KIMI K1.5: SCALING REINFORCEMENT LEARNING WITH LLMS
Scaling的解释:
- 通过系统性的方法扩展强化学习算法的能力,使其能够处理更复杂的问题、更大的状态/动作空间、更长的训练周期或更高效的资源利用
原文摘要:
研究背景与问题定位
传统预训练的瓶颈:
- 语言模型通过"next token prediction",虽能有效利用算力,但性能受限于训练数据量。当数据耗尽时,模型改进停滞。
RL的潜力与挑战:
- 强化学习理论上能让LLM通过"探索-奖励"机制自我生成数据,突破数据量限制。但此前RL训练LLM的公开成果未能达到竞争力水平。
关键问题:
- 如何设计一个简单有效的RL框架,避免复杂方法(如蒙特卡洛树搜索MCTS)的计算负担,同时实现多模态推理的突破?
Kimi K1.5的核心创新
RL训练技术
摒弃复杂组件:
- 不依赖MCTS、价值函数或过程奖励模型,而是通过改进的策略优化方法(policy optimization)直接优化模型行为。
长上下文规模化(Long Context Scaling):
- 扩展模型处理长序列的能力,这对RL中的多步推理至关重要。
性能突破与实验结果
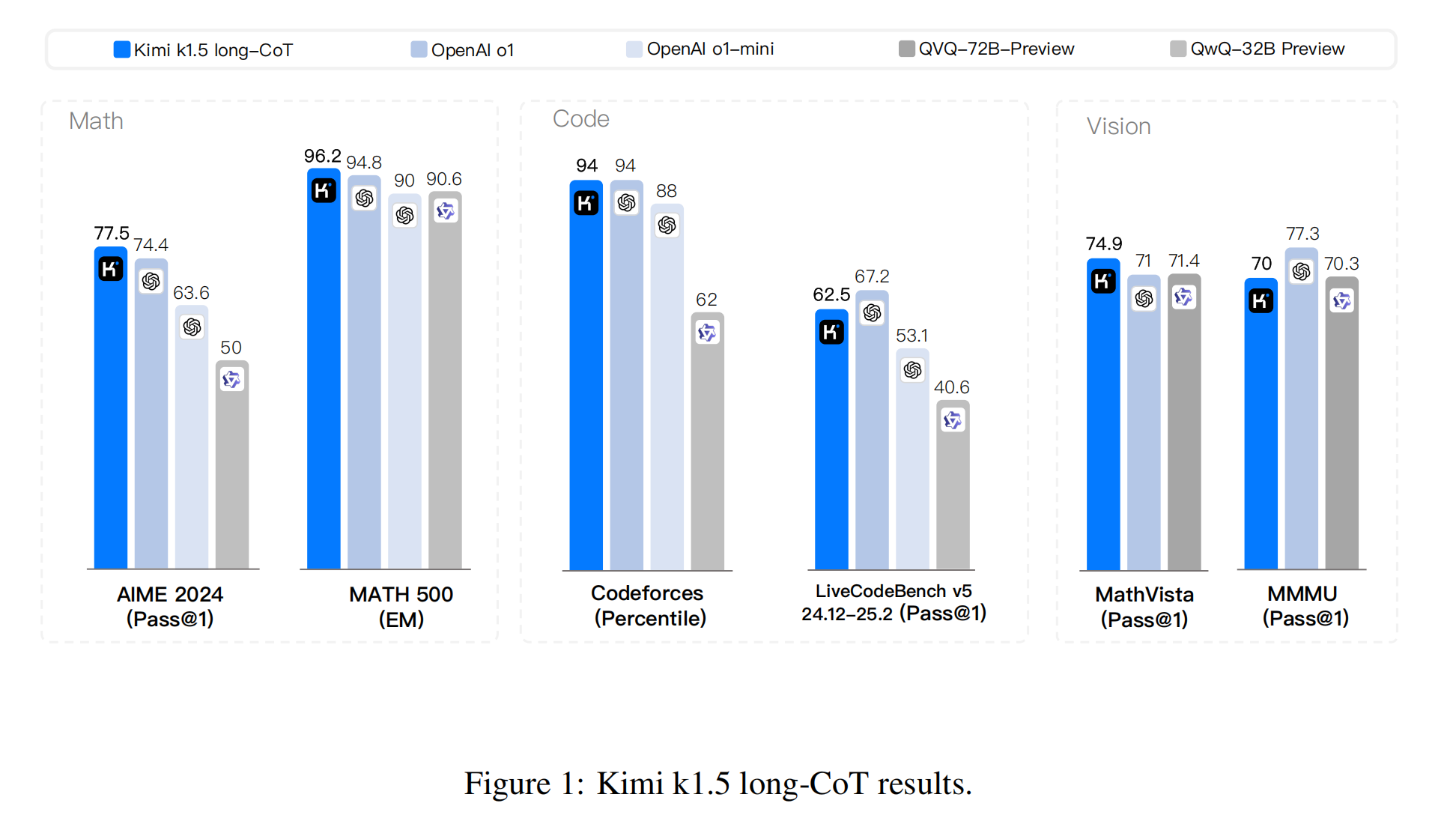
多模态SOTA
数学推理:MATH500(96.2)、MathVista(74.9)
编程:Codeforces(94%百分位)
综合推理:AIME(77.5)
- 对比基线:直接对标OpenAI的未公开模型"o1"(推测为GPT-4级模型)。
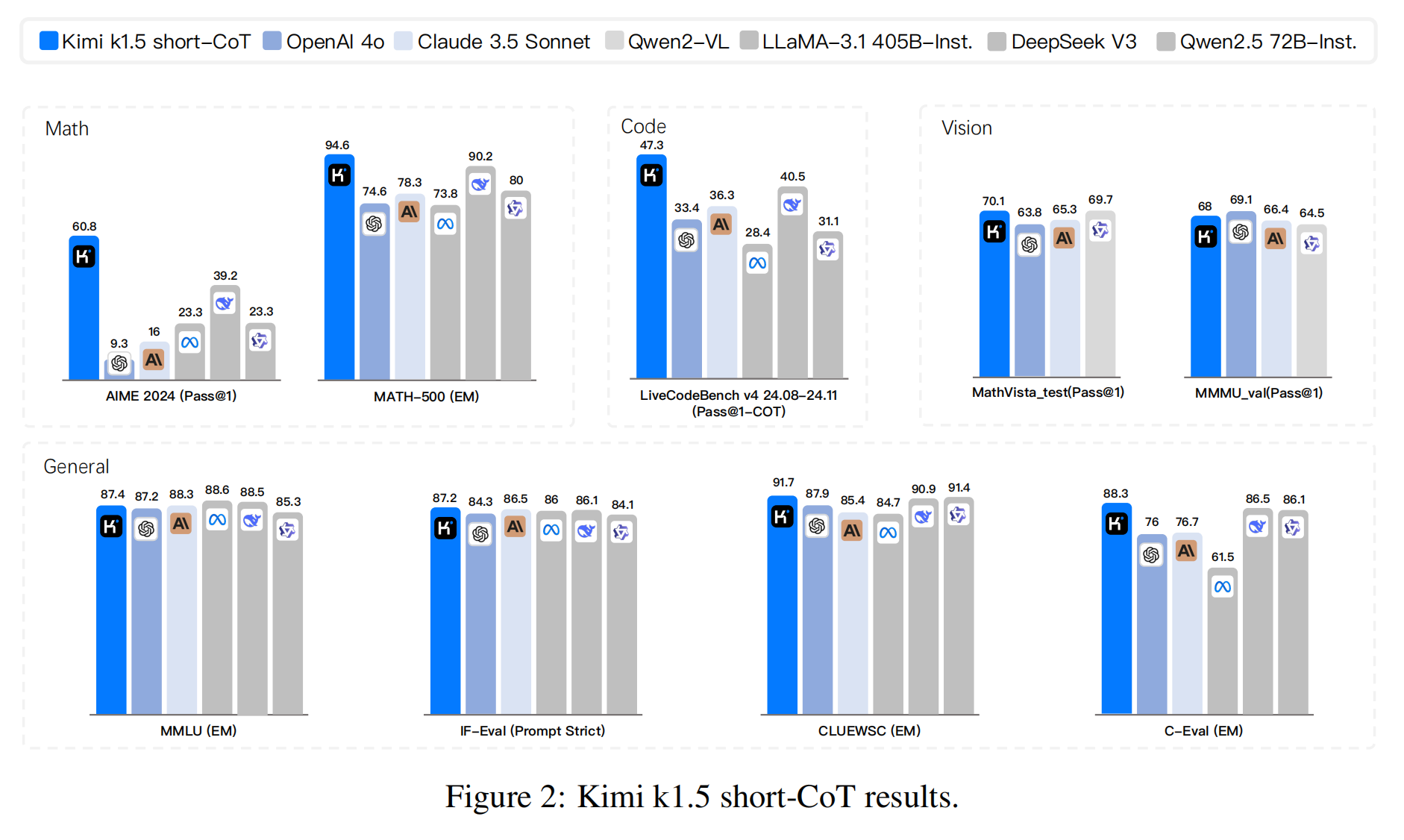
长上下文→短上下文迁移(Long2Short)
- 技术本质:用长链思维(Long-CoT)技术增强短链推理(Short-CoT)模型,可能通过:
- 长序列预训练后蒸馏到短上下文模型
- 在长上下文中学习推理模式,迁移到短任务
- 短上下文SOTA:
- LiveCodeBench(47.3)超越GPT-4o和Claude 3.5 Sonnet达**+550%**(需注意基准差异可能放大百分比)。
- 技术本质:用长链思维(Long-CoT)技术增强短链推理(Short-CoT)模型,可能通过:
1. Introduction
研究背景与现有局限
传统缩放定律(Scaling Law)的瓶颈:
- 模型性能随参数和数据规模按比例提升,但这一范式受限于**高质量训练数据的有限性。
- 当前LLM的发展面临“数据墙”:人工标注或清洗后的优质数据即将耗尽。
RL的潜力与挑战:
- RL理论上允许模型通过“探索-奖励”机制自我生成数据,从而突破静态数据集的限制。
- 但此前RL训练LLM的研究未能实现竞争力(如Anthropic的早期RLHF效果有限)。
方法论亮点
长上下文规模化(Long Context Scaling)
技术实现:
- 将RL的上下文窗口扩展至128K tokens,观察到性能随长度持续提升。
- 上下文窗口指模型在生成或处理文本时,能够“看到”和利用的前文token的最大数量
- 部分轨迹重用(Partial Rollouts):通过复用历史轨迹片段(如已生成的推理步骤)提升训练效率,避免从头生成。
- 将RL的上下文窗口扩展至128K tokens,观察到性能随长度持续提升。
理论意义:
- 上下文长度被证明是RL缩放的新关键维度。
策略优化改进(Improved Policy Optimization)
算法设计:
- 基于**长链思维(Long-CoT)的RL公式,采用在线镜像下降(Online Mirror Descent)**的变体优化策略。
- 引入长度惩罚(Length Penalty)和数据配方优化,平衡生成长度与推理质量。
对比优势:
- 无需价值函数或过程奖励模型,简化了传统RL的复杂 pipeline。
多模态联合训练
- 模型同时处理文本和视觉数据,支持跨模态推理(如图文联合解题)。
核心创新点总结
简化RL框架:
- 仅依赖长上下文和策略梯度,舍弃MCTS、价值函数等组件,降低计算成本。
Long2Short迁移技术:
将长上下文CoT(如复杂推理链)蒸馏到短上下文模型,提升短任务性能(如+550%超越GPT-4o)。
技术细节:通过长度惩罚激活和模型融合实现知识迁移。
2. Approach
Kimi的整体训练流程
- 预训练
- 常规监督微调
- 长链思维监督微调
- 强化学习训练
RL提示词集的构建方法(第1节)
长链思维监督微调(第2节)
RL训练策略(第3节)
预训练和常规监督微调(第5节)
2.1 RL Prompt Set Curation
提示词的作用
引导稳健推理:通过多样化任务迫使模型学习深层逻辑,而非记忆表面模式。
规避常见风险:
- 奖励破解(Reward Hacking):模型通过取巧(如猜测)而非正确推理获得奖励。
- 过拟合:模型仅擅长特定类型问题,丧失泛化能力。
高质量提示词集的三大标准
多样覆盖(Diverse Coverage)
领域覆盖:涵盖STEM(科学、技术、工程、数学)、编程、通用推理等多领域任务(含纯文本和图文多模态数据)。
实现方法:
- 自动过滤器:筛选需复杂推理且易于评估的问题。
- 标签系统(tagging system):按学科分类标注,确保各领域均衡表示。
难度平衡(Balanced Difficulty)
动态评估方法:
- 基于模型的难度评估:用SFT模型对每个提示生成10次答案(高温度采样增加多样性)。
- 通过率计算:正确率越低,难度越高(例:通过率20%→标记为“困难”)。
- 优势:难度评估与模型能力对齐,避免人工标注偏差。
可验证性(Accurate Evaluability)
- 核心要求:确保答案和推理过程均可被客观验证
- 防止“过程全错,结果全对”。
- 解决方案:
- 排除高风险题型:直接移除多选题、判断题等。
- 反破解检测:
- 让模型不带思维链(CoT)直接猜测答案。
- 若在N次尝试内猜中正确答案(N=8),则判定该提示易被破解,予以剔除。
- 核心要求:确保答案和推理过程均可被客观验证
2.2 Long-CoT Supervised Fine-Tuning
核心目标与实现路径
目标:
- 让模型在强化学习训练前,先掌握人类式的多步推理策略(如规划、评估、反思、探索)。
实现方法:
- 基于精修的RL提示集,构建小规模但高质量的长链思维预热数据集。
- 通过轻量级SFT让模型初步内化这些推理模式,为后续RL训练奠定基础。
长链思维预热数据集的关键设计
数据构建方法:提示工程 + 拒绝采样
- 通过提示工程直接生成高质量长链推理路径,仅保留验证正确的样本。
数据内容:
- 包含文本和图像输入的已验证多步推理过程。
2.3 Reinforcement Learning
2.3.1 Problem Setting
2.3.1.1 问题定义
输入与目标:
- 给定训练集 D = { ( x i , y i ∗ ) } i = 1 n D = \{(x_i, y_i^*)\}_{i=1}^n D={(xi,yi∗)}i=1n,其中 x i x_i xi 是问题, y i ∗ y_i^* yi∗ 是标准答案
- 目标是训练策略模型 π θ \pi_\theta πθ,使其能通过生成思维链(CoT) z = ( z 1 , … , z m ) z = (z_1, \dots, z_m) z=(z1,…,zm) 逐步推理出正确答案 y y y
自回归生成:
- 模型按顺序生成中间步骤 z t ∼ π θ ( ⋅ ∣ x , z 1 : t − 1 ) z_t \sim \pi_\theta(\cdot|x, z_{1:t-1}) zt∼πθ(⋅∣x,z1:t−1),最后生成答案 y ∼ π θ ( ⋅ ∣ x , z 1 : m ) y \sim \pi_\theta(\cdot|x, z_{1:m}) y∼πθ(⋅∣x,z1:m)
- 示例:
- 解方程 x + 2 = 5 x + 2 = 5 x+2=5 时,模型可能生成:
- z 1 z_1 z1: “移项得 x = 5 − 2 x = 5 - 2 x=5−2” → $z_2 $: “计算得 x = 3 x = 3 x=3” → y y y: “3”。
- 示例:
- 模型按顺序生成中间步骤 z t ∼ π θ ( ⋅ ∣ x , z 1 : t − 1 ) z_t \sim \pi_\theta(\cdot|x, z_{1:t-1}) zt∼πθ(⋅∣x,z1:t−1),最后生成答案 y ∼ π θ ( ⋅ ∣ x , z 1 : m ) y \sim \pi_\theta(\cdot|x, z_{1:m}) y∼πθ(⋅∣x,z1:m)
2.3.1.2 规划算法(Planning Algorithms)
搜索树( τ \tau τ)构建
节点表示:每个节点表示部分解 s = ( x , z 1 : ∣ s ∣ ) s = (x, z_{1:|s|}) s=(x,z1:∣s∣) 包含问题 x x x 和当前部分思维链 z 1 : ∣ s ∣ z_{1:|s|} z1:∣s∣(即已生成的思维链片段)。
价值评估:通过评判模型(Critic Model) v v v 对部分解打分 v ( x , z 1 : ∣ s ∣ ) v(x, z_{1:|s|}) v(x,z1:∣s∣),判断当前推理是否正确或需调整。
- 反馈形式:可以是标量分数(如0.8)或自然语言(如“这一步的公式有误”)。
搜索过程
选择扩展节点:根据价值分数选择最有潜力的节点(如最高分或最少错误)。
生成新步骤:从该节点继续生成 z ∣ s ∣ + 1 z_{|s|+1} z∣s∣+1,扩展搜索树。
迭代优化:重复直到生成完整解 y y y 。
- 类比:类似AlphaGo的蒙特卡洛树搜索(MCTS),但操作对象是文本序列而非棋步。
算法视角的规划
输入:
- 在第 t t t 次迭代时,规划算法 A A A 接收历史搜索记录 ( s 1 , v ( s 1 ) , … , s t − 1 , v ( s t − 1 ) ) (s_1, v(s_1), \dots, s_{t-1}, v(s_{t-1})) (s1,v(s1),…,st−1,v(st−1))
输出:
- 下一步方向: A ( s t ∣ s 1 , v ( s 1 ) , … ) A(s_t \mid s_1, v(s_1), \dots) A(st∣s1,v(s1),…) – 决定如何扩展搜索(如选择哪个节点继续生成)。
- 当前反馈: A ( v ( s t ) ∣ s 1 , v ( s 1 ) , … , s t ) A(v(s_t) \mid s_1, v(s_1), \dots, s_t) A(v(st)∣s1,v(s1),…,st) – 评估最新步骤的合理性。
传统实现:
- 需显式维护搜索树(如蒙特卡洛树),存储所有可能的分支和评估结果,计算成本高昂
关键视角转变:从树搜索到序列建模
统一表示为语言序列
符号简化: 将部分解 s s s 和反馈 v v v 均视为语言标记序列 z z z(如 z 1 z_1 z1: “第一步:设变量x”, z 2 z_2 z2: “反馈:这一步正确”)。
算法重定义: 规划算法 A A A 变为对序列 ( z 1 , z 2 , … ) (z_1, z_2, \dots) (z1,z2,…) 的映射,直接生成下一步 z t z_t zt 或反馈 v ( z t ) v(z_t) v(zt) 。
搜索树的扁平化
长上下文替代显式树结构:
所有历史步骤和反馈被拼接为单一序列,作为模型的上下文窗口(共128K tokens)。
示例: 模型生成10步数学推导后,发现矛盾并回溯修改第5步,全程仅通过注意力机制关联相关步骤,无需独立存储树节点。
computational buget:
- 传统规划中,搜索深度受限于计算资源;在此框架中,token数量(即上下文长度)成为隐式搜索的“预算”。
自回归预测
- 动态调整:模型在生成下一步时,可基于全部历史上下文隐式“评估”最优方向。
2.3.1.3 强化学习
**奖励模型 r r r **:
- 可验证问题:通过预先定义的准则来判断结果正确与否。正确-- r ( x , y , y ∗ ) = 1 r(x, y, y^*) = 1 r(x,y,y∗)=1 ,否则为 r = 0 r = 0 r=0。
- 开放问题(如自由文本):训练判别模型预测 y y y 是否匹配 y ∗ y^* y∗。
优化目标:
max θ E ( x , y ∗ ) ∼ D , ( y , z ) ∼ π θ [ r ( x , y , y ∗ ) ] \max_\theta \mathbb{E}_{(x,y^*)\sim D, (y,z)\sim \pi_\theta} [r(x, y, y^*)] θmaxE(x,y∗)∼D,(y,z)∼πθ[r(x,y,y∗)]- 即最大化生成正确答案的期望奖励。
RL的优势:
- 模型通过试错学习动态调整推理路径(如发现错误后回溯),而非机械遵循固定CoT模板。
2.3.2 Policy Optimization
目标函数设计
核心思想:
- 在每次迭代 i i i 中,以当前策略 π θ i \pi_{\theta_i} πθi 为参考,优化以下目标:
max θ E ( x , y ∗ ) ∼ D [ E ( y , z ) ∼ π θ [ r ( x , y , y ∗ ) ] − τ KL ( π θ ( x ) ∥ π θ i ( x ) ) ] \max_\theta \mathbb{E}_{(x,y^*)\sim D} \left[ \mathbb{E}_{(y,z)\sim \pi_\theta} [r(x,y,y^*)] - \tau \text{KL}(\pi_\theta(x) \| \pi_{\theta_i}(x)) \right] θmaxE(x,y∗)∼D[E(y,z)∼πθ[r(x,y,y∗)]−τKL(πθ(x)∥πθi(x))]
- 第一项:最大化生成答案的奖励 r ( x , y , y ∗ ) r(x,y,y^*) r(x,y,y∗)
- 第二项:KL散度正则化,约束新策略 π θ \pi_\theta πθ 与参考策略 π θ i \pi_{\theta_i} πθi 的偏离程度,由超参数 τ \tau τ 控制。
闭式解与损失函数
闭式解:
- 最优策略 π ∗ \pi^* π∗ 的形式为指数加权更新:
π ∗ ( y , z ∣ x ) = π θ i ( y , z ∣ x ) exp ( r ( x , y , y ∗ ) / τ ) Z \pi^*(y,z|x) = \frac{\pi_{\theta_i}(y,z|x) \exp(r(x,y,y^*)/\tau)}{Z} π∗(y,z∣x)=Zπθi(y,z∣x)exp(r(x,y,y∗)/τ)
- 其中 Z Z Z 为归一化因子。取对数后可得约束:
r ( x , y , y ∗ ) − τ log Z = τ log π ∗ ( y , z ∣ x ) π θ i ( y , z ∣ x ) r(x,y,y^*) - \tau \log Z = \tau \log \frac{\pi^*(y,z|x)}{\pi_{\theta_i}(y,z|x)} r(x,y,y∗)−τlogZ=τlogπθi(y,z∣x)π∗(y,z∣x)
- 作用:
- 保证策略的概率归一化
- Z Z Z 确保更新后的策略 π ∗ π^∗ π∗ 仍然是有效的概率分布(即所有可能的 ( y , z ) (y,z) (y,z) 的概率和为1)。
- 支持离策略(Off-Policy)优化
- 通过此约束,可以用旧策略 π θ i \pi_{\theta_i} πθi 的样本估计 Z Z Z 和策略梯度,而无需依赖当前策略的 π θ \pi_{\theta} πθ样本。
- 保证策略的概率归一化
替代损失函数:
为了优化这个目标函数,使用了一个代替的损失函数
L ( θ ) = E ( x , y ∗ ) ∼ D [ E ( y , z ) ∼ π θ i [ ( r ( x , y , y ∗ ) − τ log Z − τ log π θ ( y , z ∣ x ) π θ i ( y , z ∣ x ) ) 2 ] ] L(\theta) = \mathbb{E}_{(x,y^*)\sim D} \left[ \mathbb{E}_{(y,z)\sim \pi_{\theta_i}} \left[ \left( r(x,y,y^*) - \tau \log Z - \tau \log \frac{\pi_\theta(y,z|x)}{\pi_{\theta_i}(y,z|x)} \right)^2 \right] \right] L(θ)=E(x,y∗)∼D[E(y,z)∼πθi[(r(x,y,y∗)−τlogZ−τlogπθi(y,z∣x)πθ(y,z∣x))2]]归一化因子估计:
- 用 k k k 个样本 ( y j , z j ) ∼ π θ i (y_j,z_j) \sim \pi_{\theta_i} (yj,zj)∼πθi 近似 τ log Z ≈ τ log ( 1 k ∑ j = 1 k exp ( r ( x , y j , y ∗ ) / τ ) ) \tau \log Z \approx \tau \log \left( \frac{1}{k} \sum_{j=1}^k \exp(r(x,y_j,y^*)/\tau) \right) τlogZ≈τlog(k1∑j=1kexp(r(x,yj,y∗)/τ))
奖励基线:
- 使用样本奖励的均值 r ˉ = mean ( r ( x , y 1 , y ∗ ) , … , r ( x , y k , y ∗ ) ) \bar{r} = \text{mean}(r(x,y_1,y^*), \dots, r(x,y_k,y^*)) rˉ=mean(r(x,y1,y∗),…,r(x,yk,y∗)) 作为基线,减少方差。
梯度更新
对每个问题 x x x,采样 k k k 个响应 ( y j , z j ) (y_j,z_j) (yj,zj),计算梯度:
∇ θ L ≈ 1 k ∑ j = 1 k [ ∇ θ log π θ ( y j , z j ∣ x ) ( r ( x , y j , y ∗ ) − r ˉ ) − τ 2 ∇ θ ( log π θ ( y j , z j ∣ x ) π θ i ( y j , z j ∣ x ) ) 2 ] \nabla_\theta L \approx \frac{1}{k} \sum_{j=1}^k \left[ \nabla_\theta \log \pi_\theta(y_j,z_j|x) (r(x,y_j,y^*) - \bar{r}) - \frac{\tau}{2} \nabla_\theta \left( \log \frac{\pi_\theta(y_j,z_j|x)}{\pi_{\theta_i}(y_j,z_j|x)} \right)^2 \right] ∇θL≈k1j=1∑k[∇θlogπθ(yj,zj∣x)(r(x,yj,y∗)−rˉ)−2τ∇θ(logπθi(yj,zj∣x)πθ(yj,zj∣x))2]第一项:策略梯度(带基线),鼓励高奖励行为。
第二项:正则化项,防止策略突变。
离策略Off-Policy特性:样本来自旧策略 π θ i \pi_{\theta_i} πθi,而非当前策略 π θ \pi_\theta πθ。
每个iteration后,新的策略作为下一个策略的参考策略
舍弃价值函数
传统价值函数的局限
信用分配问题:在传统RL中,价值函数用于评估中间状态(如部分CoT步骤 z 1 : t z_{1:t} z1:t )的优劣,指导策略更新
- 示例:若 z t + 1 z_{t+1} zt+1 正确而 z t + 1 ′ z'_{t+1} zt+1′ 错误,价值函数会惩罚 z t + 1 ′ z'_{t+1} zt+1′
抑制探索:这种机制可能阻碍模型尝试错误但有益的路径
Kimi的方案
最终奖励驱动:
仅用答案正确性 r ( x , y , y ∗ ) r(x,y,y^*) r(x,y,y∗) 作为全局奖励,允许模型自由探索中间错误步骤。
优势:
- 模型可从错误中恢复(如生成错误步骤后修正),学习更鲁棒的推理能力。
- 提升模型在复杂推理场景中的泛化能力与策略规划能力。
长上下文支持:
- 模型通过长窗口记忆完整推理路径,隐式学习“试错-修正”模式,无需显式信用分配。
2.3.3 Length Penalty
过度思考现象
在RL训练过程中,模型倾向于生成越来越长的推理过程,尽管这可能会提高最终答案的准确性,但也带来了以下问题:
训练和推理成本增加:生成长序列需要更多的计算资源(如GPU内存和推理时间)。
人类偏好不符:人类通常更喜欢简洁、高效的推理过程,而非冗长的推导。
根本原因:
- RL训练的目标是最大化奖励,而模型发现增加推理步骤的长度可以提高正确率。但这并不总是最优的,因为部分冗长步骤可能是无效的。
长度奖励(Length Reward)
长度奖励的计算方法
给定一个问题 x x x 和 k k k 个采样响应 ( y 1 , z 1 ) , … , ( y k , z k ) (y_1, z_1), \dots, (y_k, z_k) (y1,z1),…,(yk,zk)(其中 z i z_i zi 是思维链, y i y_i yi 是最终答案):
计算每个响应的长度: len ( i ) = token数量 ( y i , z i ) \text{len}(i) = \text{token数量}(y_i, z_i) len(i)=token数量(yi,zi)
确定最短和最长的响应长度: min_len = min i len ( i ) \text{min\_len} = \min_i \text{len}(i) min_len=minilen(i), max_len = max i len ( i ) \text{max\_len} = \max_i \text{len}(i) max_len=maxilen(i)。
如果所有响应长度相同( max_len = min_len \text{max\_len} = \text{min\_len} max_len=min_len): 不施加长度奖励。
否则,计算每个响应的长度奖励 len_reward ( i ) \text{len\_reward}(i) len_reward(i):
如果答案正确 r ( x , y i , y ∗ ) = 1 r(x, y_i, y^*) = 1 r(x,yi,y∗)=1:
λ = 0.5 − len ( i ) − min_len max_len − min_len \lambda = 0.5 - \frac{\text{len}(i) - \text{min\_len}}{\text{max\_len} - \text{min\_len}} λ=0.5−max_len−min_lenlen(i)−min_len- 奖励较短响应,惩罚较长响应
如果答案错误 r ( x , y i , y ∗ ) = 0 r(x, y_i, y^*) = 0 r(x,yi,y∗)=0:
len_reward ( i ) = min ( 0 , λ ) \text{len\_reward}(i) = \min(0, \lambda) len_reward(i)=min(0,λ)- 额外惩罚长且错误的响应(避免模型通过增加无效步骤“骗奖励”)。
长度奖励的应用
- 加权融合:将长度奖励与原始奖励结合– total_reward = original_reward + α ⋅ len_reward \text{total\_reward} = \text{original\_reward} + \alpha \cdot \text{len\_reward} total_reward=original_reward+α⋅len_reward
- 其中 α \alpha α 是超参数,控制长度惩罚的强度。
- 加权融合:将长度奖励与原始奖励结合– total_reward = original_reward + α ⋅ len_reward \text{total\_reward} = \text{original\_reward} + \alpha \cdot \text{len\_reward} total_reward=original_reward+α⋅len_reward
Warm-up
直接施加长度惩罚可能会导致初期训练不稳定
因为模型尚未学会有效推理,过早惩罚长度会阻碍学习。因此,论文采用两阶段训练策略:
第一阶段(无长度惩罚): 使用标准RL优化,让模型先学会生成正确的推理过程。
第二阶段(引入长度惩罚): 在模型已经具备一定推理能力后,再施加长度奖励,优化推理效率。
2.3.4 Sampling Strategies
样本效率瓶颈
尽管RL算法能通过困难问题产生更大梯度(推动模型快速学习),但其训练效率仍受限于:
无效探索:模型在早期对困难问题的采样大多错误,导致训练信号稀疏。
数据分布不均:不同难度的问题混合训练时,简单问题可能主导梯度更新,而困难问题学习不足。
解决思路:
- 利用先验知识(如问题难度标签、历史成功率)优化采样策略,使模型聚焦于最有效的训练数据。
数据收集与难度标注
显式难度标签
- 数据来源:训练集天然包含学科等级标签(如“小学数学”vs.“数学竞赛题”)。
动态成功率统计
跟踪每个问题的历史表现:
- 在RL训练中,同一问题 x i x_i xi 会被多次采样,记录其成功率 s i s_i si(即模型生成正确答案的比例)。
意义:
- s i s_i si 越低,说明当前模型在该问题上表现越差,需更多训练。
采样策略
Curriculum Sampling
核心思想:由易到难渐进学习,模仿人类教育中的“课程设计”。
实现方式:
- 初期:主要采样简单问题,让模型快速掌握基础推理能力。
- 后期:逐步增加困难问题的比例,引导模型解决复杂任务。
Prioritized Sampling
核心思想:聚焦模型当前最弱的问题,类似“查漏补缺”。
实现方式:
- 计算每个问题 x i x_i xi 的采样权重 w i ∝ ( 1 − s i ) w_i \propto (1 - s_i) wi∝(1−si)( s i s_i si 为历史成功率)。
- 低成功率问题( s i s_i si 小)获得更高采样概率。
2.3.5 More details on Training Recipe
2.3.5.1 Test Case Generation for Coding
问题背景
数据缺陷:许多网络爬取的编程题缺乏官方测试用例,无法直接用于RL训练(因奖励需基于测试通过率计算)。
特殊判题限制:仅支持标准输入输出判题的题目(排除需特殊判题逻辑的题目,如交互题、SPJ题)。
目标:
- 利用题目描述和参考答案,自动生成有效、多样化的测试用例,确保RL训练的可靠性。
方法设计:自动化测试用例生成流程
工具与输入
测试生成库:基于开源工具 CYaRon(专用于竞赛题测试用例生成)。
输入内容:
- 题目描述(Problem Statement)。
- 参考答案(Ground Truth Solutions,假设至少存在10个正确解法)。
生成与验证步骤
初步生成:
- 使用CYaRon + Kimi k1.5生成50个候选测试用例。
有效性过滤:
对每个测试用例,随机选取10个参考答案运行,检查输出一致性。
有效性标准:至少7/10的答案输出一致 → 保留该测试用例。
题目级筛选:
通过有效性过滤的测试用例组成最终测试集。
入选标准:至少9/10的参考答案能通过所有保留的测试用例 → 该题目+测试集加入训练数据。
统计结果
初始数据:1,000个网络竞赛题中,614个符合标准判题要求。
成功生成:463个题目生成≥40个有效测试用例。
最终训练集:323个题目(通过率≈70%)。
2.3.5.2 Reward Modeling for Math
问题背景
- 在数学题的强化学习(RL)训练中,如何准确评估模型生成的答案是一个关键挑战。由于数学表达式的多样性(如因式分解、展开、等价变形等),简单的字符串匹配无法判断答案的正确性。
解决方案
经典奖励模型
设计灵感: 基于InstructGPT(Ouyang et al. 2022)的方法,使用标量输出的判别式模型。
输入输出:
- 输入:问题、参考答案、模型响应。
- 输出:标量分数(如1=正确,0=错误)。
数据规模: 收集约80万条数学题数据(问题-答案对)进行微调。
优点:
- 计算高效,适合快速推理。
- 可复用NLP领域的成熟RM架构(如BERT、RoBERTa)。
局限: 无法处理复杂等价性(如不同形式的表达式需人工设计规则)。
思维链奖励模型
设计动机: 引入分步推理**提升对数学严谨性的判断能力。
输入输出:
输入:与Classic RM相同(问题、参考答案、响应)。
输出:先生成分步推理过程,再输出JSON格式的最终判断。
{ "reasoning": "Step 1: 检查响应是否等价于参考答案... Step 2: 验证因式分解是否正确...", "correctness": true }
数据规模: 收集约80万条带人工标注思维链的数据(如标注员需解释为何答案等价或错误)。
优点:
- 更高准确率:通过分步验证处理数学等价性(如展开表达式后比较)。
- 可解释性:JSON输出提供错误定位(如“Step 2未正确应用平方差公式”)。
计算成本: 比Classic RM更耗时,但对数学等复杂任务必要性显著。
2.3.5.3 Vision Data
在Kimi K1.5的训练中,视觉数据(Vision Data)的设计旨在增强模型对多模态输入(图像+文本)的理解与推理能力,尤其是提升视觉-语言对齐的准确性。
视觉数据的三大类别
真实世界数据(Real-world Data)
数据来源:
- 科学问题图像:需结合图形理解的题目。
- 地理定位任务:基于视觉线索推断位置。
- 图表分析:复杂统计图表的解读与推理。
作用: 直接提升模型在真实场景中的视觉推理能力。
合成视觉推理数据(Synthetic Visual Reasoning Data)
生成方式:
- 程序化生成图像:通过算法自动创建几何图形、空间关系图、物体交互场景等。
- 可控难度设计:调整复杂度(如增加遮挡、变形)以针对性训练特定能力。
作用:
- 高效训练专项技能:如空间推理、几何模式识别。
- 无限数据供给:避免真实数据标注成本高的问题。
文本渲染数据(Text-rendered Data)
构建方法:
- 将纯文本(如代码、文档、表格)转换为图像。
作用:
- 模态一致性:确保模型对同一内容(无论文本原生或图像化)输出相同答案。
- 抗干扰能力:处理现实中的模糊文本图像(如低质量扫描件、屏幕反光)。
2.4 Long2short: Context Compression for Short-CoT Models
问题背景:Long-CoT的局限性
优势:Long-CoT模型通过多步详细推理(如128K上下文)在复杂任务(如数学、编程)中表现优异。
劣势:
- 高Token成本:生成冗长的推理过程增加计算开销,影响推理速度。
- 人类偏好不符:用户通常更青睐简洁的答案。
目标: 将Long-CoT的“思维先验”(如规划、纠错能力)迁移到Short-CoT模型中,在不增加Token预算的前提下提升性能。
四大迁移方法
Model Merging
方法:
- 直接对Long-CoT模型和Short-CoT模型的权重取平均,生成新模型。
- 无需训练,低成本实现能力迁移。
原理:
- Long-CoT的权重包含多步推理的隐式知识,通过融合注入Short-CoT。
优势:
- 保留Long-CoT的泛化能力,同时减少推理长度。
局限:
- 若两模型架构差异大,可能导致性能不稳定。
Shortest Rejection Sampling
方法:
- 对同一问题,用Long-CoT生成 n=8 个不同长度的响应。
- 选择其中最短的正确响应作为监督微调(SFT)样本。
作用:
- 强制Short-CoT学习Long-CoT的高效推理路径,避免冗余步骤。
优势:
- 简单高效,无需复杂优化。
示例:
- 生成长度分别为 [50, 100, 120, 80] tokens的答案,选择最短的正确解(如80 tokens)。
DPO, Direct Preference Optimization
方法:
- 用Long-CoT生成多组响应,按长度和正确性分类:
- 正样本:最短的正确解。
- 负样本:
- 错误的长响应。
- 正确但过长(如长度 > 1.5倍正样本)的响应。
- 基于正负样本对训练Short-CoT,通过DPO对齐人类偏好(简洁+正确)。
- 用Long-CoT生成多组响应,按长度和正确性分类:
优势:
- 显式优化简洁性-正确性权衡,优于传统RLHF。
Long2Short RL
方法:
- 第一阶段:标准RL训练,优化性能(不限制长度)。
- 第二阶段:
- 从第一阶段选择性能与长度平衡的模型作为基础。
- 施加长度惩罚,显著减少最大生成长度。
- 惩罚正确但冗长的响应,鼓励简洁推理。
作用:
- 在保持性能的前提下,通过RL微调压缩推理步骤。
优势:
- 动态调整生成策略,适应不同Token预算。
2.5 Other Training Details
2.5.1 Pretraining
数据选择
语言数据
英语:通用文本、学术文献、对话等
中文:新闻、书籍、百科、社交媒体等
代码:多种编程语言的公开代码库(如Python、C++)
数学推理:数学问题、证明、符号计算
知识类数据:结构化知识库(如百科、科学术语)
多模态数据(视觉-语言联合训练)
图像描述(Captioning):图文配对数据(如COCO、Flickr)
图文交错(Image-text Interleaving):文档、网页中的图文混合内容
OCR文本识别:场景文字、表格、手写体图像
知识增强数据:带视觉标注的知识图谱(如维基百科配图)
视觉问答(QA):基于图像的问答对
严格数据质量控制
相关性筛选:剔除低质量、无关或噪声数据
多样性保障:覆盖不同领域、语言风格和难度级别
平衡性优化:避免某些数据类型或主题过度主导
预训练流程
Vision-Language Pretraining
目标:建立强大的语言基础,逐步融合多模态能力
方法:
- 先训练纯文本模型,确保语言理解能力
- 分阶段引入图像、OCR等多模态数据,避免早期过拟合
能力巩固 Cooldown
目标:强化推理与知识任务的表现
方法:
- 使用精选数据(如数学证明、科学问答)微调模型
- 引入合成数据(如程序化生成的几何问题)填补长尾需求
长上下文激活 Long-Context Activation
目标:扩展序列处理能力至 131,072 tokens
方法:
- 采用稀疏注意力、分块训练等技术优化长序列效率
- 在推理、知识检索等任务中验证长上下文有效性
2.5.2 Vanilla Supervised Finetuning
数据集构建方法
非推理任务(问答、写作、文本处理等)
种子数据集构建:通过人工标注构建初始高质量数据集,并训练种子模型。
数据扩展:
- 收集多样化提示(prompts),使用种子模型为每个提示生成多个响应。
- 标注员对响应进行排序,并优化排名最高的响应,形成最终版本。
推理任务(数学、编程等)
- 基于规则与奖励模型的验证:相比人工评判,采用**拒绝采样(Rejection Sampling)**扩展SFT数据集,确保答案准确性。
数据集规模与组成
文本数据(约100万条):
- 通用问答:50万条
- 编程任务:20万条
- 数学与科学:20万条
- 创意写作:5千条
- 长上下文任务(摘要、文档问答、翻译、写作等):2万条
文本-视觉数据(100万条):
- 图表解析、OCR、基于图像的对话、视觉编程、视觉推理、带视觉辅助的数学/科学问题等。
训练策略
两阶段训练:
- 第一阶段(32K tokens):
- 训练1个epoch
- 学习率从 2 × 1 0 − 5 2 \times 10^{-5} 2×10−5 衰减至 2 × 1 0 − 6 2 \times 10^{-6} 2×10−6
- 第二阶段(128K tokens):
- 训练1个epoch
- 学习率重新预热至 1 × 1 0 − 5 1 \times 10^{-5} 1×10−5,最终衰减至 1 × 1 0 − 6 1 \times 10^{-6} 1×10−6
- 第一阶段(32K tokens):
训练效率优化:
- 将多个训练样本打包(pack)到单个训练序列中,提升GPU利用率。
2.6 RL Infrastructure
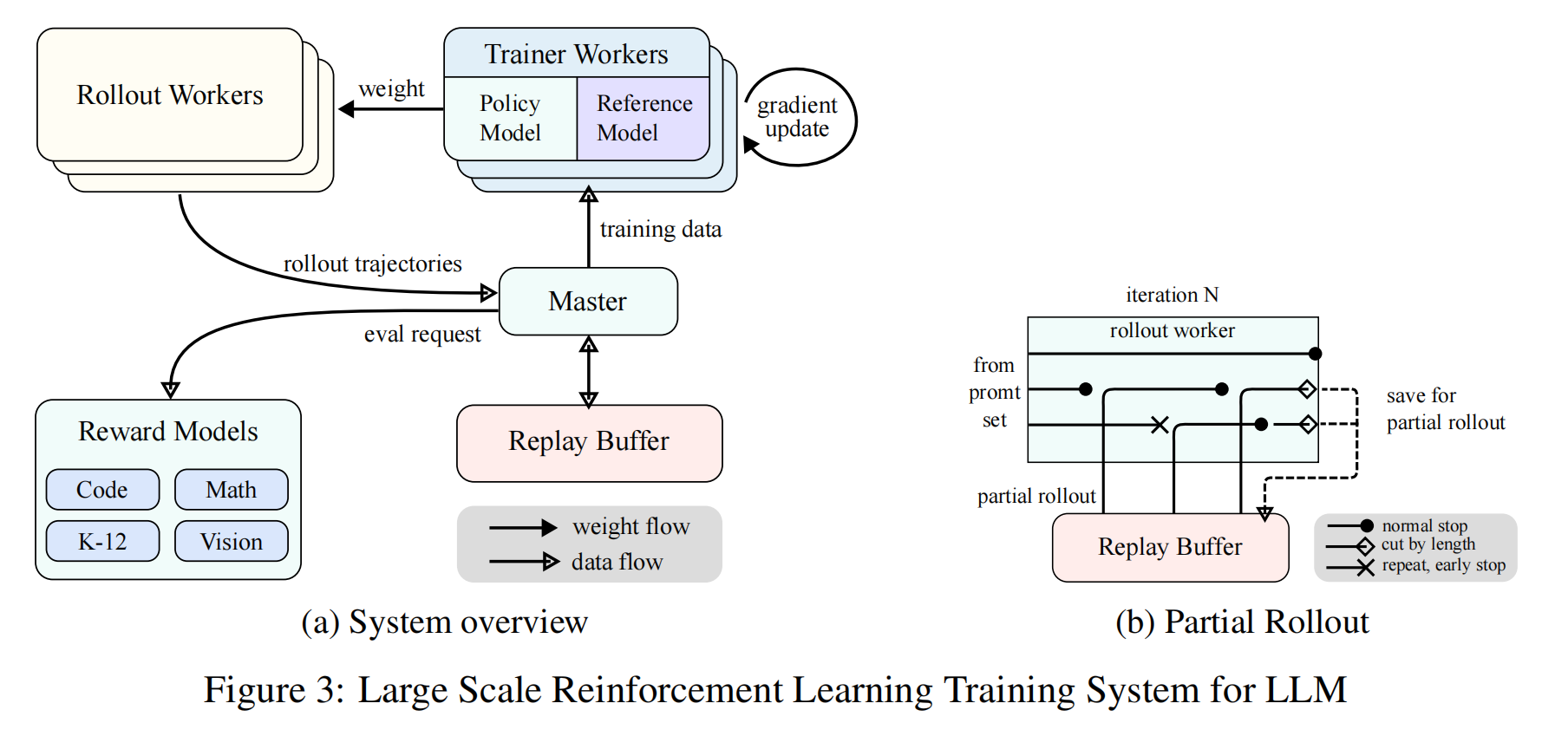
2.6.1 Large Scale Reinforcement Learning Training System for LLM
整体流程(见图3a)
采用迭代同步更新的闭环系统,包含两个核心阶段:
Rollout Phase(轨迹生成阶段)
- Rollout Workers(轨迹生成器):
- 在中央控制器(Master)协调下,与当前环境模型交互,生成多组响应轨迹(如不同解题路径)。
- 使用Partial Rollout技术,复用历史轨迹片段,避免重复生成完整序列(降低计算成本)。
- Replay Buffer(经验回放池):
- 存储多样化轨迹,打破时间相关性,确保训练数据无偏。
- Rollout Workers(轨迹生成器):
Training Phase(训练阶段)
Trainer Workers(训练器):
- 从回放池采样轨迹,计算梯度并更新模型参数。
Reward Model(奖励模型):
- 评估生成内容的质量,提供反馈信号。
Code Execution Service(代码执行服务):
- 对编程类问题,实时执行模型生成的代码,验证功能正确性,提供精确奖励信号。
系统协同设计
Central Master:
- 协调Rollout Workers、Trainer Workers、Reward Model之间的数据流,确保负载均衡。
Reward Model的多元反馈:
- 对非编程任务(如数学):基于规则或人工标注评估答案正确性。
- 对编程任务:通过代码执行服务验证实际运行结果(如单元测试通过率)。
2.6.2 Partial Rollouts for Long CoT RL
核心问题与挑战
Long-CoT的痛点:
- 生成完整的长推理轨迹需消耗大量计算资源。
- 同步训练时,长轨迹会阻塞系统,导致GPU利用率低下(短任务需等待长任务完成)。
目标:
- 高效利用计算资源:避免长轨迹独占GPU。
- 支持超长序列生成:不因长度限制牺牲模型性能。
Partial Rollouts 的运作机制
分块生成与迭代延续
固定Token预算:
设定单次Rollout的最大生成长度,超长的轨迹会被分块处理。
示例:
若任务需生成50K tokens的数学证明:
第一次Rollout:生成0-10K tokens → 存入Replay Buffer。
第二次Rollout:从10K tokens处继续生成10-20K tokens → 更新Buffer。
依此类推,直至完成全部50K tokens。
优势:
- 避免单次生成50K tokens的显存爆炸问题。
异步Rollout Workers
并行化处理:
- 长轨迹Worker:持续处理未完成的分块(如从第10K tokens继续)。
- 短轨迹Worker:同时处理新任务(如生成短问答)。
效果:
- 计算资源最大化利用,避免GPU空闲等待。
Replay Buffer 的智能管理
存储分块轨迹:保存未完成的轨迹片段(如iter n-m 到 iter n-1 的中间状态),供后续迭代直接调用。
动态加载:当前迭代(iter n)仅需计算最新分块(on-policy),历史分块从Buffer复用。
优势:减少重复计算,提升训练速度。
关键技术优化
重复检测(Repeat Detection)
问题:模型可能生成重复内容(如循环论证),浪费Token预算。
解决方案:
- 实时检测重复序列(如连续相同的公式推导步骤)。
- 提前终止:强制结束重复部分的生成。
- 惩罚机制:在损失函数中增加重复惩罚项,抑制冗余生成。
分块训练的损失计算
选择性回传梯度: 仅对关键分块(如最终答案块)计算完整损失,中间分块可跳过或降权。
目的: 避免无关中间步骤干扰策略优化。
3. Experiments
3.1 Benchmarks
Text Benchmark:
- MMLU (Hendrycks et al. 2020)
- IF-Eval (J. Zhou et al. 2023)
- CLUEWSC (L. Xu et al. 2020)
- C-EVAL (Y. Huang et al. 2023)
Reasoning Benchmark:
- HumanEval-Mul
- LiveCodeBench (Jain et al. 2024)
- Codeforces
- AIME 2024
- MATH-500 (Lightman et al. 2023)
Vision Benchmark:
- MMMU (Yue, Ni, et al. 2024)
- MATH-Vision (K. Wang et al. 2024)
- MathVista (Lu et al.2023)