Downstream Model:预训练模型的下游应用与微调技术
文章目录
1 什么是Downstream Model(下游模型)
Downstream Model(下游模型)是指在预训练模型基础上,通过微调(Fine-tuning)或迁移学习方法,针对特定任务进行优化的模型。下游任务是指我们真正想要解决的具体应用任务,如文本分类、命名实体识别等。
在自然语言处理领域,下游任务建立在预训练模型之上,利用预训练模型学习到的语言知识来解决特定问题。预训练模型通过大规模语料库学习通用语言表示,而下游任务则利用这些表示来解决具体应用场景的问题。
2 预训练模型与下游任务的关系
预训练-微调(Pre-training and Fine-tuning)是现代NLP的主流方法:
- 预训练阶段:模型在大规模无标注语料上学习通用语言表示
- 微调阶段:针对特定下游任务,使用少量标注数据调整模型参数
2017,一篇大名鼎鼎的论文 Attention Is All You Needed 正式发表,第一次提出了注意力机制(Attention),并且在Attention的基础上创造了一个全新的NLP(自然语言处理)模型Transformer。
关于注意力机制(Attention)的介绍,可以参见我的这一篇文章:【深度学习】Self-Attention机制详解:Transformer的核心引擎 。
(后面有时间写一篇文章介绍Transformer)
预训练模型如BERT (Bidirectional Encoder Representations from Transformers) 、GPT (Generative Pre-trained Transformer) 等基于大规模数据进行训练,为广泛的下游应用提供了合理的参数初始化。这种预训练思想在大型语言模型发展中起到了关键作用。
(后面有时间写一篇文章介绍BERT和GPT的区别)
预训练模型与下游任务的关系可以概括为:预训练模型学习通用语言知识和表示,下游任务利用这些知识解决特定问题,通过微调或其他迁移学习方法连接两者。
例如,一般来说,BERT或者GPT等可以输入一串文本、语音、图像等“序列”,然后输出另一串特征向量。
现在有这样一个任务:Sentiment analysis——给机器一个句子,让它判断这个句子是正面的还是负面的。所以在预训练模型的后面再加一层Linear transform,输出具体的分类标签。这里的Linear transform即为Downstream Model。当然,微调需要与下游任务对应的标注资料,比如这里就需要文本以及对应的“态度”(正面/负面)标签。
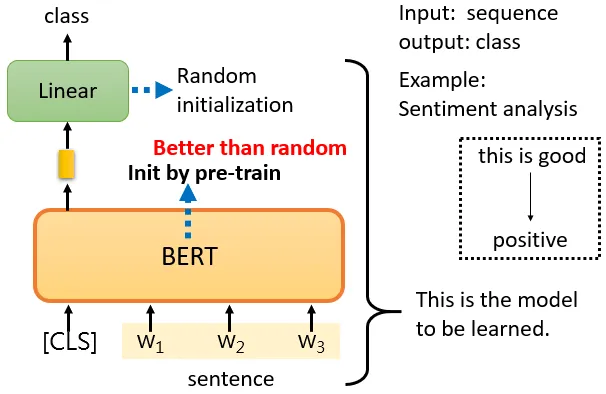
对下游任务,需要标注资料。在预训练模型的基础上接着训练(其实这个时候是在微调了)的时候,Linear transform和预训练模型都是利用Gradient descent来更新参数的。
Linear transform的参数是随机初始化的,而BERT/GPT的参数是由已经学会填空的BERT / 已经学会续写的GPT初始化的,将获得比随机初始化的预训练模型更好的性能。
3 微调技术与迁移学习
微调的必要性
对于数据集较小(几千张图片)的情况,从头开始训练具有几千万参数的大型神经网络是不现实的,因为越大的模型对数据量的要求越大,过拟合难以避免。微调提供了一种有效解决方案。
高效迁移学习
传统微调方法对于N个任务,需要N×预训练模型的参数数量。现代高效迁移学习范式旨在达到与完全微调相同的性能,但大幅减少所需参数数量。
参数高效微调
参数高效的大语言模型微调已成为使用预训练模型适应下游任务的主流方法,这种方法可以在保护隐私的同时提高模型性能。
4 应用案例
BERT模型应用
BERT模型可以通过将其输出用于下游任务,实现各种NLP应用。基于Huggingface的BERT模型构建方法已成为行业标准,包括数据集准备、模型构建和使用方法。
GPT模型应用
GPT基于自回归模型,可以应用在自然语言理解(NLU)和自然语言生成(NLG)两大任务类型中。使用GPT-3等大型预训练模型可以实现各种文本生成应用。
5 未来发展方向
多模态预训练
多模态预训练模型目前主要用于检索和生成任务,但研究者们正在探索更接近现实的应用场景。然而,多模态预训练仍面临无法学习隐性知识等挑战。
分布式学习
使用分布式数据集和联合学习来适应下游任务是一个新兴研究方向,这种方法可以在保护数据隐私的同时提高模型性能,特别适合对敏感数据有严格要求的应用场景。
通过迁移学习,即使在拥有较少数据的情况下,也能获得优异的模型性能。这使得经典预训练模型如ResNet和VGG等在各种下游任务中展现出强大的适应能力。