一、论文

1.1、论文基本信息
标题:Deep Residual Learning for Image Recognition
作者:Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun
单位:Microsoft Research
会议:CVPR 2016
主要贡献:提出了一种深度残差学习框架(Residual Learning Framework),有效解决了深度神经网络训练中的退化问题(Degradation Problem),使得可以训练更深的神经网络,并在图像识别任务中取得了显著的性能提升。
1.2、主要内容
1.2.1、退化问题(Degradation Problem)
随着网络深度的增加,模型的训练误差和测试误差都会增加,这种现象被称为退化问题。 退化问题不是由过拟合引起的,而是由于深度网络难以优化所致。
1.2.2、残差学习框架(Residual Learning Framework)
核心思想:将网络层学习的目标从原始的映射函数改为原始映射函数和输入的差,即残差映射函数。
残差块(Residual Block):通过shortcut连接将输入直接加到某些层(通常是两到三层)的输出上。
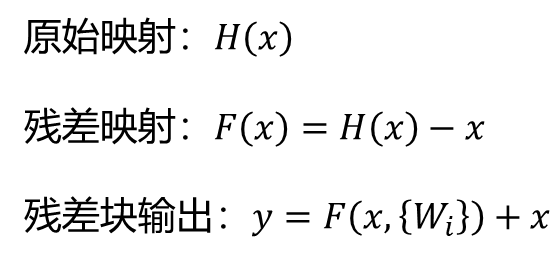
1.2.3、网络结构
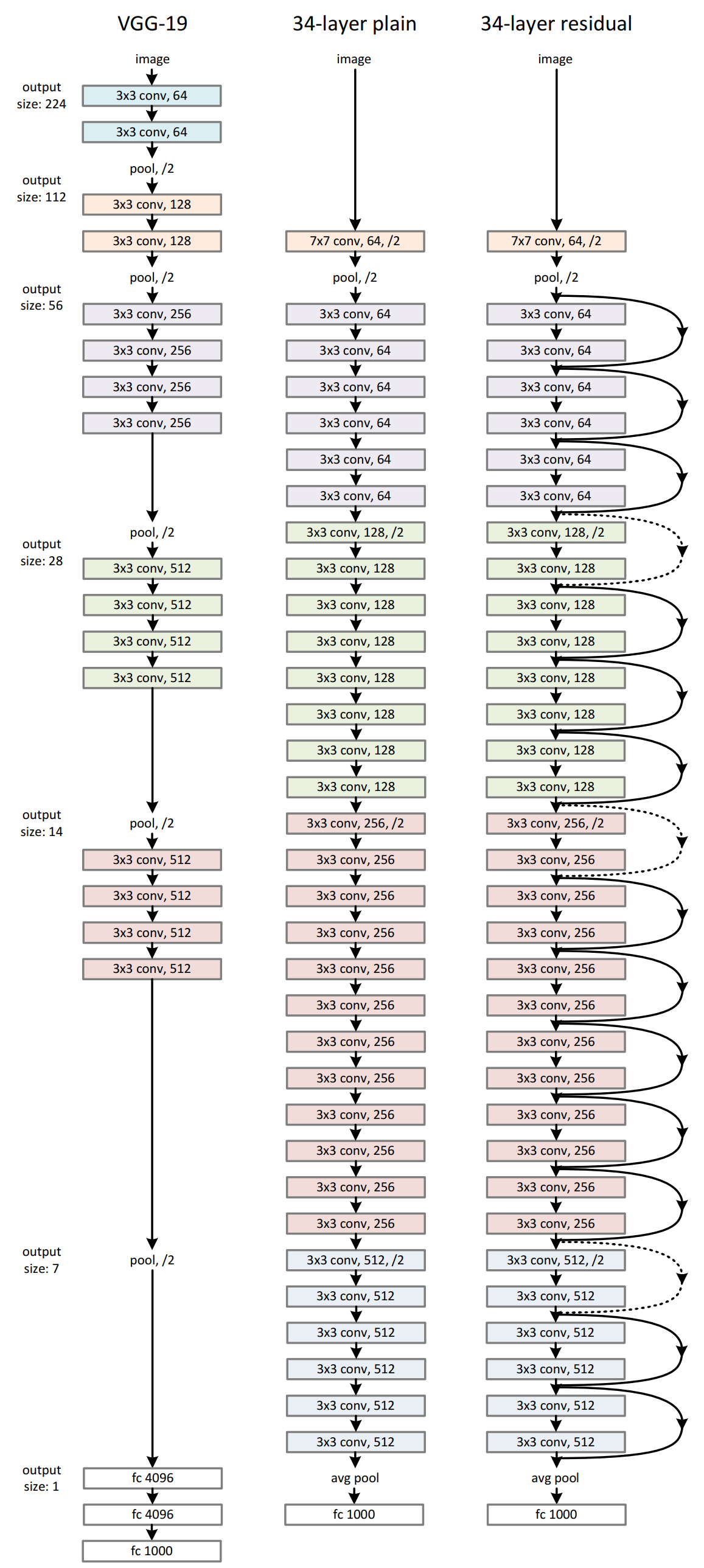
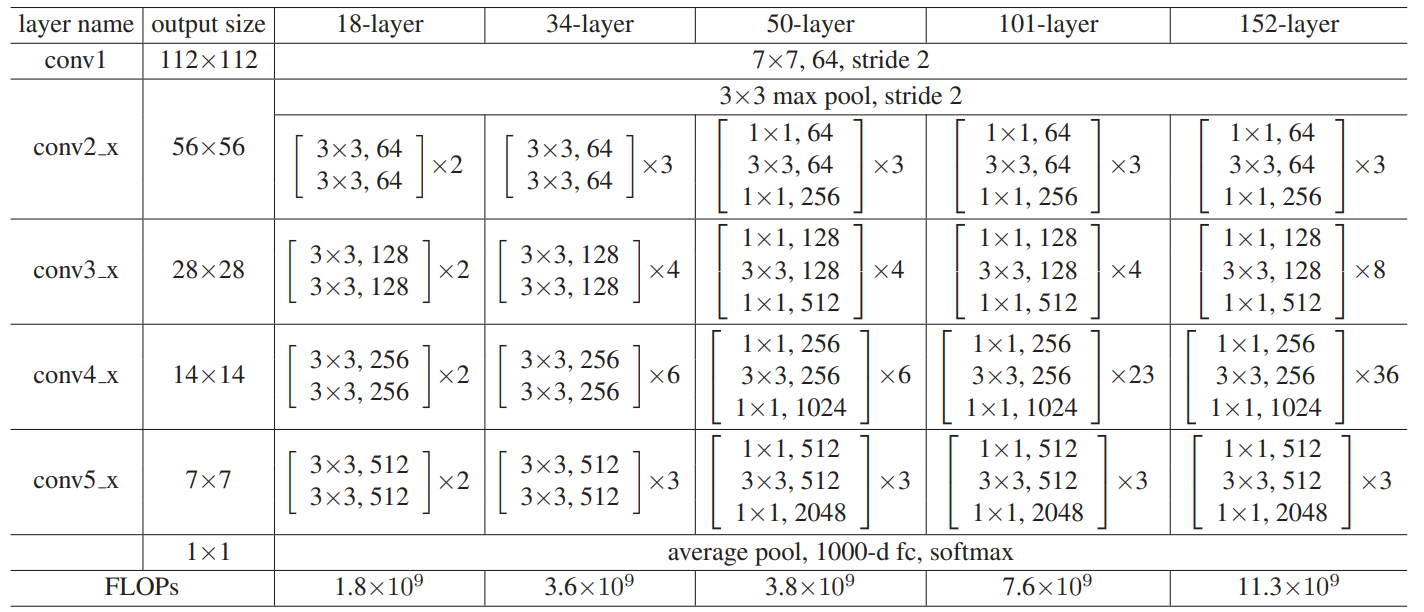
提出了一种基于残差学习的深度卷积神经网络——ResNet。 设计了18层、34层、50层、101层、152层等不同深度的ResNet,并通过实验验证了其有效性。 ResNet-152是当时ImageNet上最深的网络结构。
1.2.4、实验结果
在ImageNet分类任务上,ResNet取得了显著的成果,获得了ILSVRC 2015分类任务的第一名。 在COCO目标检测数据集上,ResNet也取得了28%的相对提升。
实验结果表明,ResNet能够有效解决退化问题,并且能够通过增加网络深度来提高性能。
1.3、作用
解决了深度神经网络的退化问题,使得训练更深的网络成为可能。
提高了图像识别的准确率,在多个基准数据集上取得了state-of-the-art的结果。
推动了深度学习的发展,为后续的计算机视觉研究提供了新的思路和方法。
1.4、影响
ResNet是深度学习领域的一项重大突破,对后续的深度学习研究产生了深远的影响。
许多后续的网络结构,如DenseNet、MobileNet等,都借鉴了ResNet的思想。
ResNet被广泛应用于各种计算机视觉任务,如图像分类、目标检测、语义分割等。
1.5、优点
解决了退化问题,可以训练非常深的网络。
网络性能好,显著提高了图像识别的准确率。
结构简洁,易于实现和扩展。
1.6、缺点
shortcut连接方式较为简单,可能不是最优的选择。
计算效率有待进一步优化,虽然比VGG网络计算量小,但仍然较大。
论文地址:
二、ResNet
2.1、网络的基本介绍
ResNet(“残差网络”的简称)是一种深度神经网络,由Microsoft研究团队于2015年提出。它在当时的ImageNet 比赛获得了图像分类第一名,目标检测第一名,在COCO数据集目标检测第一名,图像分割第一名。
ResNet的主要特点是采用了残差学习机制。在传统的神经网络中,每一层的输出都是直接通过一个非线性激活函 数得到的。但在ResNet中,每一层的输出是通过一个“残差块”得到的,该残差块包含了一个快捷连接 (shortcut)和几个卷积层。这样,在训练过程中,每一层只需要学习残差(即输入与输出之间的差异),而不 是所有的信息。这有助于防止梯度消失和梯度爆炸的问题,从而使得网络能够训练得更深。
ResNet的网络结构相对简单,并且它的训练速度也比GoogLeNet快。这使得ResNet成为了在许多计算机视觉任 务中的首选模型。
ResNet的主要优点是具有非常深的层数,可以达到1000多层,但仍然能够高效地训练。这是通过使用残差连接来 实现的,这种连接允许模型学习跨越多个层的残差,而不是直接学习每一层的输出。这使得ResNet能够更快地收 敛,并且能够更好地泛化到新的数据集,ResNet论文中共提出了五种结构,分别是ResNet-18,ResNet-34, ResNet-50,ResNet-101,ResNet-152。
2.2、 更深的网络层数
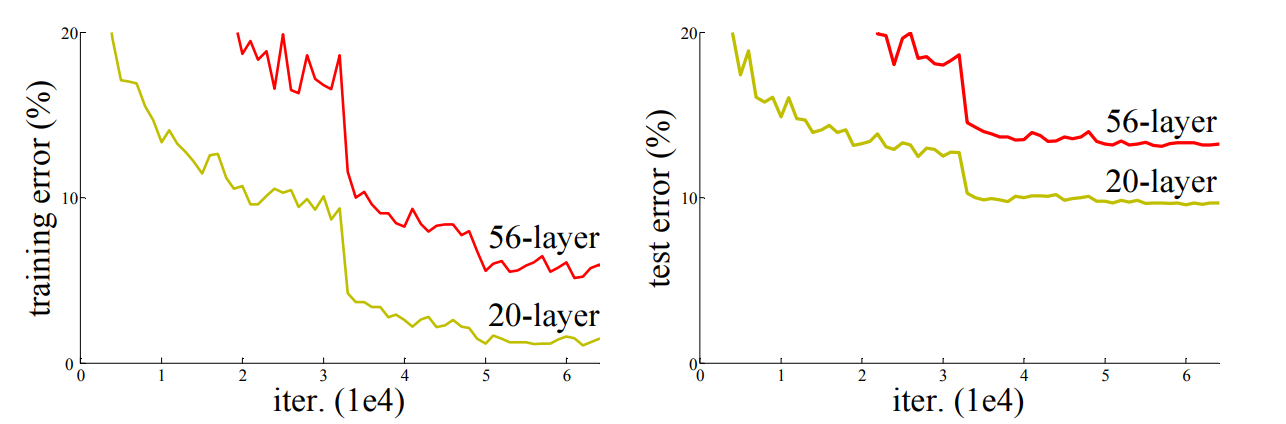
上图都是直接堆叠神经网络的结果,在左侧图中,黄色线是训练过程中20层网络的训练损失曲线,红色线是训练 过程中56层网络的训练损失曲线,理论上讲,网络深可以带来更小的损失,但是实时恰恰相反,56层的错误率要 高于20层的错误率。
主要有两个原因:
1. 梯度消失或梯度爆炸:例如在一个网络中,每一层的损失梯度的值都小于1,那么连续的链式法则之下,每向 前传播一次,都要乘以一个小于1的误差梯度,那么如果网络越深,在经过非常多的前向传播次数之后,那么 梯度越来越小,直到接近于0,这就是梯度消失。但是如果每一层的损失梯度的值都大于1,那么网络越深,在 经过非常多的前向传播次数之后,那么梯度越来越大,导致梯度爆炸。但是误差梯度肯定不会一直是1或者是 和1非常接近的数值,所以这种情况发生是非常普遍的,所以一般通过数据标准化处理,权重初始化等操作进 行抑制,但网络太深依然很难很好的抑制,当然Relu也可以抑制梯度消失问题,但是Relu可能会导致原始特征 不可逆损失,导致下一个问题,即网络退化。
2. degradation problem:直译就是退化问题,随着网络层数的增多,训练集loss逐渐下降,然后趋于饱和,当 再增加网络深度,训练集loss反而会增大。注意这并不是过拟合,因为在过拟合中训练loss是一直减小的。
用残差结构(残差结构在下一小节会详细介绍)进行网络组合时,可以很明显的解决这个问题
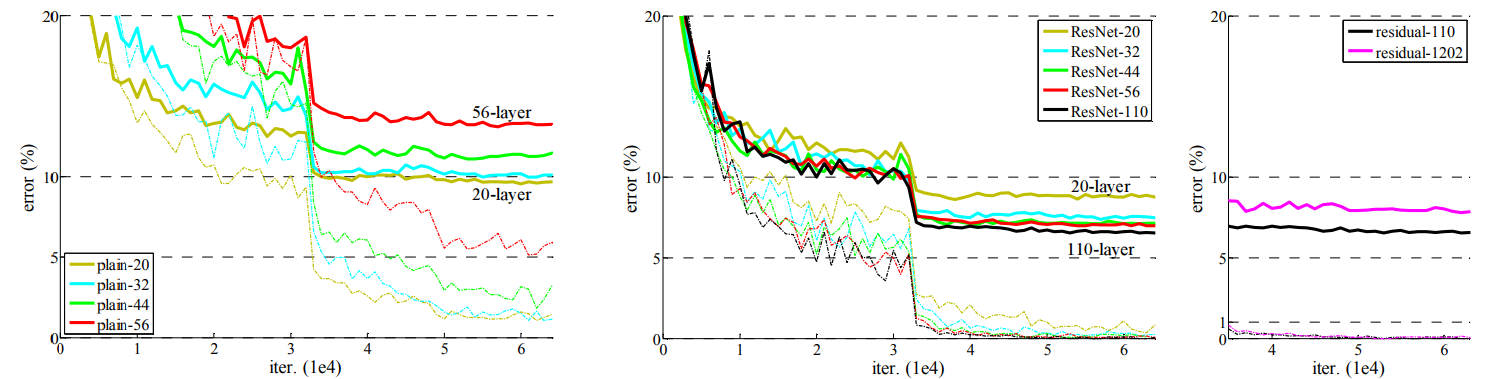
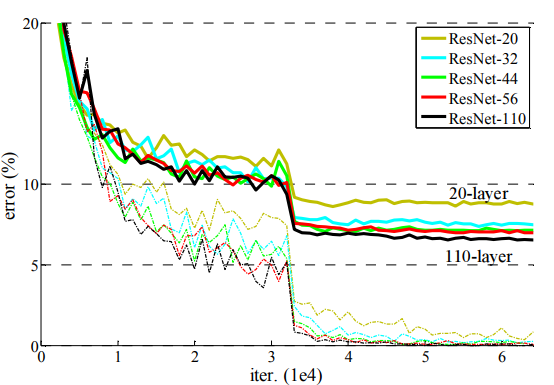
在使用残差结构后,从20层,到110层,错误率都是逐步在降低,文章讲残差网络对 degradation problem是有抑制作用的,还有下下小节讲到的Batch Normalization是对解决梯度消失或者梯度爆 炸的抑制起到了作用,但是网络退化的一部分原因也是因为梯度消失训练不动了,在使用残差网络之后,模型内 部得复杂度降低,所以抑制了退化问题。
2.3、 Residual结构
Residual结构是残差结构,在文章中给了两种不同的残差结构,在ResNet-18和ResNet-34中,用的如下图中左侧 图的结构,在ResNet-50、ResNet-101和ResNet-152中,用的是下图中右侧图的结构。
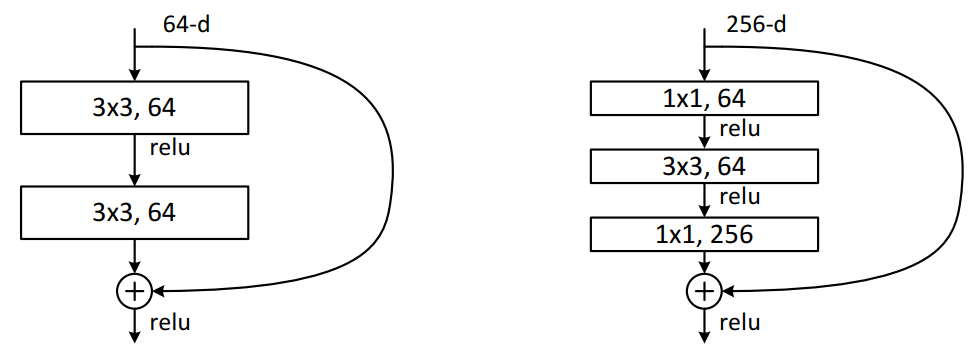
在上图左侧图可以看到输入特征矩阵的channels是64,经过一个3x3的卷积核卷积之后,要进行Relu激活函数的激活,再经过一个3x3的卷积核进行卷积,但是在这之后并没有直接经过激活函数进行激活。并且可以看到,在主 分支上有一个圆弧的线从输入特征矩阵直接连到了一个加号,这个圆弧的线是shortcut(捷径分支),它直接将 输入特征矩阵加到经过第二次3x3的卷积核卷积之后的输出特征矩阵,注意,这里描述的是加,而不是叠加或者拼 接,也就是说是矩阵对应维度位置进行一个和法运算,意味着主分支的输出矩阵和shortcut的输出矩阵的shape必 须相同,这里包括宽、高、channels,在相加之后,再经过Relu激活函数进行激活。
在上图右侧图可以看到输入特征矩阵的channels是256,要先经过一个1x1的卷积,之前在GoogLeNet提到过, 1x1的卷积是为了维度变换,所以这里也是先用1x1的卷积进行降维到64,然后再使用3x3的卷积进行特征提取, 提取完成后,在通过1x1的卷积进行升维到256,之后得到的输出矩阵再和经过shortcut的输入矩阵进行对应维度 位置的加法运算,在相加之后,再经过Relu激活函数进行激活。
可以看到上图中shortcut有实线和虚线部分,实现部分就是普通的shortcut,可以看到虚线部分不仅仅有 channels变化,还有特征矩阵的宽和高变化,虚线部分一个处理来让主分支的输出特征矩阵和shortcut的输出特 征矩阵保持一致 。
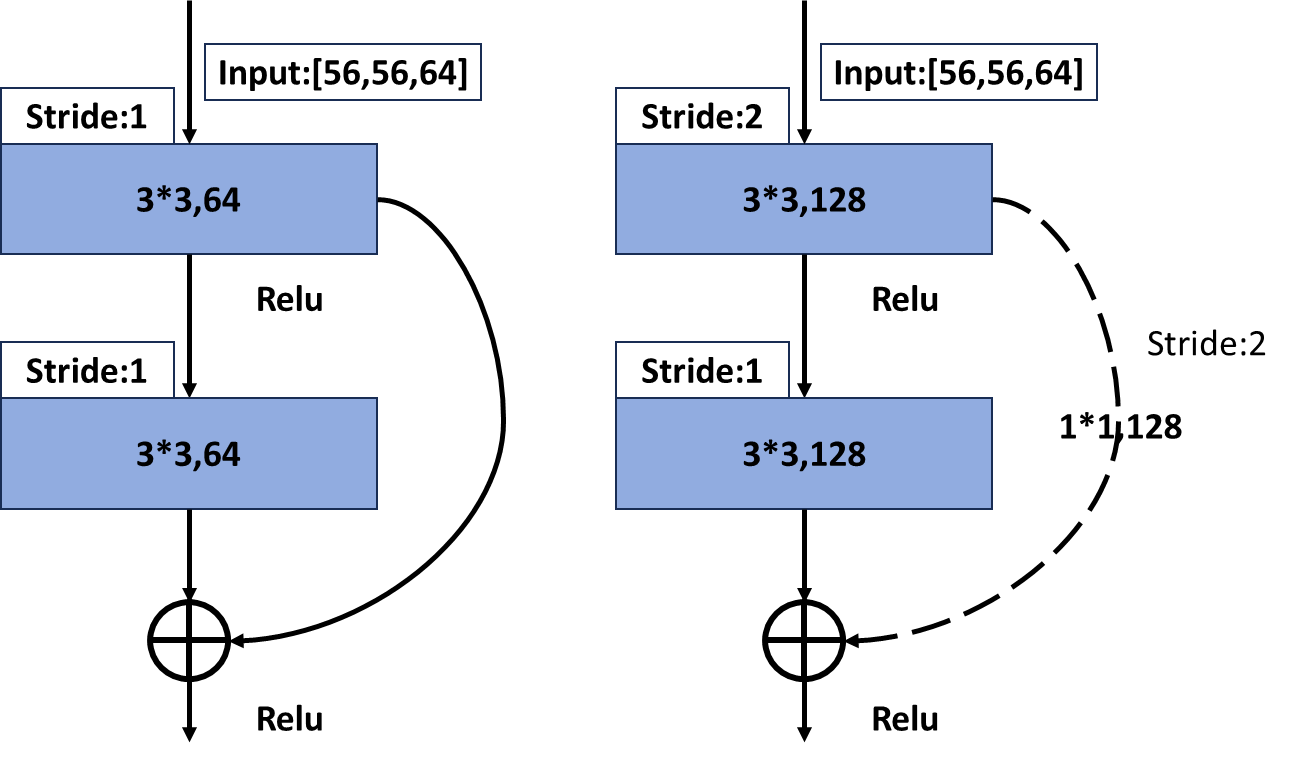
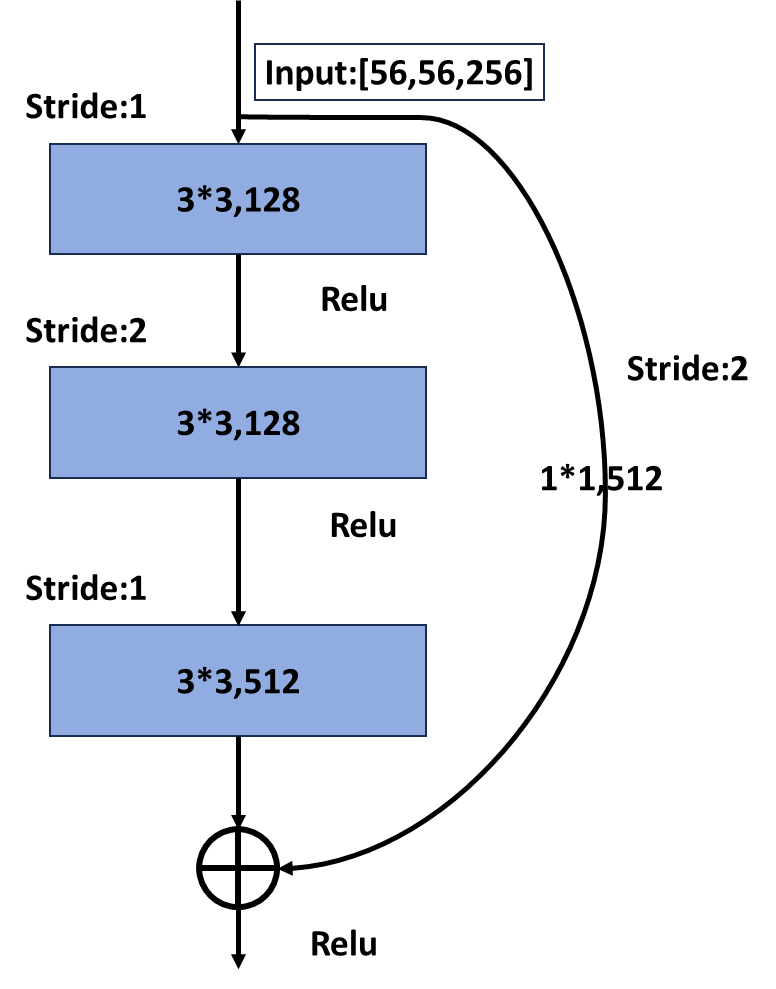
从上图左侧图可以看到,当主分支的输入特征矩阵和输出特征矩阵的shape一致时,输入特征矩阵可以经过 shortcut得到输出特征矩阵直接与主分支的输出特征矩阵进行加法运算,但是上图右侧图主分支上由于步长=2, 导致矩阵的宽和高都减半了,同时由于第一个卷积核的个数是128,导致channels从64升到了128,从而 channels也不一样了,所以主分支的输出特征矩阵是[28,28,128],那么如果将shortcut分支上加一个卷积运算, 卷积核个数为128,步长为2,那么经过shortcut分支的输出矩阵也同样为[28,28,128],那么两个输出矩阵又可以 进行相加了。

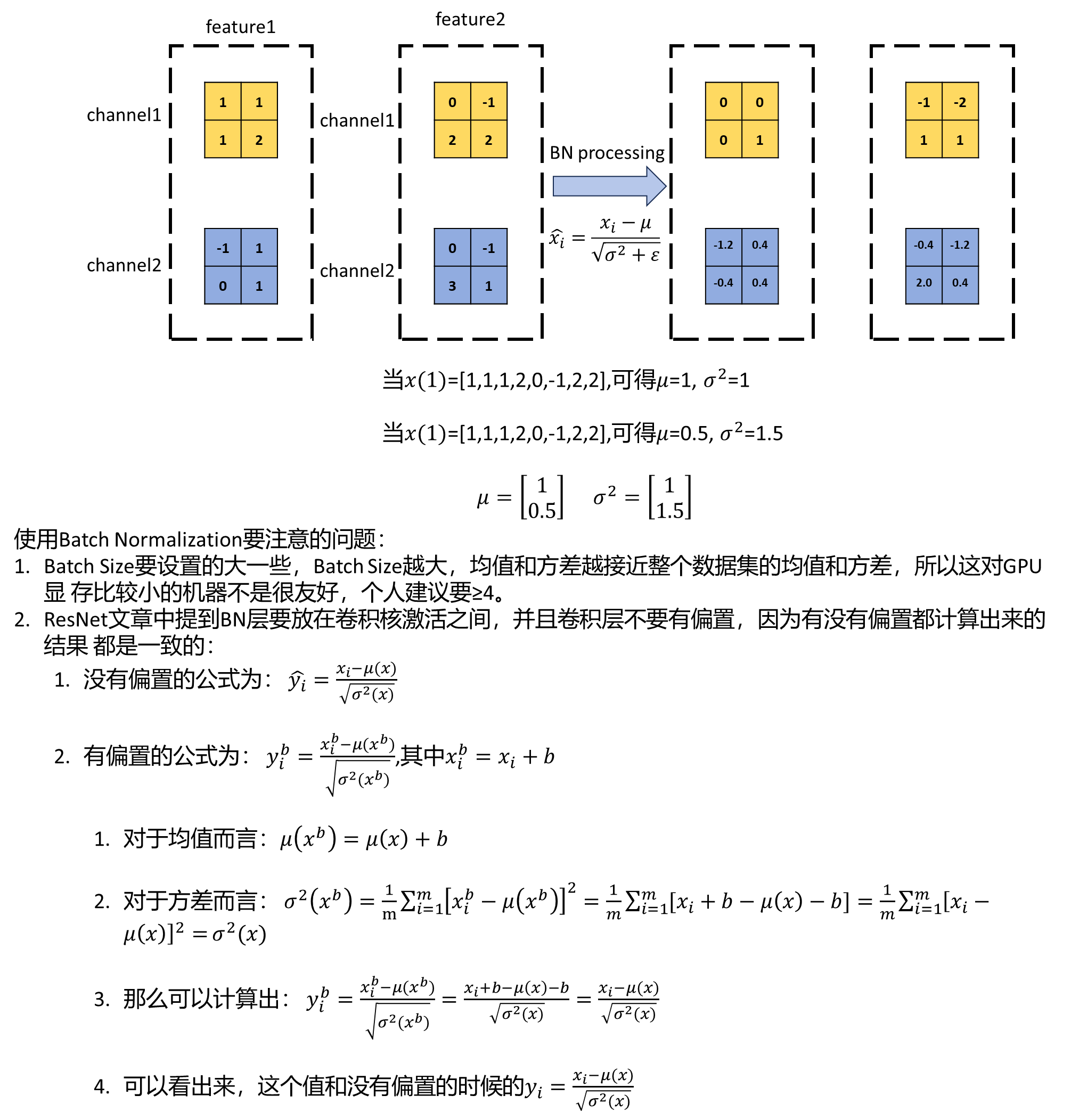
2.4、Batch Normalization
Batch Normalization的作用是将一个批次(Batch)的特征矩阵的每一个channels计算为均值为0,方差为1的分 布规律。
一般而言,在一个神经网络输入图像之前,会将图像进行预处理,这个预处理可能是标准化处理等手段,由于输 入数据满足某一分布规律,所以会加速网络的收敛。这样在输入第一次卷积的时候满足某一分布规律,但是在输 入第二次卷积时,就不一定满足某一分布规律了,再往后的卷积的输入就更不满足了,那么就需要一个中间商, 让上一层的输出经过它之后能够某一分布规律,Batch Normalization就是这个中间商,它可以让输入的特征矩阵 的每一个channels满足均值为0,方差为1的分布规律。

2.5、网络的结构
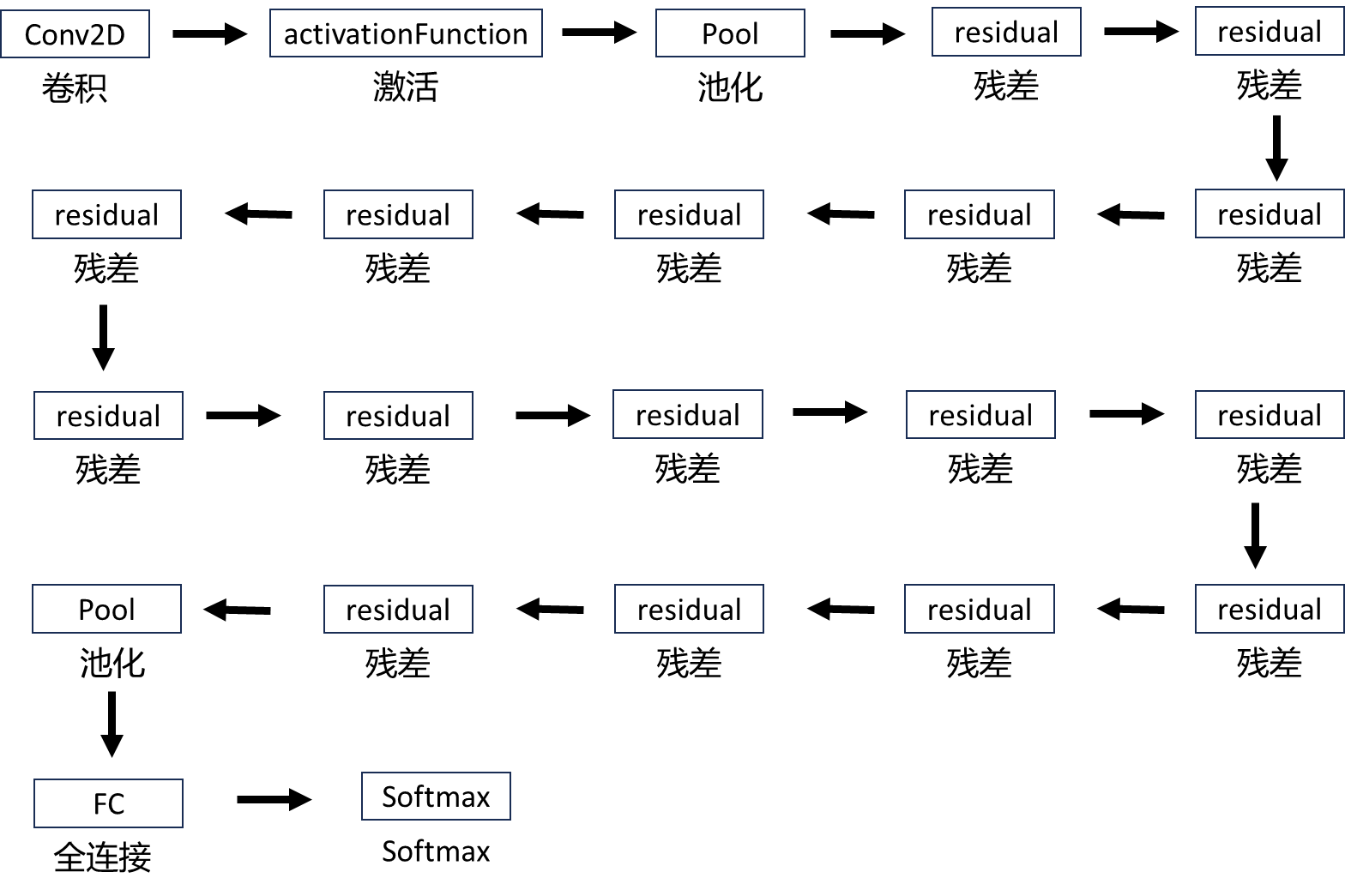
2.6、设计思路
import torch
import torch.nn as nn
from torch import Tensor
from torchsummary import summary
class BasicBlock(nn.Module):
expansion = 1 # 扩张因子,用于调整输入和输出通道数
def __init__(self, inplanes, planes, stride=1, downsample=None):
super().__init__()
# 定义第一个卷积层
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes) # 批归一化
self.relu = nn.ReLU(inplace=True) # 激活函数
# 定义第二个卷积层
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes) # 批归一化
self.downsample = downsample # 可能的降采样操作
self.stride = stride # 步幅
def forward(self, x):
identity = x # 保存输入,用于跳跃连接
out = self.conv1(x) # 通过第一个卷积层
out = self.bn1(out) # 批归一化
out = self.relu(out) # 激活
out = self.conv2(out) # 通过第二个卷积层
out = self.bn2(out) # 批归一化
if self.downsample is not None: # 如果有降采样操作
identity = self.downsample(x) # 对输入进行降采样
out += identity # 跳跃连接
out = self.relu(out) # 激活
return out # 返回输出
class Bottleneck(nn.Module):
"""
注意:原论文中,在虚线残差结构的主分支上,第一个1x1卷积层的步距是2,
第二个3x3卷积层步距是1。但在pytorch官方实现过程中是第一个1x1卷积层的步距是1,
第二个3x3卷积层步距是2,这么做的好处是能够在top1上提升大概0.5%的准确率。
可参考Resnet v1.5 https://ngc.nvidia.com/catalog/model-scripts/nvidia:resnet_50_v1_5_for_pytorch
"""
expansion: int = 4 # 扩张因子,用于调整输入和输出通道数
def __init__(self, inplanes, planes, stride=1, downsample=None, groups=1, base_width=64, dilation=1):
super().__init__()
width = int(planes * (base_width / 64.0)) * groups # 计算卷积的宽度
self.conv1 = nn.Conv2d(inplanes, width, kernel_size=1, stride=1, bias=False)
self.bn1 = nn.BatchNorm2d(width) # 批归一化
self.conv2 = nn.Conv2d(width, width, kernel_size=3, stride=stride, padding=dilation, bias=False)
self.bn2 = nn.BatchNorm2d(width) # 批归一化
self.conv3 = nn.Conv2d(width, planes * self.expansion, kernel_size=1, stride=1, bias=False)
self.bn3 = nn.BatchNorm2d(planes * self.expansion) # 批归一化
self.relu = nn.ReLU(inplace=True) # 激活函数
self.downsample = downsample # 可能的降采样操作
self.stride = stride # 步幅
def forward(self, x: Tensor) -> Tensor:
identity = x # 保存输入,用于跳跃连接
out = self.conv1(x) # 通过第一个卷积层
out = self.bn1(out) # 批归一化
out = self.relu(out) # 激活
out = self.conv2(out) # 通过第二个卷积层
out = self.bn2(out) # 批归一化
out = self.relu(out) # 激活
out = self.conv3(out) # 通过第三个卷积层
out = self.bn3(out) # 批归一化
if self.downsample is not None: # 如果有降采样操作
identity = self.downsample(x) # 对输入进行降采样
out += identity # 跳跃连接
out = self.relu(out) # 激活
return out # 返回输出
class ResNet(nn.Module):
def __init__(self, block, layers, num_classes=1000):
super().__init__()
self.inplanes = 64 # 初始通道数
# 定义初始卷积层
self.conv1 = nn.Conv2d(3, self.inplanes, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(self.inplanes) # 批归一化
self.relu = nn.ReLU(inplace=True) # 激活函数
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1) # 最大池化层
self.layer1 = self._make_layer(block, 64, layers[0]) # 第一层
self.layer2 = self._make_layer(block, 128, layers[1], stride=2) # 第二层
self.layer3 = self._make_layer(block, 256, layers[2], stride=2) # 第三层
self.layer4 = self._make_layer(block, 512, layers[3], stride=2) # 第四层
self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) # 自适应平均池化
self.fc = nn.Linear(512 * block.expansion, num_classes) # 全连接层
def _make_layer(self, block, planes, blocks, stride=1):
downsample = None # 初始化降采样层
# 如果需要降采样
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes * block.expansion),
)
layers = []
layers.append(
block(self.inplanes, planes, stride, downsample) # 添加块
)
self.inplanes = planes * block.expansion # 更新输入通道数
for _ in range(1, blocks): # 添加后续的块
layers.append(
block(self.inplanes, planes)
)
return nn.Sequential(*layers) # 返回层的序列
def forward(self, x):
x = self.conv1(x) # 通过初始卷积层
x = self.bn1(x) # 批归一化
x = self.relu(x) # 激活
x = self.maxpool(x) # 池化
x = self.layer1(x) # 通过第一层
x = self.layer2(x) # 通过第二层
x = self.layer3(x) # 通过第三层
x = self.layer4(x) # 通过第四层
x = self.avgpool(x) # 通过自适应平均池化
x = torch.flatten(x, 1) # 展平张量
x = self.fc(x) # 通过全连接层
return x # 返回输出
# 定义不同版本的ResNet
def resnet18(num_classes=1000):
# https://download.pytorch.org/models/resnet18-f37072fd.pth
return ResNet(BasicBlock, [2, 2, 2, 2], num_classes=num_classes)
def resnet34(num_classes=1000):
# https://download.pytorch.org/models/resnet34-333f7ec4.pth
return ResNet(BasicBlock, [3, 4, 6, 3], num_classes=num_classes)
def resnet50(num_classes=1000):
# https://download.pytorch.org/models/resnet50-19c8e357.pth
return ResNet(Bottleneck, [3, 4, 6, 3], num_classes=num_classes)
def resnet101(num_classes=1000):
# https://download.pytorch.org/models/resnet101-63fe2227.pth
return ResNet(Bottleneck, [3, 4, 23, 3], num_classes=num_classes)
def resnet152(num_classes=1000):
# https://download.pytorch.org/models/resnet152-394f9c45.pth
return ResNet(Bottleneck, [3, 8, 26, 3], num_classes=num_classes)
if __name__ == '__main__':
# model = resnet18(num_classes=3)
# model = resnet34(num_classes=3)
# model = resnet50(num_classes=3)
# model = resnet101(num_classes=3)
model = resnet152(num_classes=3) # 创建ResNet152模型
print(summary(model, (3, 224, 224))) # 打印模型总结from torchvision import models
from torchsummary import summary
resnet_models = {
"resnet18": models.resnet18(pretrained=False),
"resnet34": models.resnet34(pretrained=False),
"resnet50": models.resnet50(pretrained=False),
"resnet101": models.resnet101(pretrained=False),
"resnet152": models.resnet152(pretrained=False),
}
'''
当pretrained=True是会自动下载预训练模型
'''
for name, model in resnet_models.items():
print(summary(model,(3,244,244)))