目录
一、HBase 初印象
在大数据的广阔天地中,数据量如同宇宙中的繁星,不断膨胀,传统数据库在海量数据的重压下逐渐力不从心。这时,HBase 作为大数据存储领域的一颗璀璨新星,闪耀登场。它基于 Hadoop 分布式文件系统(HDFS)构建,是一款分布式非关系型数据库(NoSQL),专为处理海量数据而生,在大数据生态系统里占据着举足轻重的地位。
与传统关系型数据库不同,HBase 采用面向列的存储方式,数据以列族(Column Family)的形式组织,这使得它在处理稀疏数据时优势尽显。比如,在记录用户信息时,若某些用户的部分字段为空,传统关系型数据库仍会为这些空值分配存储空间,而 HBase 则不会,极大地节省了宝贵的存储空间。
HBase 最为人称道的,是其强大的实时读写能力。在毫秒级的时间内,它就能对数据执行读写操作,在需要实时获取数据的应用场景中大放异彩,像电商平台的实时订单处理、在线推荐系统根据用户实时行为推荐商品,以及金融领域的实时交易监控等场景,HBase 都能游刃有余地应对。
并且,HBase 具有出色的可扩展性。随着数据量的疯狂增长,只需简单地增加节点,就能轻松存储更多的数据,就像不断扩充容量的超级仓库,轻松接纳源源不断的数据。在大数据的浪潮中,HBase 正以其独特的魅力和强大的功能,成为众多企业处理海量数据的得力助手,开启大数据存储与处理的新时代。
二、HBase 核心概念大揭秘
2.1 数据模型剖析
2.1.1 表(Table)
在 HBase 的世界里,表是数据存储的基础容器,好比是一个巨大的仓库,用来存放各种数据。这和我们熟悉的关系数据库中的表类似,但又有着独特之处。创建 HBase 表时,不需要像关系数据库那样详细地声明每一列的具体信息,只需声明列族即可,后续可以根据实际需求动态地添加列,这使得 HBase 在应对数据结构变化时更加灵活。例如,在创建一个存储用户信息的表时,我们只需声明“基本信息”“联系方式”等列族,至于每个列族下具体有哪些列,可以在数据插入时再确定。
2.1.2 行键(Row Key)
行键堪称每行数据独一无二的标识,就像每个人的身份证号码,是区分不同行数据的关键。在 HBase 中,数据按照行键的字典序排列存储,这一特性对数据的存储和查询有着深远的影响。当进行查询操作时,如果使用行键进行精确查询,HBase 能够快速定位到目标数据,查询效率极高。因为行键有序排列,在进行范围查询时,HBase 也能利用这一特性,迅速筛选出符合条件的数据。比如,在一个按时间顺序存储交易记录的表中,以交易时间作为行键,当我们需要查询某个时间段内的交易记录时,HBase 就能高效地完成任务。但如果行键设计不合理,如大量数据的行键前缀相同,就可能导致数据热点问题,即大量的数据操作集中在某一个或几个 Region 上,影响系统的整体性能。
2.1.3 列族(Column Family)
列族是相关列的集合,是 HBase 数据模型的重要组成部分。它就像是一个文件夹,将一些相关的列放在一起,方便管理和存储。在物理存储上,同一列族的数据会被存储在一起,这大大提高了数据的读写性能。例如,在前面提到的用户信息表中,“基本信息”列族可以包含姓名、年龄、性别等列,这些列的数据在存储和读取时会被视为一个整体,减少了磁盘 I/O 操作,提升了效率。而且,列族在创建表时就需要确定,一旦确定,修改起来相对困难,所以在设计表结构时,需要谨慎规划列族,确保其符合业务需求和数据访问模式。
2.1.4 列限定符(Column Qualifier)
列限定符是列族内进一步细分数据的关键。在同一个列族中,通过不同的列限定符可以区分不同的列。它与列族一起,构成了列的完整标识。比如在“联系方式”列族中,通过“电话”“邮箱”等列限定符,就能准确地定位到用户的具体联系方式。列限定符可以根据实际需求动态添加,这为数据的灵活存储和管理提供了便利。在记录用户的兴趣爱好时,随着用户兴趣的变化,可以随时添加新的列限定符来记录不同的兴趣爱好。
2.1.5 时间戳(Timestamp)
时间戳在 HBase 中主要用于实现数据的版本控制。每个单元格的数据都可以有多个版本,而时间戳就是区分这些版本的依据。当数据发生更新时,HBase 会自动为新的数据版本分配一个新的时间戳,时间戳越大,表示数据越新。在读取数据时,如果不指定时间戳,默认返回最新版本的数据。这一特性在很多场景下都非常有用,比如在保存用户的操作记录时,通过时间戳可以清晰地看到用户在不同时间的操作内容,方便进行数据回溯和分析。
2.1.6 单元格(Cell)
单元格是 HBase 中数据存储的最小单位,由行键、列族、列限定符和时间戳共同唯一确定。它就像是一个小盒子,里面存放着具体的数据值。单元格中的数据是以字节码的形式存储的,这使得 HBase 能够存储各种类型的数据,无论是文本、数字还是二进制数据。在前面提到的用户信息表中,“user1”用户在“基本信息”列族下“姓名”列限定符对应的单元格,在某个时间戳下可能存储着“张三”这个值,这个单元格就是通过行键“user1”、列族“基本信息”、列限定符“姓名”和特定的时间戳来确定的。
2.2 存储结构探秘
2.2.1 Region
Region 是 HBase 实现分布式存储和负载均衡的最小单元。可以把它想象成一个数据分片,每个 Region 负责存储表中一部分数据。当表中的数据量不断增加时,Region 会自动进行分裂,以保证数据的均衡存储和高效访问。具体来说,当一个 Region 的大小超过设定的阈值(默认是 10GB)时,HBase 会将其按照行键的顺序拆分成两个新的 Region,然后将这两个新 Region 分配到不同的 RegionServer 上。这样一来,数据就被分散存储到了多个节点上,避免了单个节点负载过高的问题,同时也提高了数据的读写性能。例如,在一个存储海量用户行为数据的表中,随着数据量的不断增长,Region 会不断分裂,使得数据能够均匀地分布在整个集群中。
2.2.2 Store
每个 Region 由多个 Store 组成,每个 Store 对应一个列族。Store 在数据存储中起着关键作用,它负责管理和存储对应列族的数据。当数据写入 HBase 时,会首先写入到对应的 Store 中。在读取数据时,也会从相应的 Store 中获取数据。由于每个列族的数据被存储在单独的 Store 中,这使得数据的管理和维护更加清晰,同时也有利于提高数据的读写效率。比如在一个包含用户基本信息和用户订单信息的表中,“基本信息”列族和“订单信息”列族的数据会分别存储在不同的 Store 中,当我们查询用户基本信息时,只需要从对应的 Store 中读取数据,减少了不必要的数据读取。
2.2.3 MemStore
MemStore 是 HBase 中的内存缓存,它就像是一个临时仓库,用于暂存那些还未持久化到磁盘上的数据。当客户端进行数据写入操作时,数据首先会被写入到 MemStore 中。当 MemStore 中的数据量达到一定阈值(默认是 128MB)时,会触发 Flush 操作,将 MemStore 中的数据持久化到磁盘上,生成一个 StoreFile 文件。MemStore 的存在大大提高了 HBase 的读写性能。因为内存的读写速度远远快于磁盘,数据先写入内存可以减少磁盘 I/O 操作,提高写入效率。在读取数据时,如果所需数据在 MemStore 中,也能快速返回,提升了查询速度。但如果 MemStore 占用内存过大,可能会影响系统的稳定性,所以需要合理配置 MemStore 的大小。
2.3.4 StoreFile
StoreFile 是 MemStore 数据持久化后的文件,它以 HFile 格式存储在 HDFS 上。HFile 文件是一种经过优化的存储格式,采用了 Bloom Filter、Block Index 等技术,以提高数据的读取效率。Bloom Filter 可以快速判断某个键是否存在于文件中,减少不必要的磁盘 I/O 操作;Block Index 则提供了对数据块的索引,使得在读取数据时能够快速定位到目标数据块。随着数据的不断写入和 MemStore 的不断 Flush,会产生多个 StoreFile 文件。为了提高查询性能和减少磁盘空间占用,HBase 会定期对这些 StoreFile 文件进行合并操作,将多个小的 StoreFile 文件合并成一个大的 StoreFile 文件,同时删除那些已经被更新或删除的数据。
三、HBase 架构与工作原理深度解析
3.1 架构组件介绍
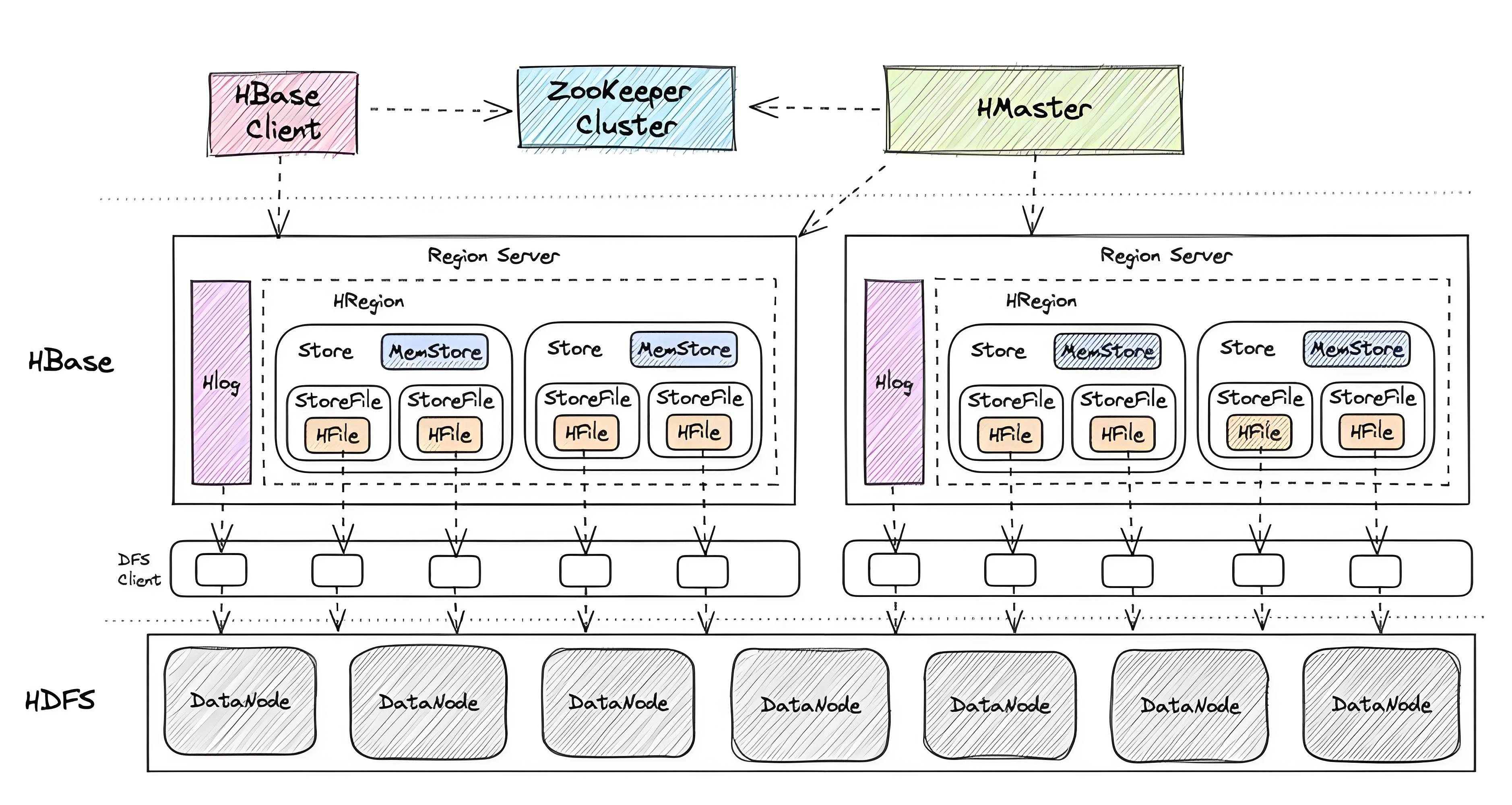
3.1.1 HMaster
HMaster 堪称 HBase 集群的“大管家”,承担着众多关键职责。在元数据表格管理方面,它就像一位严谨的图书管理员,精心维护着 HBase 中所有表和 Region 的元数据信息。当用户创建新表时,HMaster 会在元数据中记录相关信息,就像为新到的图书登记入库;当表的结构发生变化,如添加或删除列族时,HMaster 也会及时更新元数据,确保信息的准确性。
在监视 Region 负载均衡上,HMaster 如同一位精明的调度员,时刻关注着各个 RegionServer 的负载情况。一旦发现某个 RegionServer 负载过高,它会迅速采取行动,将部分 Region 迁移到负载较轻的 RegionServer 上,实现负载的均衡分配。这就好比在一个繁忙的物流中心,调度员会根据各个仓库的存储情况,合理分配货物,避免某个仓库过于拥挤。
HMaster 还是故障转移的“救火队长”。当某个 RegionServer 出现故障时,它能迅速察觉,并将该 RegionServer 上的 Region 转移到其他健康的 RegionServer 上,确保数据的可用性和系统的稳定性。在 Region 拆分时,HMaster 则负责协调和管理,确保拆分过程的顺利进行。
3.1.2 RegionServer
RegionServer 是 HBase 中真正负责数据存储和处理的“实干家”。它主要承担着处理 Cell 数据的读写重任,就像一位勤劳的仓库管理员,随时响应客户端的读写请求,准确地存储和获取数据。
RegionServer 还负责 Region 的拆分与合并操作。当一个 Region 的数据量增长到一定程度时,RegionServer 会将其拆分成两个或多个小的 Region,以提高数据的管理和访问效率,这就像是将一个过大的仓库分割成多个小仓库,便于管理;而当一些小的 Region 数据量较少时,RegionServer 又会将它们合并成一个大的 Region,节省资源。
RegionServer 与 Zookeeper 和 HDFS 有着紧密的交互关系。它会在 Zookeeper 上注册自己的信息,以便 HMaster 能够实时监控其状态;在数据存储方面,RegionServer 将数据存储在 HDFS 上,利用 HDFS 的分布式存储和高可靠性,确保数据的安全存储。
3.1.3 Zookeeper
Zookeeper 在 HBase 架构中扮演着不可或缺的“协调者”角色。在实现 Master 高可用上,Zookeeper 就像一位公正的选举官,当 HBase 集群中有多个 HMaster 时,它会通过选举机制,确保在任何时刻只有一个 HMaster 处于活跃状态,其他 HMaster 作为备用。一旦活跃的 HMaster 出现故障,Zookeeper 会立即启动选举,从备用 HMaster 中选出新的活跃 HMaster,保证系统的正常运行。
Zookeeper 还记录着 RegionServer 的部署信息,就像一个详细的地图,让 HMaster 和客户端能够随时了解各个 RegionServer 的位置和状态。在存储 meta 表位置信息上,Zookeeper 同样发挥着重要作用。客户端在进行数据读写操作时,首先会通过 Zookeeper 获取 meta 表的位置,进而找到对应的 RegionServer 和 Region,实现数据的准确访问。
3.2 读写流程详解
3.2.1 读流程
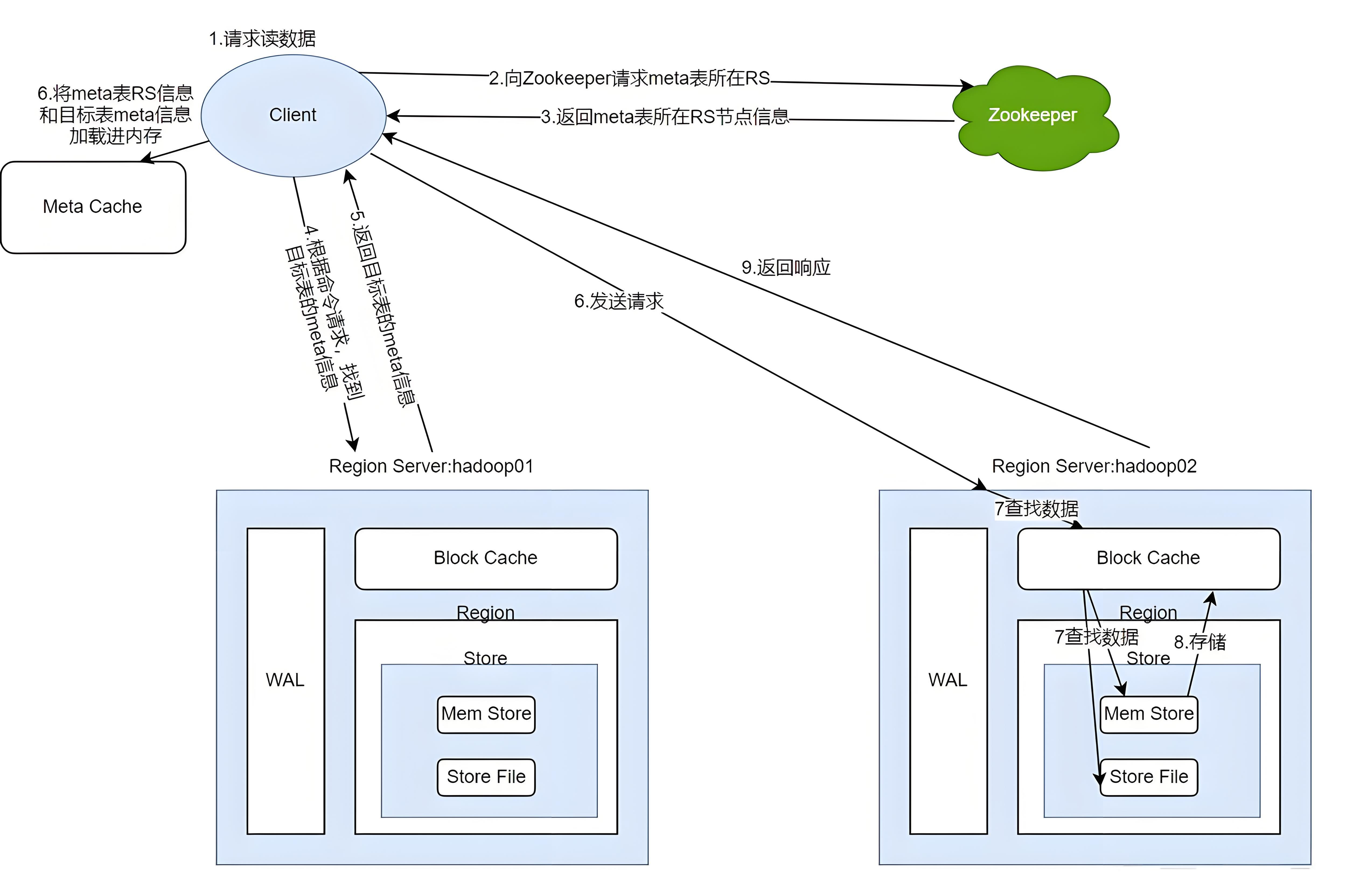
当客户端发起读请求时,就像开启了一场数据寻宝之旅。它首先会访问 Zookeeper,就像向一位智慧的向导询问宝藏的线索,获取 meta 表所在的 RegionServer 位置。得到线索后,客户端前往对应的 RegionServer,读取 meta 表,从这张记录着所有 Region 信息的“藏宝图”中,查询出目标数据所在的 RegionServer 和 Region。为了提高后续访问效率,客户端会将该表的 region 信息以及 meta 表的位置信息缓存在本地的 meta cache 中,就像将重要的地图信息保存起来。
接着,客户端与目标 RegionServer 建立通讯,开始真正的寻宝行动。RegionServer 会分别在 Block Cache(读缓存)、MemStore 和 Store File(HFile)中查询目标数据,就像在不同的宝藏箱中寻找宝物。它会将查到的所有数据,即同一条数据的不同版本(time stamp)或者不同的类型(Put/Delete)进行合并,确保得到最准确的结果。查询到的数据块(Block,HFile 数据存储单元,默认大小为 64KB)会被缓存到 Block Cache 中,方便下次查询。最后,RegionServer 将合并后的最终结果返回给客户端,完成这次数据寻宝之旅。
3.2.2 写流程
客户端发起写请求时,同样先求助于 Zookeeper,确定写入数据对应的 HRegion 和 HRegionServer。找到目标后,客户端与对应的 HRegionServer 进行通讯,开始数据写入操作。数据会被依次写入 HLog 和 Memstore,HLog 就像一个可靠的备份记录员,先将数据记录下来,防止数据丢失;Memstore 则像一个临时的收纳盒,暂存数据。
在 Memstore 中,数据会进行排序,以便后续的处理。完成写入操作后,HRegionServer 会向客户端发送 ack,表示写入成功。当 Memstore 中的数据量达到一定阈值时,就会触发刷写操作,将数据持久化到磁盘上,生成 HFile 文件。随着数据的不断写入,会产生多个 HFile 文件,当这些文件达到一定数量或大小阈值时,就会触发合并操作,将多个小的 HFile 文件合并成一个大的 HFile 文件,同时删除那些已经被更新或删除的数据。当 Region 中的数据量持续增长,达到 Region 的分裂阈值时,就会触发 Region 分裂操作,将一个大的 Region 分裂成两个小的 Region,以保证系统的性能和数据的均衡存储。
四、HBase 基础操作实战演练
4.1 环境搭建
4.1.1 准备工作
安装 HBase 之前,需要确保 Java、Hadoop 和 Zookeeper 环境已准备就绪。首先,Java 需安装 1.8 或更高版本,可从 Oracle 官网下载安装包,安装完成后,在终端运行java -version,若显示版本信息,则安装成功。
其次,Hadoop 安装 2.7 或更高版本,从 Apache Hadoop 官网下载二进制包并解压,设置HADOOP_HOME和PATH环境变量,例如export HADOOP_HOME=/path/to/hadoop-3.3.1和export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin。
最后,Zookeeper 用于 HBase 的集群协调,可从 Apache Zookeeper 官网下载并解压。解压后,在conf目录下复制zoo_sample.cfg文件并命名为zoo.cfg,编辑zoo.cfg文件,配置数据存储目录等参数。
4.1.2 下载与安装
从 Apache HBase 官网下载二进制包,如hbase-2.4.9-bin.tar.gz,下载完成后解压到指定目录,如/usr/local/hbase。接着,配置环境变量,在~/.bashrc或~/.bash_profile文件中添加export HBASE_HOME=/usr/local/hbase和export PATH=$PATH:$HBASE_HOME/bin,执行source ~/.bashrc或source ~/.bash_profile使环境变量生效。
在hbase-2.4.9/conf目录下,有几个关键的配置文件需要修改。在hbase-env.sh文件中,配置 Java 环境,如export JAVA_HOME=/path/to/java ;在hbase-site.xml文件中,配置 HBase 的运行参数,如hbase.rootdir指定 HBase 在 HDFS 中的根目录,hbase.zookeeper.quorum配置 Zookeeper 集群的主机名,hbase.zookeeper.property.clientPort指定 Zookeeper 监听的端口。
4.1.3 启动与验证
启动 Hadoop,在终端运行start-dfs.sh和start-yarn.sh,确保 Hadoop 正常启动。然后,在 HBase 目录中启动 HBase,运行./bin/start-hbase.sh。使用./bin/hbase shell命令进入 HBase Shell,如果出现 HBase Shell 的提示,则说明 HBase 已启动成功。在 HBase Shell 中,运行status命令,可查看 HBase 集群的状态信息,如集群是否正常运行、RegionServer 的数量等。
4.2 基本操作示例
4.2.1 创建表
使用 HBase Shell 创建表,示例命令为create 'users', 'info',该命令创建了名为users的表,包含一个列族info。若使用 Java API 创建表,示例代码如下:
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.TableDescriptor;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.util.Bytes;
public class CreateTableExample {
public static void main(String[] args) throws Exception {
// 获取HBase配置
Configuration conf = HBaseConfiguration.create();
// 获取HBase Admin实例
HBaseAdmin admin = new HBaseAdmin(conf);
// 创建表
TableDescriptor tableDescriptor = new TableDescriptor(Bytes.toBytes("my_table"));
HColumnDescriptor columnDescriptor = new HColumnDescriptor(Bytes.toBytes("my_column_family"));
tableDescriptor.addFamily(columnDescriptor);
admin.createTable(tableDescriptor);
// 关闭Admin实例
admin.close();
}
}在这段代码中,首先获取 HBase 配置,然后创建HBaseAdmin实例,接着创建TableDescriptor和HColumnDescriptor对象,分别用于定义表和列族,最后使用admin.createTable(tableDescriptor)方法创建表,并在操作完成后关闭admin实例。
4.2.2 插入数据
使用 HBase Shell 插入数据,示例命令为put 'users', '1001', 'info:name', 'Alice',该命令向users表中插入一条数据,行键为1001,在info列族下,name列限定符对应的值为Alice。若要指定时间戳,可使用命令put 'users', '1001', 'info:age', '30', 1619836800000,其中1619836800000为时间戳。
使用 Java API 插入数据,示例代码如下:
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.util.Bytes;
public class InsertDataExample {
public static void main(String[] args) throws Exception {
// 获取HBase配置
Configuration conf = HBaseConfiguration.create();
// 获取HTable实例
HTable table = new HTable(conf, "my_table");
// 创建Put对象
Put put = new Put(Bytes.toBytes("row1"));
put.add(Bytes.toBytes("my_column_family"), Bytes.toBytes("column1"), Bytes.toBytes("value1"));
// 插入数据
table.put(put);
// 关闭HTable实例
table.close();
}
}在这段代码中,先获取 HBase 配置和HTable实例,然后创建Put对象,通过put.add方法添加数据,最后使用table.put(put)方法将数据插入表中,并关闭table实例。
4.2.3 查询数据
使用 HBase Shell 查询单行数据,命令为get 'users', '1001',该命令查询users表中行键为1001的数据。若要查询指定列族和列限定符的数据,可使用命令get 'users', '1001', {COLUMN => 'info:name'}。
使用 HBase Shell 进行范围查询,命令为scan 'users', {STARTROW => '1001', ENDROW => '1003'},该命令查询users表中行键在1001(包含)到1003(不包含)之间的数据。还可以通过设置LIMIT参数限制返回的行数,如scan 'users', {LIMIT => 10}表示只返回 10 行数据。
4.2.4 更新数据
使用 HBase Shell 更新数据,通过put命令实现,例如put 'users', '1001', 'info:age', '31',该命令将users表中行键为1001,info列族下age列限定符对应的值更新为31。由于 HBase 中相同行键、列族和列限定符的数据,新插入的数据时间戳会更新,所以新插入的数据会覆盖旧值。
4.2.5 删除数据
使用 HBase Shell 删除指定单元格数据,命令为delete 'users', '1001', 'info:age',该命令删除users表中行键为1001,info列族下age列限定符对应的单元格数据。若要删除整行数据,命令为deleteall 'users', '1001',该命令删除users表中行键为1001的整行数据。
五、HBase 应用场景与优势展示
5.1 应用场景举例
5.1.1 大数据分析
在大数据分析领域,HBase 处理大规模数据集实时查询和分析时优势显著。以电商巨头阿里巴巴为例,在“双十一”购物狂欢节期间,平台会产生海量的交易数据,包括用户购买记录、浏览行为、商品信息等。这些数据量巨大,传统数据库难以快速处理和分析。阿里巴巴将这些数据存储在 HBase 中,利用 HBase 基于列存储的特性,能够快速定位和查询相关数据。通过与 MapReduce、Spark 等大数据分析工具集成,对这些数据进行实时分析,为商家提供销售趋势分析、用户行为洞察等服务,帮助商家优化商品策略和运营方案;同时,也为用户提供个性化的商品推荐,提升用户购物体验。据统计,在“双十一”期间,HBase 能够支持每秒数百万次的读写操作,确保了数据分析的实时性和准确性。
5.1.2 日志处理
对于大规模日志数据的收集、存储和分析,HBase 是理想之选。许多互联网公司每天都会产生海量的日志数据,如用户访问日志、系统操作日志等。这些日志数据对于公司了解用户行为、系统性能以及排查问题至关重要。以搜索引擎公司百度为例,百度每天要处理数十亿次的用户搜索请求,产生大量的搜索日志。百度使用 HBase 存储这些日志数据,通过合理设计行键,如将时间戳和用户 ID 组合作为行键,方便按时间和用户维度进行查询和分析。借助 HBase 的高并发读写能力,能够快速存储和检索日志数据。百度利用 Hive、Pig 等工具对 HBase 中的日志数据进行进一步处理和分析,挖掘用户的搜索偏好、地域分布等信息,为搜索引擎的优化和广告投放提供有力支持。
5.1.3 物联网数据管理
随着物联网技术的飞速发展,大量的物联网设备不断产生数据,HBase 在存储和处理这些数据方面发挥着重要作用。以智能城市项目为例,城市中的交通传感器、环境监测设备、智能电表等各种物联网设备每天都会产生海量的数据。这些数据具有高频写入、时间序列性强、大规模并发等特点。HBase 的水平扩展性使其可以轻松应对数据量的不断增长,通过增加 Region Server 来提升存储容量和处理能力;其高吞吐量和低延迟的特性,能够快速处理大量设备同时上传的数据;独特的列族设计非常适合时间序列数据的存储和检索,通过合理设计行键,如将设备 ID 和时间戳组合,能够高效地查询某个设备在特定时间段内的数据。在智能城市项目中,HBase 帮助城市管理者实时监测交通流量、环境指标等,为城市的智能化管理和决策提供数据支持。
5.1.4 实时数据处理
在实时读写操作场景中,HBase 表现出色,广泛应用于实时监控、在线分析等领域。以股票交易系统为例,股票价格实时波动,交易数据瞬息万变,对数据的实时读写要求极高。HBase 凭借其毫秒级的读写响应时间,能够实时存储股票交易数据,包括股票价格、成交量、买卖盘信息等。投资者可以通过交易系统实时查询股票的最新价格和交易情况,进行快速的交易决策;同时,金融机构也可以利用 HBase 对交易数据进行实时分析,监控市场动态,防范金融风险。
5.2 优势总结
5.2.1 高扩展性
HBase 通过水平扩展来支持海量数据存储和高并发访问,展现出强大的扩展性。当数据量不断增长时,只需简单地添加 Region Server 节点,就能增加系统的存储容量和处理能力。这是因为 HBase 将数据划分为多个 Region,每个 Region 由一个 Region Server 负责管理。随着节点的增加,Region 会被自动分配到新的节点上,实现负载均衡。在一个拥有数千个节点的 HBase 集群中,可以轻松存储 PB 级别的数据,并支持每秒数百万次的并发读写操作,满足了大型互联网公司和企业对海量数据处理的需求。
5.2.2 高性能
HBase 在实现高性能读写方面有诸多关键因素。基于内存的数据访问是其高性能的重要保障,数据首先会被写入内存中的 MemStore,内存的读写速度远快于磁盘,大大减少了数据写入的延迟。在读取数据时,如果数据在 MemStore 中,也能快速返回。HBase 采用了数据压缩技术,如 Snappy、Gzip 等,减少了数据在磁盘上的存储体积,降低了磁盘 I/O 操作,提高了数据读取效率;同时,通过精心设计的缓存机制,如 Block Cache,将频繁访问的数据块缓存起来,进一步提升了查询性能。在处理大规模数据时,HBase 基于行键的有序存储和快速索引机制,使得查询操作能够快速定位到目标数据,实现高效的读写。
5.2.3 灵活的数据模型
HBase 的无模式特点使其在应对不同数据结构时非常灵活,创建表时只需定义列族,无需预先定义所有列,后续可以根据实际需求动态添加列,这为数据的存储和管理提供了极大的便利。列族存储方式将相关列的数据存储在一起,不仅提高了存储效率,还方便了对同一列族数据的批量操作。数据多版本特性,每个单元格的数据可以有多个版本,通过时间戳来区分,在需要保留数据历史版本的场景中,如数据回溯、审计等,发挥着重要作用。在存储用户操作记录时,可以通过时间戳记录用户每次操作的内容,方便后续查询和分析。
5.2.4 与 Hadoop 生态集成
HBase 与 Hadoop 生态系统中的其他组件,如 HDFS、MapReduce 等无缝集成,在大数据处理流程中展现出协同优势。HBase 将数据存储在 HDFS 上,利用 HDFS 的分布式存储和高可靠性,确保数据的安全存储和持久化;与 MapReduce 集成后,HBase 可以利用 MapReduce 强大的计算能力对数据进行批量处理和分析,实现复杂的数据处理任务,如数据挖掘、机器学习等。在一个电商大数据分析项目中,数据首先通过 Flume 等工具收集并存储到 HBase 中,然后利用 MapReduce 对 HBase 中的数据进行分析,生成销售报表、用户画像等,最后将分析结果存储回 HBase 或其他存储系统中,供业务系统使用,整个过程高效流畅,充分体现了 HBase 与 Hadoop 生态集成的优势。
六、结语
HBase 作为大数据领域的重要基石,以其独特的数据模型、强大的架构和卓越的性能,在海量数据存储与实时处理的舞台上独领风骚。通过深入学习 HBase 的核心概念、架构原理和基础操作,我们领略到它在应对大数据挑战时的从容与高效。无论是大数据分析、日志处理,还是物联网数据管理和实时数据处理等场景,HBase 都展现出无可替代的优势,为企业和开发者提供了强大的数据处理能力。
然而,HBase 的世界远不止于此,它还有更多的高级特性和优化技巧等待我们去探索。希望大家能以本文为起点,在实际项目中不断实践和总结,持续深入学习 HBase,充分挖掘它的潜力,为大数据开发工作打下坚实的基础,在大数据的广阔天地中创造更多的价值。