前言:
Hello,这里宣传一下我们学校的零基础学Linux操作系统MOOC,有公开的学习群聊还有热心答疑~
本人通过老师指导了解到国产开源Linux操作系统OpenEuler,遂使用该系统完成开源大数据开发平台的搭建,收获很大。
本文使用截至25/4/21最新的OpenEulerLTS版本和Hadoop、spark最新版,搭建完全分布式集群。搭建过程适用于各种Linux系统,基本思路大差不差,供参考。
本文声明全文原创,且永远不会收费,延续开源精神。希望文章能够对在学习路上的你有所帮助。
如果你想搭建简单的伪分布式集群,请参考:基于OpenEuler的Hadoop单机伪分布式集群搭建
文章目录
- 技术简介
-
- Hadoop和Spark概述
- OpenEuler概述
- 实验方案
- OpenEuler操作系统(含图形化界面)安装
- Hadoop完全分布式集群搭建
-
- 设置主机名
- NAT模式网络配置
-
- windows中设置
- VMware中设置
- OpenEuler中
- 添加Hadoop用户
-
- 为什么使用普通用户而不是root用户
- 添加用户
- JDK安装及环境变量配置
-
- 安装JDK
- 配置java环境变量
- 安装HADOOP及环境变量配置
-
- 安装Hadoop
- 配置环境变量
- 授予hadoop用户Hadoop安装目录的权限
- 修改Hadoop相关配置文件
-
- vi core-site.xml
- vi hdfs-site.xml
- vi yarn-site.xml
- vi mapred-site.xml
- vi workers
- sudo vi /etc/hosts
- 克隆和配置集群
-
- 克隆集群
- 修改node节点的主机名
- 修改集群的IP地址和UUID
- 配置ssh免密登录
- 关闭防火墙
- 配置时钟同步
- 格式化HDFS
- 启动和停止Hadoop集群
- 监控集群
-
- HDFS监控 : master:9870
- YARN监控 : master:8088
- HDFS文件系统测试
-
- 创建目录并查看
- 创建文件并上传,查看
- 删除文件
- Eclipse配置Hadoop
-
- 安装eclipse
- eclipse连接Hadoop
- 创建Java项目并配置Hadoop
- MapReduce: WordCount测试项目
-
- 编写并上传测试文件
- 编写代码并编译为jar包
- Hadoop执行WordCount
- MapReduce:UserVisitCount测试项目
-
- 编写并上传测试文件
- 编写代码并编译为jar包
- Hadoop执行代码
- Spark Local模式部署
-
- 安装Spark
- 授予Hadoop用户spark安装目录权限
- 修改用户环境变量
- 配置spark环境变量
- 使用自带Pi example计算PI值
- Spark完全分布式部署
-
- 修改spark环境变量
- 修改workers文件
- 分发spark
- 启动spark
- 监控-masrer:8080
- Spark测试
-
- Spark-WordCount测试
- SparkPi测试
技术简介
Hadoop和Spark概述
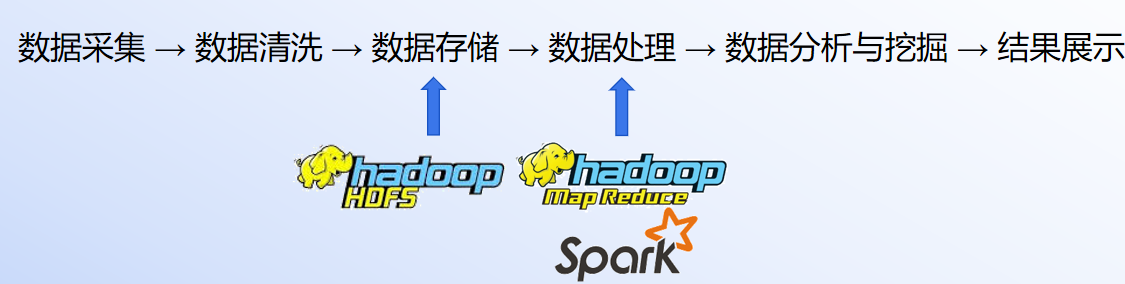
一张图了解Hadoop和spark的功能
Hadoop主要有三个核心组件:HDFS、MapReduce、YARN。
我们最常接触到的就是HDFS和MapReduce,HDFS叫做hadoop分布式文件系统,简单来说就是在hadoop上存储文件的,更规范的说,是将数据以分布式的方式存储在集群中的多个节点上。
MapReduce是一个分布式计算框架,简单来说就是负责计算的,规范的讲,就是对存储在 HDFS 上的大规模数据进行并行处理和计算。
那么Spark是什么?被认为是一个比MapReduce快10-100倍的分布式计算框架。那么究竟快不快,希望你动手试一试。在实际开发中,spark和Hadoop是一般是协同工作的,Hadoop和spark各有优缺点。
下面的链接中介绍了Hadoop和spark的异同:
difference-between-hadoop-and-spark
OpenEuler概述
华为主导开发的开源Linux操作系统,有丰富的文档和社区,详情请看:
OpenEuler官网
实验方案
- 虚拟机环境
虚拟机软件:VMWare WorkStation 17 Pro
虚拟机数量:3 台
虚拟机操作系统:OpenEuler 24.03 LTS SP1 (2025/4/21 LTS最新)
分配资源:2处理器/ 1核心/ 4GB 内存/ 32GB硬盘(划重点,官方要求)
- 软件环境
Hadoop版本:3.4.1 (2025/4/21最新)
Spark版本:spark-3.5.5 (2025/4/21最新)
Java版本:OpenJDK 1.8
开发工具:eclipse-java-2025-03
hadoop-eclipse-plugin-2.6.0.jar
- 运行模式
Hadoop和Spark都是完全分布模式。关于Hadoop三种模式的区别请看:
hadoop-different-modes-of-operation/
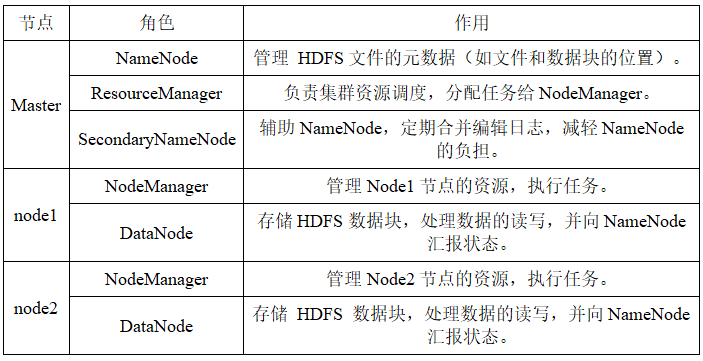
- 节点角色分配

OpenEuler操作系统(含图形化界面)安装
参考本人文章: VMware安装OpenEuler及UKUI图形化界面
Hadoop完全分布式集群搭建
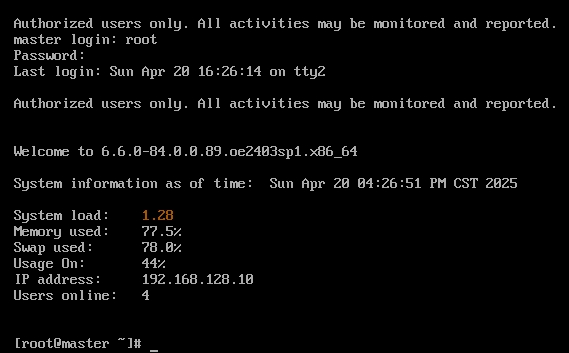
设置主机名
- 登录root用户
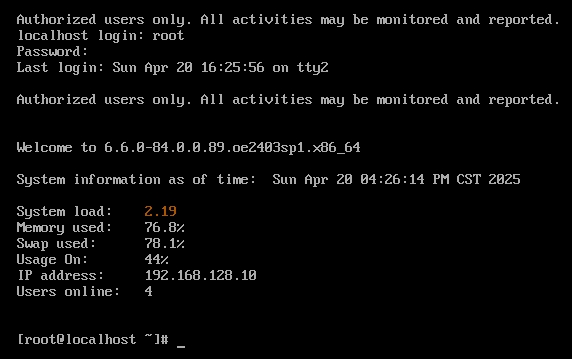
- 修改主机名
hostnamectl set-hostname master
hostname #查看主机名

- 重新登录可以看到已经生效
NAT模式网络配置
windows中设置
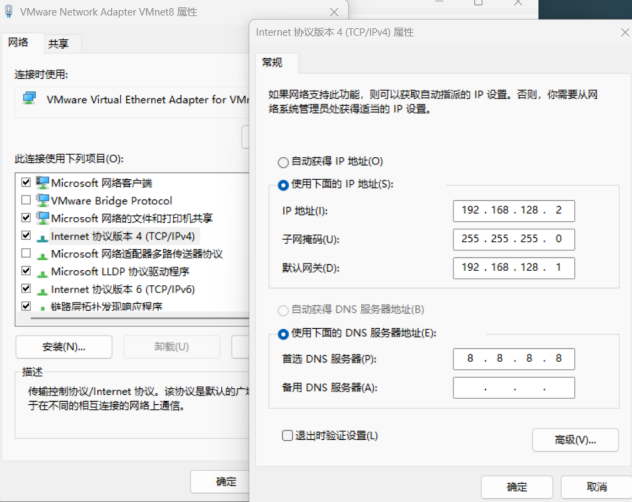
- 本项目中使用VMWare创建虚拟机,网络模式为NAT模式网络。
- 首先,需要确保开启Windows中网络适配器中的VMnet8。

- 然后右击,点击属性,修改IPv4中的IP、子网掩码、网关和DNS。
- 使用192.168.128.0网段, DNS=8.8.8.8。
VMware中设置
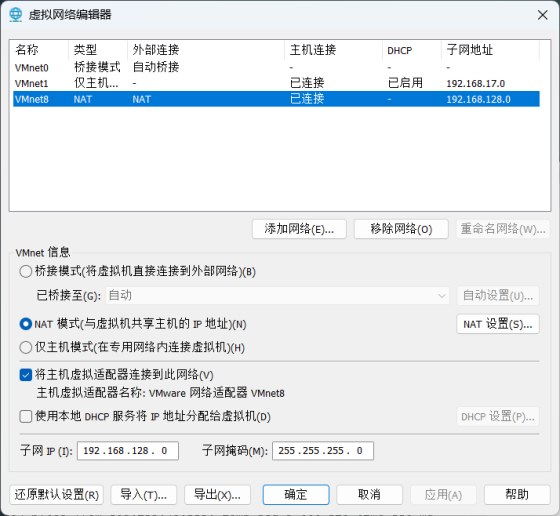
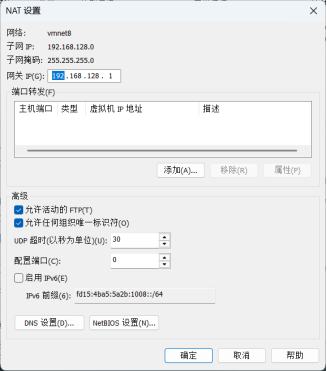
在VMWare中编辑虚拟网络,选中VMNet8,取消勾选DHCP选项,并设置子网、子网掩码、网关(与前面Windows中网络适配器的修改保持一致)。
OpenEuler中
- 修改网卡配置
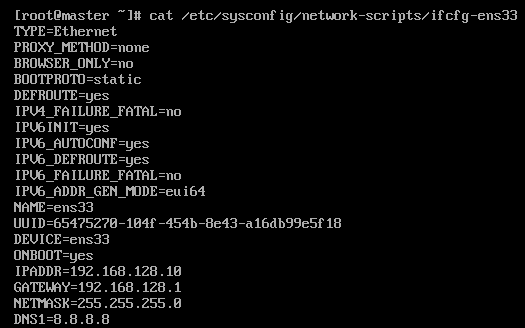
vi /etc/sysconfig/network-scripts/ifcfg-ens33
修改bootproto=static,并添加如下信息:
IPADDR=192.168.128.10
NETMASK=255.255.255.0
GATEWAY=192.168.128.1
DNS1=8.8.8.8
- 重新加载网卡
nmcli connection reload ens33

- 查看ip地址已经成功生效
ip addr
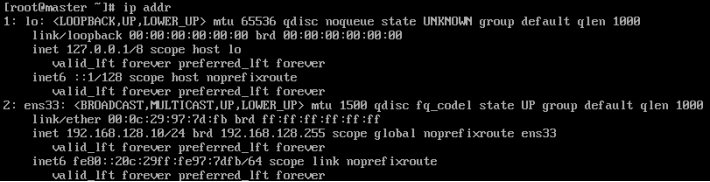
- 使用ping www.baidu.com,可以ping通外网

添加Hadoop用户
为什么使用普通用户而不是root用户
在真实开发环境中,一般不直接使用root用户。root用户拥有最高权限,为了安全性、更好的管理权限和避免风险,应使用普通用户并授予相关权限。
如果要使用root身份使用Hadoop,应在安装完Hadoop后进入$HADOOP_HOME/sbin目录修改如下文件:
vi start-dfs.sh、vi stop-dfs.sh:
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
vi start-yarn.sh和vi stop-yarn.sh:
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
本文中使用普通用户hadoop搭建Hadoop完全分布式集群,并授予hadoop用户sudo权限和Hadoop相关文件权限。
添加用户
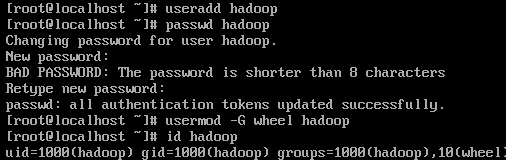
- 添加hadoop用户
useradd hadoop
- 修改用户密码
passwd hadoop
- 添加到wheel组中,授予hadoop用户sudo权限
usermod -G wheel hadoop
- 查看信息,已经添加wheel组
id hadoop
JDK安装及环境变量配置
安装JDK
- 根据官方描述,Hadoop3.3版本以上支持java8和java11(仅运行环境),本次项目中使用的是Hadoop3.4.1和java8

使用dnf search java-1.8查找安装包
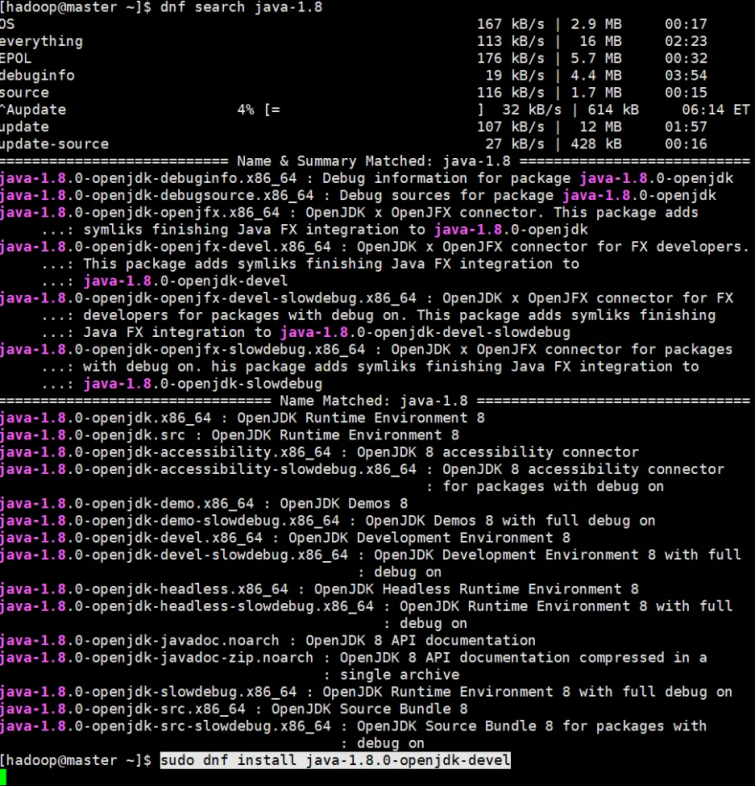
使用sudo dnf install java-1.8.0-openjdk-devel安装,该安装包包括JRE(java运行环境)和JDK

- 安装完成:
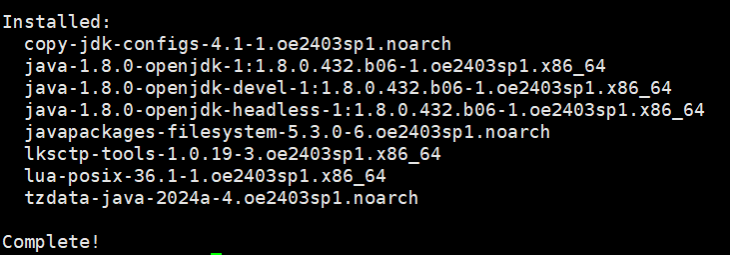
java -version
查看安装版本

配置java环境变量
使用which java找到java所在位置
使用readlink -f /usr/bin/java获取链接指向的java所在位置
which java
readlink -f /usr/bin/java

- 配置java环境变量
vi ~/.bashrc
添加如下行:
JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.432.b06-1.oe2403sp1.x86_64/jre
export PATH=$PATH:$JAVA_HOME/bin
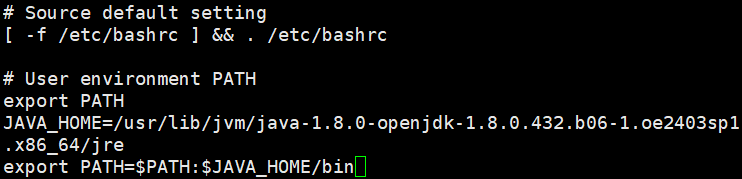
- 使用source ~/.bashrc使生效
source ~/.bashrc

安装HADOOP及环境变量配置
安装Hadoop
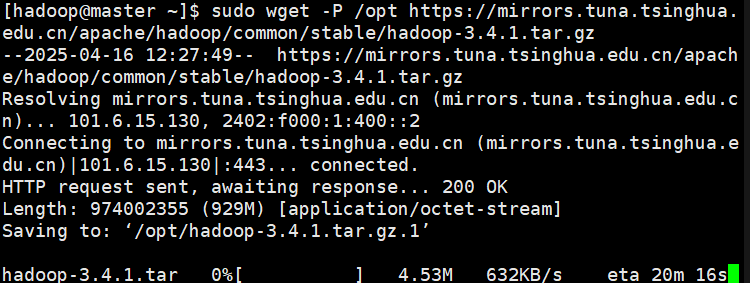
- 使用wget获取Hadoop安装包,并将其放在/opt目录下:
wget -P /opt https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/stable/hadoop-3.4.1.tar.gz

- 使用tar -zvxf解压安装包
tar -zvxf hadoop-3.4.1.tar.gz

- 将hadoop-3.4.1改名为hadoop
mv hadoop-3.4.1 hadoop

配置环境变量
- 编辑用户环境变量
vi ~/.bashrc
确保有如下:
HADOOP_HOME=/opt/hadoop
export PATH=$HADOOP_HOME:$PATH
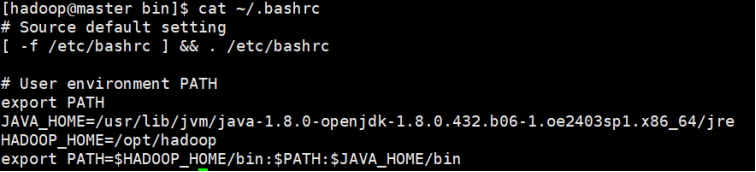
- 使用source ~/.bashrc使生效
source ~/.bashrc

- 进入Hadoop安装目录:$HADOOP_HOME/etc/hadoop,修改如下文件:
cd $HADOOP_HOME/etc/hadoop
sudo vi hadoop-env.sh
sudo vi yarn-env.sh
添加:
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.432.b06-1.oe2403sp1.x86_64/jre



授予hadoop用户Hadoop安装目录的权限
sudo chown -R hadoop:hadoop /opt/hadoop

修改Hadoop相关配置文件
cd $HADOOP_HOME/etc/hadoop
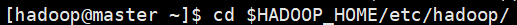
vi core-site.xml
设置默认文件系统HDFS系统主节点为 master,端口为 9000和临时目录所在位置。
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop/tmp</value>
</property>
</configuration>
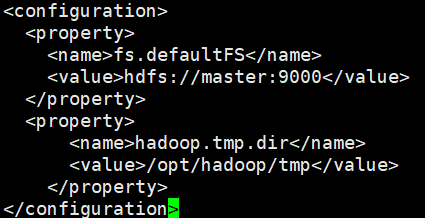
vi hdfs-site.xml
设置每个HDFS文件的副本数和namenode、datanode数据的存储位置。
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/hadoop/data/nn</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/hadoop/data/dn</value>
</property>
</configuration>
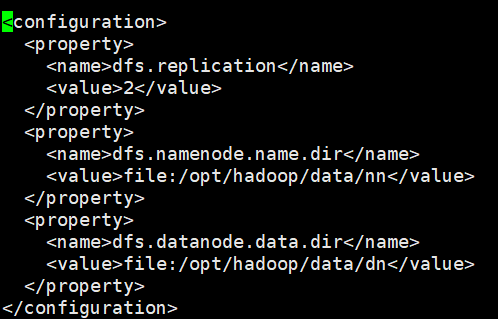
vi yarn-site.xml
设置resourcemanager的主机名、mapreduce_shuffle服务和设置yarn应用所需的hadoop路径。
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.application.classpath</name>
<value>
<!-- 这里填入hadoop classpath命令得到得值 -->
</value>
</property>
</configuration>
vi mapred-site.xml
指定yarn为mapreduce的执行框架。
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
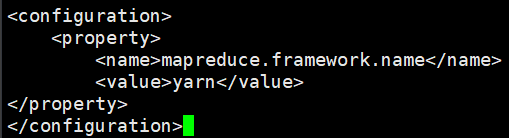
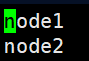
vi workers
指定集群的工作节点,会在这些节点上启动DATa Node和NodeManager。
node1
node2
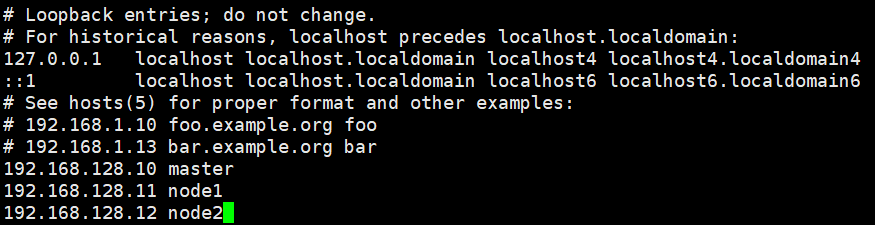
sudo vi /etc/hosts
配置主机名与IP映射。保证可以通过主机名互相访问。
192.168.128.10 master
192.168.128.11 node1
192.168.128.12 node2
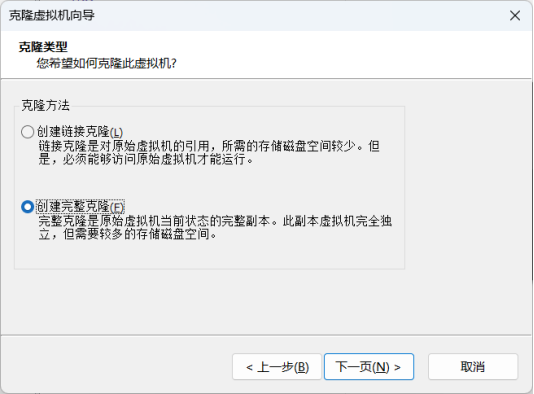
克隆和配置集群
克隆集群
克隆master为node1和node2。
修改node节点的主机名
修改node1和node2的hostname分别为node1和node2:
hostnamectl set-hostname node1
hostnamectl set-hostname node2
使用hostname查看修改情况
hostname


修改集群的IP地址和UUID
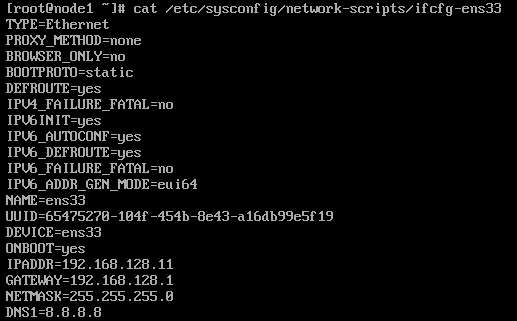
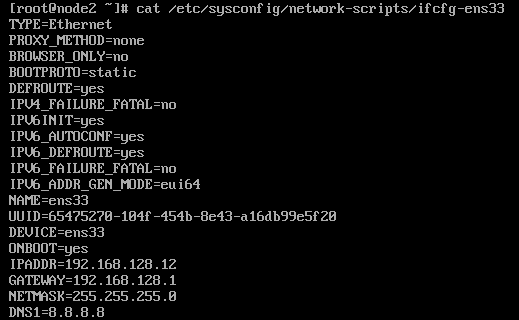
- 使用vi /etc/sysconfig/network-scripts/ifcfg-ens33修改网卡文件
node1:
IPADDR=192.168.128.11
node2:
IPADDR=192.168.128.12
并且修改UUID保证每台虚拟机的UUID唯一
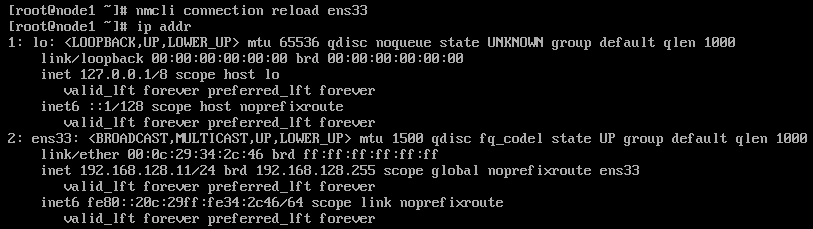
- 重新加载ens33
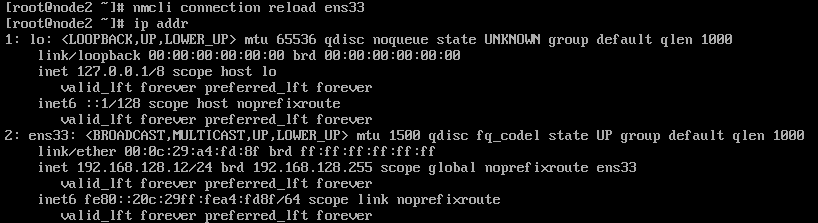
nmcli connection reload ens33
- 查看地址生效
ip addr
- ping www.baidu.com可以ping成功
ping www.baidu.com


配置ssh免密登录
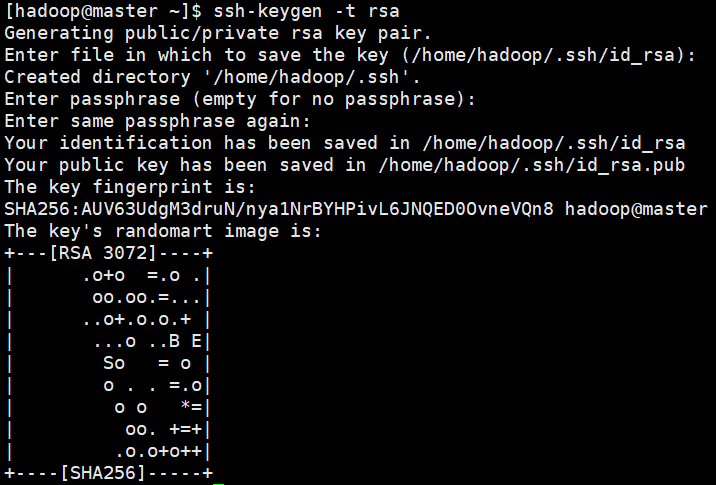
- 在master执行ssh-keygen -t rsa产生公钥与私钥对
ssh-keygen -t rsa
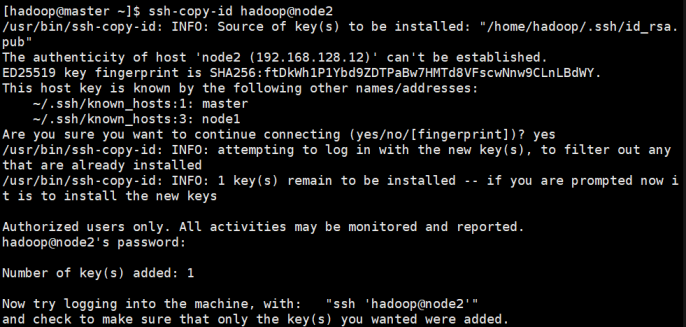
- 使用如下命令,将公钥复制到master 上,开启免密登录
ssh-copy-id hadoop@master
ssh-copy-id hadoop@node1
ssh-copy-id hadoop@node2
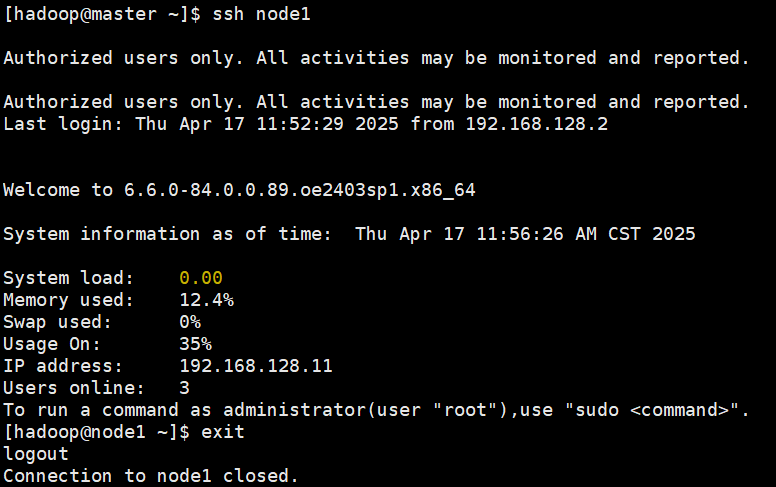
- 测试免密登录
ssh node1
exit
ssh node2
exit
无需密码登录
关闭防火墙
对所有节点执行:
sudo systemctl stop firewalld #停止
sudo systemctl disable firewalld #关闭开机自启
sudo systemctl status firewalld #显示inactive(dead)说明已经关闭
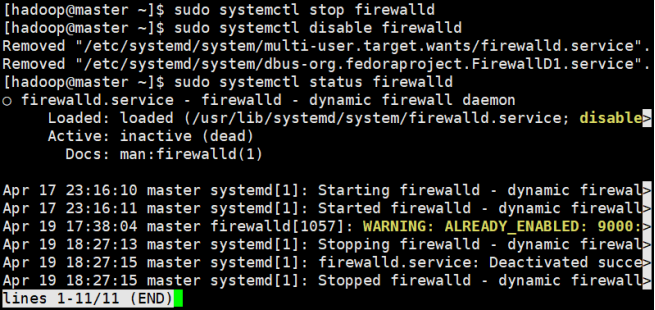
注意在真实开发环境中不推荐直接关闭防火墙,而是开放所需端口和服务。
例如这种:

配置时钟同步
Hadoop是一个分布式系统,集群中有多个节点,如果节点之间的系统时间不一致,容易造成错误。
- 对master作如下修改
vi /etc/chrony.conf
local stratum 10
allow 192.168.128.0/24
允许本网段的主机将master作为时间源。

- 对node1和node2分别作如下修改:
vi /etc/chrony.conf
server master iburst
将master节点作为节点的时间源。

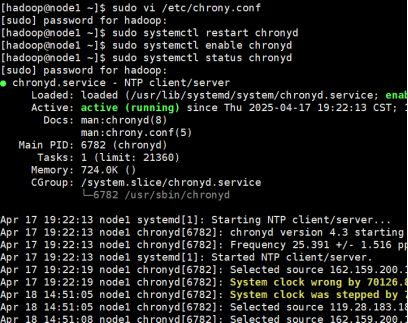
- 启动chronyd服务
分别在master和node节点执行:
sudo systemctl restart chronyd #重启
sudo systemctl enable chronyd #设置开机自启
sudo systemctl status chronyd #查看状态,active(running)已启动

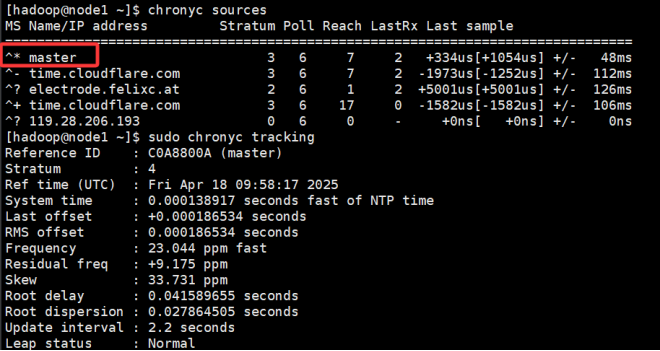
- 分别在node节点使用:
chronyc sources
如果master前面是*,代表master成为node的时间源
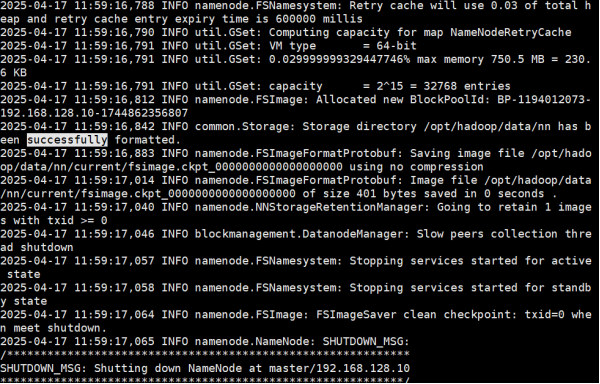
格式化HDFS
- 分别对master、node1、node2格式化:
cd $HADOOP_HOME
bin/hdfs namenode -format
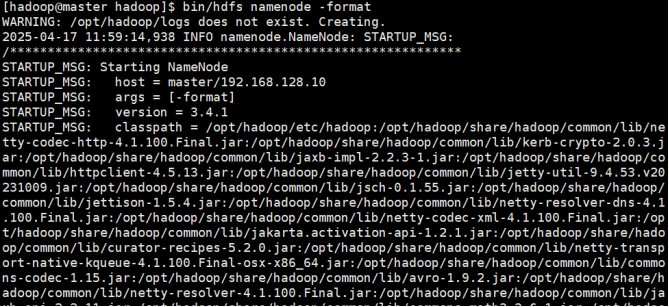
2) 显示successful成功
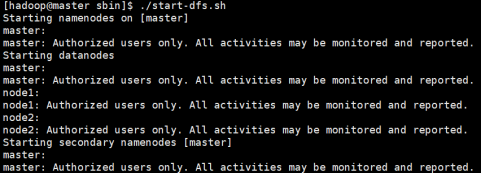
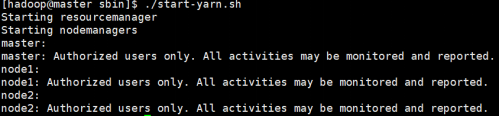
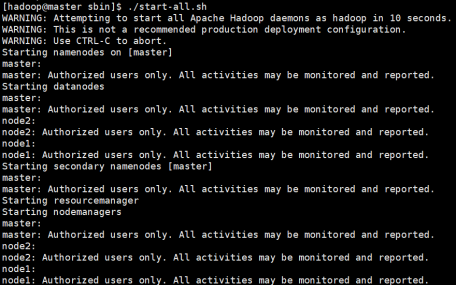
启动和停止Hadoop集群
启动Hadoop集群
有两种方式:
cd $HADOOP_HOME/sbin
./start-dfs.sh
./start-yarn.sh
#或者
./start-all.sh
- 使用jps查看
jps
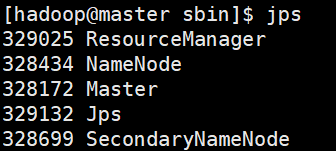
master节点应该有:
NameNode、ResourceManager、SecondaryNameNode
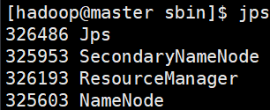
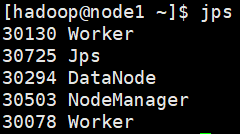
node应该有DataNode和NodeManager
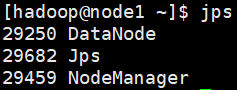
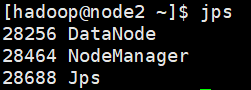
- 停止Hadoop集群
同样有两种方式:
./stop-dfs.sh
./stop-yarn.sh
#或者
./stop-all.sh
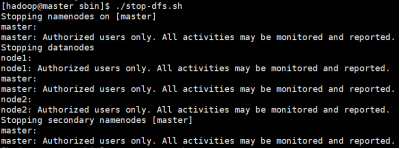
监控集群
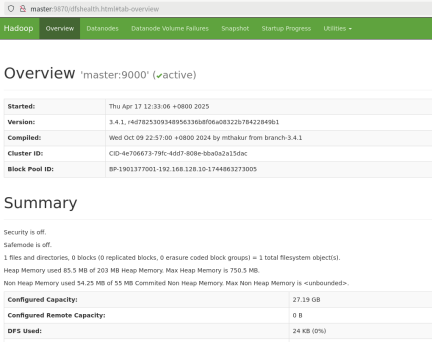
HDFS监控 : master:9870
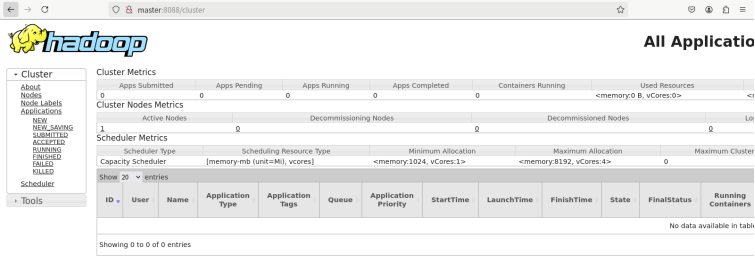
YARN监控 : master:8088
HDFS文件系统测试
创建目录并查看
hdfs dfs -mkdir /input #创建/input目录
hdfs dfs -ls / #查看根目录下的文件

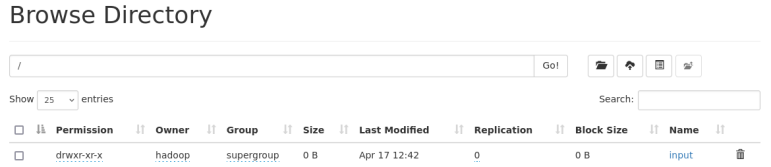
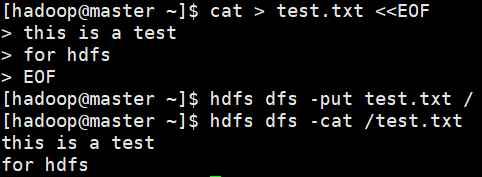
创建文件并上传,查看
- 创建文件
cat > test.txt << EOF
> this is a test
> for hdfs
> EOF
上传test.txt文件到/目录
hdfs dfs -put test.txt /
- 查看test.txt文件
hdfs dfs -cat /test.txt
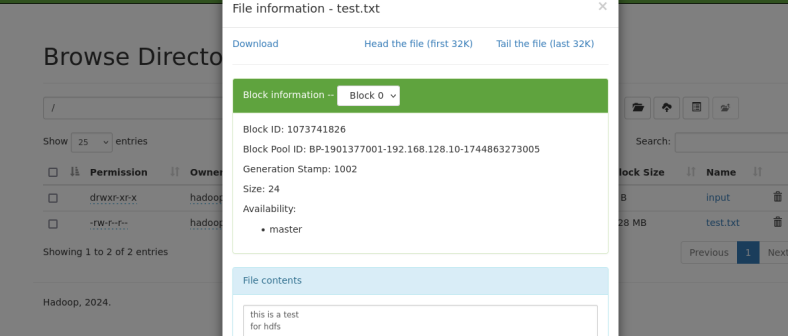
删除文件
hdfs dfs -rm -f /test.txt
删除test.txt文件

Eclipse配置Hadoop
安装eclipse
- 下载链接:eclipse-java-2025-03
- 解压
解压到/opt目录:
tar -zvxf Downloads /eclipse-java-2025-03-R-linux-gtk-x86_64

- 添加桌面快捷方式
进入/home/hadoop/eclipse目录,将eclipse添加到桌面
eclipse连接Hadoop
- 下载Hadoop-eclipse-plugin
链接: hadoop-eclipse-plugin-2.6.0.jar
- 安装Hadoop-eclipse-plugin
将hadoop-eclipse-plugin-2.6.0.jar文件复制到eclipse安装目录的dropins目录

- 重新启动IDE后,点击
windwos-preferences-gradle-hadoop Map/Reduce,选择Hadoop的安装目录/opt/hadoop
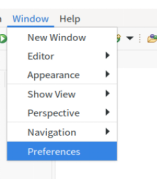
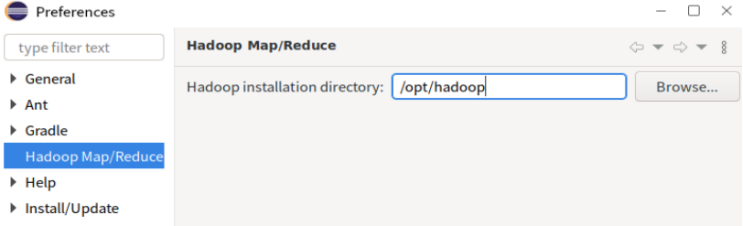
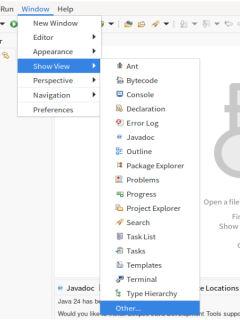
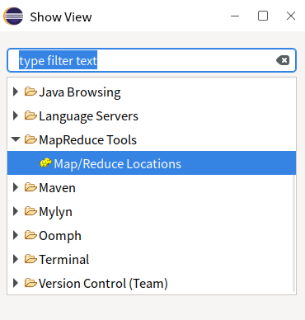
- 点击
windows-show view-other-Map/Reduce Locations,显示DFS Location。
- 创建dfs locations
点击右下角紫色小象
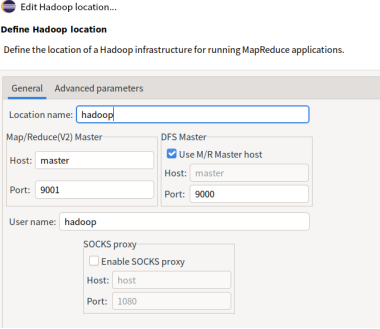
输入Host为master,dfs master 端口为9000,map/reduce master端口为9001
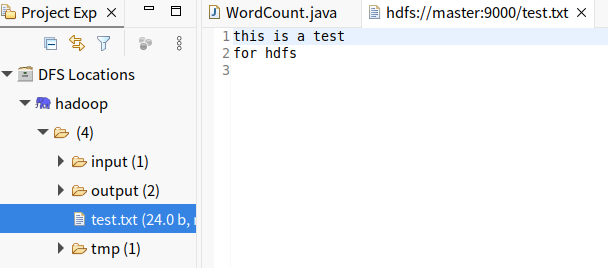
- 配置成功后,左侧project explorer成功显示dfs locations及hdfs系统中的内容
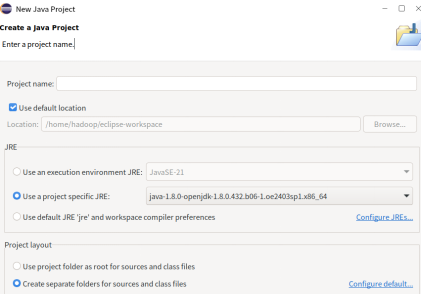
创建Java项目并配置Hadoop
创建项目,选择jdk1.8
导入Hadoop jar文件
选中项目,点击file-properties-java build path-libraries-add external jars
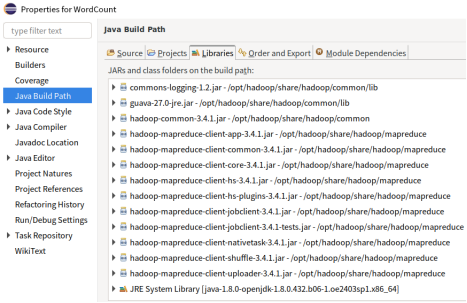
导入Hadoop安装目录/opt/hadoop下的如下jar文件:
share/hadoop/common/hadoop-common-3.3.4.jar
share/hadoop/mapreduce/hadoop-mapreduce-client-*.jar
share/hadoop/common/lib/guava-*.jar
share/hadoop/common/lib/commons-logging-*.jar
MapReduce: WordCount测试项目
编写并上传测试文件
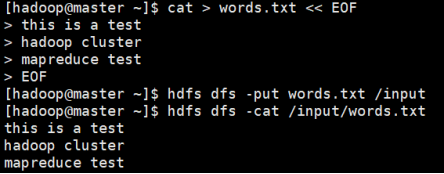
编写words.txt存放词频统计的测试文件,指定EOF为结束符
cat > words.txt <<EOF
> this is a test
> hadoop cluster
> mapreduce test
> EOF
hdfs dfs -put words.txt /input#上传测试文件
hdfs dfs -cat /input/words.txt#查看测试文件
编写代码并编译为jar包
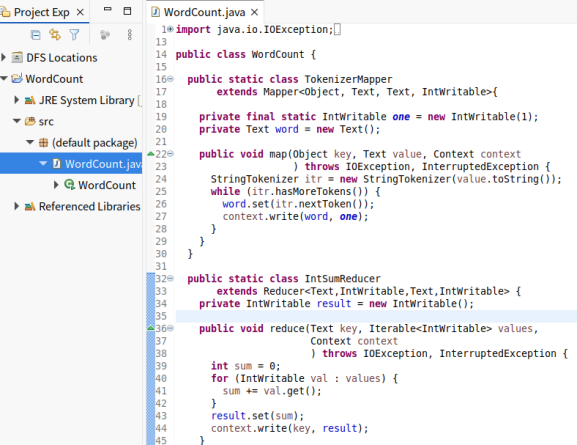
- hadoop官方给出了WordCount代码:
链接:WordCount源码
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
- 创建WordCount.java
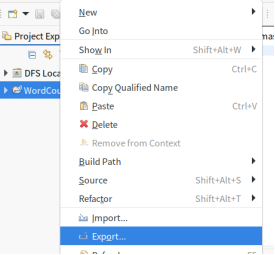
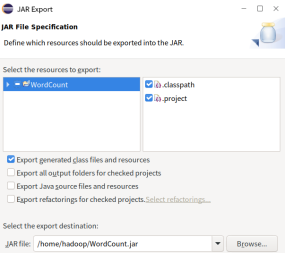
- 右击项目目录, 点击export-java-jar file, 编译为jar文件
Hadoop执行WordCount
hadoop jar WordCount.jar WordCount /input /output
输入文件只有一个文件的时候可以直接写输入目录/input,否则写详细位置。
将WordCount.jar 文件上传到Hadoop上执行。
该命令含义为:hadoop jar jar文件位置 类名 输入文件位置 输出目录

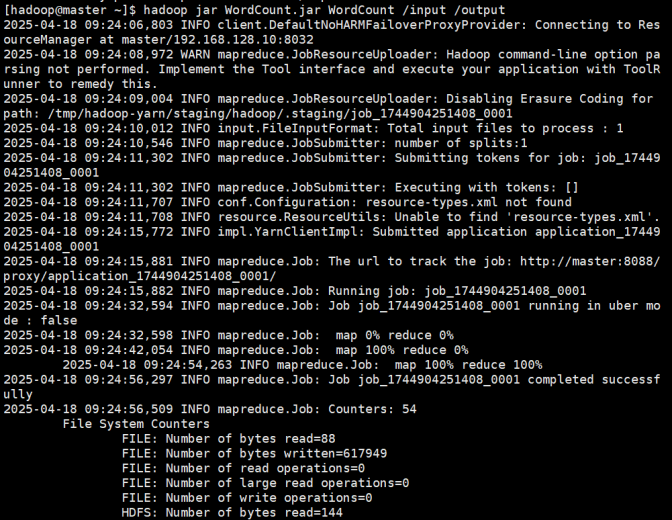
执行结果如下:
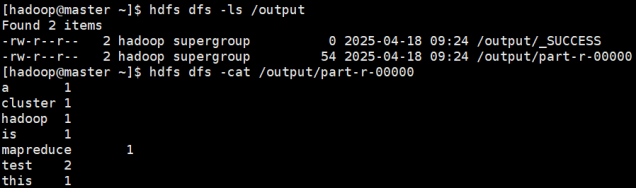
hdfs dfs -ls /output
查看到生成一个/output目录,包含如下文件:
_SUCCESS:表示成功
part-r-00000:包含执行结果
hdfs dfs -cat /output/part-r-00000
查看到词频统计结果
查看网页端的/output目录:
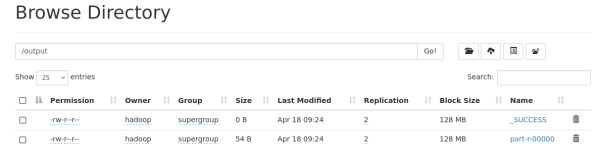
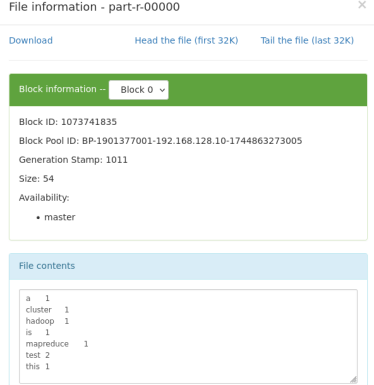
查看part-r-00000文件的内容, 可以看到已经成功执行, 并统计出词频结果
MapReduce:UserVisitCount测试项目
编写并上传测试文件
cat > users.txt <<EOF
>user1
>user1
>user2
>user2
>user2
>user1
>user2
> EOF
hdfs dfs -put users.txt /input #上传测试文件
hdfs dfs -cat /input/users.txt #查看测试文件
编写代码并编译为jar包
UserVisitCount是一个用于统计不同用户访问次数的程序,编写代码如下:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class UserVisitCount {
public static class UserVisitMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text user = new Text();
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString().trim();
if (!line.isEmpty()) {
user.set(line);
context.write(user, one);
}
}
}
public static class UserVisitReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
context.write(key, new IntWritable(sum));
}
}
public static void main(String[] args) throws Exception {
if (args.length != 2) {
System.err.println("Usage: UserVisitCount <input path> <output path>");
System.exit(-1);
}
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "User Visit Count");
job.setJarByClass(UserVisitCount.class);
job.setMapperClass(UserVisitMapper.class);
job.setReducerClass(UserVisitReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
右击项目目录, 点击export-java-jar file, 编译为jar文件
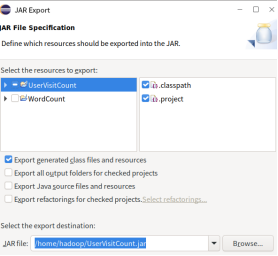
Hadoop执行代码
使用
hadoop jar UserVisitCount.jar UserVisitCount /input/users.txt /output
将UserVisitCount.jar 文件上传到Hadoop上执行。
该命令含义为:hadoop jar jar文件位置 类名 输入文件 输出目录
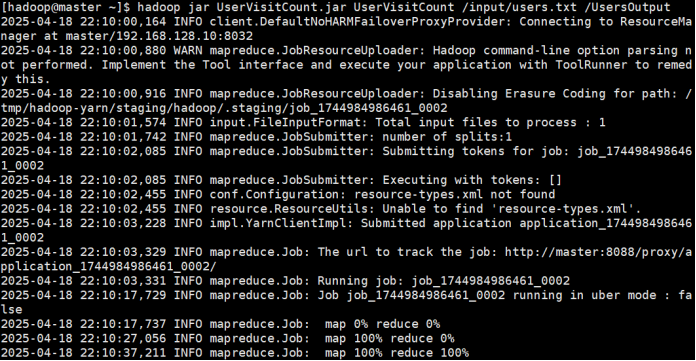
执行结果如下:
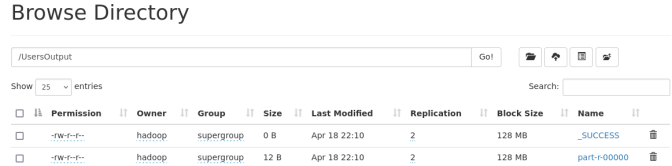
hdfs dfs -ls /output查看到生成一个/output目录,包含如下文件:
_SUCCESS:表示成功
part-r-00000:包含执行结果
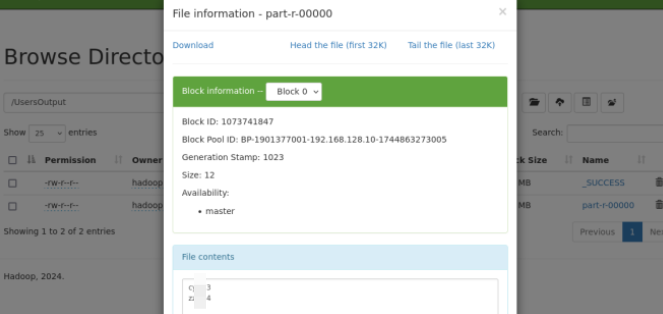
hdfs df s-cat /output/part-r-00000查看到用户访问次数统计结果

查看网页端的/output目录:
查看part-r-00000文件的内容, 可以看到已经成功执行, 并统计出用户访问次数结果
Spark Local模式部署
安装Spark
- 获取spark-3.5.5-bin-hadoop3.tgz安装包。
sudo wget -P /opt https://dlcdn.apache.org/spark/spark-3.5.5/spark-3.5.5-bin-hadoop3.tgz
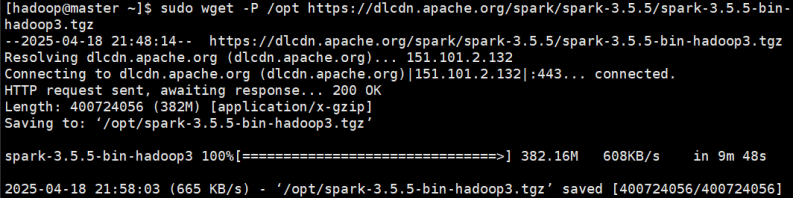
- 使用sudo tar -zvxf spark-3.5.5-bin-hadoop3.tgz -C /opt命令解压,指定安装目录为/opt。
sudo tar -zvxf spark-3.5.5-bin-hadoop3.tgz -C /opt
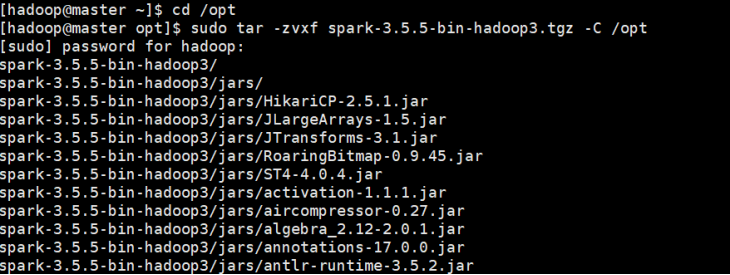
- 安装完成后使用sudo mv spark-3.5.5-bin-hadoop3.tgz hadoop,
将spark-3.5.5-bin-hadoop3的名字改成spark。

授予Hadoop用户spark安装目录权限
sudo chown -R hadoop:hadoop /opt/spark

修改用户环境变量
vim ~/.bashrc

确保有如下环境变量,编辑完成保存后使用source ~/.bashrc使生效:
JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.432.b06-1.oe2403sp1.x86_64/jre
HADOOP_HOME=/opt/hadoop
HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
SPARK_HOME=/opt/spark
export PATH=$HADOOP_HOME/bin:$PATH:$JAVA_HOME/bin:$SPARK_HOME/bin

配置spark环境变量
- 进入spark安装目录下的conf目录,复制一份spark-env.sh.template为spark-env.sh。
cp spark-env.sh.template spark-env.sh

- 修改spark-env.sh为如下内容:
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.432.b06-1.oe2403sp1.x86_64/jre
export HADOOP_CONF_DIR=/opt/hadoop/etc/hadoop
export SPARK_DIST_CLASSPATH=$(/opt/hadoop/bin/hadoop classpath)

使用自带Pi example计算PI值
run-example SparkPi 2>&1 | grep “Pi is roughly”

Spark完全分布式部署
修改spark环境变量
vi spark-env.sh
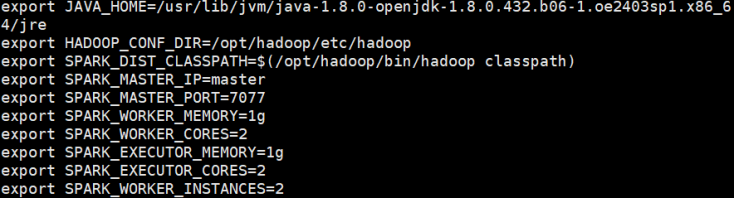
修改添加如下内容,设置spark的IP和端口、worker和Executor的内存和核心数、每个机器跑两个worker实例:
export SPARK_MASTER_IP=master
export SPARK_MASTER_PORT=7077
export SPARK_WORKER_MEMORY=1g
export SPARK_WORKER_CORES=2
export SPARK_EXECUTOR_MEMORY=1g
export SPARK_EXECUTOR_CORES=2
export SPARK_WORKER_INSTANCES=2
修改workers文件
先把workers模板配置文件拷贝一份为workers:
cp workers.template workers

vi workers
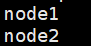
编辑文件,设置workers为:
node1
node2
分发spark
在master执行如下命令:
scp -r /opt/spark node1:~
scp -r /opt/spark node2:~
该命令将spark安装目录分发给node1和node2的家目录

进入node1和node2,使用sudo mv spark /opt将spark安装目录移动到/opt
sudo mv spark /opt


启动spark
在master上cd $SPARK_HOME/sbin
cd $SPARK_HOME/sbin
执行./start-all.sh启动spark
./start-all.sh
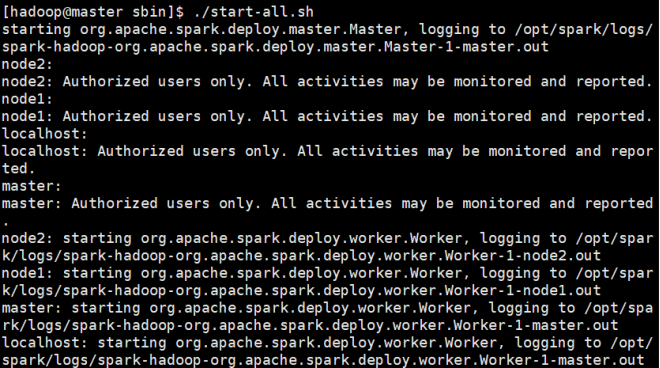
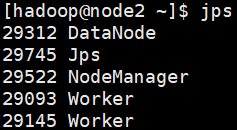
使用jps,在master上可以看到Master,在node上可以看到两个Worker(因为之前配置每个机器两个worker实例)
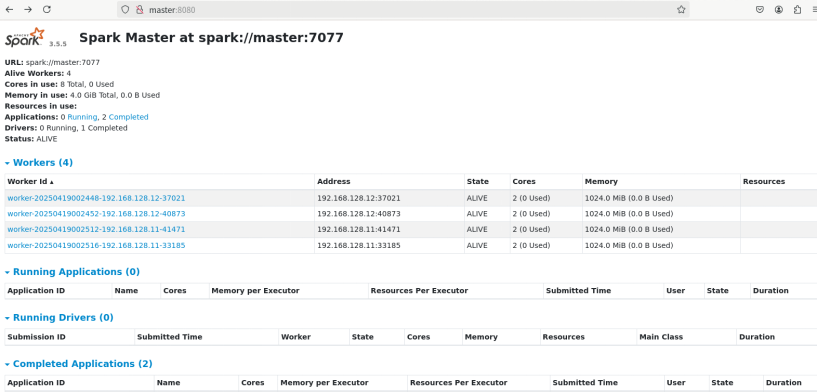
监控-masrer:8080
Spark测试

在介绍提交命令之前,先说一下deploy模式。默认是client模式,你提交后在本地master上执行,结果在终端上可以看见,在master:8080页面是看不到driver执行的;cluster模式会在集群上执行driver,同时可以在master:8080页面监控到并查看到结果。
Spark-WordCount测试
执行如下指令,使用spark自带的wordcount程序计算词频,读取hdfs系统里的words.txt输入文件:
/opt/spark/bin/spark-submit \
--class org.apache.spark.examples.JavaWordCount \
--master spark://master:7077 \
--deploy-mode cluster \
/opt/spark/examples/jars/spark-examples_2.12-3.5.5.jar \
hdfs://master:9000/input/words.txt

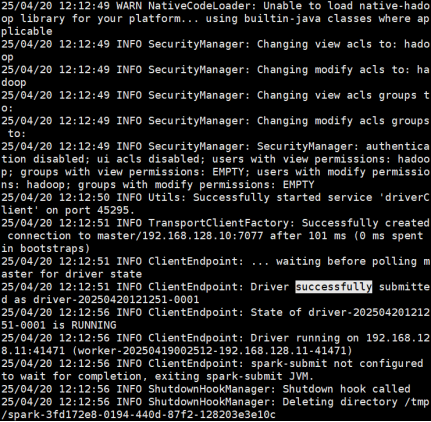
网页端显示完成
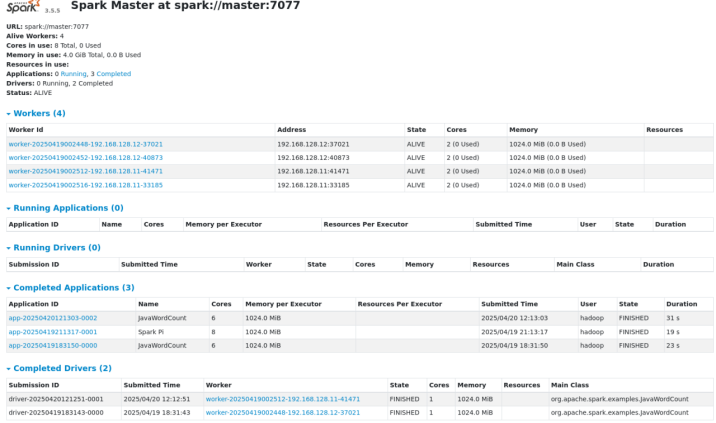
点击网页端的stdout可以看到结果
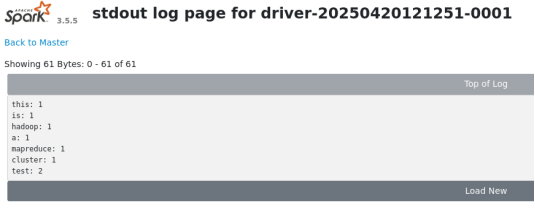
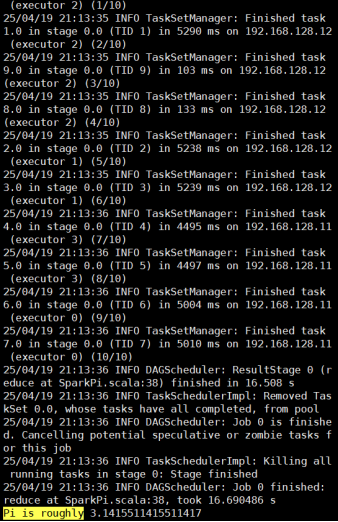
SparkPi测试
执行如下命令,这是spark自带的pi值计算程序
$SPARK_HOME/bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://master:7077 \
$SPARK_HOME/examples/jars/spark-examples_*.jar 10
10是迭代轮数,就是用10个任务来并行计算(每个任务各算一点,然后合并)。

迭代十次并给出pi值,结果如下: