clone 系统调用(The clone system call)
在 Linux 中,使用 clone() 系统调用来创建新的线程或进程。fork() 系统调用和 pthread_create() 函数都基于 clone() 的实现。
clone() 系统调用允许调用者决定哪些资源应该与父进程共享,哪些应该被复制或隔离。
📌 clone() 系统调用的标志
clone() 通过一组标志来控制父子进程或线程之间的资源共享。常见的标志包括:
- C L O N E _ F I L E S CLONE\_FILES CLONE_FILES:共享文件描述符表,意味着子进程或子线程将共享父进程的文件描述符(打开的文件)。
- C L O N E _ V M CLONE\_VM CLONE_VM:共享地址空间,意味着子进程或子线程将与父进程共享同一个虚拟内存地址空间。
- C L O N E _ F S CLONE\_FS CLONE_FS:共享文件系统信息,如根目录和当前目录。
- C L O N E _ N E W N S CLONE\_NEWNS CLONE_NEWNS:不共享挂载命名空间,意味着子进程或子线程将有自己的挂载点,不与父进程共享。
- C L O N E _ N E W I P C CLONE\_NEWIPC CLONE_NEWIPC:不共享 IPC 命名空间(例如,System V IPC 对象、POSIX 消息队列等)。
- C L O N E _ N E W N E T CLONE\_NEWNET CLONE_NEWNET:不共享网络命名空间(例如,网络接口、路由表等)。
🧠 重要概念解释
- f o r k ( ) fork() fork():系统调用,用于创建新进程,复制父进程的所有资源,形成父子进程。
- p t h r e a d _ c r e a t e ( ) pthread\_create() pthread_create():函数,用于在用户空间创建新线程。通常与线程库(如 POSIX 线程库)配合使用。
- 命名空间(Namespace):在 Linux 中,命名空间用于隔离系统资源。不同的命名空间提供进程间的隔离,例如文件系统、IPC、网络等命名空间。
✅ 创建线程与进程的区别
- 如果使用
CLONE_FILES | CLONE_VM | CLONE_FS组合标志,调用者会创建一个新线程,因为它共享父进程的文件描述符表、地址空间和文件系统信息。 - 如果不使用这些标志,调用者将创建一个新进程,因为新进程将拥有自己的资源,如地址空间、文件描述符表等。
命名空间与“容器”技术(Namespaces and “Containers”)
“容器”是一种轻量级的虚拟机形式,它们共享同一个内核实例,与传统的虚拟化技术不同,传统虚拟化技术通过虚拟机监视器(hypervisor)运行多个虚拟机(VM),每个虚拟机都有一个独立的内核实例。
📌 容器技术的例子
- LXC(Linux Containers):允许运行轻量级的“虚拟机”,并提供类似虚拟化的隔离功能。
- Docker:一种专门用于运行单一应用程序的容器技术,广泛用于开发和部署应用。
容器技术依赖于几个内核特性,其中之一就是命名空间(namespace)。命名空间通过隔离不同的资源,避免它们在全局范围内可见。
🔒 命名空间的作用
命名空间为容器提供了资源隔离,使得容器中的进程不会被其他容器的进程所干扰。比如:
- 没有容器时,系统中的所有进程都在
/proc中可见; - 有容器时,一个容器中的进程不会被其他容器看到(在
/proc中不可见,也无法被杀死)。
🧠 关键概念解释
命名空间(Namespace):命名空间用于隔离系统资源,使得在不同的命名空间中,资源(如进程、网络接口、挂载点等)是独立的,互不干扰。Linux 支持多种类型的命名空间,包括进程 ID(PID)命名空间、网络命名空间、文件系统命名空间等。
容器(Container):容器是一种通过利用命名空间和其他内核特性(如控制组cgroup)实现的轻量级虚拟化技术。容器共享主机的内核,但它们的资源(如进程、文件系统、网络等)是隔离的。
struct nsproxy结构体:用于管理和分组资源类型的内核数据结构。它是实现命名空间隔离的关键,支持的命名空间类型包括 IPC、网络、PID、挂载等。
📌 容器如何实现资源隔离
- 容器通过将资源(如网络接口、进程 ID 等)分配到不同的命名空间来实现资源的隔离。
- 例如,网络命名空间会将网络接口列表存储在
struct net中,而不是使用全局的网络接口列表。
📊 默认命名空间与创建新命名空间
- 系统启动时会初始化一个默认的命名空间(如
init_net),所有进程默认共享该命名空间。 - 当创建新的命名空间时,系统会为新命名空间创建一个新的
net命名空间,并将新进程关联到这个新的命名空间,而不是默认的命名空间。
访问当前进程(Accessing the Current Process)
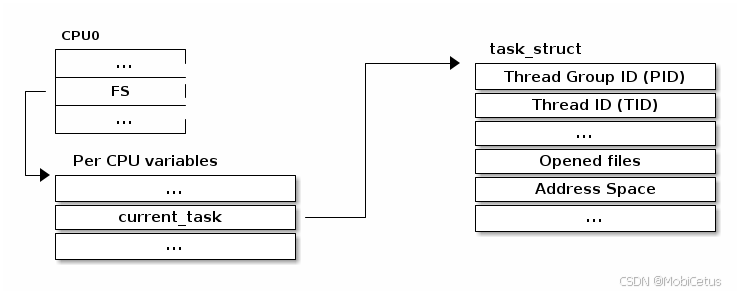
访问当前进程是一个常见的操作,很多系统调用都需要访问当前进程的相关信息:
- 打开文件时需要访问
struct\ task_struct中的file字段。 - 映射新文件时需要访问
struct\ task_struct中的mm字段。
📌 访问当前进程的宏
为了支持快速访问当前进程,尤其是在多处理器配置中,每个 CPU 都有一个变量来存储和获取指向当前 struct\ task_struct 的指针。
以前的实现方式
在以前,current 宏的实现方式如下:
/* 获取当前栈指针 */
register unsigned long current_stack_pointer asm("esp") __attribute_used__;
/* 获取当前线程信息结构体 */
static inline struct thread_info *current_thread_info(void)
{
return (struct thread_info *)(current_stack_pointer & ~(THREAD_SIZE – 1));
}
#define current current_thread_info()->task
s t r u c t t a s k _ s t r u c t struct\ task\_struct struct task_struct:Linux 内核中用于表示进程(包括线程)的核心数据结构,包含了进程的调度信息、文件描述符、地址空间等。
c u r r e n t current current 宏:用于快速访问当前进程的 t a s k _ s t r u c t task\_struct task_struct 结构体。在多核处理器上,它通过每个 CPU 特有的变量来加速访问。
c u r r e n t _ s t a c k _ p o i n t e r current\_stack\_pointer current_stack_pointer:通过汇编指令直接获取当前栈指针,用于定位当前线程的信息。
t h r e a d _ i n f o thread\_info thread_info:存储与线程相关的信息,通常包含线程的状态、栈、进程 ID 等。通过 c u r r e n t _ s t a c k _ p o i n t e r current\_stack\_pointer current_stack_pointer`获取线程信息后,可以进一步访问线程的任务结构体。
THREAD_SIZE:定义了线程的栈大小,通常用于按位操作栈指针,确定当前线程的信息。
上下文切换(Context Switching)
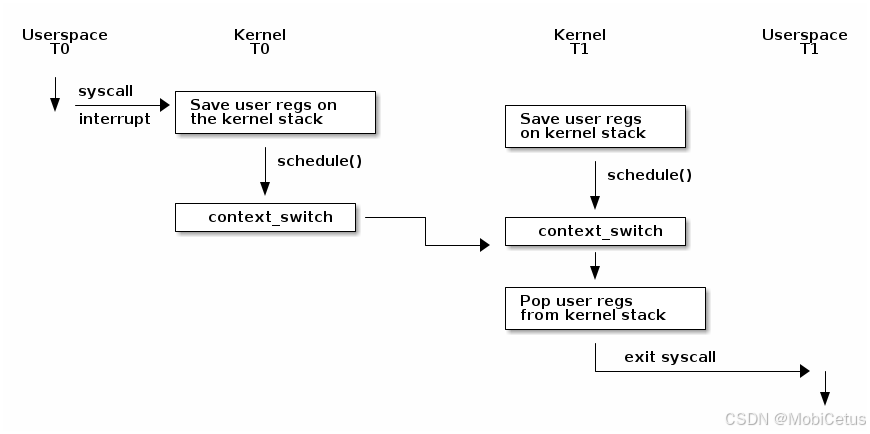
上图展示了 Linux 内核中上下文切换的整体流程:
- 触发内核态:上下文切换只能在内核态进行,通常由系统调用或中断引发。此时,用户空间寄存器会被保存到内核栈中。
- 调用
schedule():在某些时刻(如线程阻塞等待 I/O 或时间片用尽),内核会调用schedule(),决定从线程 T0 切换到线程 T1。 context_switch()函数:该函数执行与架构相关的操作,如更新地址空间(若从用户态切换到其他用户态)并维护 TLB(Translation Lookaside Buffer)。- 若
!next->mm(目标切换到内核线程),则共享prev->active_mm。 - 若
next->mm(目标切换到用户进程),则调用switch_mm_irqs_off()处理内存映射切换。
- 若
switch_to():context_switch()最终调用switch_to()进行真正的寄存器状态和内核栈切换。其实现包含以下关键步骤:- 保存被调度出线程的寄存器到当前栈:如
ebp, ebx, edi, esi等“调用者保存的寄存器”; - 更新
esp(栈指针),切换到新线程的内核栈; - 恢复新线程的寄存器,然后跳转到
__switch_to继续执行。
- 保存被调度出线程的寄存器到当前栈:如
首先要注意的是,上下文切换之前必须完成一次从用户空间到内核空间的过渡(如通过系统调用或中断)。在这一点上,用户空间的寄存器状态会被保存到内核栈上。当调度器调用 schedule() 函数后,可能判定当前线程(如 T0)需要切换到另一个线程(如 T1),原因可能包括当前线程等待I/O操作完成而阻塞,或其时间片耗尽。
此时,context_switch() 会执行特定于体系结构的操作,并在需要时切换地址空间:
static __always_inline struct rq *
context_switch(struct rq *rq, struct task_struct *prev,
struct task_struct *next, struct rq_flags *rf)
{
prepare_task_switch(rq, prev, next);
arch_start_context_switch(prev);
if (!next->mm) { // 若目标线程为内核线程(无用户地址空间)
enter_lazy_tlb(prev->active_mm, next);
next->active_mm = prev->active_mm;
if (prev->mm)
mmgrab(prev->active_mm);
else
prev->active_mm = NULL;
} else { // 若目标线程为用户线程
membarrier_switch_mm(rq, prev->active_mm, next->mm);
switch_mm_irqs_off(prev->active_mm, next->mm, next);
if (!prev->mm) { // 如果来源线程是内核线程
rq->prev_mm = prev->active_mm;
prev->active_mm = NULL;
}
}
rq->clock_update_flags &= ~(RQCF_ACT_SKIP|RQCF_REQ_SKIP);
prepare_lock_switch(rq, next, rf);
switch_to(prev, next, prev); // 执行寄存器状态和内核栈切换
barrier();
return finish_task_switch(prev);
}
接下来调用特定于体系结构的函数 s w i t c h _ t o switch\_to switch_to,它负责切换寄存器状态和内核栈指针。寄存器状态保存在栈中,而栈指针被保存在任务结构体中:
#define switch_to(prev, next, last) \
do { \
((last) = __switch_to_asm((prev), (next))); \
} while (0)
下面是 x86 架构上 _ _ s w i t c h _ t o _ a s m \_\_switch\_to\_asm __switch_to_asm 的汇编实现:
SYM_CODE_START(__switch_to_asm)
pushl %ebp
pushl %ebx
pushl %edi
pushl %esi
pushfl
movl %esp, TASK_threadsp(%eax)
movl TASK_threadsp(%edx), %esp
#ifdef CONFIG_STACKPROTECTOR
movl TASK_stack_canary(%edx), %ebx
movl %ebx, PER_CPU_VAR(stack_canary)+stack_canary_offset
#endif
#ifdef CONFIG_RETPOLINE
FILL_RETURN_BUFFER %ebx, RSB_CLEAR_LOOPS, X86_FEATURE_RSB_CTXSW
#endif
popfl
popl %esi
popl %edi
popl %ebx
popl %ebp
jmp __switch_to
SYM_CODE_END(__switch_to_asm)
在上下文切换过程中,你会发现指令指针(IP / EIP / RIP)并没有被显式保存。之所以不需要额外保存,有以下几个原因:
总是在同一个函数中恢复执行
当任务恢复时,它会回到同一个函数内继续执行,从而不必担心额外的指令指针保存。schedule()(或context_switch()内联)的调用者返回地址已保存在内核栈中
schedule()所在函数(或直接调用context_switch()的地方)的返回地址会保存在栈中。当切换回来时,CPU 会自动从栈中取出这个返回地址。使用
jmp执行__switch_to()函数
当__switch_to()函数执行完毕并返回时,它会从栈中弹出原先(下一个任务)的返回地址,因而无需我们显式地保存 IP。
🧠 关键概念解释
指令指针(Instruction Pointer)
指示 CPU 正在执行的下一条指令的地址。在 x86 上通常被称为 EIP(32 位)或 RIP(64 位)。内核栈(Kernel Stack)
每个任务都有自己的内核栈,用于在内核态保存函数调用、寄存器以及返回地址等信息。schedule()和context_switch()
Linux 内核调度的重要函数,它们在切换任务时会内联或调用一系列的汇编/内核逻辑来完成上下文切换。
阻塞与唤醒任务(Blocking and Waking Up Tasks)
任务状态(Task States)
下图展示了任务(线程)的各种状态以及它们之间的可能转换路径:
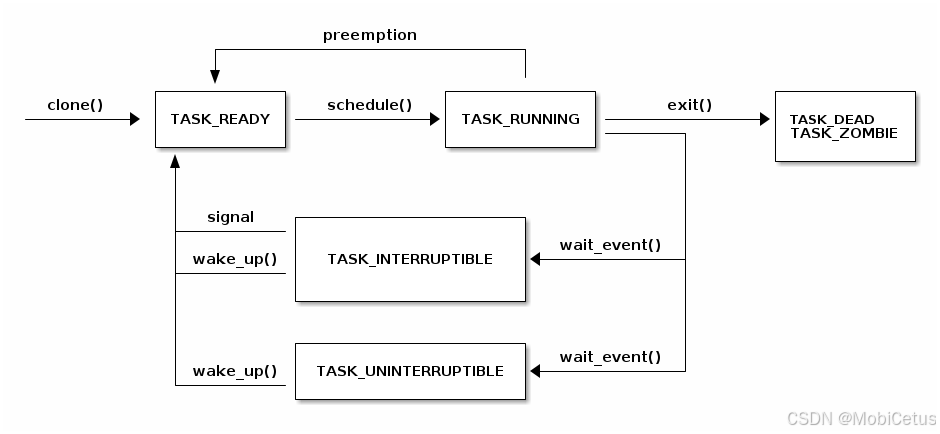
- 从
clone()创建新任务,初始状态为TASK_READY。 - 当调度器调用
schedule()后,任务变为TASK_RUNNING。 - 如果任务调用
exit(),它会变为TASK_DEAD或TASK_ZOMBIE。 - 运行中的任务可以因为 I/O 或其他事件调用
wait_event()进入阻塞状态:TASK_INTERRUPTIBLE:可中断的睡眠状态,可以被信号唤醒;TASK_UNINTERRUPTIBLE:不可中断的睡眠状态,只有事件发生才唤醒。
- 被阻塞的任务可通过
wake_up()被重新唤醒并返回TASK_READY状态,等待再次被调度执行。
阻塞当前线程(Blocking the Current Thread)
阻塞当前线程是操作系统中一个关键操作,它的意义在于当当前线程无法继续运行(例如等待 I/O 完成)时,让出 CPU,让其他线程得以运行,从而实现高效调度。
实现线程阻塞的操作步骤如下:
- 将当前线程的状态设置为
TASK_UNINTERRUPTIBLE或TASK_INTERRUPTIBLE; - 将该线程添加到等待队列中;
- 调用调度器
schedule(),选择另一个READY队列中的任务; - 执行上下文切换,将 CPU 控制权交给新的任务。
等待队列是一个链表,每个元素包含一些额外的信息,如指向任务结构体的指针。
💡 关于 wait_event 的重要说明
wait_event和wake_up之间的时序非常关键。为了防止死锁,在检查条件前,任务必须先加入等待队列;- 唤醒操作
wake_up会检查条件是否满足,并在满足时唤醒线程; - 唤醒前还会检查是否有信号(如果线程为可中断状态);
- 唤醒后,调度器会重新安排任务执行,通过
schedule()完成实际的上下文切换。
TASK_RUNNING:线程正在 CPU 上执行;TASK_READY:线程就绪,等待调度;TASK_INTERRUPTIBLE:线程在等待某事件,可被信号中断;TASK_UNINTERRUPTIBLE:线程在等待某事件,不能被信号中断;wait_event:内核机制,用于让线程等待某个条件;wake_up:当条件满足时,唤醒被阻塞的线程;schedule():内核调度函数,选择下一个要运行的线程。
唤醒任务(Waking up a Task)
我们可以使用内核提供的 wake_up 原语来唤醒被阻塞的任务。当某个事件(如 I/O 完成)发生时,内核会调用 wake_up 将等待中的线程重新置为可运行状态。其主要操作流程如下:
🧱 唤醒流程(高层操作步骤)
- 从等待队列中选择一个任务
找到在特定等待队列中阻塞的任务,通常这些任务正在等待某个条件或事件完成。 - 将任务状态设置为
TASK_READY
这意味着该任务已经可以继续执行,不再处于TASK_INTERRUPTIBLE或TASK_UNINTERRUPTIBLE阻塞状态。 - 将任务插入调度器的就绪队列(READY queue)中
被唤醒的任务将重新加入调度器的就绪队列,等待系统调度器下一次调度。
🧠 多核系统中的复杂性(SMP 系统)
在 SMP(对称多处理)系统中,唤醒任务的过程更为复杂,原因如下:
- 每个 CPU 核心有自己的就绪队列
为了避免锁竞争与提升并行性,Linux 在每个 CPU 上维护独立的调度队列。 - 任务队列之间需要负载均衡
如果唤醒的任务在不同的 CPU 上被调度,系统需要确保多个队列负载平衡,防止有的 CPU 空闲而有的 CPU 拥堵。 - 唤醒其他 CPU 可能需要发信号
如果目标任务位于非当前 CPU 的就绪队列中,需要通过 IPI(中断)唤醒对应的处理器,以便它能及时调度该任务。