目录
(一)HDFS(Hadoop Distributed File System)
一、引言
随着大数据时代的来临,Hadoop 作为一个开源的分布式计算框架,在数据存储和处理方面发挥着至关重要的作用。在学习 Hadoop 的过程中,我收获颇丰,以下是我对 Hadoop 学习的一些心得体会以及相关实践内容。
二、Hadoop 基础架构
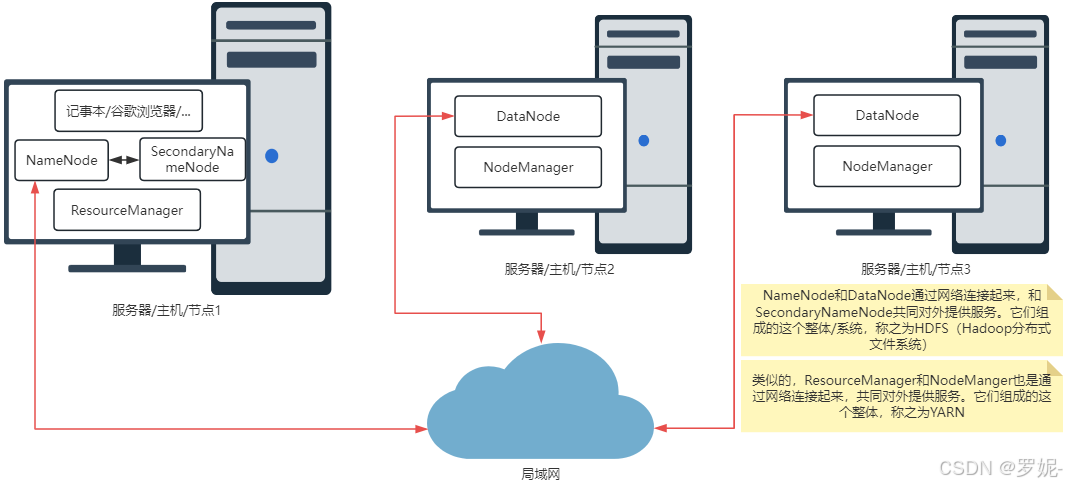
(一)HDFS(Hadoop Distributed File System)
HDFS 是 Hadoop 的分布式文件系统,它具有高度容错性,并且被设计成可以在低成本的硬件上运行。HDFS 采用主从架构,主要由以下两个组件构成:
- NameNode
- NameNode 是 HDFS 的主节点,它管理文件系统的命名空间,包括文件和目录的元数据信息。它维护着文件系统树以及整个文件系统的文件和目录的元数据。
- 例如,当一个新文件被创建时,NameNode 会记录该文件的名称、权限、所属用户和组等信息。
- DataNode
- DataNode 是 HDFS 的从节点,负责存储实际的数据块。文件在 HDFS 中被分割成固定大小的数据块(通常为 128MB),这些数据块被存储在不同的 DataNode 上。
- DataNode 会定期向 NameNode 发送心跳信号,以表明自己的存活状态,并报告自己所存储的数据块信息。
(二)MapReduce
MapReduce 是一种编程模型,用于大规模数据集(大于 1TB)的并行运算。它主要由两个阶段组成:
- Map 阶段
- Map 函数以 <key, value> 对作为输入,对输入数据进行处理,并产生一系列中间 < key, value > 对。例如,在一个单词计数的应用中,Map 函数会将输入的文本行分割成单词,并为每个单词生成 < 单词,1 > 这样的中间结果。
- Reduce 阶段
- Reduce 函数以 Map 阶段产生的中间 <key, value> 对作为输入,对相同 key 的值进行合并操作。在单词计数的例子中,Reduce 函数会将相同单词对应的所有 1 相加,得到单词的出现次数。
- Reduce 函数以 Map 阶段产生的中间 <key, value> 对作为输入,对相同 key 的值进行合并操作。在单词计数的例子中,Reduce 函数会将相同单词对应的所有 1 相加,得到单词的出现次数。
三、Hadoop 安装与配置
视频安装(奶妈级):hadoop集群搭建
!!注意事项
- 硬件要求
- 内存:确保主机有足够的内存来支持虚拟机的运行。一般来说,如果要运行多个虚拟机或者虚拟机中需要运行内存密集型的应用程序(如数据库服务器、大数据处理工具等),建议主机至少有 8GB 以上的内存。例如,如果你想在虚拟机中安装 Windows Server 并运行 SQL Server 进行开发测试,主机内存小于 8GB 可能会导致虚拟机运行缓慢。
- 处理器:多核处理器能够更好地分配资源给虚拟机。对于简单的虚拟机使用场景,如运行一些轻量级的 Linux 发行版用于学习命令行操作,单核处理器可能足够,但如果要运行复杂的操作系统或者多任务处理的应用,最好有多核处理器,以提供更好的性能。
- 磁盘空间:要考虑虚拟机操作系统本身的安装空间以及在虚拟机中存储数据所需的空间。例如,安装一个完整的 Windows 10 虚拟机可能需要至少 30GB 的磁盘空间,并且随着使用还会不断增加,所以要预留足够的磁盘空间。
- 虚拟机软件选择
- VMware Workstation:功能强大,支持多种操作系统,适用于专业开发人员和企业级用户。它提供了丰富的网络配置选项、高级的虚拟机管理功能(如克隆、快照等)。但是,对于个人非商业用途是收费软件。
- VirtualBox:开源免费,适合初学者和个人用户。虽然功能相对 VMware Workstation 可能稍显简单,但对于基本的虚拟机安装和使用完全足够,例如学习 Linux 系统或者搭建简单的测试环境。
- 操作系统镜像获取
- 合法来源:确保从合法渠道获取操作系统镜像。对于商业操作系统,如 Windows,需要有合法的许可证密钥。对于 Linux 发行版,最好从官方网站下载,以避免安全风险和版权问题。例如,Ubuntu 可以从ubuntu.com官方网站下载,这样可以保证获取到最新、最安全的版本。
- 验证完整性:下载完成后,最好验证操作系统镜像的完整性。一些官方网站会提供镜像文件的哈希值(如 MD5、SHA - 1 或 SHA - 256 等),可以使用相应的哈希计算工具来检查下载的文件是否与官方提供的哈希值一致,防止镜像文件在下载过程中被篡改。
- 虚拟机安装过程
- 合理配置虚拟机参数:在创建虚拟机时,根据操作系统的要求和实际使用需求配置参数。如分配合理的内存、CPU 核心数和磁盘空间。以安装 CentOS 为例,如果只是用于简单的服务器搭建和测试,分配 1GB 内存、1 个 CPU 核心和 10GB 磁盘空间可能就足够,但如果要安装图形界面并且运行多个服务,可能需要分配更多的资源。
- 安装选项选择:在安装操作系统过程中,注意安装选项。例如,在安装 Linux 时,要注意分区设置。对于新手来说,选择默认的分区方案可能比较简单,但如果对系统性能和数据存储有特殊要求,可能需要手动分区。另外,对于一些操作系统安装过程中的软件选择,如是否安装额外的组件(如开发工具、服务器软件等),要根据实际用途来决定。
- 网络配置
- 网络模式选择:虚拟机软件一般提供多种网络模式,如桥接模式、NAT 模式和仅主机模式。桥接模式可以让虚拟机和主机处于同一局域网,方便虚拟机与其他设备通信,但可能会占用局域网 IP 资源;NAT 模式下虚拟机通过主机的网络连接访问外部网络,比较方便,但外部网络设备不能直接访问虚拟机;仅主机模式主要用于虚拟机和主机之间的内部通信。根据具体的使用场景选择合适的网络模式。
- 网络安全设置:如果虚拟机要连接外部网络,需要注意网络安全。安装防火墙并合理配置规则,防止虚拟机被外部攻击。对于一些需要对外提供服务的虚拟机,如 Web 服务器,要确保服务的安全性,如设置正确的端口访问权限、定期更新软件补丁等。
- 更新与维护
- 操作系统更新:安装完成后,要及时更新虚拟机中的操作系统。对于 Windows 系统,要开启自动更新功能或者定期手动检查更新;对于 Linux 系统,可以使用相应的包管理工具(如 yum for CentOS、apt for Ubuntu 等)更新系统软件包,以保证系统的安全性和稳定性。
- 虚拟机软件更新:同时,要关注虚拟机软件本身的更新,更新可能会修复软件的漏洞、提高性能或者增加新的功能。例如,VMware Workstation 的更新可能会提供更好的对新操作系统的支持或者优化虚拟机的资源分配。
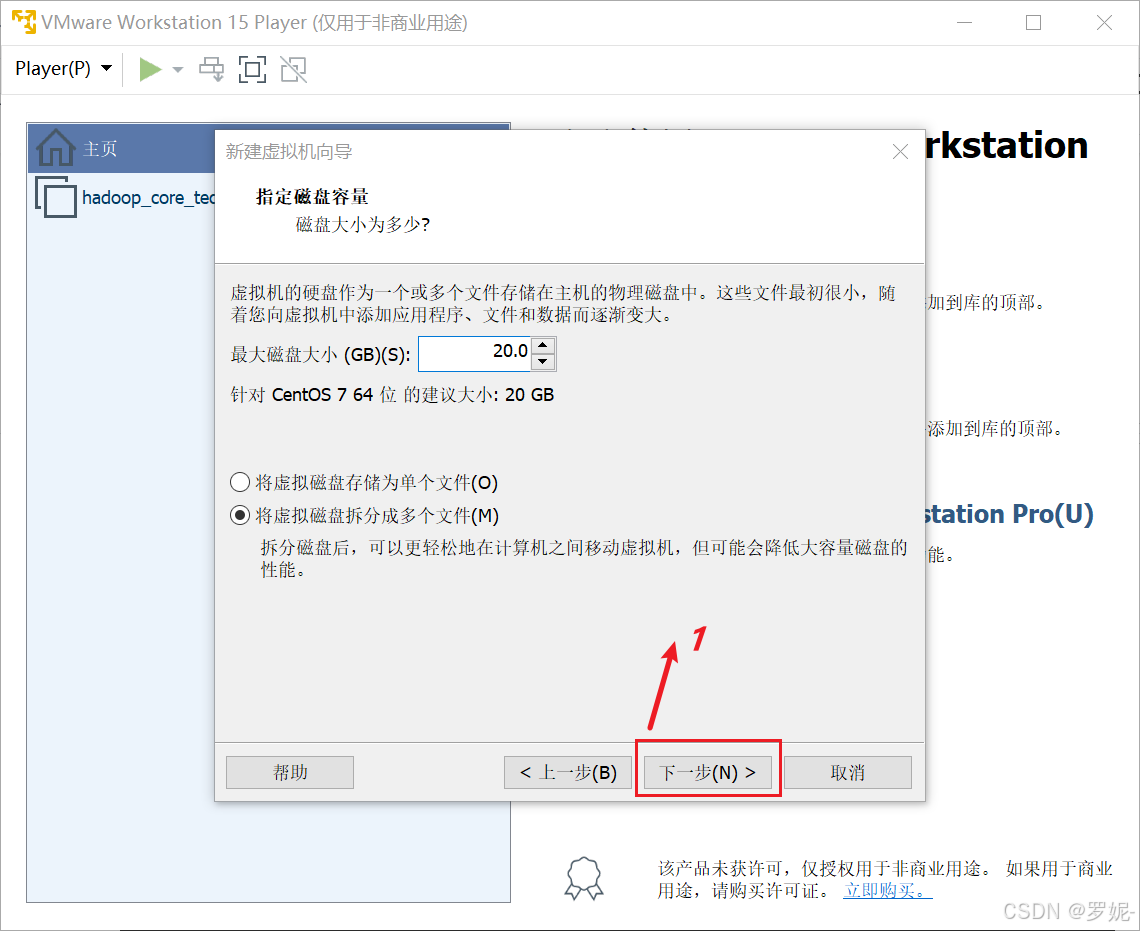
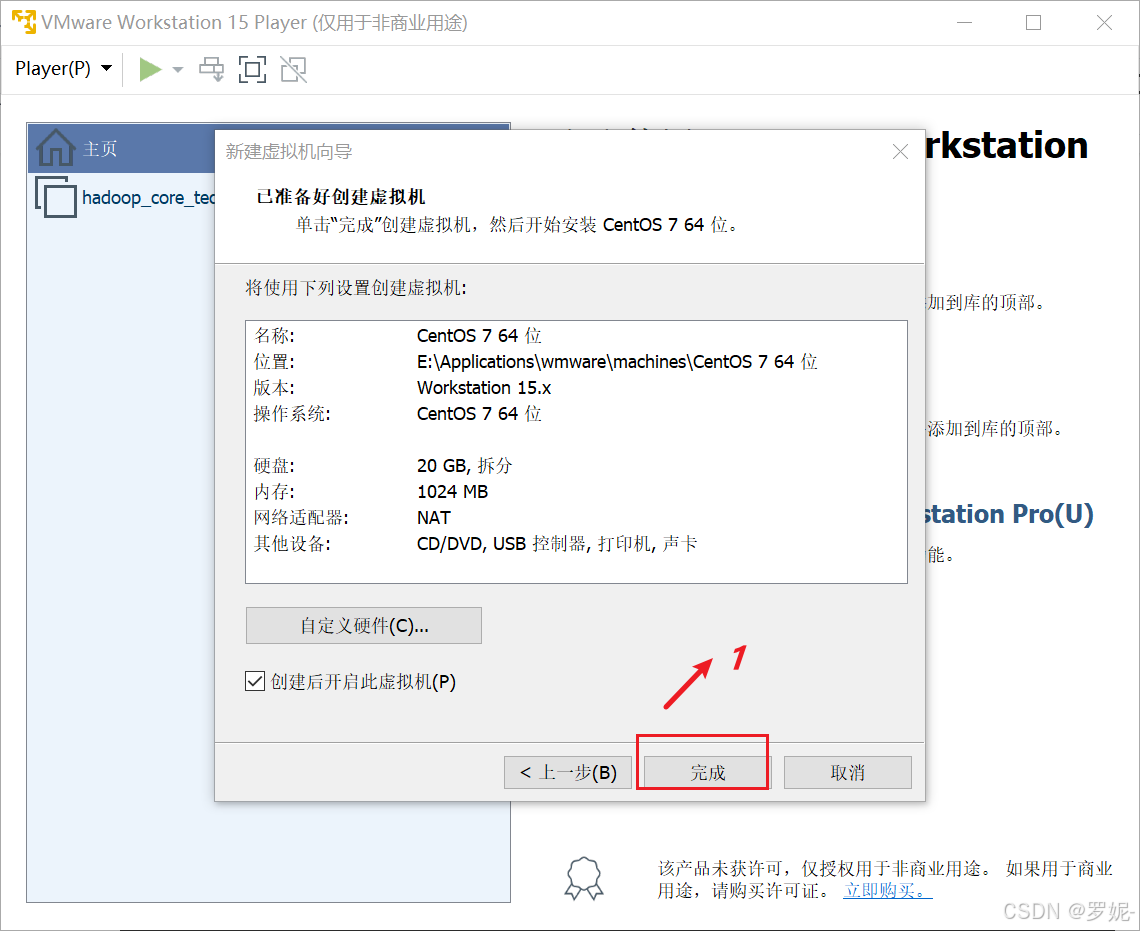
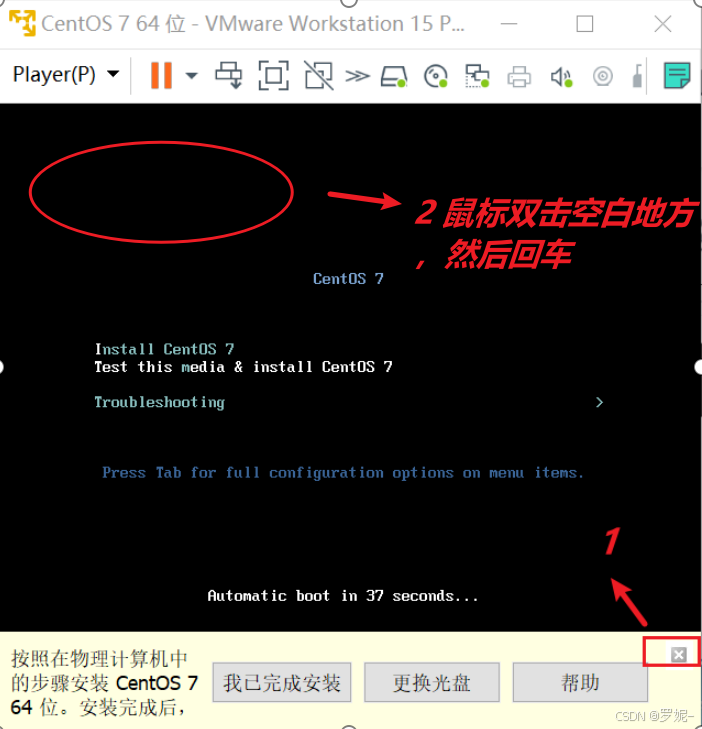
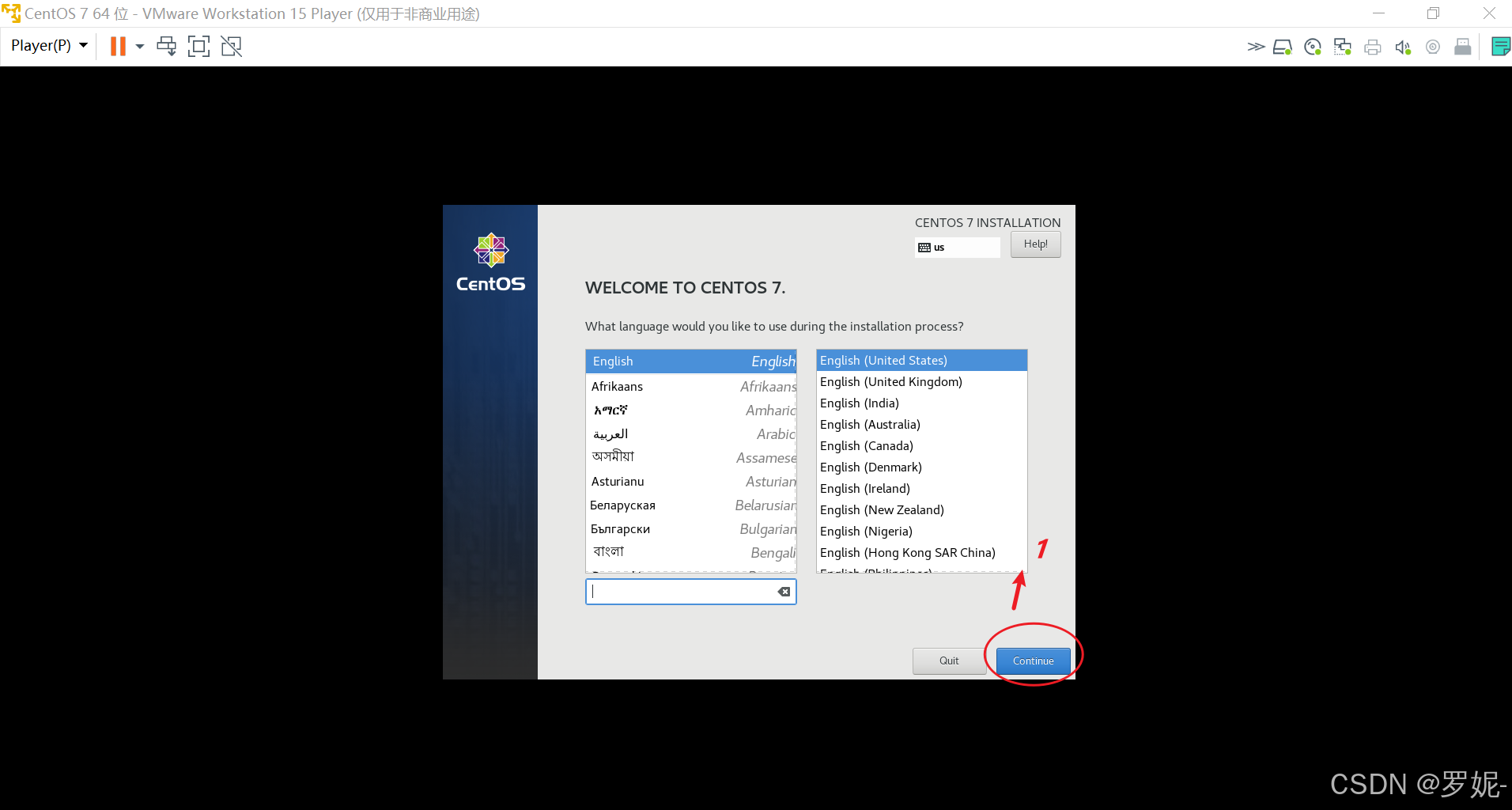
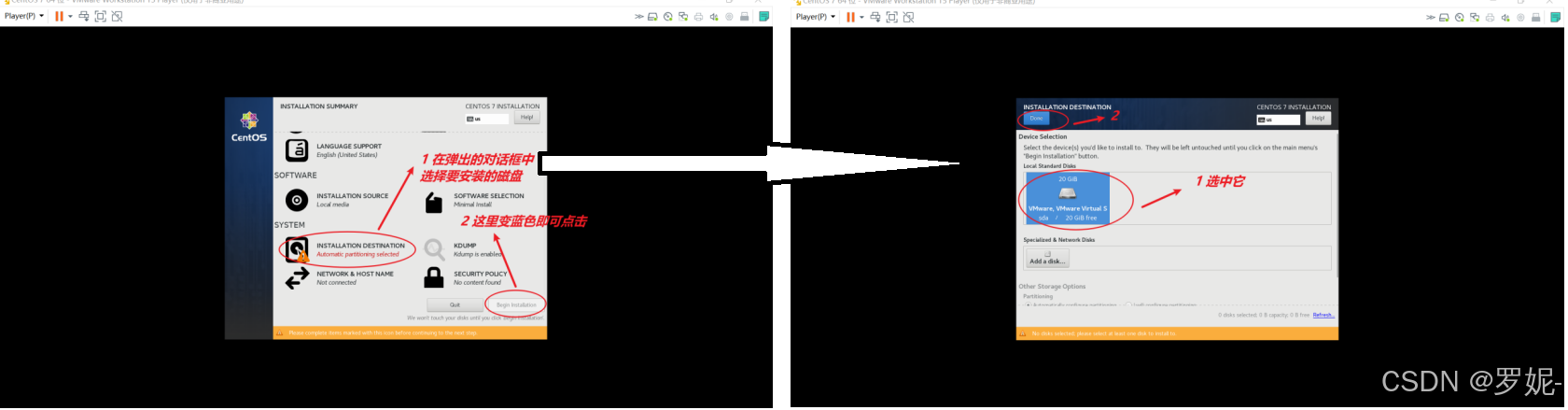
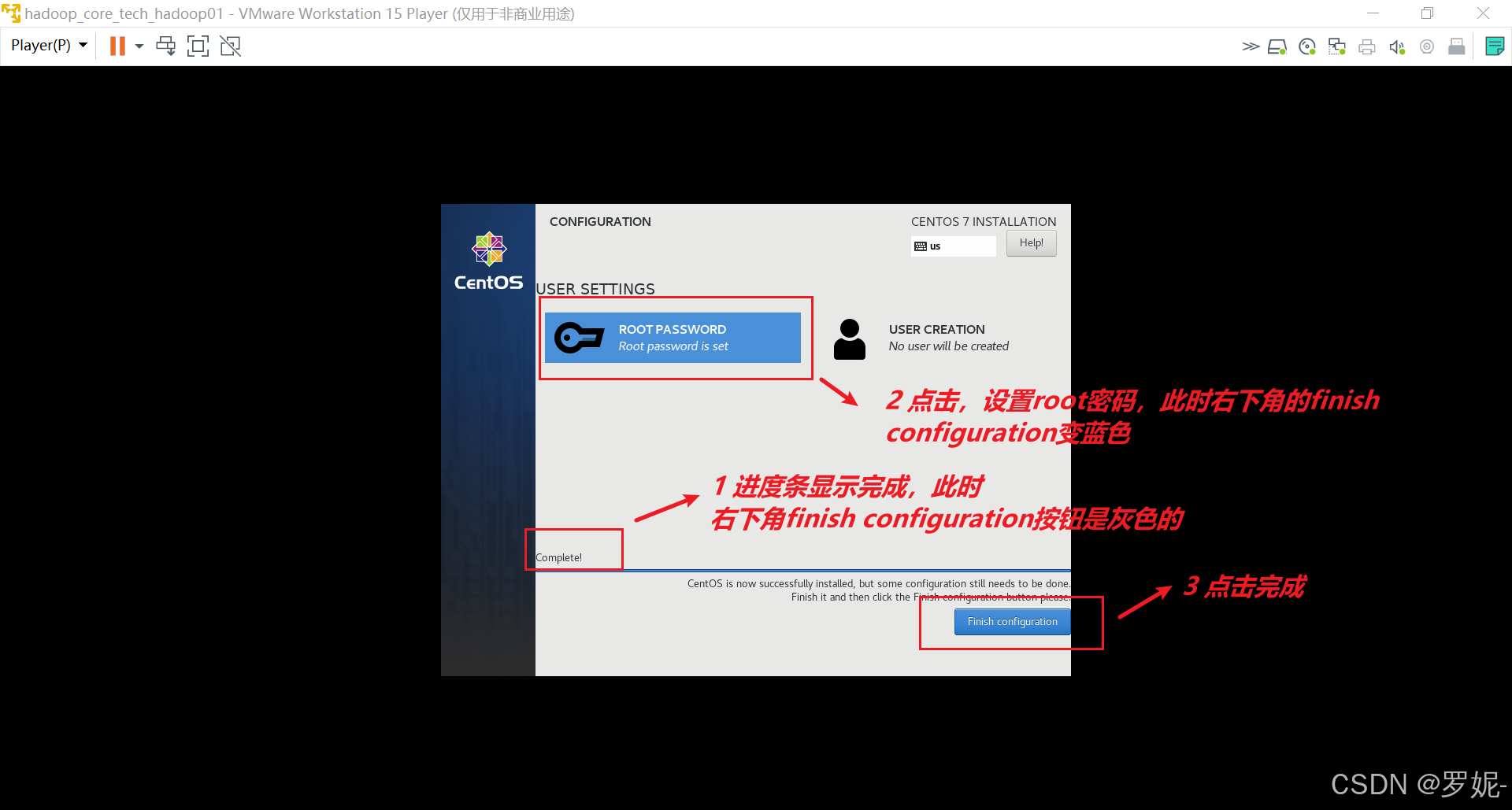
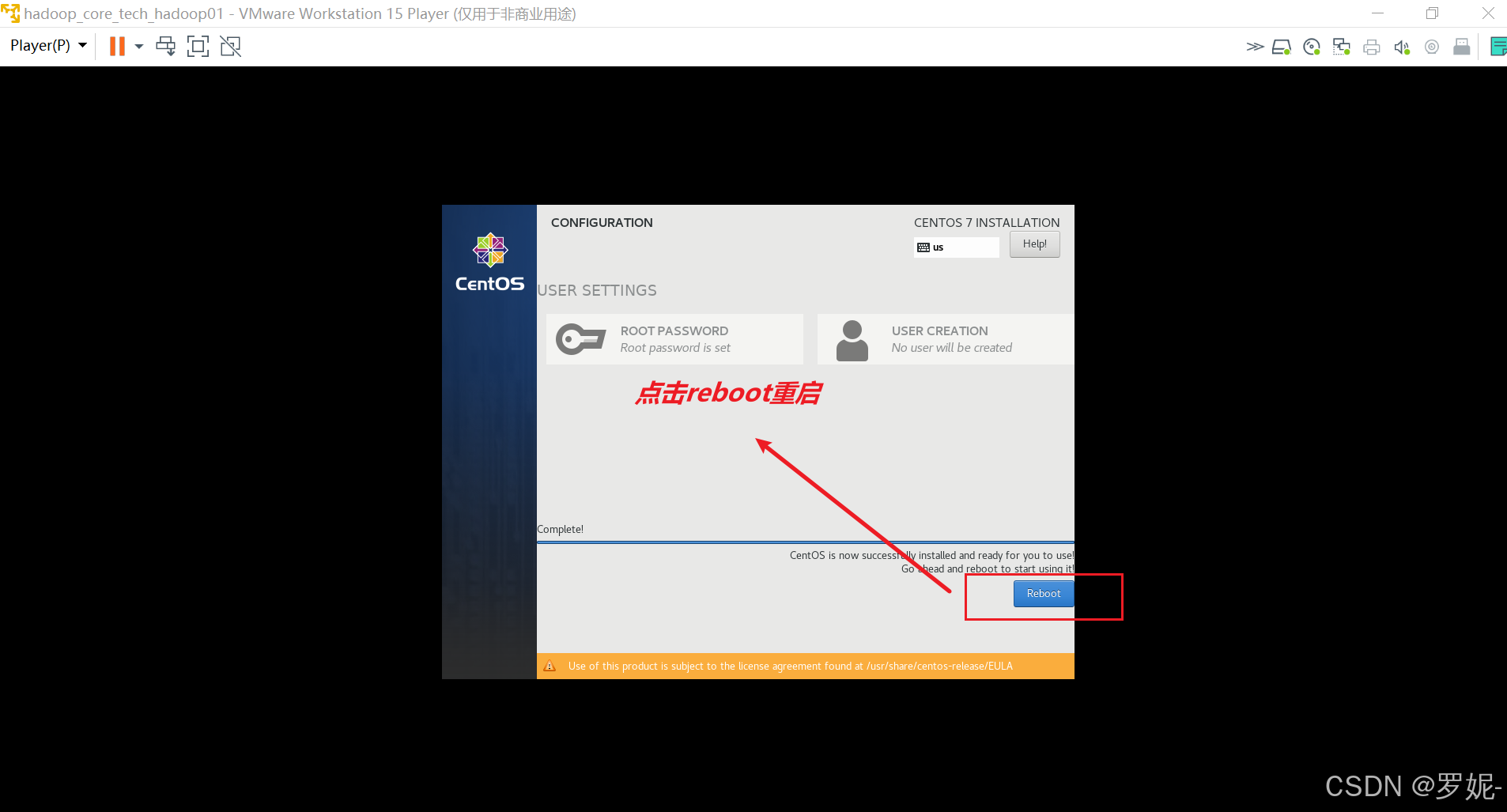
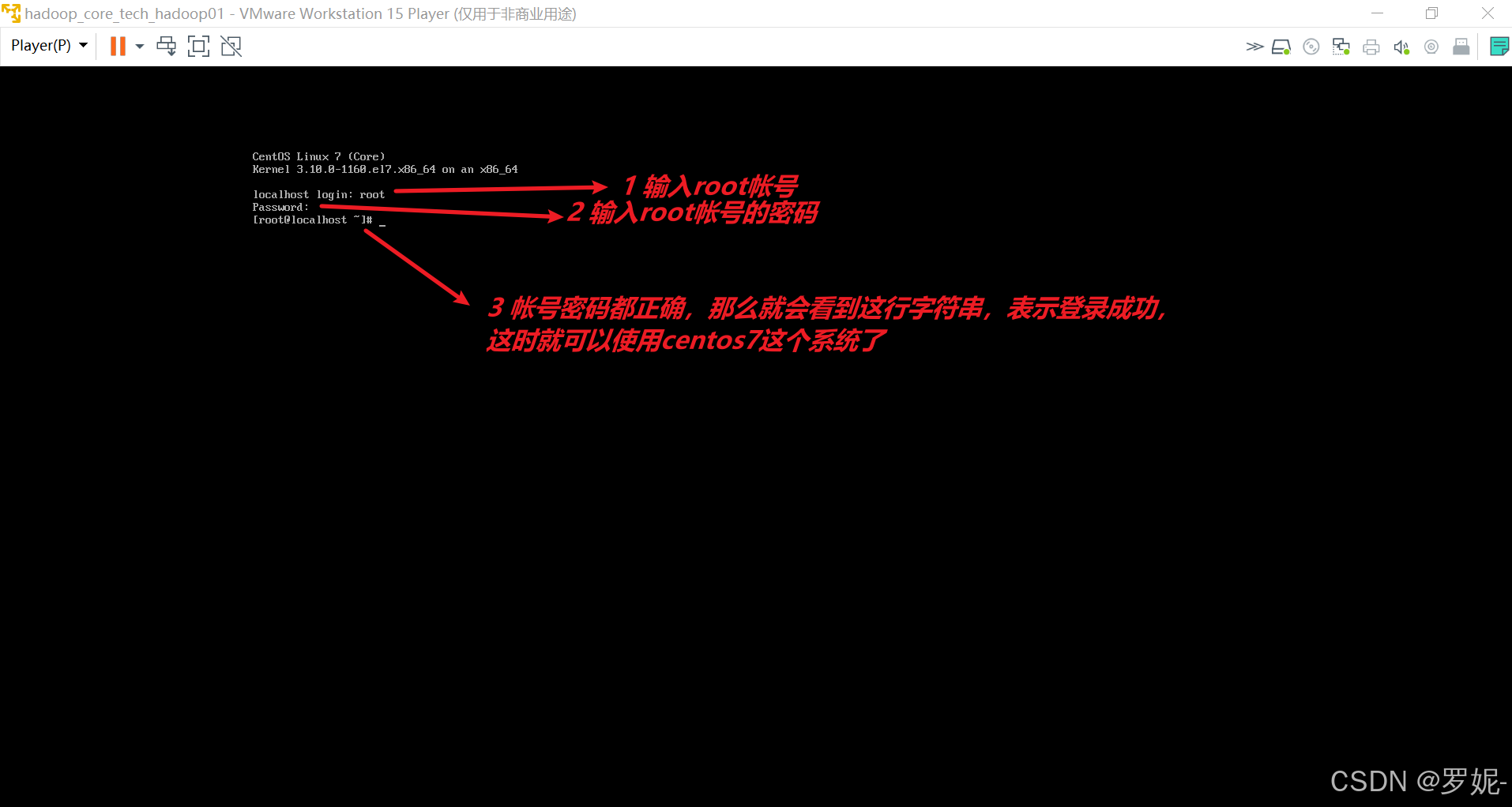
以下是在 Ubuntu 系统上安装 Hadoop 的基本步骤:
(一)安装 Java 环境
Hadoop 是基于 Java 开发的,因此首先需要安装 Java。
sudo apt - get update
sudo apt - get install default - jdk通过以上命令可以在 Ubuntu 系统上安装默认的 JDK 版本。
(二)下载和解压 Hadoop
- 从 Hadoop 官方网站(Apache Hadoop)下载适合版本的 Hadoop。
- 解压下载的文件到指定目录,例如:
tar - xzf hadoop - 3.3.4. tar.gz - C /usr/local/
cd /usr/local/
sudo mv hadoop - 3.3.4 hadoop(三)配置 Hadoop 环境变量
编辑~/.bashrc文件,添加以下内容:
(四)配置 Hadoop 核心文件
core - site.xml- 配置 HDFS 的默认文件系统和临时目录。
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
</configuration>2.hdfs - site.xml
- 配置 HDFS 的副本数量等参数。
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>3.mapred - site.xml
- 配置 MapReduce 的框架为 YARN。
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>4.yarn - site.xml
- 配置 YARN 的相关参数,如资源管理器地址等。
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>localhost</value>
</property>
<property>
<name>yarn.nodemanager.aux - services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>(五)格式化 HDFS
在首次启动 Hadoop 之前,需要对 HDFS 进行格式化:
hdfs namenode - format(六)启动 Hadoop
1.启动 HDFS:
start - dfs.sh2.启动 YARN:
start - yarn.sh四、简单的 Hadoop 应用示例 - 单词计数
以下是一个使用 Hadoop MapReduce 实现单词计数的 Java 代码示例:
(一)Map 类
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] words = line.split(" ");
for (String w : words) {
word.set(w);
context.write(word, one);
}
}
}在 Map 类中,我们将输入的文本行分割成单词,并为每个单词生成 <单词,1> 的中间结果。
(二)Reduce 类
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable>{
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
context.write(key, new IntWritable(sum));
}
}在 Reduce 类中,我们将相同单词对应的所有 1 相加,得到单词的出现次数。
(三)主类
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputPath;
import org.apache.hadoop.mapreduce.lib.output.FileOutputPath;
import java.io.IOException;
public class WordCount {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputPath.addInputPath(job, new Path(args[0]));
FileOutputPath.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true)? 0 : 1);
}
}主类用于配置和提交 MapReduce 作业,指定输入路径和输出路径,并调用 Map 和 Reduce 类来执行单词计数操作。
五、HDFS 常用命令
文件系统操作
- 创建目录
- 命令格式:
hdfs dfs -mkdir [options] <path> - 例如,在 HDFS 根目录下创建一个名为
testdir的目录:hdfs dfs -mkdir /testdir
- 命令格式:
- 查看目录内容
- 命令格式:
hdfs dfs -ls [options] <path> - 例如,查看 HDFS 根目录下的内容:
hdfs dfs -ls /
- 命令格式:
- 上传文件
- 命令格式:
hdfs dfs -put <localSrc>... <dst> - 例如,将本地文件
/home/user/data.txt上传到 HDFS 的/testdir目录下:hdfs dfs -put /home/user/data.txt /testdir
- 命令格式:
- 下载文件
- 命令格式:
hdfs dfs -get <src> <localDst> - 例如,将 HDFS 中的
/testdir/data.txt下载到本地/home/user/downloads目录:hdfs dfs -get /testdir/data.txt /home/user/downloads
- 命令格式:
- 删除文件或目录
- 命令格式:
hdfs dfs -rm [options] <path>(删除文件)和hdfs dfs -rm -r [options] <path>(递归删除目录) - 例如,删除 HDFS 中的
/testdir/data.txt文件:hdfs dfs -rm /testdir/data.txt - 例如,递归删除 HDFS 中的
/testdir目录:hdfs dfs -rm -r /testdir
- 命令格式:
- 创建目录
文件权限操作
- 查看文件权限
- 命令格式:
hdfs dfs -ls -d <path> - 例如,查看 HDFS 中
/testdir目录的权限:hdfs dfs -ls -d /testdir
- 命令格式:
- 修改文件权限
- 命令格式:
hdfs dfs -chmod [-R] <MODE[,MODE]... | OCTALMODE> <path> - 例如,将
/testdir目录及其子目录和文件的权限设置为 755:hdfs dfs -chmod -R 755 /testdir
- 命令格式:
- 查看文件权限
文件复制操作
- 在 HDFS 内部复制文件
- 命令格式:
hdfs dfs -cp [options] <src> <dst> - 例如,将 HDFS 中的
/testdir/data.txt复制到/testdir/copydata.txt:hdfs dfs -cp /testdir/data.txt /testdir/copydata.txt
- 命令格式:
- 在 HDFS 内部复制文件
一、 文件路径增删改查
| 命令 | 功能 |
| hdfs dfs -mkdir dir | 创建文件夹 |
| hdfs dfs -rmr dir | 删除文件夹dir |
| hdfs dfs -ls | 查看目录文件信息 |
| hdfs dfs -lsr | 递归查看文件目录信息 |
| hdfs dfs -stat path | 返回指定路径的信息 |
二、空间大小查看
| 命令 | 功能 |
| hdfs dfs -du -h dir | 按照适合阅读的形式人性化显示文件大小 |
| hdfs dfs -dus uri | 递归显示目标文件的大小 |
| hdfs dfs -du path/file | 显示目标文件file的大小 |
三、判断
| 命令 | 功能 |
| hdfs fs -test -e /dir/a.txt | 判断文件是否存在,正0负1 |
| hdfs fs -test -d /dir | 判断dir是否为目录,正0负1 |
| hdfs fs -test -z /dir/a.txt | 判断文件是否为空,正0负1 |
四、运行pipies作业
- hdfs pipes -conf 作业的配置
hdfs pipes -conf /home/user/pipes_conf.xml- hdfs pipes -jobconf <key=value>, <key=value>, … 增加/覆盖作业的配置项
hdfs pipes -jobconf mapreduce.map.memory.mb=1024,mapreduce.reduce.memory.mb=2048- hdfs pipes -input 输入目录
hdfs pipes -input /input_data- hdfs pipes -output 输出目录
hdfs pipes -output /output_data- hdfs pipes -jar Jar文件名
hdfs pipes -jar /home/user/jars/my_pipes_job.jar- hdfs pipes -inputformat InputFormat类
hdfs pipes -inputformat org.apache.hadoop.mapred.TextInputFormat- hdfs pipes -map Java Map类
hdfs pipes -map com.example.MyMapClass- hdfs pipes -partitioner Java Partitioner
hdfs pipes -partitioner com.example.MyPartitioner- hdfs pipes -reduce Java Reduce类
hdfs pipes -reduce com.example.MyReduceClass- hdfs pipes -writer Java RecordWriter
hdfs pipes -writer com.example.MyRecordWriter基于 Hadoop MapReduce 的扩展词频统计示例(Java 实现)
1. 处理复杂文本格式的 Mapper 类(例如包含标点符号、大小写混合等情况)
import java.io.IOException;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class AdvancedWordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
// 定义正则表达式来匹配单词,这里可以处理包含标点符号、大小写混合等情况
private static final Pattern WORD_PATTERN = Pattern.compile("\\w+([-']\\w+)*");
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString().toLowerCase(); // 先统一转换为小写,方便后续统计
Matcher matcher = WORD_PATTERN.matcher(line);
while (matcher.find()) {
String matchedWord = matcher.group();
word.set(matchedWord);
context.write(word, one);
}
}
}在这个扩展的 Mapper 类中,我们使用了正则表达式来更精准地匹配文本中的单词,它可以处理包含连字符、撇号等情况的单词,同时将文本统一转换为小写字母形式,使得统计词频时能忽略大小写差异,更符合实际复杂文本处理的需求。
2. 基于词频统计进行额外数据分析的 Reducer 类(例如统计高频词和低频词)
import java.io.IOException;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.List;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class AdvancedWordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private static final int TOP_N = 10; // 定义统计高频词的数量
private static final int BOTTOM_N = 10; // 定义统计低频词的数量
private List<WordCountPair> wordCountList = new ArrayList<>();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
wordCountList.add(new WordCountPair(key.toString(), sum));
// 正常输出每个单词及其词频
context.write(key, new IntWritable(sum));
}
@Override
protected void cleanup(Context context) throws IOException, InterruptedException {
// 对所有单词按照词频进行排序
Collections.sort(wordCountList, Comparator.comparingInt(WordCountPair::getCount).reversed());
// 输出高频词
context.write(new Text("Top " + TOP_N + " High Frequency Words:"), new IntWritable(0));
for (int i = 0; i < TOP_N && i < wordCountList.size(); i++) {
WordCountPair pair = wordCountList.get(i);
context.write(new Text(pair.getWord()), new IntWritable(pair.getCount()));
}
// 输出低频词
context.write(new Text("Bottom " + BOTTOM_N + " Low Frequency Words:"), new IntWritable(0));
for (int i = wordCountList.size() - 1; i >= wordCountList.size() - BOTTOM_N && i >= 0; i--) {
WordCountPair pair = wordCountList.get(i);
context.write(new Text(pair.getWord()), new IntWritable(pair.getCount()));
}
}
// 内部类用于存储单词和其词频的对应关系,方便排序和后续操作
private static class WordCountPair {
private String word;
private int count;
public WordCountPair(String word, int count) {
this.word = word;
this.count = count;
}
public String getWord() {
return word;
}
public int getCount() {
return count;
}
}
}这个 Reducer 类在完成常规的词频统计累加并输出每个单词词频的基础上,通过一个内部类 WordCountPair 来存储单词及其词频信息,将所有单词的统计信息收集到一个列表中,在 cleanup 方法里(cleanup 方法在每个 Reducer 处理完所有输入数据后执行一次)对列表按照词频进行排序,进而分别输出高频词和低频词的相关信息,实现了更深入的数据挖掘和分析功能。
3. 驱动类(用于配置和提交作业)
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class AdvancedWordCountDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "advanced word count");
job.setJarByClass(AdvancedWordCountDriver.class);
job.setMapperClass(AdvancedWordCountMapper.class);
job.setReducerClass(AdvancedWordCountReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true)? 0 : 1);
}
}驱动类与之前基本的词频统计示例类似,主要是配置作业参数,指定新的 Mapper 和 Reducer 类,定义输入输出的键值对类型以及输入输出路径等,然后提交作业并根据作业完成情况返回相应的退出码。
使用 Hadoop Streaming 实现扩展词频统计(Python 实现)
1. 处理复杂文本格式的 Mapper 脚本(advanced_mapper.py)
#!/usr/bin/env python
import re
import sys
# 定义正则表达式来匹配单词,可处理更复杂格式,如包含标点、大小写混合等情况
word_pattern = re.compile(r"\w+([-']\w+)*")
for line in sys.stdin:
line = line.lower() # 转换为小写
words = word_pattern.findall(line)
for word in words:
print(f"{word}\t1")这个 Mapper 脚本使用 Python 的正则表达式模块 re 来更准确地提取文本中的单词,同样先将文本转换为小写形式后再进行单词匹配,使其能处理各种复杂的文本输入格式,然后按照 单词 \t 1 的格式输出到标准输出供 Reducer 使用。
2. 基于词频统计进行额外数据分析的 Reducer 脚本(advanced_reducer.py)
#!/usr/bin/env python
import sys
from collections import defaultdict
from heapq import nlargest, nsmallest
TOP_N = 10 # 定义统计高频词的数量
BOTTOM_N = 10 # 定义统计低频词的数量
word_count_dict = defaultdict(int)
for line in sys.stdin:
word, count = line.strip().split('\t')
count = int(count)
word_count_dict[word] += count
# 正常输出每个单词及其词频
for word, count in word_count_dict.items():
print(f"{word}\t{count}")
# 统计高频词
high_frequency_words = nlargest(TOP_N, word_count_dict.items(), key=lambda x: x[1])
print("Top {} High Frequency Words:".format(TOP_N))
for word, count in high_frequency_words:
print(f"{word}\t{count}")
# 统计低频词
low_frequency_words = nsmallest(BOTTOM_N, word_count_dict.items(), key=lambda x: x[1])
print("Bottom {} Low Frequency Words:".format(BOTTOM_N))
for word, count in low_frequency_words:
print(f"{word}\t{count}")在这个扩展的 Reducer 脚本中,使用 defaultdict 来方便地统计每个单词的词频,先完成常规的词频输出后,借助 Python 的 heapq 模块中的 nlargest 和 nsmallest 函数分别找出词频最高的 TOP_N 个单词和词频最低的 BOTTOM_N 个单词,并输出相应的高频词和低频词信息,实现了更深入的数据挖掘分析功能。
3. 运行命令示例
与之前 Hadoop Streaming 词频统计示例类似,假设你已经将上述两个 Python 脚本上传到 Hadoop 集群环境中,且有相应的输入文本文件(例如在 HDFS 中的 /input/complex_words.txt 路径下),要将输出结果存放到 /output/advanced_wordcount 路径,可以使用以下命令来运行基于 Hadoop Streaming 的扩展词频统计作业
hadoop jar /path/to/hadoop-streaming.jar \
-input /input/complex_words.txt \
-output /output/advanced_wordcount \
-mapper advanced_mapper.py \
-reducer advanced_reducer.py \
-file advanced_mapper.py \
-file advanced_reducer.py六、YARN 命令
查看集群状态
- 命令格式:
yarn cluster -list -all - 此命令可以查看整个 YARN 集群的状态信息,包括节点数量、资源使用情况等。
- 命令格式:
提交作业
- 命令格式(以 MapReduce 作业为例):
yarn jar <jar - file> [main - class] args... - 例如,提交一个名为
wordcount.jar的 MapReduce 作业:yarn jar wordcount.jar com.example.WordCount input output,其中input是输入路径,output是输出路径。
- 命令格式(以 MapReduce 作业为例):
查看作业状态
命令格式:
yarn application -list此命令可以列出当前 YARN 集群中正在运行和已经完成的作业信息,包括作业 ID、状态、用户等。
查看特定作业详细信息:
yarn application -status <application - id>例如,查看作业 ID 为
application_12345的详细状态:yarn application -status application_12345
七、学习hadoop会遇到的问题
- 环境配置问题
- Java 环境问题
- 未安装或版本不兼容:Hadoop 是基于 Java 开发的,若未安装 Java 或者 Java 版本与 Hadoop 要求不匹配,会导致启动失败。例如,Hadoop 3.x 通常要求 Java 8 或更高版本,若安装了 Java 7,在启动 Hadoop 进程时会报错。
- 环境变量设置错误:
JAVA_HOME等环境变量如果设置错误,Hadoop 无法正确找到 Java 运行环境。比如路径中包含空格或者指向错误的 Java 安装目录,会使得 Hadoop 的相关脚本(如启动脚本)无法正常执行。
- Hadoop 配置文件问题
- 配置参数错误:在配置文件(如
core - site.xml、hdfs - site.xml、mapred - site.xml和yarn - site.xml)中,参数设置不当会引发各种问题。例如,在core - site.xml中设置的fs.defaultFS参数如果格式错误或者指向不存在的 HDFS 服务地址,将无法正确访问 HDFS。 - 文件格式错误:配置文件必须是正确的 XML 格式。如果 XML 标签不匹配、缺少闭合标签或者存在语法错误,在启动 Hadoop 服务时会导致解析失败。
- 配置参数错误:在配置文件(如
- 网络配置问题
- 节点间通信故障:在 Hadoop 集群环境中,节点之间需要通过网络进行通信。如果网络设置(如防火墙规则、IP 地址配置、端口开放等)存在问题,会导致 DataNode 无法向 NameNode 发送心跳信号,或者 ResourceManager 无法与 NodeManager 通信,影响集群的正常运行。
- 主机名解析问题:如果主机名无法正确解析,Hadoop 服务可能无法启动或者出现节点识别错误。例如,在配置文件中使用主机名来指定服务地址,但没有在 DNS 服务器或者
/etc/hosts文件中正确配置主机名与 IP 地址的映射关系。
- Java 环境问题
- 数据存储与读取问题
- HDFS 存储问题
- 数据块损坏或丢失:由于硬件故障、网络问题或者软件错误,存储在 HDFS 中的数据块可能会损坏或丢失。HDFS 有数据冗余机制(通过副本数量来保证数据可靠性),但如果多个副本同时出现问题,会导致数据丢失。
- 存储空间不足:没有合理规划磁盘空间,或者随着数据的不断积累,HDFS 存储空间不足。这可能导致新数据无法写入,甚至影响整个集群的正常运行。
- 数据读取性能问题
- 数据分布不均:如果数据在 HDFS 中的分布不均匀,某些 DataNode 存储的数据过多,而其他 DataNode 空闲,会导致读取数据时出现热点问题,部分节点负载过重,影响数据读取效率。
- 小文件问题:HDFS 适合存储大文件,过多的小文件会占用 NameNode 大量的内存来存储元数据,并且在读取这些小文件时,会增加大量的文件打开和关闭操作,降低读取性能。
- HDFS 存储问题
- 编程与应用开发问题
- MapReduce 编程问题
- 逻辑错误:在编写 MapReduce 程序时,很容易出现逻辑错误。例如,在 Mapper 类中对输入数据的处理不符合预期,或者 Reducer 类中对中间结果的聚合方式错误,导致最终计算结果不准确。
- 数据类型不匹配:MapReduce 程序中,输入输出的数据类型需要严格匹配。如果在 Mapper 和 Reducer 之间的数据类型定义不一致,会导致程序运行时出现类型转换错误。
- 性能问题:没有合理优化 MapReduce 程序,可能导致性能低下。例如,没有充分利用并行计算的优势,或者在数据传输过程中产生过多的冗余数据,增加网络和磁盘 I/O 开销。
- 与其他框架或工具集成问题
- 与数据库集成:当尝试将 Hadoop 与数据库(如 MySQL、HBase)集成时,可能会遇到连接问题、数据格式转换问题或者事务处理问题。例如,在将 MapReduce 计算结果存储到数据库时,由于数据量过大或者数据库的写入性能限制,导致存储失败。
- 与数据处理工具集成:如果要结合其他数据处理工具(如 Spark、Flink)使用 Hadoop,需要解决框架之间的兼容性问题、资源竞争问题以及数据共享和转换问题。
- MapReduce 编程问题
八、学习心得
(一)对分布式系统的理解
通过学习 Hadoop,我对分布式系统有了更深入的理解。Hadoop 的架构设计使得它能够在集群环境下高效地处理大规模数据。在分布式系统中,数据被分散存储在多个节点上,通过网络进行通信和协作。Hadoop 的 HDFS 通过数据块的复制和分布式存储,保证了数据的可靠性和高可用性,而 MapReduce 编程模型则为处理大规模数据提供了一种简单而有效的方法。
(二)编程思维的转变
在编写 Hadoop 应用程序时,需要从传统的单机编程思维转变为分布式编程思维。在 MapReduce 模型中,我们需要考虑如何将问题分解成 Map 和 Reduce 两个阶段,并且要注意数据在不同节点之间的传输和处理。这种编程思维的转变对于提高数据处理效率和解决大规模数据问题非常重要。
(三)实践中的挑战与解决
在安装和配置 Hadoop 的过程中,遇到了许多问题,例如环境变量配置错误、网络连接问题等。通过查阅官方文档和在线论坛,逐步解决了这些问题。在实际编写 MapReduce 程序时,也遇到了数据类型不匹配、逻辑错误等问题。通过调试和优化代码,最终实现了正确的功能。这些实践经验让我明白,在学习新技术时,实践操作和解决问题的能力是非常重要的。
九、总结
Hadoop 是大数据领域中非常重要的技术之一,通过对 Hadoop 的学习和实践,我不仅掌握了其基本架构和操作方法,还培养了分布式编程思维和解决实际问题的能力。在未来的学习和工作中,我将继续深入研究 Hadoop 及其相关技术,探索更多大数据处理的应用场景。