Proxmox VE 是一个功能强大、开源的虚拟化平台,结合了 KVM 和 LXC,同时支持高可用集群、存储管理(ZFS、Ceph)和备份恢复。相比 VMware ESXi 和 Hyper-V,PVE 具有开源、低成本、高灵活性的特点,适用于中小企业、开发测试环境以及私有云建设。如果需要一个免费的、开源的企业级虚拟化解决方案,PVE 是一个值得考虑的选择。
安装过程非常简单的,下面简单讲解一下部署超融合的步骤:
一、创建集群
下面是硬件配置,共三台
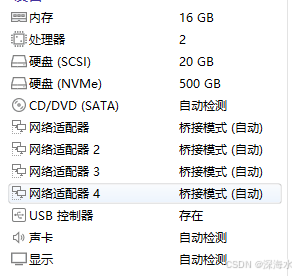
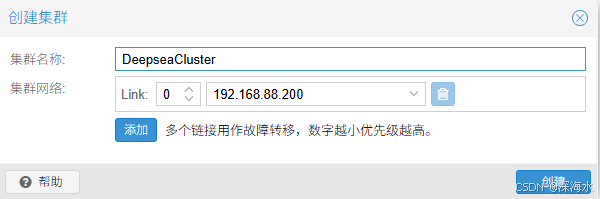
安装完之后创建集群

输入集群名称
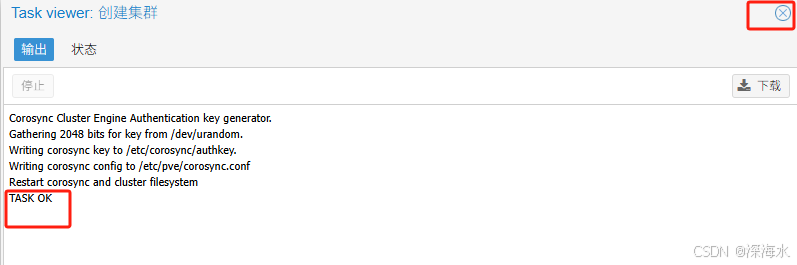
检查输出状态没有问题之后关闭
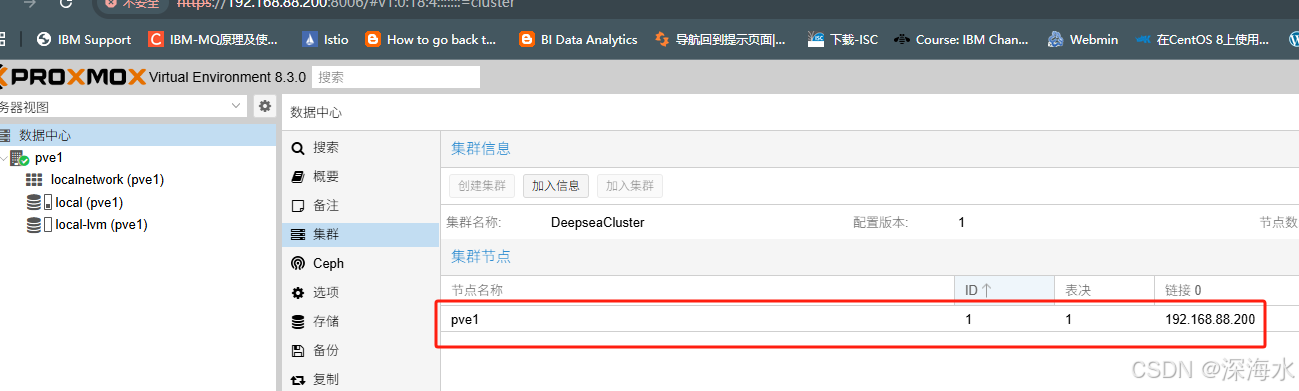
 创建好之后如下
创建好之后如下
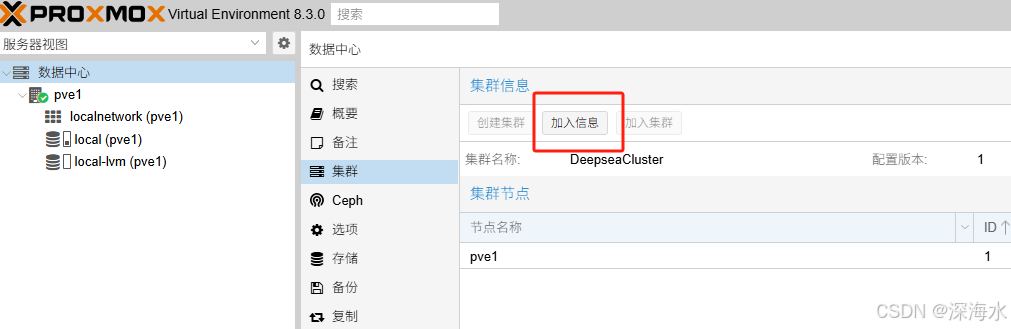
登陆第二台服务器加入集群

出现下图 需要输入加入信息
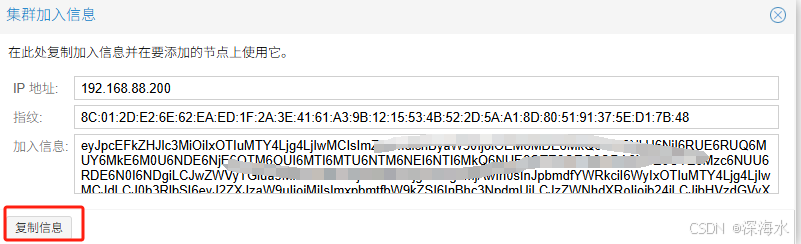
加入信息在第一台复制,如下图
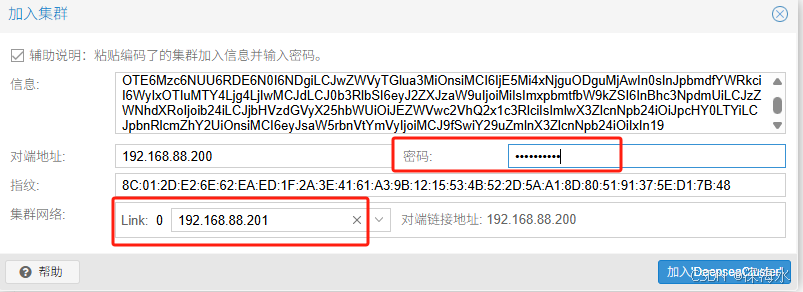
 粘贴加入信息,并选择管理网卡和输入密码
粘贴加入信息,并选择管理网卡和输入密码
下图出现关闭
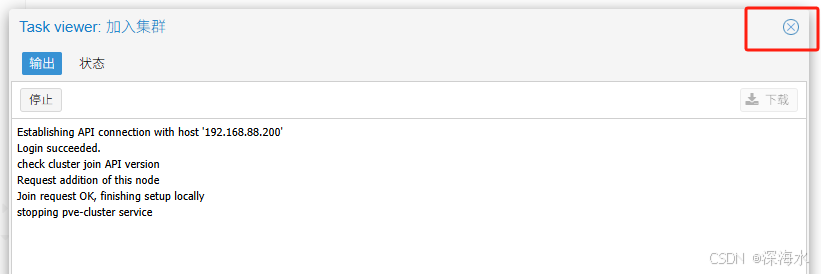
刷新登陆可以看到下图
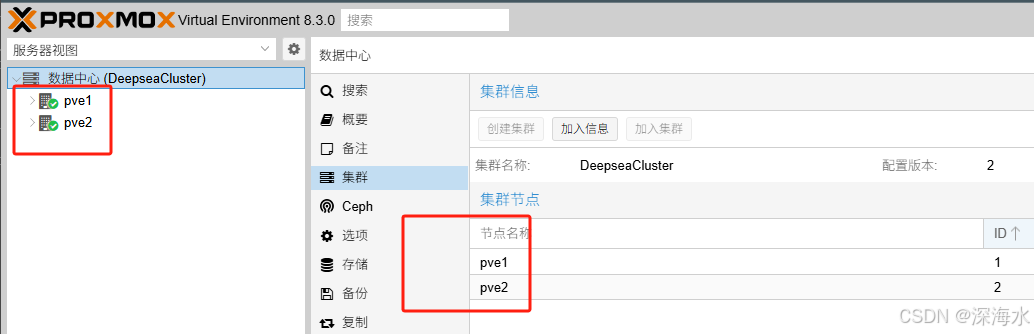
以此类推,把其余主机加入
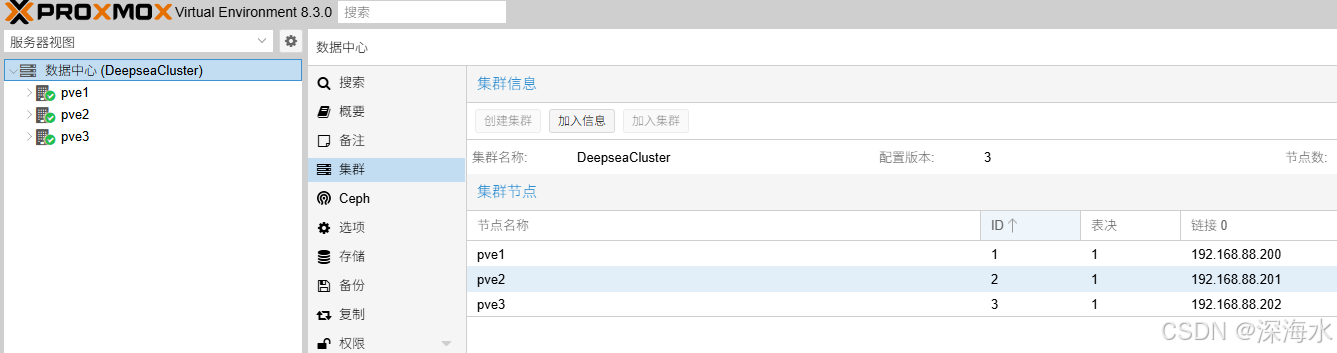
二、创建网络用于连接存储
在每台主机上添加网络配置,这里使用的是Bond
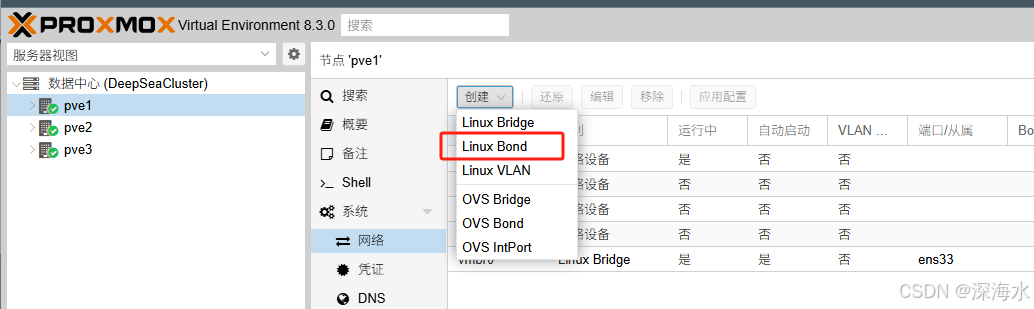
下面是的Bond特点,请根据实际情况选择
| 模式 | 模式编号 | 特点 |
|---|---|---|
| LACP(802.3ad) | mode=4 |
需要支持 LACP 交换机,带宽聚合+负载均衡+故障恢复 |
| Active-Backup | mode=1 |
简单,适合冗余,但不增加带宽 |
| Balance-XOR | mode=2 |
负载均衡,需交换机支持 |
📌 最佳选择:LACP(802.3ad)
需要 支持 LACP(链路聚合控制协议)的交换机
在 交换机端 配置 LAG(链路聚合组)
双网卡 2x10Gbps,可提升到 20Gbps 带宽
因交换机不支持,所以这里选择了Active-Backup,注意要配置使用不同网段
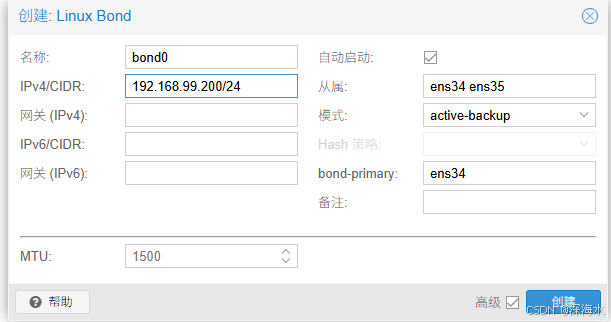
应用配置让生效,生效如下图
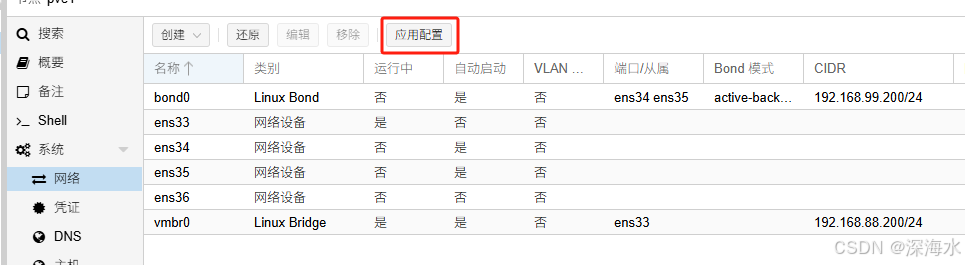
应用之后如下图处于运行中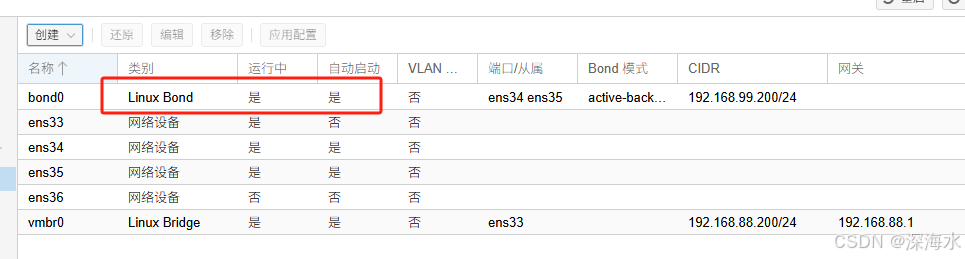
其余主机重复上述步骤
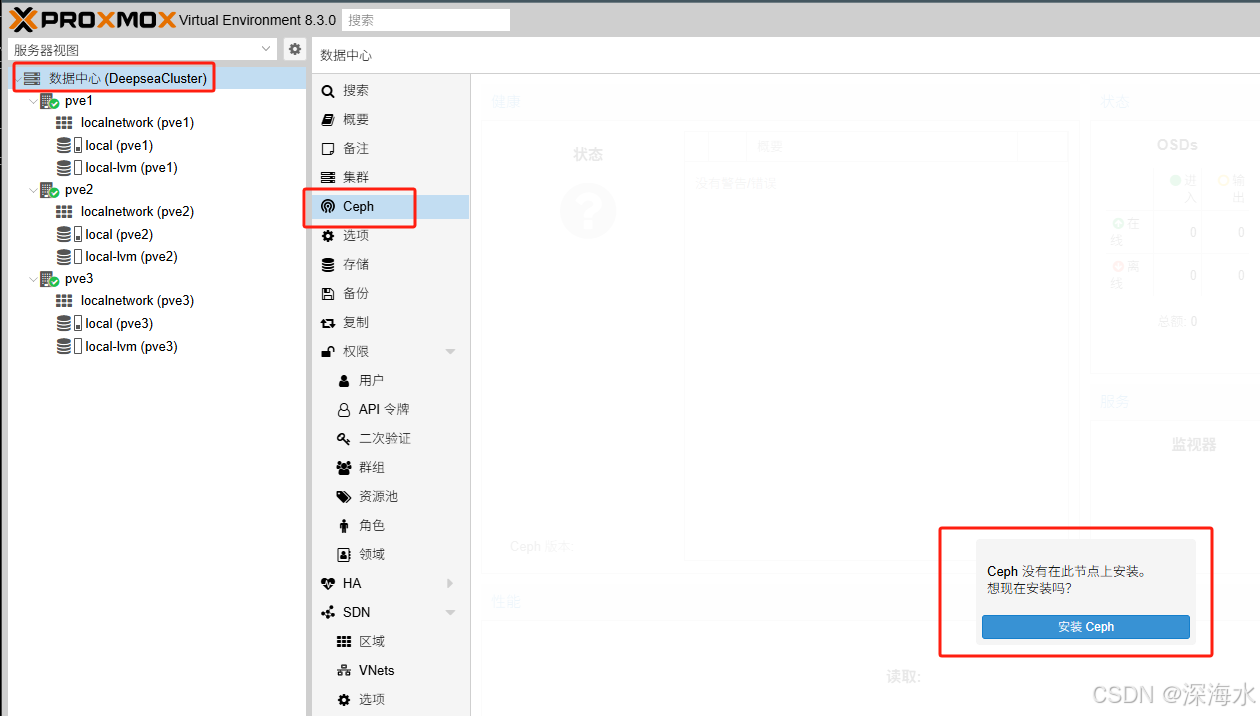
三、安装和配置Ceph
Ceph 是一个开源的分布式存储系统,在 Proxmox VE(PVE) 中可用于 高可用共享存储,支持 块存储(RBD)、文件存储(CephFS)和对象存储(RGW)。
📌 适用场景:
高可用存储:无单点故障,数据自动复制
Proxmox HA(高可用集群):支持 VM 迁移
分布式存储:自动均衡,扩展性强
每个节点至少 1 块 SSD/HDD(用于 OSD),前文有讲述,这里不再重复,开始配置:
 下图因没有订阅,因此选择“无订阅”
下图因没有订阅,因此选择“无订阅”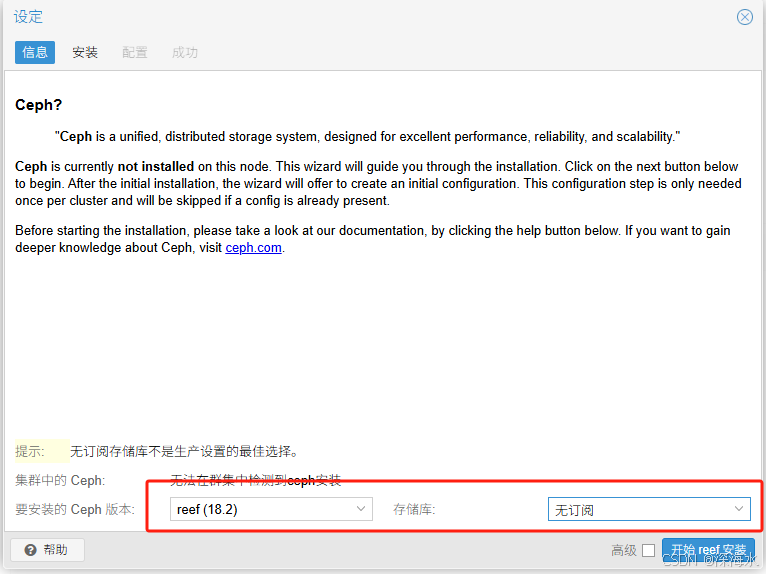
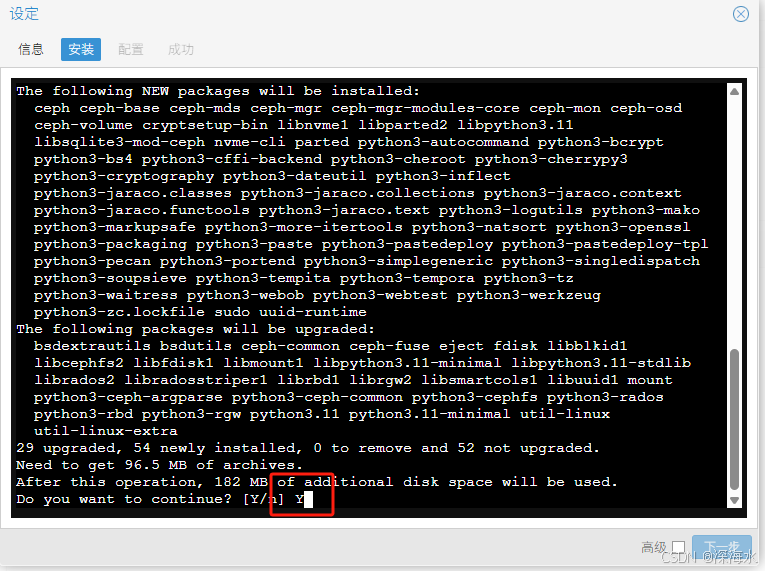
下图输入Y完成安装
 出现下图表示安装完成
出现下图表示安装完成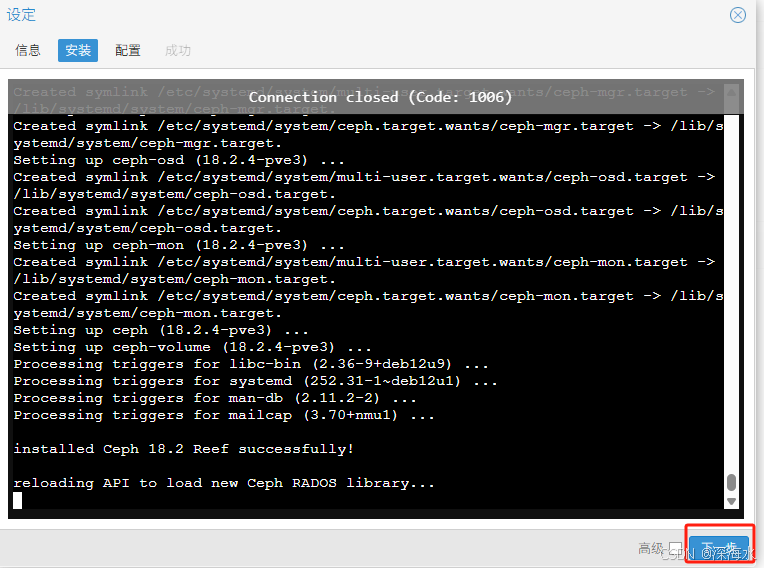
选择上步创建的网络
public_network(192.168.88.0/24):用于客户端访问
cluster_network(192.168.99.0/24):专门用于 OSD 数据复制
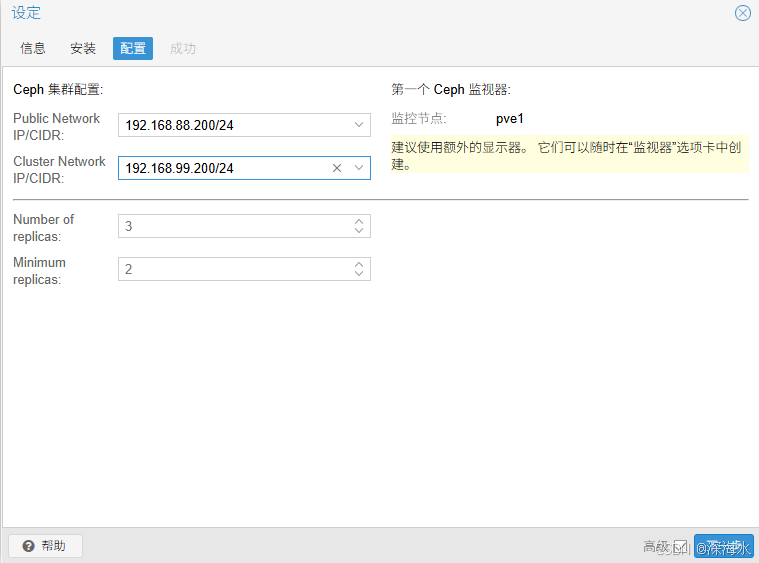
下图表示成功
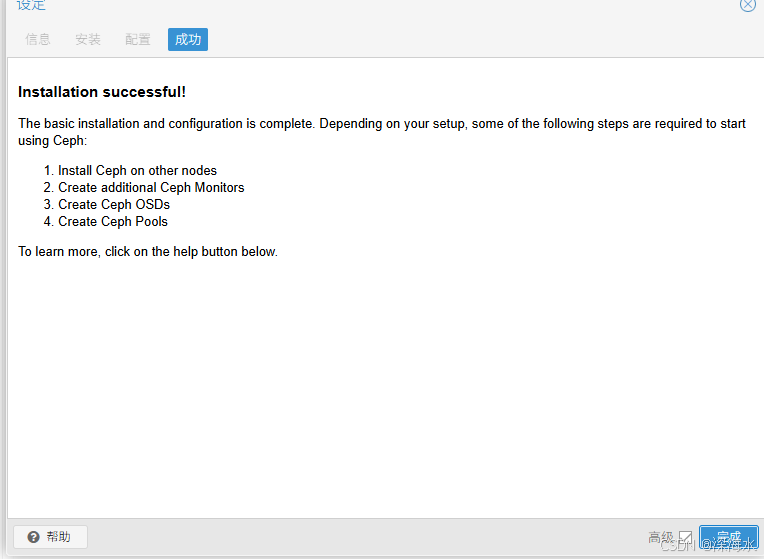 登陆到其余主机节点,按上面办法完成安装。
登陆到其余主机节点,按上面办法完成安装。

下图选择一个主机, 添加监视器
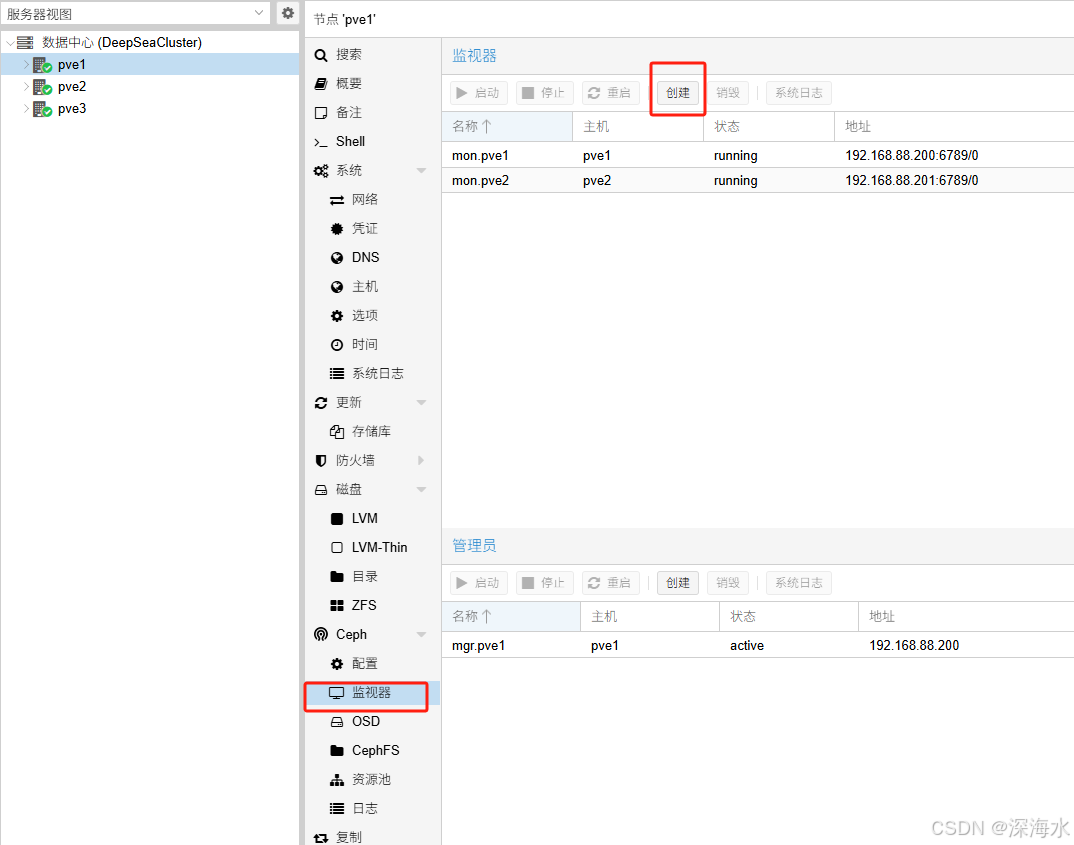
将各个节点全部添加进去
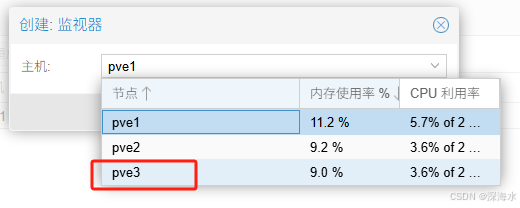
添加完如下图
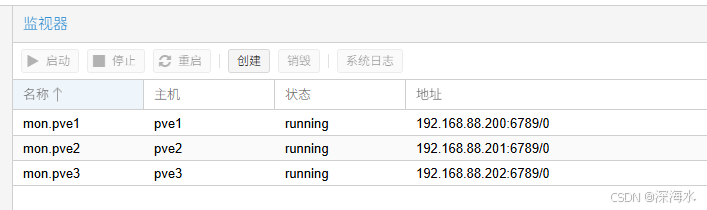 添加完成后,主机状态显示running,表示正常。开始创建Ceph OSD
添加完成后,主机状态显示running,表示正常。开始创建Ceph OSD

根据实际情况选择硬盘

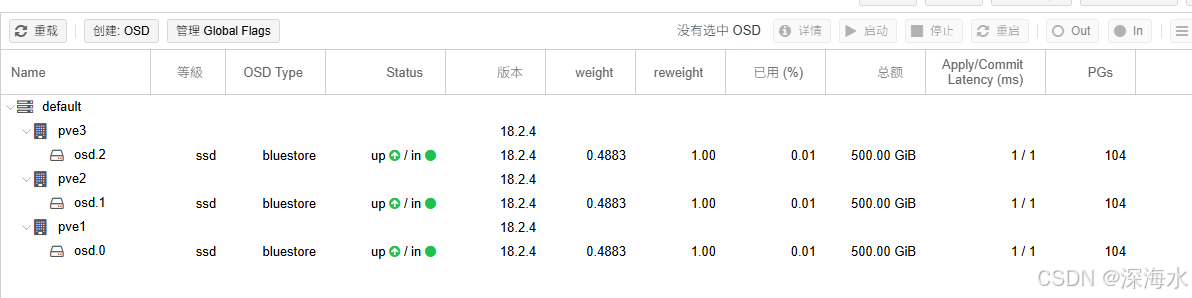
添加完之后稍等几秒,如果没有up,可以手动启动
在每个节点上将硬盘添加上,例如三个节点,每个节点500GB,最终结果如下:
创建资源池
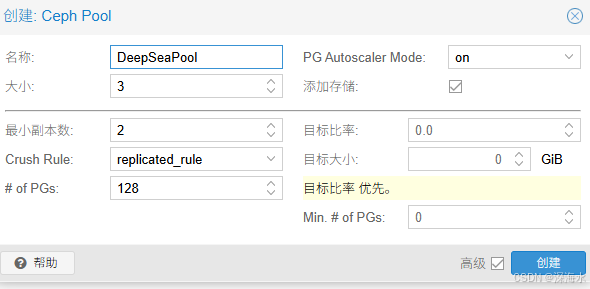
成功之后如下图
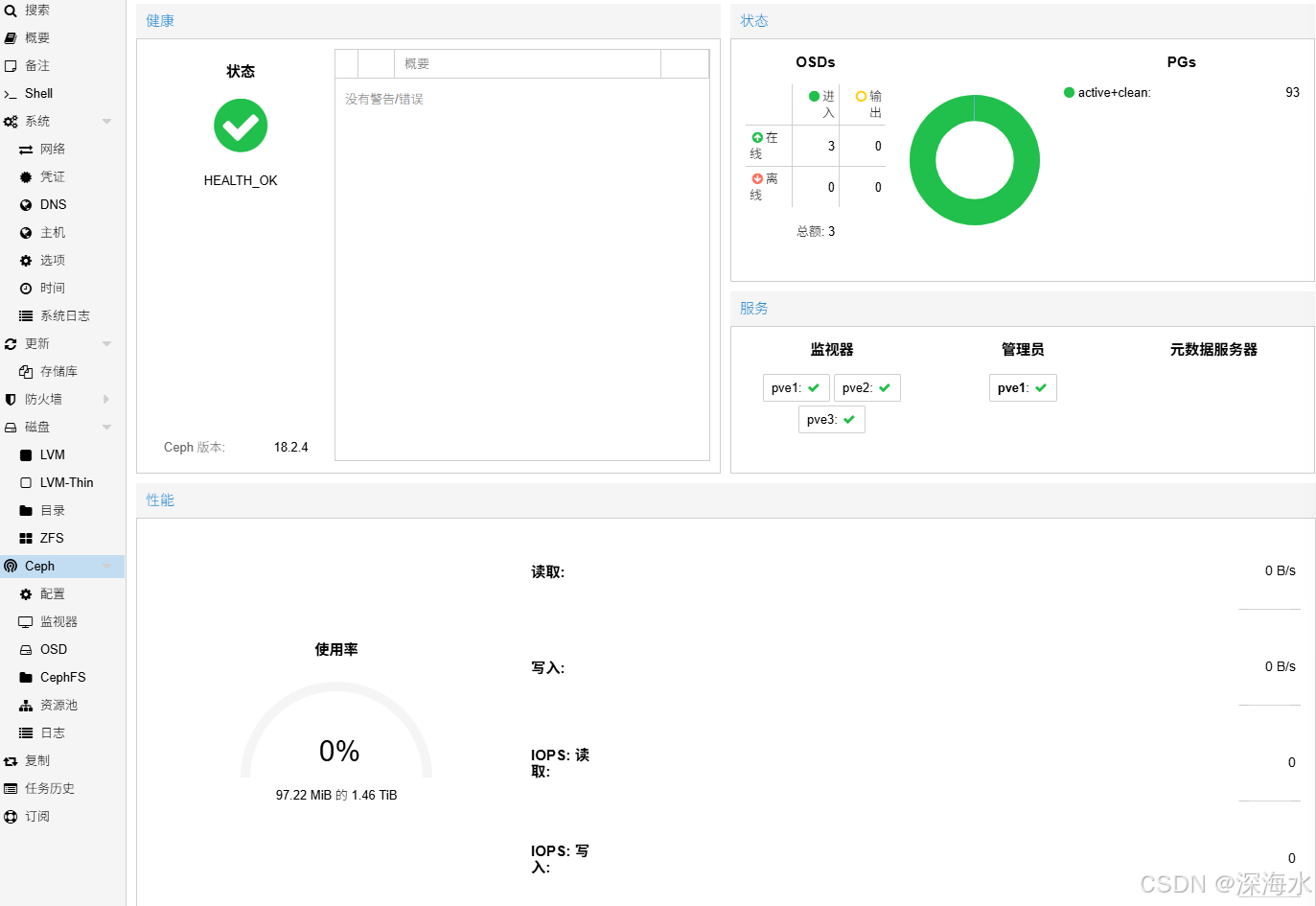
创建好的存储资源池
还可以在集群的“存储”中添加其他存储,如下图添加SMB/CIFS

结果如下
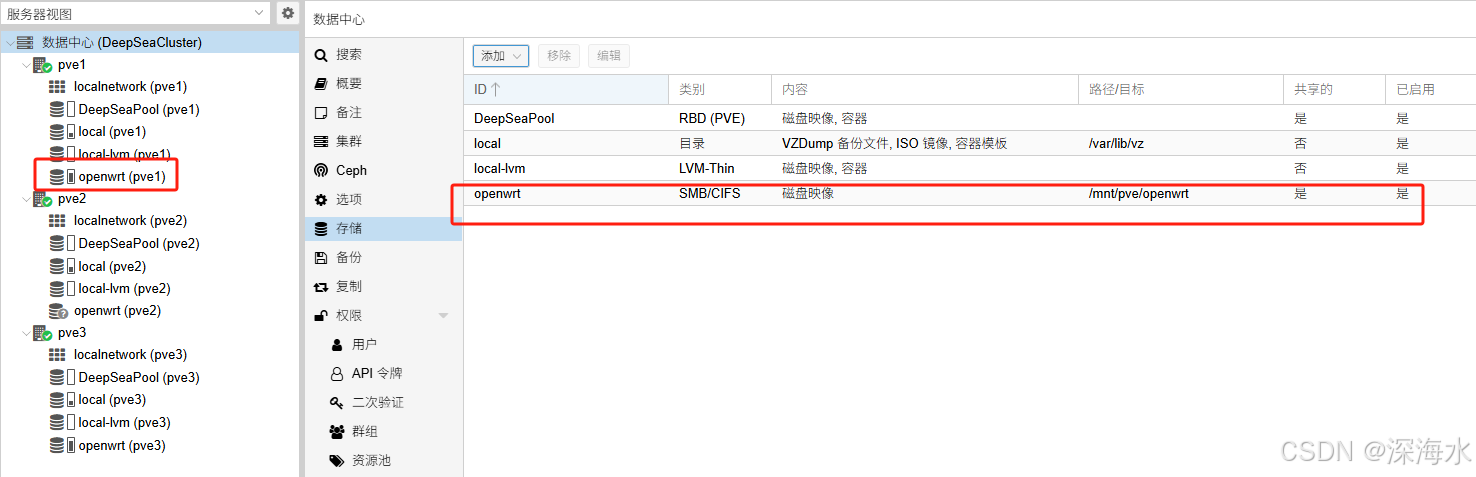
以上完成之后,就可以开始使用该存储创建虚拟机了。
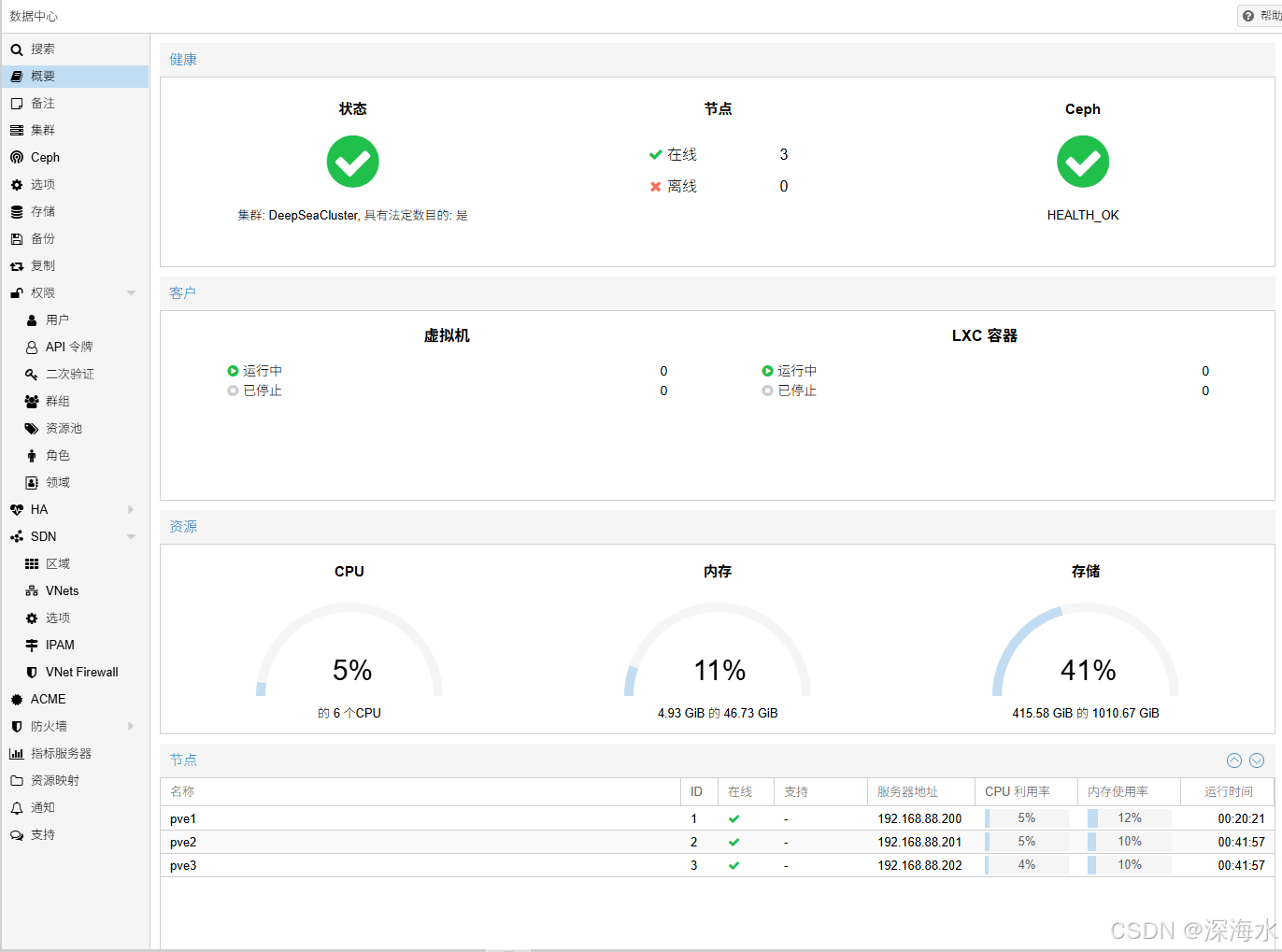
通过以下可以监测到系统运行状态
四、安装系统
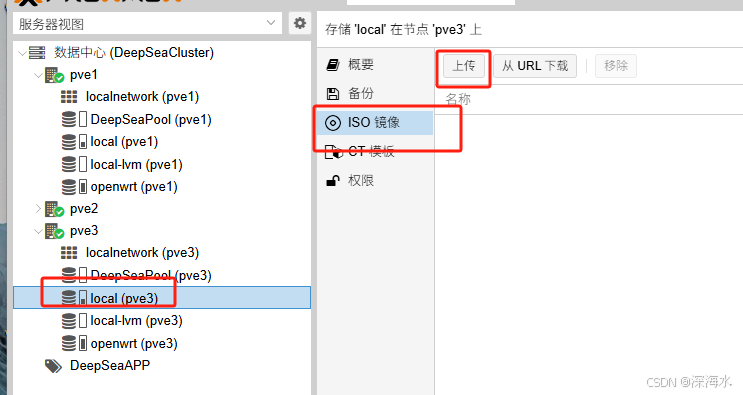
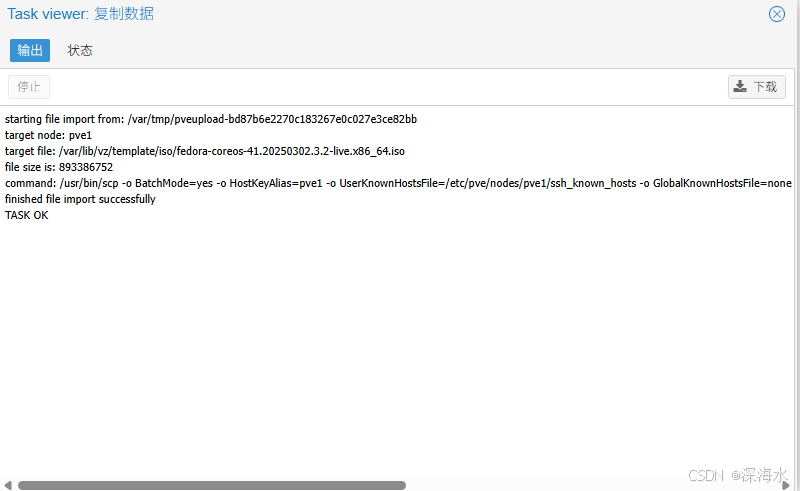
上传镜像
右上解创建虚拟机
下图中的资源池,在集群管理中创建即可
其余按提示即可,在下图开始管理
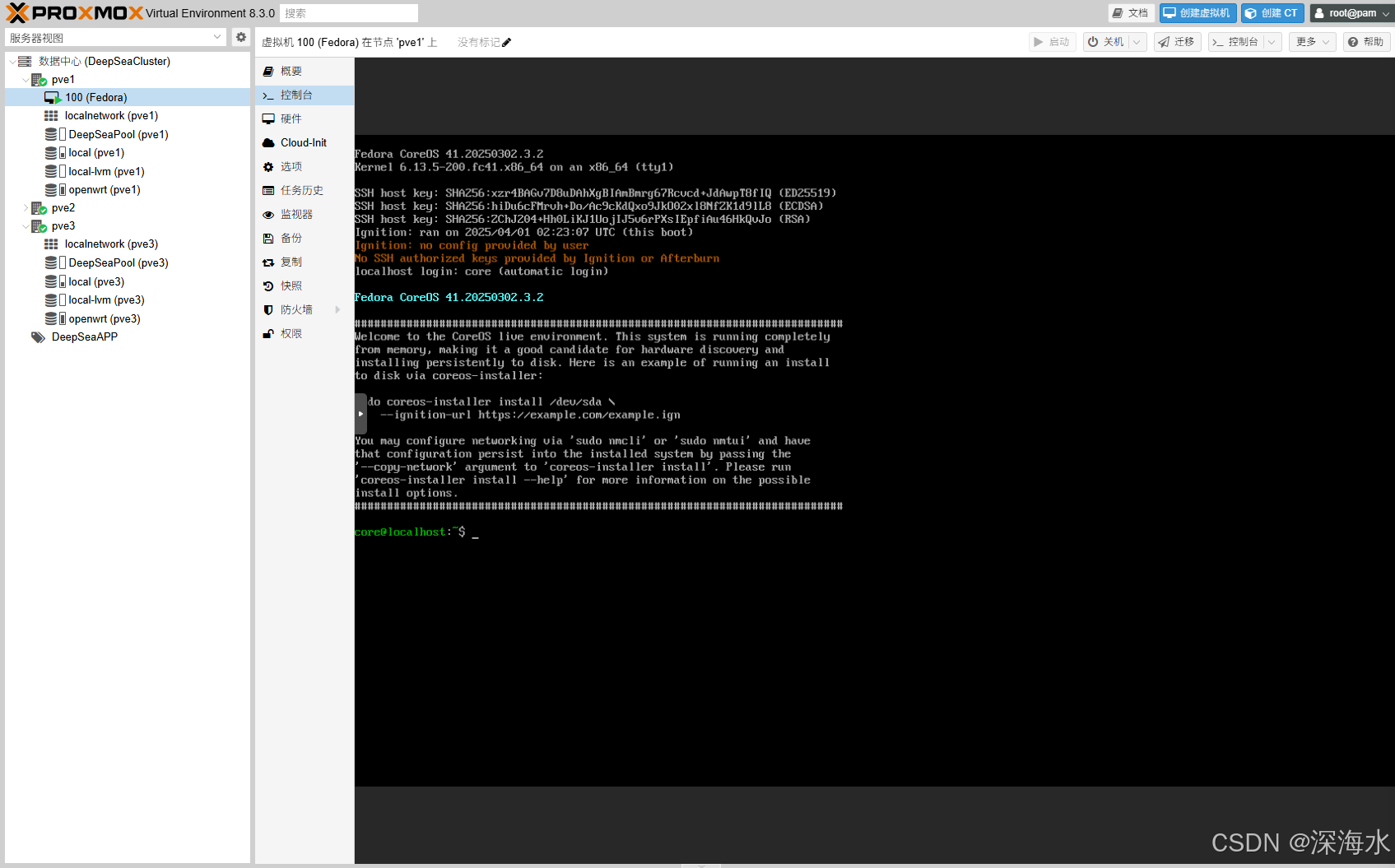
五、配置所有节点都能访问ISO
如果希望所有节点都能访问 ISO,需要 NFS 共享 ISO 目录,或手动同步。
我们通过SMB加载ISO文件,将ISO镜像添加到下图的SMB存储内容中就可以在安装操作系统时选择共享存储中的ISO镜像文件了

下面就可以上传ISO镜像到SMB共享存储中了。建议使用NFS。
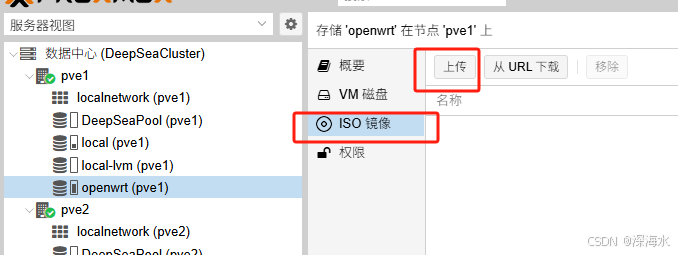
如果无法上传ISO镜像,可能是local空间满了(不要往local上传文件,该目录可用空间大小影响上传ISO文件的大小),可以增加空间,或者删除临时文件
rm -rf /var/tmp/*
六、使用HA
即使启用了 HA(高可用) 和 共享存储,在创建虚拟机(VM)时,仍然需要指定一个初始运行的 节点主机。但 HA 会自动处理故障转移,具体行为取决于 HA 配置。
为什么需要选择节点?
1.虚拟机总是需要一个初始运行的节点
在 Proxmox VE 中,每台物理服务器(节点)运行
pve-cluster服务,虚拟机必须在某个节点上启动。共享存储(如 Ceph、NFS、iSCSI、SMB)让 VM 的磁盘数据可在多个节点间访问,但不会自动选择在哪个节点创建 VM。
2.HA 仅在故障时才会迁移 VM
你选择的初始节点 正常运行时,VM 会一直运行在该节点。
只有当 选定节点故障,HA 机制才会自动迁移 VM 到其他可用节点。
如何让 Proxmox 选择最优节点?
如果你不想手动选择节点,可以使用 HA 组(HA Groups),方法如下:
1. 创建 HA 组
在 Proxmox Web UI:
进入 Datacenter → HA → Groups
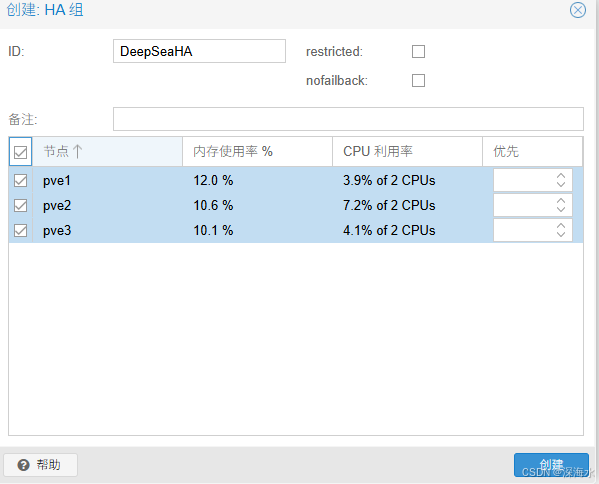
创建一个 HA 组,勾选 restricted(限制 VM 只能运行在此组内的节点)
添加多个节点,并设定优先级
| 选项 | 作用 | 是否推荐使用? | 适用场景 |
|---|---|---|---|
| restricted | 限制 HA 资源只能在指定节点上运行 | 建议在特定情况下使用 | 有 PCI 直通、CPU 架构不同、需要绑定特定节点 |
| nofailback | 防止 HA 资源在故障节点恢复后自动回迁 | 推荐使用 | 避免 VM 频繁迁移、提升稳定性 |
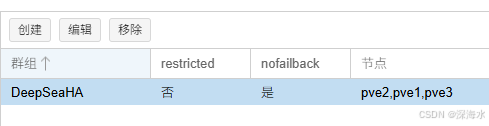
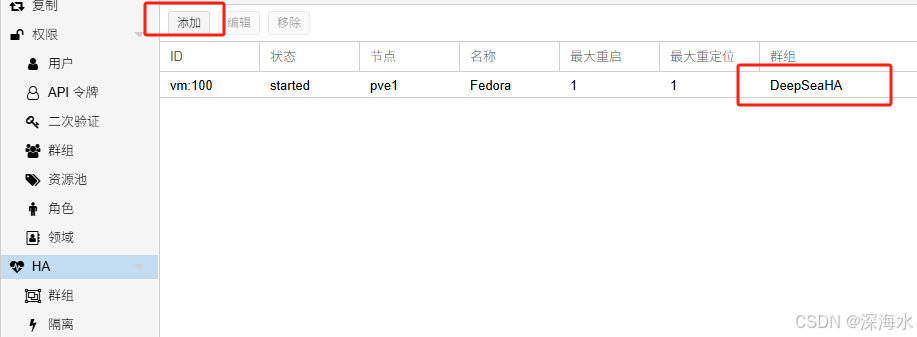
2. 创建 VM 并加入 HA
创建 VM 时,仍然需要手动选择一个初始节点。
然后进入 Datacenter → HA → Resources,添加该 VM 并指定它的 HA 组。
这样,如果 VM 运行的节点故障,Proxmox 会根据 HA 组规则自动选择一个 健康的节点 启动 VM。
七、出现手动关半节点如何自动迁移虚拟机
ha-manager set vm:<VMID> --migration=relocate 这个命令需要 针对每个 HA 受管的虚拟机 单独设置。
如何批量设置所有 HA VM?
如果你有多个 VM,可以用以下方法 批量设置:
方法 1:使用 for 循环(推荐)
你可以用 shell 脚本 一次性修改所有 HA 受管 VM:
for VMID in $(ha-manager status | awk '/vm:/ {print $2}' | cut -d':' -f2); do
ha-manager set vm:$VMID --migration=relocate
done
这个脚本会:
获取所有 HA 受管的 VMID
依次执行
ha-manager set vm:<VMID> --migration=relocate
这样就不需要手动一台台输入 VMID 了。
方法 2:手动对每个 VM 设置
如果你的 VM 数量不多,也可以手动执行:
ha-manager set vm:100 --migration=relocate
ha-manager set vm:101 --migration=relocate
ha-manager set vm:102 --migration=relocate
如何检查是否生效?
执行:
ha-manager status
看看每个 VM 的 migration 选项是否变成 relocate。
其他 HA 迁移策略
如果你想了解更多 HA 迁移策略:
ha-manager set vm:<VMID> --migration=<策略>
其中:
relocate:(推荐) 允许 VM 自动迁移 到其他节点stop:在故障时 直接关闭 VM(不迁移)freeze:保持 VM 状态不变,不迁移、不重启
一般来说,relocate 是最好的选择,除非有特殊需求。
总结
| 方法 | 适用场景 | 命令 |
|---|---|---|
| 单个 VM 手动设置 | 适用于 VM 数量少 | ha-manager set vm:<VMID> --migration=relocate |
| 批量设置所有 HA VM | 适用于 VM 数量多 | for 循环批量执行 |
| 检查是否生效 | 确认迁移策略是否更新 | ha-manager status |
批量修改所有 HA 受管 VM,这样以后关机节点时,VM 就会自动迁移到其他节点,不会直接关机。
八、PVE使用Ceph RBD作为VM存储性能优化
1、启用 RBD 缓存
在 PVE 服务器上:
ceph config set client rbd_cache true
ceph config set client rbd_cache_size 33554432 # 32MB
2、关闭 Ceph Debug 日志
ceph config set mon debug_mon 0
ceph config set osd debug_osd 0
3、调整 Ceph I/O 队列
ceph config set osd osd_op_num_threads_per_shard 4
ceph config set osd osd_op_num_shards 8
4、结论
✅ Ceph RBD 是 PVE 存储 VM 的最佳方案(高性能、高可用)。
✅ 通过 PVE Web 界面可以轻松添加 Ceph 存储。
✅ 优化 RBD 缓存、OSD I/O,可提高 Ceph 运行效率。
九、PVE+Ceph 性能优化:节点级别 & 全局级别
1、全局级别优化(所有 Ceph 节点同步)
这些配置 全局生效,只需在 一个 MON(监视器)节点 上执行,Ceph 会自动同步到所有节点。
✅ 1. 启用 RBD 缓存
ceph config set client rbd_cache true
ceph config set client rbd_cache_size 33554432 # 32MB 缓存
ceph config set client rbd_cache_max_dirty 25165824 # 25MB 写入缓存
ceph config set client rbd_cache_target_dirty 16777216 # 16MB 触发写入
ceph config set client rbd_cache_max_dirty_age 5 # 5秒后写入
✅ 作用:提高 RBD(VM 磁盘)的读写性能,减少 IO 延迟。
✅ 2. 关闭 Ceph Debug 日志
ceph config set mon debug_mon 0
ceph config set osd debug_osd 0
ceph config set mgr debug_mgr 0
ceph config set mds debug_mds 0
ceph config set client debug_client 0
✅ 作用:减少日志占用的 CPU 和 IO,提高性能。
✅ 3. 调整 Ceph I/O 线程
ceph config set osd osd_op_num_threads_per_shard 4
ceph config set osd osd_op_num_shards 8
✅ 作用:提高 OSD 处理请求的能力,减少 IO 阻塞。
✅ 4. 调整 CRUSH 规则,优化数据分布
ceph balancer mode upmap
ceph balancer on
✅ 作用:确保 Ceph 自动均衡数据分布,防止某些 OSD 过载。
2、节点级别优化(每个 PVE+Ceph 节点都要执行)
这些优化需要 在每个 OSD 节点(运行 ceph-osd 的服务器)手动执行。
✅ 1. 调整 BlueStore 缓存
在每个 OSD 节点上执行:
echo "bdev_sync_submit = false" >> /etc/ceph/ceph.conf
echo "bluestore_cache_size = 4294967296" >> /etc/ceph/ceph.conf # 4GB 缓存
echo "bluestore_cache_kv_max = 1073741824" >> /etc/ceph/ceph.conf # 1GB 作为 key-value 处理
echo "bluestore_cache_meta_max = 1073741824" >> /etc/ceph/ceph.conf # 1GB 用于元数据缓存
然后重启 OSD:
systemctl restart ceph-osd.target
✅ 2. 调整 Linux 内核参数
在每个 OSD 节点执行:
echo "vm.dirty_ratio = 10" >> /etc/sysctl.conf
echo "vm.dirty_background_ratio = 5" >> /etc/sysctl.conf
echo "vm.swappiness = 10" >> /etc/sysctl.conf
sysctl -p
✅ 作用:减少 Linux 对磁盘的写入压力,提高 Ceph 响应速度。
✅ 3. 启用 NOOP I/O 调度器(适用于 SSD)
如果 OSD 运行在 SSD/NVMe 上,优化磁盘调度:
echo "noop" > /sys/block/sdX/queue/scheduler
或者永久生效:
echo 'GRUB_CMDLINE_LINUX_DEFAULT="elevator=noop"' >> /etc/default/grub
update-grub && reboot
✅ 作用:减少 SSD/NVMe 的调度开销,提高 IO 吞吐量。
3、计算节点优化(所有 PVE 计算节点执行)
即使某些节点没有 Ceph OSD,它们作为 Ceph Client(RBD 挂载 VM) 也可以优化性能。
✅ 1. 在 PVE 计算节点启用 KRBD
在 storage.cfg 中找到 Ceph RBD 配置,添加:
krbd 1
然后在 PVE 计算节点上运行:
systemctl restart pve-cluster pvedaemon
✅ 作用:让 VM 直接使用 Linux 内核的 RBD 驱动,提高磁盘性能。
✅ 2. 提高 QEMU-KVM 性能
编辑 /etc/modprobe.d/kvm.conf:
options kvm ignore_msrs=1
options kvm-intel nested=1
然后运行:
update-initramfs -u && reboot
✅ 作用:优化 KVM 虚拟化,提高 VM 运行效率。
4、结论
✅ 全局优化(MON 节点执行一次):Ceph RBD 缓存、I/O 线程、日志优化、CRUSH 规则。
✅ OSD 优化(每个 OSD 服务器执行):BlueStore 缓存优化、Linux 内核优化、SSD 调度优化。
✅ PVE 计算节点优化(所有 PVE 服务器执行):启用 KRBD,提高 KVM 性能。
如果你希望进一步测试优化效果,可以:
fio --filename=/dev/rbd0 --direct=1 --rw=randrw --bs=4k --numjobs=4 --iodepth=32 --runtime=30 --time_based --group_reporting --name=test-rbd
这会测试 Ceph RBD 的 4K 随机读写性能,看看优化是否有效!