Meta最新发布的Llama 4系列标志着开源大语言模型(LLM)的重大演进,其采用的混合专家(MoE)架构尤为引人注目。
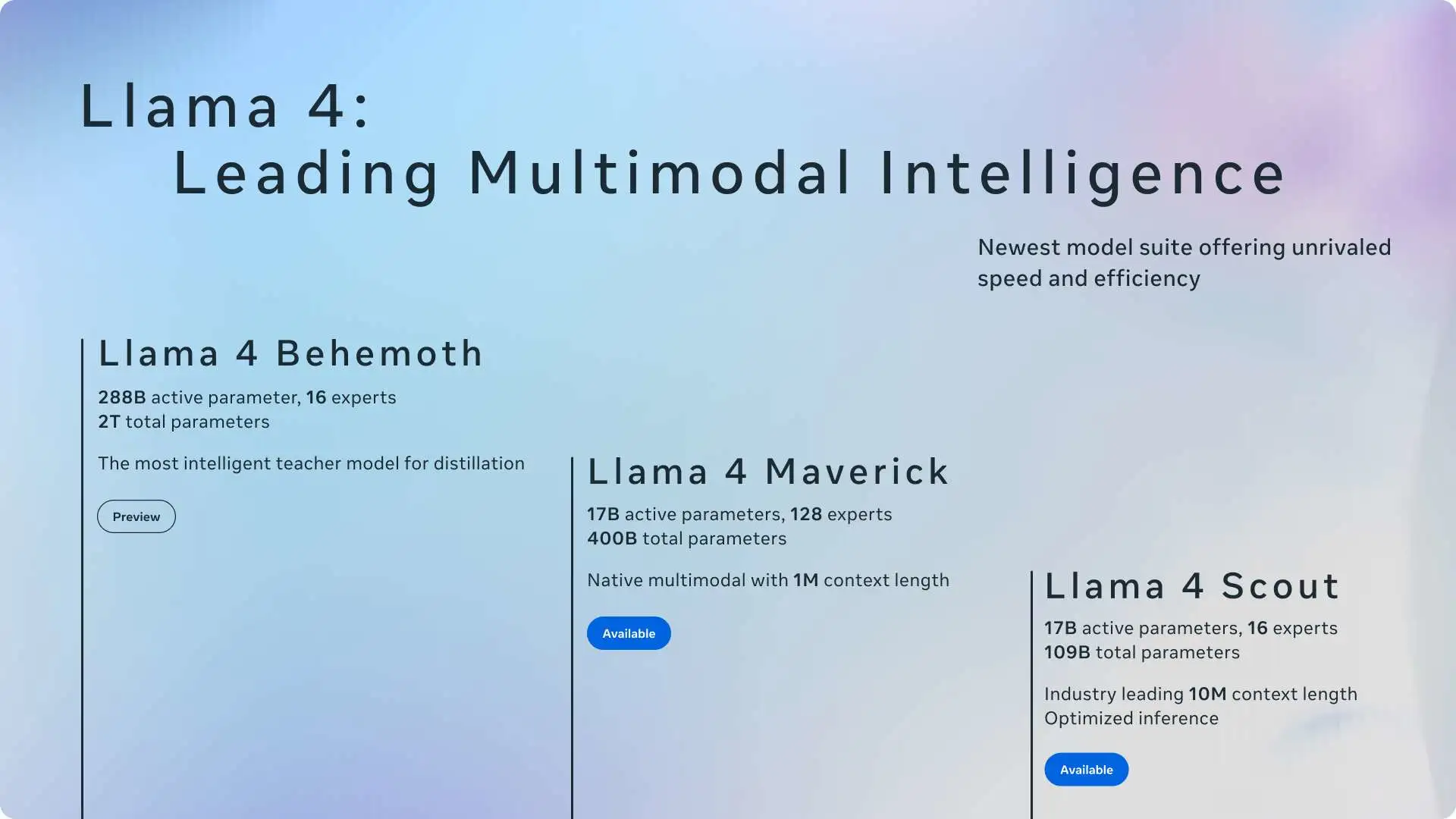
两大核心模型——Llama 4 Scout(170亿参数含16专家)和Llama 4 Maverick(170亿参数含128专家)——展现了Meta向高效能AI模型的战略转型,这些模型在挑战传统扩展范式的同时保持了强大性能。
本文将深入解析这些模型的技术原理、架构创新、训练方法、性能基准测试及安全措施。通过多维度技术剖析,我们可以更清晰地理解Meta如何突破计算效率型大语言模型的能力边界。
理解专家混合架构
在深入探讨Llama 4的具体实现之前,理解MoE架构背后的核心理念至关重要。
为何选择MoE?
• 可扩展性与可控计算成本:模型可提升容量,而不会线性增加推理成本
• 动态路由机制:通过学习的门控机制,将每个token路由至最相关的专家模块
核心概念
专家混合(Mixture-of-Experts,MoE)是一种模型架构设计方法,其核心在于模型由多个"专家"神经网络组成,每个专家专精于处理任务的不同方面。通过路由机制(通常是一个"门控网络")动态决定由哪些专家或专家组合来处理特定输入。
与传统稠密模型(所有参数对每个输入都激活)不同,MoE模型在前向传播时仅选择性激活部分参数。
这种选择性激活机制使MoE模型能够扩展到更大的总参数量,同时在推理和训练阶段保持合理的计算成本。
MoE模型与稠密模型的差异解析
在早期Llama版本等标准稠密Transformer模型中,每个输入词元都需要调用全部参数参与计算。随着模型规模扩大,计算成本和内存需求呈线性增长。
而MoE模型通过以下机制引入稀疏性:
参数专家化分组:用多个专家模块替代Transformer块中的前馈网络层(FFN)
动态路由机制:通过可学习的路由函数决定每个词元分配的专家组合
局部专家激活:每个输入词元仅激活部分专家模块,实际调用的参数量仅占总量的很小比例
这种架构使MoE模型具备双重优势:在激活参数量相同的情况下性能优于稠密模型,在总参数量相同时计算效率更高。
Llama 4的MoE架构实现

体系结构概览
Llama 4推出两种MoE变体:
• **Llama 4 Scout:**170亿激活参数配置,集成16个专家模块
**•****Llama 4 Maverick:**170亿激活参数配置,集成128个专家模块
注:所述"170亿参数"特指推理时激活的参数量,其总参数量将显著更高。这种设计使模型既能调用海量参数空间中的知识,又能保持合理的计算资源需求。
专家分布与路由机制
(基于行业先进模型的典型实现方案)
尽管Meta未公开具体实现细节,当前顶尖MoE模型通常采用以下设计原则:
专家部署策略
• 结构替代:用MoE层部分或全部替换Transformer块中的FFN层
• 动态激活:采用Top-k路由机制(通常k=1或2),每个词元仅激活最相关的k个专家
• 负载均衡:通过算法确保各专家训练量均衡,防止出现某些专家完全未被调用的"专家坍缩"现象
Llama 4的对比实验设计
Scout(16专家)与Maverick(128专家)的核心差异揭示Meta正在探索:
→ 不同稀疏化程度对模型性能的影响
→ 少量通用型专家 vs 大量专用型专家的效益权衡
预训练阶段
Meta 指出,LLaMA 4 模型在数据效率上有所提升,尤其在低资源语言和代码领域表现更优。
训练数据
语料构成:混合公开数据集与授权数据
训练规模:约 15–20 万亿 tokens(Meta 未公布精确数字)
<