4、基于策略梯度的深度强化学习算法
策略梯度算法的原理是使用一个策略网络来拟合具体的策略概率分布Π(a|s),使得在这个概率分布下,获得的奖励尽可能多。
1)策略梯度蒙特卡洛算法(REINFORCE)
核心思想
REINFORCE是一种经典的 策略梯度蒙特卡洛算法 ,属于无模型(Model-Free)、同策略(On-Policy)的强化学习方法。其核心思想是通过直接优化策略参数来最大化期望累积回报,采用蒙特卡洛采样估计策略梯度。
算法步骤
- 从初始状态s0开始,根据当前策略Π(θ)采样得到一条轨迹τ=(s0,a0,r0,s1,a1,r1,⋯,sT,aT,rT)
- 计算轨迹τ的累积回报
- 计算策略梯度的无偏估计
其中N是采样轨迹的数量。
- 使用随机梯度上升法更新策略参数θ,即
其中 α是学习率。
特点
- 优点:算法结构简单,直接优化策略,无需估计价值函数,适用于随机性策略。
- 缺点:梯度估计方差大,样本效率低,对奖励尺度敏感。
基于离散动作空间的实现代码
#! /usr/bin/env python
import gym
import torch
import torch.nn as nn
import numpy as np
from collections import deque
from torch.distributions import Categorical
import matplotlib as plt
# 策略网络的构造
class PolicyNet(nn.Module):
def __init__(self, state_dim, nacts):
super().__init__()
# 特征提取层
self.featnet = nn.Sequential(
nn.Linear(state_dim, 256),
nn.ReLU(),
nn.Linear(256, 256),
nn.ReLU()
)
# 策略层
self.pnet = nn.Linear(256, nacts)
def forward(self, x):
feat = self.featnet(x)
logits = self.pnet(feat)
return logits
# 动作决策
def act(self, x):
with torch.no_grad():
logits = self(x)
dist = Categorical(logits=logits)
return dist.sample().cpu().item()
class ActionBuffer(object):
def __init__(self, buffer_size):
super().__init__()
self.buffer = deque(maxlen=buffer_size)
def reset(self):
self.buffer.clear()
def push(self, state, action, reward, done):
self.buffer.append((state, action, reward, done))
def sample(self):
# 轨迹采样
state, action, reward, done = \
zip(*self.buffer)
reward = np.array(reward, dtype=np.float32)
# reward = np.stack(reward, 0)
# 计算回报函数
for i in reversed(range(len(reward)-1)):
reward[i] = reward[i] + GAMMA*reward[i+1]
# 减去平均值,提高稳定性
reward = reward - np.mean(reward)
return np.stack(state, 0), np.stack(action, 0), reward, np.stack(done, 0)
def __len__(self):
return len(self.buffer)
def train(buffer, pnet, optimizer):
# 获取训练数据
state, action, reward, _ = buffer.sample()
state = torch.tensor(state, dtype=torch.float32)
action = torch.tensor(action, dtype=torch.long)
reward = torch.tensor(reward, dtype=torch.float32)
# 计算损失函数
logits = pnet(state)
dist = Categorical(logits=logits) #归一化概率
lossp = -(reward*dist.log_prob(action)).mean()
optimizer.zero_grad()
lossp.backward()
optimizer.step()
return lossp.item()
def plot_rewards(all_rewards):
plt.figure(figsize=(10, 5))
plt.plot(all_rewards, label='Episode Rewards')
plt.xlabel('Episode')
plt.ylabel('Reward')
plt.title('Training Rewards')
plt.legend()
plt.grid(True)
plt.show()
def save_model(model, path):
torch.save(model.state_dict(), path)
print(f"Model saved to {path}")
def load_model(model, path):
model.load_state_dict(torch.load(path))
model.eval()
print(f"Model loaded from {path}")
BATCH_SIZE = 16
NSTEPS = 1000000
GAMMA = 0.99
env = gym.make("CartPole-v0", render_mode='human')
buffer = ActionBuffer(BATCH_SIZE)
pnet = PolicyNet(env.observation_space.shape[0], env.action_space.n)
# pnet.cuda()
optimizer = torch.optim.Adam(pnet.parameters(), lr=1e-3)
all_rewards = []
all_losses = []
episode_reward = 0
loss = 0.0
state = env.reset()
for nstep in range(NSTEPS):
print("step========",nstep)
if isinstance(state, tuple):
state=state[0]
state_t = torch.tensor(state, dtype=torch.float32).unsqueeze(0)
action = pnet.act(state_t)
next_state, reward, done, _, _ = env.step(action)
buffer.push(state, action, reward, done)
state = next_state
episode_reward += reward
if done:
state = env.reset()
all_rewards.append(episode_reward)
episode_reward = 0
if done or len(buffer) == BATCH_SIZE:
loss = train(buffer, pnet, optimizer)
buffer.reset()
# 保存最终模型
save_model(pnet, "policy_net_final.pth")
plot_rewards(all_rewards)基于连续动作空间的实现代码
#! /usr/bin/env python
import gym
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
from collections import deque
from torch.distributions import Normal #用于定义正态分布,策略网络输出的动作会采样自该分布
class PolicyNet(nn.Module):
def __init__(self, state_dim, act_dim, act_min, act_max):
super().__init__()
self.state_dim = state_dim
self.act_dim = act_dim
self.featnet = nn.Sequential(
nn.Linear(state_dim, 256),
nn.ReLU(),
nn.Linear(256, 256),
nn.ReLU()
)
self.pnet_mu = nn.Linear(256, act_dim) #输出动作的均值
self.pnet_logs = nn.Parameter(torch.zeros(act_dim)) #输出动作的标准差的对数(log(sigma)),使用 nn.Parameter 使其可训练
self.act_min = act_min
self.act_max = act_max
def forward(self, x):
feat = self.featnet(x)
mu = (self.act_max - self.act_min)*self.pnet_mu(feat).sigmoid() + self.act_min
#将网络输出的均值通过 sigmoid 映射到 [0, 1],再缩放到 [act_min, act_max]
sigma = (F.softplus(self.pnet_logs) + 1e-4).sqrt()
#通过对 log(sigma) 应用 softplus 函数,保证标准差为正,并加上一个很小的值 1e-4 防止数值不稳定。
return mu, sigma
def act(self, x):
with torch.no_grad():
mu, sigma = self(x)
dist = Normal(mu, sigma)
return dist.sample().clamp(self.act_min, self.act_max).squeeze().cpu().item()
#clamp:将动作限制在 [act_min, act_max] 范围内
class ActionBuffer(object):
def __init__(self, buffer_size):
super().__init__()
self.buffer = deque(maxlen=buffer_size)
def reset(self):
self.buffer.clear()
def push(self, state, action, reward, done):
self.buffer.append((state, action, reward, done))
def sample(self):
# 轨迹采样
state, action, reward, done = \
zip(*self.buffer)
reward = np.stack(reward, 0)
# 计算回报函数
for i in reversed(range(len(reward)-1)):
reward[i] = reward[i] + GAMMA*reward[i+1]
# 减去平均值,提高稳定性
reward = reward - np.mean(reward)
return np.stack(state, 0), np.stack(action, 0), reward, np.stack(done, 0)
def __len__(self):
return len(self.buffer)
def train(buffer, pnet, optimizer):
# 获取训练数据
state, action, reward, _ = buffer.sample()
state = torch.tensor(state, dtype=torch.float32)
action = torch.tensor(action, dtype=torch.float32)
reward = torch.tensor(reward, dtype=torch.float32)
# 计算损失函数
mu, sigma = pnet(state)
dist = Normal(mu, sigma)
lossp = -(reward*dist.log_prob(action)).mean()
optimizer.zero_grad()
lossp.backward()
torch.nn.utils.clip_grad_norm_(pnet.parameters(), 50.0)
optimizer.step()
return lossp.item()
BATCH_SIZE = 16
NSTEPS = 1000000
GAMMA = 0.9
env = gym.make("Pendulum-v1", render_mode="human")
buffer = ActionBuffer(BATCH_SIZE)
pnet = PolicyNet(env.observation_space.shape[0], env.action_space.shape[0],
env.action_space.low[0], env.action_space.high[0])
# pnet.cuda()
optimizer = torch.optim.Adam(pnet.parameters(), lr=1e-4)
all_rewards = []
all_losses = []
episode_reward = 0
loss = 0.0
state = env.reset()
for nstep in range(NSTEPS):
if isinstance(state, tuple):
state = state[0]
state_t = torch.tensor(state, dtype=torch.float32).unsqueeze(0)
action = pnet.act(state_t)
action = np.array([action])
next_state, reward, done, _, _ = env.step(action)
buffer.push(state, action, reward, done)
state = next_state
episode_reward += reward
if done:
state = env.reset()
all_rewards.append(episode_reward)
episode_reward = 0
if done or len(buffer) == BATCH_SIZE:
loss = train(buffer, pnet, optimizer)
buffer.reset()2)经典策略梯度算法(VPG)
核心思想
VPG是策略梯度算法的基础形式,与REINFORCE类似,但通常结合基线函数或优势函数来降低方差。
算法步骤
- 采样轨迹:与 REINFORCE 相同,从初始状态开始,根据当前策略采样得到轨迹。
- 估计价值函数:使用函数逼近器(如神经网络)估计状态价值函数V(s)。
- 计算优势函数:A(s, a)=R(s, a)+V(s') - V(s),其中R(s, a)是即时奖励,s'是下一个状态。
- 计算策略梯度:
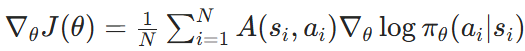
- 更新策略参数:使用随机梯度上升法更新策略参数θ。
特点
- 优点:实现简单,适合作为策略梯度方法的入门。
- 缺点:梯度估计方差大,对学习率敏感,策略更新可能导致性能崩溃。
基于离散动作空间的实现代码
import gym
import torch
import torch.nn as nn
import numpy as np
from collections import deque
from torch.distributions import Categorical
import matplotlib.pyplot as plt
# 策略网络的构造
class PolicyNet(nn.Module):
def __init__(self, state_dim, nacts):
super().__init__()
# 特征提取层
self.featnet = nn.Sequential(
nn.Linear(state_dim, 256),
nn.ReLU(),
nn.Linear(256, 256),
nn.ReLU()
)
# 策略层
self.pnet = nn.Linear(256, nacts)
def forward(self, x):
feat = self.featnet(x)
logits = self.pnet(feat)
return logits
# 动作决策
def act(self, x):
with torch.no_grad():
logits = self(x)
dist = Categorical(logits=logits)
return dist.sample().cpu().item()
# 价值网络的构造
class ValueNet(nn.Module):
def __init__(self, state_dim):
super().__init__()
self.featnet = nn.Sequential(
nn.Linear(state_dim, 256),
nn.ReLU(),
nn.Linear(256, 256),
nn.ReLU()
)
self.vnet = nn.Linear(256, 1)
def forward(self, x):
feat = self.featnet(x)
value = self.vnet(feat)
return value
class ActionBuffer(object):
def __init__(self, buffer_size):
super().__init__()
self.buffer = deque(maxlen=buffer_size)
def reset(self):
self.buffer.clear()
def push(self, state, action, reward, done, next_state):
self.buffer.append((state, action, reward, done, next_state))
def sample(self):
# 轨迹采样
state, action, reward, done, next_state = \
zip(*self.buffer)
reward = np.array(reward, dtype=np.float32)
state = np.stack(state, 0)
action = np.stack(action, 0)
done = np.stack(done, 0)
next_state = np.stack(next_state, 0)
return state, action, reward, done, next_state
def __len__(self):
return len(self.buffer)
def train(buffer, pnet, vnet, p_optimizer, v_optimizer):
# 获取训练数据
state, action, reward, done, next_state = buffer.sample()
state = torch.tensor(state, dtype=torch.float32)
action = torch.tensor(action, dtype=torch.long)
reward = torch.tensor(reward, dtype=torch.float32)
done = torch.tensor(done, dtype=torch.float32)
next_state = torch.tensor(next_state, dtype=torch.float32)
# 计算价值函数
with torch.no_grad():
value = vnet(state).squeeze()
next_value = vnet(next_state).squeeze()
# 计算优势函数
advantage = reward + (1 - done) * GAMMA * next_value - value
# 计算策略损失
logits = pnet(state)
dist = Categorical(logits=logits)
policy_loss = -(advantage * dist.log_prob(action)).mean()
# 计算价值损失
target_value = reward + (1 - done) * GAMMA * next_value
value_loss = ((vnet(state).squeeze() - target_value) ** 2).mean()
# 更新策略网络
p_optimizer.zero_grad()
policy_loss.backward()
p_optimizer.step()
# 更新价值网络
v_optimizer.zero_grad()
value_loss.backward()
v_optimizer.step()
return policy_loss.item(), value_loss.item()
def plot_rewards(all_rewards):
plt.figure(figsize=(10, 5))
plt.plot(all_rewards, label='Episode Rewards')
plt.xlabel('Episode')
plt.ylabel('Reward')
plt.title('Training Rewards')
plt.legend()
plt.grid(True)
plt.show()
def save_model(model, path):
torch.save(model.state_dict(), path)
print(f"Model saved to {path}")
def load_model(model, path):
model.load_state_dict(torch.load(path))
model.eval()
print(f"Model loaded from {path}")
BATCH_SIZE = 16
NSTEPS = 1000000
GAMMA = 0.99
env = gym.make("CartPole-v0", render_mode='human')
buffer = ActionBuffer(BATCH_SIZE)
pnet = PolicyNet(env.observation_space.shape[0], env.action_space.n)
vnet = ValueNet(env.observation_space.shape[0])
p_optimizer = torch.optim.Adam(pnet.parameters(), lr=1e-3)
v_optimizer = torch.optim.Adam(vnet.parameters(), lr=1e-3)
all_rewards = []
all_policy_losses = []
all_value_losses = []
episode_reward = 0
policy_loss = 0.0
value_loss = 0.0
state = env.reset()
for nstep in range(NSTEPS):
print("step========", nstep)
if isinstance(state, tuple):
state = state[0]
state_t = torch.tensor(state, dtype=torch.float32).unsqueeze(0)
action = pnet.act(state_t)
next_state, reward, done, _, _ = env.step(action)
buffer.push(state, action, reward, done, next_state)
state = next_state
episode_reward += reward
if done:
state = env.reset()
all_rewards.append(episode_reward)
episode_reward = 0
if done or len(buffer) == BATCH_SIZE:
policy_loss, value_loss = train(buffer, pnet, vnet, p_optimizer, v_optimizer)
all_policy_losses.append(policy_loss)
all_value_losses.append(value_loss)
buffer.reset()
# 保存最终模型
save_model(pnet, "policy_net_final.pth")
save_model(vnet, "value_net_final.pth")
plot_rewards(all_rewards)基于连续动作空间的实现代码
import gym
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
from collections import deque
from torch.distributions import Normal
# 策略网络
class PolicyNet(nn.Module):
def __init__(self, state_dim, act_dim, act_min, act_max):
super().__init__()
self.state_dim = state_dim
self.act_dim = act_dim
self.featnet = nn.Sequential(
nn.Linear(state_dim, 256),
nn.ReLU(),
nn.Linear(256, 256),
nn.ReLU()
)
self.pnet_mu = nn.Linear(256, act_dim)
self.pnet_logs = nn.Parameter(torch.zeros(act_dim))
self.act_min = act_min
self.act_max = act_max
def forward(self, x):
feat = self.featnet(x)
mu = (self.act_max - self.act_min) * self.pnet_mu(feat).sigmoid() + self.act_min
sigma = (F.softplus(self.pnet_logs) + 1e-4).sqrt()
return mu, sigma
def act(self, x):
with torch.no_grad():
mu, sigma = self(x)
dist = Normal(mu, sigma)
return dist.sample().clamp(self.act_min, self.act_max).squeeze().cpu().item()
# 价值网络
class ValueNet(nn.Module):
def __init__(self, state_dim):
super().__init__()
self.featnet = nn.Sequential(
nn.Linear(state_dim, 256),
nn.ReLU(),
nn.Linear(256, 256),
nn.ReLU()
)
self.vnet = nn.Linear(256, 1)
def forward(self, x):
feat = self.featnet(x)
value = self.vnet(feat)
return value
class ActionBuffer(object):
def __init__(self, buffer_size):
super().__init__()
self.buffer = deque(maxlen=buffer_size)
def reset(self):
self.buffer.clear()
def push(self, state, action, reward, done, next_state):
self.buffer.append((state, action, reward, done, next_state))
def sample(self):
state, action, reward, done, next_state = zip(*self.buffer)
reward = np.stack(reward, 0)
state = np.stack(state, 0)
action = np.stack(action, 0)
done = np.stack(done, 0)
next_state = np.stack(next_state, 0)
return state, action, reward, done, next_state
def __len__(self):
return len(self.buffer)
def train(buffer, pnet, vnet, p_optimizer, v_optimizer):
state, action, reward, done, next_state = buffer.sample()
state = torch.tensor(state, dtype=torch.float32)
action = torch.tensor(action, dtype=torch.float32)
reward = torch.tensor(reward, dtype=torch.float32)
done = torch.tensor(done, dtype=torch.float32)
next_state = torch.tensor(next_state, dtype=torch.float32)
# 计算价值函数
with torch.no_grad():
value = vnet(state).squeeze()
next_value = vnet(next_state).squeeze()
# 计算优势函数
advantage = reward + (1 - done) * GAMMA * next_value - value
# 计算策略损失
mu, sigma = pnet(state)
dist = Normal(mu, sigma)
policy_loss = -(advantage * dist.log_prob(action)).mean()
# 计算价值损失
target_value = reward + (1 - done) * GAMMA * next_value
value_loss = ((vnet(state).squeeze() - target_value) ** 2).mean()
# 更新策略网络
p_optimizer.zero_grad()
policy_loss.backward()
torch.nn.utils.clip_grad_norm_(pnet.parameters(), 50.0)
p_optimizer.step()
# 更新价值网络
v_optimizer.zero_grad()
value_loss.backward()
v_optimizer.step()
return policy_loss.item(), value_loss.item()
BATCH_SIZE = 16
NSTEPS = 1000000
GAMMA = 0.9
env = gym.make("Pendulum-v1", render_mode="human")
buffer = ActionBuffer(BATCH_SIZE)
pnet = PolicyNet(env.observation_space.shape[0], env.action_space.shape[0],
env.action_space.low[0], env.action_space.high[0])
vnet = ValueNet(env.observation_space.shape[0])
p_optimizer = torch.optim.Adam(pnet.parameters(), lr=1e-4)
v_optimizer = torch.optim.Adam(vnet.parameters(), lr=1e-4)
all_rewards = []
all_policy_losses = []
all_value_losses = []
episode_reward = 0
policy_loss = 0.0
value_loss = 0.0
state = env.reset()
for nstep in range(NSTEPS):
if isinstance(state, tuple):
state = state[0]
state_t = torch.tensor(state, dtype=torch.float32).unsqueeze(0)
action = pnet.act(state_t)
action = np.array([action])
next_state, reward, done, _, _ = env.step(action)
buffer.push(state, action, reward, done, next_state)
state = next_state
episode_reward += reward
if done:
state = env.reset()
all_rewards.append(episode_reward)
episode_reward = 0
if done or len(buffer) == BATCH_SIZE:
policy_loss, value_loss = train(buffer, pnet, vnet, p_optimizer, v_optimizer)
all_policy_losses.append(policy_loss)
all_value_losses.append(value_loss)
buffer.reset()3)置信度区间策略优化算法
为了减少策略梯度的波动,同时尽量提高优势函数比较大的动作的概率,可以考虑再初始策略附近的一个置信区间内对策略进行优化(也就是初始的策略和优化过程中的策略尽量不要偏离过大),让这个策略对应的动作能够尽量增加正的优势函数产生的概率,减少负的优势函数产生的概率。这就是基于置信区间的策略梯度算法,包括置信区间策略优化算法和近端策略优化算法的基本思想。
3.1)置信度区间策略优化(Trust Region Policy Optimization, TRPO)
核心思想
TRPO通过限制新旧策略之间的KL散度来确保策略更新的稳定性,适用于高维连续动作空间。
算法步骤

公式详解








特点
- 优点:通过KL散度约束保证策略更新的稳定性,避免性能崩溃。
- 缺点:实现复杂,计算成本高,需要计算二阶导数。
实现代码
import time
import gym
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.distributions import Categorical
import random
from PIL import Image
from collections import deque
import numpy as np
from scipy.optimize import minimize
class ActorNet(nn.Module):
def __init__(self, img_size, num_actions):
super().__init__()
# 输入图像的形状(c, h, w)
self.img_size = img_size
self.num_actions = num_actions
# 对于Atari环境,输入为(4, 84, 84)
print(img_size[0])
self.featnet = nn.Sequential(
nn.Conv2d(img_size[0], 32, kernel_size=8, stride=4),
nn.ReLU(),
nn.Conv2d(32, 64, kernel_size=4, stride=2),
nn.ReLU(),
nn.Conv2d(64, 64, kernel_size=3, stride=1),
nn.ReLU(),
nn.Flatten(),
)
gain = nn.init.calculate_gain('relu')
self.pnet1 = nn.Sequential(
nn.Linear(self._feat_size(), 512),
nn.ReLU(),
)
self._init(self.featnet, gain)
self._init(self.pnet1, gain)
# 策略网络,计算每个动作的概率
gain = 1.0
self.pnet2 = nn.Linear(512, self.num_actions)
self._init(self.pnet2, gain)
def _feat_size(self):
with torch.no_grad():
x = torch.randn(1, *self.img_size)
x = self.featnet(x).view(1, -1)
return x.size(1)
def _init(self, mod, gain):
for m in mod.modules():
if isinstance(m, (nn.Linear, nn.Conv2d)):
nn.init.orthogonal_(m.weight, gain=gain)
nn.init.zeros_(m.bias)
def forward(self, x):
feat = self.featnet(x)
feat = self.pnet1(feat)
return self.pnet2(feat)
def act(self, x):
with torch.no_grad():
logits = self(x)
m = Categorical(logits=logits).sample().squeeze()
return m.cpu().item()
class CriticNet(nn.Module):
def __init__(self, img_size):
super().__init__()
# 输入图像的形状(c, h, w)
self.img_size = img_size
# 对于Atari环境,输入为(4, 84, 84)
self.featnet = nn.Sequential(
nn.Conv2d(img_size[0], 32, kernel_size=8, stride=4),
nn.ReLU(),
nn.Conv2d(32, 64, kernel_size=4, stride=2),
nn.ReLU(),
nn.Conv2d(64, 64, kernel_size=3, stride=1),
nn.ReLU(),
nn.Flatten()
)
gain = nn.init.calculate_gain('relu')
self.vnet1 = nn.Sequential(
nn.Linear(self._feat_size(), 512),
nn.ReLU()
)
self._init(self.featnet, gain)
self._init(self.vnet1, gain)
# 价值网络,根据特征输出每个动作的价值
gain = 1.0
self.vnet2 = nn.Linear(512, 1)
self._init(self.vnet2, gain)
def _feat_size(self):
with torch.no_grad():
x = torch.randn(1, *self.img_size)
x = self.featnet(x).view(1, -1)
return x.size(1)
def _init(self, mod, gain):
for m in mod.modules():
if isinstance(m, (nn.Linear, nn.Conv2d)):
nn.init.orthogonal_(m.weight, gain=gain)
nn.init.zeros_(m.bias)
def forward(self, x):
feat = self.featnet(x)
feat = self.vnet1(feat)
return self.vnet2(feat).squeeze(-1)
def val(self, x):
with torch.no_grad():
val = self(x).squeeze()
return val.cpu().item()
class ActionBuffer(object):
def __init__(self, buffer_size):
super().__init__()
self.buffer = deque(maxlen=buffer_size)
def reset(self):
self.buffer.clear()
def push(self, state, action, value, reward, done):
self.buffer.append((state, action, value, reward, done))
def sample(self, next_value):
state, action, value, reward, done = \
zip(*self.buffer)
value = np.array(value + (next_value,))
done = np.array(done).astype(np.float32)
reward = np.array(reward).astype(np.float32)
delta = reward + GAMMA * (1 - done) * value[1:] - value[:-1]
rtn = np.zeros_like(delta).astype(np.float32)
adv = np.zeros_like(delta).astype(np.float32)
reward_t = next_value
delta_t = 0.0
for i in reversed(range(len(reward))):
reward_t = reward[i] + GAMMA * (1.0 - done[i]) * reward_t
delta_t = delta[i] + (GAMMA * LAMBDA) * (1.0 - done[i]) * delta_t
rtn[i] = reward_t
adv[i] = delta_t
return np.stack(state, 0), np.stack(action, 0), rtn, adv
def __len__(self):
return len(self.buffer)
class EnvWrapper(object):
def __init__(self, env, num_frames):
super().__init__()
self.env_ = env
self.num_frames = num_frames
self.frame = deque(maxlen=num_frames)
def _preprocess(self, img):
# 预处理数据
img = Image.fromarray(img)
img = img.convert("L")
img = img.crop((0, 30, 160, 200))
img = img.resize((84, 84))
img = np.array(img) / 256.0
return img - np.mean(img)
def reset(self):
obs = self.env_.reset()
if isinstance(obs, tuple):
obs = obs[0]
for _ in range(self.num_frames):
self.frame.append(self._preprocess(obs))
return np.stack(self.frame, 0)
def step(self, action):
obs, reward, done, _, _ = self.env_.step(action)
self.frame.append(self._preprocess(obs))
return np.stack(self.frame, 0), np.sign(reward), done, {}
def render(self):
return self.env_.render()
@property
def env(self):
return self.env_
def flat_grad(grads):
grad_flatten = []
for grad in grads:
grad_flatten.append(grad.reshape(-1))
grad_flatten = torch.cat(grad_flatten)
return grad_flatten
def flat_params(model):
params = []
for param in model.parameters():
params.append(param.data.view(-1))
params_flatten = torch.cat(params)
return params_flatten
def update_model(model, new_params):
index = 0
for param in model.parameters():
param_length = param.numel()
param.data = new_params[index:index + param_length].view(param.size())
index += param_length
def get_kl(old_dist, new_dist, actions):
kl = old_dist.log_prob(actions) - new_dist.log_prob(actions)
return kl.sum(-1, keepdim=True)
def train(buffer, next_value, pnet, vnet, optimizer, delta=0.01):
state, action, rtn, adv = buffer.sample(next_value)
state = torch.tensor(state, dtype=torch.float32)
action = torch.tensor(action, dtype=torch.long)
rtn = torch.tensor(rtn, dtype=torch.float32)
adv = torch.tensor(adv, dtype=torch.float32)
logits = pnet(state)
values = vnet(state)
old_dist = Categorical(logits=logits)
logp0 = old_dist.log_prob(action).detach()
# 策略目标函数
def get_loss(volatile=False):
logits = pnet(state)
new_dist = Categorical(logits=logits)
logp1 = new_dist.log_prob(action)
ratio = torch.exp(logp1 - logp0)
loss = -(ratio * adv).mean()
return loss
# KL散度约束
def get_kl_constraint(volatile=False):
logits = pnet(state)
new_dist = Categorical(logits=logits)
kl = get_kl(old_dist, new_dist, action)
return kl.mean()
# 计算梯度
loss = get_loss()
grads = torch.autograd.grad(loss, pnet.parameters())
flat_grads = flat_grad(grads)
# 计算Fisher信息矩阵向量积
def fisher_vector_product(p):
kl = get_kl_constraint()
# 第一次调用 autograd.grad,设置 retain_graph=True
grads_kl = torch.autograd.grad(kl, pnet.parameters(), create_graph=True, retain_graph=True)
flat_grads_kl = flat_grad(grads_kl)
kl_v = (flat_grads_kl * p.clone().detach().requires_grad_(False)).sum()
# 第二次调用 autograd.grad,同样设置 retain_graph=True
grads_kl_v = torch.autograd.grad(kl_v, pnet.parameters(), retain_graph=True)
flat_grads_kl_v = flat_grad(grads_kl_v).data
return flat_grads_kl_v + 0.1 * p.clone().detach().requires_grad_(False)
# 共轭梯度法求解步长
def conjugate_gradient(Avp, b, nsteps, residual_tol=1e-10):
x = torch.zeros(b.size())
r = b.clone()
p = b.clone()
rdotr = torch.dot(r, r)
for i in range(nsteps):
_Avp = Avp(p)
alpha = rdotr / torch.dot(p, _Avp)
x += alpha * p
r -= alpha * _Avp
new_rdotr = torch.dot(r, r)
beta = new_rdotr / rdotr
p = r + beta * p
rdotr = new_rdotr
if rdotr < residual_tol:
break
return x
step_dir = conjugate_gradient(fisher_vector_product, flat_grads.data, 10)
# 计算步长
shs = 0.5 * (step_dir * fisher_vector_product(step_dir)).sum(0, keepdim=True)
lm = torch.sqrt(shs / delta)
fullstep = step_dir / lm[0]
# 线搜索
old_params = flat_params(pnet)
def linesearch(model, f, x, fullstep, expected_improve_rate, max_backtracks=10, accept_ratio=.1):
fval = f(True).item()
for stepfrac in [.5 ** x for x in range(max_backtracks)]:
xnew = x + stepfrac * fullstep
update_model(model, xnew)
newfval = f(True).item()
actual_improve = fval - newfval
expected_improve = expected_improve_rate * stepfrac
ratio = actual_improve / expected_improve
if ratio > accept_ratio and actual_improve > 0:
return True, xnew
return False, x
expected_improve = (flat_grads * fullstep).sum(0, keepdim=True)
success, new_params = linesearch(pnet, get_loss, old_params, fullstep, expected_improve)
update_model(pnet, new_params)
# 价值迭代
for niter in range(NITERS):
values = vnet(state)
lossv = 0.5 * (rtn - values).pow(2).mean()
vnet.zero_grad()
torch.nn.utils.clip_grad_norm_(vnet.parameters(), 0.5)
lossv.backward()
optimizer.step()
return get_loss().cpu().item()
GAMMA = 0.99
LAMBDA = 0.95
NFRAMES = 4
BATCH_SIZE = 32
NSTEPS = 1000000
REG = 0.01
NITERS = 4
EPS = 0.2
env = gym.make('PongDeterministic-v4', render_mode='human')
env = EnvWrapper(env, NFRAMES)
state = env.reset()
buffer = ActionBuffer(BATCH_SIZE)
pnet = ActorNet((4, 84, 84), env.env.action_space.n)
vnet = CriticNet((4, 84, 84))
# pnet.cuda()
# vnet.cuda()
optimizer = torch.optim.Adam([
{'params': pnet.parameters(), 'lr': 1e-4},
{'params': vnet.parameters(), 'lr': 1e-4},
])
all_rewards = []
all_losses = []
all_values = []
episode_reward = 0
loss = 0.0
state = env.reset()
for nstep in range(NSTEPS):
state_t = torch.tensor(state, dtype=torch.float32).unsqueeze(0)
action = pnet.act(state_t)
value = vnet.val(state_t)
next_state, reward, done, _ = env.step(action)
buffer.push(state, action, value, reward, done)
state = next_state
episode_reward += reward
if done:
state = env.reset()
all_rewards.append(episode_reward)
state_t = torch.tensor(next_state, dtype=torch.float32).unsqueeze(0)
all_values.append(vnet.val(state_t))
episode_reward = 0
if done or len(buffer) == BATCH_SIZE:
with torch.no_grad():
state_t = torch.tensor(next_state, dtype=torch.float32).unsqueeze(0)
next_value = vnet.val(state_t)
# 调用 train 函数进行模型训练
loss = train(buffer, next_value, pnet, vnet, optimizer)
all_losses.append(loss)
buffer.reset()3.2)近端策略优化(Proximal Policy Optimization, PPO)
核心思想
PPO是TRPO的简化版本,通过裁剪目标函数来限制策略更新幅度,无需显式计算KL散度。
算法步骤

特点
- 优点:实现简单,性能优异,适合大规模并行训练。
- 缺点:裁剪机制可能过于保守,限制了策略的探索能力。
实现代码
#! /usr/bin/env python
import time
import gym
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.distributions import Categorical
import random
from PIL import Image
from collections import deque
import numpy as np
class ActorNet(nn.Module):
def __init__(self, img_size, num_actions):
super().__init__()
# 输入图像的形状(c, h, w)
self.img_size = img_size
self.num_actions = num_actions
# 对于Atari环境,输入为(4, 84, 84)
print(img_size[0])
self.featnet = nn.Sequential(
nn.Conv2d(img_size[0], 32, kernel_size=8, stride=4),
nn.ReLU(),
nn.Conv2d(32, 64, kernel_size=4, stride=2),
nn.ReLU(),
nn.Conv2d(64, 64, kernel_size=3, stride=1),
nn.ReLU(),
nn.Flatten(),
)
gain = nn.init.calculate_gain('relu')
self.pnet1 = nn.Sequential(
nn.Linear(self._feat_size(), 512),
nn.ReLU(),
)
self._init(self.featnet, gain)
self._init(self.pnet1, gain)
# 策略网络,计算每个动作的概率
gain = 1.0
self.pnet2 = nn.Linear(512, self.num_actions)
self._init(self.pnet2, gain)
def _feat_size(self):
with torch.no_grad():
x = torch.randn(1, *self.img_size)
x = self.featnet(x).view(1, -1)
return x.size(1)
def _init(self, mod, gain):
for m in mod.modules():
if isinstance(m, (nn.Linear, nn.Conv2d)):
nn.init.orthogonal_(m.weight, gain=gain)
nn.init.zeros_(m.bias)
def forward(self, x):
feat = self.featnet(x)
feat = self.pnet1(feat)
return self.pnet2(feat)
def act(self, x):
with torch.no_grad():
logits = self(x)
m = Categorical(logits=logits).sample().squeeze()
return m.cpu().item()
class CriticNet(nn.Module):
def __init__(self, img_size):
super().__init__()
# 输入图像的形状(c, h, w)
self.img_size = img_size
# 对于Atari环境,输入为(4, 84, 84)
self.featnet = nn.Sequential(
nn.Conv2d(img_size[0], 32, kernel_size=8, stride=4),
nn.ReLU(),
nn.Conv2d(32, 64, kernel_size=4, stride=2),
nn.ReLU(),
nn.Conv2d(64, 64, kernel_size=3, stride=1),
nn.ReLU(),
nn.Flatten()
)
gain = nn.init.calculate_gain('relu')
self.vnet1 = nn.Sequential(
nn.Linear(self._feat_size(), 512),
nn.ReLU()
)
self._init(self.featnet, gain)
self._init(self.vnet1, gain)
# 价值网络,根据特征输出每个动作的价值
gain = 1.0
self.vnet2 = nn.Linear(512, 1)
self._init(self.vnet2, gain)
def _feat_size(self):
with torch.no_grad():
x = torch.randn(1, *self.img_size)
x = self.featnet(x).view(1, -1)
return x.size(1)
def _init(self, mod, gain):
for m in mod.modules():
if isinstance(m, (nn.Linear, nn.Conv2d)):
nn.init.orthogonal_(m.weight, gain=gain)
nn.init.zeros_(m.bias)
def forward(self, x):
feat = self.featnet(x)
feat = self.vnet1(feat)
return self.vnet2(feat).squeeze(-1)
def val(self, x):
with torch.no_grad():
val = self(x).squeeze()
return val.cpu().item()
class ActionBuffer(object):
def __init__(self, buffer_size):
super().__init__()
self.buffer = deque(maxlen=buffer_size)
def reset(self):
self.buffer.clear()
def push(self, state, action, value, reward, done):
self.buffer.append((state, action, value, reward, done))
def sample(self, next_value):
state, action, value, reward, done = \
zip(*self.buffer)
value = np.array(value + (next_value,))
done = np.array(done).astype(np.float32)
reward = np.array(reward).astype(np.float32)
delta = reward + GAMMA * (1 - done) * value[1:] - value[:-1]
rtn = np.zeros_like(delta).astype(np.float32)
adv = np.zeros_like(delta).astype(np.float32)
reward_t = next_value
delta_t = 0.0
for i in reversed(range(len(reward))):
reward_t = reward[i] + GAMMA * (1.0 - done[i]) * reward_t
delta_t = delta[i] + (GAMMA * LAMBDA) * (1.0 - done[i]) * delta_t
rtn[i] = reward_t
adv[i] = delta_t
return np.stack(state, 0), np.stack(action, 0), rtn, adv
def __len__(self):
return len(self.buffer)
class EnvWrapper(object):
def __init__(self, env, num_frames):
super().__init__()
self.env_ = env
self.num_frames = num_frames
self.frame = deque(maxlen=num_frames)
def _preprocess(self, img):
# 预处理数据
img = Image.fromarray(img)
img = img.convert("L")
img = img.crop((0, 30, 160, 200))
img = img.resize((84, 84))
img = np.array(img) / 256.0
return img - np.mean(img)
def reset(self):
obs = self.env_.reset()
if isinstance(obs, tuple):
obs = obs[0]
for _ in range(self.num_frames):
self.frame.append(self._preprocess(obs))
return np.stack(self.frame, 0)
def step(self, action):
obs, reward, done, _, _ = self.env_.step(action)
self.frame.append(self._preprocess(obs))
return np.stack(self.frame, 0), np.sign(reward), done, {}
def render(self):
return self.env_.render()
@property
def env(self):
return self.env_
def train(buffer, next_value, pnet, vnet, optimizer, use_gae=False):
state, action, rtn, adv = buffer.sample(next_value)
state = torch.tensor(state, dtype=torch.float32)
action = torch.tensor(action, dtype=torch.long)
rtn = torch.tensor(rtn, dtype=torch.float32)
adv = torch.tensor(adv, dtype=torch.float32)
logits = pnet(state)
values = vnet(state)
dist = Categorical(logits=logits) #构建策略分布
logp0 = dist.log_prob(action).detach()
if not use_gae:
adv = (rtn - values).detach() #.detach():同样是为了避免梯度回传,仅计算数值
# 策略迭代
lossp = 0.0
for niter in range(NITERS):
logits = pnet(state)
dist = Categorical(logits=logits)
logp1 = dist.log_prob(action)
# PPO算法的概率比值
ratio = torch.exp(logp1 - logp0)
# PPO算法的概率截断
ratio_clip = ratio.clamp(1.0 - EPS, 1.0 + EPS)
ratio_adv = torch.min(ratio * adv, ratio_clip * adv)
pnet.zero_grad()
# PPO算法的损失函数
lossp = -ratio_adv.mean() - REG * dist.entropy().mean()
lossp.backward()
torch.nn.utils.clip_grad_norm_(pnet.parameters(), 0.5) #对梯度进行裁剪,防止梯度爆炸
optimizer.step()
# 价值迭代
for niter in range(NITERS):
values = vnet(state)
lossv = 0.5 * (rtn - values).pow(2).mean()
vnet.zero_grad()
torch.nn.utils.clip_grad_norm_(vnet.parameters(), 0.5)
lossv.backward()
optimizer.step()
return lossp.cpu().item()
GAMMA = 0.99
LAMBDA = 0.95
NFRAMES = 4
BATCH_SIZE = 32
NSTEPS = 1000000
REG = 0.01
NITERS = 4
EPS = 0.2
env = gym.make('PongDeterministic-v4', render_mode='human')
# env = gym.make("Pendulum-v1")
env = EnvWrapper(env, NFRAMES)
state = env.reset()
buffer = ActionBuffer(BATCH_SIZE)
pnet = ActorNet((4, 84, 84), env.env.action_space.n)
# pnet = ActorNet((4, 84, 84), env.env.action_space.shape[0])
vnet = CriticNet((4, 84, 84))
# pnet.cuda()
# vnet.cuda()
optimizer = torch.optim.Adam([
{'params': pnet.parameters(), 'lr': 1e-4},
{'params': vnet.parameters(), 'lr': 1e-4},
])
all_rewards = []
all_losses = []
all_values = []
episode_reward = 0
loss = 0.0
state = env.reset()
for nstep in range(NSTEPS):
state_t = torch.tensor(state, dtype=torch.float32).unsqueeze(0)
action = pnet.act(state_t)
value = vnet.val(state_t)
next_state, reward, done, _ = env.step(action)
buffer.push(state, action, value, reward, done)
state = next_state
episode_reward += reward
if done:
state = env.reset()
all_rewards.append(episode_reward)
state_t = torch.tensor(next_state, dtype=torch.float32).unsqueeze(0)
all_values.append(vnet.val(state_t))
episode_reward = 0
if done or len(buffer) == BATCH_SIZE:
with torch.no_grad():
state_t = torch.tensor(next_state, dtype=torch.float32).unsqueeze(0)
next_value = vnet.val(state_t)
loss = train(buffer, next_value, pnet, vnet, optimizer)
buffer.reset()
if nstep % 100 == 0:
print("nstep=", nstep, "reward=", reward)
state = env.reset()
for i in range(1000):
env.render()
state_t = torch.tensor(state, dtype=torch.float32).unsqueeze(0)
action = pnet.act(state_t)
state, reward, done, _ = env.step(action)
time.sleep(0.01)
if done:
state = env.reset()4)克罗内克分解近似置信区间算法(ACKTR)
核心思想
在强化学习中,策略梯度算法通过计算策略参数的梯度来更新策略,以最大化累计奖励。自然梯度优化是一种有效的策略更新方法,它考虑了策略分布的几何结构,理论上能比普通梯度下降更快地收敛。然而,计算精确的自然梯度涉及到计算 Fisher 信息矩阵的逆,这在高维情况下计算量巨大且难以实现。
ACKTR 算法利用克罗内克分解(Kronecker Factored Approximation)来近似 Fisher 信息矩阵及其逆,从而高效地计算自然梯度的近似值。通过这种近似,既保留了自然梯度优化的优势,又降低了计算复杂度,使得算法在大规模问题上也能快速收敛 。
实现步骤




特点
- 优点:样本效率高,计算高效,适用于高维参数空间。
- 缺点:实现复杂,对超参数敏感,自然梯度的步长选择仍需谨慎。