\\best.onnx";
std::wstring modelPath = std::wstring(onnxpath.begin(), onnxpath.end());
// 加载模型并创建会话
Ort::Session session_(env, modelPath.c_str(), session_options);
// ************************************************************
// ******************* 4.获取模型输入输出信息 *******************
int input_nodes_num = session_.GetInputCount(); // 输入节点输
int output_nodes_num = session_.GetOutputCount(); // 输出节点数
std::vector<std::string> input_node_names; // 输入节点名称
std::vector<std::string> output_node_names; // 输出节点名称
Ort::AllocatorWithDefaultOptions allocator; // 创建默认配置的分配器实例,用来分配和释放内存
// 输入图像尺寸
int input_h = 0;
int input_w = 0;
// 获取模型输入信息
for (int i = 0; i < input_nodes_num; i++) {
// 获得输入节点的名称并存储
auto input_name = session_.GetInputNameAllocated(i, allocator);
input_node_names.push_back(input_name.get());
// 显示输入图像的形状
auto inputShapeInfo = session_.GetInputTypeInfo(i).GetTensorTypeAndShapeInfo().GetShape();
int ch = inputShapeInfo[1];
input_h = inputShapeInfo[2];
input_w = inputShapeInfo[3];
std::cout << "input format: " << ch << "x" << input_h << "x" << input_w << std::endl;
}
// 获取模型输出信息
int num = 0;
int nc = 0;
for (int i = 0; i < output_nodes_num; i++) {
// 获得输出节点的名称并存储
auto output_name = session_.GetOutputNameAllocated(i, allocator);
output_node_names.push_back(output_name.get());
// 显示输出结果的形状
auto outShapeInfo = session_.GetOutputTypeInfo(i).GetTensorTypeAndShapeInfo().GetShape();
num = outShapeInfo[0];
nc = outShapeInfo[1];
std::cout << "output format: " << num << "x" << nc << std::endl;
}
// **************************************************************
// ******************* 5.输入数据预处理 *******************
// 默认是BGR需要转化成RGB
cv::Mat rgb, blob;
cv::cvtColor(image, rgb, cv::COLOR_BGR2RGB);
// 对图像尺寸进行缩放
cv::resize(rgb, blob, cv::Size(input_w, input_h));
blob.convertTo(blob, CV_32F);
// 对图像进行标准化处理
blob = blob / 255.0; // 归一化
cv::subtract(blob, cv::Scalar(0.485, 0.456, 0.406), blob); // 减去均值
cv::divide(blob, cv::Scalar(0.229, 0.224, 0.225), blob); //除以方差
// CHW-->NCHW 维度扩展
cv::Mat timg = cv::dnn::blobFromImage(blob);
std::cout << timg.size[0] << "x" << timg.size[1] << "x" << timg.size[2] << "x" << timg.size[3] << std::endl;
// ********************************************************
// ******************* 6.推理准备 *******************
// 占用内存大小,后续计算是总像素*数据类型大小
size_t tpixels = 3 * input_h * input_w;
std::array<int64_t, 4> input_shape_info{ 1, 3, input_h, input_w };
// 准备数据输入
auto allocator_info = Ort::MemoryInfo::CreateCpu(OrtDeviceAllocator, OrtMemTypeCPU);
Ort::Value input_tensor_ = Ort::Value::CreateTensor<float>(allocator_info, timg.ptr<float>(), tpixels, input_shape_info.data(), input_shape_info.size());
// 模型输入输出所需数据(名称及其数量),模型只认这种类型的数组
const std::array<const char*, 1> inputNames = { input_node_names[0].c_str() };
const std::array<const char*, 1> outNames = { output_node_names[0].c_str() };
// **************************************************
// ******************* 7.执行推理 *******************
std::vector<Ort::Value> ort_outputs;
try {
ort_outputs = session_.Run(Ort::RunOptions{ nullptr }, inputNames.data(), &input_tensor_, 1, outNames.data(), outNames.size());
}
catch (std::exception e) {
std::cout << e.what() << std::endl;
}
// **************************************************
// ******************* 8.后处理推理结果 *******************
// 1x5 获取输出数据并包装成一个cv::Mat对象,为了方便后处理
const float* pdata = ort_outputs[0].GetTensorMutableData<float>();
cv::Mat prob(num, nc, CV_32F, (float*)pdata);
// 后处理推理结果
cv::Point maxL, minL; // 用于存储图像分类中的得分最小值索引和最大值索引(坐标)
double maxv, minv; // 用于存储图像分类中的得分最小值和最大值
cv::minMaxLoc(prob, &minv, &maxv, &minL, &maxL);
// 获得最大值的索引,只有一行所以列坐标既为索引
int max_index = maxL.x;
std::cout << "label id: " << max_index << std::endl;
// ********************************************************
// 在测试图像上加上预测的分类标签
cv::putText(image, labels[max_index], cv::Point(50, 50), cv::FONT_HERSHEY_SIMPLEX, 1.0, cv::Scalar(0, 0, 255), 2, 8);
cv::imshow("输入图像", image);
cv::waitKey(0);
// ******************* 9.释放资源*******************
session_options.release();
session_.release();
// *************************************************
return 0;
}
由于预处理与推理都是调用onnxruntime_cxx_api.h中的部分,所以直接写在main.cpp中测试
通过OrtSessionOptionsAppendExecutionProvider_CUDA(session_options, 0);可以控制是使用cpu推理还是gpu_cuda进行推理
实际推理耗时如下
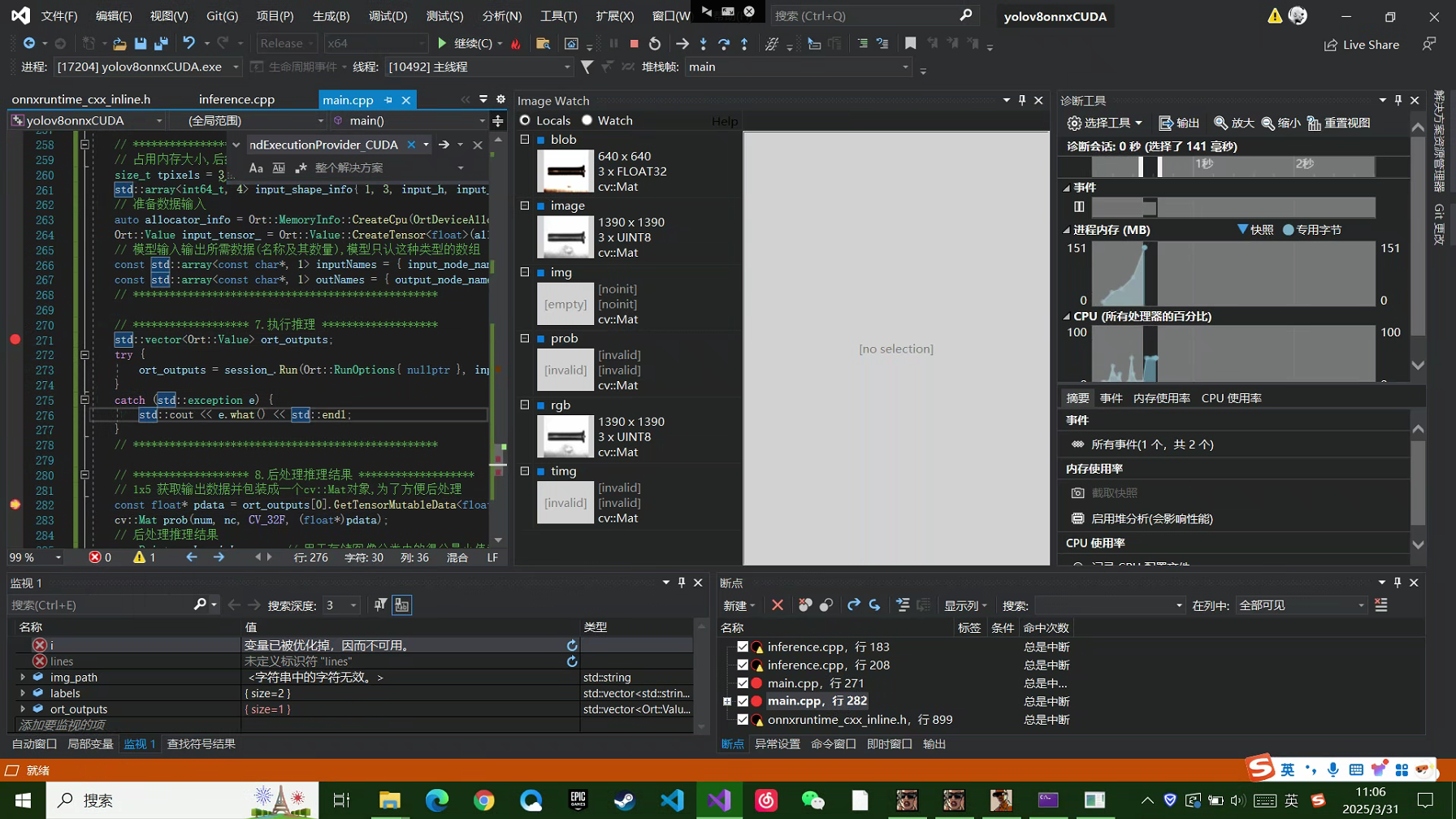
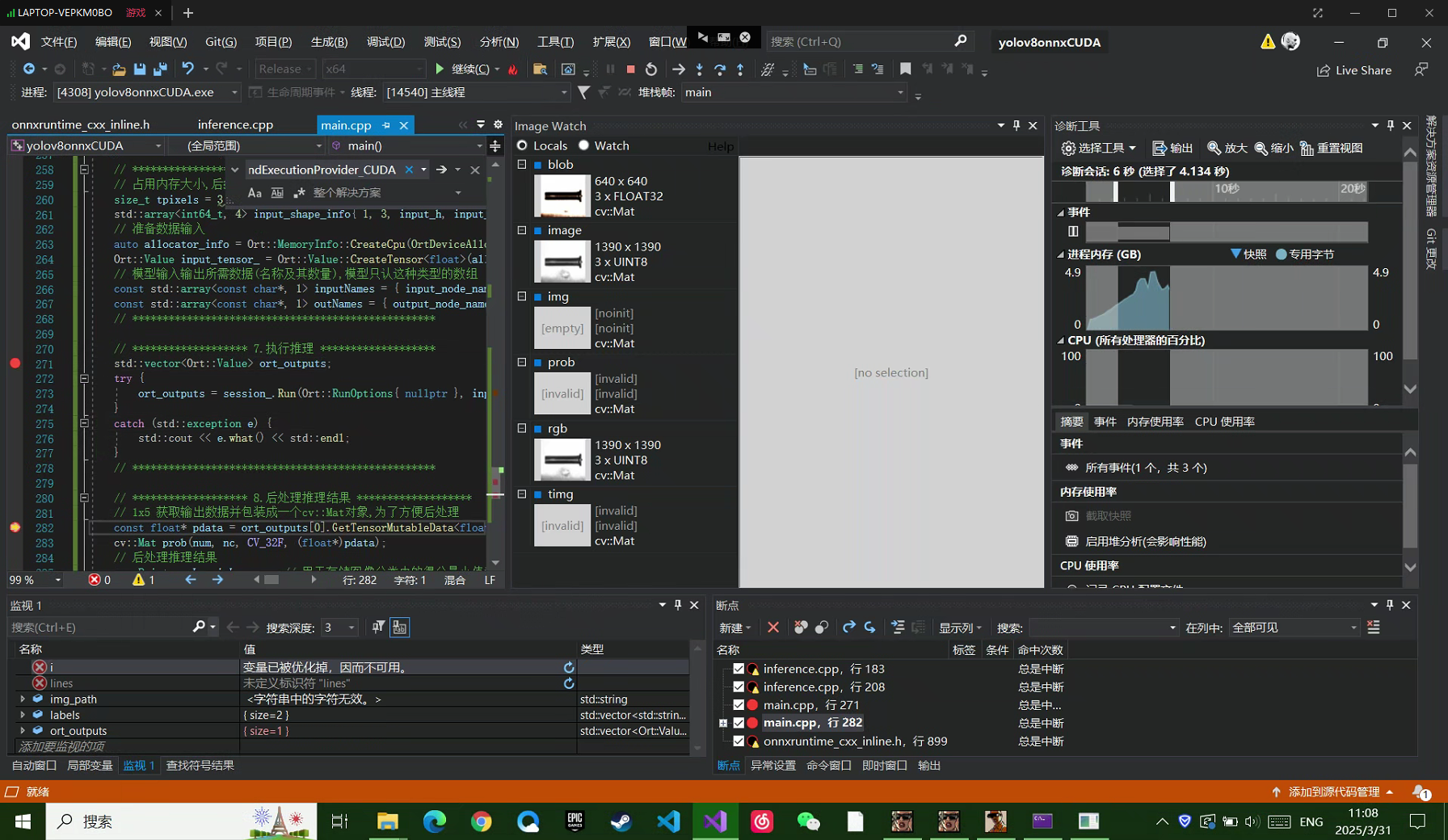
cpu用时141毫秒而gpu用时4.134秒
这里硬件环境是r7-3750h 1650-4g 16g运行内存
两者运行时间差异太大
可能是gpu计算分配耗时比较久,有知道原因的小伙伴可以在博客下留言告知