1. 整体流程概览
随着ChatGPT的爆火,人工智能的重要性日益凸显,相信大家也像我一样好奇人工智能为何会那么强大?它是通过怎样的训练流程来变得强大。在之前的学习和使用中,深度神经网络模型(deep neural network, DNN)的训练流程一直未能在我的脑海中留下清晰的路径,借着最近的学习情况,对DNN模型的训练流程进行了梳理,将整体流程画成了下面的图。

从图中(主要展示了监督学习模型)可以看到,深度神经网络的训练过程主要包括:数据预处理、模型构建、损失函数构建与优化器构建四个部分,最后通过测试集来对模型进行评价划分到了模型测试阶段。尽管看上去是分为了四个大的模块,实际上这些模块都是为了模型而服务。数据预处理部分是为了生成模型能理解的数据,同时提高模型计算的效率。损失函数和优化器是为了对模型的效果进行评估,并实时反馈,以更新模型参数,提升模型性能。下面将详细对每一个模块进行分析。
以线性神经网络为例,训练过程的代码如下(代码来源《动手学深度学习》):
# 超参数设置
lr = 0.03
num_epochs = 3
# 模型
net = linreg
# 损失函数
loss = squared_loss
for epoch in range(num_epochs):
# 1. 计算每一个batch_size的损失
for X, y in data_iter(batch_size, features, labels):
l = loss(net(X, w, b), y) # X和y的小批量损失
# 因为l形状是(batch_size,1),而不是一个标量。l中的所有元素被加到一起,
# 并以此计算关于[w,b]的梯度
l.sum().backward()
sgd([w, b], lr, batch_size) # 使用参数的梯度更新参数
# 2. 计算每一轮训练总的损失
with torch.no_grad():
train_l = loss(net(features, w, b), labels)
print(f'epoch {epoch + 1}, loss {float(train_l.mean()):f}')
2. 数据预处理
第一部分是数据预处理,在这个过程中,首先是对数据进行清洗与预处理,将处理完成的全体样本数据集进行划分,通常分为训练集、验证集(可省略)和测试集。训练时,为了提高训练速度与GPU使用率,通常会将训练样本划分为多个批量来进行训练。
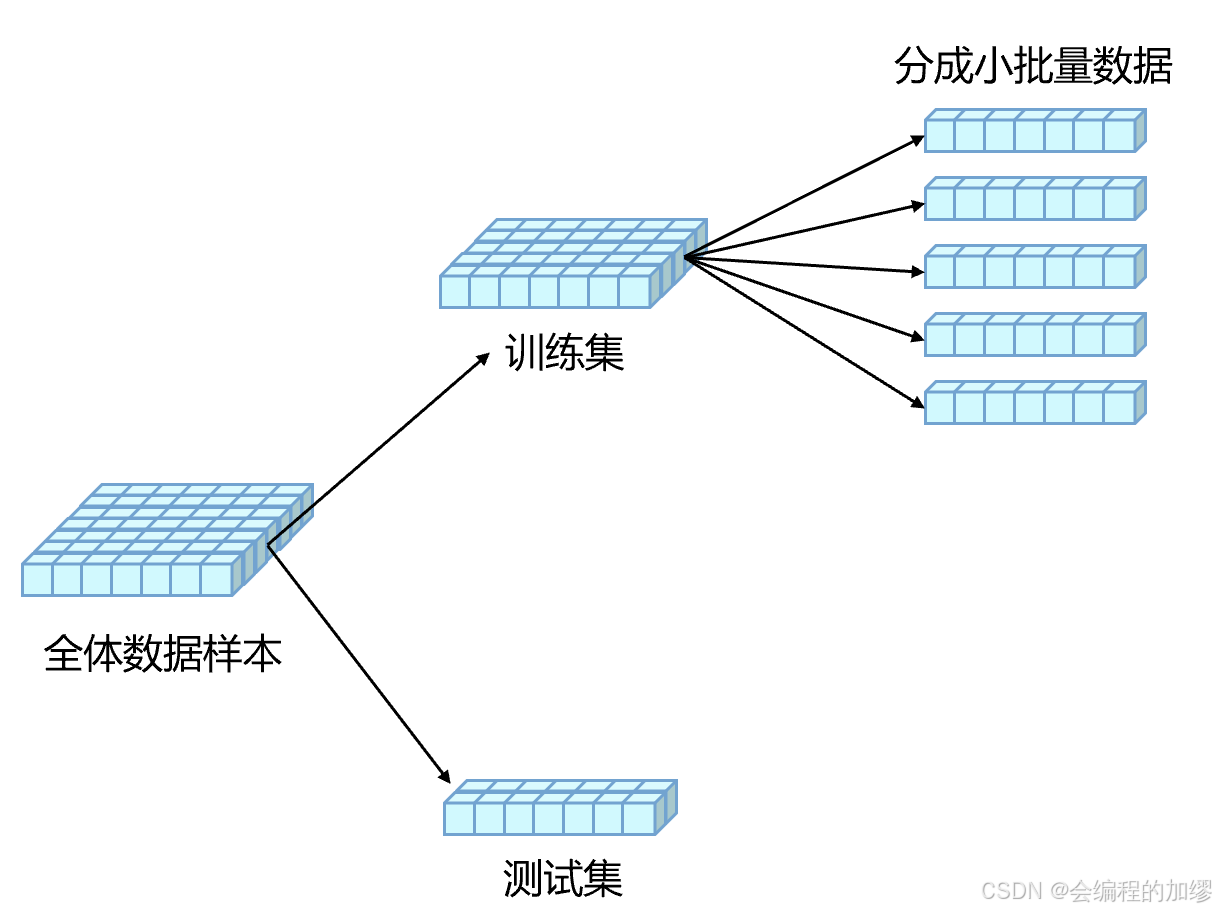
数据迭代器与预处理部分的代码示例,详情可以参考该博客
# 获取小批量数据
def data_iter(batch_size, features, labels):
num_examples = len(features)
indices = list(range(num_examples)) # 生成编号
# 样本随机读取
random.shuffle(indices) # 直接打乱原本存储位置的indices的顺序
for i in range(0, num_examples, batch_size):
batch_indices = torch.tensor( # 生成所有要提取的数据编号
indices[i:min(i + batch_size, num_examples)])
yield features[batch_indices], labels[batch_indices]
3. 模型定义与初始化
其次,我们需要选择一个合适的模型,并对模型进行初始化,来设定最初模型参数。设置好初始模型后,便可以将预先处理好的数据输入模型中,得到预测值 y ^ \hat{y} y^。图中模型用了多层线性感知机,主要包括输入层、隐藏层和输出层这三个层结构。

线性回归模型初始化:
w = torch.normal(0, 0.01, size = (2,1), requires_grad= True)
# w = torch.zeros((2,1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)
print(w, b)
def linear(X, w, b):
"""线性回归模型"""
return torch.matmul(X, w) + b
4. 损失函数
模型输出了它的预测值,但我们无法凭借肉眼去分辨模型的好坏。在监督学习中,可以采用训练数据的标签来与模型预测值进行对比,从而通过损失函数计算训练数据预测值值与训练数据标签的差距。
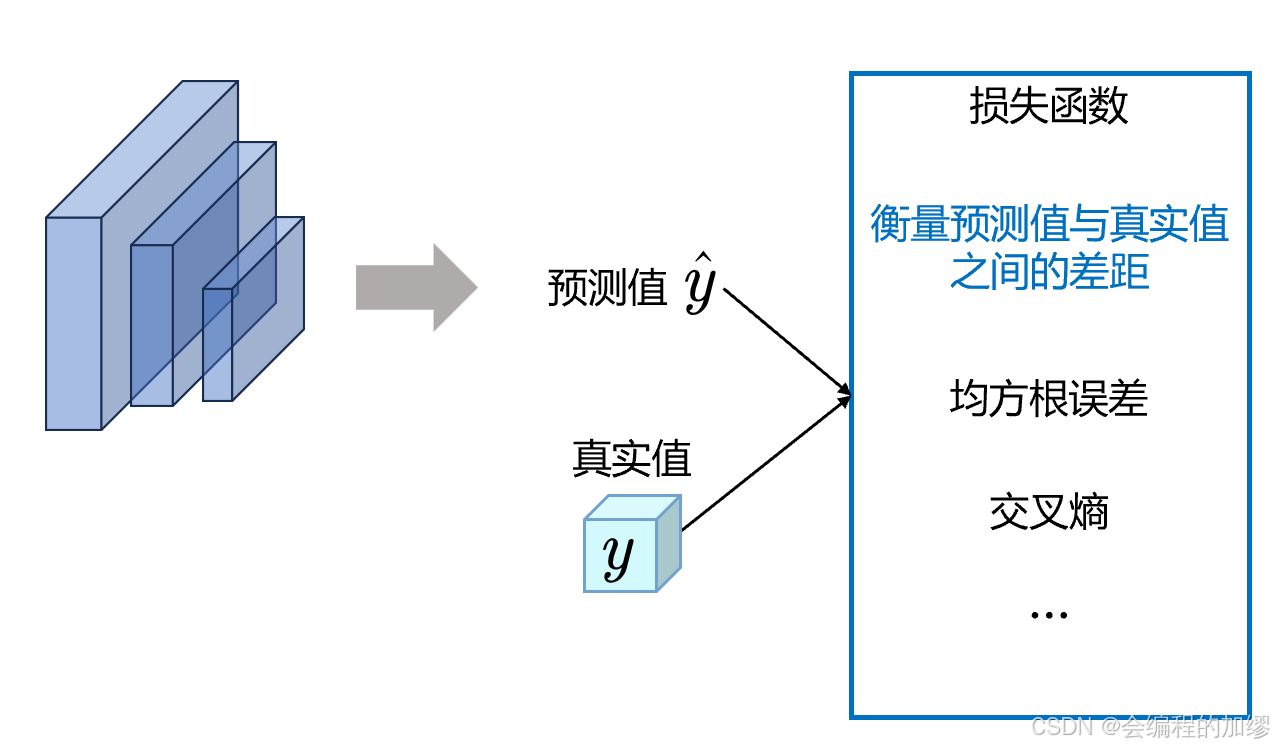
损失函数示例:
def squared_loss(y_hat, y):
"""均方损失"""
return (y_hat - y.reshape(y_hat.shape)) ** 2 / 2
5. 优化器
知道预测值与真实值的差距之后,下一步便是想办法来缩小这个差距,缩小这个差距常用的方法是优化器。例如,梯度下降法计通过算损失函数的梯度,找到让这个损失变得小的方向,并沿着这个方向来对模型参数进行更新。在优化器中,通常需要输入一些超参数,如学习率(learning rate),如果用的是小批量随机梯度下降或其他与批量相关的方法,还需要输入批量大小(batch size)作为参数。

小批量随机梯度下降优化器代码示例:
def sgd(params,lr,batch_size):
"""input:
params: 待更新的参数,这里为[w, b]
lr: learning rate, 决定每一步更新的大小
batch_size: 规范优化步长"""
with torch.no_grad(): # 禁止梯度计算,节约计算资源
for param in params:
param -= lr * param.grad / batch_size # param.grad是访问已计算好的梯度
param.grad.zero_() # 将梯度清零,为下一次做准备
6. 总结
该博客从数据预处理、模型定义与初始化、损失函数和优化器四个部分简单地解析了深度学习网络模型的训练流程,并以线性模型的代码作为例子,给出了每一部分的实现样例,帮助我们理解该训练流程,以及各个组件。希望该博客能让大家对DNN的训练有一个清晰的认知,知道在每一步是在干嘛。因为目前的各种算法模型封装的实在太好了,如果不仔细看和思考,真的看不明白,还是得将这些流程熟记于心,万变不离其宗!
我是会编程的加缪,如果对我的内容感兴趣记得关注我哦! 上面内容是本人浅显的见解与记录,欢迎各位大佬批评指正、交流学习!