1. 概述
目标检测(Object Detection)和目标追踪(Object Tracking)是计算机视觉中的两个关键技术,它们在多种实际应用场景中发挥着重要作用。
目标检测指的是在静态图像或视频帧中识别出特定类别的目标对象,并通常以矩形框(bounding box)的形式标出其位置。目标检测算法通常只处理单个图像帧,其任务是检测出该帧中所有感兴趣的对象。
目标追踪则涉及对视频中连续帧里的目标对象进行识别和跟踪。与目标检测不同,目标追踪需要在视频序列中维持对目标的识别,确保同一目标在不同帧中被连续检测和标记,即使目标在场景中移动或变换姿态。目标追踪算法需要处理整个视频序列,确保目标的一致性和唯一性。
本文旨在帮助读者理解“目标检测”和“目标追踪”这两个概念,并指导如何在编程中实现这些技术以及如何对它们进行可视化展示。这些技术在商业领域的应用非常广泛,包括但不限于自动化农业监控、机器人导航、交通流量分析等。
2. 检测和跟踪
目标检测是针对单个视频帧或图像的。对象检测算法的任务是在这张静态图片中识别并定位一个或多个特定的对象。这通常涉及到使用矩形框(bounding boxes)来标出对象的位置,并且可能会包括对象的类别信息。
对象跟踪则是一项更为复杂的任务,它涉及视频序列中的连续帧。对象跟踪算法不仅要识别出视频中的每一帧中的对象,还要能够在连续的帧之间关联同一个对象,确保对同一个对象的跟踪是连续和一致的。这通常需要为每个对象分配一个唯一的标识符(ID),并在整个视频序列中维持这个 ID 的一致性。
在对象跟踪中,可能会用到以下几种技术:
- 卡尔曼滤波器(Kalman Filter):这是一种数学算法,用于从一系列的测量中估计对象的位置和速度,即使在测量中含有噪声或误差时也能做出准确的预测。
- 光流(Optical Flow):这是一种计算图像中物体运动模式的技术,它可以估计图像中每个像素或一组特征点的运动速度,从而帮助跟踪移动的对象。
对象跟踪的算法示例包括 DeepSort、Sort 以及 OpenCV 中的原生跟踪算法等。这些算法利用了不同的策略和技术来有效地在视频帧之间跟踪对象,即使在目标遮挡、快速运动或光照变化等复杂情况下也能有效工作。
3. 光流追踪
光流是一种描述和估计图像中物体运动的计算机视觉技术。当物体或相机在三维空间中移动时,图像序列中的相应物体会出现视觉上的移动。光流利用这种视觉变化来推断物体在连续视频帧或图像序列中的运动。
光流的关键特点包括:
- 二维向量场:光流表示为一个二维向量场,其中每个向量代表一个位移向量。
- 位移向量:每个向量显示了图像中一个点从第一帧到第二帧的位移。这些向量的方向和大小通常用来表示物体的运动方向和速度。
- 稀疏与密集光流:光流可以是稀疏的,即只计算图像中关键特征点的位移;也可以是密集的,即计算图像中每个像素的位移。
- 应用领域:光流在多个领域有广泛应用,包括但不限于:
- 结构从运动(Structure from Motion)
- 视频压缩
- 视频稳定化
- 物体跟踪
- 运动检测
- 机器人导航
- 计算方法:光流可以通过多种算法计算,包括基于梯度的方法、基于频域的方法、以及基于能量最小化的方法。
- 局限性:光流可能受到多种因素的影响,如光照变化、遮挡、快速运动等,这些因素可能导致光流计算的不准确或失败。
4. Yolov8 算法
YOLOv8 是基于 YOLO(You Only Look Once)的模型,由 Ultralytics 开发。通常,这个模型专门用于:
- 检测对象
- 分割
- 分类对象
YOLOv8 系列模型被广泛认为是该领域最好的模型之一,提供卓越的准确性和更快的性能。它的易用性归功于它由五个独立的模型组成,每个模型都满足不同的需求、时间限制和范围。
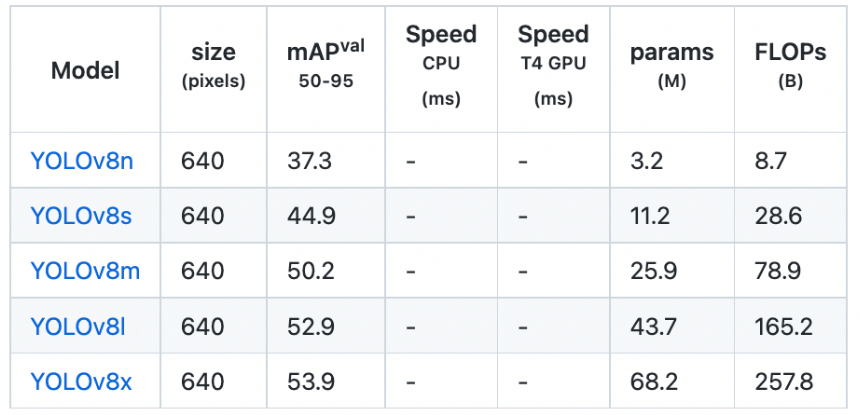
在比较 YOLOv8 不同版本时,可以看到模型在多个方面存在差异:
- 平均精度(mAP):不同版本的 YOLOv8 在平均精度上有所不同,这是一个衡量模型在目标检测任务上性能的指标。
- 参数数量:各模型拥有的参数数量也不同,参数数量越多,模型的复杂度通常越高,这可能会影响模型的推理速度和资源消耗。
- 资源消耗和速度:一些模型可能在运行时更为资源密集,这可能会影响处理速度。例如,X 模型被认为是最先进的,提供了更高的精度,但可能会导致视频或图像渲染速度变慢。而 Nano 模型(N)则是最快的选择,但在准确性上做了一些妥协。
YOLOv8 系列提供了不同版本的模型以适应不同的应用场景和需求。用户可以根据自己的具体需求,如对速度或准确性的偏好,来选择最合适的模型版本。例如,如果应用场景对速度要求极高,可能更适合选择 Nano 模型;而如果对检测精度有较高要求,X 模型可能是更好的选择。
4.1 SORT 算法
SORT 算法由 Alex Bewley 提出,是一种用于视频序列中二维多目标跟踪的跟踪算法。它是其他跟踪算法(如 DeepSort)的基础。由于其极简主义的特点,该算法非常易于使用和实现。您可以通过这里了解更多关于该算法的信息,甚至可以查看源代码。
4.2 数学原理
4.2.1 卷积神经网络(CNN)
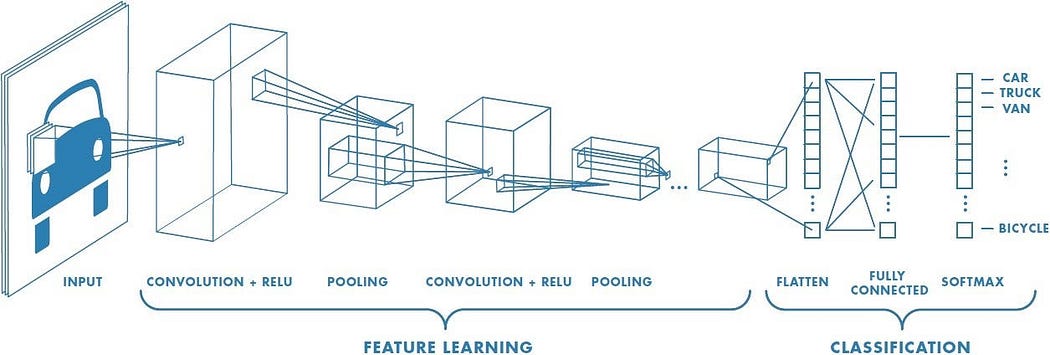
卷积神经网络结构 [来源:点击这里 ]
卷积神经网络(CNN)是基于卷积层和池化层的神经网络。正如在《卷积神经网络全面指南——简单易懂的方式》中所述,“卷积操作的目标是从输入图像中提取高级特征,例如边缘”。简单来说,卷积层负责从初始输入中提取最重要的特征。而池化层则负责简化内容,即“负责减少卷积特征的空间尺寸”。通过这种过程,机器能够理解初始输入的特征。因此,我们得到了一个复杂的特征学习过程,其中卷积层和池化层相互堆叠[4]。
4.2.1 光流数学原理
连续两帧之间的像素运动被称为光流。无论是相机在运动还是场景在运动,都取决于运动的主体。
光流的基本目标是计算由于相机运动或物体运动而导致的物体的位移向量。为了计算所有图像像素或稀疏特征集合的运动向量,我们的主要目标是确定它们的位移。
如果我们用一张图片来说明光流问题,它看起来会像这样:
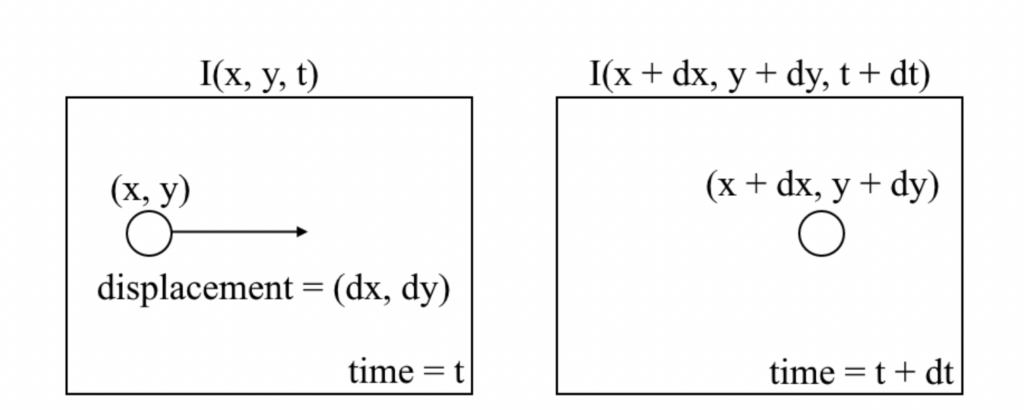
光流通过定义一个密集的向量场来发挥作用,它是计算机视觉和机器学习应用中的关键组成部分,包括目标跟踪、目标识别、运动检测和机器人导航等。在这个场中,每个像素都被赋予了一个位移向量,这有助于确定输入视频序列中每个移动目标像素的方向和速度[5]。
5. 实践操作
5.1 使用 YOLOv8 和 SORT 进行目标跟踪
首先,需要了解如何使用 YOLOv8 模型。
pip install ultralytics
# 如果在 Jupyter Notebook 中,请使用 !pip install ultralytics
然后:
from ultralytics import YOLO
# 假设你已经安装了 opencv
import cv2
MODEL = "yolov8x.pt" # 创建你选择的模型实例
model = YOLO(MODEL)
results = model("people.jpg",show=True)
# "0" 将会一直显示窗口,直到有按键按下(适用于视频)
# waitKey(1) 将会显示一帧图像 1 毫秒
cv2.waitKey(0)

这是从 YOLOv8x 版本获得的结果。
现在,已经了解了基础内容,接下来将进入真正的目标检测和跟踪。
import cv2
from ultralytics import YOLO
import math
# 使用 cvzone,它比 cv2 更美观且易于使用
import cvzone
# 从 SORT 导入所有函数
from sort import *
# cap = cv2.VideoCapture(0) #用于网络摄像头
# cap.set(3,1280)
# cap.set(4,720)
cap = cv2.VideoCapture("data/los_angeles.mp4")
model = YOLO("yolos/yolov8n.pt")
cap 变量是我们使用的视频实例,model 是 YOLOv8 模型的实例。
classes = {0: 'person',
1: 'bicycle',
2: 'car',
...
78: 'hair drier',
79: 'toothbrush'}
result_array = [classes[i] for i in range(len(classes))]
最初,从 YOLOv8 API 获取的类别是以浮点数或类别 ID 的形式。当然,每个数字都对应一个类别名称。创建一个字典会更简单,如果需要的话,还可以将其转换为数组(我懒得手动做了)。
# 线条坐标(稍后解释)
l = [593,500,958,500]
while True:
# 按帧读取视频内容
_, frame = cap.read()
# 每一帧都通过 YOLO 模型
results = model(frame,stream=True)
for r in results:
# 创建边界框
boxes = r.boxes
for box in boxes:
# 提取坐标
x1, y1, x2, y2 = box.xyxy[0]
x1, y1, x2, y2 = int(x1),int(y1),int(x2),int(y2)
# 创建实例的宽度和高度
w,h = x2-x1,y2-y1
cvzone.cornerRect(frame,(x1,y1,w,h),l=5, rt = 2, colorC=(255,215,0), colorR=(255,99,71))
# 每个边界框的置信度或准确度
conf = math.ceil((box.conf[0]*100))/100 # 类别 ID(数字)
cls = int(box.cls[0])
这是检测每个对象的部分。现在是时候跟踪并统计道路上的每一辆车了:
while True:
_, frame = cap.read()
results = model(frame,stream=True)
detections = np.empty((0,5)) #创建一个空数组 for r in results:
boxes = r.boxes
for box in boxes:
''' 其余代码 '''
ins = np.array([x1,y1,x2,y2,conf]) #每个对象都应该这样记录
detections = np.vstack((detections,ins)) # 然后将它们堆叠在一起形成一个公共数组
tracks = tracker.update(detections) #将我们的检测结果发送到跟踪函数
cv2.line(frame, (l[0],l[1]),(l[2],l[3]),color=(255,0,0),thickness=3) #作为阈值的线条
现在,将创建一个数组来存储我们所有的检测结果。接下来,将这个数组发送到跟踪函数中,在那里可以提取唯一的 ID 和边界框坐标(这些坐标与之前的相同)。重要的是 cv2.line 实例:正在使用特定的坐标生成一条线。如果某些 ID 的车辆穿过这条线,总计数将增加。本质上,正在建立一个根据车辆 ID 运行的车辆计数器。
for result in tracks:
x1,y1,x2,y2,id = result
x1,y1,x2,y2 = int(x1),int(y1),int(x2),int(y2)
#.putTextRect 是为了在边界框上方放置一个矩形
cvzone.putTextRect(frame,f'{result_array[cls]} {conf} id:{int(id)} ',(max(0,x1),max(35,y1-20)),scale=1, thickness=1, offset=3, colorR=(255,99,71))
#边界框中心的坐标
cx,cy = x1+w//2, y1+h//2 if l[0]<cx<l[2] and l[1]-10<cy<l[3]+10:
if totalCount.count(id) == 0:
#统计每一个新穿过线的车辆
totalCount.append(id)
#当一个对象穿过线时,线条会改变颜色
cv2.line(frame, (l[0],l[1]),(l[2],l[3]),color=(127,255,212),thickness=5)
#显示计数车辆数量的矩形
cvzone.putTextRect(frame,f' Total Count: {len(totalCount)} ',(70,70),scale=2, thickness=1, offset=3, colorR=(255,99,71))
m.write(frame)
cv2.imshow("Image",frame)
cv2.waitKey(1)
现在,最有趣的部分来了:cx 和 cy 是边界框中心的坐标。通过使用这些值,可以判断车辆是否穿过了指定的线条(查看代码)。如果车辆确实穿过了线条,我们的下一步是验证分配给这辆车的 ID 是否唯一,也就是说,这辆车之前没有穿过线条。
5.1 结果
车辆跟踪和计数
如图所示,我在这里显示了边界框,以及对应的目标类别、置信度和唯一 ID。左上角显示了总目标数量。
5.2 使用光流进行目标跟踪
SORT 算法通过分配 ID 并将当前帧与上一帧建立联系来进行跟踪,而光流过程则更侧重于运动估计。换句话说,它估计哪些物体在移动,并估计物体的运动方向或向量。
光流有两种类型:
- 稀疏光流(Sparse Optical Flow)
- 密集光流(Dense Optical Flow)
虽然密集光流会计算每一帧中每个像素的光流(从而创建一个仅包含移动物体的图像),但稀疏光流则计算物体的主要特征点的流向量。
现在我们来看看代码:
flow = cv2.calcOpticalFlowFarneback(prevgray, gray, None, 0.5, 3, 15, 3, 5, 1.2, 0)
首先,我们需要计算光流。我们可以通过 OpenCV 库来实现,它已经包含了这个算法。当然,不要忘记将这个函数放在一个while循环中,以便算法能够持续计算光流(读取视频和处理视频的过程与使用 YOLOv8 和 SORT 进行目标跟踪小节中的内容相同)。
def draw_flow(img, flow, step=16):
# 获取图像的高和宽
h, w = img.shape[:2]
# 在图像上以网格模式创建点
y, x = np.mgrid[step/2:h:step, step/2:w:step].reshape(2,-1).astype(int)
# 获取网格点处的光流方向
fx, fy = flow[y,x].T
# 创建线条以显示光流方向
lines = np.vstack([x, y, x-fx, y-fy]).T.reshape(-1, 2, 2)
lines = np.int32(lines + 0.5)
# 将灰度图像转换为彩色
img_bgr = cv2.cvtColor(img, cv2.COLOR_GRAY2BGR)
# 绘制线条以表示光流方向
cv2.polylines(img_bgr, lines, 0, (0, 255, 0))
# 在线条的起始点绘制小圆圈 for (x1, y1), (_x2, _y2) in lines:
cv2.circle(img_bgr, (x1, y1), 1, (0, 255, 0), -1)
return img_bgr
这是负责稀疏光流的def函数。我们只需要从图像中提取点,将其转换为流向量,然后简单地进行可视化。
def draw_hsv(flow):
# 获取流向量矩阵的高和宽
h, w = flow.shape[:2]
# 将流向量矩阵分解为其 x 和 y 分量
fx, fy = flow[:,:,0], flow[:,:,1]
# 计算流向量的角度并转换为度
ang = np.arctan2(fy, fx) + np.pi
# 计算流向量的大小
v = np.sqrt(fx*fx + fy*fy)
# 创建一个空的 HSV 图像
hsv = np.zeros((h, w, 3), np.uint8)
# 根据流向量的角度设置 HSV 图像的色调通道
hsv[...,0] = ang * (180 / np.pi / 2)
# 将 HSV 图像的饱和度通道设置为最大值
hsv[...,1] = 255
# 根据流向量的大小设置 HSV 图像的亮度通道
hsv[...,2] = np.minimum(v * 4, 255)
# 将 HSV 图像转换为 BGR 色彩空间
bgr = cv2.cvtColor(hsv, cv2.COLOR_HSV2BGR)
# 返回最终的 BGR 图像,其中包含光流可视化结果 return bgr
这是负责密集光流的def函数。在这里,该函数将流向量转换为色调值,因此最终结果将仅显示移动的像素[7]。