Scala 和 Java 的 Lambda 表达式在概念上有相似之处,Scala 的 Lambda 和函数式编程能力比 Java 更早、更彻底,语法更灵活,且不依赖接口。
| 特性 | Java Lambda | Scala Lambda |
|---|---|---|
| 语法 | -> 符号,需绑定接口 |
=> 符号,直接作为函数值 |
| 类型推断 | 有限,需上下文信息 | 强大,通常无需显式声明 |
| 函数式支持 | 基于接口的 SAM(单一抽象方法) | 原生函数类型,支持高阶函数 |
| 灵活性 | 受限,需符合接口定义 | 极高,支持柯里化、模式匹配等 |
变量
Scala中的变量分为两种:可变 var 和 不可变 val
可变var:可以随时修改var声明的变量的值
不可变val:val声明的变量,值不能被修改,否则会报错: error: reassignment to val
在实际工作中,针对一些不需要改变值的变量,通常建议使用val,这样可以不用担心值被错误的修改(等于java中的final类型)。这样可以提高系统的稳定性和健壮性!
无论声明val变量,还是声明var变量,都可以手动指定变量的类型.
如果不指定,Scala会自动根据值,进行类型推断
val c = 1 等价于 val c: Int = 1
数据类型
Scala中的数据类型可以分为两种,基本数据类型和增强版数据类型 .
基本数据类型有: Byte、Char、Short、Int、Long、Float、Double、Boolean
增强版数据类型有: StringOps、RichInt、RichDouble、RichChar 等
操作符
Scala的算术操作符与Java的算术操作符没有什么区别。
比如 +、-、*、/、% 等,以及 &、|、^、>>、<< 等。注意:Scala中没有提供++、–操作符
if 表达式
在Scala中,if表达式是有返回值的,就是if或者else中最后一行语句返回的值,这一点和java中的if是不一样的,java中的if表达式是没有返回值的 。而if和else子句的值的类型可能还不一样,此时if表达式的值Scala会自动进行推断,取两个类型的公共父类型。如果if后面没有跟else,则默认else的值是Unit,也可以用()表示,类似于java中的void或者null。
for
scala> :paste
// Entering paste mode (ctrl-D to finish)
val n = 10
for(i <- 1 to n)
println(i)scala> :paste
// Entering paste mode (ctrl-D to finish)
val n = 10
for(i <- 1 until 10)println(i)
1 to 10 可以获取1~10之间的所有数字
1 until 10可以获取1~9之间的所有数字
to 和 until 其实都是函数,一个是闭区间,一个是开区间
scala> for(c <- "hello scala") println(c)
字符串操作
在这里for循环后面没有使用花括号,都省略了,因为for循环的循环体代码就只有一行
高级for
if守卫
if守卫模式,假设我们想要获取1~10之间的所有偶数,使用普通的for循环,需要把每一个数字都循环出来,然后判断是否是偶数。如果在for循环里面使用if守卫,可以在循环的时候就执行一定的逻辑,判断数值是否是偶数。scala> for(i <- 1 to 10 if i % 2 == 0) println(i)
yield 类似于 Collector.toList
我们在使用for循环迭代数字的时候,可以使用yield指定一个规则,对迭代出来的数字进行处理,并且创建一个新的集合
scala> for(i <- 1 to 10) yield i *2
res16: scala.collection.immutable.IndexedSeq[Int] = Vector(2, 4, 6, 8, 10, 12,14,16,18,20)
while
类似Java的while
集合体系 类似Java集合
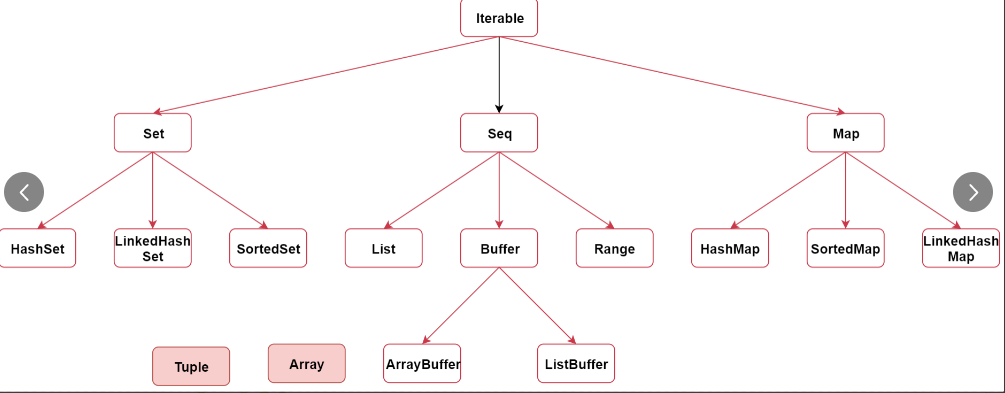
可变集合:在 scala.collection.mutable 这个包下面
不可变集合:在 scala.collection.immutable 这个包下面
在创建集合的时候,如果不指定具体的包名,默认会使用不可变集合。
Set:不需要new 关键字
scala> val s = scala.collection.mutable.SortedSet[String]()s: scala.collection.mutable.SortedSet[String] = TreeSet()
scala> s +=("c")
res45: s.type = TreeSet(c)
scala> s +=("a")
res46: s.type = TreeSet(a, c)
scala> s +=("b")
res47: s.type = TreeSet(a, b, c)
List:不需要new 关键字
scala> val lb = scala.collection.mutable.ListBuffer[Int]()
lb: scala.collection.mutable.ListBuffer[Int] = ListBuffer()
scala> lb +=1
res56: lb.type = ListBuffer(1)
scala> lb +=2
res57: lb.type = ListBuffer(1, 2)
scala> lb +=5
res58: lb.type = ListBuffer(1, 2, 5)
scala> lb -=5
res59: lb.type = ListBuffer(1, 2)#head:表示获取List中的第一个元素
#tail:表示获取List中第一个元素之后的所有元素#:: 通过 :: 操作符,可以将head和tail的结果合并成一个List
scala> l.head :: l.tail
res52: List[Int] = List(1, 2)
Map
scala> val ages = scala.collection.mutable.Map(("jack",30),("tom",25))
scala.collection.mutable.Map[String,Int] = Map(tom-> 25, jack -> 30)
scala> val age = ages("jack")age: Int = 30
scala> val age = ages("jack1")java.util.NoSuchElementException: key not found: jack1scala> val age = ages.getOrElse("jack1", 0)
age: Int = 0
Array
Scala中Array的含义与Java中的数组类似,长度不可变
由于Scala和Java都是运行在JVM中,双方可以互相调用,因此Scala数组的底层实际上就是Java数组,数组初始化后,长度就固定下来了,而且元素全部根据其类型进行初始化。
ArrayBuffer
Scala中ArrayBuffer与Java中的ArrayList类似,长度可变,ArrayBuffer:添加元素、移除元素
Tuple
Tuple:称之为元组,它与Array类似,都是不可变的,但与数组不同的是元组可以包含不同类型的元素,Tuple中的元素角标从 1 开始
注意:目前 Scala 支持的元组最大长度为 22 ,对于更大长度可以使用集合或数组。
scala> val t = (1, 3.14, "hehe")
t: (Int, Double, String) = (1,3.14,hehe)
scala> t._1
res117: Int = 1
scala> t._3
res118: String = hehe
集合总结
很多集合体系中的数据结构,有的是可变的,有的是不可变的,有的是既是可变的又是不可变
的,听起来有点乱,在这里总结一下
可变集合: LinkedHashSet、ListBuffer、ArrayBuffer、LinkedHashMap
不可变集合: List、SortedMap
可变+不可变集合: Set、HashSet、SortedSet、Map、HashMap还有两个编外人员:
Array、Tuple
Array:长度不可变,里面的元素可变
Tuple:长度不可变,里面的元素也不可变
函数
在Scala中定义函数需要使用 def 关键字,函数包括函数名、参数、函数体。
Scala要求必须给出函数所有参数的类型,但是函数返回值的类型不是必须的,因为Scala可以自己根据函数体中的表达式推断出返回值类型。
函数中最后一行代码的返回值就是整个函数的返回值,不需要使用return,这一点与Java不同,java中函数的返回值是必须要使用return的。
scala> :paste
// Entering paste mode (ctrl-D to finish)
def sayHello(name: String, age: Int) = {println("My name is "+name+",age is "+age)
age
}
// Exiting paste mode, now interpreting.
sayHello: (name: String, age: Int)Int
scala> sayHello("Scala",18)My name is Scala,age is 18
res120: Int = 18
默认参数
scala> def sayHello(fName: String, mName: String = "mid", lName: String = "last")
sayHello: (fName: String, mName: String, lName: String)String
scala> sayHello("zhang","san")res122: String = zhang san last
带名参数
在调用函数时,也可以不按照函数定义的参数顺序来传递参数,而是使用带名参数的方式来传递。
scala> def sayHello(fName: String, mName: String = "mid", lName: String = "last")
sayHello: (fName: String, mName: String, lName: String)String
scala> sayHello(fName = "Mick", lName = "Tom", mName = "Jack")res127: String = Mick Jack Tom
可变参数
在Scala中,有时我们需要将函数定义为参数个数可变的形式,可以使用变长参数来定义函数。
scala> :paste
// Entering paste mode (ctrl-D to finish)
def sum(nums: Int*) = {var res = 0 for (num <- nums) res += num
res
}
// Exiting paste mode, now interpreting.
sum: (nums: Int*)Int
scala> sum(1,2,3,4,5)res129: Int = 15
特殊的函数-过程
在Scala中,定义函数时,如果函数体直接在花括号里面而没有使用=连接,则函数的返回值类型就是Unit,这样的函数称之为过程,过程通常用于不需要返回值的函数
过程还有一种写法,就是将函数的返回值类型显式定义为Unit 。
区别:
// 函数
def sayHello(name: String) = "Hello, " + name
def sayHello(name: String): String = "Hello, " + name
// 过程
def sayHello(name: String) { "Hello, " + name }
def sayHello(name: String): Unit = "Hello, " + name
lazy
Scala提供了lazy特性,如果将一个变量声明为lazy,则只有在第一次使用该变量时,变量对应的表达式才会发生计算,这种特性对于特别耗时的操作特别有用,比如打开文件这个操作。
scala> import scala.io.Source._import scala.io.Source._
// 即使D://test.txt文件不存在,代码也不会报错,只有变量使用时才会报错
scala> lazy val lines = fromFile("D://test.txt").mkStringlines: String = <lazy>
Scala面向对象编程
主要学习Scala中的类、对象和接口注意:
Scala中类和java中的类基本是类似的
Scala中的对象时需要定义的,而java中的对象是通过class new出来的
Scala中的接口是trait,java中的接口是interface
类:
class Person{
var name = "scala"
def sayHello(){
println("Hello,"+name)
}
def getName= name
}object Person {
var age = 1
println("this Person object!")
def getAge = age
}
伴生对象
object Person {
private val fdNum= 1
def getFdNum = fdNum
}
class Person(val name: String, val age: Int) {
def sayHello = println("Hi, " + name + ",you are " + age + " years old!"
}

从Array object的源码中可以看出来,它里面就是在apply方法内部使用new Array创建的对象
class Person(val name: String){
println("my name is,"+name)
}
object Person {
def apply(name: String) = {
println("apply exec...")
new Person(name)
}
}
package com.demo
/**
* Created by xuwei
*/
object mainDemo {
def main(args: Array[String]): Unit = {
println("hello scala!")
}/**
* Created by xuwei
*/
object PersonDemo {
def main(args: Array[String]): Unit = {
val p1 = new Person("tom")
val p2 = new Person("jack")
p1.sayHello(p2.name)
p1.makeFriends(p2)
}
}
trait HelloTrait { def sayHello(name: String)}
trait MakeFriendsTrait { def makeFriends(p: Person)}
class Person(val name: String) extends HelloTrait with MakeFriendsTrait {
def sayHello(name: String) = println("Hello, " + name)
def makeFriends(p: Person) = println("Hello, my name is " + name + ", your
}
//先定义一个匿名函数,赋值给变量sayHelloFunc
val sayHelloFunc = (name: String) => println("Hello, " + name)
//再定义一个高阶函数,这个高阶函数的参数会接收一个函数
//参数: (String) => Unit 表示这个函数接收一个字符串,没有返回值
def greeting(func: (String) => Unit, name: String) { func(name) }
![]()
![]()
# 先定义一个高阶函数
def greeting(func: (String) => Unit, name: String) { func(name) }
# 使用高阶函数:完整写法
greeting((name: String) => println("Hello, " + name), "scala")
# 使用高阶函数:高阶函数可以自动推断出参数类型,而不需要写明类型
greeting((name) => println("Hello, " + name), "scala")
# 使用高阶函数:对于只有一个参数的函数,还可以省去其小括号
greeting(name => println("Hello, " + name), "scala")def demo1(day: Int) {
day match {
case 1 => println("Monday")
case 2 => println("Tuesday")
case 3 => println("Wednesday")
case _ => println("none")
}
}import java.io._
def processException(e: Exception) {
e match {
case e1: IllegalArgumentException => println("IllegalArgumentException "
case e2: FileNotFoundException => println("FileNotFoundException " + e2)
case e3: IOException => println("IOException " + e3)
case _: Exception => println("Exception " )
}
}
// try - catch 应用
try {
val lines02 = scala.io.Source.fromFile("D://test02.txt").mkString
} catch {
case ex: FileNotFoundException => println("no file")
case ex: IOException => println("io exception")
case ex: Exception => println("exception")
}class Person
case class Teacher(name: String, sub: String) extends Person
case class Student(name: String, cla: String) extends Person
def check(p: Person) {
p match {
case Teacher(name, sub) => println("Teacher, name is " + name + ", sub is
case Student(name, cla) => println("Student, name is " + name + ", cla is
case _ => println("none")
}
}
val ages = Map("jack" -> 18, "tom" -> 30, "jessic" -> 27)
def getAge(name: String) {
val age = ages.get(name)
age match {
case Some(age) => println("your age is " + age)
case None => println("none")
}
}
class cat(val name: String){
def catchMouse(){println(name+" catch mouse")}
}
class dog(val name: String)
implicit def object2Cat (obj: Object): cat = {
if (obj.getClass == classOf[dog]) {
val dog = obj.asInstanceOf[dog]
new cat(dog.name)
}
else Nil
}