Lecture 16 Ray Tracing 4_哔哩哔哩_bilibili
老师说的“高频采样”问题是什么?
现在考虑一个特殊情况:
❗ 一个像素内,图像信号变化很剧烈(高频):
比如:
细网格纹理
马赛克背景
很高频的条纹图案
但是 GPU 只对每个像素执行一次采样(比如中心点),就会发生:
| 真实像素区域图像 | 实际采样点获取值 | 显示出来的颜色 |
|---|---|---|
| 黑白黑白黑白 | 中间采到了白 | 整个像素显示为白 |
| 实际应该是混色 | 却显示纯白 | ❗ 出现“走样(aliasing)” |
这就叫做欠采样。
🎯 信号处理的对应概念是什么?
你老师说的是「采样定理(奈奎斯特定理)」:
一个信号要被正确重构,采样频率必须至少是信号最高频率的两倍。
也就是说:
如果一个像素区域的真实图案变化频率很高(很多细节)
但你只采了一个点
那你就永远无法重构真实内容
还会反过来得到错误的颜色信息(这就是走样 aliasing)
所以怎么办?
✅ 方案 1:使用 多重采样(MSAA)
一个像素内采多个点(4x, 8x)
平均它们的值 → 得到更真实的代表色
本质是把一个像素“当作一个小区域平均”
✅ 方案 2:使用 Mipmap
远处高频图案很容易 alias
Mipmap 自动降低频率(模糊贴图),防止采样混乱
❓“什么是高频图案?”它在图像中具体表现是什么?
频率在图像中是什么意思?
图像也可以被看作一个二维信号(像素强度的分布),频率指的是:
图像中亮度或颜色变化的快慢程度
举例对比(请脑中想象或画出):
| 图案 | 频率描述 |
|---|---|
| 🌫️ 渐变背景 | ✅ 低频(颜色变化慢,邻近像素差异小) |
| 🔲 棋盘格、条纹、马赛克 | ❗ 高频(颜色变化快,黑白快速交替) |
| 📷 照片中花纹细节 | 中频到高频(具体纹理结构) |
| 🌌 纯色背景 + 噪点 | 高频(噪点 = 快速变化的亮度值) |

| 场景 | 高频源头 |
|---|---|
| 贴图细节(砖墙、织布) | 细小花纹或对比强烈的结构 |
| UI元素缩放 | 尖锐边缘/线条密集导致高频 |
| 地面网格线、栅栏 | 黑白重复元素密度高 |
| 远处重复贴图 | 随着距离拉远,相同像素看见更密的细节 → 高频现象放大 |
❌ 频谱图上的每个点,并不对应原图中具体的“某个像素位置”,
✅ 它对应的是原图中的“某个方向 + 某个频率”上的波动强度。
频谱图中心的 0 点(频率为 0 的位置)表示原图的“平均亮度值”(也叫 DC 分量)。
✅ 中心点越亮,代表图像整体越亮;
❌ 它不表示图像中某个具体像素,而是整个图像的“亮度基准线”。
傅里叶变换会把图像分解成一堆正弦波分量:
每种
(u,v)频率 → 表示图像中某种周期性的结构强度其中
(u=0, v=0),即频率为 0,就是:
“整张图没有变化,只有一个常数值” → 也就是图像的平均亮度
图形渲染中用来解决贴图在斜角视图下模糊失真的问题的一种高级纹理采样技术。
各向异性过滤 = 让 GPU 在采样贴图时,按不同方向的分辨率差异,自适应使用更细的 mipmap、更多的采样点,以减少斜视模糊。
🧠 你为什么需要它?
来看一个非常典型的场景:
🎯 你有一张砖墙贴图,铺在地上:
当你正上方向下看时,砖纹理很清晰
但你以斜视角平贴地面往远处看时,地面变得很模糊、马赛克
👉 这是因为:
远处的贴图区域,在屏幕上压扁成了很薄的条
普通的各向同性采样(如双线性、三线性过滤)认为:
“你这个像素区域是正方形,选一张 mipmap 就够了”但实际上,像素区域被压缩成了长条(比如 1 像素高 × 20 像素宽),
→ 你需要用 长条形区域 来采样!
| 名称 | 中文 | 描述 | 单位 |
|---|---|---|---|
| Radiance | 辐射亮度 | 描述从某个表面向某个方向发出的“光的强度密度” | W / (m²·sr)(瓦每平方米每球面度) |
| Irradiance | 辐照度 | 描述单位表面上收到的光通量密度(不考虑方向) | W / m²(瓦每平方米) |
Prediction – assuming they won’t ever ask for depth, so the depth stays hidden
This is protective — and deeply human — but it builds a glass wall:

the formula on the slide is a fundamental expression in physically based rendering. It's called the Reflection Equation, and it computes how much light is reflected from a point on a surface in a particular direction.
为什么有人会说“一个像素打出多条 pass”?
✅ 可能来源一:Path Tracing 的“像素打出光线”
在路径追踪中,我们确实会说:
“从每个像素打出一条光线(eye ray)”,
然后这条光线会在场景中发生多次反弹 → 每一跳称为一次 path bounce
于是,有人可能误以为:
“Pixel 发出 Ray → Ray 产生多个 bounce → 就是 pixel 发出多个 pass?”
这只是 渲染算法的模拟过程,不是 Shader 中像素主动发起 Pass。
✅ GPU 对这个像素相关的片元 shader 多次执行,每个 pass 是渲染管线中的独立阶段
不是像素“打出了”什么,而是:
这个像素所在的位置,被多个 Pass 的渲染目标覆盖并处理
“一个像素点发出了多条光线路径用于 Monte Carlo 积分” ✅
This is called backward path tracing, and it's more computationally efficient because we:
Only trace light paths that contribute to what the camera sees
Avoid wasting rays that go to nowhere (which is common in real-world light simulation)
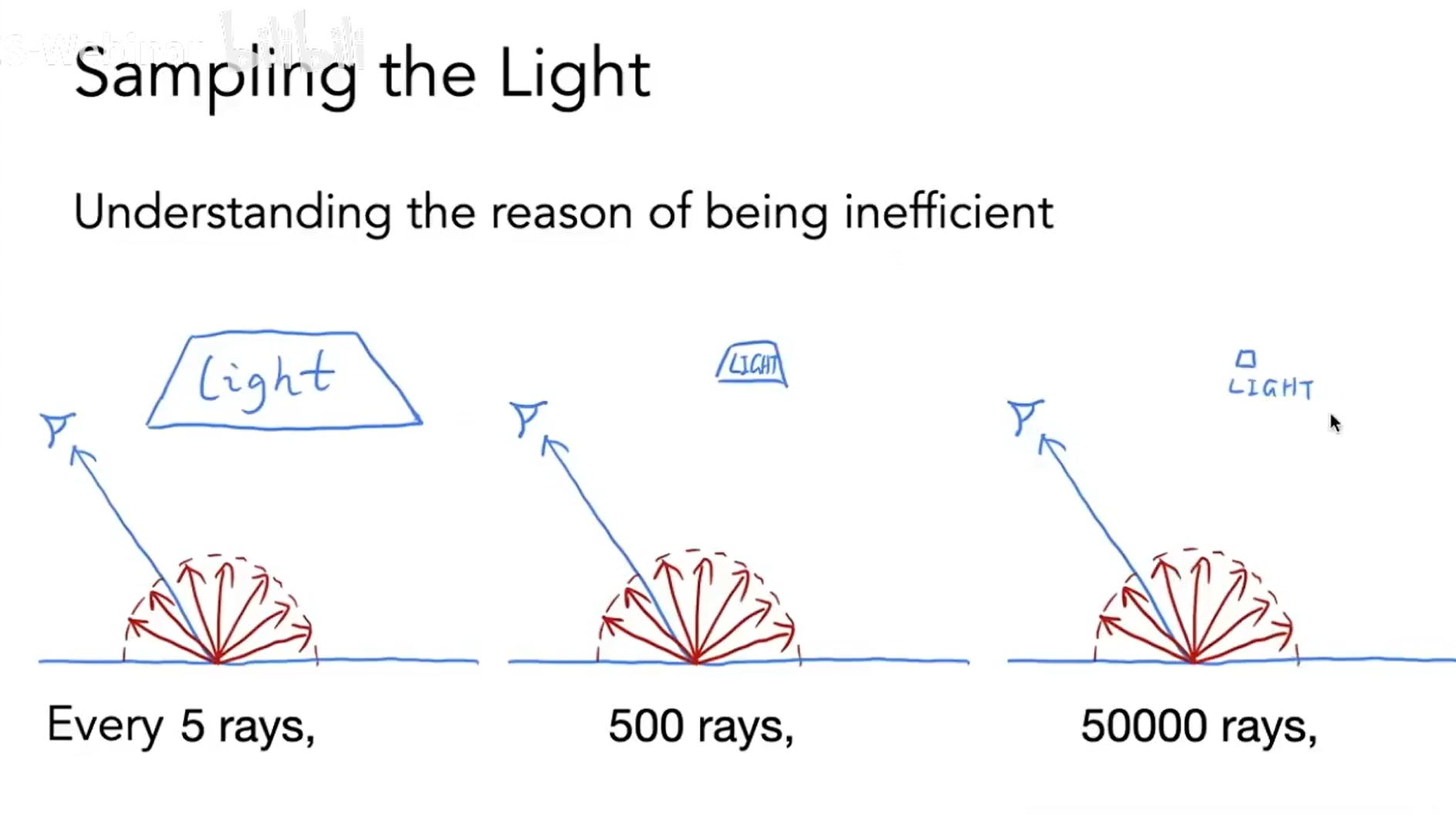
Whether the light source can reach or not is purely a matter of luck.


The purpose of integrating in rendering:
🎯 To compute how much light contributes to a point (like a pixel or a surface),
from all relevant directions, positions, or paths.
That is: integration lets us accumulate total light — across a domain like:
all incoming directions above a surface (solid angle)
all light-emitting surfaces (area)
all paths from eye to light (path space)
The true target of integration in rendering is:
🎯 The radiance arriving at the camera (eye) through a pixel.
That’s what we ultimately want to compute. Everything else — light, surface, BRDF, angles — is just how we get there.
🎯 The true purpose of all that integration — whether it’s over directions, surfaces, or paths —
is to compute how much radiance reaches the camera (or eye) through a pixel.

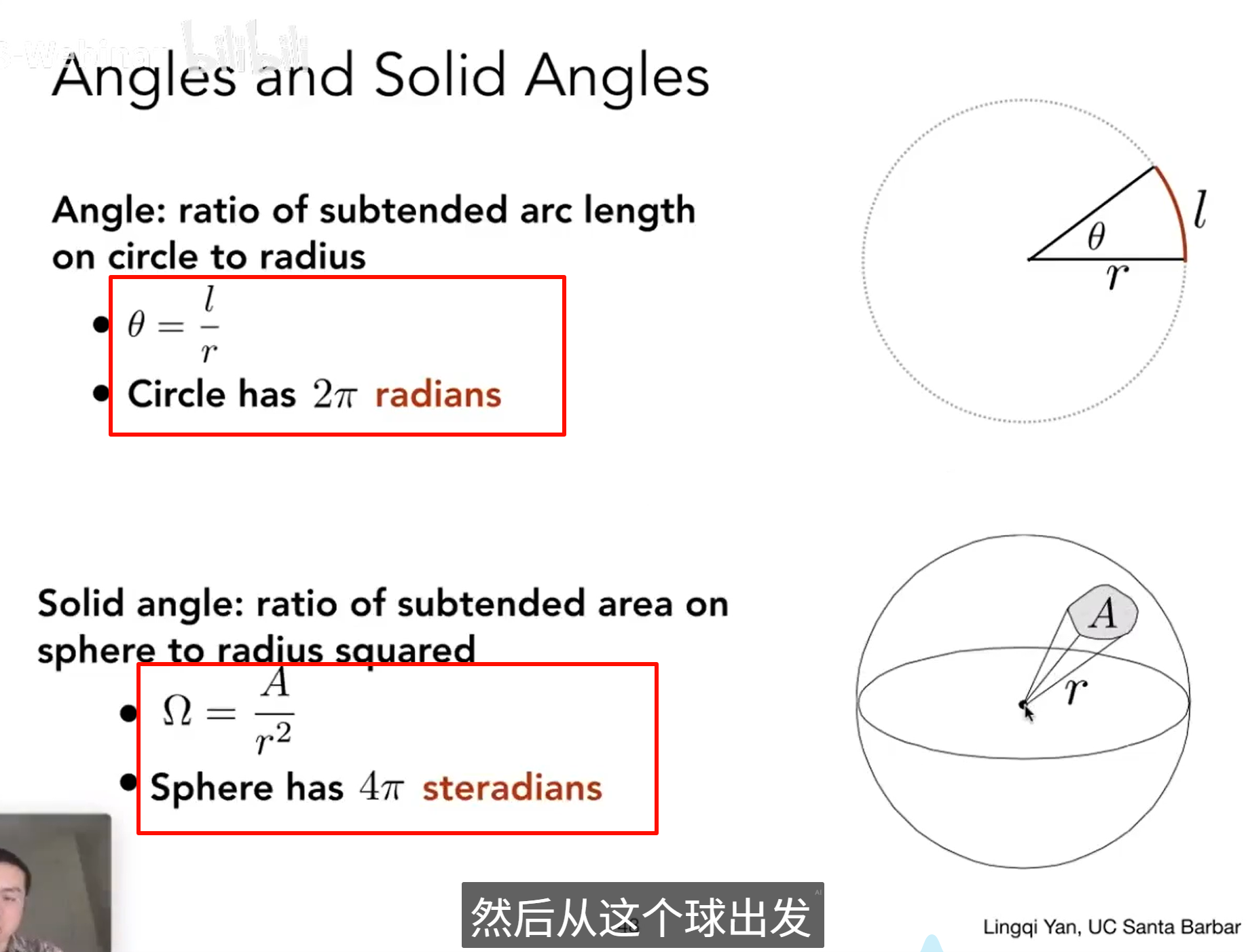
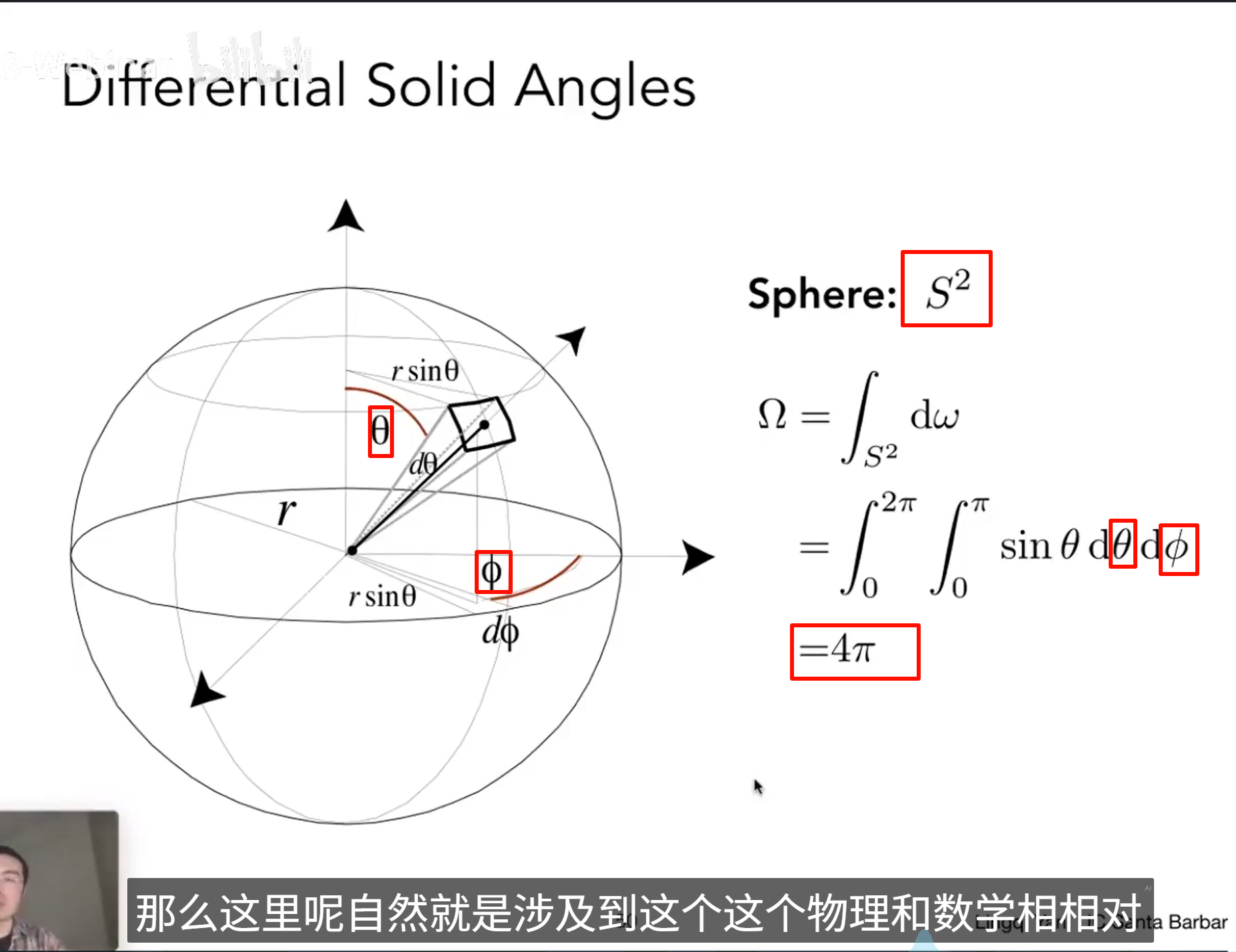
dω — Differential Solid Angle
✅ As long as it's implemented correctly, it keeps the rendering unbiased — only more noisy or less noisy.
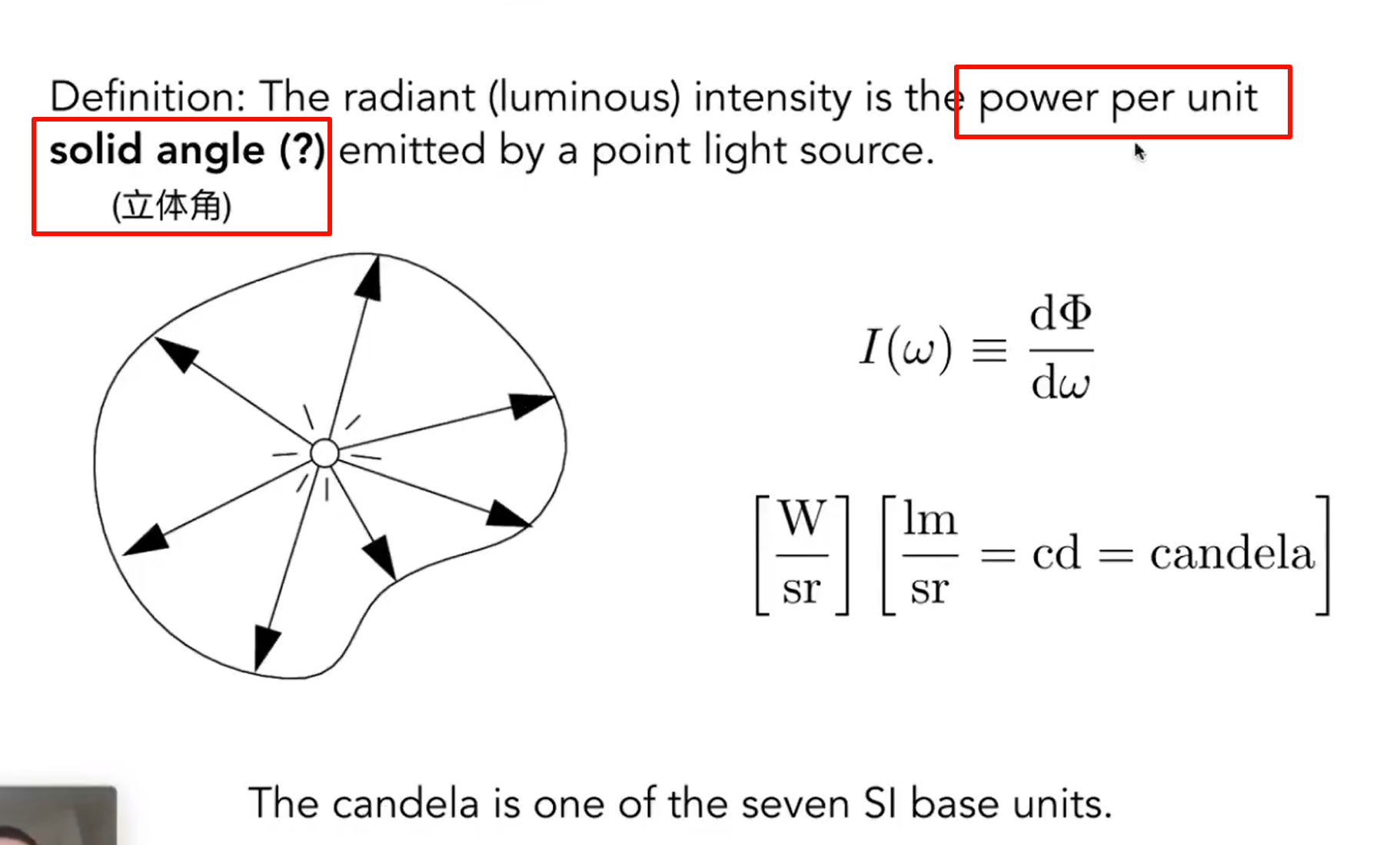

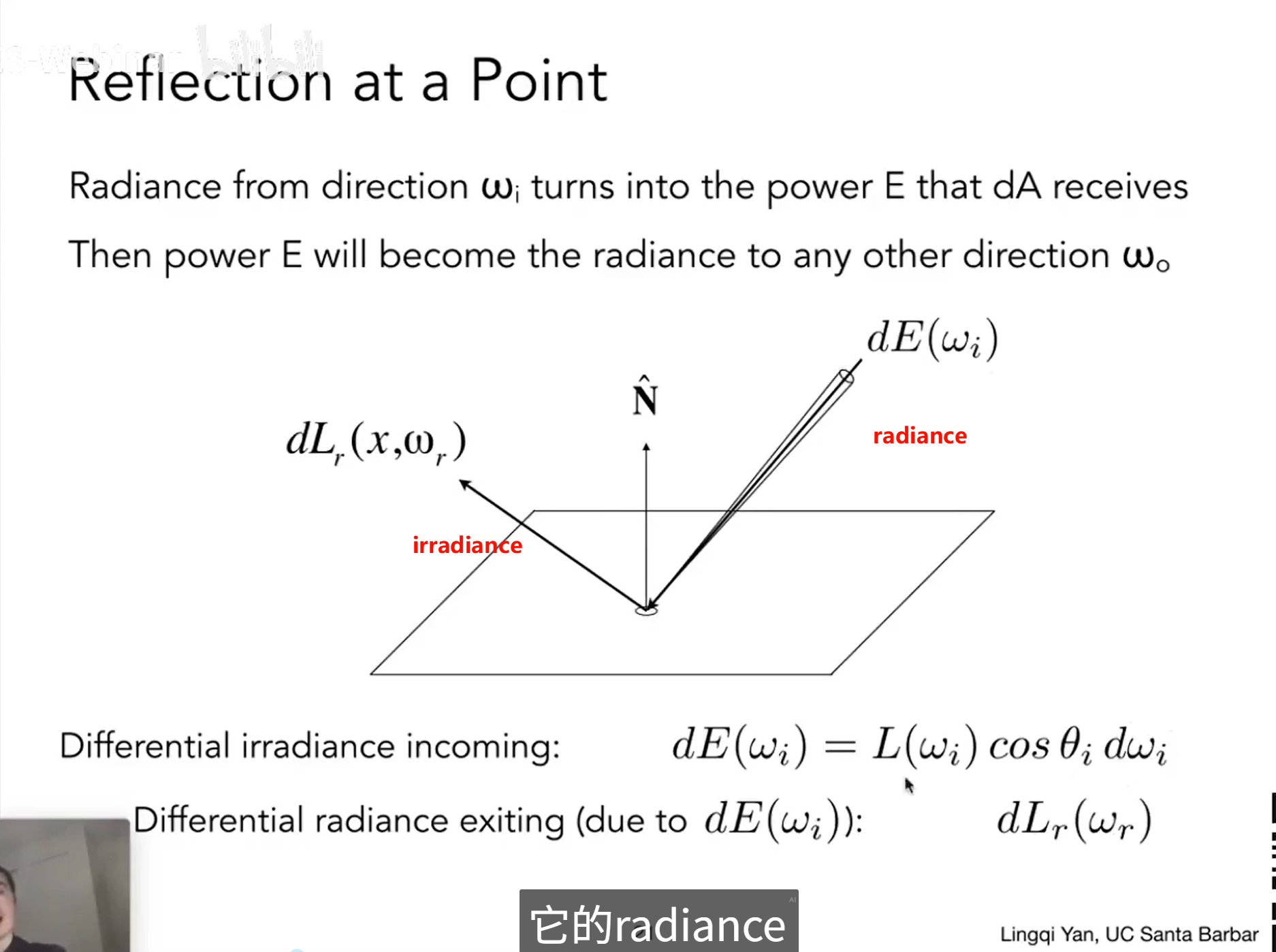
irradiance :power per unit area (incoming )
![]() this is power reference
this is power reference
![]() area reference
area reference
t should be noted that for the light that provides a calculable value of power, during the calculation process, it needs to be projected onto the normal line perpendicular to the area in order to be included in the irradiance.
----
and to distinguish from intensity:power per solid angle (outcoming)
they're all differential

their radiance values still come from the same global function L(x,ω)L(x, \omega)L(x,ω) — because radiance is a property of the scene, not of just one object.
It is a global field defined over the entire scene:
For any point xxx in the scene and any direction ω\omegaω,
L(x,ω)L(x, \omega)L(x,ω) tells you:
“What is the amount of light leaving that point in that direction?”
This means:
Whether xxx is on the wall, the table, or a teapot
Whether ω\omegaω is going up, down, or toward the camera
→ You always evaluate the same function LLL, just at different inputs.
Radiance L(xi,−ωi)L(x_i, -\omega_i)L(xi,−ωi) does not just depend on the light source —
it depends on everything that contributes light from point xix_ixi in direction −ωi-\omega_i−ωi.
That includes:
Light sources ✅
Reflected light from other surfaces ✅
Emission from that surface itself ✅
probability theory ------概率密度函数-----pdf
a discrete random variable.
Monte Carlo integration is a numerical method to approximate an integral using random sampling.
BRDF 全称是:
Bidirectional Reflectance Distribution Function
(双向反射分布函数)
它描述的是:
🔁 一个表面在一个方向接受光照(入射方向),
会以多大概率把光反射到另一个方向(出射方向)。


BRDF 决定了光在表面上“怎么反弹”,是连接光照与材质外观的数学桥梁。
“菲涅尔项”(Fresnel term)是 BRDF 中非常重要的一个物理因素,它描述的是:
💡 光在不同入射角时反射比例的变化,特别是随着视角接近掠射角(即表面平行)时,反射会急剧增强。
✅ 菲涅尔项(Fresnel term)解释
在现实中,当光线从一种介质(如空气)射向另一种介质(如水、金属)时:
部分光会反射
部分光会折射(透射进去)
反射部分的比例取决于入射角和材料的折射率,这个反射比例就是由 Fresnel 方程给出的。
🎯 菲涅尔效应的直觉效果:
| 入射角 | 反射比例(Fresnel) |
|---|---|
| 垂直入射(正面) | 比较低(偏向漫反射) |
| 斜入射(掠射角) | 很高(接近镜面) |
这解释了为什么你看玻璃/水的边缘特别亮:掠射角反射强!


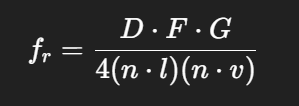 Cook-Torrance BRDF 的核心公式
Cook-Torrance BRDF 的核心公式
它假设每个表面是由很多微小镜面构成,
每个“微面”对光的反射行为类似镜子,但它们法线方向不同。
D:Microfacet Distribution Function(微表面分布项)
描述有多少微镜面朝向半角方向
常见模型:GGX(Trowbridge-Reitz),Beckmann
越粗糙的表面 → 越多随机分布的微面 → D 越宽 → 高光更散
F:Fresnel Term(菲涅尔项)
控制反射率随视角变化(正面低,侧面高)
让表面在掠射角变得更亮,贴近真实物理
通常用 Schlick 近似简化计算
G:Geometry Term(遮蔽-遮挡函数)
表示微面之间是否遮挡彼此或遮挡视线
物理上解释为什么粗糙表面反射更弱:更多能量“卡住了”
常见模型:Smith G1-G2 函数(和 D 搭配使用)
"What the hell are you laughing at…? Idiot.
Let me guess — hooked on those damn short videos again, aren’t you?"
| 类型 | 含义 |
|---|---|
| 各向同性 (Isotropic) | 表面粗糙度、反射行为在所有方向上都一致(无方向性) |
| 各向异性 (Anisotropic) | 表面具有方向性纹理结构,导致反射随方向发生变化(如拉丝金属、头发) |
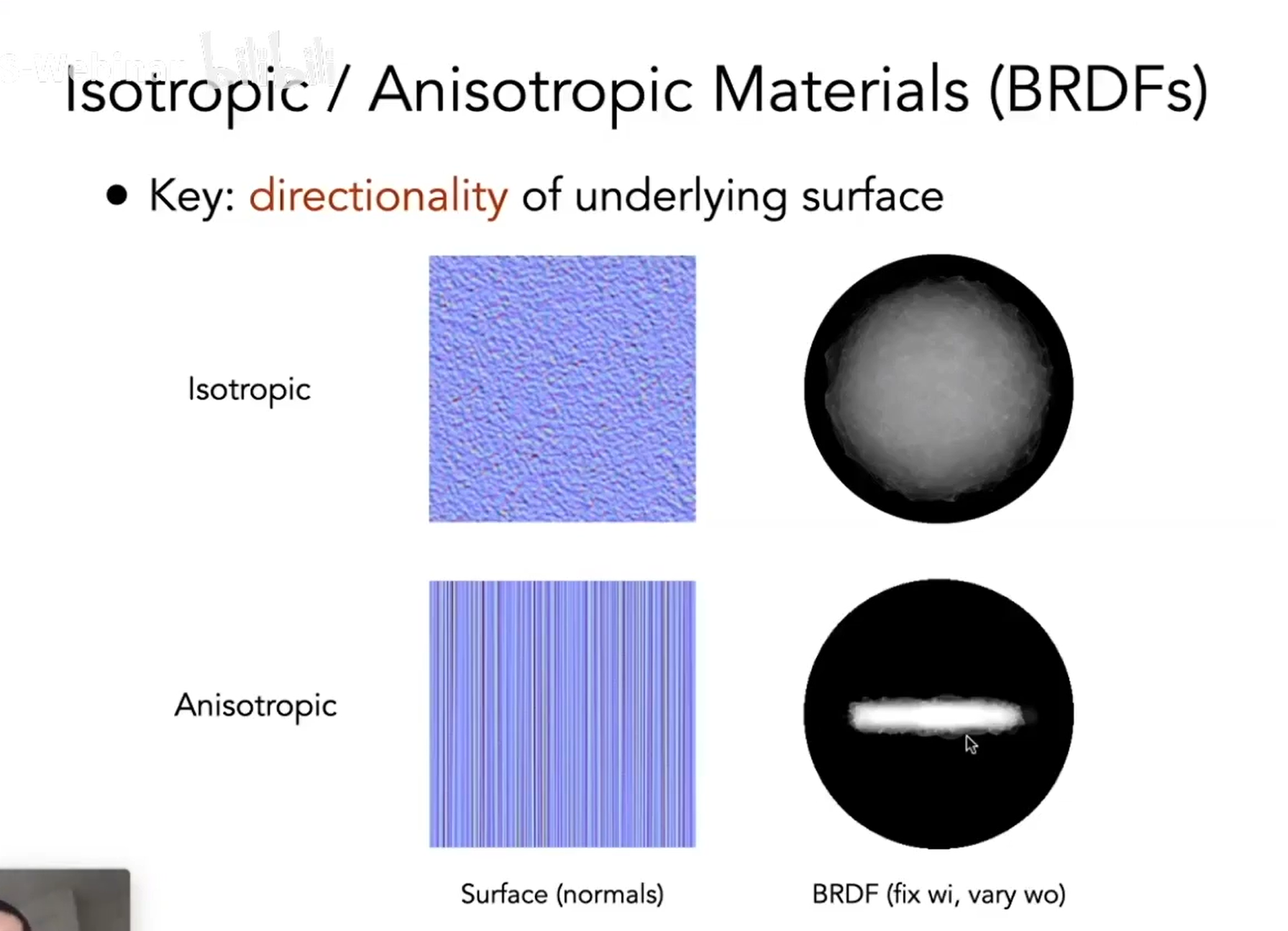
BRDF 分布图
这显示了在固定入射光方向 ωi\omega_iωi 下,不同出射方向 ωo\omega_oωo 对应的反射强度(也就是 BRDF 的方向性响应):
上方(各向同性):
BRDF 分布图是对称的
入射光反射是均匀扩散的,高光是圆形分布

下方(各向异性):
BRDF 图是横向拉伸的椭圆,反射只集中在某一方向带上
表示像头发、CD、拉丝金属那样的“方向性高光”

想象你在看一根头发:
光从正面斜照上去
如果你从与头发垂直方向观察,会看到亮亮的一条高光线(不是一小点,而是一条)
因为头发的微结构是沿着它自身延展的,光就沿着这个方向拉开反射
所以图中下方右图是一个“横向拉开的亮条纹”,说明:
→ BRDF 的反射方向在特定方向上增强了
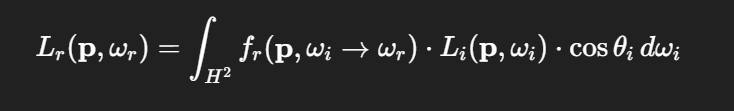

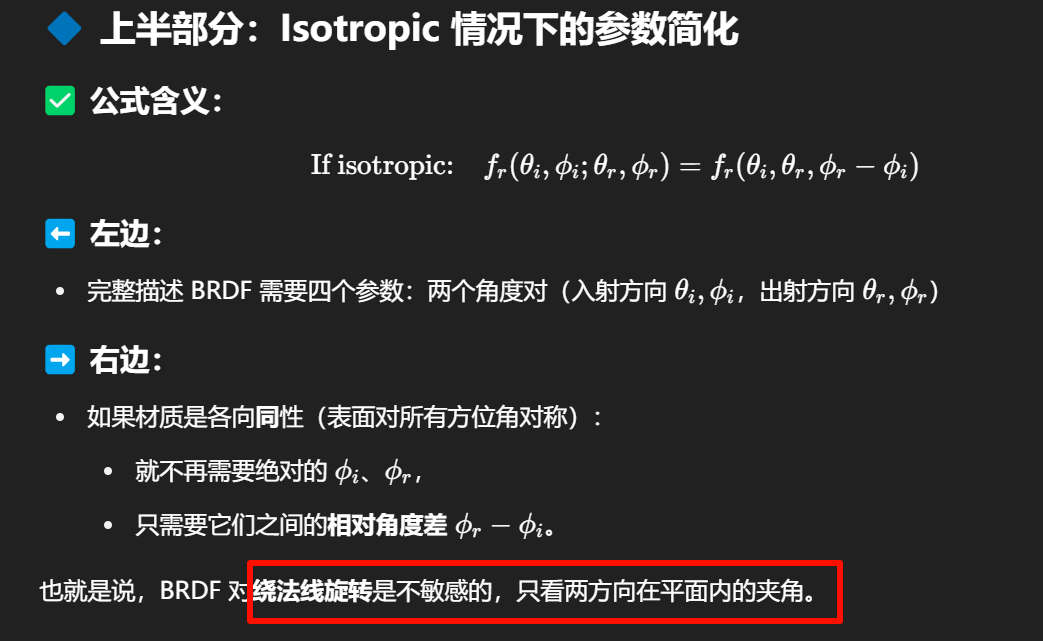
应用互易性原则(Reciprocity)
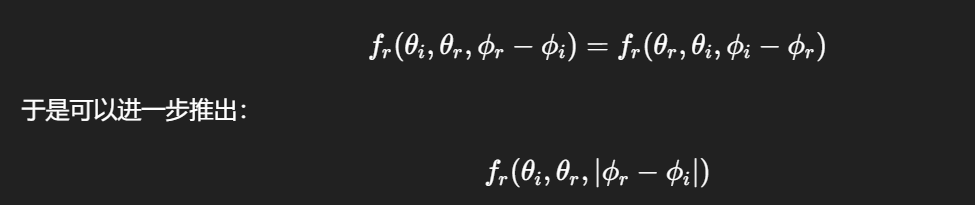
如果一个 BRDF 是:
各向同性
满足互易性
那么你只需要 3 个参数(θi,θr,∣ϕr−ϕi∣\theta_i, \theta_r, |\phi_r - \phi_i|θi,θr,∣ϕr−ϕi∣)就能唯一描述反射函数。
原来需要 4 个角度参数,现在只剩 3 个——这就是视频中提到的“维度降了一维”。

要高精度还原一个材质的 BRDF,需要成千上万个采样点,不能简单地用低维函数拟合。
例如经典的 MERL BRDF 数据库:
来自 MIT,记录了 100 多种真实材质的 BRDF
每种材质约 1GB 数据(每个 BRDF 约几十万方向对)


Vertex Connection and Merging(VCM,顶点连接与合并)
一种混合方法:结合了 BDPT(连接)和 Photon Mapping(合并)技术。
可以在保持高质量的同时覆盖更广泛的路径类型。
兼具无偏和有偏技术的优势。
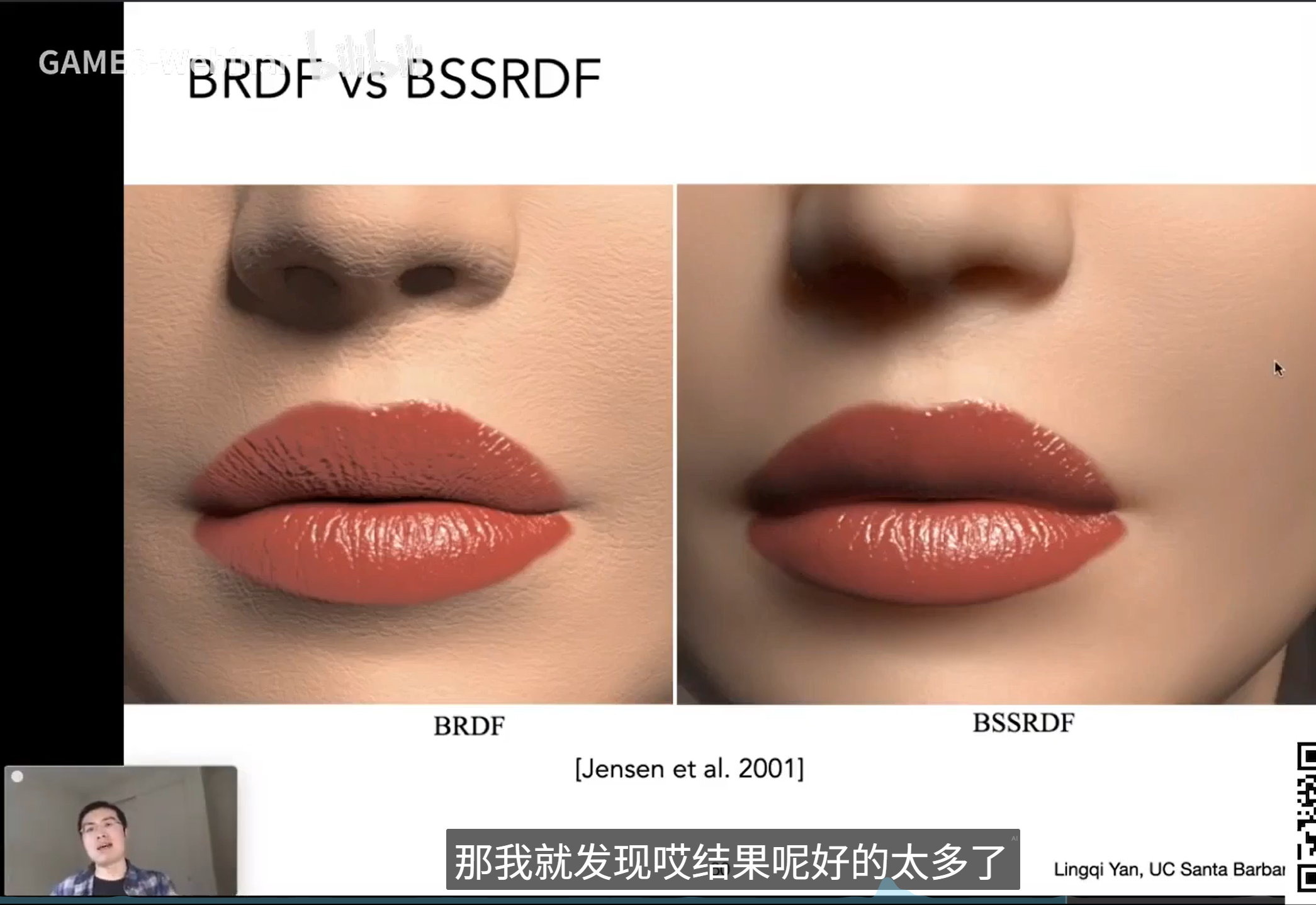
光场是对“任意位置任意方向上存在的光线的集合”的建模。
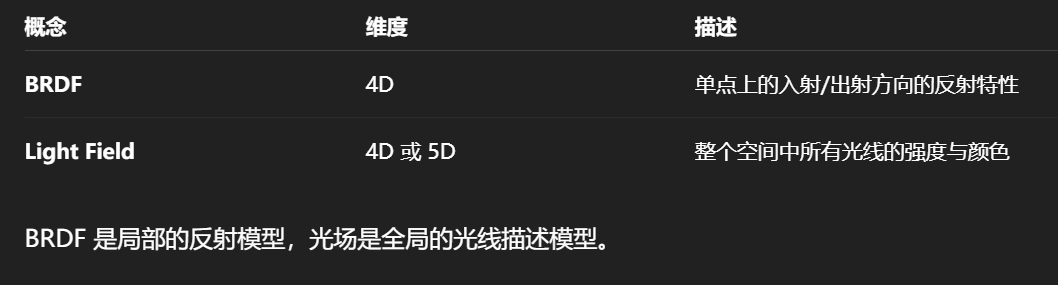
“全光函数(Plenoptic Function)”是比光场更全面、更基础的概念,是描述我们所能感知的全部光信息的理论模型,最早由 Adelson 和 Bergen 在 1991 年提出。
| 参数 | 含义 |
|---|---|
| x,y,zx, y, z | 光线所处的位置 |
| θ,ϕ\theta, \phi | 光线的传播方向(通常用极坐标) |
| λ\lambda | 光的波长(颜色) |
| tt | 时间 |
| PP | 在该点、该方向、该波长、该时间上的光强 |
| 模型名称 | 维度 | 特点 |
|---|---|---|
| 全光函数 | 7D | 完整模拟,包含时间和波长 |
| 光场(Light Field) | 4D | 通常忽略时间和波长,假设真空中光直线传播 |
| 图像 | 2D | 相机在某一时间某一点某方向的快照 |
任意一条光线可以被两个点的位置来确定——这里就是两个平面上各一个点。
降低维度:相比于全光函数的7D,这种表示只需要4D就足够表示静态场景中的所有光线。
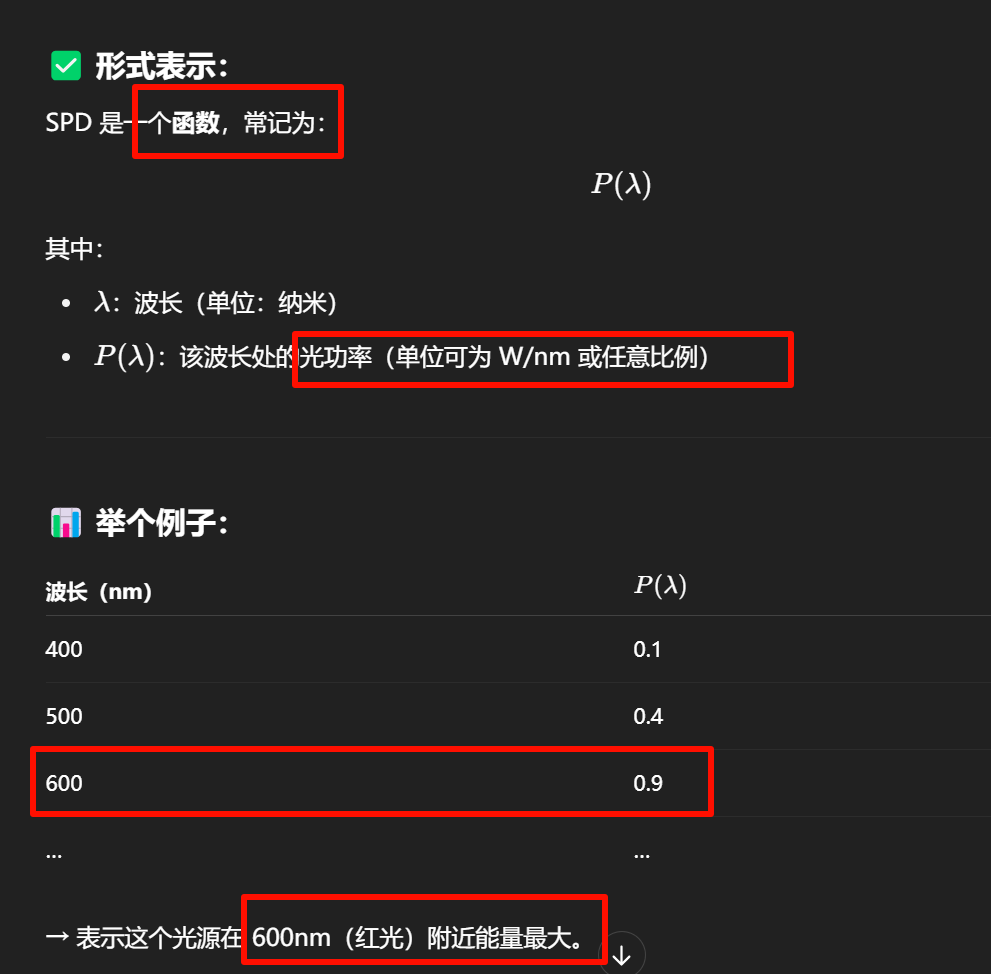
**SPD(Spectral Power Distribution,光谱功率分布)**是指:
在不同波长下的光能强度分布,它告诉我们一个光源在每个波长(通常 380–780nm,可见光范围)上发出的能量有多少。

数值解与真实解(物理轨迹)之间的偏差不断积累和扩大,导致模拟轨迹“发散”或“漂离正确路径”
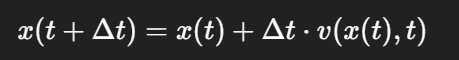
这个公式只根据当前点的导数(斜率)做一次线性外推,图中对应的是步骤 a:
它假设当前导数在整个步长内都恒定不变。
但如果轨迹是曲线(如图所示),那么这个外推就会偏离真实曲线。
随着步数增多,这种误差会积累,导致模拟轨迹 越来越“飘”离真实轨迹,这就是老师说的“越来越远”。

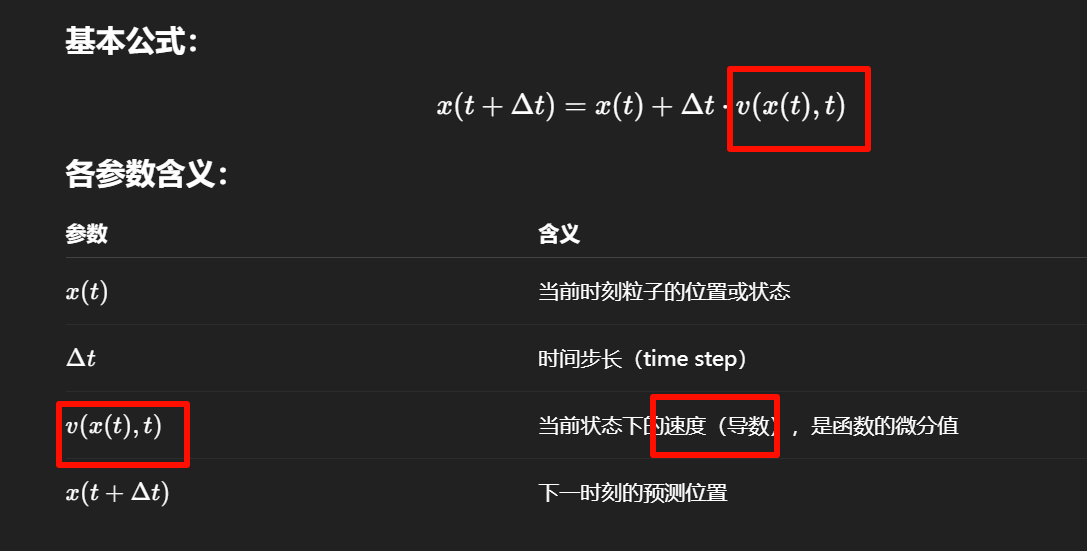


自适应步长法本身不是一种数值积分方法,而是一种“控制框架”或“策略”,
它必须依赖某种具体的积分方法(如欧拉法、中点法、Runge-Kutta)来作为“运算核心”。


-----------------
-----------------
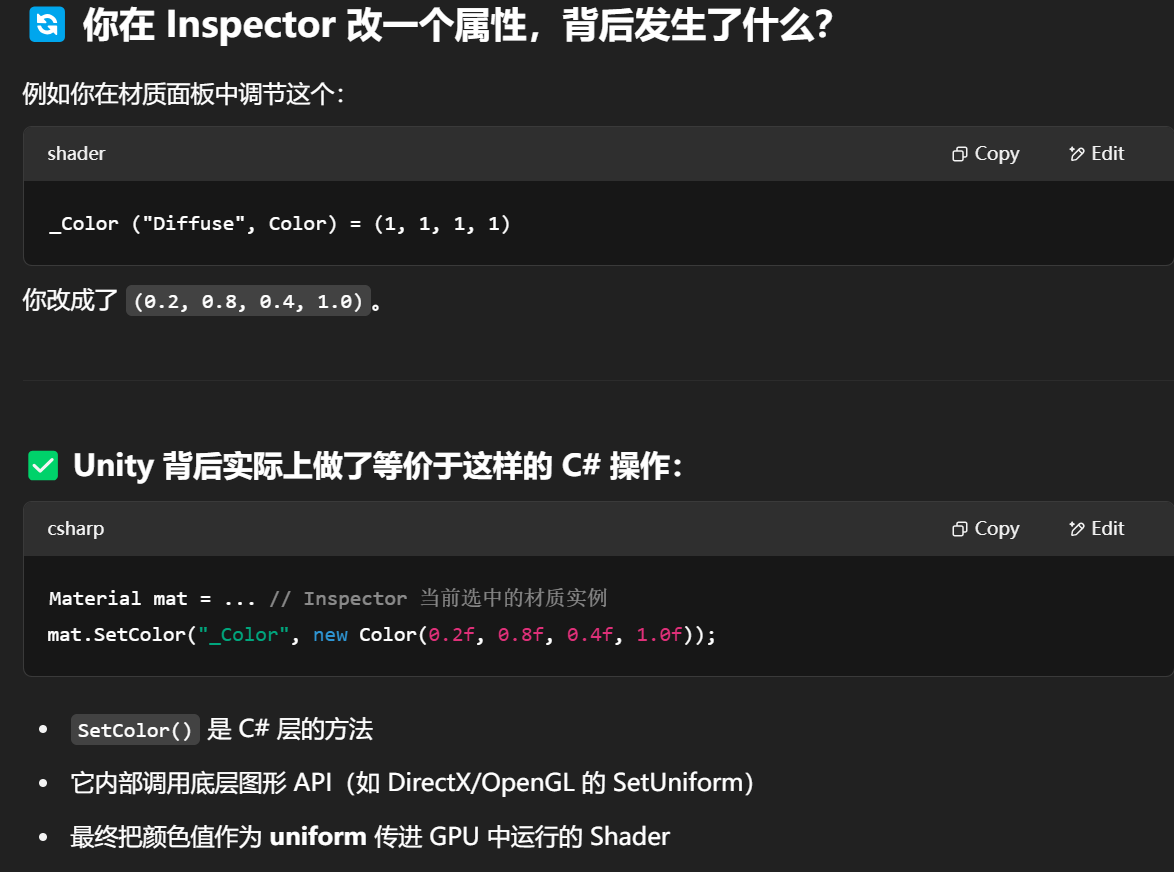
Properties
自定义材质 Inspector
Unity 根据名称和类型自动生成 uniform 例如 _Color 变成 uniform fixed4 _Color;
材质运行时将值注入到对应 uniform ,Unity 调用 GPU API(如 glUniform4f)

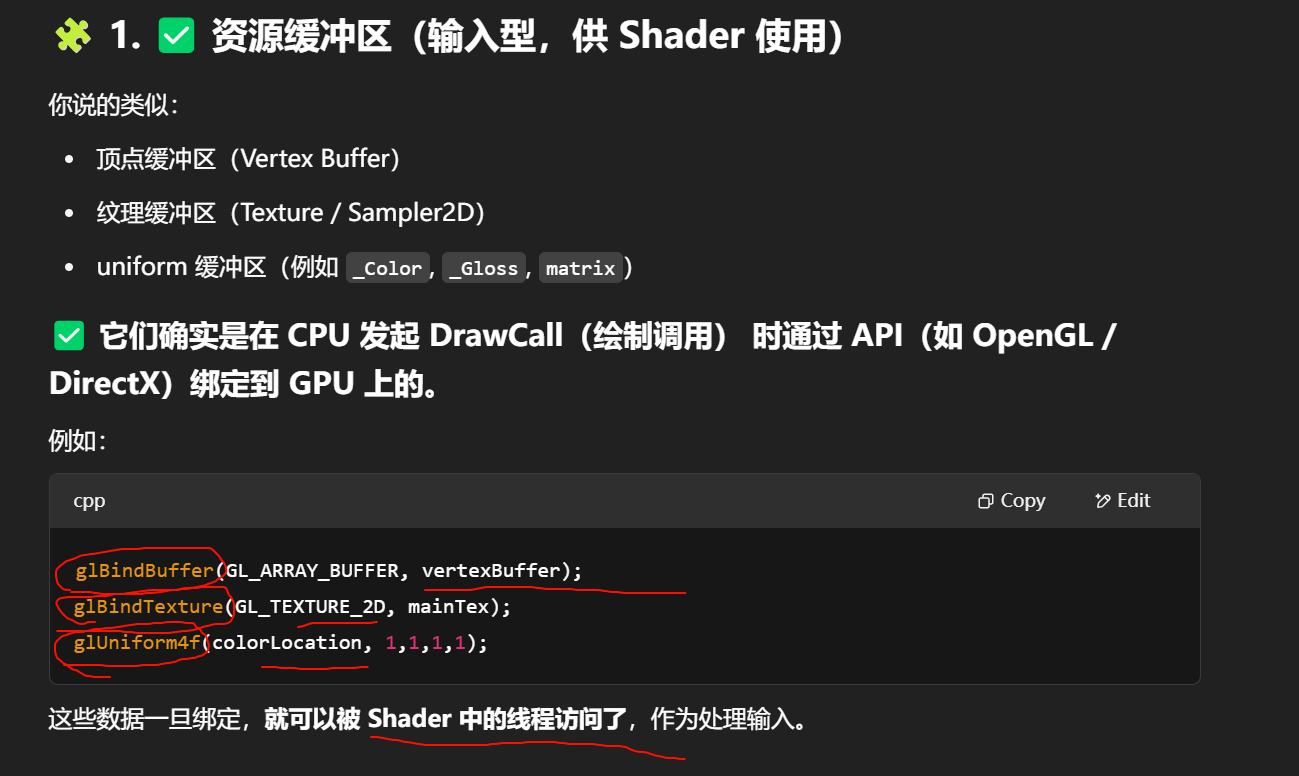
总共有多少种类型的缓冲区?
| 类别 | 常用缓冲区名 |
|---|---|
| 输入类 | 顶点缓冲、索引缓冲、uniform、纹理、结构体缓冲 |
| 输出类 | 颜色缓冲、深度缓冲、模板缓冲、shadow map、RT |
| 过程类 | FBO、G-Buffer、CommandBuffer、UAV |
首先统一术语:“缓冲区”这个词不是一种东西,而是一类机制的统称。
它在不同上下文中分为两大类:
| 类型 | 属于谁控制 | 举例 | 典型用途 |
|---|---|---|---|
| 资源缓冲区 | CPU → GPU | 顶点缓冲区、uniform 缓冲区、纹理缓冲区 | 提供数据给 Shader 使用 |
| 帧缓冲区(Framebuffer) | GPU 内部创建 | 颜色缓冲区、深度缓冲区、模板缓冲区(stencil) | 存储渲染结果或辅助测试 |
| 类型 | 用途 | 常见表现 |
|---|---|---|
| Vertex Buffer | 顶点位置/法线/UV/切线等 | v.vertex、v.normal |
| Index Buffer | 描述三角形顶点索引 | DrawIndexed 使用 |
| Uniform Buffer | 全局参数,如 _Color, _Cutoff |
uniform 变量、Properties |
| Texture / Sampler | 图像数据(可采样) | _MainTex、tex2D() |
| Structured Buffer | 任意结构化数据(高级用途) | Compute Shader 使用 |
| Constant Buffer | 小批量常量优化传输(DX11 特有) | HLSL 中 cbuffer |
| Storage Buffer | 可读写任意数据(Vulkan/GL4+) | 用于 Compute Shader 等 |
🧩 2. ✅ 帧缓冲区(输出型,由 GPU 内部管理)
包括:
| 缓冲区类型 | 意义 |
|---|---|
| 颜色缓冲区 (color buffer) | 存储片元着色器计算的颜色,最终显示在屏幕上 |
| 深度缓冲区 (depth buffer / Z-buffer) | 存储每个片元到摄像机的距离,用于遮挡判断 |
| 模板缓冲区 (stencil buffer) | 用于执行遮罩、轮廓剔除等复杂逻辑 |
✅ 这些缓冲区是 GPU 自动管理并与“当前渲染目标(Framebuffer)”绑定的。
它们不是从 CPU 发进去的“值”,而是:
由 GPU 在渲染开始时分配空间
然后由 GPU 在每帧运行中不断写入或读取
有些 Shader(如 ShadowCaster)只写深度缓冲区而不写颜色
🔴 二类:输出缓冲区(Shader 写入结果)
| 类型 | 用途 | 表现 |
|---|---|---|
| Color Buffer | 输出最终颜色 | return fixed4(...) to SV_Target |
| Depth Buffer | 存储每个像素的深度值 | ZTest, ZWrite 使用 |
| Stencil Buffer | 模板测试遮罩 | Stencil { ... } block |
| G-Buffer | 延迟渲染下的多个输出缓冲区 | Albedo, Normal, Specular 等 |
| Shadow Map | 专用深度缓冲 → 光源视角 | ShadowCaster Pass 写入 |
| RenderTexture | 手动指定的输出目标 | Camera.targetTexture |
⚙️ 三类:中间过程缓冲区(GPU 自用 / 高级控制)
它不一定是“每帧必有”,但在更复杂的渲染技术(如延迟渲染、后处理、Compute Shader、HDRP)中是绝对核心的基础设施。
| 类型 | 用途 | 举例 |
|---|---|---|
| Frame Buffer Object (FBO) | 封装一组颜色+深度输出缓冲 | OpenGL 中的 Framebuffer |
| Command Buffer | 用来记录和控制 DrawCall 队列 | Unity 的 CommandBuffer |
| Atomic Counter / UAV | 高级并发写入控制,用于计算/排序等 | Compute Shader、HDRP 内部使用 |
GPU 内部为每一帧渲染分配一块“Framebuffer 对象(FBO)”,
它是一个结构体,包含多个附加的缓冲区(color, depth, stencil 等)。
就像一个画布(Framebuffer)上贴了几张纸(缓冲区):
一张纸用来画颜色(color buffer)
一张纸用来记录深度(depth buffer)
另一张纸用来当遮罩(stencil buffer)
这块“画布”(FBO)不是永久占硬件的槽,而是:
根据当前相机视图、渲染目标自动分配内存
每一帧开始前清空或重建
每个渲染 Pass 可以绑定不同的缓冲区组合(多 Pass 多配置)
你可以自己构建 framebuffer 的等价物 —— 就是 RenderTexture + CommandBuffer。
缓冲区不是从“类型本身”定义的,而是从“用途 + 生命周期 + 绑定方式”定义的。
GPU 中的缓冲区没有“本质上的分类标签”,只有功能角色。
你对它的管理方式、使用方式、生命周期、绑定点,才决定它“表现为哪一类”。
🧱 重构更严谨的三类逻辑(更贴合底层真实结构)
| 类别 | 定义核心 | 管理/分配方 | 是否可在 Shader 中访问 | 示例缓冲区 |
|---|---|---|---|---|
| 资源缓冲区 | 来自 CPU 或 Asset 的输入数据 | CPU / Unity | ✅(作为输入) | uniform、顶点缓冲、纹理、SSBO、Structured Buffer |
| 目标缓冲区 | 当前 Pass 的输出目标或测试参考 | GPU / Framebuffer 管理 | ❌(除非用特殊方式) | 颜色缓冲、深度缓冲、模板缓冲、MRT、Shadow Map |
| 中转缓冲区 | 明确创建用于 Pass 间传递或并行计算 | 开发者 / SRP 管理者 | ✅(读/写/并发) | G-Buffer、RenderTexture、RWBuffer、UAV |
📌 解释重点:
✅ 一个缓冲区可以扮演多个角色
例:
RenderTexture可以在 Pass A 中是“颜色输出”,Pass B 中变成“纹理输入”
✅ 是否“GPU 管理”不是分类依据,而是行为模式
Framebuffer 自动附加是 GPU 管理的结果
但
RenderTexture也在 GPU 中,但由你或 SRP 显式控制
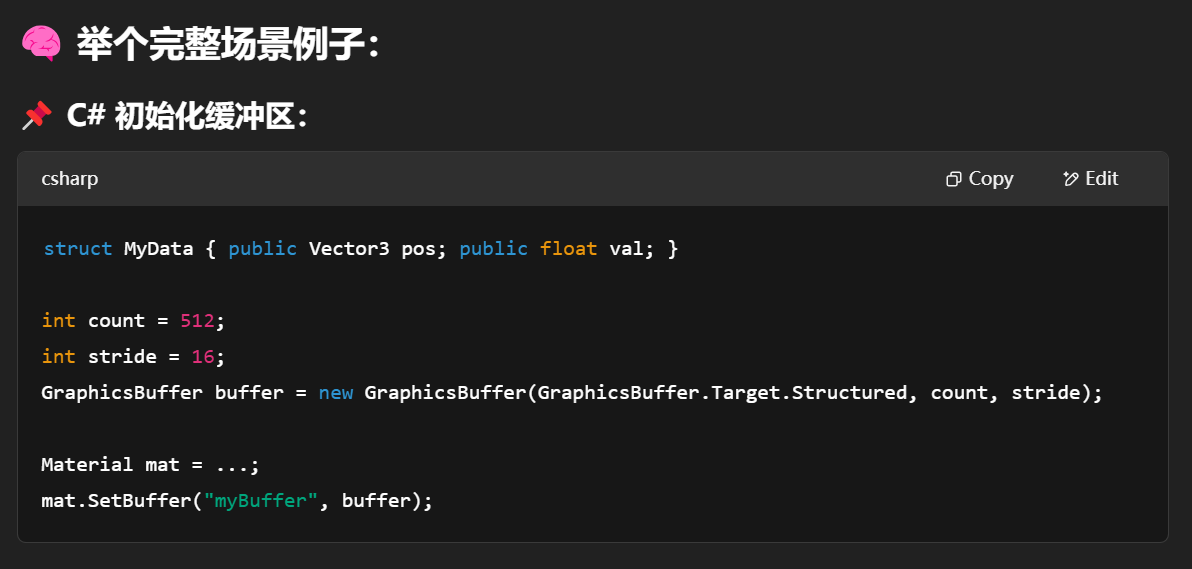

🚚 多个变量上传(uniform):
实际上 Unity 内部也会打包成一个 ConstantBuffer(CBV),通过 GPU API 上传
属于 GPU “快车道”,但只能传少量参数
🚛 缓冲区上传(StructuredBuffer):
是一块 GPU 上真实分配的 Buffer(更像“内存”)
支持数千个结构体、数组元素访问
更适合 Compute Shader、GPU 实例化、动态顶点更新等重载操作
uniform = 轻量控制参数(材质、颜色、阈值)
StructuredBuffer = 大批量结构数据(实例、粒子、网格等)
| 对比点 | 普通 Texture2D | RenderTexture |
|---|---|---|
| 来源 | 从磁盘/资源加载 | 实时由 GPU 渲染生成 |
| 用法 | 用来采样、贴图 | 可采样,也可以作为渲染目标(输出) |
| 是否可写入 | ❌ 只读 | ✅ 可写(作为 Shader 输出目标) |
| 是否有深度/模板缓冲 | ❌ 没有 | ✅ 可选添加 |
🎮 实用例子:监视器/摄像头屏幕显示
创建一个 RenderTexture,分辨率例如 512x512
创建一个 Camera,让它只渲染某些物体
把这个 RT 赋值给摄像头的
targetTexture用这个 RT 作为一个材质的主贴图,贴在一个平面上
游戏运行时,这个平面就像一个实时画面显示器
RenderTexture ≈ GPU Framebuffer(含颜色缓冲 + 可选深度缓冲) + 纹理接口
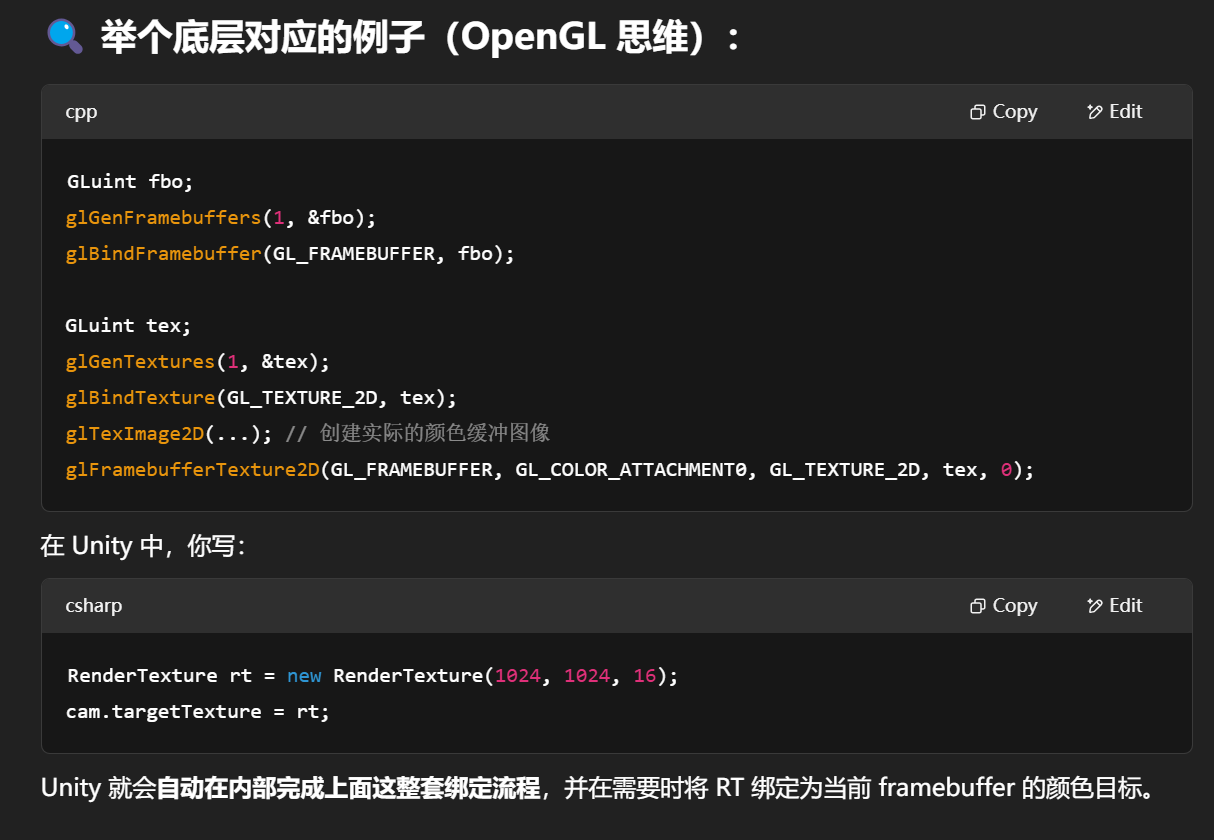
GPU → CPU 的读回有什么特点?
| 特性 | 描述 |
|---|---|
| ✅ 可以在一帧内完成 | 一般是异步执行,结果在几帧之后的某个回调函数里拿到 |
| ⚠️ 非常慢 | 因为打断了 GPU 的流水线,需要同步等待 |
| 🚫 不适合高频使用 | 若每帧都大量回读,CPU-GPU 通道会成为瓶颈 |
| ✅ 适合用于调试/数据导出 | 比如截图、探针数据提取、GBuffer 分析、性能测试等 |
这些缓冲区在GPU 调度顺序上有强弱优先级吗?
同一帧中,有没有显式的顺序机制来安排谁先写谁后写?
GPU 是怎么保证 Shader 在访问这些缓冲区时不出错?需要你显示控制吗?会自动调度吗?
哪些缓冲区是需要你显式同步 / 管理访问顺序的?哪些是流水线自动安排的?
「GPU 在同一帧内对不同缓冲区的读写,调度顺序是谁控制的?是否可控?我能干预吗?」
「我是否需要显式管理不同缓冲区的读写时机?哪些是自动完成的?哪些要同步?」
不需要你管理访问时机的:
| 类别 | 说明 |
|---|---|
| uniform | Unity 每帧自动同步,无需干预 |
| texture | Shader 采样是延迟读、只读,不产生冲突 |
| vertex buffer | 每个 DrawCall 独立绑定,互不干扰 |
✅ 这类资源在使用时是天然安全的,管线中会自动处理加载、读取等顺序。
⚠️ Depth / Stencil Buffer
Unity 默认行为:
多个 Pass 使用同一个 Depth Buffer → 会自动清空或重写
你可以用
ZWrite Off、ZTest Always或Camera.clearFlags精细控制
你要自己决定:
当前 Pass 是否保留前一个 Pass 写的深度值?
是否在第二个 Pass 开始前 clear 深度?
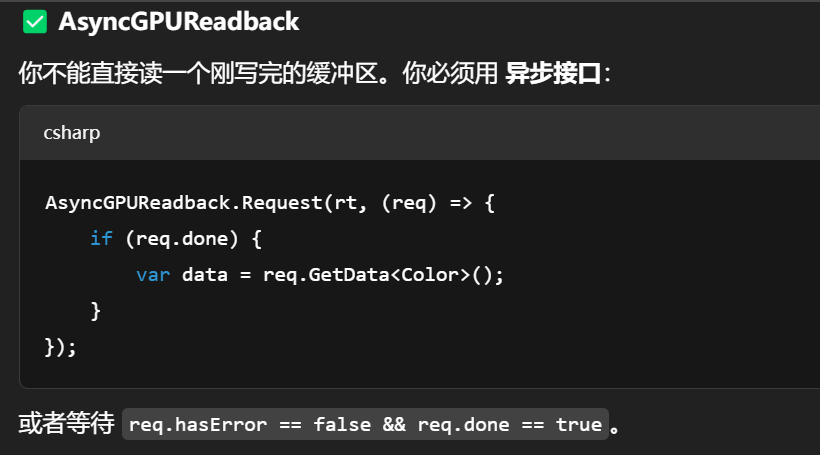
| 是否自动时序调度? | 缓冲区类型 | 是否需你干预顺序? |
|---|---|---|
| ✅ 自动 | uniform, texture, vertex | ❌ 不用 |
| ❌ 需手动 | RenderTexture (RT)、Color/Depth、RWBuffer | ✅ 需要切换目标/清除/ping-pong |
| ❌ 严重依赖同步 | RWBuffer 并写、AsyncGPUReadback | ✅ 强烈建议分 Pass / 加 barrier |
「GPU 渲染流水线中,不同缓冲区的处理顺序是固定的,还是动态调度的?我有没有办法干预它的先后处理顺序?」
---------
想越界访问(如边读边写),必须自己负责协调
意思是我还可以设置“边读边写”?读写的对象是缓冲区是吧?
Stencil Buffer 的访问阶段:Rasterizer 之后、Blend 前
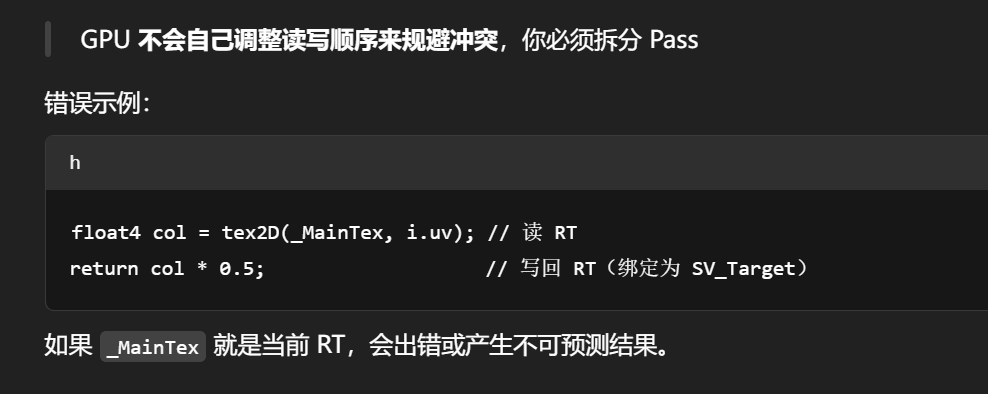
如何跨帧保留 GPU 数据,比如用于残影、TAA、前一帧信息?这些缓冲区如何正确存活和流转?」
“跨帧”通常意味着“双缓冲(ping-pong)”或“轮换机制”
因为:
当前帧要写入新内容
下一帧要读取旧内容
同一 RT 不能同时读写(GPU 会出错)
RenderTexture rt1,rt2创建,生命周期由你控制每帧交替使用 rt1 和 rt2,避免读写同一张图
第一个 Pass 输出到当前 RT
第二个 Pass 读取上一帧 RT,合成你要的效果
交换索引
Swap(),进入下一帧
在 Unity 中,如果我什么都不写,Unity 会自动怎么处理这些缓冲区?比如:它会自动绑定、清除、管理生命周期吗?我有没有办法控制得更细?
缓冲区在 Compute Shader 中的访问方式是否相同?我需要额外管理什么?是否有特殊的同步或绑定机制?
| 图形 Shader(如 fragment) | Compute Shader |
|---|---|
| 执行对象是像素、顶点、三角形片元 | 执行对象是线程组(ThreadGroup) |
| 管线按固定阶段推进 | 没有管线,完全由你编程决定每个线程干什么 |
| Shader 不支持并行写入一个目标资源 | 允许并发读写 RWBuffer / RWTexture |
| Shader 写的是 Framebuffer 等显式目标 | Compute 可写入自定义任意 RWStructuredBuffer 等 |
| 图形管线关键词 | Compute Shader 中对等机制 |
|---|---|
SV_Target |
RWTexture2D / RWStructuredBuffer |
uniform |
cbuffer 或常量直接传入 |
sampler2D |
Texture2D |
| 资源访问顺序由 GPU 管线控制 | 资源访问顺序完全由你在线程中编写逻辑控制 |
Compute Shader 缓冲区类型与绑定方式(Unity)
| HLSL 类型 | Unity 绑定方式(C#) | 说明 |
|---|---|---|
StructuredBuffer<T> |
computeShader.SetBuffer(...) |
只读结构化数据 |
RWStructuredBuffer<T> |
同上 | 可读写结构化数据 |
RWTexture2D<float4> |
computeShader.SetTexture(...) |
可读写图像数据(如图形缓冲) |
cbuffer 常量块 |
computeShader.SetFloat() 等 |
全局参数传入 |
你必须 手动管理的关键点(和图形 Shader 不同)
| 问题 | 图形管线处理方式 | Compute 中的责任 |
|---|---|---|
| 读写冲突同步 | 管线顺序自然避免 | ❗你必须使用 Interlocked* 原子操作 |
| 线程访问顺序 | GPU 自动调度 | ❗你必须用 groupshared / barrier 控制 |
| 数据生存期 / 生命周期 | Unity 自动管理 | ✅ Unity 创建后手动销毁 |
| RT/Buffer 切换与再绑定 | 自动绑定 | ✅ 你必须手动绑定每个 Dispatch 前的资源 |
| 执行调度粒度 | 每像素、每顶点由 DrawCall 控制 | ✅ 你用 Dispatch(x,y,z) 显式指定 |
同一个.shader文件里的多个pass之间有执行顺序吗,是谁管理的(如果这个问题不恰当则转换成恰当说法)
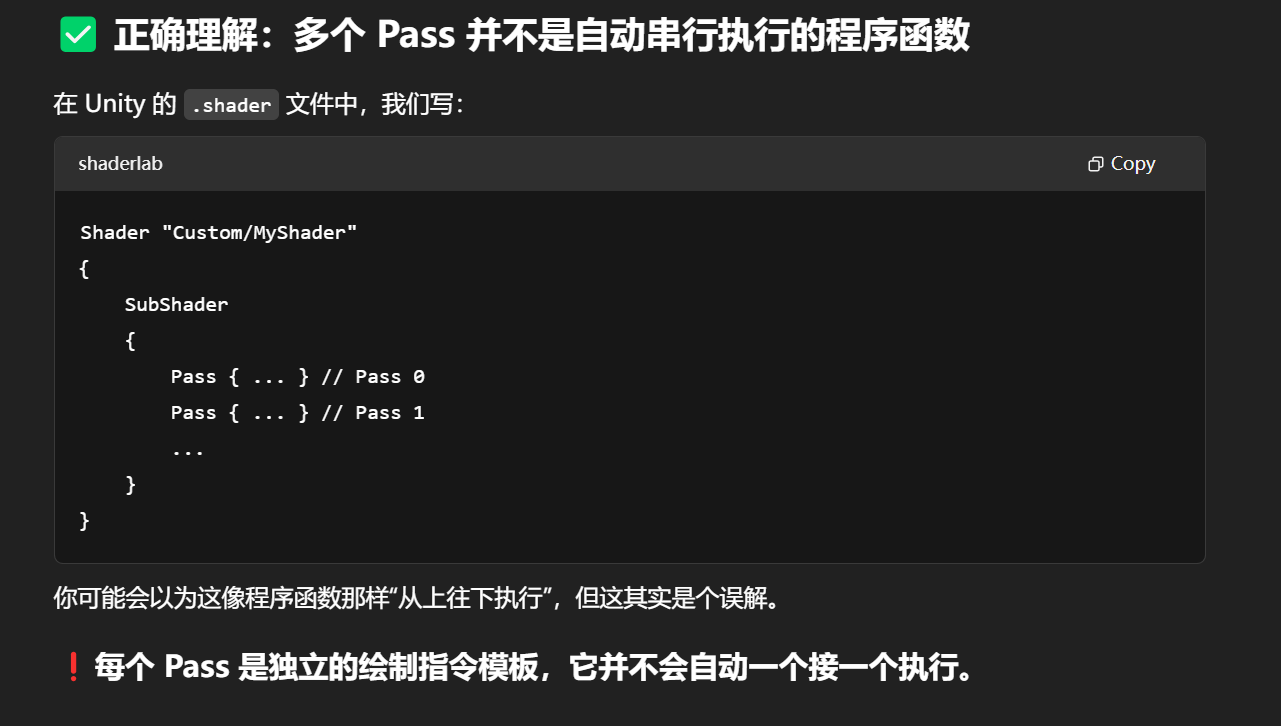
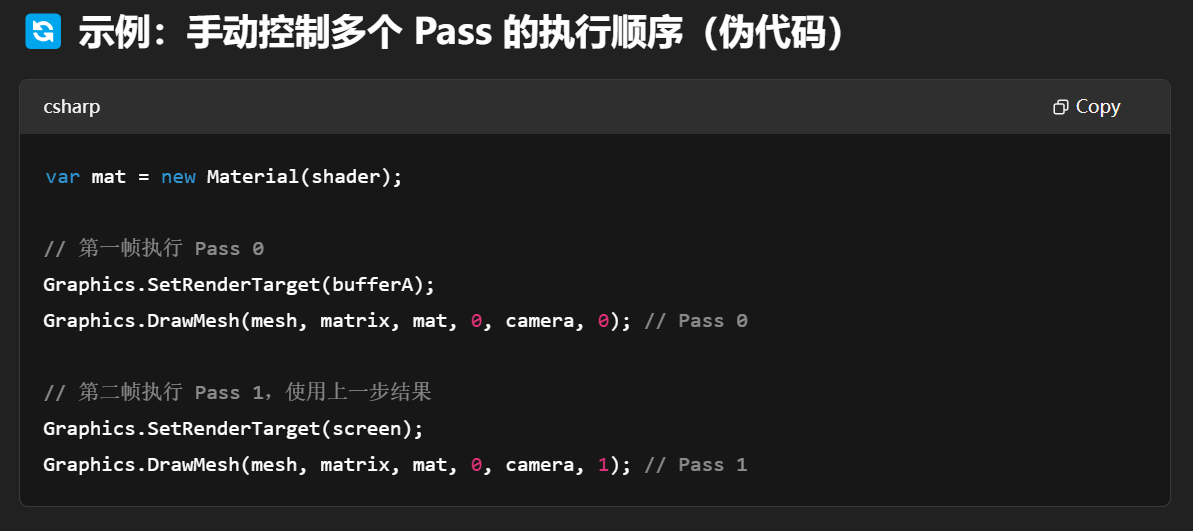
默认情况下每个 Pass 是独立的
你写在 Shader 里的 Pass 顺序本身只是“定义顺序”,但具体执行顺序要看 Unity 的渲染路径(如 Forward、Deferred 等)在做什么样的光照处理。
在 Forward 渲染路径下(你这份 Shader 就是走 Forward):
Unity 首先调用所有带有
LightMode = "ForwardBase"的 Pass(用来处理主光源、ambient、环境光等);然后为每个额外的像素光源调用一次
LightMode = "ForwardAdd"的 Pass(每个光源各调用一次,并进行 additive blend);如果启用了实时阴影,还会调用
LightMode = "ShadowCaster"的 Pass,用来生成阴影贴图。
也就是说:
Unity 按照“功能”调用各个 Pass,而不是照你写的顺序顺序执行。

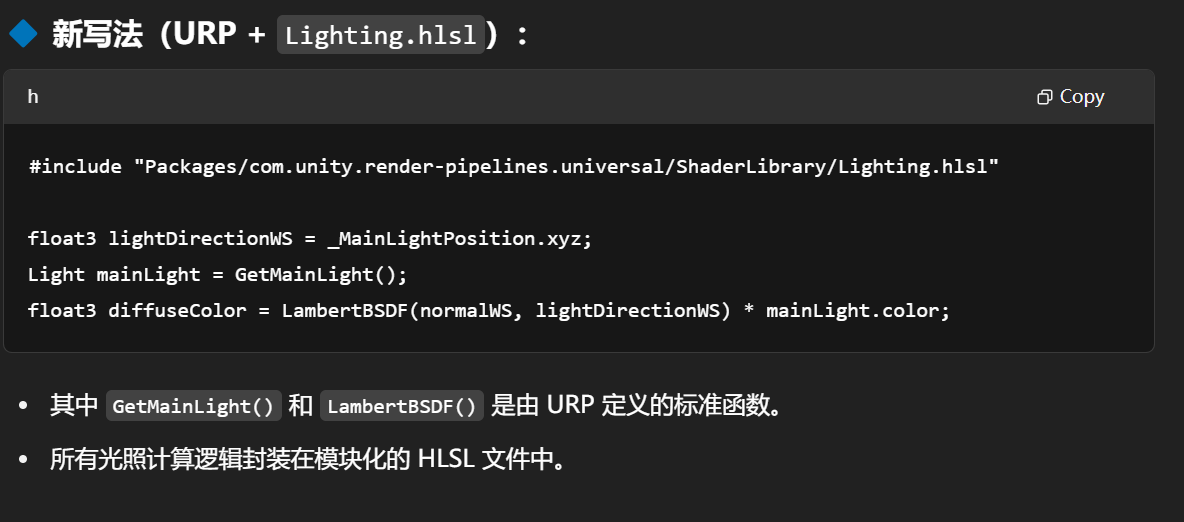
RenderType — 可自定义,但有限制
Tags { "RenderType" = "TransparentCutOut" }
✅ 作用:
RenderType是 Unity 用来分类材质的标识,用于 摄像机渲染剔除(Camera culling)、Image Effects、SRP Batch 等内部机制。它不影响 Shader 本身的渲染方式,而是告诉 Unity:“这个 Shader 属于哪类”。
📌 常用内建值(在 Built-in 管线中):
| RenderType | 含义 |
|---|---|
Opaque |
不透明物体 |
Transparent |
透明物体 |
TransparentCutOut |
透明剪裁(例如 Alpha Test) |
Background |
天空盒、背景 |
Overlay |
屏幕空间 UI 或特效 |
TreeOpaque |
树木的不透明部分 |
TreeTransparentCutout |
树木带 alpha test 的部分 |
❓我可以自定义吗?
✅ 可以写任何字符串,比如
RenderType="MyCustomType"⚠️ 但 Unity 内部功能(比如图像效果或脚本中通过
FindWithTag("RenderType")查找)只识别内建字符串。如果你用 URP/HDRP,Shader Stripping 和 SRP Batching 也可能依赖内建值。
🔶 2. Queue — 渲染排序系统的“排队号”
shader
Copy
Tags { "Queue" = "AlphaTest" }
✅ 作用:
决定渲染顺序,是 Unity 渲染管线中非常关键的一环。
🎯 内建队列名称与数值(可手动指定数值):
| 队列名称 | 数值 | 含义 |
|---|---|---|
Background |
1000 | 最先渲染(如天空盒) |
Geometry |
2000 | 常规物体默认值(不透明) |
AlphaTest |
2450 | 使用 alpha test 的材质(如树叶) |
Transparent |
3000 | 透明材质 |
Overlay |
4000 | UI 和后期特效等 |
🔧 高级用法:偏移调整
"Queue" = "Transparent+10" 或
"Queue" = "Geometry-1"
可以在某类物体之间精细控制渲染顺序。例如:
给角色加 Outline 时,使用
Geometry+1让外描边后画;自定义天空层(
Background+50)用于动态远景特效。
Queue 控制的是 Scene 中所有“渲染对象的整体排序优先级”,而非 Shader 内部的 Pass 执行顺序。
在 Unity 的渲染阶段,每个 渲染对象(Renderer)(如 MeshRenderer、SkinnedMeshRenderer 等)被排序进入渲染队列时:
它会取材质上的 Tag(例如
Queue = "Transparent+1");Unity 会将它作为一个整数排序优先级(如
3001);这个数值决定了 Scene 中这个对象何时被渲染
👉 换句话说,不管你一个 Shader 文件中有多少个 Pass,只要它挂在某个对象上,Queue 值就决定它在“场景渲染阶段”中排在第几位被渲染。
Unity 在渲染一个物体时,如果该物体有多个材质(如多个材质球),每个材质的 Queue 会被分别取出作为独立绘制批次插入排序队列。
如果你给一个角色的皮肤用的是
"Geometry",而装备用了"Transparent+5";那么皮肤部分就会被先绘制,装备延后渲染。
这在角色叠加透明特效时非常有用。
Shader 文件中的 Pass 执行顺序
当一个对象使用某个 Shader 渲染时,Unity 会按照 Shader 文件中定义的 Pass 顺序依次执行每个 Pass。
例如,以下 Shader 中定义了两个 Pass:
Shader "Custom/PassOrderExample"
{
SubShader
{
Pass
{
// 第一个 Pass:设置红色
Color (1, 0, 0, 1)
}
Pass
{
// 第二个 Pass:设置蓝色
Color (0, 0, 1, 1)
}
}
}
在这个例子中,Unity 会先执行第一个 Pass,将对象渲染为红色,然后执行第二个 Pass,将其渲染为蓝色。由于第二个 Pass 后执行,其效果会覆盖第一个 Pass 的结果。
你有两个物体:
物体 A 使用 Shader A,它有 3 个 Pass。
物体 B 使用 Shader B,它只有 1 个 Pass。
如果:
Shader A 的 Queue 是
"Geometry"(2000)Shader B 的 Queue 是
"Transparent"(3000)
那么:
Unity 会先渲染 Queue 小的 → 先渲染物体 A(即便它有 3 个 Pass)
然后再渲染物体 B
对物体 A,Unity 会按你写在 Shader 里的
Pass顺序执行对物体 B,它只有一个 Pass,就执行那个 Pass
一个正在运行的 Scene 所用的渲染管线是唯一的;
所有材质、Shader、光照、后处理等都必须适配该渲染管线。
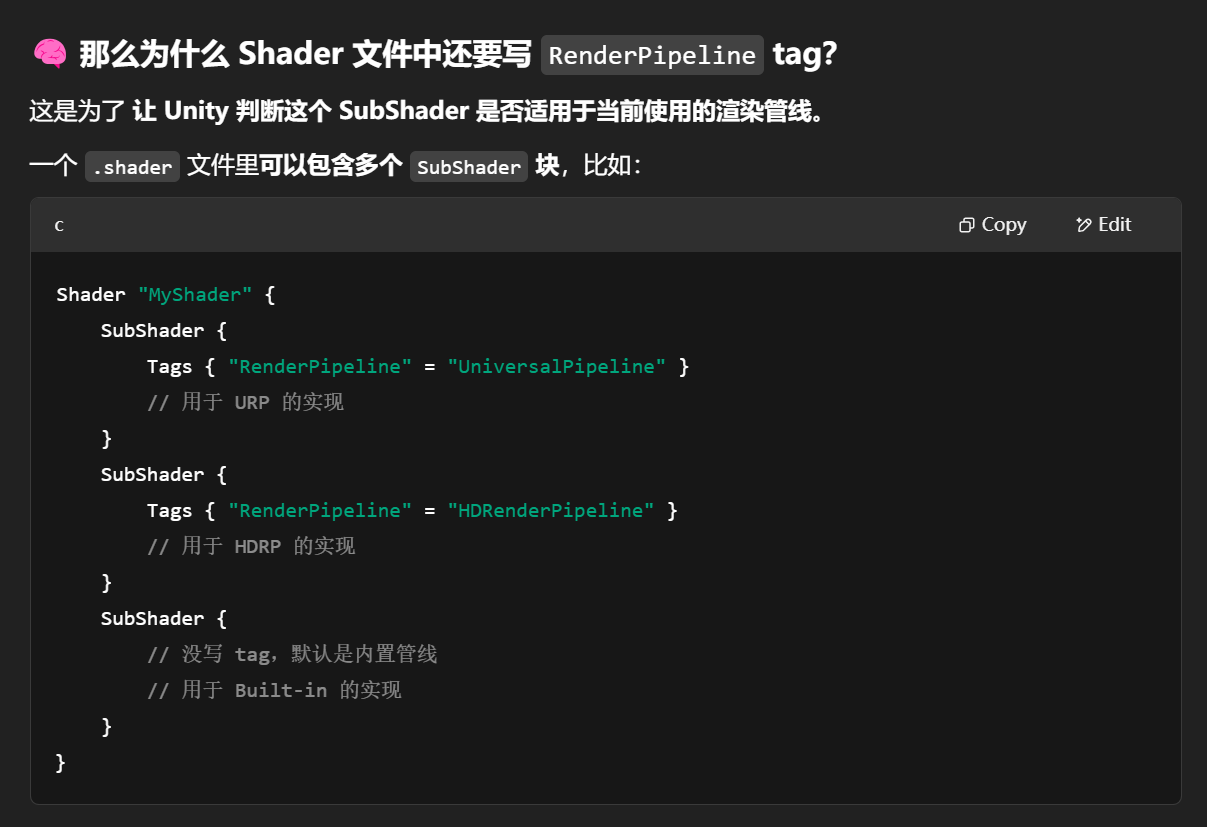

这只是作用在 SubShader 层级,不影响整个 Shader 的其他 SubShader;
对于 Shader 替换(Replacement Shader) 的情况非常有用,防止不小心替代了阴影通道。
调试为什么一个物体没有产生阴影,这个 tag 是检查的重点之一。
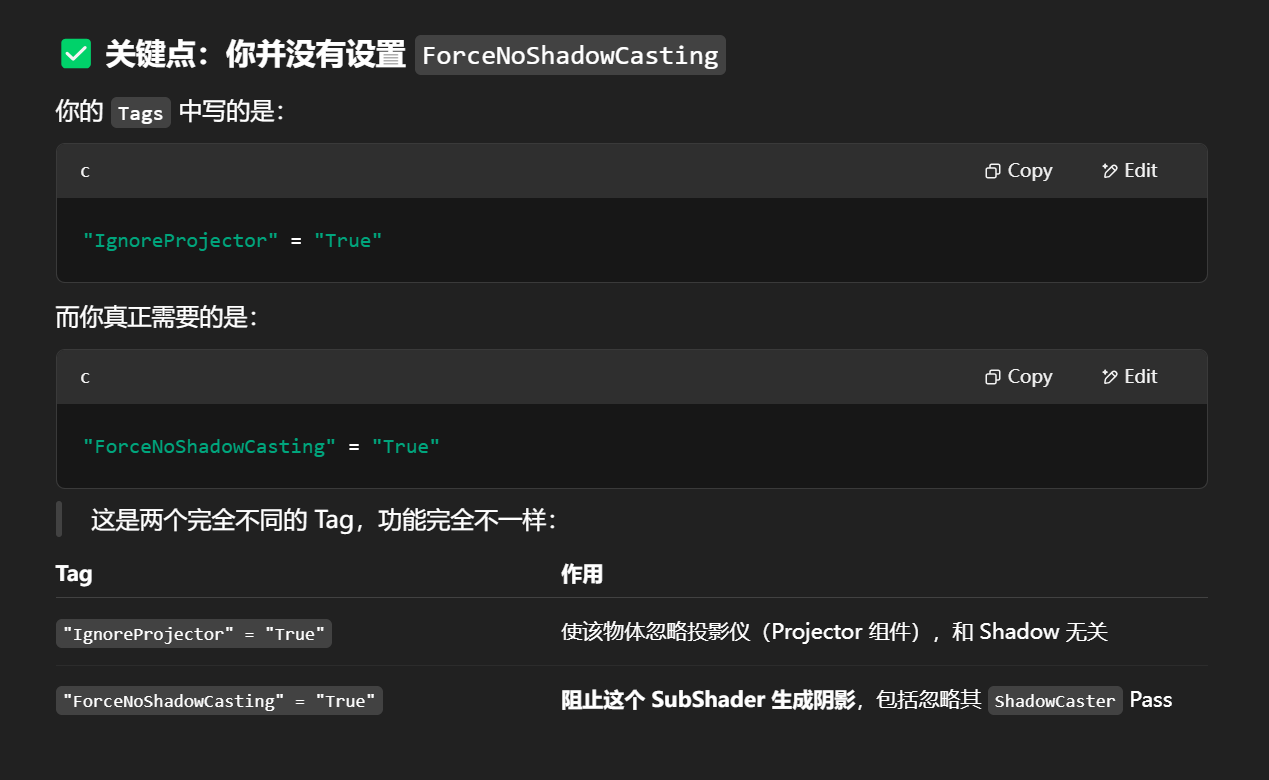
它们都是 Unity 内置定义的 multi_compile shader keyword 集合
#pragma multi_compile_fwdbase#pragma multi_compile_fwdadd_fullshadows
这些不是你自己声明的自定义 keywords,而是 Unity 自己预定义的一些 keyword 集合宏,本质是一个 宏展开:
它会在编译时展开为多个 #pragma multi_compile 的 keyword 组合。
它们所代表的作用域
| 指令 | 用途说明 | 展开关键词(大致) |
|---|---|---|
#pragma multi_compile_fwdbase |
用于 ForwardBase Pass 阶段的光照条件变体 | DIRECTIONAL, POINT, SPOT, LIGHTMAP_ON, DIRLIGHTMAP_COMBINED, SHADOWS_SCREEN 等 |
#pragma multi_compile_fwdadd_fullshadows |
用于 ForwardAdd Pass 阶段的额外光源加法,包含完整阴影支持 | SHADOWS_CUBE, SHADOWS_DEPTH, SHADOWS_SOFT, POINT_COOKIE, SPOT 等 |
这些宏会让 Unity 编译出一整套对应的变体(variants),从而能适配不同的光照条件和阴影设置。
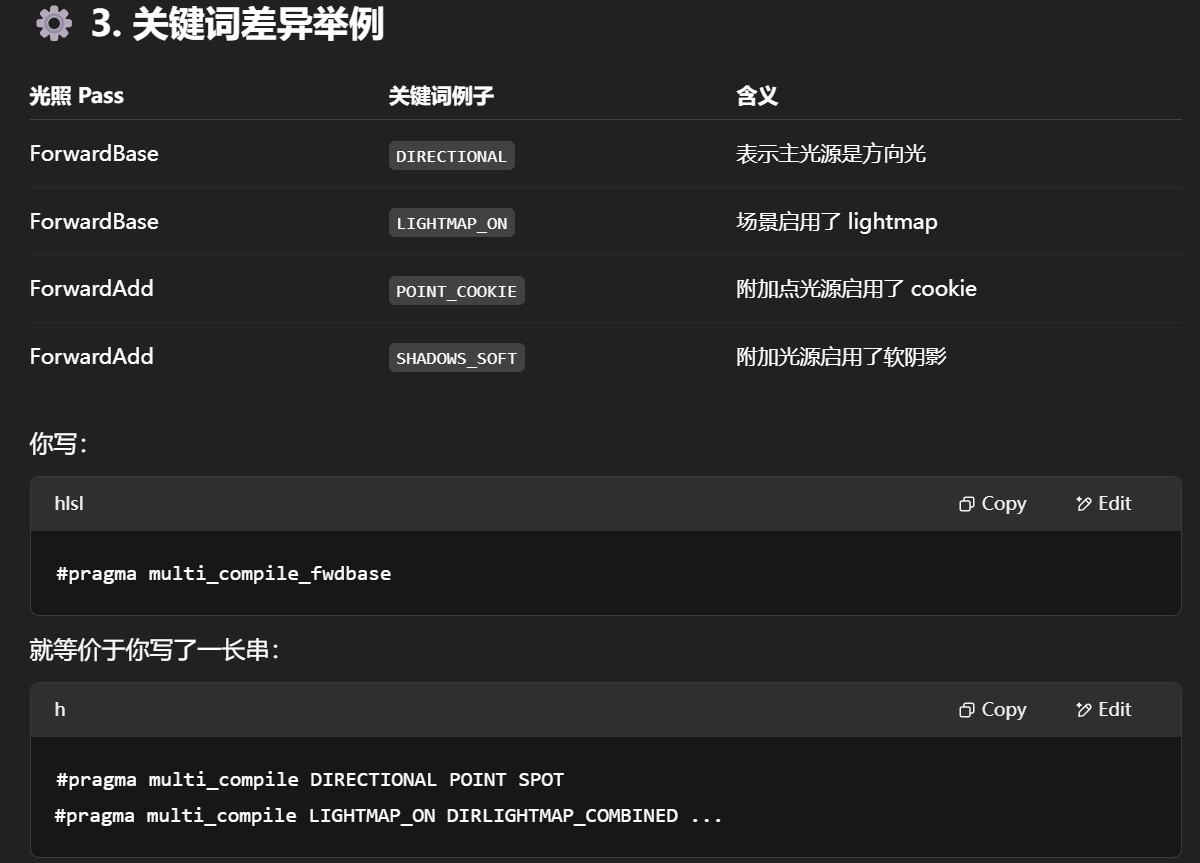
关键词用于控制 Shader 在不同条件下使用不同的分支(变体),从而实现静态分支控制(Static Branching)。
| 项目 | shader_feature |
multi_compile |
|---|---|---|
| 用途 | 常用于自定义材质选项(如开关描边、反射等) | 用于功能完整的变体生成(如光照、阴影) |
| 编译变体数量 | 较少(只包含实际启用的) | 很多(组合数可能爆炸) |
| 优点 | 减少构建体积,节省性能 | 灵活且自动覆盖所有条件 |
| 使用场景 | 自定义效果开关、开关控制等 | Unity 内置管线宏,如 multi_compile_fwdbase、多光源支持等 |
#pragma shader_feature 的一个重要 行为特性,而且这个“set”的语义并不像程序里的“枚举”那样直观。
一个 #pragma shader_feature A B C 语句,定义了一个 关键词集合(set)。这个集合中的关键词有一个共同点:
Unity 每次编译 Shader 的时候,最多启用其中一个关键词,也可以一个都不启用。
它等价于告诉 Unity:
“请为这 3 个关键词分别创建一个变体,还要再创建一个‘都不启用’的默认变体”。
#pragma shader_feature A B C
Unity 会生成以下 4 种变体:
启用状态 编译的变体描述
无关键词启用 默认状态(none)
A 启用 变体 1
B 启用 变体 2
C 启用 变体 3
👉 注意,它不会创建 A+B、A+C、B+C 或 A+B+C 这样的组合(这是 multi_compile 才会做的事)。
Fallback 通常是指在某些 变体缺失、编译不成功、关键词匹配不到 的时候,Unity 会尝试使用备用的 Shader。
但更常见的一个误解是:
❌ “Fallback 是你写的那一行
Fallback "Diffuse"”
✅ 但在 keyword 系统中,fallback 更接近于“匹配不上 keyword 时还能不能渲染”的保障机制
❌ 问题来了:
如果材质上没有开启这两个 keyword 中的任何一个(即所有 keyword 都处于未启用状态),Unity 找不到与之匹配的变体!
如果没设置 fallback,就会渲染出错(shader missing 或 pink)。
编译器看到 #include,会直接把文件内容贴进去,就像你手动复制了那段代码。
ZWrite On
Blend SrcAlpha OneMinusSrcAlpha
然后有多个透明玻璃在一起,你会看到:
只有第一个玻璃被绘制;
后面的玻璃完全不显示;
整体效果像是不透明一样遮住了后面的透明物体。
这就是ZWrite 把透明物体误当成遮挡物了。
GPU 默认的输出方式是“替换而非混合”:
如果你不写 Blend,那默认行为是:
当前片元颜色 直接覆盖 framebuffer 中已有的颜色,无论你返回的是透明色(如 alpha=0.2),都不会做“和背景颜色融合”的过程。
在 Unity 中,ZWrite 实际控制的是哪一个缓冲区?它和透明物体的混合(Blend)所涉及的缓冲区是相互独立的吗?多个 Pass 又是如何共享或分离这些缓冲区的?
ZWrite控制的是 Z-buffer(深度缓冲区) 的写入权限,而Blend操作的是 Color buffer(颜色缓冲区)。这两个缓冲区是 独立存在 的,但在渲染流程中是协同判断可见性和颜色合成的。
| 步骤 | 缓冲区 | 控制指令 | 作用 |
|---|---|---|---|
| ① 先进行深度测试 | Z-buffer | ZTest |
判断当前片元是否遮挡 |
| ② 若通过,则执行颜色混合 | Color buffer | Blend |
合成最终颜色 |
③ 若 ZWrite On,则更新 Z-buffer |
Z-buffer | ZWrite |
替换深度值(遮挡别人) |
Shader 的多个 Pass 究竟共享哪些缓冲区?哪些是隔离的?
“我在每个 Pass 里设置的 ZWrite、Blend、ColorMask、ZTest 等,究竟作用在哪些统一的资源上?它们是共享的吗?”
多个 Pass(在同一个 SubShader 内)是连续地渲染这个物体,每个 Pass:
共用相同的模型(Mesh);
共用 GPU 的 Color Buffer(颜色缓冲)、Z-buffer(深度缓冲)、Stencil Buffer(模板缓冲);
但 每个 Pass 可以单独决定是否写入这些缓冲,通过
ZWrite、Blend、ColorMask、ZTest、Stencil控制。
你可以想象多个 Pass 是“多次绘制同一个模型”,每次绘制都:
判断:我当前要不要写颜色缓冲?
判断:我当前要不要写深度缓冲?
判断:我当前要不要 blend?
判断:我当前 ZTest 是什么策略?
不同 Pass 定义不同行为,会导致哪些渲染差异?
| 场景 | Pass1 设置 | Pass2 设置 | 效果 |
|---|---|---|---|
| 深度遮挡但不显示 | ZWrite On + ColorMask 0 |
—— | 第一个 Pass 写深度但不显示颜色:用于遮挡 |
| 透明合成 | ZWrite Off + Blend 开启 |
—— | 当前 Pass 叠加颜色但不阻挡后面物体 |
| 多层发光 | ZWrite Off + Blend One One |
第二个 Pass 继续叠加 | 多 Pass 发光体 |
| 描边效果 | Pass1 正常写 | Pass2 放大 + 只写颜色 | 实现边缘高亮但不影响遮挡关系 |
“我写了什么 ➝ GPU 做了什么 ➝ 我看到什么”
Pass {
ZWrite Off
Blend SrcAlpha OneMinusSrcAlpha
}
➤ 你写了:
关闭 ZWrite(不写入深度缓冲);
开启 Blend(颜色会与背景混合)。
➤ GPU 执行:
检查 ZTest,通过后进入 Blend;
Blend 使用当前像素 alpha 和 framebuffer 的背景色计算最终色;
不写入 Z-buffer,因此它不会阻挡后面的透明物体。
➤ 你看到的:
当前透明物体和背景叠加;
后绘制的透明物体也能透过它叠加,视觉上感觉“通透”。
📐 延迟渲染特殊情况:多个颜色缓冲(Render Targets)
你说得对,延迟渲染(Deferred Rendering)会让一个 Pass 输出多个颜色缓冲(通常是 G-Buffer):
#pragma target 3.0
#pragma multi_compile_prepassfinal
这类 Shader 会写入:
GBuffer0:颜色、反射率等
GBuffer1:法线信息
GBuffer2:镜面属性
ZBuffer:深度信息
🧠 而这些是由 Unity 延迟渲染管线统一接管,你写的 Pass 只是在一个阶段中填数据而已(颜色合成之后处理)。
| 状态 | 控制指令 | 解释 |
|---|---|---|
| 颜色写入 | ColorMask / Blend |
是否写颜色,以及怎么混合 |
| 深度写入 | ZWrite |
是否写 Z-buffer |
| 深度测试 | ZTest |
是否通过深度判断 |
| 模板写入与测试 | Stencil 系列指令 |
与遮罩有关的逻辑(可选) |
| 渲染队列 | Tags { "Queue" } |
控制多个物体的绘制顺序 |
Queue 是 Shader 层级的渲染排序标签,不是 Pass 层级的属性
Unity 只会读取 SubShader 或 Shader 的最外层 Tags { "Queue" = "..." },用于决定这个物体的整体渲染排序位置。
渲染队列是以“物体为单位”提交到 GPU 的,而不是以 Pass 为单位。
Stencil 是一个独立的缓冲区
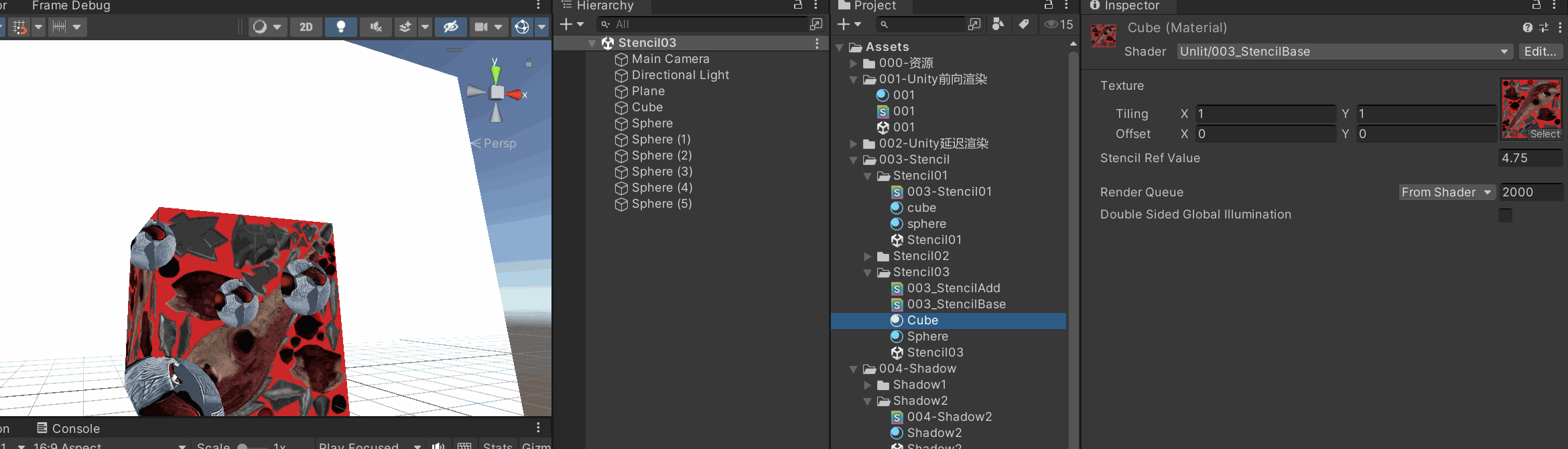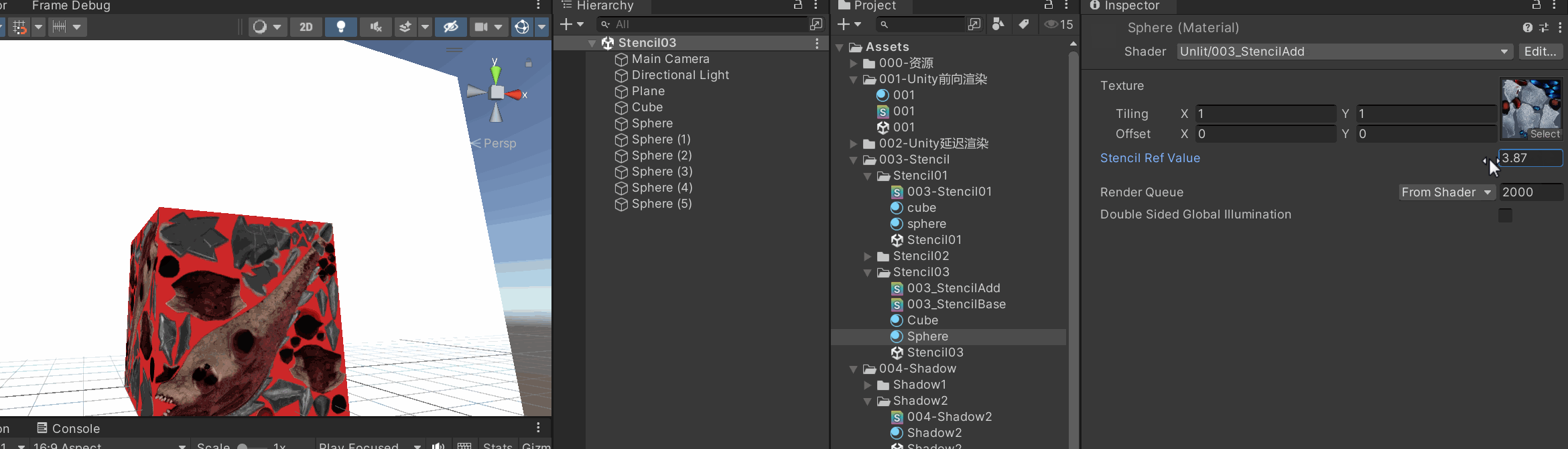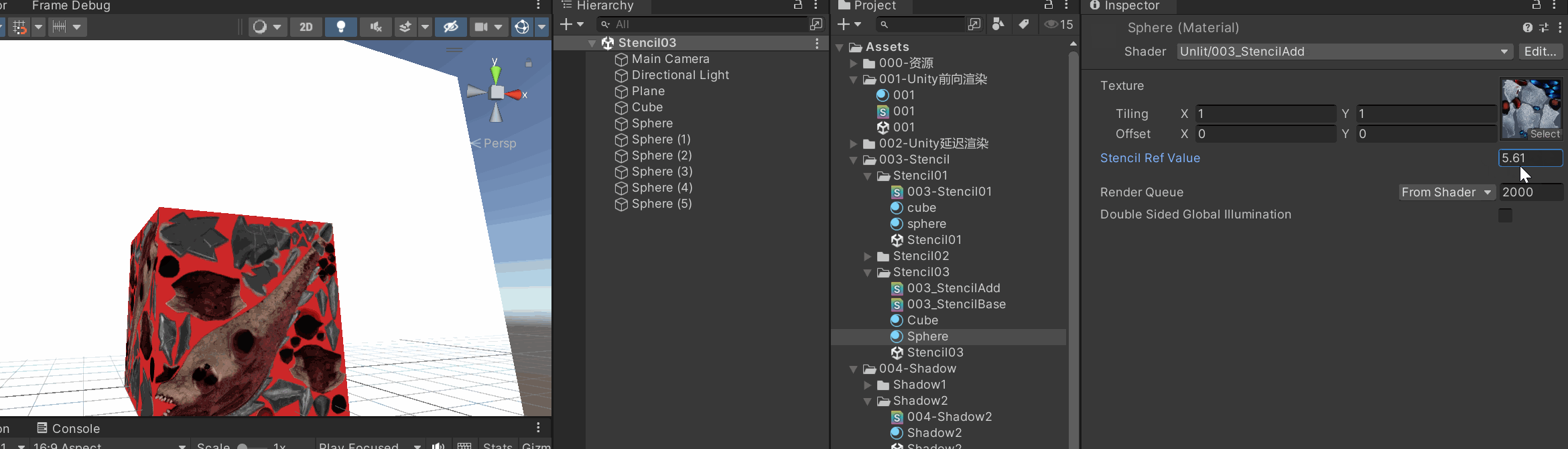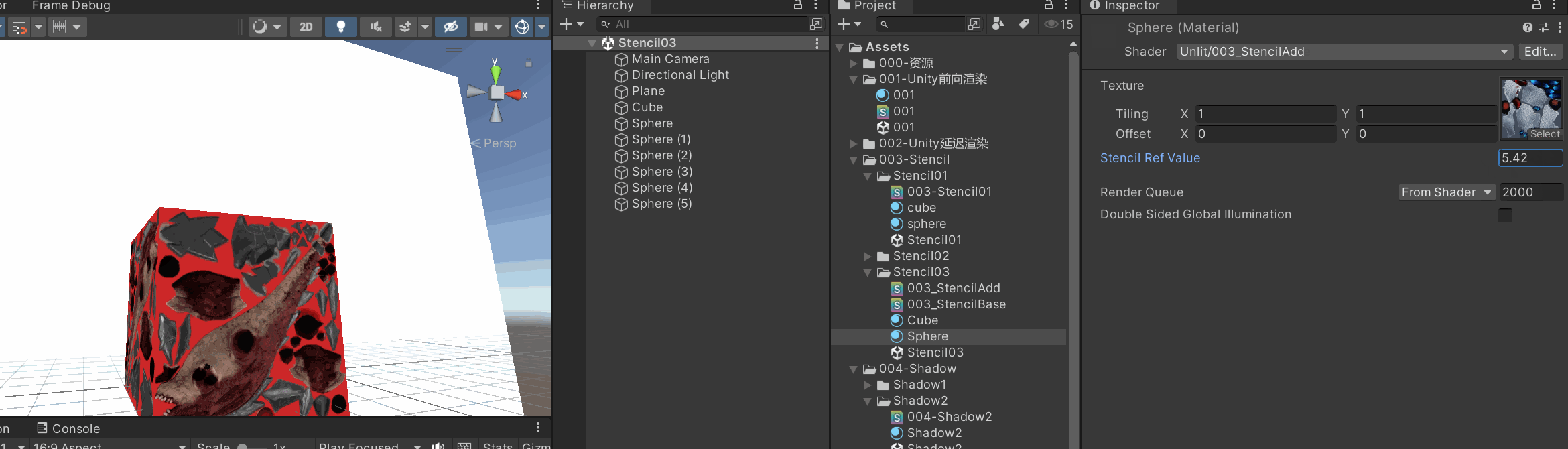
| 参数 | 类型 | 默认值 | 含义 |
|---|---|---|---|
| Ref | int (0–255) |
0 | 要和当前像素的 stencil 值进行比较的参考值。 |
| ReadMask | int (位掩码) |
255 (0xFF) | 比较时参与的位。Stencil 值 和 Ref 都会与这个掩码进行 & 运算后再比较。 |
| Comp | enum |
Always |
参考值和当前 stencil 值之间的比较方式。 |
| Pass | enum |
Keep |
stencil 测试 + 深度测试都通过时,对 stencil 值的操作。 |
| Fail | enum |
Keep |
stencil 测试失败时的操作。 |
| ZFail | enum |
Keep |
stencil 测试通过,但深度测试失败时的操作。 |
| WriteMask | int |
255 | 写入 stencil 值时使用的掩码,限制修改的位。 |
和 Z-buffer(深度缓冲)与 Color buffer(颜色缓冲)并列存在;
每个像素对应一个 整数值(通常是 8 位),范围是 0–255;
每次像素渲染时可以:
读取 当前像素的 stencil 值;
比较 该值与设定值;
写入/替换/递增/递减 stencil 值。
Stencil 设置是作用在 Shader 中每个 Pass 上的,而不是整个 Shader 统一的
换句话说,Stencil 是 per-Pass 设置,每个 Pass 可以有不同的 stencil 行为。
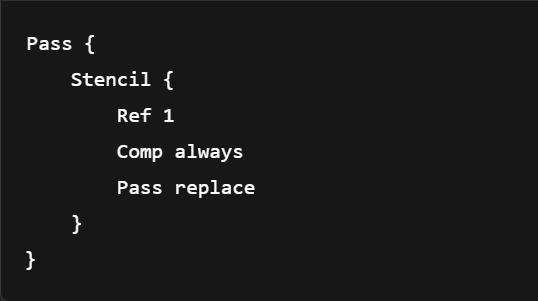
意味着:
当前这个 Pass 渲染的像素,会把 stencil buffer 对应像素的值设置为 1;
只有当前 Pass 受到影响;
下一个 Pass 可以设置不同的行为,例如只允许 stencil=1 的像素通过:
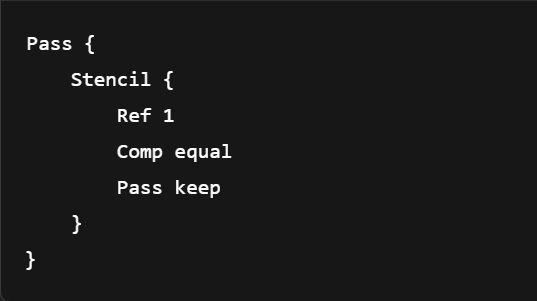
🧠 理解关键点:Stencil 的作用范围和时间线
| 范畴 | 是否共享 | 注解 |
|---|---|---|
| ❗ 同一个物体的多个 Pass | ✅ 共享 stencil 缓冲,后续 Pass 可以读取前面 Pass 写入的值 | |
| ❗ 不同 Shader(即不同材质) | ✅ 共享 stencil 缓冲,只要渲染在同一个屏幕上 | |
| ✅ 不同物体 | ✅ 共享 stencil(只要渲染到同一 framebuffer) | |
| ✅ 所有物体渲染完成后,下一帧之前 | ✅ stencil 值会保留 | 通常每帧被清零(除非开启持久 framebuffer) |
🧠 Comp 比较方式
| 值 | 作用 | 解释 |
|---|---|---|
Always |
总是通过 | 不管 stencil 值是啥都通过(常用于写入) |
Never |
总是失败 | 所有片元都会被 stencil 拒绝(调试用) |
Equal |
相等时通过 | Ref & ReadMask == Stencil & ReadMask |
NotEqual |
不等时通过 | Ref != Stencil |
Less / Greater |
小于 / 大于 | 比较参考值与 stencil 值的大小 |
LEqual / GEqual |
小于等于 / 大于等于 | 同上 |
| 值 | 含义 |
|---|---|
Keep |
保留当前 stencil 值 |
Zero |
把 stencil 值设为 0 |
Replace |
把 stencil 值替换为 Ref |
Invert |
取反 stencil 值(按位) |
IncrSat / DecrSat |
递增/递减(饱和到 [0,255]) |
IncrWrap / DecrWrap |
递增/递减(255 回到 0) |
如果你写在 SubShader 外层(如下):
SubShader {
Stencil {
Ref 1
Comp Equal
Pass Keep
}
Pass {
// ...
}
}
Unity 会忽略这个设置,它不会自动分发到每个 Pass,也不会报错,但行为是未定义的(通常不执行)。
Stencil 必须写在某个具体的 Pass 块中

在 Unity 的渲染管线中,每个 Pass 对每个片元(fragment)执行以下操作:
剪裁测试(Scissor Test):判断片元是否在渲染区域内。
模板测试(Stencil Test):
使用
Ref、Comp、ReadMask等参数进行比较。如果测试失败,执行
Fail操作,片元被丢弃。
深度测试(Depth Test):
使用
ZTest指令设置比较函数。如果测试失败,执行
ZFail操作,片元被丢弃。
模板缓冲区更新(Stencil Buffer Update):
如果前两个测试都通过,执行
Pass操作,更新模板缓冲区。
颜色混合(Blending):
使用
Blend指令设置混合模式。使用
ColorMask指令控制写入的颜色通道。
颜色缓冲区写入(Color Buffer Write):
将最终颜色写入颜色缓冲区。
深度缓冲区写入(Depth Buffer Write):
如果启用了
ZWrite,将深度值写入深度缓冲区。
在 Unity 的 ShaderLab 中,ZTest(深度测试)可以在 SubShader 或 Pass 级别设置。Amplify Creations
在
SubShader中设置ZTest:该设置会应用于该SubShader中的所有Pass,除非某个Pass中另行指定了ZTest。在
Pass中设置ZTest:该设置仅影响当前Pass,并会覆盖在SubShader中的设置

stencil的comp是整数的比较,equal是一定范围内(差不多1左右)相等就算相等