本文介绍如何用纯PyTorch从零搭建一个扩散模型(DDPM, Denoising Diffusion Probabilistic Model),用于生成MNIST手写数字。我们使用一个简化的U-Net作为核心噪声预测网络,并手动实现加噪和去噪过程。本文适合想深入理解扩散模型原理和实现机制的朋友。
背景知识简述:什么是DDPM?
扩散模型是一种生成模型,它通过逐步向数据中添加高斯噪声,将真实图像“扩散”成纯噪声,然后再训练一个神经网络学会“逆扩散”过程,从噪声中逐步还原出真实图像。
这个过程分为两个阶段:
正向扩散(Forward Process):逐步给图像加噪,最终变成纯噪声。
反向生成(Reverse Process):训练网络预测噪声,然后从纯噪声中逐步还原图像。
1. DDPM (Denoising Diffusion Probabilistic Models) 原理介绍
DDPM(去噪扩散概率模型) 是一种生成模型,它通过逐步向数据添加噪声,直到数据完全变成噪声,再通过一个神经网络模型反向推理出原始数据。这种方法的特点是可以非常有效地进行生成,并且在图像生成领域取得了显著的成功。
1.1 扩散过程与去噪过程
扩散过程(Forward Diffusion Process):
扩散过程是一个逐步向数据添加噪声的过程。在每一步,图像会与一定量的噪声进行混合,最终使图像变成纯噪声。这个过程是固定的,不需要训练,通常是基于一个预设的噪声调度(即每个时间步噪声的强度)来完成的。数学表示:
假设我们有一个图像 x_0(初始图像),扩散过程的目标是生成一个噪声图像 x_t,随着时间步的增加(即 t 从 0 到 T),数据逐渐被加上噪声,直到最终变为纯噪声。扩散过程定义为:
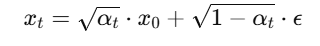
其中,α_t 是控制噪声比例的参数,ϵ 是标准正态分布的噪声,x_t 是在时间步 t 时的图像。
去噪过程(Reverse Diffusion Process):
去噪过程是一个逐步去除噪声的过程。与扩散过程相反,去噪过程的目的是从纯噪声中逐步恢复到真实图像。这个过程通过训练一个神经网络模型来预测每个时间步的噪声,并根据这个预测逐步去除噪声,最终生成清晰的图像。在反向过程中,模型通过学习从 x_t 预测出噪声 ϵ,并通过以下公式逐步更新图像:
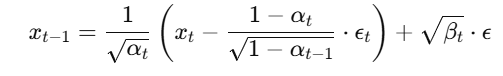
其中,β_t 是每个时间步的噪声增加量,ϵ_t 是模型预测的噪声。
1.2 噪声的预测
DDPM的关键在于训练一个神经网络去预测每个时间步的噪声(或称为“残差”)。这个神经网络通常是一个卷积神经网络(如U-Net)。模型输入的是加噪的图像 xtx_txt 和时间步 ttt,输出的是该时间步的噪声预测 ϵt\epsilon_tϵt,然后使用该预测来去除噪声。
1.3 DDPM的训练与生成
DDPM的训练目标是最小化模型输出的噪声预测与真实噪声之间的均方误差(MSE)。通过训练,模型能够学习到如何从每个加噪图像中恢复出真实的噪声,从而使得它能够在生成过程中有效地去除噪声。
2. 基于PyTorch实现DDPM
现在我们将结合代码来详细解析实现过程。以下是基于PyTorch实现DDPM的步骤。
2.1 MNIST数据集加载
在代码中,我们通过自定义 Dataset 类来加载MNIST数据集。MNIST数据集的图像是28x28的灰度图,通过二进制格式存储为IDX文件。我们通过 struct 和 numpy 来解析文件内容并将图像转为PyTorch tensor。
class MNIST_IDX(Dataset):
def __init__(self, image_file, label_file, transform=None):
self.transform = transform
with open(label_file, 'rb') as f:
magic, num = struct.unpack(">II", f.read(8))
self.labels = np.frombuffer(f.read(), dtype=np.uint8)
with open(image_file, 'rb') as f:
magic, num, rows, cols = struct.unpack(">IIII", f.read(16))
images = np.frombuffer(f.read(), dtype=np.uint8).reshape(num, 28, 28)
self.images = images
def __len__(self):
return len(self.labels)
def __getitem__(self, idx):
img = self.images[idx]
img = torch.from_numpy(img).float().unsqueeze(0) / 255.0 # [1, 28, 28]
if self.transform:
img = self.transform(img)
return img
2.2 简化版U-Net模型
我们使用一个简化版的U-Net模型来实现去噪过程。U-Net结构包括了下采样、瓶颈部分和上采样部分。每个步骤都包含了卷积层,激活函数和跳跃连接(skip connection),使得网络能够保留空间信息。
class SimpleUNet(nn.Module):
def __init__(self, in_channels=1, base_channels=64):
super().__init__()
self.down1 = nn.Sequential(
nn.Conv2d(in_channels + 1, base_channels, 3, 1, 1),
nn.ReLU(),
nn.Conv2d(base_channels, base_channels, 3, 1, 1),
nn.ReLU()
)
self.down2 = nn.Sequential(
nn.Conv2d(base_channels, base_channels*2, 3, 2, 1),
nn.ReLU()
)
self.middle = nn.Sequential(
nn.Conv2d(base_channels*2, base_channels*2, 3, 1, 1),
nn.ReLU()
)
self.up2 = nn.Sequential(
nn.ConvTranspose2d(base_channels*2, base_channels, 4, 2, 1),
nn.ReLU()
)
self.out = nn.Sequential(
nn.Conv2d(base_channels, in_channels, 3, 1, 1)
)
def forward(self, x, t):
t_embed = t[:, None, None, None].float() / 1000
t_embed = t_embed.expand(-1, 1, x.shape[2], x.shape[3])
x = torch.cat([x, t_embed], dim=1)
x1 = self.down1(x)
x2 = self.down2(x1)
x3 = self.middle(x2)
x4 = self.up2(x3)
out = self.out(x4 + x1)
return out
2.3 扩散过程与去噪
接下来,我们实现扩散过程和去噪过程。扩散过程将噪声逐步添加到图像中,而去噪过程则通过模型逐步去除噪声。
前向扩散函数:
def forward_diffusion_sample(x_0, t, noise=None): if noise is None: noise = torch.randn_like(x_0) sqrt_alpha_hat = alpha_hat[t][:, None, None, None].sqrt().to(x_0.device) sqrt_one_minus = (1 - alpha_hat[t])[:, None, None, None].sqrt().to(x_0.device) return sqrt_alpha_hat * x_0 + sqrt_one_minus * noise, noise采样(去噪)函数:
@torch.no_grad() def sample_ddpm(model, image_size=28, n_samples=64, device='cpu'): model.eval() x = torch.randn(n_samples, 1, image_size, image_size).to(device) for t in reversed(range(T)): t_tensor = torch.full((n_samples,), t, device=device, dtype=torch.long) predicted_noise = model(x, t_tensor) beta_t = beta[t].to(device) alpha_t = alpha[t].to(device) alpha_hat_t = alpha_hat[t].to(device) if t > 0: noise = torch.randn_like(x) else: noise = 0 x = 1 / alpha_t.sqrt() * (x - (1 - alpha_t) / (1 - alpha_hat_t).sqrt() * predicted_noise) + beta_t.sqrt() * noise return x2.4 训练过程
在训练过程中,我们使用每个时间步的加噪图像
x_t和对应的噪声epsilon_t来训练模型。目标是最小化模型预测噪声和真实噪声之间的均方误差。def train(): device = torch.device("cuda" if torch.cuda.is_available() else "cpu") dataset = MNIST_IDX("data/MNIST/raw/train-images.idx3-ubyte", "data/MNIST/raw/train-labels.idx1-ubyte") dataloader = DataLoader(dataset, batch_size=128, shuffle=True) model = SimpleUNet().to(device) optimizer = torch.optim.Adam(model.parameters(), lr=1e-3) mse = nn.MSELoss() for epoch in range(100): for step, x in enumerate(dataloader): x = x.to(device) t = torch.randint(03. 总结
DDPM利用扩散过程和去噪过程来生成图像,训练一个神经网络来预测每个时间步的噪声,从而逐步去除噪声,生成真实图像。我们通过前向扩散过程将噪声添加到数据中,通过反向去噪过程恢复数据。在实现过程中,使用了简化的U-Net作为生成网络,并结合PyTorch进行训练与推理。
附代码
import os
import struct
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
from torchvision.utils import make_grid
from matplotlib import pyplot as plt
# ========== 1. 数据集类 ==========
class MNIST_IDX(Dataset):
def __init__(self, image_file, label_file, transform=None):
self.transform = transform
with open(label_file, 'rb') as f:
magic, num = struct.unpack(">II", f.read(8))
self.labels = np.frombuffer(f.read(), dtype=np.uint8)
with open(image_file, 'rb') as f:
magic, num, rows, cols = struct.unpack(">IIII", f.read(16))
images = np.frombuffer(f.read(), dtype=np.uint8).reshape(num, 28, 28)
self.images = images
def __len__(self):
return len(self.labels)
def __getitem__(self, idx):
img = self.images[idx]
img = torch.from_numpy(img).float().unsqueeze(0) / 255.0 # [1, 28, 28]
if self.transform:
img = self.transform(img)
return img
# ========== 2. 模型(简化版 U-Net) ==========
class SimpleUNet(nn.Module):
def __init__(self, in_channels=1, base_channels=64):
super().__init__()
self.down1 = nn.Sequential(
nn.Conv2d(in_channels + 1, base_channels, 3, 1, 1), # +1是为了时间嵌入
nn.ReLU(),
nn.Conv2d(base_channels, base_channels, 3, 1, 1),
nn.ReLU()
)
self.down2 = nn.Sequential(
nn.Conv2d(base_channels, base_channels*2, 3, 2, 1),
nn.ReLU()
)
self.middle = nn.Sequential(
nn.Conv2d(base_channels*2, base_channels*2, 3, 1, 1),
nn.ReLU()
)
self.up2 = nn.Sequential(
nn.ConvTranspose2d(base_channels*2, base_channels, 4, 2, 1),
nn.ReLU()
)
self.out = nn.Sequential(
nn.Conv2d(base_channels, in_channels, 3, 1, 1)
)
def forward(self, x, t):
# 将时间步t扩展为图像尺寸并拼接
t_embed = t[:, None, None, None].float() / 1000 # normalize
t_embed = t_embed.expand(-1, 1, x.shape[2], x.shape[3])
x = torch.cat([x, t_embed], dim=1)
x1 = self.down1(x)
x2 = self.down2(x1)
x3 = self.middle(x2)
x4 = self.up2(x3)
out = self.out(x4 + x1) # skip connection
return out
# ========== 3. Diffusion超参数 ==========
T = 300 # 总时间步
beta = torch.linspace(1e-4, 0.02, T)
alpha = 1. - beta
alpha_hat = torch.cumprod(alpha, dim=0)
# ========== 4. 加噪函数 ==========
def forward_diffusion_sample(x_0, t, noise=None):
if noise is None:
noise = torch.randn_like(x_0)
sqrt_alpha_hat = alpha_hat[t][:, None, None, None].sqrt().to(x_0.device)
sqrt_one_minus = (1 - alpha_hat[t])[:, None, None, None].sqrt().to(x_0.device)
return sqrt_alpha_hat * x_0 + sqrt_one_minus * noise, noise
# ========== 5. 采样函数 ==========
@torch.no_grad()
def sample_ddpm(model, image_size=28, n_samples=64, device='cpu'):
model.eval()
x = torch.randn(n_samples, 1, image_size, image_size).to(device)
for t in reversed(range(T)):
t_tensor = torch.full((n_samples,), t, device=device, dtype=torch.long)
predicted_noise = model(x, t_tensor)
beta_t = beta[t].to(device)
alpha_t = alpha[t].to(device)
alpha_hat_t = alpha_hat[t].to(device)
if t > 0:
noise = torch.randn_like(x)
else:
noise = 0
x = 1 / alpha_t.sqrt() * (x - (1 - alpha_t) / (1 - alpha_hat_t).sqrt() * predicted_noise) + beta_t.sqrt() * noise
return x
# ========== 6. 主训练函数 ==========
def train():
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
dataset = MNIST_IDX("data/MNIST/raw/train-images.idx3-ubyte", "data/MNIST/raw/train-labels.idx1-ubyte")
dataloader = DataLoader(dataset, batch_size=128, shuffle=True)
model = SimpleUNet().to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
mse = nn.MSELoss()
for epoch in range(20):
for step, x in enumerate(dataloader):
x = x.to(device)
t = torch.randint(0, T, (x.shape[0],), device=device).long()
x_noisy, noise = forward_diffusion_sample(x, t)
noise_pred = model(x_noisy, t)
loss = mse(noise_pred, noise)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if step % 100 == 0:
print(f"Epoch {epoch} Step {step} Loss: {loss.item():.4f}")
# 每个epoch生成图像
samples = sample_ddpm(model, device=device)
grid = make_grid(samples[:64], nrow=8, normalize=True)
npimg = grid.cpu().numpy().transpose(1, 2, 0)
plt.figure(figsize=(6,6))
plt.imshow(npimg, cmap='gray')
plt.axis('off')
plt.title(f"Samples at Epoch {epoch}")
plt.show()
# ========== 7. 启动训练 ==========
if __name__ == "__main__":
train()