5月16日复盘
一、图像处理之目标检测
1. 目标检测认知
Object Detection,是指在给定的图像或视频中检测出目标物体在图像中的位置和大小,并进行分类或识别等相关任务。
目标检测将目标的分割和识别合二为一。
What、Where
2. 使用场景
目标检测用于以下场景:
- 图像处理;
- 自动驾驶:检测周围的车辆、行人、交通灯、道路标志等;
- 安防监控:监控公共场,发现异常行为,保障公共安全;
- 人脸检测;
- 医学影像分析:在医学影像方面可以识别肿瘤、组织变异等,用于医疗辅助;
- 无人机应用:识别特定目标,引导无人机飞行,比如监测天气、线路检测、搜寻救援、军事等;
- 缺陷检测:工业;
更多场景:140个场景
【https://blog.csdn.net/wcl291121957/article/details/138313404】
【https://blog.csdn.net/wcl291121957/article/details/138318995】
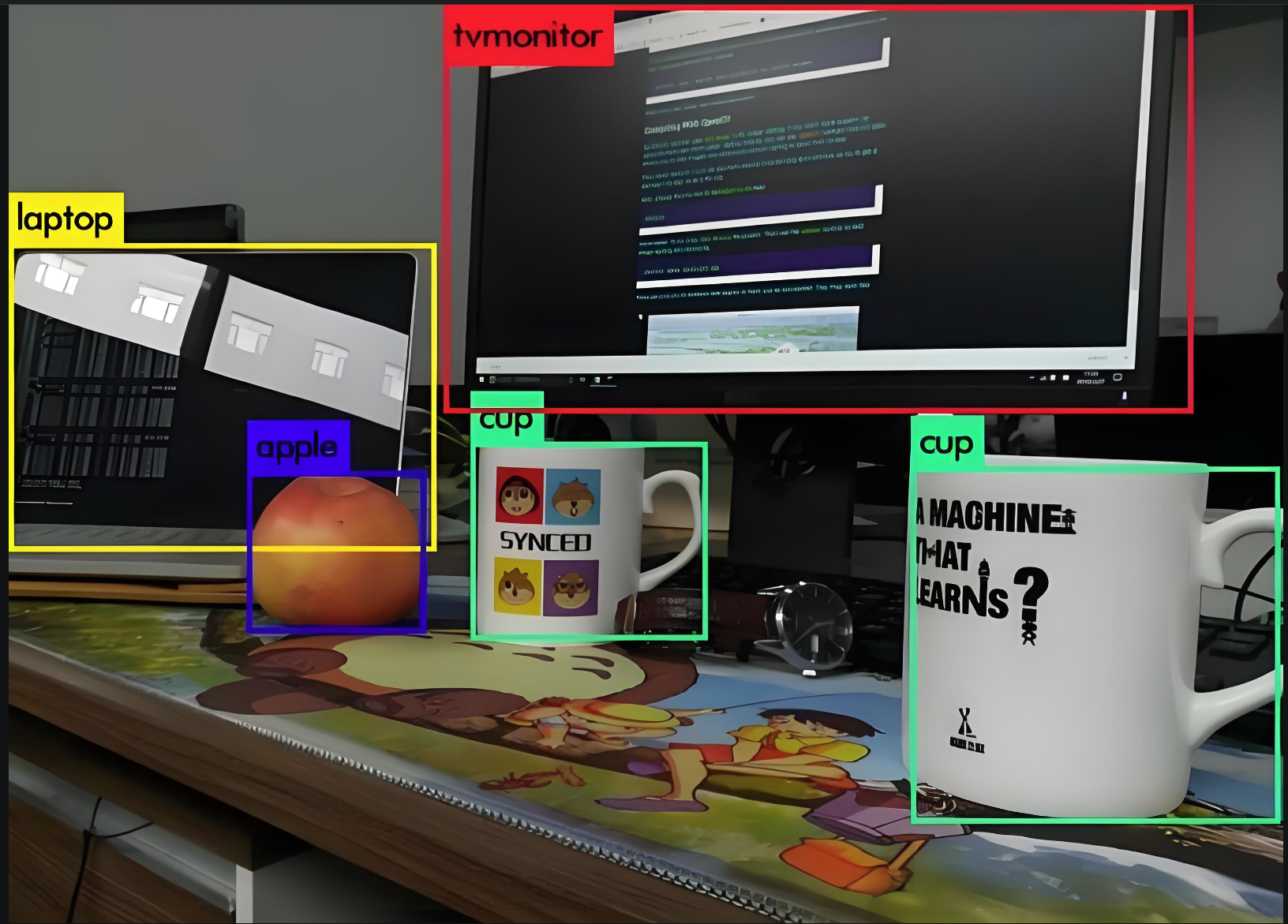
3. 目标识别与标注
目标识别包含了分类 + 坐标位置(x, y, w, h)
What、where
二、目标检测网络基础
1. 目标检测方法
Detection主要分为以下三个支系:
| one-stage系 | two-stage系 | ||
|---|---|---|---|
| 主要算法 | YOLO系列、SSD、RetinaNet | Fast R-CNN、Faster R-CNN | R-CNN、SPPNet |
| 检测精度 | 较低(随着网络的改进,精度也不低) | 较高 | 极高 |
| 检测速度 | 较快(达到实时视频流级别) | 较慢,5 fps | 极慢 |
| 鼻祖 | YOLOv1 | Fast R-CNN | R-CNN |
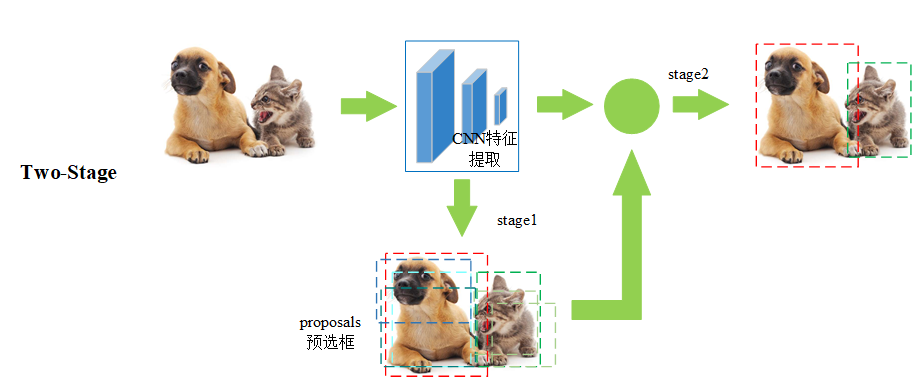
1.1 two-stage
双阶段,两部到位,特点如下:
- 候选区域生成:第一阶段生成候选区域(Region Proposals);
- 区域分类和回归:第二阶段对候选区域进行分类和回归,即对每个候选区域进行目标分类和位置精修。
- 代表算法:R-CNN(Region-CNN)系列,包括Fast R-CNN、Faster R-CNN、Mask R-CNN等。
基本流程:

比如猫狗混合图:
1.2 one-stage
单阶段,一步到位,特点如下:
- 端到端训练:直接从图像中提取特征并进行分类和回归,即同时进行目标分类和位置回归。
- 实时性高:由于仅有一个阶段,计算速度快,适合实时应用。
- 代表算法:YOLO(You Only Look Once)系列、SSD等。
基本流程:
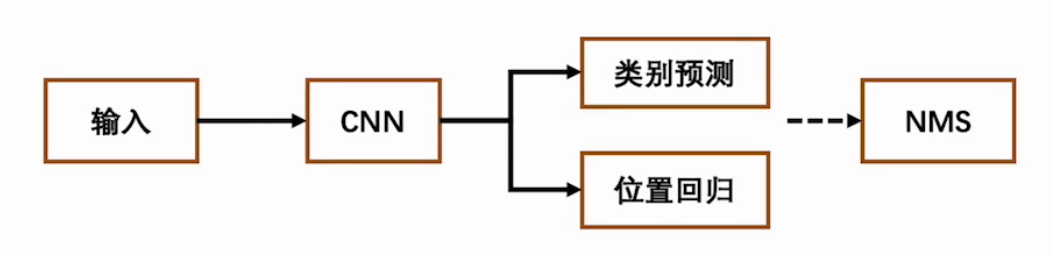
比如猫狗混合图:

2. 目标检测指标
2.1 目标框指标
在目标检测中,每个检测出的目标物体通常都会标注一个框(Bounding Box),用于表示目标的位置和大小,这个框叫目标框。
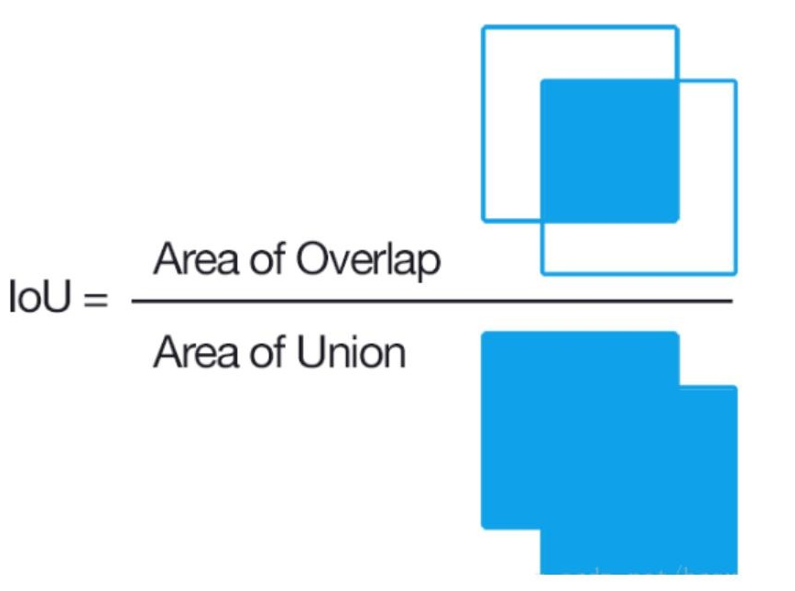
2.1.1 IoU
基础英文单词:【交集】Intersection 【并集】Union
loU(Intersection over Union),预选框正确性的度量指标。
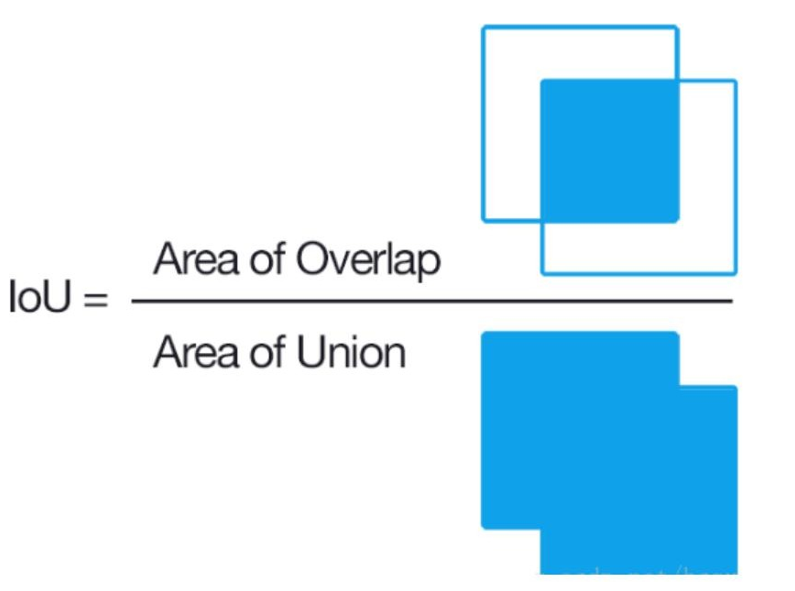
前景目标交并比:
I o U = A ∩ B A ∪ B IoU=\frac{\mathrm{A\cap B}}{\mathrm{A\cup B}} IoU=A∪BA∩B
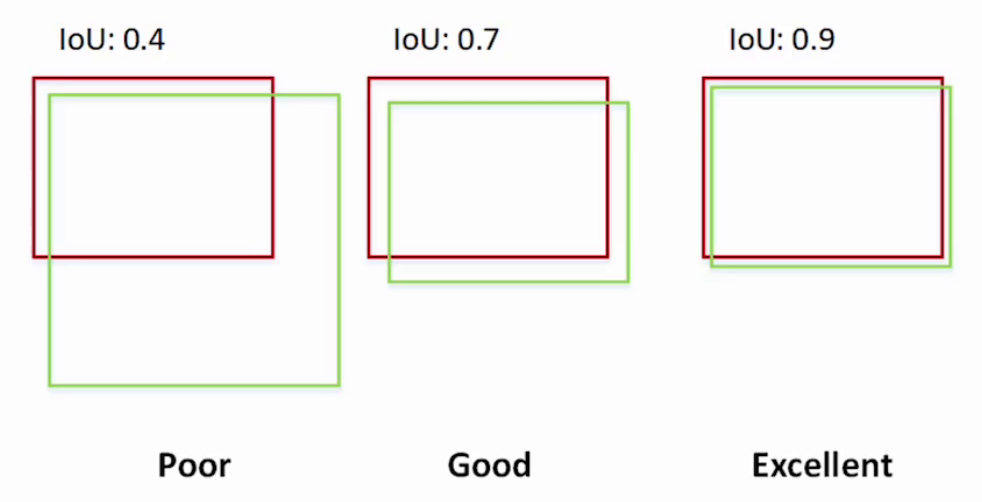
**比如:**红框是真实位置及大小,绿色框是预选框
2.1.2 Confidence

- 假设现在你是唐伯虎,你需要在一群人中找到秋香(检测人脸)。你们应该都已经找到了,并且很自信地肯定,绿色框内的人脸就是秋香。但是计算机没有这么自信呀,它只能够生成一系列预测框(红色框),每个框有一个值,称之为置信度,置信度可以暂时理解为自信程度,类比到你自己,你们是不是很自信地认为绿色框框就是秋香的脸,如果你百分百肯定这个框就是秋香,那好,这个框框的置信度就为 1,只是听大家说秋香长得很漂亮,这时候有些人会觉得黄色框框里的人长得也挺漂亮,我觉得黄色框框内的人是秋香,但是又看看绿色框框,好像这个才是秋香,纠结来纠结去,一下子拿不定主意,所以现在的他显得有点不够自信了,不过他最终还是做出了如下判断

- 目标检测过程中,往往最后会生成很多的预测框,每个预测框自身都会带一个置信度,用来衡量预测框内为目标(秋香)的自信程度,自信程度越高,说明当前训练的模型对于这个框的结果越认可。这个认可的自信程度就被称为置信度。
在目标检测中,目标框会标注一个置信度(Confidence Score),通常指的是模型对于预测结果的置信程度。
置信度通常是一个0到1之间的实数,是由神经网络模型预测出来的,代表着模型对该预选框的信心。
置信度一般分为两部分:
- 目标存在置信度(Objectness score):一个标量,表示预选框中存在(任何)目标的概率。
- 类别置信度(Class confidence):多个标量(每个类别一个),预选框中目标属于每一个类别的概率。
置信度是通过神经网络模型在训练过中学习得到的:
- 分类损失(Classification loss):用于计算类别置信度的误差。
- 定位损失(Localization loss):用于计算预选框与实际标注框之间的位置误差。
- 目标存在的损失(Objectness loss):用于计算目标存在置信度的误差。
综合置信度:
在某些目标检测算法(如YOLO)中,综合置信度通常表示为:
综合置信度 = 目标存在的置信度 × 类别置信度 综合置信度=目标存在的置信度×类别置信度 综合置信度=目标存在的置信度×类别置信度
置信度的预测机制使得目标检测算法能够在复杂的图像中准确地定位和识别目标物体。
2.2 精度和召回率
精度和召回率的计算是基于置信度阈值来计算的,即IOU的最小值;
2.2.1 混淆矩阵
混淆矩阵是一种特定的表格布局,用于可视化监督学习算法的性能,特别是分类算法。在这个矩阵中,每一行代表实际类别,每一列代表预测类别。矩阵的每个单元格则包含了在该实际类别和预测类别下的样本数量。通过混淆矩阵,我们不仅可以计算出诸如准确度、精确度和召回率等评估指标,还可以更全面地了解模型在不同类别上的性能。
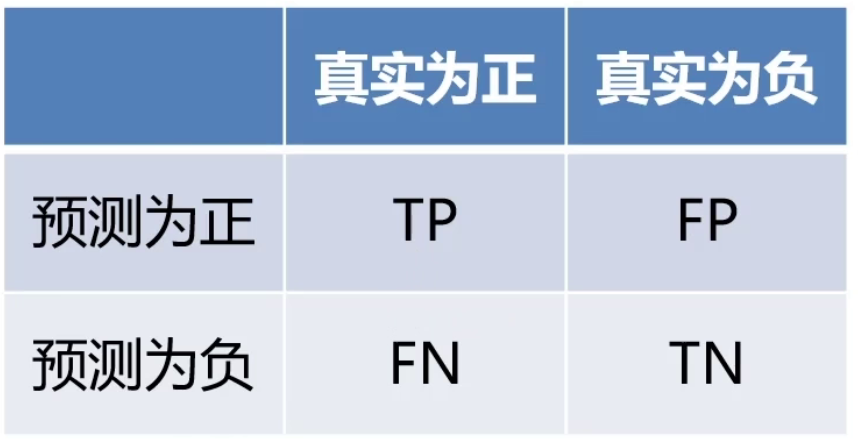
混淆矩阵的四个基本组成部分是:
- True Positives(TP):当模型预测为正类,并且该预测是正确的,我们称之为真正(True Positive);
- True Negatives(TN):当模型预测为负类,并且该预测是正确的,我们称之为真负(True Negative);
- False Positives(FP):当模型预测为正类,但该预测是错误的,我们称之为假正(False Positive);
- False Negatives(FN):当模型预测为负类,但该预测是错误的,我们称之为假负(False Negative)
2.2.2 Precision和Recall
参考下图

2.2.4 小案例
以下是一个关于精度(Precision)和召回率(Recall)的小测试题,用于理解精度和召回率。
假设在一个二分类任务中,我们有以下的混淆矩阵(Confusion Matrix):
| 预测为正类(Positive) | 预测为负类(Negative) | |
|---|---|---|
| 实际为正类(True Positive) | 50 (TP) | 10(FN) |
| 实际为负类(True Negative) | 5(FP) | 35 (TN) |
请计算以下指标:
- 精度(Precision): (50)/50 + 5 = 10 / 11
- 召回率(Recall): (50) / (50 + 10) = 5 / 6
2.3 mAP的计算
- 平均平均精确度(mean Average Precision,mAP) 是在不同置信度阈值下计算的平均精确度(Average Precision, AP)的平均值
- AP 是在不同召回率水平下的精确度平均值,而 mAP 则是多个类别上的 AP 的平均值
- mAP 衡量的是模型在所有类别上的好坏
- mAP 计算步骤
- 计算每个类别的 AP:对于数据集中包含的每个类别,分别计算 AP
- 计算 mAP:将所有类别的 AP 取平均值,得到 mAP
mAP(Mean Average Precision)是评估模型效果的综合指标,是根据recall和Precision计算出来的。
2.3.1 计算步骤
- 根据IoU划分TP和FP;
- 按置信度从大到小进行排序,计算从Top-1到Top-N对应的Precision值和Recall值;
- 绘制P-R曲线,进行AP(面积)计算;
- A P 50 {AP}_{50} AP50:设定目标框置信度阀值(IoU),常用阀值0.5,这意味着如果一个预测框和真实框之间的IoU大于或等于0.5,则认为该预测框是正确的(即正样本),否则认为是错误的(即负样本);
- A P 75 {AP}_{75} AP75:设定目标框置信度阀值(IoU),常用阀值0.75,这意味着如果一个预测框和真实框之间的IoU大于或等于0.75,则认为该预测框是正确的(即正样本),否则认为是错误的(即负样本);
- A P 50 − 95 {AP}_{50-95} AP50−95:阀值设置为0.50、0.55、0.60…·…0.95,针对每个阀值分别求AP之后再求平均值。
2.3.2 案例分析
场景假设:假如有8个( 即真实值为正, TP+FN=8 ) 目标,检索出来20个目标框(ID),即预测值为正(TP+FP=20)。
注意:8个目标不是说一张图有8个label,是所有样本,所有分类一共8个label,比如可能10000张高铁图片,抽烟的人检测到8人。
我们设定一个阈值,比如50%,来决定哪个样本被划分为正类,哪个样本被划分为负类。如果一个样本的置信度评分超过50%,我们就把它看作是正类;如果低于50%,则视为负类。
然后,可以按照置信度评分对所有目标框进行排序。从置信度最高的目标框开始,计算当前状态下模型的精确率和召回率,然后依次增加目标框,再次计算精确率和召回率。重复这个过程,直到遍历完所有目标框。这样,就得到了一系列的精确率和召回率值。
①、目标框的置信度(Confidence Score)以及正负样本预测结果如下表:
| ID | Confidence | TP | FP | IoU | Label |
|---|---|---|---|---|---|
| 1 | 0.23 | 0 | 1 | 0.1 | 0 |
| 2 | 0.76 | 1 | 0 | 0.8 | 1 |
| 3 | 0.01 | 0 | 1 | 0.2 | 0 |
| 4 | 0.91 | 1 | 0 | 0.9 | 1 |
| 5 | 0.13 | 0 | 1 | 0.2 | 0 |
| 6 | 0.45 | 0 | 1 | 0.3 | 0 |
| 7 | 0.12 | 1 | 0 | 0.8 | 1 |
| 8 | 0.03 | 0 | 1 | 0.2 | 0 |
| 9 | 0.38 | 1 | 0 | 0.9 | 1 |
| 10 | 0.11 | 0 | 1 | 0.1 | 0 |
| 11 | 0.03 | 0 | 1 | 0.2 | 0 |
| 12 | 0.09 | 0 | 1 | 0.4 | 0 |
| 13 | 0.65 | 0 | 1 | 0.3 | 0 |
| 14 | 0.07 | 0 | 1 | 0.2 | 0 |
| 15 | 0.12 | 0 | 1 | 0.1 | 0 |
| 16 | 0.24 | 1 | 0 | 0.8 | 1 |
| 17 | 0.10 | 0 | 1 | 0.1 | 0 |
| 18 | 0.23 | 0 | 1 | 0.1 | 0 |
| 19 | 0.46 | 0 | 1 | 0.1 | 0 |
| 20 | 0.08 | 1 | 0 | 0.9 | 1 |
②、按照置信度降序排序
| ID | Confidence | Label |
|---|---|---|
| 4 | 0.91 | 1 |
| 2 | 0.76 | 1 |
| 13 | 0.65 | 0 |
| 19 | 0.46 | 0 |
| 6 | 0.45 | 0 |
| 9 | 0.38 | 1 |
| 16 | 0.24 | 1 |
| 1 | 0.23 | 0 |
| 18 | 0.23 | 0 |
| 5 | 0.13 | 0 |
| 7 | 0.12 | 1 |
| 15 | 0.12 | 0 |
| 10 | 0.11 | 0 |
| 17 | 0.10 | 0 |
| 12 | 0.09 | 0 |
| 20 | 0.08 | 1 |
| 14 | 0.07 | 0 |
| 8 | 0.03 | 0 |
| 11 | 0.03 | 0 |
| 3 | 0.01 | 0 |
③、TOP-N概念理解:以返回的前N个框计算指标,N从1开始直到所有目标框结束。
如果N=5,则可计算出:TP = 2 , FP = 3,共有目标8个
Precision = 2/5 = 40%
Recall = 2/8 = 25%
| ID | Score | Label | 混淆矩阵 |
|---|---|---|---|
| 4 | 0.91 | 1 | True Positives |
| 2 | 0.76 | 1 | True Positives |
| 13 | 0.65 | 0 | False Positives |
| 19 | 0.46 | 0 | False Positives |
| 6 | 0.45 | 0 | False Positives |
如果N = 3 呢?则可计算出:TP = 2 , FP = 1,共有目标8个
Precision = 2/3 = 66.7%
Recall = 2/8 = 25%
随着N的增大,召回率必然不会变小,但是精度也是很难评。
④、mAp计算
PASCAL VOC 2010以前:设置11个recall阈值[0, 0.1, 0.2, …, 1],计算Recall大于等于每一个阈值时的最大Precision,AP即平均值
A P = 1 11 ∑ r ∈ { 0 , 0.1 , . . . , 1 } p i n t e r p ( r ) p i n t e r p ( r ) = max r ~ : r ~ ≥ r p ( r ~ ) r ~ 表示处于阈值 r 和下一级阈值之间的 r e c a l l 值 ( 相同的阈值可能对应不同的精度 ) \mathrm{AP}=\frac{1}{11}\sum_{r\in\{0,0.1,...,1\}}p_{interp(r)}\quad p_{interp(r)}=\max_{\tilde{r}:\tilde{r}\geq r}p(\tilde{r}) \\ \tilde{r}表示处于阈值r和下一级阈值之间的recall值(相同的阈值可能对应不同的精度) AP=111r∈{0,0.1,...,1}∑pinterp(r)pinterp(r)=r~:r~≥rmaxp(r~)r~表示处于阈值r和下一级阈值之间的recall值(相同的阈值可能对应不同的精度)
以上数据整理如下:
| ID | Score | Label | Recall | Precision |
|---|---|---|---|---|
| 4 | 0.91 | 1 | 1/8(0.125) | 1/1 |
| 2 | 0.76 | 1 | 2/8(0.25) | 2/2 |
| 13 | 0.65 | 0 | 2/8(0.25) | 2/3 |
| 19 | 0.46 | 0 | 2/8(0.25) | 2/4 |
| 6 | 0.45 | 0 | 2/8(0.25) | 2/5 |
| 9 | 0.38 | 1 | 3/8(0.375) | 3/6 |
| 16 | 0.24 | 1 | 4/8(0.5) | 4/7 |
| 1 | 0.23 | 0 | 4/8(0.5) | 4/8 |
| 18 | 0.23 | 0 | 4/8(0.5) | 4/9 |
| 5 | 0.13 | 0 | 4/8(0.5) | 4/10 |
| 7 | 0.12 | 1 | 5/8(0.625) | 5/11 |
| 15 | 0.12 | 0 | 5/8(0.625) | 5/12 |
| 10 | 0.11 | 0 | 5/8(0.625) | 5/13 |
| 17 | 0.10 | 0 | 5/8(0.625) | 5/14 |
| 12 | 0.09 | 0 | 5/8(0.625) | 5/15 |
| 20 | 0.08 | 1 | 6/8(0.75) | 6/16 |
| 14 | 0.07 | 0 | 6/8(0.75) | 6/17 |
| 8 | 0.03 | 0 | 6/8(0.75) | 6/18 |
| 11 | 0.03 | 0 | 6/8(0.75) | 6/19 |
| 3 | 0.01 | 0 | 6/8(0.75) | 6/20 |
于是就有了下面的数据:
| R | 0 | 0.1 | 0.2 | 0.3 | 0.4 | 0.5 | 0.6 | 0.7 | 0.8 | 0.9 | 1.0 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| P | 1.0 | 1.0 | 1.0 | 0.5 | 0.571 | 0.571 | 0.455 | 0.375 | 0 | 0 | 0 |
于是可以计算出mAP值:
A P = 1 11 ( 1 + 1 + 1 + 0.5 + 0.571 + 0.571 + 0.455 + 0.375 + 0 + 0 + 0 ) = 49.75 % \begin{aligned}&\mathrm{AP}=\frac{1}{11}(1+1+1+0.5+0.571+0.571+0.455+0.375+0+0+0)\\&=49.75\%\end{aligned} AP=111(1+1+1+0.5+0.571+0.571+0.455+0.375+0+0+0)=49.75%
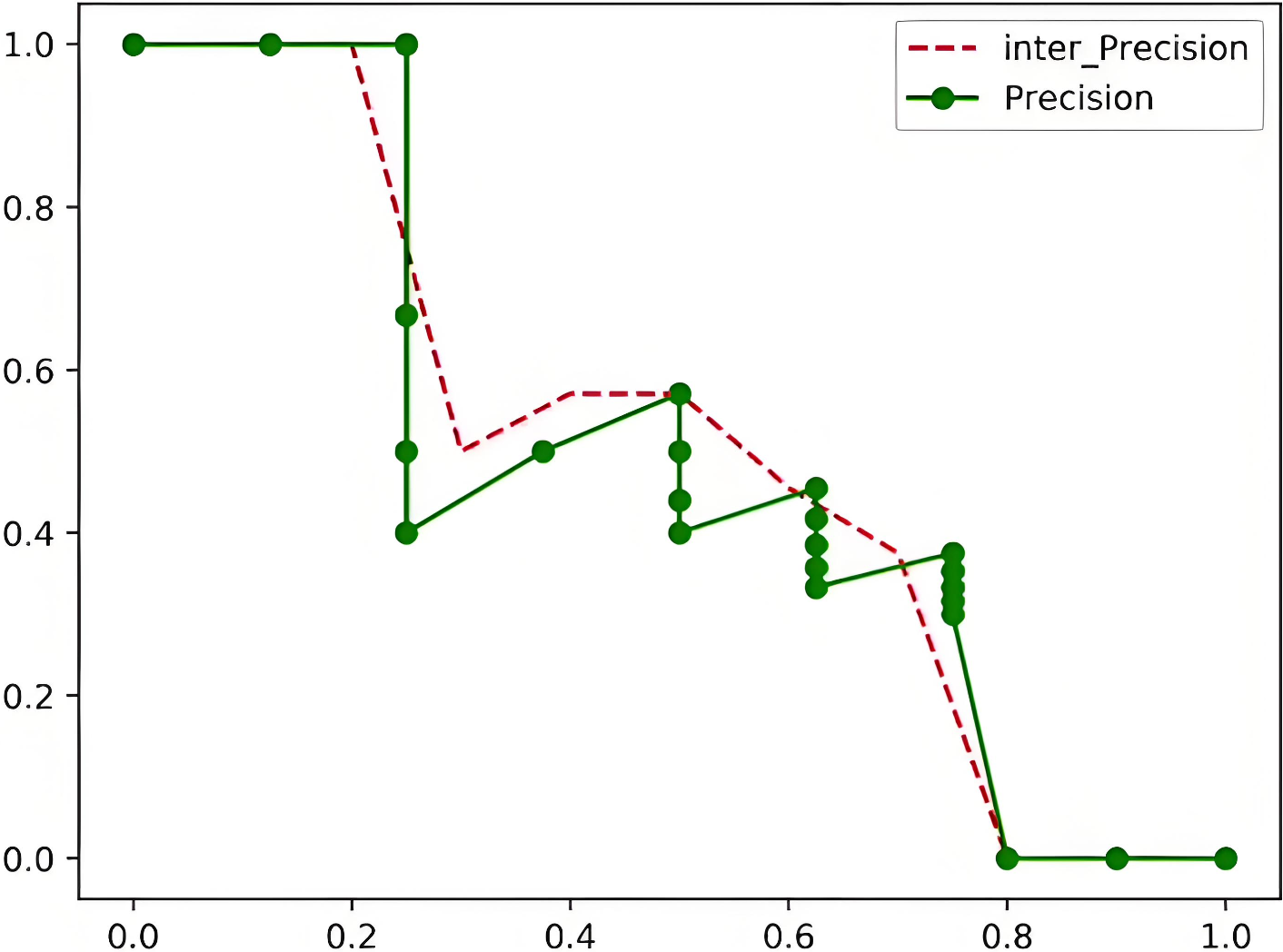
PASCAL VOC 2010以后采用面积法:
假设真实目标数为M,recall取样间隔为[0, 1/M, …, M/M],假设有 8 个目标,recall 取值 = [0, 0.125, 0.25, 0.375, 0.5, 0.625, 0.75, 0.875, 1.0]
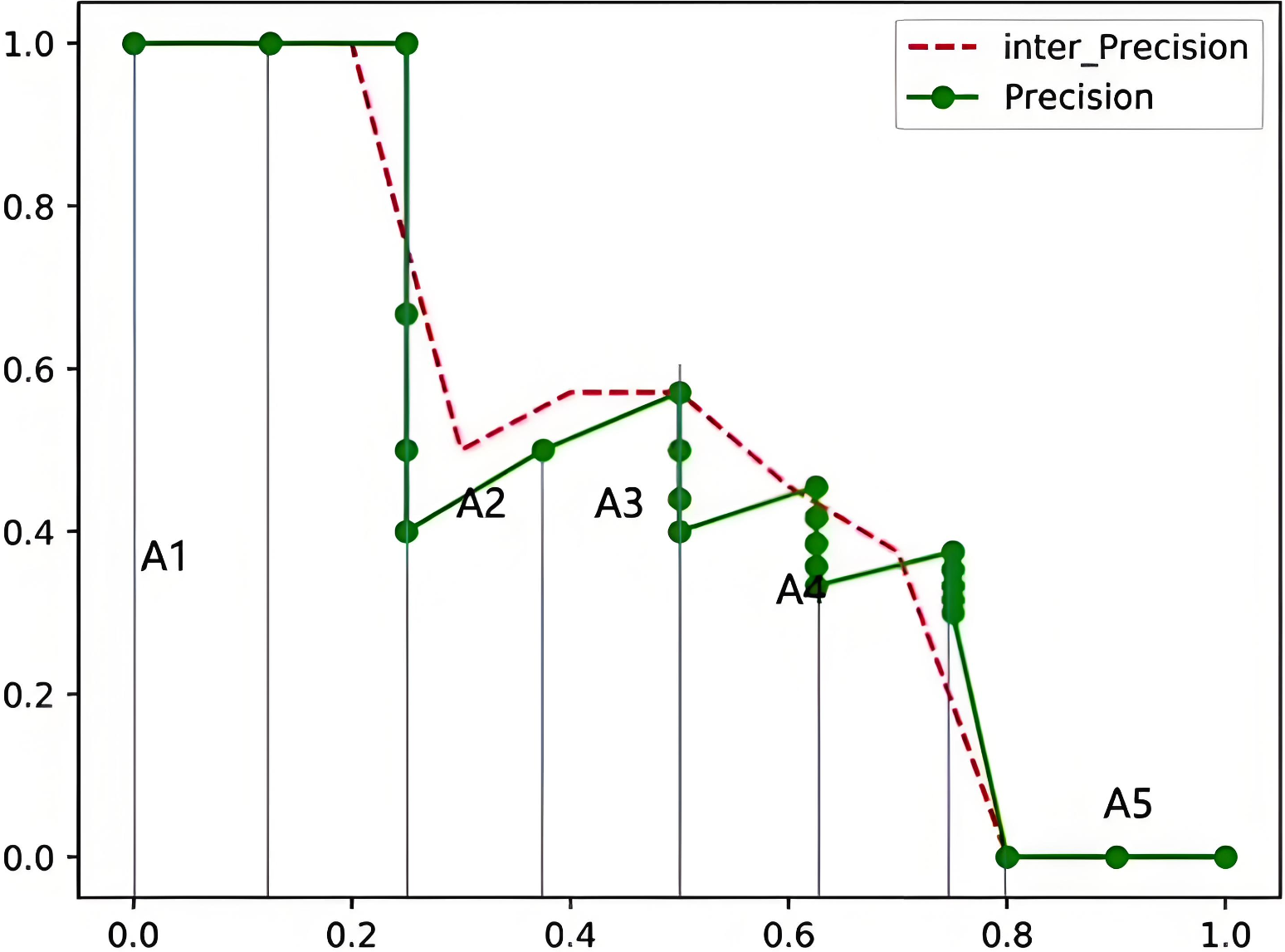
把各块面积加起来就是mAP值了:
注意:高还是阈值r和下一级阈值之间最高的精度,宽其实就是1/M
m A P = 0.12 5 ⋆ 1 + ( 0.25 − 0.125 ) ⋆ 1 + ( 0.375 − 0.25 ) ⋆ 0.5 + ( 0.5 − 0.375 ) ⋆ 0.571 + ( 0.625 − 0.5 ) ⋆ 0.455 + ( 0.75 − 0.675 ) ⋆ 0.375 + ( 0.875 − 0.75 ) ⋆ 0 = 48.7 % \begin{aligned} &\mathrm{mAP=0.125^{\star}1+(0.25-0.125)^{\star}1+(0.375-} \\ &0.25)^{\star}0.5+(0.5-0.375)^{\star}0.571+(0.625- \\ &0.5)^\star0.455+(0.75-0.675)^\star0.375+(0.875-0.75)^\star0 \\ &=48.7\% \end{aligned} mAP=0.125⋆1+(0.25−0.125)⋆1+(0.375−0.25)⋆0.5+(0.5−0.375)⋆0.571+(0.625−0.5)⋆0.455+(0.75−0.675)⋆0.375+(0.875−0.75)⋆0=48.7%
3. 后处理方法NMS
目标检测的后处理方法主要用于优化检测结果,比如检测出来的各个目标有多个目标框怎么搞?
非极大值抑制(Non-maximum suppression, NMS)是目标框后处理方法,是非常重要的一个环节。
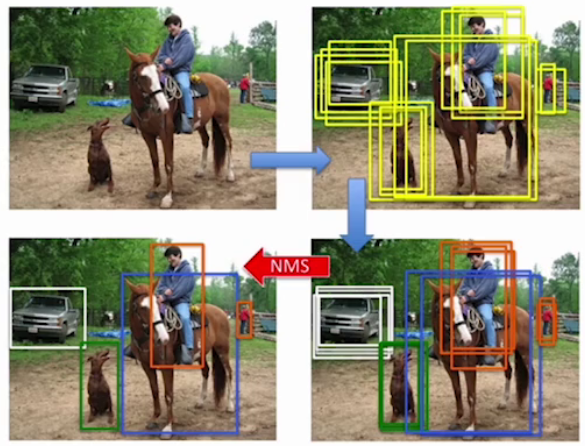
上图最终输出的目标框计算过程如下:按照类别各自分开处理
- 设定目标框置信度阈值,常用阈值0.5,小于该值的框会被过滤掉;
- 根据置信度降序排列候选框;
- 选取置信度最高的框A添到输出列表,并将其从候选框列表中删除;
- 候选框列表中所有框依次与A计算loU,删除大于IoU阈值的框;
- 重复上述过程,直到候选框列表为空;
- 输出列表就是最后留下的目标框;
4. 检测速度
4.1 前传耗时
单位ms,从输入图像到输出最终结果所消耗的时间,包括前处理耗时(如图像归一化)、网络前传耗时、后处理耗时(如非极大值抑制)。
4.2 FPS
FPS(Frames Per Second,每秒帧数),每秒钟能处理的图像的数量,实时监测要求 FPS 达到 30
4.3 FLOPS
FLOPS(Floating Point Operations Per Second,每秒浮点运算次数)是衡量计算设备性能的一个重要指标,特别是在高性能计算和深度学习领域。它表示设备在一秒内可以执行的浮点运算次数
- KFLOPS:每秒千次浮点运算( 1 0 3 10^3 103 FLOPS)
- MFLOPS:每秒百万次浮点运算( 1 0 6 10^6 106FLOPS)
- GFLOPS:每秒十亿次浮点运算( 1 0 9 10^9 109FLOPS)
- TFLOPS:每秒万亿次浮点运算( 1 0 12 10^{12} 1012FLOPS)
- PFLOPS:每秒千万亿次浮点运算( 1 0 15 10^{15} 1015FLOPS)
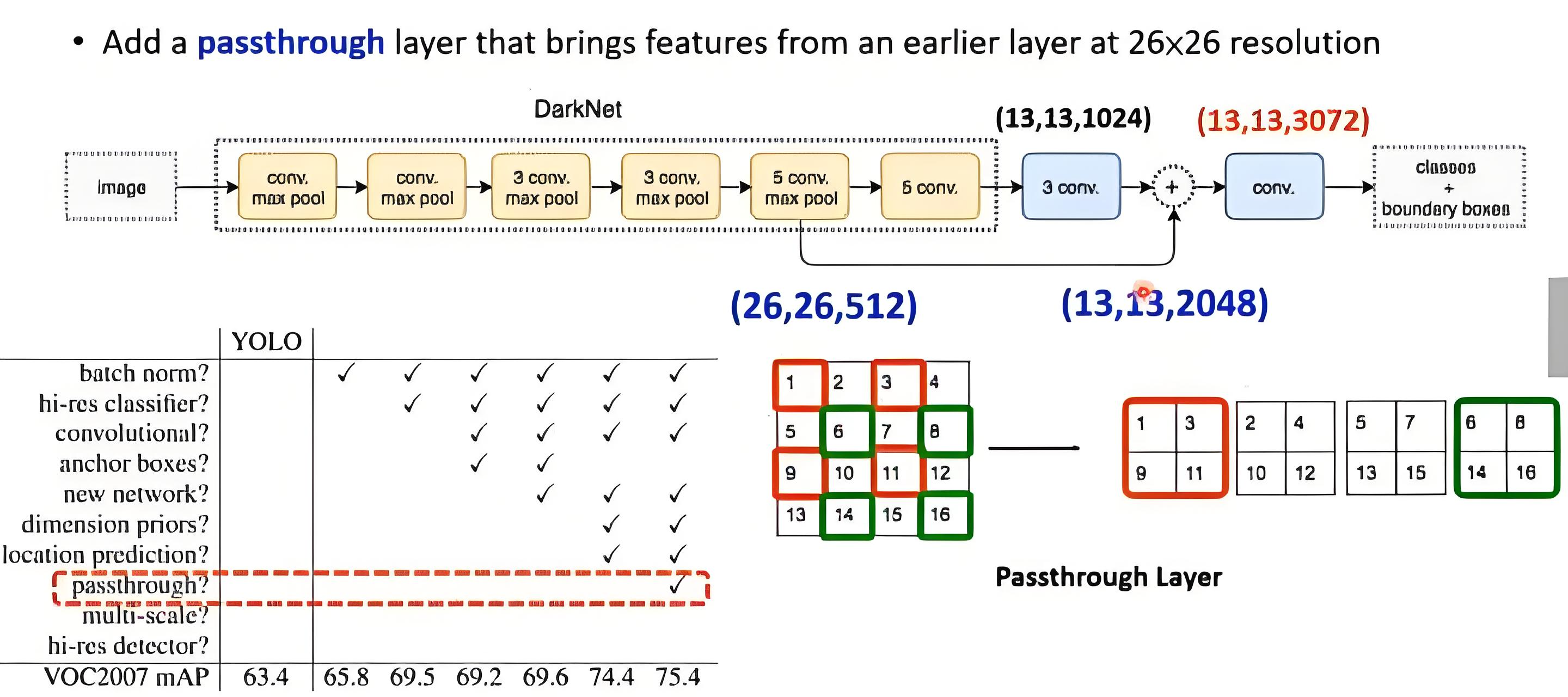
5. 整体网络结构
目标检测网络主要由Backbone、Neck、Head三块组成。
5.1 网络结构图

结构图内部展开:
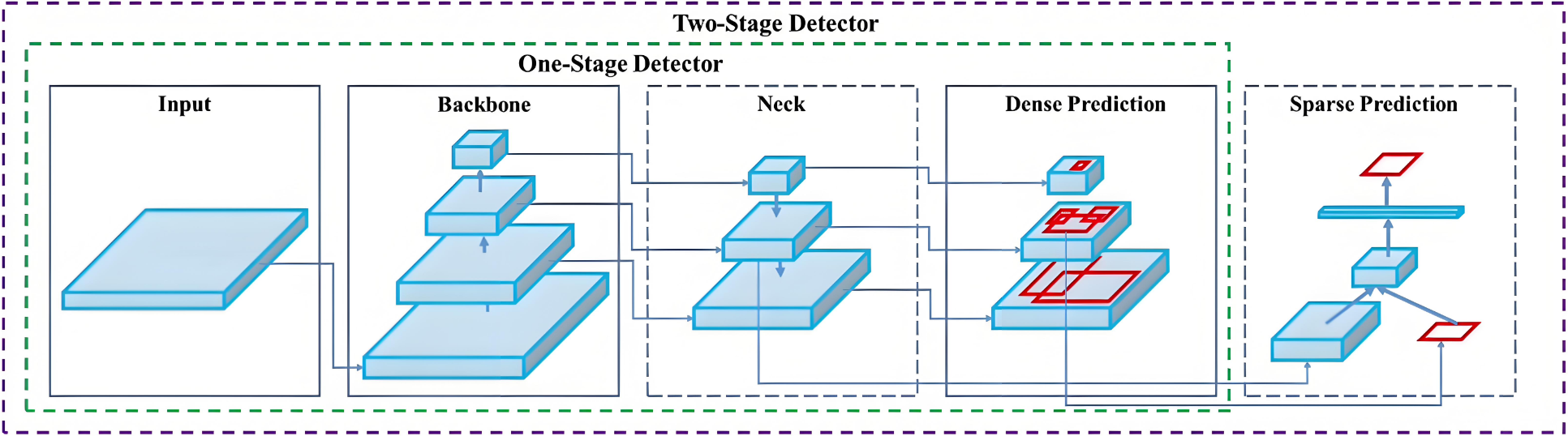
5.1.1 Backbone network
- 描述:
- Backbone network,即主干网络(骨干网络),目标检测网络最为核心的部分,主要是使用不同的卷积神经网络构建
- 任务:
- 特征提取:从输入图像中提取特征信息,这些特征通常包含丰富的信息,能够帮助后续模块进行目标检测
5.1.2 Neck network
- 描述:
- Neck network,即颈部网络,主要对主干网络输出的特征进行整合,常见的整合方式FPN(Feature Pyramid Network);
- 任务:
- 特征融合:将主干网络提取的多尺度特征进行融合,以增强特征的表达能力和鲁棒性
5.1.3 Detection head
- 描述:
- Detection head,即检测头,在特征之上进行预测,包括物体的类别和位置
- 任务:
- 目标检测:检测头的主要任务是基于融合后的特征图,通过回归任务预测边界框的坐标,通过分类任务预测目标的类别,生成最终的检测结果,包括边界框和类别
5.2 YOLO网络结构
| Model | Backbone | Neck | Head | Prediction Loss |
|---|---|---|---|---|
| v1 | GoogLeNet | None | FC → 7×7×(5+5+20) | MSE Loss |
| v2 | Darknet19 | Passthrough | 13×13×5×(5+20) | MSE Loss |
| v3 | Darknet53 | FPN | 13×13×3×(5+80), 26×26×3×(5+80), 52×52×3×(5+80) | MSE Loss |
| v4 | Darknet53_CSP | SPP、FPN、PAN | 13×13×3×(5+80), 26×26×3×(5+80), 52×52×3×(5+80) | CIoU Loss |
| v5 | Darknet53_CSP | SPP, cspFPN, cspPAN | 13×13×3×(5+80), 26×26×3×(5+80), 52×52×3×(5+80) | GIoU Loss |
三、 目标检测数据集
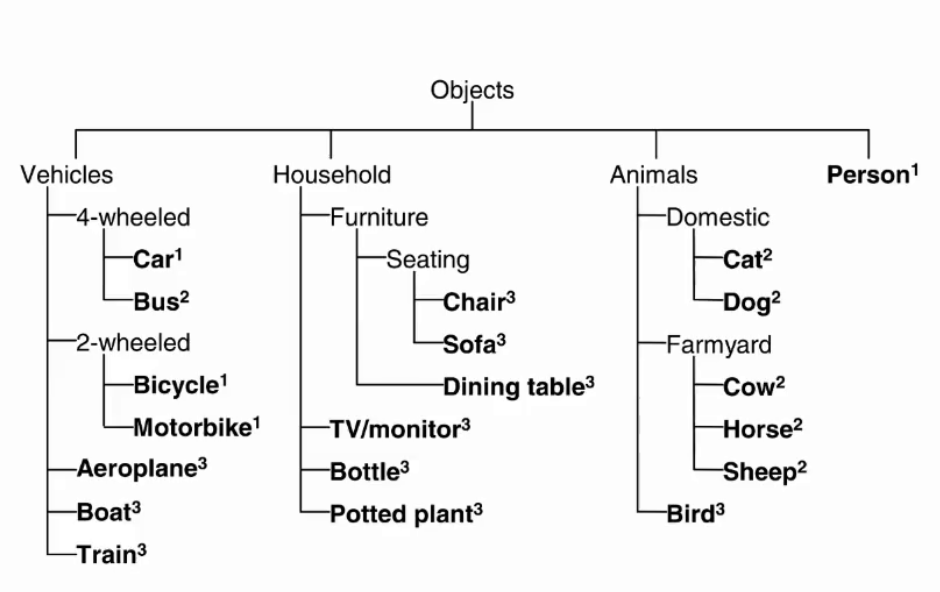
1. PASCAL VOC
共20类,主要用于目标检测。
VOC2007: 9963张图,24640个标注目标。
VOC2012: 23080图片,54900目标
https://www.kaggle.com/datasets/zaraks/pascal-voc-2007

分类结构如下:
目标检测如下:

图像分割:

行为识别:

人体布局:

2. MS COCO
MS COCO数据集,全称是Microsoft Common Objects in Context.
- 80分类、20万个图像、超过50万目标标注。
- 可用来图像识别、目标检测和分割等任务。
- 数据集分为训练集、验证集和测试集。
https://www.kaggle.com/datasets/awsaf49/coco-2017-dataset
四、YOLOV1全解
You Only Look Once,把检测问题转化成回归问题,一个CNN就搞定了!!!效率高,可对视频进行实时检测,应用领域非常广,到V3的时被美国军方用于军事行动,作者出于某种压力就退出了后续版本的更新,改由其他大佬继承衣钵!
作者:
Joseph Redmon ,Santosh Divvala , Ross Girshick 和 Ali Farhadi 。
Joseph Redmon 是YOLO系列的主要创始人,他在华盛顿大学进行研究工作时提出了 YOLO 的概念。
论文:
https://www.cv-foundation.org/openaccess/content_cvpr_2016/papers/Redmon_You_Only_Look_CVPR_2016_paper.pdf
1. 发展历史
当年Fast R-CNN效果很好,但是速度太慢,距离实时检测差得远,于是YOLO横空出世。
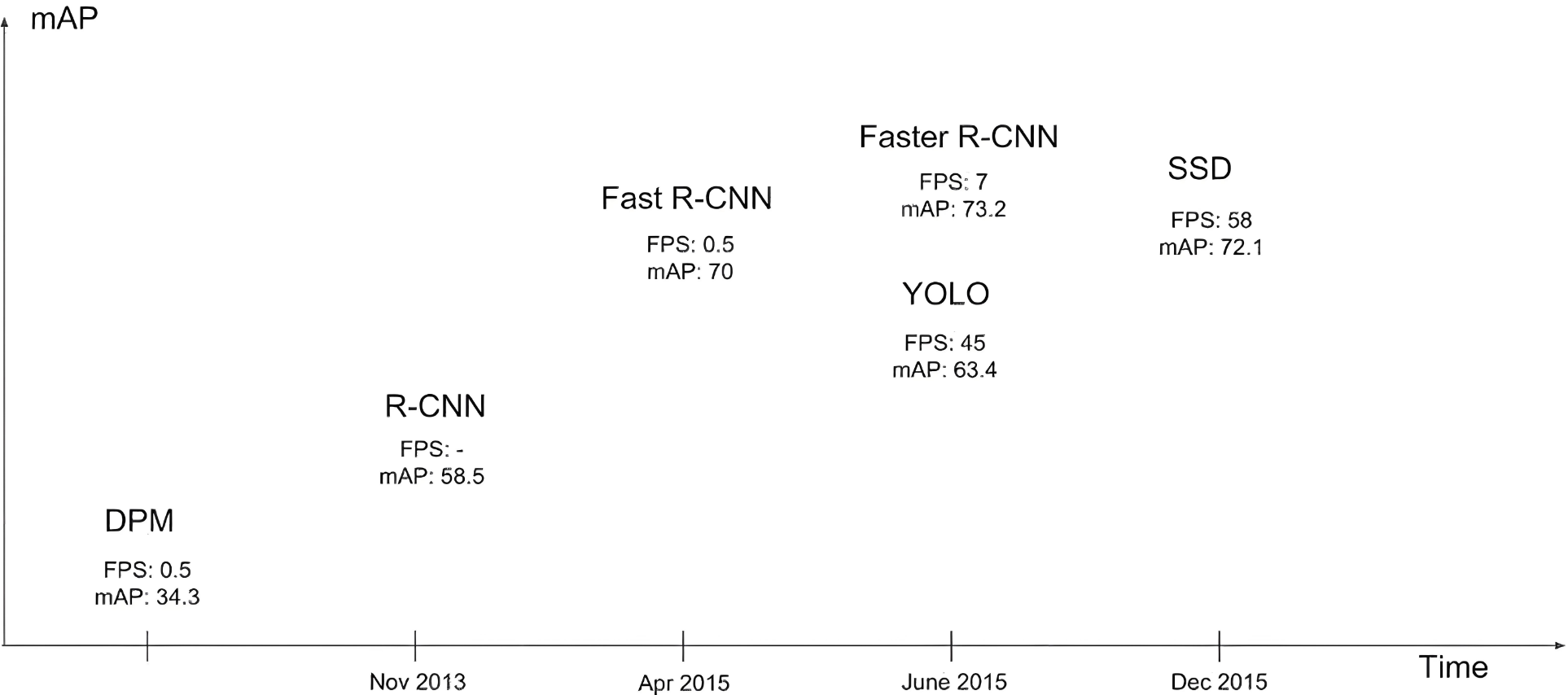
YOLO发展历史:
2. 网络特征
直接对输入图预测出边框坐标(x,y,w,h)和物体类别©、置信度(Confidence),是典型的One-stage目标检测方法,运行速度快,可以做到实时检测。

3. 网络结构
结构:24个卷积层,4个池化,2个全连接层

4. 核心思想
4.1 候选框策略
- 将输入图像分为 S × S S\times S S×S 个grid;
- 每个grid预测 B B B 个Bounding Box,每个bbox包含4个坐标和置信度;
- 每个grid预测 C C C 类类别概率
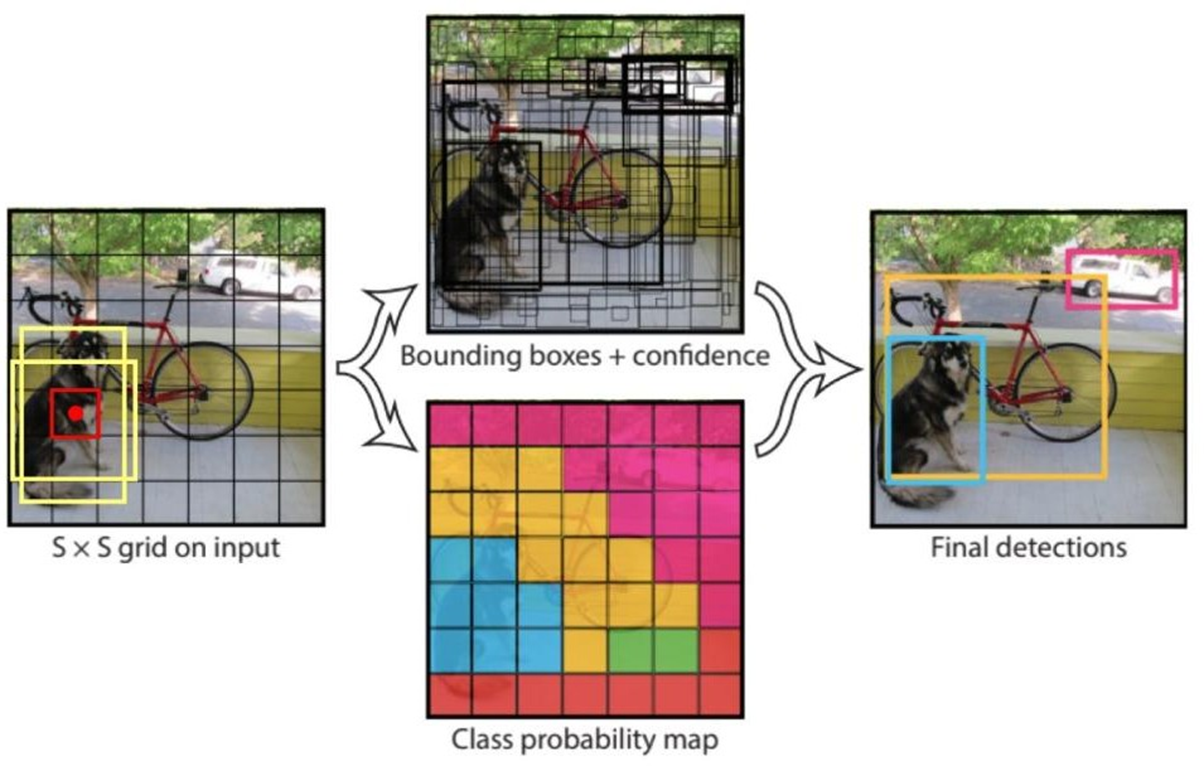
4.2 预测流程
- 将图片划分为 7 × 7 7 \times 7 7×7 个Grid
- 目标中心落在哪个grid cell里,就由其预测
- 每个grid预测 2 2 2 个bbox
- 每个grid预测 20 20 20 个类别概率(当时VOC数据集是20分类)

合体效果图如下:
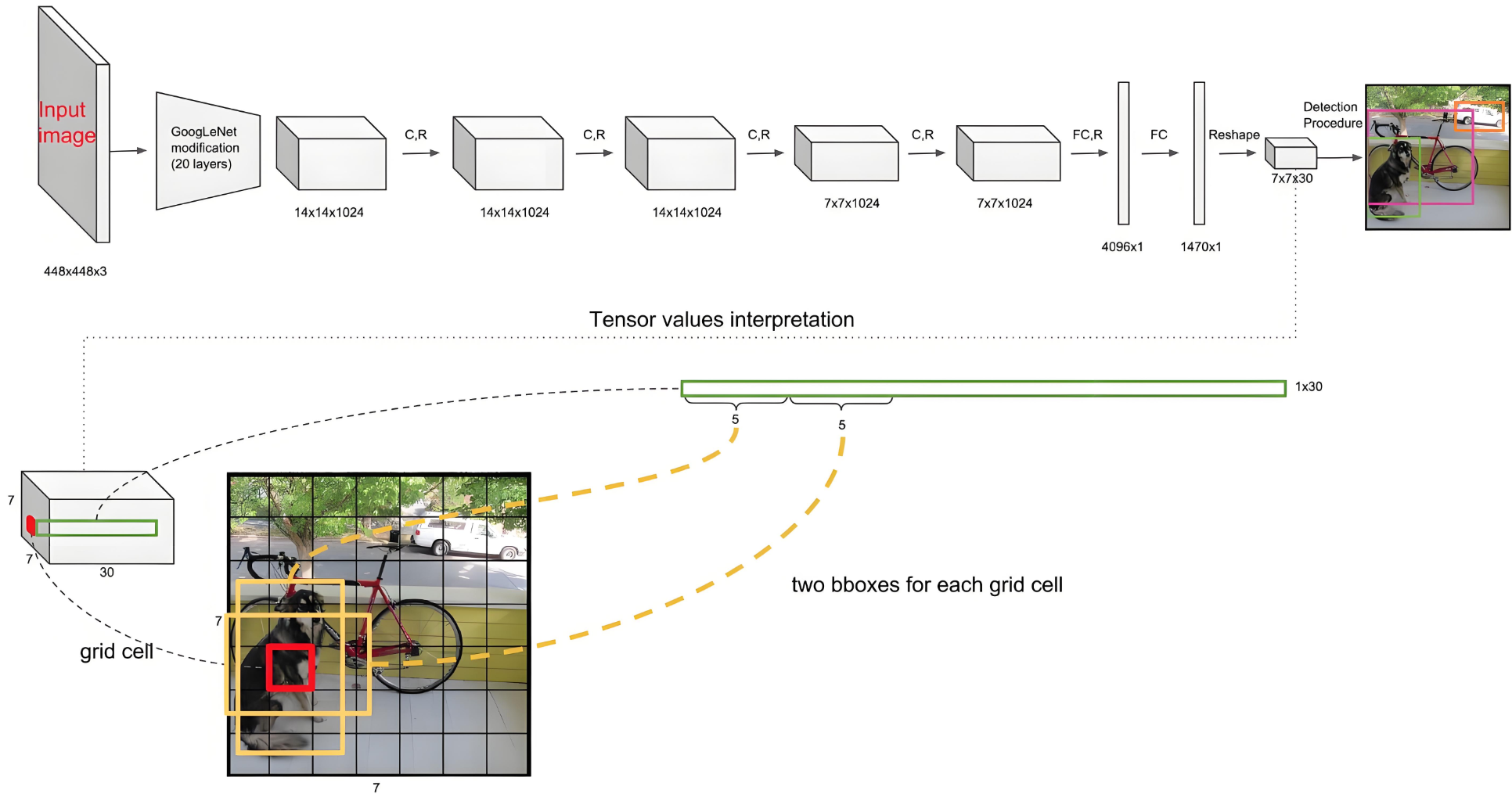
图中数字解释:
- 7 × 7:表示把图片分成7 × 7共49个Grid;
- 30则代表每个Grid有30个参数:20 +2 × (1+4)=30
20个分类、2个Bounding(候选框),每个候选框分别有1个Confidence和(x,y,w,h)表示的坐标位置 。
4.3 坐标详解
在 YOLOv1 中,模型预测的 x, y, w, h 是目标边界框(Bounding Box)的参数,具体含义如下:
1. x 和 y:
x和y表示预测边界框的中心点相对于当前网格单元的偏移量。- 具体来说:
- 每个图像被划分为一个
S x S的网格(例如 YOLOv1 默认是7 x 7)。 - 如果某个目标的中心落在某个网格单元中,则该网格单元负责预测该目标。
x和y是相对于该网格单元左上角的归一化偏移量,取值范围为[0, 1]。- 归一化的意思是:假设每个网格单元的实际宽度和高度为 1,则
x和y是中心点距离网格单元左上角的相对位置。
- 每个图像被划分为一个
2. w 和 h:
w和h表示预测边界框的宽度和高度,但它们是相对于整个图像的归一化值。- 具体来说:
w是预测框的宽度与整个图像宽度的比值。h是预测框的高度与整个图像高度的比值。- 因此,
w和h的取值范围通常也是[0, 1]。
总结:
x, y:表示边界框中心点相对于所在网格单元的归一化偏移量。w, h:表示边界框的宽度和高度相对于整个图像的归一化值
4.3.1 公式
计算中心点的实际坐标:

计算边界框的实际宽度和高度:
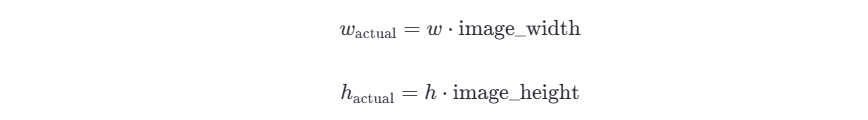
得到边界框的四个顶点坐标:

4.3.2 示例
假设我们有一张输入图像,大小为 448x448(YOLOv1 默认输入尺寸)。我们将图像划分为 7x7 的网格,每个网格单元的大小为:
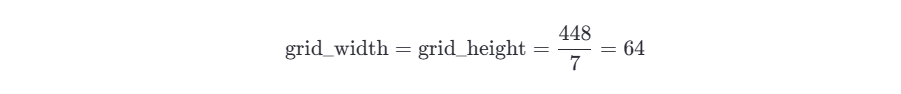
现在,假设某个目标的中心点落在网格单元 (3, 2) 中(即第 3 列、第 2 行的网格单元),并且模型预测的边界框参数为:
- x=0.3(中心点相对于网格单元左上角的归一化偏移量)
- y=0.7(中心点相对于网格单元左上角的归一化偏移量)
- w=0.5(边界框宽度相对于图像宽度的归一化值)
- h=0.4(边界框高度相对于图像高度的归一化值)
我们需要计算这个边界框的实际像素坐标。




5. 损失函数
5.1 整体概览
整个损失函数由5部分组成:
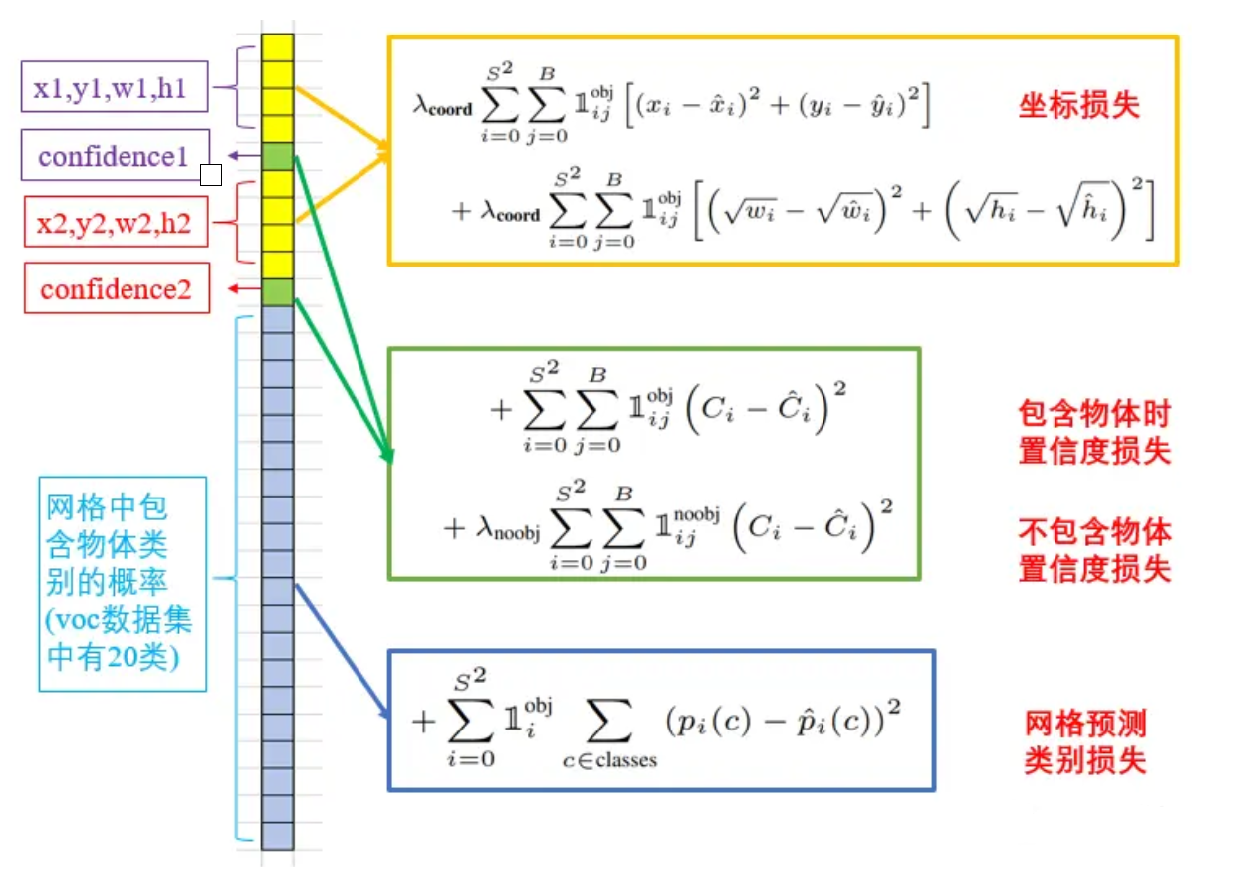
整体合并后公式如下:
λ c o o r d ∑ i = 0 S 2 ∑ j = 0 B 1 i j o b j [ ( x i − x ^ i ) 2 + ( y i − y ^ i ) 2 ] 【注解:边框中心点误差】 + λ c o o r d ∑ i = 0 S 2 ∑ j = 0 B 1 i j o b j [ ( w i − w ^ i ) 2 + ( h i − h ^ i ) 2 ] 【注解:边框宽高误差】 + ∑ i = 0 S 2 ∑ j = 0 B 1 i j o b j ( C i − C ^ i ) 2 【注解:有物体时置信度误差】 + λ noobj ∑ i = 0 S 2 ∑ j = 0 B 1 i j noobj ( C i − C ^ i ) 2 【注解:无物体时置信度误差】 + ∑ i = 0 S 2 1 i o b j ∑ c ∈ c l a s s e s ( p i ( c ) − p ^ i ( c ) ) 2 【注解:网格内有物体时的分类误差】 \begin{gathered} \lambda_{\mathbf{coord}}\sum_{i=0}^{S^{2}}\sum_{j=0}^{B}\mathbb{1}_{ij}^{\mathrm{obj}}\left[\left(x_{i}-\hat{x}_{i}\right)^{2}+\left(y_{i}-\hat{y}_{i}\right)^{2}\right]【注解:边框中心点误差】 \\ +\lambda_{\mathbf{coord}}\sum_{i=0}^{S^{2}}\sum_{j=0}^{B}\mathbb{1}_{ij}^{\mathrm{obj}}\left[\left(\sqrt{w_{i}}-\sqrt{\hat{w}_{i}}\right)^{2}+\left(\sqrt{h_{i}}-\sqrt{\hat{h}_{i}}\right)^{2}\right] 【注解:边框宽高误差】\\ +\sum_{i=0}^{S^2}\sum_{j=0}^B\mathbb{1}_{ij}^{\mathrm{obj}}\left(C_i-\hat{C}_i\right)^2 【注解:有物体时置信度误差】\\ +\lambda_\text{noobj}\sum_{i=0}^{S^2}\sum_{j=0}^B\mathbb{1}_{ij}^\text{noobj}\left(C_i-\hat{C}_i\right)^2 【注解:无物体时置信度误差】\\ +\sum_{i=0}^{S^2}\mathbb{1}_i^\mathrm{obj}\sum_{c\in\mathrm{classes}}\left(p_i(c)-\hat{p}_i(c)\right)^2 【注解:网格内有物体时的分类误差】 \\ \end{gathered} λcoordi=0∑S2j=0∑B1ijobj[(xi−x^i)2+(yi−y^i)2]【注解:边框中心点误差】+λcoordi=0∑S2j=0∑B1ijobj[(wi−w^i)2+(hi−h^i)2]【注解:边框宽高误差】+i=0∑S2j=0∑B1ijobj(Ci−C^i)2【注解:有物体时置信度误差】+λnoobji=0∑S2j=0∑B1ijnoobj(Ci−C^i)2【注解:无物体时置信度误差】+i=0∑S21iobjc∈classes∑(pi(c)−p^i(c))2【注解:网格内有物体时的分类误差】
公式解释:
- λ c o o r d \lambda_{coord} λcoord是一个权重系数,用于平衡坐标损失与其他损失项,论文中设置的值为 5
- S 2 S^2 S2表示有多少个 grid,
- B 表示框的个数,在 YOLOv1 中是 2 种,即 B 为 2
- obj 表示有物体时的情况
- noobj 表示没有物体时的情况
- i j i j ij 表示第 i 个 的第 j 个框
- 1 i j o b j 1_{ij}^{obj} 1ijobj是一个指示函数,当某个边界框负责某个对象时为 1,否则为 0
- x i 和 y i x_i和y_i xi和yi表示实际的坐标, x i ^ 和 y i ^ \hat{x_i}和\hat{y_i} xi^和yi^表示预测的坐标
- w i 和 h i w_i和h_i wi和hi表示实际的宽高, w i ^ 和 h i ^ \hat{w_i}和\hat{h_i} wi^和hi^表示预测的宽高
- C i C_i Ci表示实际的置信度分数( C i = P r ( o b j ) ∗ I o U C_i=Pr(obj)*IoU Ci=Pr(obj)∗IoU), C i ^ \hat{C_i} Ci^表示预测的置信度分数
- λ n o o b j \lambda_{noobj} λnoobj一个较小的权重系数,用来减少无对象区域的置信度损失的影响,论文中设置的值为 0.5
- 1 i j n o o b j 1_{ij}^{noobj} 1ijnoobj是一个指示函数,当某个边界框负责某个对象时为 0,否则为 1
- p i ( c ) p_i(c) pi(c)是第 i 个网格单元格中对象的真实类别分布, p i ^ ( c ) \hat{p_i}(c) pi^(c)是预测的类别概率分布
5.2 详细解读
公式部分非常规操作详解:
①、关于开根号
$$
\begin{gathered}
\lambda_{\mathbf{coord}}\sum_{i=0}{S{2}}\sum_{j=0}{B}\mathbb{1}_{ij}{\mathrm{obj}}\left[\left(\sqrt{w_{i}}-\sqrt{\hat{w}_{i}}\right){2}+\left(\sqrt{h_{i}}-\sqrt{\hat{h}_{i}}\right){2}\right] \
\
开根号是为了减少在反向传播更新参数时大框对小框的影响
\end{gathered}
$$
②、关于S的平方以及i和j
+ ∑ i = 0 S 2 ∑ j = 0 B I i j o b j ( C i − C ^ i ) 2 + λ noobj ∑ i = 0 S 2 ∑ j = 0 B 1 i j noobj ( C i − C ^ i ) 2 这里的 i 和 j 表示第 i 个 c e l l 的第 j 个框,训练时只有一个匹配 S 2 则表示共有 7 ∗ 7 共 49 个 G r i d C e l l \begin{gathered} +\sum_{i=0}^{S^2}\sum_{j=0}^B\mathbb{I}_{ij}^{\mathrm{obj}}\left(C_i-\hat{C}_i\right)^2 \\ +\lambda_\text{noobj}\sum_{i=0}^{S^2}\sum_{j=0}^B\mathbb{1}_{ij}^\text{noobj}\left(C_i-\hat{C}_i\right)^2 \\ \\ 这里的i和j表示第i个cell的第j个框,训练时只有一个匹配\\ {S^2}则表示共有7 * 7 共49个Grid Cell \end{gathered} +i=0∑S2j=0∑BIijobj(Ci−C^i)2+λnoobji=0∑S2j=0∑B1ijnoobj(Ci−C^i)2这里的i和j表示第i个cell的第j个框,训练时只有一个匹配S2则表示共有7∗7共49个GridCell
③、关于权重系数
$$
\begin{gathered}
\lambda_{\mathbf{coord}} \
\
\lambda_{\mathbf{coord}} 表示调高位置(坐标和宽高都加入了该系数)误差的权重,毕竟这玩意很重要,设置为5
\end{gathered}
$$
④、关于不含物体的置信度
λ noobj ∑ i = 0 S 2 ∑ j = 0 B 1 i j noobj ( C i − C ^ i ) 2 noobj表示没有物体时的情况 λ noobj = 0.5 用于调整没有目标时的权重系数 \begin{gathered} \lambda_\text{noobj}\sum_{i=0}^{S^2}\sum_{j=0}^B\mathbb{1}_{ij}^\text{noobj}\left(C_i-\hat{C}_i\right)^2 \\ \\ \text{noobj}表示没有物体时的情况 \\ \lambda_\text{noobj}=0.5用于调整没有目标时的权重系数 \end{gathered} λnoobji=0∑S2j=0∑B1ijnoobj(Ci−C^i)2noobj表示没有物体时的情况λnoobj=0.5用于调整没有目标时的权重系数


6. 算法性能对比
各网络性能对比:
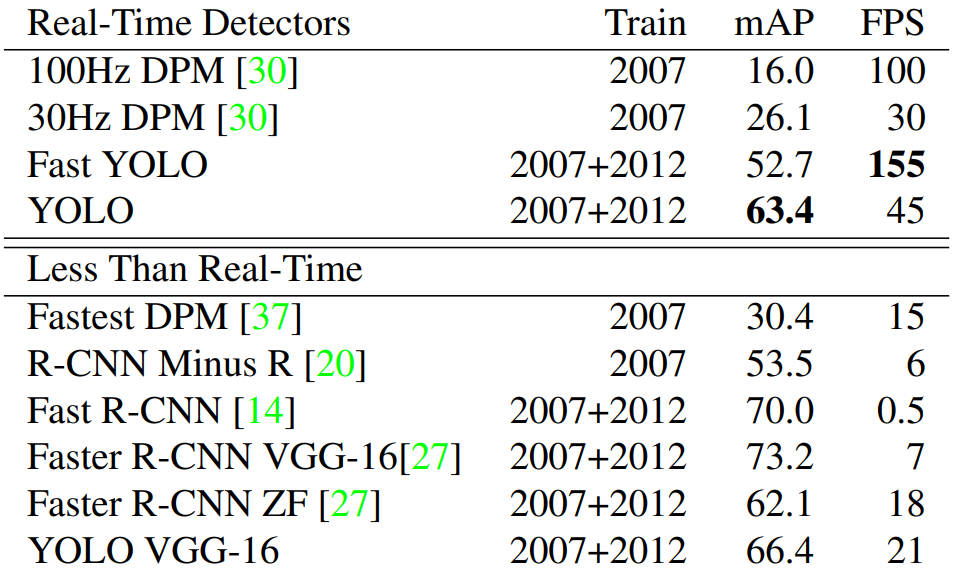
和Fast R-CNN多维度对比:

- Fast R-CNN:
- Correct:71.6%的检测结果是正确的
- Loc:8.6%的错误是由于定位不准确
- Sim:4.3%的错误是由于相似类别的误分类
- Other:1.9%的错误是由于其他原因。
- Background:13.6%的错误是将背景误判为对象
- YOLO:
- Correct:65.5%的检测结果是正确的
- Loc:19.0%的错误是由于定位不准确
- Sim:6.75%的错误是由于相似类别的误分类
- Other:4.0%的错误是由于其他原因
- Background:4.75%的错误是将背景误判为对象
7. YOLOV1特点总结
下面我们对YOLOV1做个总结
7.1 优点
- 更快更简单:可达到45fps,远高于Faster R-CNN系列,轻松满足视频目标检测。
- 避免产生背景错误:YOLO区域选择阶段是对整张图进行输入,上下文充分利用,不易出现错误背景信息。
7.2 缺点
定位精度低:网格划分有些粗糙和单一,多少难定
每个Cell只预测一个类别,如重叠或距离太近效果比较差
小物体检测效果一般,长宽比可选尺寸及比例单一
五、YOLOV2
V2对V1进行了诸多的提升和改进。
论文地址:
https://openaccess.thecvf.com/content_cvpr_2017/papers/Redmon_YOLO9000_Better_Faster_CVPR_2017_paper.pdf
1. 和V1对比
加入不同优化点后产生的效果对比

1.1 加入BN
(YOLOV1出来的时候还没有BN)
V2加入Batch Normalization
网络的每一层的输入都做了归一化,收敛相对更容易
经过Batch Normalization处理后的网络会提升2.4%的mAP
目前Batch Normalization已经成网络必备处理
1.2 更大分辨率
高分辨率分类器的思路如下:
- 预训练:首先,基础网络(如Darknet-19)在ImageNet数据集上以较低分辨率(如224x224)进行预训练,这一步是为了让模型学习到基本的图像特征表示。
- 调整输入分辨率:为了提高模型对不同尺寸物体的检测能力,会增加输入图像的分辨率,并在这个更高的分辨率下继续训练模型。例如,将输入分辨率从224x224增加到448x448,并在ImageNet上再次微调网络。这有助于模型适应更高分辨率下的特征提取。
- 目标检测微调:最后一步是在目标检测数据集(如Pascal VOC或COCO)上微调模型。这意味着使用特定于目标检测的数据和标签来优化模型参数,使其能够有效地执行目标检测任务。对于VOC数据集,这意味着模型被训练来识别并定位20种类别的对象。
通过这种方式,YOLOv2确保了模型不仅能够在低分辨率图像上表现良好,而且在高分辨率图像上也能够有效工作。这对于目标检测任务尤其重要,因为高分辨率图像可以提供更多的细节信息,有助于更精确地定位和识别小目标。这个高分辨率的分类网络使 mAP 增加了近 4%
V1训练时用224×224,测试时用448×448,影响最终效果
V2训练时额外进行10次448×448的训练微调
使用高分辨率分类器后,YOLOV2的mAP提升了约4%
1.3 网络结构
采用darknet-19作为主干网络:
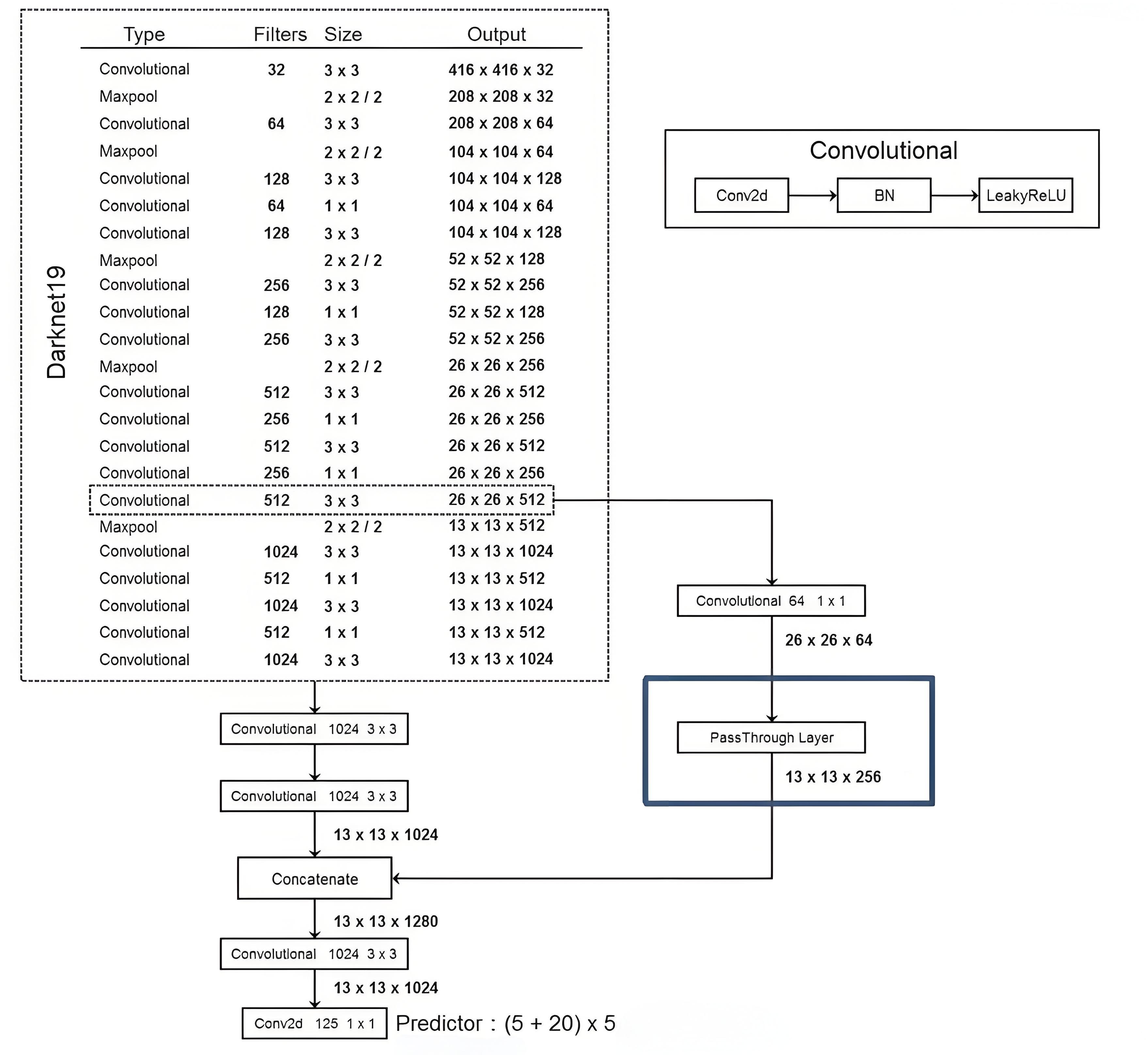
- Darknet,实际输入为416*416
- 没有FC层,5次降采样(416 ➗32=13)
- 1*1卷积节省了很多参数
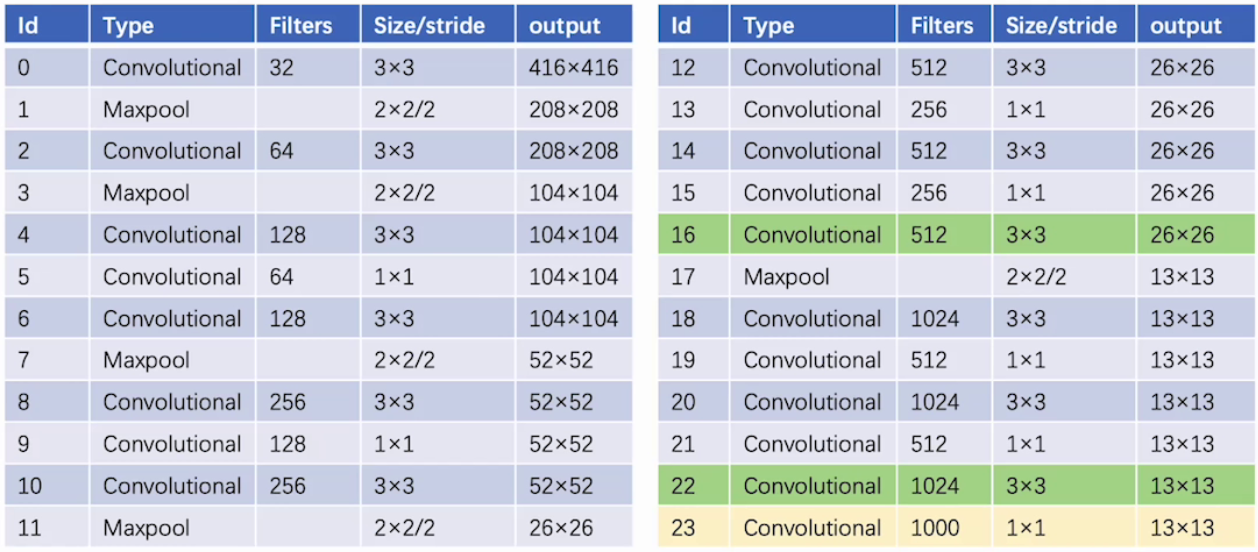
包含:19个conv层、5个max pooling层、无FC层,每个conv层后接入BN层
1.4 边框策略
在YOLOv2中,引入了Anchor Boxes(先验框)的思想来替代YOLOv1中直接预测边界框的方式。
1.4.1 Anchor Boxes
先验框是在训练神经网络之前定义的框,用于指导网络学习如何预测目标的位置和类别。YOLOv2中的先验框是基于训练数据集中的目标边界框而来的,它们代表了不同尺寸和比例的目标。
1.4.2 聚类先验框
YOLOv2使用K-means聚类算法来提取先验框。K-means是一种无监督学习算法,用于将数据点分为K个不同的簇,以便找到数据的聚类结构。在YOLOv2中,K表示使用的先验框数量,值为5。
先明确目的:K-means算法的目标是将训练数据中的边界框分配到最接近的聚类中心,以便找到最佳的先验框。
使用K-means聚类算法对训练数据中的边界框进行聚类,以确定先验框的大小和比例。聚类通常在边界框的宽度和高度上进行,以找到不同尺寸和比例的先验框。
计算步骤:

如下图,选取不同的 k 值(聚类的个数)运行 K-means算法,并画出平均 IOU 和 K 值的曲线图。当 k = 5 时,可以很好的权衡模型复杂性和高召回率。与手工挑选的相比,K-means 算法挑选的检测框形状多为瘦高型。
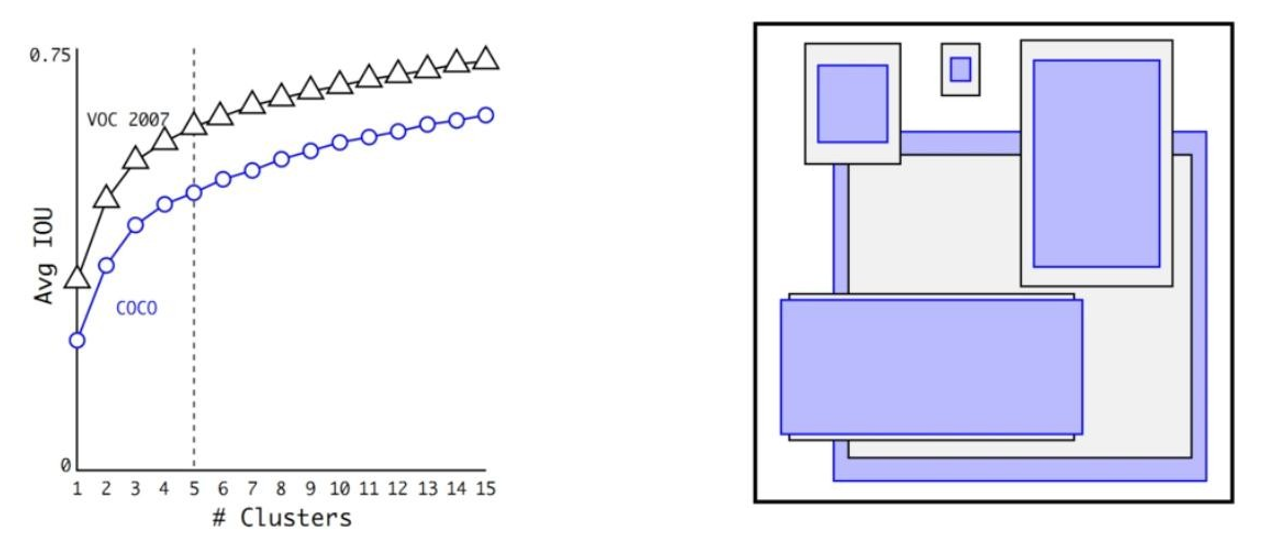
整体Precious降低0.3%,但是召回率却从81%提升到88%;

1.5 损失函数
1.5.1 输出特征维度
通道数:num_anchors x (4+1 + num_classes)
每个anchor都有4个边界框回归参数( t x , t y , t w , t h t_x, t_y, t_w, t_h tx,ty,tw,th) + 置信度 + 类别概率
VOC数据集20类、COCO数据集80类
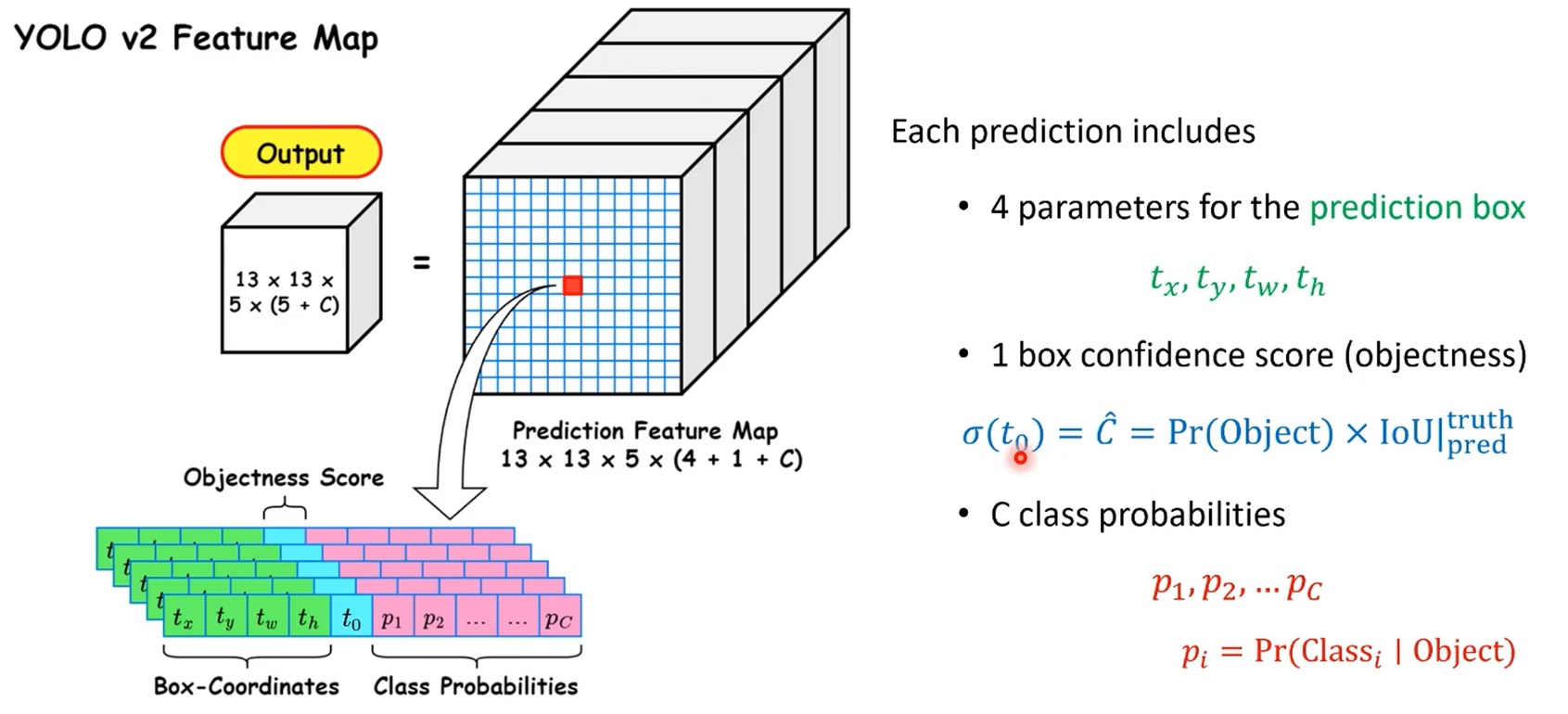
t x 、 t y t_x、t_y tx、ty是模型预测的中心坐标偏移量, t w 和 t h t_w和t_h tw和th是模型预测的宽度、高度的相对偏移量
yolov1和yolov2输出对比
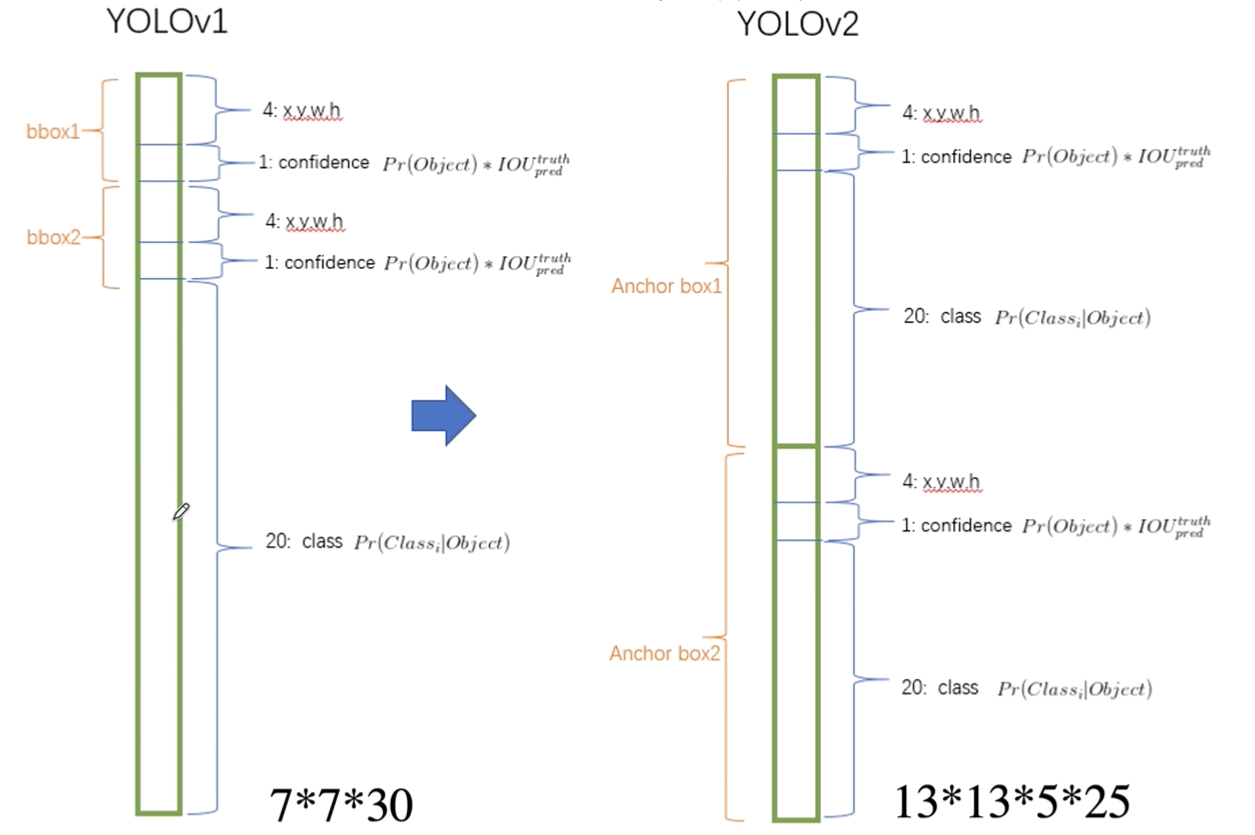
YOLOV1是通过模型直接预测位置和大小,这就带来了一系列问题:
- 违背了YOLO的以格子为中心点的预测思想;
- 导致收敛很慢,模型很不稳定,尤其刚开始进行训练的时候;
1.5.2 损失原理

yolov2损失,原论文没有给具体损失函数,根据代码和结合yolov1所得:
注意:下图紫色为锚框的信息,红色是预测框信息(这里是根据预测值由左边的公式所得),绿色依旧为真实值

1.6 边界框回归
YOLOv2 不是直接预测边界框的位置,而是预测相对于 Anchor Boxes 的偏移量。这意味着每个 Anchor Box 会预测一个小的偏移量,用以调整 Anchor Box 的位置和大小,使之更接近真实的目标框。
1.6.1 边界框回归
参考图如下:
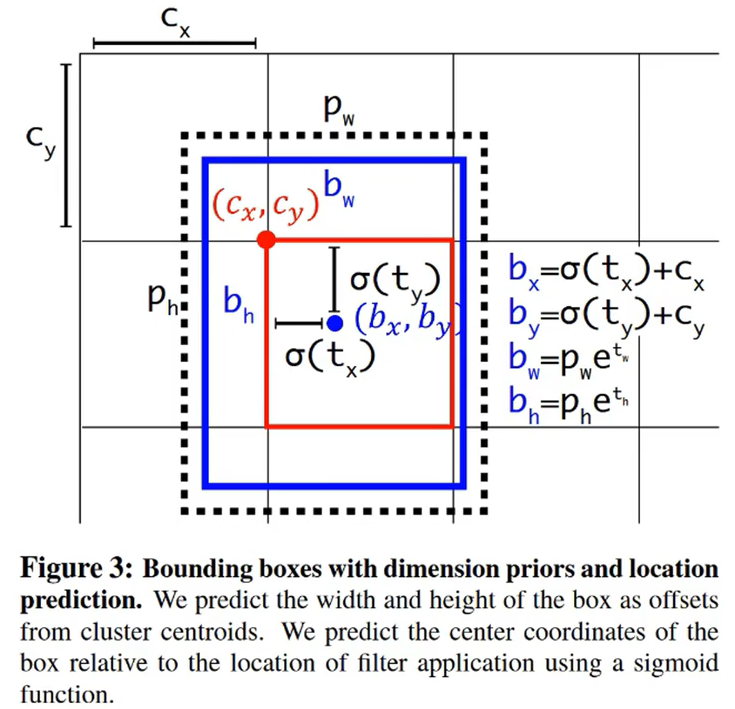
计算公式如下:
- t x 、 t y t_x、t_y tx、ty是网络预测的中心坐标偏移量
- c x 、 c y c_x、c_y cx、cy是单元格与图像左上角的偏移量
- σ \sigma σ是 Sigmoid 函数,用于将 t x 和 t y t_x和t_y tx和ty映射到 [0,1] 区间内
- b x 、 b y b_x、b_y bx、by是最终预测的边界框中心坐标
- b w 和 b h b_w和b_h bw和bh是最终预测编辑框的大小
- p w 和 p h p_w和p_h pw和ph是 Anchor Box 的宽度和高度
- t w 和 t h t_w和t_h tw和th是宽度、高度的相对偏移量
公式如下:
b x = σ ( t x ) + c x b y = σ ( t y ) + c y b w = p w e t w b h = p h e t h \begin{aligned} &b_{x} =\sigma\left(t_x\right)+c_x \\ &b_{y} =\sigma\left(t_y\right)+c_y \\ &b_{w} =p_we^{t_w} \\ &b_{h} =p_he^{t_h} \end{aligned} bx=σ(tx)+cxby=σ(ty)+cybw=pwetwbh=pheth
这样我们就可以保证,中心坐标点不会飘出整个框。
例子参考如下:
例如预测值: ( σ ( t x ) , σ ( t y ) , t w , t h ) = ( 0.2 , 0.1 , 0.2 , 0.32 ) , a n c h o r 框为: p w = 3.19275 , p h = 4.00944 在特征图位置: b x = 0.2 + 1 = 1.2 b y = 0.1 + 1 = 1.1 b w = 3.19275 ∗ e 0.2 = 3.89963 b h = 4.00944 ∗ e 0.32 = 5.52151 \begin {aligned} \text{例如预测值:} \\ &(\sigma\left(t_x\right), \sigma\left(t_y\right), t_w, t_h) =(0.2,0.1,0.2,0.32),\\ &{anchor框为:}p_{w}=3.19275,p_{h}=4.00944 \\ \\ \text{在特征图位置:} \\ &b_{x}=0.2+1=1.2\\ &b_{y}=0.1+1=1.1\\ &b_{w}=3.19275*e^{0.2}=3.89963\\ &b_{h}=4.00944*e^{0.32}=5.52151 \\ \end{aligned} 例如预测值:在特征图位置:(σ(tx),σ(ty),tw,th)=(0.2,0.1,0.2,0.32),anchor框为:pw=3.19275,ph=4.00944bx=0.2+1=1.2by=0.1+1=1.1bw=3.19275∗e0.2=3.89963bh=4.00944∗e0.32=5.52151
1.6.2 坐标映射
在画候选框的时候需要映射到原始图片:13 × 32 = 416
在原图中的位置: b x = 1.2 ∗ 32 = 38.4 b y = 1.1 ∗ 32 = 35.2 b w = 3.89963 ∗ 32 = 124.78 b h = 5.52151 ∗ 32 = 176.68 \begin {aligned} \text{在原图中的位置:} \\ &b_{x} =1.2*32=38.4 \\ & b_{y} =1.1*32=35.2 \\ &b_{w} =3.89963*32=124.78 \\ &b_{h} =5.52151*32=176.68 \end{aligned} 在原图中的位置:bx=1.2∗32=38.4by=1.1∗32=35.2bw=3.89963∗32=124.78bh=5.52151∗32=176.68
1.7 特征融合
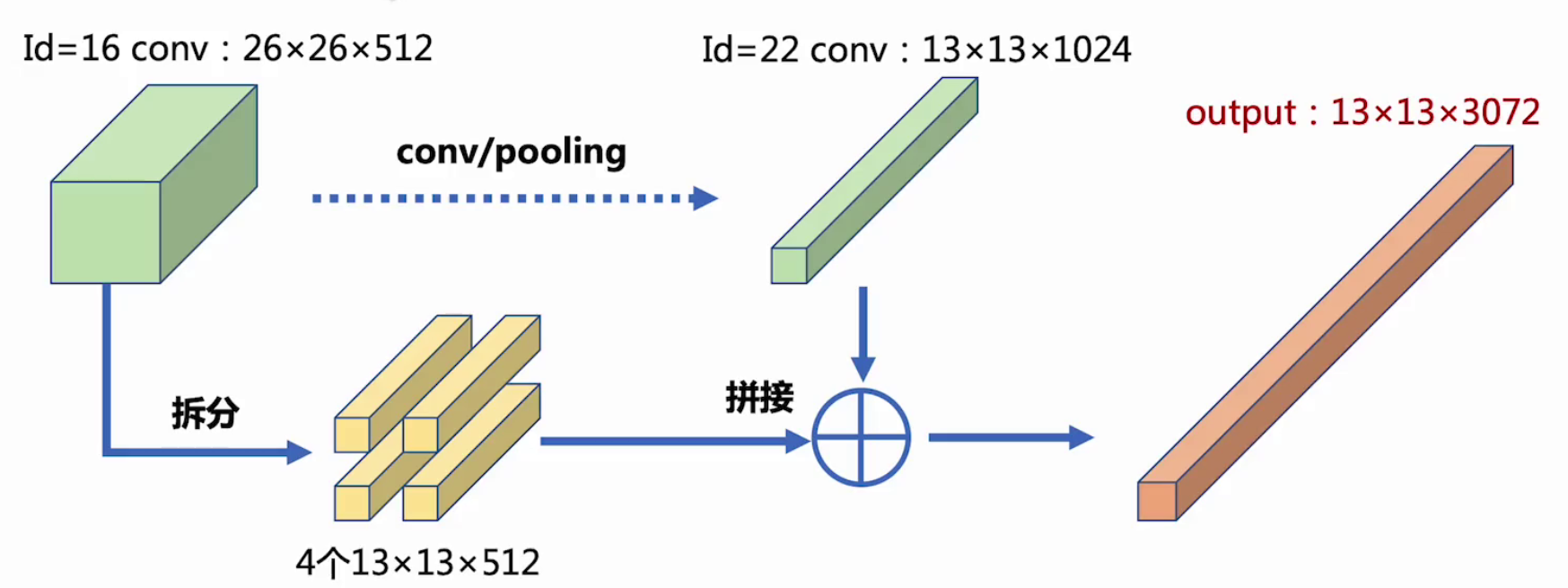
最后一层时感受野太大了,小目标可能丢失了,需融合之前的特征。
id=16的conv层与id=22的conv层进行passthrough,用于提升小目标检测精度。
1.7 训练策略优化
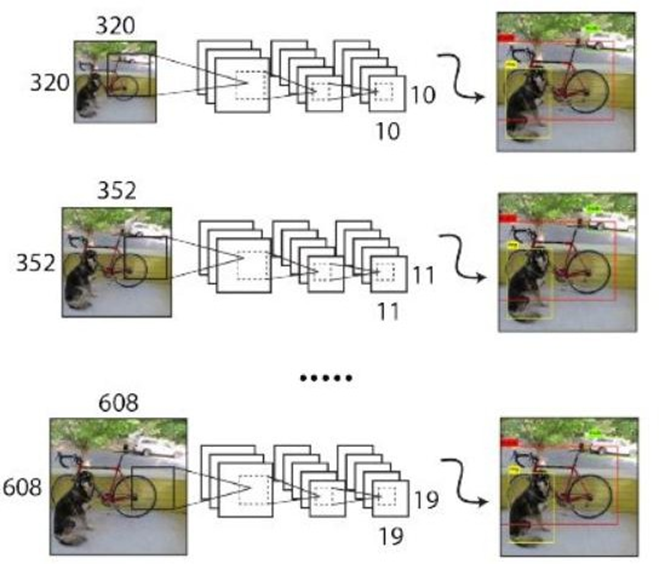
采用多尺度训练方法:
先用224*224对主干网络进行预训练,再用448 x 448对主干网络进行微调(10轮)
设计了416 x 416和544 x 544两种输入尺寸的网络
由于没有FC层,可输入任意尺寸图像,整个网络下采样倍数是32,共有320、352、384、416、448、…、608等10种输入图像尺寸,每10个batch就随机更换一种尺寸
2. 性能对比
这里简单的看下就行了,实际主要还是和V1对比

六、YOLOV3
原作者做完V3就退出了。
论文地址:
https://arxiv.org/pdf/1804.02767.pdf
1. 一图表意图
略微有点过分,但是没有针对任何人的意思~~~
2. 优化的点
- 改进网络结构,使其更适合小目标检测
- 特征做的更细致,融入多特征图信息来预测不同规格物体
- 更丰富的先验框,3种scale,每种3个规格,共9种
- softmax改进,预测多标签任务
3. 网络结构
3.1 主干网络
YOLOV3主干结构采用darknet-53。
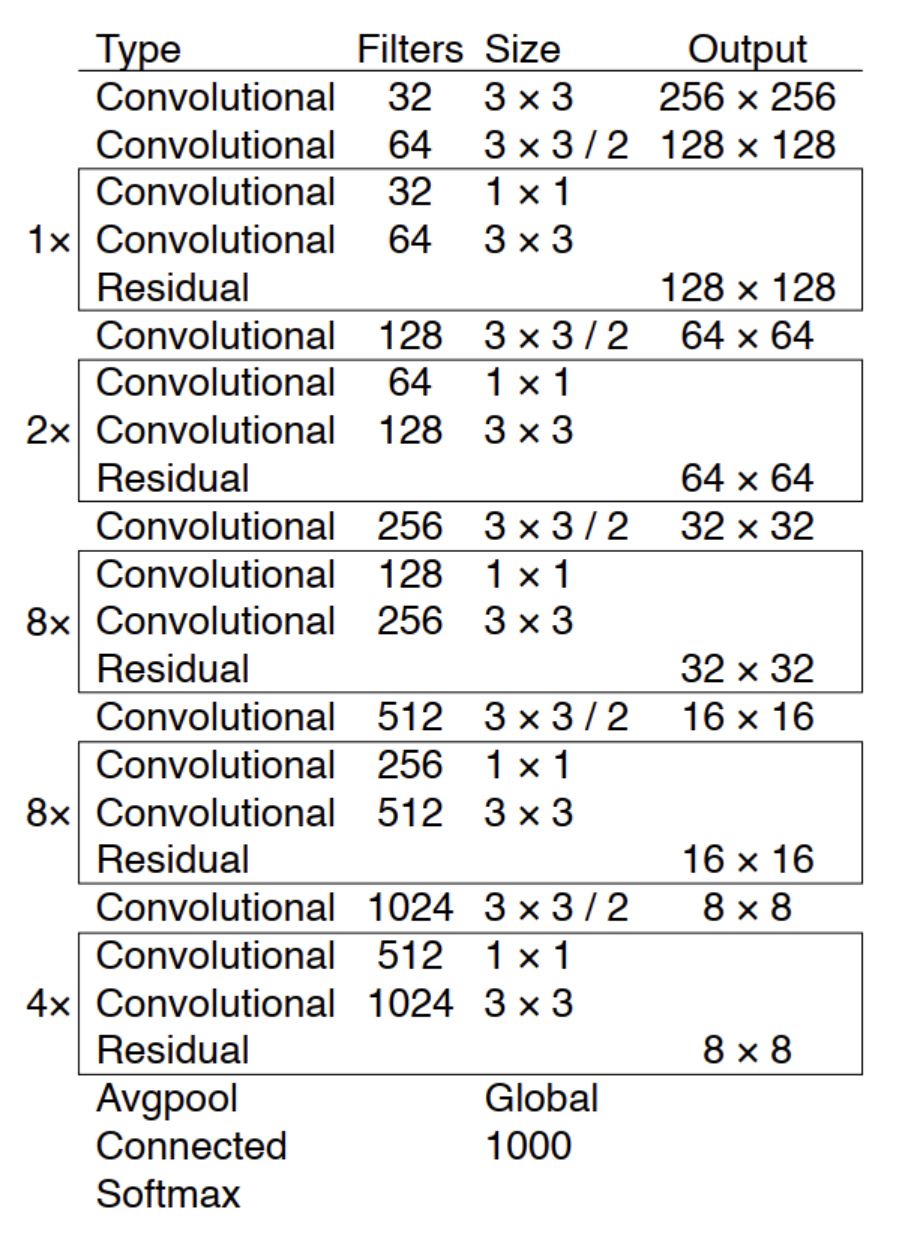
没有池化和FC,尺寸变换是通过Stride实现的,简单粗暴效果好!
3.2 整体结构
整体网络基本融合了当下几种优秀套路~
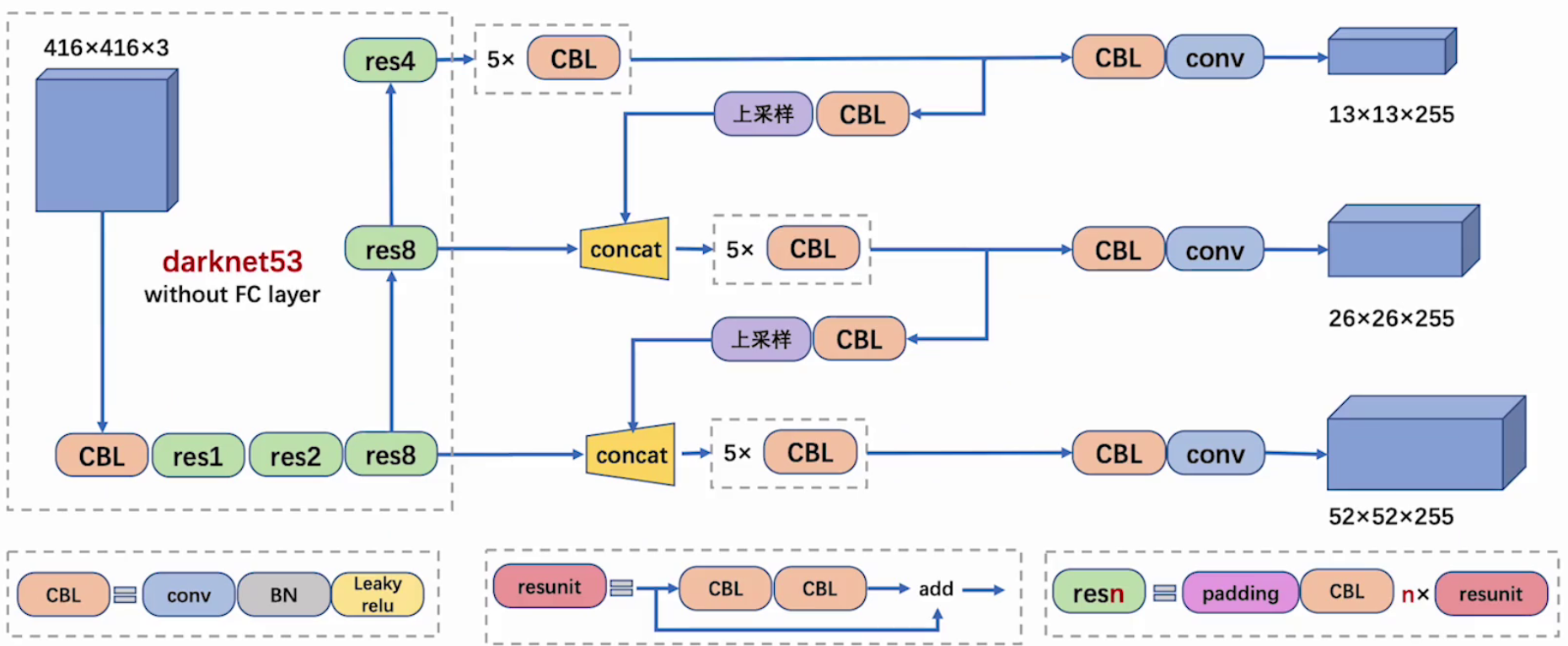
有4个坐标变换系数( t x , t y , t w , t h t_x, t_y, t_w, t_h tx,ty,tw,th)+置信度+类别概率,使用1 x 1卷积预测,通道数=3 x (4+1+80) = 255
3.3 特征输出
特征图尺寸越小,感受野越大,他们分别适配不同大小的目标;
52 × 52感受野更小,更适合检测小目标;
13 × 13感受野更大,更适合检测大目标;

参考下面的图可知: 255 = 3 × (1 + 4 + 80)
3.4 特征融合
3.4.1 FPN
Feature Pyramid Networks for Object Detection
用于目标检测的特征金字塔网络
先观察下面四张图:
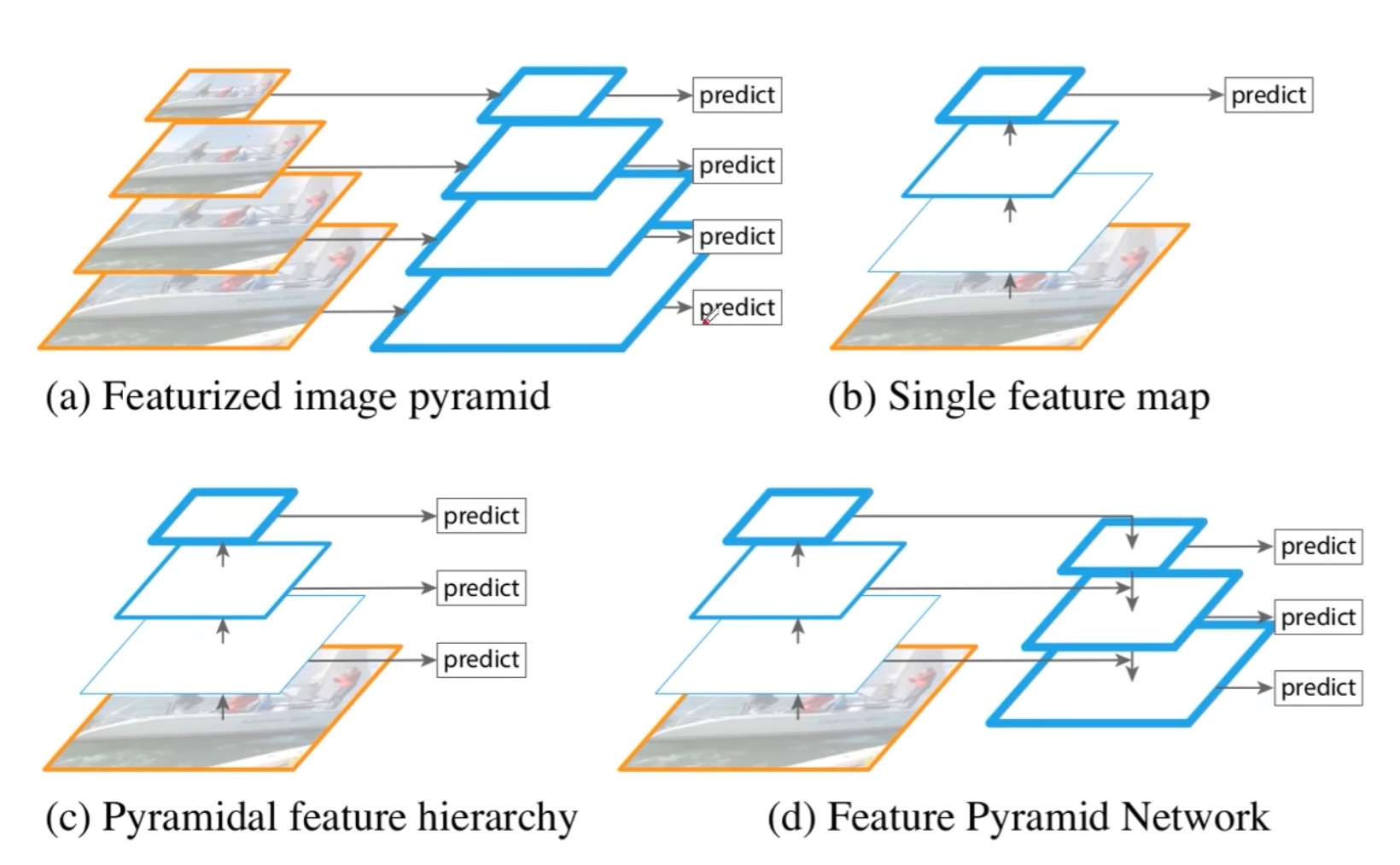
图a:特征化图像金字塔
①、当我们要检测不同的尺度目标时,需要把图像送入不同的尺度
②、需要根据不同的尺度图片一次进行预测
③、需要多少个不同尺度就需要预测多少次,效率较低
图b:单特征映射
①、得到一个特征图并进行预测
②、特征丢失,对于小目标效果不好;
图c:金字塔特征层次结构
①、把图像传给backbone,在传播的过程中分别进行预测
②、相互之间独立,特征没有得到充分利用
图d:特征金字塔网络
①、不是简单的不同特征图上进行预测
②、会对不同的特征图进行融合后进行预测
3.4.2 FPN融合细节
融合细节如下图:艺高者胆大
1 × 1卷积完成channel的一致性
2 × up完成尺寸的一致性
这样就可以进行特征相加了
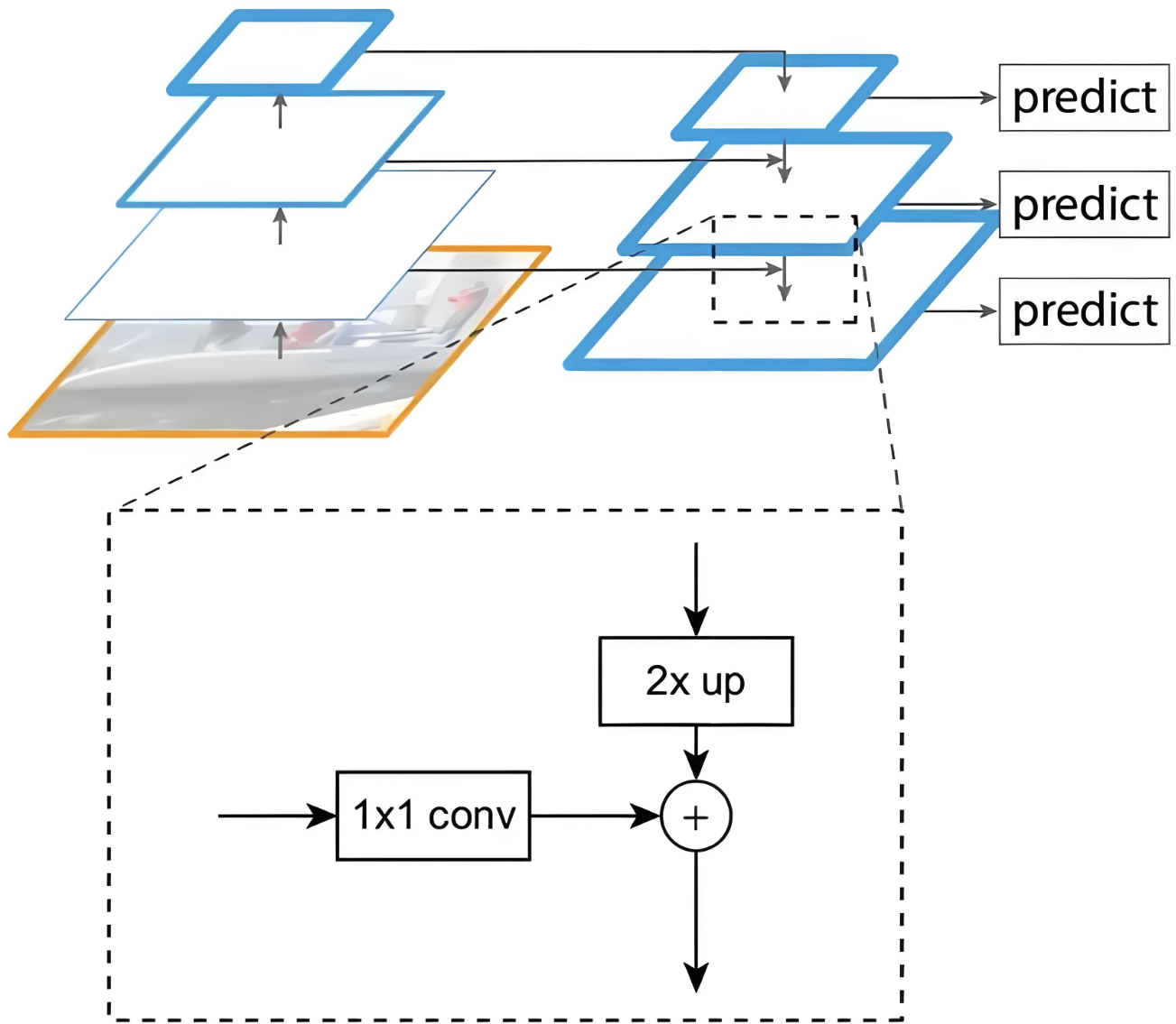
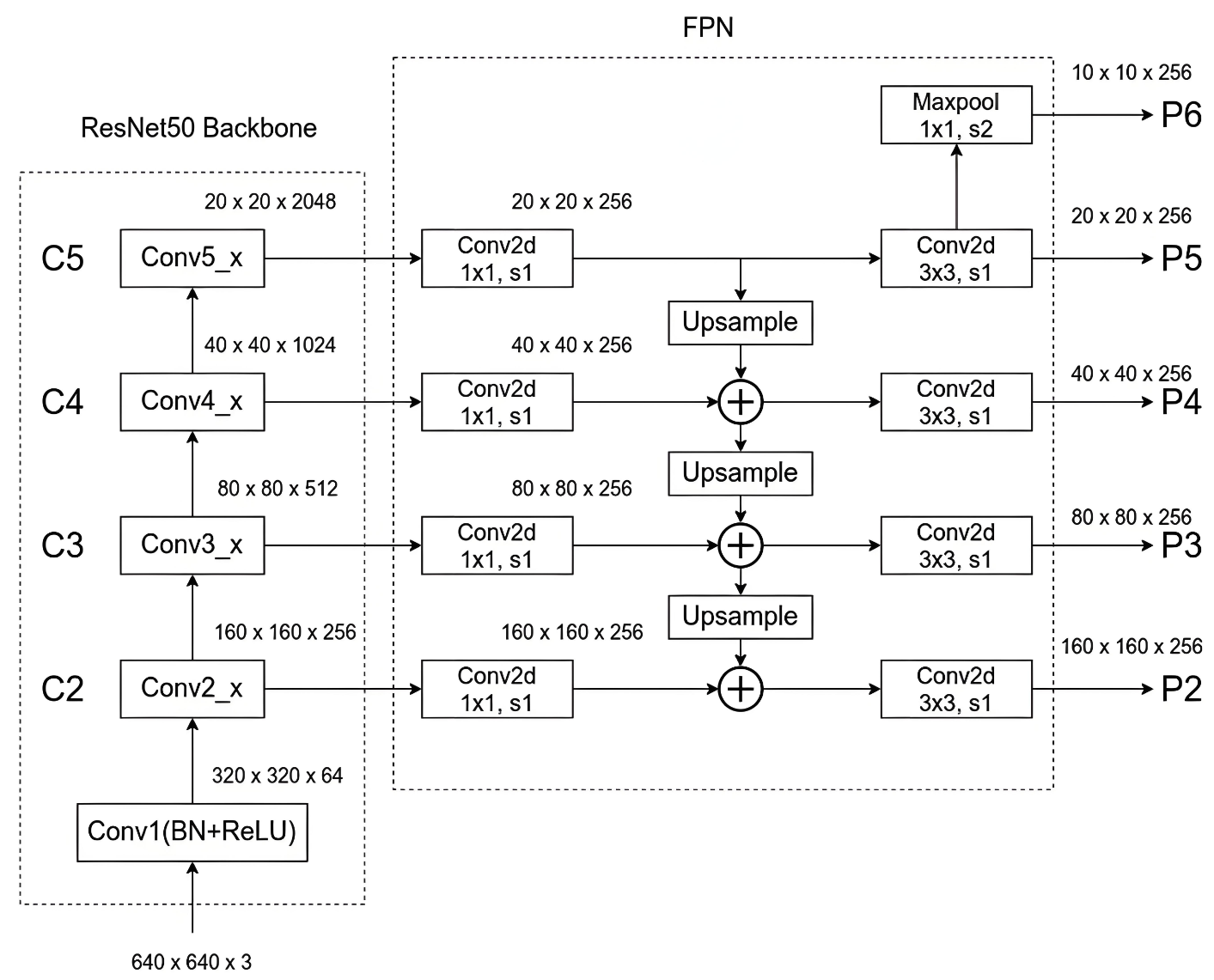
3.4.3 整体结构
通过整体结构去更好的理解FPN的特征融合过程:
3.5 先验框优化
共设计了9种先验框:
- 13×13特征图上:(116 × 90),(156 × 198),(373 × 326)
- 26×26特征图上:(30 × 61),(62 × 45),(59 × 119)
- 52×52特征图上:(10 × 13),(16 × 30),(33 × 23)

预选框个数:
**YOLOV2: **13 x 13 x 5=845个预测框
YOLOV3:(13 x 13+26 x 26+52 x 52) x 3=10647个利用阈值过滤掉置信度低于阈值的预选框。
每个cell同样最终只预测一个结果,取置信度最大的。
4. 损失函数
4.1 softmax替代
YOLOV3在预测类别时采用了logistic regression,每个类别单独使用二分类的logistic回归,而不是softmax;
我们这里假设为二分类:
i f y = 1 : p ( y ∣ x ) = y ^ if y = 0 : p ( y ∣ x ) = 1 − y ^ 联合起来: p ( y ∣ x ) = y ^ y ( 1 − y ^ ) ( 1 − y ) 展开并取对数如下:预测为正样本的损失加上预测为负样本的损失 log p ( y ∣ x ) = ylog ( y ^ ) + ( 1 − y ) log ( 1 − y ^ ) = − L ( y ^ , y ) \begin{aligned} &\mathrm{if}\quad y=1:\quad p(y\mid x)=\hat{y} \\ &\operatorname{if} \quad y=0:\quad p(y\mid x)=1-\hat{y} \\ 联合起来: \\ &p(y\mid x)=\hat{y}^y(1-\hat{y})^{(1-y)} \\ 展开并取对数如下:预测为正样本的损失加上预测为负样本的损失 \\ &\log p(y\mid x)=\text{ylog}(\hat{y})+(1-y)\log(1-\hat{y})=-L(\hat{y},y) \end{aligned} 联合起来:展开并取对数如下:预测为正样本的损失加上预测为负样本的损失ify=1:p(y∣x)=y^ify=0:p(y∣x)=1−y^p(y∣x)=y^y(1−y^)(1−y)logp(y∣x)=ylog(y^)+(1−y)log(1−y^)=−L(y^,y)
4.2 整体损失函数
L o s s = λ c o o r d ∑ i = 0 S 2 ∑ j = 0 B I i j o b j [ ( x i − x ^ i j ) 2 + ( y i − y ^ i j ) 2 ] + λ c o o r d ∑ i = 0 S 2 ∑ j = 0 B I i j o b j [ ( w i j − w ^ i j ) 2 + ( h i j − h ^ i j ) 2 ] + ∑ i = 0 S 2 ∑ j = 0 B I i j o b j [ C ^ i j log ( C i j ) + ( 1 − C ^ i j ) log ( 1 − C i j ) ] + λ n o o b j ∑ i = 0 S 2 ∑ j = 0 B I i j n o o b j [ C ^ i j log ( C i j ) + ( 1 − C ^ i j ) log ( 1 − C i j ) ] + ∑ i = 0 S I i j o b j ∑ c ∈ c l a s s e s ( [ P ^ i j log ( P i j ) + ( 1 − P ^ i j ) log ( 1 − P i j ) ] \begin{gathered} Loss=\lambda_{coord}\sum_{i=0}^{S^2}\sum_{j=0}^BI_{ij}^{obj}[(x_i-\hat{x}_i^j)^2+(y_i-\hat{y}_i^j)^2]+ \\ \lambda_{coord}\sum_{i=0}^{S^{2}}\sum_{j=0}^{B}I_{ij}^{obj}[(\sqrt{w_{i}^{j}}-\sqrt{\hat{w}_{i}^{j}})^{2}+(\sqrt{h_{i}^{j}}-\sqrt{\hat{h}_{i}^{j}})^{2}]+ \\ \sum_{i=0}^{S^2}\sum_{j=0}^BI_{ij}^{obj}[\hat{C}_i^j\log(C_i^j)+(1-\hat{C}_i^j)\log(1-C_i^j)]+ \\ \lambda_{noobj}\sum_{i=0}^{S^{2}}\sum_{j=0}^{B}I_{ij}^{noobj}[\hat{C}_{i}^{j}\log(C_{i}^{j})+(1-\hat{C}_{i}^{j})\log(1-C_{i}^{j})] +\\ \sum_{i=0}^{S}I_{ij}^{obj}\sum_{c\in classes}([\hat{P}_{i}^{j}\log(P_{i}^{j})+(1-\hat{P}_{i}^{j})\log(1-P_{i}^{j})] \end{gathered} Loss=λcoordi=0∑S2j=0∑BIijobj[(xi−x^ij)2+(yi−y^ij)2]+λcoordi=0∑S2j=0∑BIijobj[(wij−w^ij)2+(hij−h^ij)2]+i=0∑S2j=0∑BIijobj[C^ijlog(Cij)+(1−C^ij)log(1−Cij)]+λnoobji=0∑S2j=0∑BIijnoobj[C^ijlog(Cij)+(1−C^ij)log(1−Cij)]+i=0∑SIijobjc∈classes∑([P^ijlog(Pij)+(1−P^ij)log(1−Pij)]
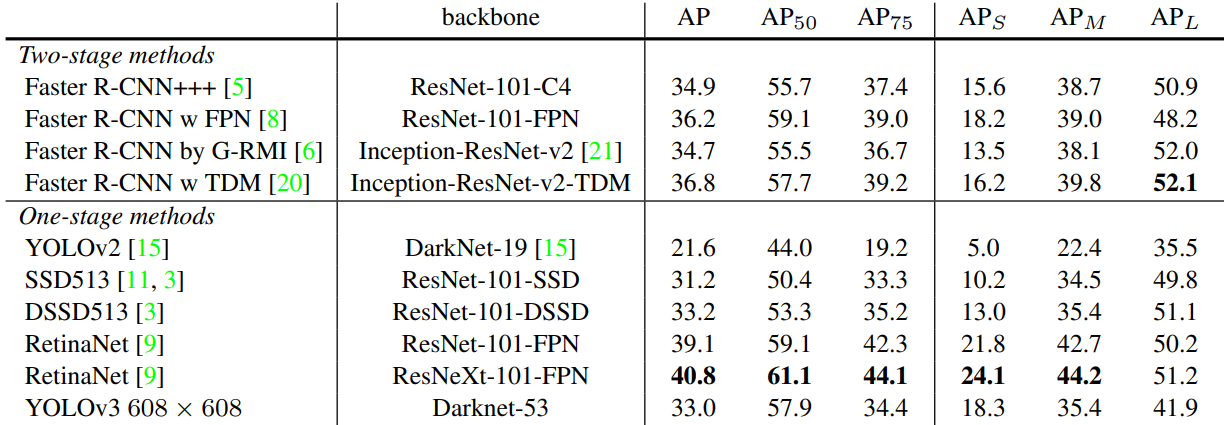
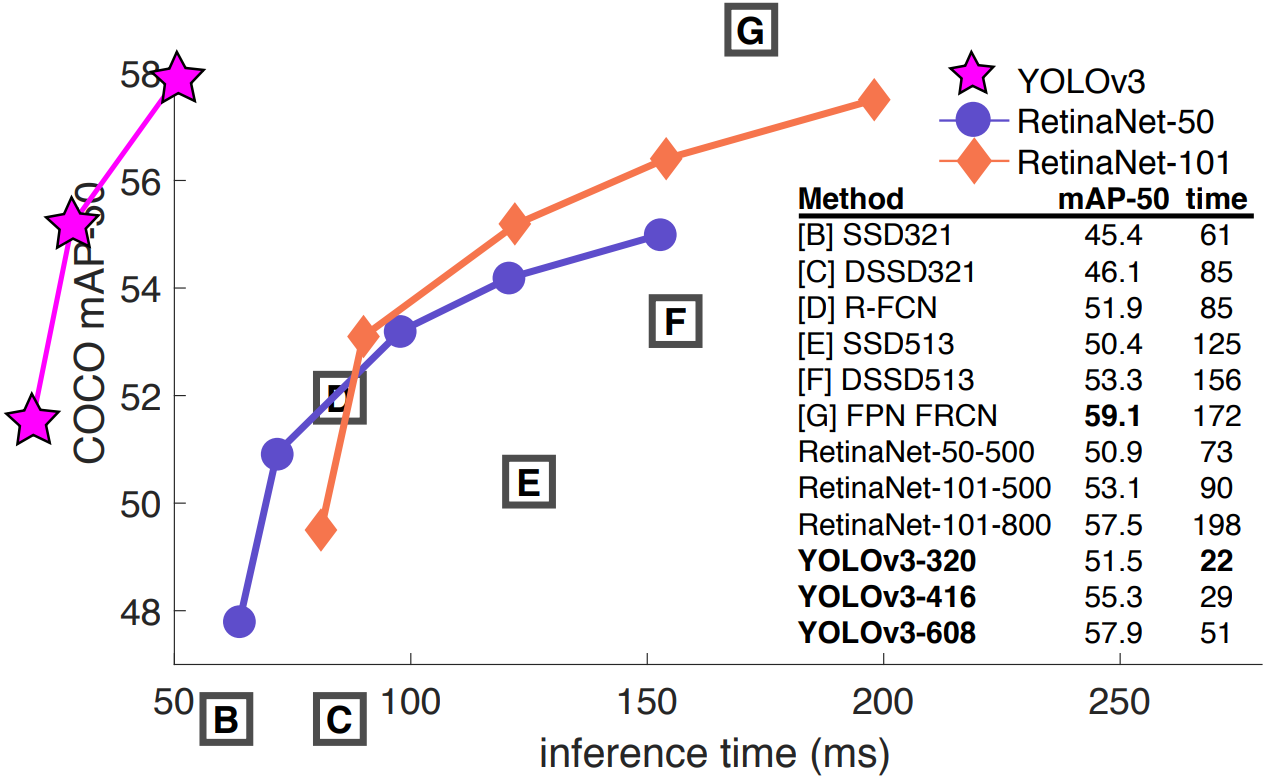
5. 性能对比
整体来看,YOLOV3性能整体比YOLOV2优秀~~
- AP50:IoU 阈值为 0.5 时的 AP 测量值
- AP75:IoU 阈值为 0.75 时的 AP 测量值
- APs:对于小目标的 AP 值
- APm:对于中等目标的 AP 值
- APL:对于大目标的 AP 值