目录

引言
随着ChatGPT、GPT-4等大语言模型的出现,人工智能技术在各个领域展现出惊人的能力。然而,这些通用大模型在特定领域和任务中往往需要进一步优化才能发挥最佳效果。大模型微调(Fine-tuning)作为一种关键的优化技术,能够有效提升模型在特定场景下的表现。本文将从概念、原理、方法到实践,全面介绍大模型微调技术。
从GPT-3到ChatGPT的演进过程中,微调技术发挥了关键作用。例如,ChatGPT通过指令微调(Instruction Tuning)和人类反馈强化学习(RLHF)等技术,将通用的语言模型转变为能够理解和执行具体指令的对话助手。这种转变充分展示了微调技术在提升模型实用性方面的重要价值。
一、什么是大模型微调?
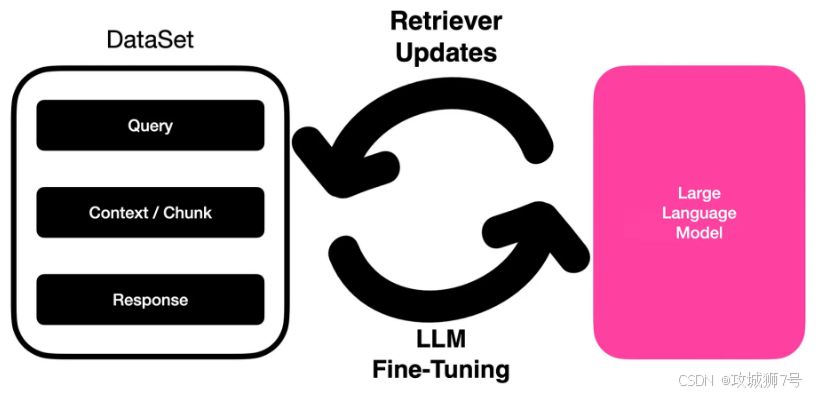
大模型微调是在预训练模型的基础上,使用特定任务的数据集对模型进行进一步训练,使其更好地适应特定应用场景的过程。这个过程可以类比为"因材施教"——在学生(模型)已经掌握基础知识(预训练)的前提下,针对特定科目(任务)进行专门的训练和指导。
1.1 预训练与微调的区别
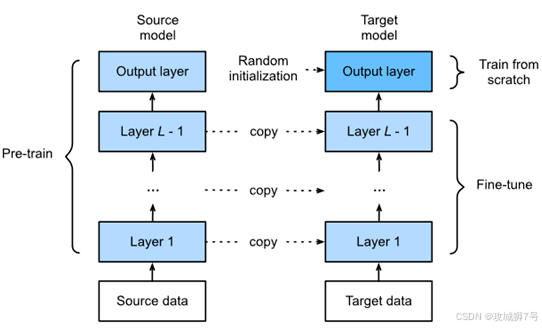
(1)预训练阶段
- 使用海量通用数据(通常是互联网文本)
- 学习基础语言理解能力(词义、语法、知识等)
- 构建通用语言表示(通过自监督学习)
- 计算资源需求巨大(可能需要数千GPU训练数月)
- 训练目标通常是下一个词的预测
- 模型规模可达数千亿参数
(2)微调阶段
- 使用特定任务数据(通常是高质量标注数据)
- 优化特定场景表现(如问答、摘要等)
- 保留并改进已有能力(避免灾难性遗忘)
- 计算资源需求相对较小(单GPU即可完成)
- 训练目标更加具体(如分类准确率)
- 可选择性更新部分参数
1.2 微调的技术演进
微调技术经历了多个发展阶段:
(1)传统微调(2018年前)
- 全参数更新
- 需要大量标注数据
- 计算资源要求高
(2)迁移学习时代(2018-2020)
- 引入预训练-微调范式
- 降低了数据需求
- 提高了训练效率
(3)参数高效微调(2020至今)
- 提出LoRA等创新方法
- 显著降低资源需求
- 保持接近全参数微调的效果
二、为什么需要微调?
2.1 解决大模型的固有局限
(1)知识时效性
- 预训练数据可能已经过时(如GPT-3的训练数据截止于2021年)
- 无法自动获取最新知识(如新冠疫情相关信息)
- 需要通过微调注入新信息
- 实例:医疗模型需要及时更新最新的治疗方案和药物信息
(2)专业领域适应
- 通用模型缺乏专业领域深度(如法律、医疗术语)
- 特定行业术语理解有限(如金融市场专业词汇)
- 需要领域特定数据训练
- 案例:法律大模型需要学习最新的法规和判例
(3)任务特定优化
- 提高特定任务的准确性(如情感分析)
- 减少模型幻觉问题(避免虚假信息)
- 优化输出格式和风格(符合业务需求)
- 示例:客服机器人需要保持统一的回复风格
2.2 微调的优势
(1)成本效益
- 相比预训练成本更低(降低90%以上)
- 无需从零训练模型(避免重复建设)
- 快速实现任务适配(数天内完成)
- 实例:某企业用5天时间微调客服模型,性能提升40%
(2)数据效率
- 只需少量标注数据(通常几百条即可)
- 充分利用预训练知识(知识迁移)
- 快速收敛到理想效果(训练轮次少)
- 案例:使用1000条数据微调后准确率提升30%
(3)部署灵活
- 支持增量更新(定期注入新知识)
- 便于版本管理(多个微调版本切换)
- 适应不同应用场景(场景化定制)
- 示例:同一基座模型适配多个行业领域
三、主流微调方法
3.1 全参数微调
全参数微调是最直接的微调方式,更新模型的所有参数。虽然效果最好,但存在以下问题:
- 需要大量计算资源(通常需要多张高端GPU)
- 容易出现过拟合(尤其是数据量小时)
- 存储成本高(需要存储完整模型副本)
- 不适合小规模数据集(容易丢失通用能力)
- 部署成本高(每个任务都需要完整模型)
3.2 参数高效微调(PEFT)
PEFT技术通过只更新部分参数来实现高效微调,主要包括:
(1)LoRA(Low-Rank Adaptation)
- 原理:通过低秩矩阵分解减少参数量
- 实现:将权重更新分解为两个小矩阵相乘
- 优势:
* 参数量减少99%以上
* 训练速度提升2-3倍
* 显存需求降低80%
* 性能接近全参数微调
- 应用:广泛用于商业场景
(2)LoRA的改进版本
- LoRA+:
* 为不同矩阵设置不同学习率
* 提升训练稳定性
* 加快收敛速度
- rsLoRA:
* 引入秩稳定化机制
* 改善高秩训练效果
* 提高模型鲁棒性
- DoRA:
* 权重分解为幅度和方向
* 更精细的参数控制
* 更好的泛化能力
- PiSSA:
* 使用主奇异值初始化
* 保持模型稳定性
* 提高训练效率
(3)其他PEFT方法
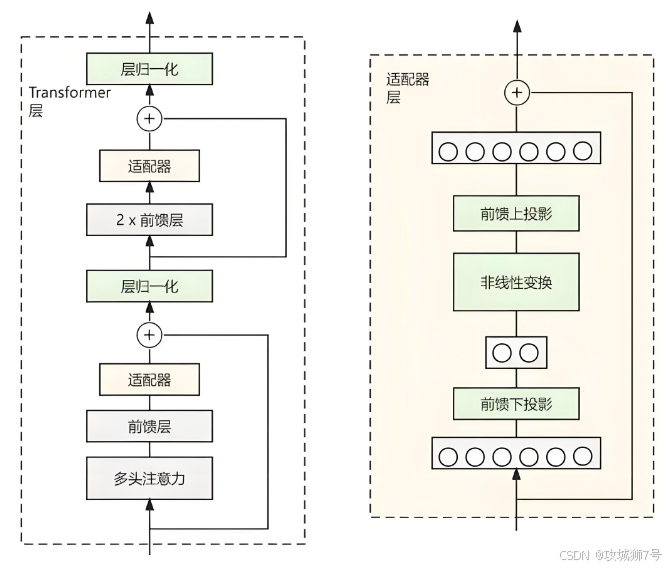
- Adapter Tuning:
* 在原有层间插入小型适配层
* 仅训练适配层参数
* 模块化设计,便于切换
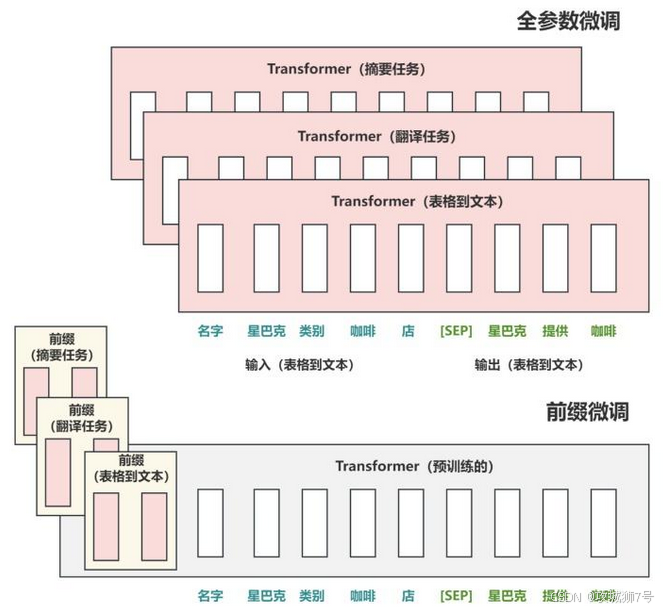
- Prefix Tuning:
* 在输入序列前添加可训练前缀
* 极低的参数量(<1%)
* 适合序列生成任务
- Prompt Tuning:
* 优化软提示词
* 参数量最少
* 实现简单,易于部署
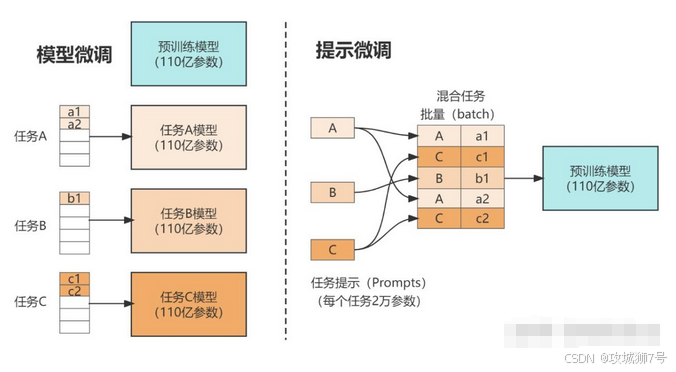
(4)对比RAG
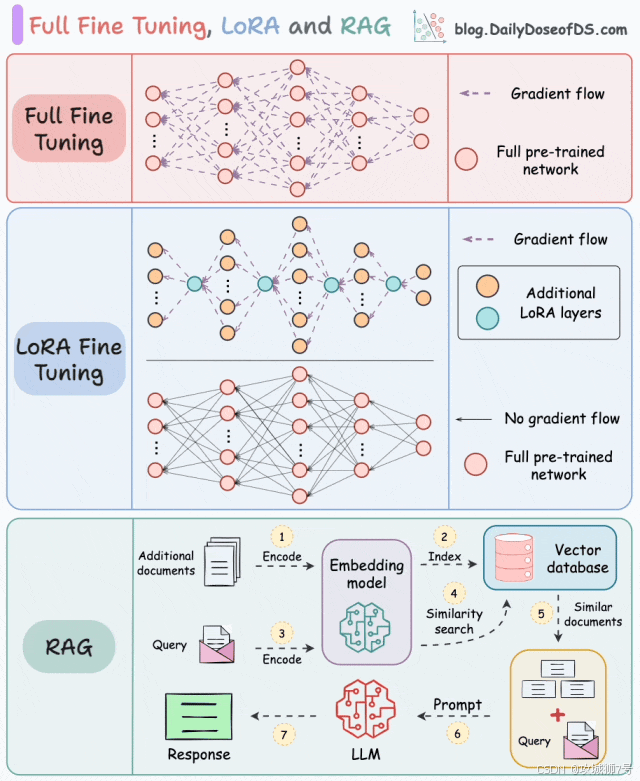
四、微调实践指南
4.1 数据准备
(1)数据质量要求
- 高质量标注数据(准确率>95%)
- 领域相关性强(与目标任务高度相关)
- 覆盖目标场景(包含各种用例)
- 数据格式规范(统一的格式标准)
- 避免数据偏差(平衡各类别数据)
- 注意数据隐私(脱敏处理)
(2)数据量建议
- 最少10条样本(OpenAI建议)
- 建议50-100条起步(效果明显)
- 根据效果逐步增加(增量优化)
- 避免过多噪声数据(影响效果)
- 定期更新数据集(保持时效性)
- 构建验证集(占比10-20%)
4.2 微调参数配置
1. 关键超参数
- 学习率:
* 通常选择1e-5到1e-4
* 可使用学习率预热
* 考虑使用学习率调度
- 批次大小:
* 根据GPU显存调整
* 通常8-32较为合适
* 可使用梯度累积
- 训练轮数:
* 避免过拟合
* 使用早停机制
* 监控验证集性能
- 优化器选择:
* 常用AdamW
* 设置合适的权重衰减
* 调整优化器参数
(2)LoRA特定参数
- rank(秩):
* 通常选择4-8
* 根据任务复杂度调整
* 权衡效果和效率
- alpha:
* 缩放因子,一般为16或32
* 影响更新步长
* 需要实验确定
- dropout:
* 防止过拟合,通常0.1
* 可根据数据量调整
* 监控训练曲线
- target_modules:
* 选择需要微调的层
* 通常包括注意力层
* 可选择关键层微调
4.3 训练过程管理
(1)监控指标
- 训练损失:
* 观察收敛趋势
* 检测异常波动
* 及时调整参数
- 验证集性能:
* 定期评估效果
* 避免过拟合
* 选择最佳模型
- GPU显存使用:
* 监控资源占用
* 优化批次大小
* 处理OOM问题
- 训练速度:
* 跟踪训练进度
* 估算完成时间
* 优化训练效率
(2)常见问题处理
- 显存不足:
* 减小批次大小
* 使用梯度累积
* 采用混合精度训练
- 过拟合:
* 增加正则化
* 使用早停策略
* 调整模型结构
- 欠拟合:
* 增加训练轮数
* 调整学习率
* 扩充训练数据
- 不稳定:
* 检查数据质量
* 调整优化器参数
* 使用梯度裁剪
五、微调效果评估
5.1 评估指标
(1)通用指标
- 准确率:分类任务的基本指标
- 召回率:检索任务的重要指标
- F1分数:平衡准确率和召回率
- 困惑度:生成任务的评估指标
- AUC:二分类任务的综合指标
- 混淆矩阵:详细的分类评估
(2)任务特定指标
- BLEU:机器翻译质量评估
- ROUGE:文本摘要效果评估
- 人工评估:主观质量评价
- 响应时间:模型性能指标
- 资源占用:部署效率指标
- 业务指标:实际应用效果
5.2 常见优化策略
(1)数据优化
- 增加数据多样性:
* 收集不同场景数据
* 使用数据增强技术
* 构建综合测试集
- 清理噪声数据:
* 去除异常样本
* 修正标注错误
* 统一数据格式
- 平衡数据分布:
* 处理类别不平衡
* 采样策略调整
* 权重平衡
- 增强数据质量:
* 专家审核
* 交叉验证
* 持续优化
(2)模型优化
- 调整微调参数:
* 学习率调优
* 批次大小选择
* 训练轮数控制
- 选择合适的PEFT方法:
* 任务特点分析
* 资源约束考虑
* 效果对比实验
- 集成多个微调模型:
* 模型融合
* 投票机制
* 集成学习
- 结合领域知识:
* 规则约束
* 专家经验
* 业务逻辑
六、未来发展趋势
(1)技术演进
- 更高效的微调方法:
* 参数压缩技术
* 知识蒸馏
* 动态适应
- 自动化参数选择:
* 超参数优化
* 架构搜索
* 自适应调整
- 多模态微调融合:
* 跨模态学习
* 统一表示
* 协同优化
- 持续学习能力:
* 增量学习
* 终身学习
* 知识更新
(2)应用拓展
- 垂直领域深化:
* 专业领域适配
* 场景化定制
* 精细化优化
- 个性化定制:
* 用户特征学习
* 偏好适配
* 动态更新
- 实时适应能力:
* 在线学习
* 快速适应
* 动态优化
- 跨语言迁移:
* 多语言支持
* 文化适应
* 语义对齐
大模型微调技术正在快速发展,从全参数微调到参数高效微调,从单一方法到多种技术的融合,微调技术在提升模型性能的同时,也在不断降低应用门槛。随着技术的进步和应用的深入,相信微调技术将在AI领域发挥越来越重要的作用,推动大模型在各个领域的落地应用。
未来,微调技术将朝着更高效、更智能、更易用的方向发展。通过持续的创新和实践,微调技术将帮助更多企业和开发者构建专属的AI应用,为各行各业带来更大的价值。