质数
试除法判定质数
输入一个数n判断是否为质数
步骤----for循环从2开始(小于2的不是质数也不是合数),结束条件为i<=n/i(注意等于号),所有质数一定在根号n左边(有证明可自己去找),只需判断n%i是否有余数就行
代码:
#include <iostream>
using namespace std;
bool is_prime(int a)
{
if(a<2) return false;//小于2的直接排除
for(int i=2;i<=a/i;i++)//注意是小于等于 5*5=25
{
if(a%i==0) return false;
}
return true;
}
int main(){
int n;
cin>>n;
while(n--){
int a;
cin>>a;
if(is_prime(a))cout<<"Yes"<<endl;
else cout<<"No"<<endl;
}
return 0;
}分解质因数
质数=素数,因数=约数
质因数:
每个合数都可以写成几个质数相乘的形式。其中每个质数都是这个合数的因数,叫做质因数。
把一个合数用质因数相乘的形式表示出来,叫做分解质因数。

如果能除(无余数) 就一直除到不能除为止,由于从小到大遍历,且一旦满足就会除尽,所以按照这个步骤最后能得到所有质因子(互质)
代码
#include<iostream>
using namespace std;
int n;
void divide(int a){
for(int i=2;i<=a/i;i++)
{
int s=0;
if(a%i==0){
while(a%i==0)
{
a/=i;
s++;
}
cout<<i<<" "<<s<<endl;
}
}
if(a>1)cout<<a<<" "<<1<<endl;
cout<<endl;
}
int main(){
cin>>n;
while(n--){
int a;
cin>>a;
divide(a);
}
return 0;
}筛质数
朴素筛法(埃式筛法)
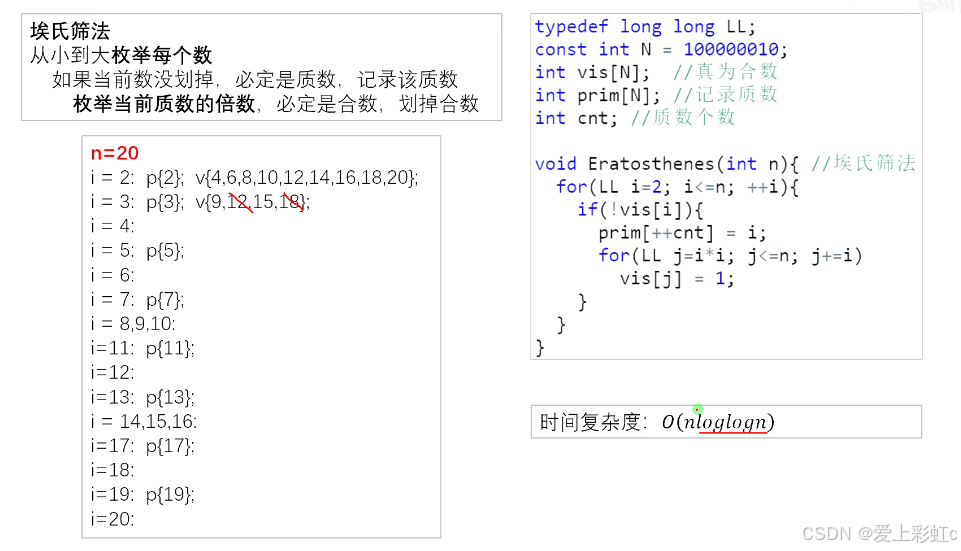
思想就是每次枚举到某个数,就把数据范围内所有这个数的倍数筛掉(枚举到的这个数一定是质数,因为如果不是在前面就会被筛掉)
需要一个数组vis记录是否为合数
一个数组prim记录所有质数(当前数如果是质数就加入)
cnt相当于索引
有一个细节,i开始筛的时候是从i*i开始的,比如此时i=3,遍历筛倍数就从9开始,9,12,15...,可以降低重复
代码:
#include <iostream>
#include <cstring>
using namespace std;
const int N=1e6+10;
typedef long long LL;
int vis[N],prim[N];
int A_get_prime(int n){
int cnt=0;
for(LL i=2;i<=n;i++){
if(!vis[i]){
prim[cnt++]=i;
for(LL j=i*i;j<=n;j+=i){
vis[j]=1;
}
}
}
return cnt;
}
int main(){
int n;
cin>>n;
memset(vis,0,sizeof vis);
cout<<A_get_prime(n);
return 0;
}当然,使用longlong主要是在j那里会进行一次乘法可能会爆内存,所以j用longlong,i也要改成longlong类型才满足类型转换,如果不用longlong就把i*i改成i+i,这样不会爆内存
线性筛法(欧拉筛)
优化是,每个合数只被他的最小质因数筛掉,而且只筛掉一遍,时间复杂度是O(n)
参考证明:【欧拉筛法】https://www.bilibili.com/video/BV1gyNJeVEfz?vd_source=5ee68676a0e9e18690592f6c4e3cff49
AcWing 868. 线性筛的正确性和复杂度证明 - AcWing
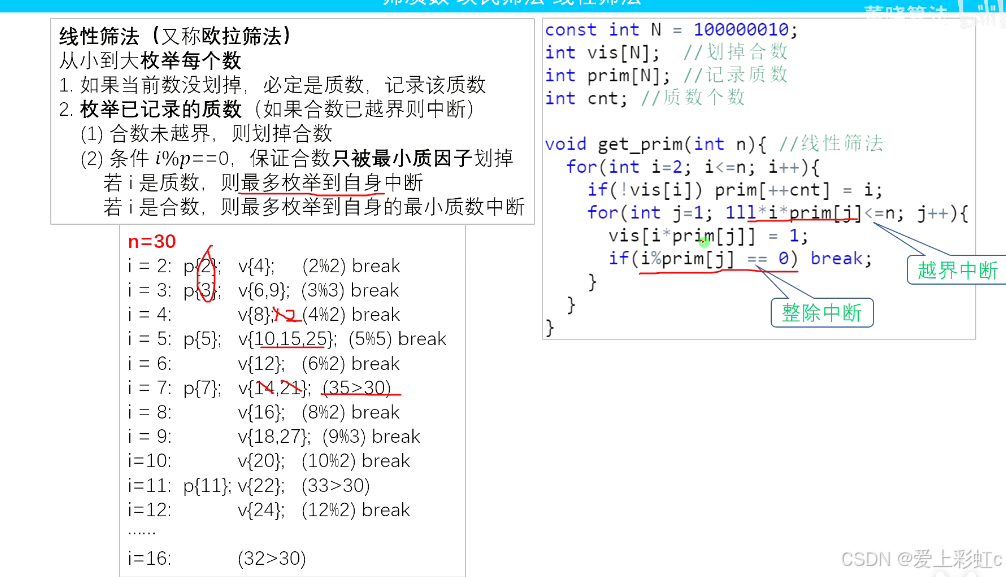
代码层面上看,就是在朴素筛法的基础上,每次增加判断,遍历质数集合的每个数,判断条件是
当前i*素数集合里的素数不超过范围n,如果i%prim[j]==0就中断,但是最少要乘一个素数
代码:
#include <iostream>
#include <cstring>
using namespace std;
const int N=1e6+10;
typedef long long LL;
int vis[N],prim[N];
int O_get_prime(int n){
int cnt=0;
for(LL i=2;i<=n;i++){
if(!vis[i])
{
prim[cnt++]=i;
}
for(int j=0;prim[j]*i<=n;j++){
vis[prim[j]*i]=1;
if(i%prim[j]==0)break;
}
}
return cnt;
}
int main(){
int n;
cin>>n;
memset(vis,0,sizeof vis);
cout<<O_get_prime(n);
return 0;
}注意大括号的范围,线性筛是遍历到每一个数都要进行一个for循环
具体证明思路,下次再写
约数

试除法求约数
思路和试除法求质数一样,只是说我们要把求到的约数存起来,然后输出,并且有一个小细节
x是i的约数,那么i/x也是i的约数,我们循环的时候可以一起加入约数集合,这样可以只循环根号n
代码
#include <iostream>
#include <algorithm>
#include <vector>
using namespace std;
vector<int> get_divisors(int a){
vector <int> ans;
for(int i=1;i<=a/i;i++){//注意这里是小于等于是因为防止漏掉比如5*5=25,
//但是这样会压入两个5,所以下面要有个判断
if(a%i==0){
ans.push_back(i);
if(i!=(a/i))ans.push_back(a/i);
}
}
sort(ans.begin(), ans.end());//之所以用排序能降低时间复杂度
//是因为约数相比于遍历原数的个数小很多
return ans;
}
int main(){
int n;
cin>>n;
while(n--){
int a;
cin>>a;
vector<int> res=get_divisors(a);
for(auto t:res){
cout<<t<<" ";
}
cout<<endl;
}
return 0;
}
约数个数
注意,可以用筛法求1到n的约数个数和约数之和,这个我们遇见题目再学习,下面主要是实现两个公式
在我们分解质因数之后,对于每一个质因数,可以取0个 1个 2个 ...共有 ai+1种取法,所以约数个数就是上面那个公式
约数之和就是遍历所有约数加起来,也就是每个质因子的所有可能取得的个数依次遍历再相乘,记两遍就好了
用unordered_map存储质因数分解后的结果
#include <iostream>
#include <algorithm>
#include <cstring>
#include <unordered_map>
using namespace std;
const int N=110;
const int mod=1e9+7;
unordered_map <int,int> m;
int main(){
int n;
cin>>n;
while(n--)
{
int a;
cin>>a;
for(int i=2;i<=a/i;i++)//注意结束条件,遍历一半
{
while(a%i==0)
{
a/=i;
m[i]++;
}
}
if(a>1)m[a]++;
}
long long res=1;
for(auto t:m){
res=(res*(t.second+1))%mod;
}
cout<<res;
return 0;
}
约数之和

核心计算如上
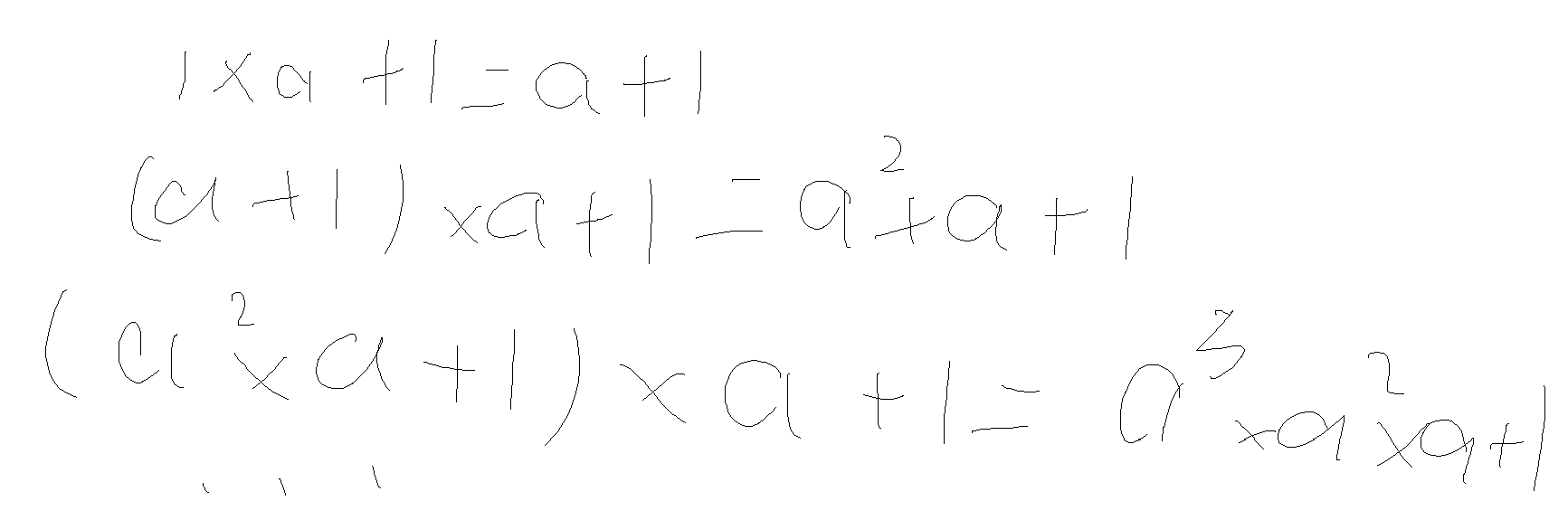
#include <iostream>
#include <algorithm>
#include <cstring>
#include <unordered_map>
using namespace std;
typedef long long ll;
const int N=110;
const int mod=1e9+7;
unordered_map <int,int> m;
int main(){
int n;
cin>>n;
while(n--)
{
int a;
cin>>a;
for(int i=2;i<=a/i;i++)
{
while(a%i==0)
{
a/=i;
m[i]++;
}
}
if(a>1)m[a]++;
}
ll res=1;
for(auto t:m){
ll a=t.first,b=t.second;
ll x=1;
while(b--)x=(x*a+1)%mod;
res=res*x%mod;
}
cout<<res;
return 0;
}
最大公约数
辗转相除法,证明的话不在这里证明了,结论非常好记忆 a和b的公约数 等于 b和 a%b的公约数
不用考虑 a b大小,如果a<b 第一轮的结果是 gcd(b,a) a%b=a;

代码:
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
int n;
int gcd(int a,int b)
{
if(a%b==0) return b;
return gcd(b,a%b);
}
int main(){
cin>>n;
while(n--){
int a,b;
cin>>a>>b;
cout<<gcd(a,b)<<endl;
}
return 0;
}快速幂

#include <iostream>
using namespace std;
int n;
int main(){
cin>>n;
while(n--)
{
long long a,b,p;
cin>>a>>b>>p;
long long res=1;//尽量使用longlong
while(b)
{
if(b&1)res=(res*a)%p;
a=a*a%p;//注意这里也要取模,否则会溢出,取模运算在除了除法里可以随意用
b>>=1;
}
cout<<res<<endl;
}
return 0;
}快速幂(费马小定理)求逆元


只要 a p互质逆元就存在,如果要使用费马小定理还要求p是质数,这样就可以直接用快速幂求解
#include <iostream>
using namespace std;
typedef long long ll;
int n;
ll qim(int a,int b,int p)
{
ll u=(ll)a;
ll res=1;
while(b)
{
if(b&1)res=res*u%p;
u=u*u%p;//注意算术优先级 如果是u*=u%p 其实是先算了取余,所以会报错
b>>=1;
}
return res;
}
int main(){
cin>>n;
while(n--){
int a,p;
cin>>a>>p;
if(!(a%p))cout<<"impossible"<<endl;
else cout<<qim(a,p-2,p)<<endl;;
}
return 0;
}
求组合数
四种方法对应四种不同的数据表现形式
方法1---朴素递推公式(打表)
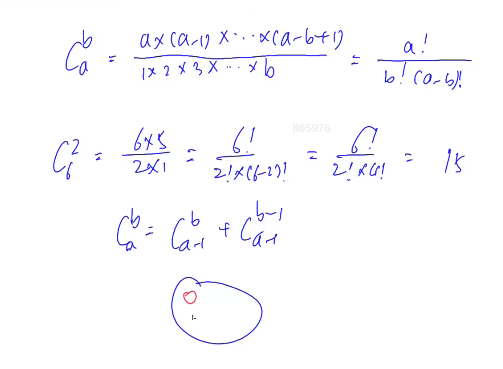

有取余操作,且可以递推打表
需要记住的细节是,初始化时,j=0的点初值都赋值为1,每次循环遍历的时
00
10 11
20 21 22
30 31 32 33...
00 11 22 33的值都是1,这个不用特别去赋值,遍历过程中会实现
代码
#include <iostream>
using namespace std;
const int N=2010;
const int mod=1e9+7;
int c[N][N];
void init()
{
for(int i=0;i<N;i++)
for(int j=0;j<=i;j++)
{
if(!j)c[i][j]=1;
else c[i][j]=(c[i-1][j]+c[i-1][j-1])%mod;
}
}
int main()
{
init();
int n;
cin>>n;
while(n--){
int a,b;
cin>>a>>b;
cout<<c[a][b]<<endl;
}
return 0;
}
方法2---快速幂,求乘法逆元

在取模运算中,除一个数相当于乘这个数的乘法逆元(这个时候就可以转换为乘法)
对于组合数公式
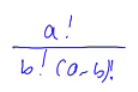
我们需要知道a的阶乘,以及b的阶乘和a-b的阶乘的逆元
我们知道如果a对p取模,只要满足a p互质就有逆元,满足p是质数就能用费马小定理,也就是可以用快速幂求解,题目中是对一个很大的·质数取模所以满足条件,如何对阶乘求逆元,这里用了一个递推式,相当于对i求逆元再和i-1的阶乘的逆元相乘
所以我们需要打表,记录阶乘和逆元,最后计算,时间复杂度大约为o(n)
代码:
#include <iostream>
using namespace std;
typedef long long ll;
const ll N=100010;
const ll q=1e9+7;
ll f[N],g[N];
ll qmi(ll a, ll k, ll p)
{
ll res = 1;
while (k)
{
if (k & 1) res = res * a % p;
a = a * a % p;
k >>= 1;
}
return res;
}
int main()
{
int n;
cin>>n;
f[0]=g[0]=1;
for(ll i=1;i<=N;i++)
{
f[i]=f[i-1]*i%q;
g[i]=g[i-1]*qmi(i,q-2,q)%q;
// cout<<i<<" "<<f[i]<<" "<<g[i]<<endl;
}
while(n--)
{
int a,b;
cin>>a>>b;
cout << f[a] % q * g[b] % q * g[a-b] % q << endl;
}
return 0;
}非常容易越界,不知道怎么添加ll就全部都写成ll
方法3 ---卢卡斯定理
记住结论,套用公式就行,当然这里要用前面乘法逆元的板子

#include<iostream>
#include <cstring>
using namespace std;
const int N=100010;
long long f[N],g[N];
long long locus(long long a,long long b,int q)
{
if(b==0)return 1;
return locus(a/q,b/q,q)%q*(f[a%q]%q*g[b%q]%q*g[a%q-b%q]%q);
}
long long qmi(long long a,long long b,long long q)
{
long long res=1;
while(b)
{
if(b&1)res=res*a%q;
a=(long long)a*a%q;
b>>=1;
}
return res;
}
int main(){
int n;
cin>>n;
while(n--)
{
long long q;
long long a,b;
cin>>a>>b>>q;
memset(f,0,sizeof f);
memset(g,0,sizeof g);
f[0]=g[0]=1;
for(long long i=1;i<q;i++)
{
f[i]=(long long)f[i-1]*i%q;
g[i]=(long long)g[i-1]%q*qmi(i,q-2,q)%q;
}
cout<<locus(a,b,q)%q<<endl;
}
return 0;
}一直报错,问题出在边界,取模要考虑所有情况,不能漏掉取模,还有尽量开longlong
方法4---高精度乘法+线性筛
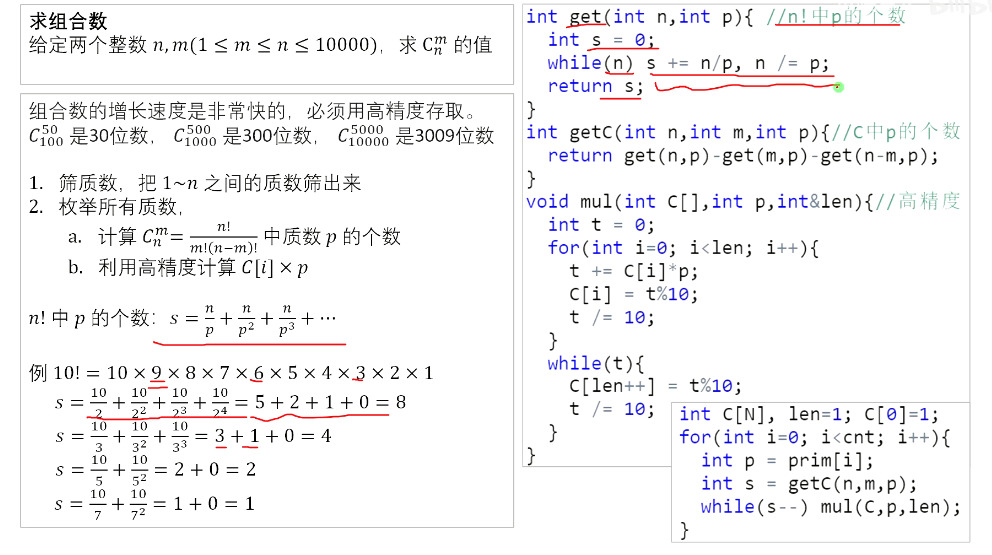
将所有阶乘分解质因数
#include <iostream>
#include <algorithm>
#include <cstring>
#include <vector>
using namespace std;
const int N=20001;
int C[N],len=1;
int prime[5010],st[5010],cnt;
int s[5010];
int a,b;
//线性筛法求质数
void get_prime(int a)
{
memset(st,0,sizeof st);
memset(prime,0,sizeof prime);
cnt=0;
for(int i=2;i<=a;i++)
{
if(!st[i])prime[cnt++]=i;
for(int j=0;j<cnt&&prime[j]<=a/i;j++)
{
st[prime[j]*i]=1;
if(i%prime[j]==0)break;
}
}
}
int get_C(int a,int p)
{
int res=0;
while(a){
res+=a/p;
a/=p;
}
return res;
}
void mul(int C[N],int p,int &len)
{
int t=0;
for(int i=0;i<len;i++){
t=t+p*C[i];
C[i]=t%10;
t/=10;
}
while(t){
C[len++]=t%10;
t/=10;
}
}
int main()
{
cin>>a>>b;
//对这个组合数进行分解质因数
//1.枚举范围内所有的质数---线性筛
get_prime(a);
//输出2到a内所有质数
// for(int i=0;i<cnt;i++)cout<<prime[i]<<" ";
//2.分解质因数,看看每个质数有多少个
for(int i=0;i<cnt;i++)
s[i]=get_C(a, prime[i])-get_C(b,prime[i])-get_C(a-b,prime[i]);
//查看分解质因数的结果
// for(int i=0;i<cnt;i++)cout<<prime[i]<<" "<<s[i]<<endl;
//3.高精度乘法
memset(C, 0, sizeof C); // 初始化高精度数组
C[0]=1;
for(int i=0;i<cnt;i++)
{
int u=s[i];
while(u>0)
{
mul(C,prime[i],len);
u--;
}
}
for(int i=len-1;i>=0;i--) cout<<C[i];
return 0;
}