前言
在 LLM(大语言模型)驱动的智能体架构中,知识库(Knowledge Base)、数据库(Database)和大模型(LLM)是关键组成部分,它们共同决定了智能体的理解能力、决策能力和执行能力。本篇博客将详细解析这三个部分的作用、实现方式以及优化策略。
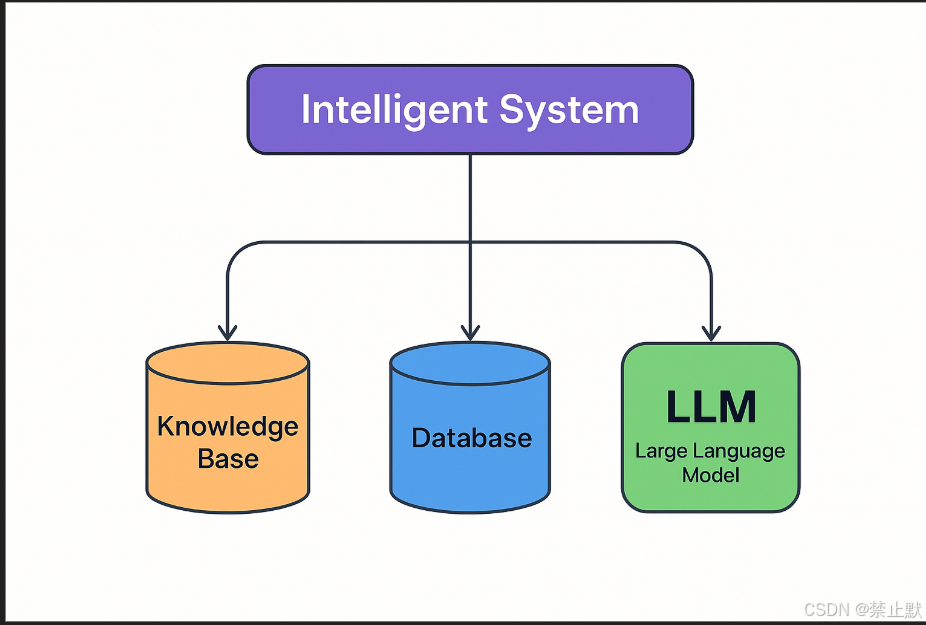
1. 智能体中的知识库(Knowledge Base)
1.1 知识库的作用
知识库用于存储和检索智能体在回答问题或执行任务时所需的信息,主要功能包括:
存储领域知识:如法律、医学、金融等专业知识。
存储长期记忆:用于记住用户的偏好、历史对话等。
增强LLM能力:提供额外的上下文,提高智能体的回答准确性。
1.2 知识库的类型
结构化知识库
使用 数据库(SQL / NoSQL) 存储数据,如 MySQL、MongoDB。
适用于 规则明确、关系强 的知识,如企业客户数据、财务报表。
非结构化知识库
使用 文档(Docs, PDFs, 网页) 存储知识。
适用于 开放领域、非标准格式 的知识,如新闻文章、维基百科等。
向量数据库(Vector Database)
使用 嵌入(Embeddings) 存储和检索文本信息,代表工具如 FAISS、Pinecone。
适用于 语义搜索,即使关键词不同,也能找到相关信息。
1.3 知识库的实现
1.3.1 使用向量数据库(FAISS)存储知识
from sentence_transformers import SentenceTransformer
import faiss
import numpy as np
# 1. 初始化嵌入模型
model = SentenceTransformer('all-MiniLM-L6-v2')
# 2. 生成向量并存入FAISS
documents = ["人工智能是一门研究如何使计算机具有智能的学科。",
"机器学习是一种让计算机通过数据自动学习的技术。"]
vectors = model.encode(documents)
# 3. 创建FAISS索引
index = faiss.IndexFlatL2(vectors.shape[1])
index.add(np.array(vectors))
# 4. 查询相似文档
query = "机器学习的定义是什么?"
query_vector = model.encode([query])
_, result_indices = index.search(np.array(query_vector), 1)
print("最相关的文档:", documents[result_indices[0][0]])
在这个例子中,我们使用 FAISS 存储和检索语义相似的知识,提高 LLM 的准确性。
2. 智能体中的数据库(Database)
2.1 数据库的作用
智能体的数据库用于存储结构化数据,并提供快速查询能力:
用户数据:存储用户信息、偏好、历史记录。
知识存储:用于存储领域特定的信息,如法律法规、产品数据等。
日志记录:存储智能体的对话历史、执行日志等。
2.2 数据库的类型
| 类型 | 特点 | 适用场景 |
|---|---|---|
| 关系型数据库(SQL) | 结构化存储、表格格式、支持复杂查询 | 客户信息、订单数据 |
| 非关系型数据库(NoSQL) | 适用于存储大量非结构化数据 | 文本、日志、缓存 |
| 向量数据库 | 存储文本、图像的语义嵌入 | 语义检索、知识问答 |
2.3 数据库的实现
2.3.1 使用 MongoDB 存储智能体对话数据
from pymongo import MongoClient
# 连接 MongoDB
client = MongoClient("mongodb://localhost:27017/")
db = client["chatbot"]
collection = db["conversations"]
# 存储对话
chat_data = {
"user_id": 123,
"timestamp": "2025-04-01 12:00:00",
"user_input": "你好",
"bot_response": "你好!有什么可以帮助你的吗?"
}
collection.insert_one(chat_data)
# 查询对话历史
for chat in collection.find({"user_id": 123}):
print(chat)
使用 MongoDB 可以高效存储智能体的对话记录,便于个性化优化。
3. LLM(大语言模型)在智能体中的作用
3.1 LLM 的核心能力
自然语言理解(NLU):识别用户意图、分析文本含义。
上下文推理(CoT, Chain-of-Thought):进行多步推理,提高回答准确性。
文本生成:自动生成连贯、自然的文本。
3.2 LLM 的优化策略
提示工程(Prompt Engineering)
通过优化输入提示,提高 LLM 生成的文本质量。
示例:
你是一个金融专家,请根据以下市场数据分析当前投资趋势:
微调(Fine-tuning)
通过训练特定领域的数据,优化 LLM 在某个领域的表现。
例如:使用医学数据微调 GPT 以提高医疗问答的准确性。
RAG(检索增强生成)
结合知识库,避免 LLM 生成错误信息。
示例:
用户提问 "最新的租房法律是什么?"
智能体查询数据库,获取最新法规
结合法规内容,使用 LLM 生成回答
3.3 LLM 与数据库、知识库的结合
LLM 并不能存储长期数据,因此需要结合数据库与知识库:
数据库 存储结构化信息,如用户偏好、历史数据。
知识库 存储非结构化文本,如行业文档、维基百科条目。
LLM 负责理解和处理用户输入,结合知识库和数据库生成答案。
示例架构:
用户输入 ——> LLM 解析意图 ——> 查询数据库/知识库 ——> 结合数据生成回答 ——> 返回给用户
4. 总结
知识库 主要用于存储和检索领域知识,提升 LLM 回答的精准度。
数据库 主要用于存储用户数据、日志等结构化信息。
LLM 作为智能体的核心,负责理解用户输入并结合知识库、数据库生成合理的回答。
智能体的最佳实践
采用向量数据库(FAISS/Pinecone) 存储语义信息,提高知识检索能力。
结合关系型数据库(MySQL)与 NoSQL(MongoDB) 统一管理结构化与非结构化数据。
优化 LLM 的提示(Prompt Engineering),提升问答质量。
使用 RAG(检索增强生成) 让 LLM 结合知识库,提高答案的准确性。
5. 未来发展方向
更高效的知识检索方式:探索更快的向量数据库,提高查询速度。
多模态智能体:结合语音、图片、视频等信息,提高智能体的能力。
自治智能体(Autonomous Agent):结合 LLM、数据库、知识库,实现自主决策和任务执行。
未来,LLM、知识库和数据库的深度融合将进一步提升智能体的智能化水平,使其在自动化办公、法律咨询、医学诊断等领域发挥更大作用!🚀