系列文章目录
大模型推理 & memory bandwidth bound (1) - 性能瓶颈与优化概述
大模型推理 & memory bandwidth bound (2) - Multi-Query Attention
大模型推理 & memory bandwidth bound (3) - MLA
大模型推理 & memory bandwidth bound (4) - Speculative Decoding
大模型推理 & memory bandwidth bound (5) - Medusa
文章目录
前言
“We additionally observe that inference from large models is often not bottlenecked on arithmetic operations, but rather on memory bandwidth and communication, so additional computation resources might be available.” —— 《Fast Inference from Transformers via Speculative Decoding》
“For most applications, auto-regressive sampling (ArS) is highly memory bandwidth bound and thus cannot make effective use of modern accelerator hardware.” —— 《Accelerating large language model decoding with speculative sampling》
前面两篇,我们分析了MQA和MLA对于大模型推理加速的贡献,其通过压缩KV Cache,增加算数强度的方式,缓解了大模型增量推理时的memory bandwidth bound问题。本篇我们来探究另一种流行的推理加速范式Speculative Decoding,其使用小号的模型draft model去做自回归采样,而后使用目标模型target model对其进行验证和纠错。在论文《Fast Inference from Transformers via Speculative Decoding》中,作者通过Speculative Decoding实现了2X-3X的解码加速,且不改变输出分布。
如下两篇论文是同一时期的工作,idea基本一致,本篇讲解主要依托于前者:
- Fast Inference from Transformers via Speculative Decoding
- Accelerating large language model decoding with speculative sampling
需要指出的是,随着相关方法的不断涌现,Speculative Decoding已不单指上述两篇工作,也是对这一类方法的统称。去年(2024)有一篇关于Speculative Decoding的综述,还有佬根据这篇综述做的论文阅读合订本,一起放在下边。
- Unlocking Efficiency in Large Language Model Inference: A Comprehensive Survey of Speculative Decoding
- Speculative Decoding 论文阅读合订本
一、原理概述
前言中已经提到了一些,我们在这边对原理做一个更加正式的介绍。
Speculative Decoding包含两个模型,一个是目标模型 M p M_p Mp ,对应的采样分布是 p ( x t ∣ x < t ) p(x_t|x_{<t}) p(xt∣x<t) ,另一个是近似/草稿模型 M q M_q Mq ,对应的采样分布是 q ( x t ∣ x < t ) q(x_t|x_{<t}) q(xt∣x<t) 。草稿模型更加高效,通常意味着模型尺寸明显小于目标模型。其执行基本流程概括如下:
1)用 M q M_q Mq 连续采样 γ \gamma γ 个 token 作为 candidates ;
2)用 M p M_p Mp 对这些 token 做并行验证,即通过比对这些 token 的两个分布 q ( x t ∣ x < t ) q(x_t|x_{<t}) q(xt∣x<t) 和 p ( x t ∣ x < t ) p(x_t|x_{<t}) p(xt∣x<t) 来判断当前 token 是否应该被 M p M_p Mp 接受(后面会讲是怎么做的);一旦当前 token 被拒绝,后续 token 全部拒绝;
3) M p M_p Mp 做额外的一次采样:如果中途有 token 被拒绝,需要根据adjust distribution重新采样;而如果 γ \gamma γ 个 token 全部接受,则 M p M_p Mp 自然也要采样下一个 token ,这种最乐观的情况下,一次采样了 γ + 1 \gamma +1 γ+1 个 token。

实现效果如上图所示,其中绿色部分为 M q M_q Mq 采样并且为 M p M_p Mp 接受的 token ,红色部分是被 M p M_p Mp 拒绝的 token ,蓝色部分是 M p M_p Mp 额外的采样。图中每一行代表一次迭代,也即对上述的基本流程执行了一次,可以看到只通过 9 次迭代就完成了整个序列的输出。
在Speculative Decoding的设定下, M p M_p Mp 被唤醒的次数是减少了,但是考虑到 M p M_p Mp 的耗时,采样一个序列是否真的能加速呢?下图是对encoder-decoder模型在自回归和Speculative Decoding设置下耗时对比,我们主要关心的是decoder部分,可以看到确实能提速。原因解释如下:1) M p M_p Mp 执行一次验证的耗时和自回归解码迭代一次的耗时基本相同,因为验证多个 token 是并行的;2) M q M_q Mq 解码耗时远低于 M p M_p Mp ,所以这部分额外的计算对总耗时影响较小,当然这实际取决于你选择的模型。

现在来看一下使用Speculative Decoding时需要关注那些事情。
- M q M_q Mq 和 M p M_p Mp 的词表需要一致: M p M_p Mp 建议的 tokens 是否为 M q M_q Mq 所接受依赖于这一点;目前 M q M_q Mq 和 M p M_p Mp 的选择通常是同一个系列不同尺寸的模型,这个要求自然满足;
- M q M_q Mq 和 M p M_p Mp 模型尺寸的选择:两者模型尺寸差异建议至少是一个数量级,这样 M q M_q Mq 的解码耗时才会明显低于 M p M_p Mp ,才有加速效果;可以的话,这两个模型尺寸都往大了选,因为 M q M_q Mq 模型大意味着输出相对更靠谱,接受率应该会更高一点;
- γ \gamma γ 的选择:通常在 5 左右, M q M_q Mq 建议的 tokens 需要考虑接受率的问题, γ \gamma γ 过高会导致 M q M_q Mq 解码次数增加,而且实际被接受的 token 个数明显小于 γ \gamma γ ,影响加速效果。
论文中还有很多分析,在这里就不赘述了,兴趣的可以去原文。
二、Speculative Sampling
前面我们留了一些疑问,比如:1)我们还不知道Speculative Decoding中 M p M_p Mp是怎么接受或拒绝建议的 token 的;2)之前还提到Speculative Decoding不改变模型的输出分布,为什么?这一节就通过介绍Speculative Sampling具体细节来回答这些问题。
注:区分Speculative Decoding和Speculative Sampling这两个概念,个人理解Speculative Decoding更倾向于描述完整的解码架构,Speculative Sampling则是采样方法。
1.Rejection Sampling流程
在介绍Speculative Sampling之前先介绍Rejection Sampling,Speculative Sampling可以认为是Rejection Sampling的改进版本。先说下Rejection Sampling的目标:已知分布 p ( x ) p(x) p(x) 和 q ( x ) q(x) q(x) ,经由Rejection Sampling采样规则在建议分布 q ( x ) q(x) q(x) 上采样,使其采样分布逼近目标分布 p ( x ) p(x) p(x) 。采样流程如下:

其中 r ∼ U ( 0 , 1 ) r \sim U(0,1) r∼U(0,1) 表示生成一个随机数 r r r ,它服从均匀分布; M M M 是一个参数,需满足 p ( x ) ≤ M q ( x ) p(x) \le Mq(x) p(x)≤Mq(x) 。采样步骤很简单,是依据 r r r 和 p ( x ) M q ( x ) \frac{p(x)}{Mq(x)} Mq(x)p(x) 的大小来决定是接受还是拒绝当前的采样 x x x ,如果拒绝则需要重新采样。但是光看公式可能不理解它的物理意义是什么,我们用可视化的方式来帮助理解。
下图(自己懒得画了,别人的图)中红色曲线表示目标分布 p ( x ) p(x) p(x) ,蓝色曲线表示建议分布的缩放 M q ( x ) Mq(x) Mq(x) 。所以就理解了参数 M M M 的选择是希望整个分布曲线能包络住目标分布。 p ( x ) M q ( x ) \frac{p(x)}{Mq(x)} Mq(x)p(x) 意味着在样本 x x x 上两个分布曲线的高度之比,也即采样概率之比。以图中黑色竖线为例, p ( x ) M q ( x ) \frac{p(x)}{Mq(x)} Mq(x)p(x) 实际上对应的就是竖线与目标分布曲线(红色曲线)的交点, r < p ( x ) M q ( x ) r < \frac{p(x)}{Mq(x)} r<Mq(x)p(x) 表示采样落在目标曲线下方,直接接受该采样;反之表示在两条曲线只减(灰色区域),此时选择拒绝。显而易见,最后的采样分布应当趋近于目标分布。

(https://zhuanlan.zhihu.com/p/604094053)
2.Rejection Sampling分布一致性证明
以上是直观理解,下面会证明:被接受样本 x x x 的分布 p a c c e p t e d ( x ) p_{accepted}(x) paccepted(x) 和目标分布 p ( x ) p(x) p(x) 一致。不感兴趣的可以直接跳过。
【证明1】
p a c c e p t e d ( x ) = ( p ( x ) M ⋅ q ( x ) ⋅ q ( x ) ) / 1 M = p ( x ) \begin{aligned} p_{accepted}(x) & = (\frac{p(x)}{M \cdot q(x)} \cdot q(x)) / \frac{1}{M} \\ & =p(x) \end{aligned} paccepted(x)=(M⋅q(x)p(x)⋅q(x))/M1=p(x)
使用建议分布采样的概率是 q ( x ) q(x) q(x) ,其被接受的概率为 p ( x ) M q ( x ) \frac{p(x)}{Mq(x)} Mq(x)p(x) ,因此采样被接受的概率为 p ( x ) M q ( x ) ⋅ q ( x ) \frac{p(x)}{Mq(x)} \cdot q(x) Mq(x)p(x)⋅q(x) ;然而实际采样的时候对建议分布做了 M M M 倍的放大,导致采样后被接受的概率降低为 1 M \frac{1}{M} M1 ,因此需要除以归一化因子 1 M \frac{1}{M} M1 。虽然这种证明方式不严谨,但是易于理解。
【证明2】
先列出公式,然后再对每一行做出说明。
p a c c e p t e d ( x ) = P ( x ∣ a c c e p t e d ) = P ( a c c e p t e d ∣ x ) ⋅ q ( x ) P ( a c c e p t e d ) = P ( a c c e p t e d ∣ x ) ⋅ q ( x ) ∫ P ( a c c e p t e d ∣ x ) ⋅ q ( x ) d x = p ( x ) M ⋅ q ( x ) ⋅ q ( x ) ∫ p ( x ) M ⋅ q ( x ) ⋅ q ( x ) d x = p ( x ) \begin{aligned} p_{accepted}(x) &= P(x|accepted) \\ &= \frac{P(accepted|x) \cdot q(x)}{P(accepted)} \\ &= \frac{P(accepted|x) \cdot q(x)}{\int P(accepted|x) \cdot q(x)dx} \\ &= \frac{\frac{p(x)}{M \cdot q(x)} \cdot q(x)}{\int \frac{p(x)}{M \cdot q(x)} \cdot q(x)dx} \\ &= p(x) \end{aligned} paccepted(x)=P(x∣accepted)=P(accepted)P(accepted∣x)⋅q(x)=∫P(accepted∣x)⋅q(x)dxP(accepted∣x)⋅q(x)=∫M⋅q(x)p(x)⋅q(x)dxM⋅q(x)p(x)⋅q(x)=p(x)
第一行将要求的概率表示为被接受的样本中是 x x x 的概率 P ( x ∣ a c c e p t e d ) P(x|accepted) P(x∣accepted) ;第二行使用了贝叶斯公式;第三行使用了全概率公式,分母的积分表示采样被接受的概率;采样的 x x x 被接受的概率为 P ( a c c e p t e d ∣ x ) = p ( x ) M ⋅ q ( x ) P(accepted|x)=\frac{p(x)}{M \cdot q(x)} P(accepted∣x)=M⋅q(x)p(x) ,将其代入公式会得到第四行;最后求得结果。
3.Speculative Sampling流程
(https://zhuanlan.zhihu.com/p/7162909442)
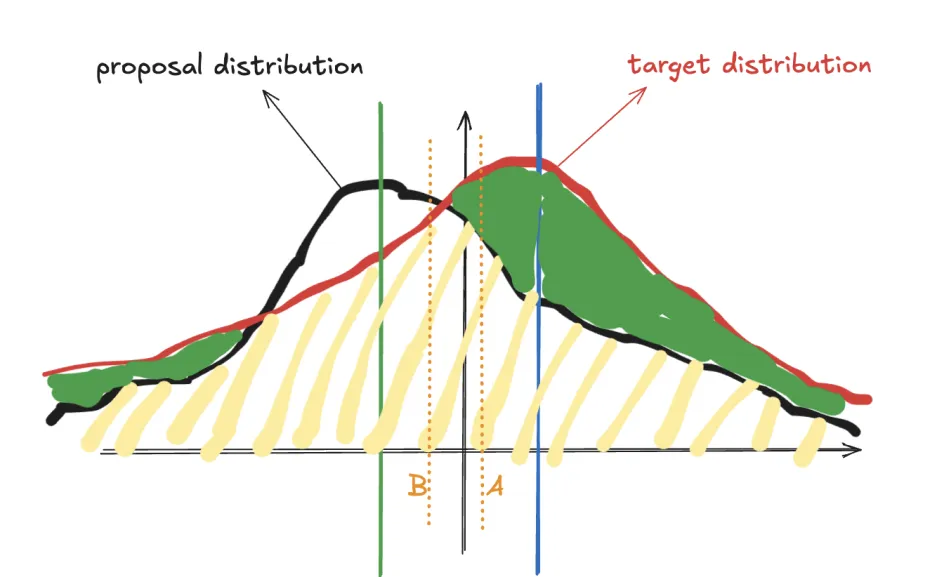
Speculative Sampling的采样是不需要 M M M 的,比较了 r r r 和 p ( x ) q ( x ) \frac{p(x)}{q(x)} q(x)p(x) 的大小,当 r < p ( x ) q ( x ) r < \frac{p(x)}{q(x)} r<q(x)p(x) 时接受,反之则拒绝,拒绝之后使用adjusted distribution重新采样。我们将上述流程转成如下更好理解的方式:
1)若 q ( x ) ≤ p ( x ) q(x) \le p(x) q(x)≤p(x) ,直接接受;
2)若 q ( x ) > p ( x ) q(x) \gt p(x) q(x)>p(x) ,则以概率 1 − p ( x ) q ( x ) 1-\frac{p(x)}{q(x)} 1−q(x)p(x) 的概率拒绝;
3)如果是情况2),还需要重新在新的分布 p ′ ( x ) = n o r m ( m a x ( 0 , p ( x ) − q ( x ) ) ) p'(x)= norm(max(0,p(x)-q(x))) p′(x)=norm(max(0,p(x)−q(x))) 上采样,这个分布就是上面提到的adjusted distribution。
同样的,我们结合图像(如上图所示)来更好的理解Speculative Sampling的工作原理。
- 1)的情况对应图中蓝色竖线,建议分布曲线在目标分布曲线下方,此时显然应当尽可能采样以接近目标分布,因此采样接收率为1;
- 2)的情况对应图中绿色竖线,建议分布曲线在目标分布曲线上方,此时建议分布的采样概率相比于目标分布的过高,接受率应为 p ( x ) q ( x ) \frac{p(x)}{q(x)} q(x)p(x) ,这类似于拒绝采样的做法;
- 使用1)和2)的采样方法,available的采样区域是图中黄色斜条纹区域,想要使得采样服从目标分布 p ( x ) p(x) p(x) ,还需要采样图中绿色部分,3)就是做了这部分采样。
具体看一下绿色部分的采样分布 p ′ ( x ) p'(x) p′(x) 是如何表达的:
p ′ ( x ) = n o r m ( m a x ( 0 , p ( x ) − q ( x ) ) ) = p ( x ) − m i n ( q ( x ) , p ( x ) ) ∑ x ′ ( p ( x ′ ) − m i n ( q ( x ′ ) , p ( x ′ ) ) ) = p ( x ) − m i n ( q ( x ) , p ( x ) ) 1 − ∑ x ′ m i n ( q ( x ′ ) , p ( x ′ ) ) = p ( x ) − m i n ( q ( x ) , p ( x ) ) 1 − β \begin{aligned} p'(x) &= norm(max(0,p(x)-q(x))) \\ &= \frac{p(x)-min(q(x),p(x))}{\sum_{x'}(p(x')-min(q(x'),p(x')))} \\ & = \frac{p(x)-min(q(x),p(x))}{1 - \sum_{x'}min(q(x'),p(x'))} \\ &= \frac{p(x)-min(q(x),p(x))}{1-\beta} \end{aligned} p′(x)=norm(max(0,p(x)−q(x)))=∑x′(p(x′)−min(q(x′),p(x′)))p(x)−min(q(x),p(x))=1−∑x′min(q(x′),p(x′))p(x)−min(q(x),p(x))=1−βp(x)−min(q(x),p(x))
其实还是比较容易理解的,对于绿色区域,当前的概率和肯定不是1,所以需要除以一个归一化因子,也就是第二行的分母;从第三行到第四行,这是由于采样接受率(acceptance rate)有
β = ∑ x m i n ( q ( x ) , p ( x ) ) \beta = \sum_{x}min(q(x),p(x)) β=x∑min(q(x),p(x))
这一点由论文的Theorem 3.5给出,这里不展开了。
4.Speculative Sampling分布一致性证明
根据上面所说,采样的概率 P ( x = x ′ ) P(x=x') P(x=x′) 来源于两部分:第一部分是接受了 M q M_q Mq 的采样 x ′ x' x′ ,对应上图黄色区域,对应的情况是1)或者2)中被采样接受的部分;第二部分是拒绝了draft model的采样(来源于2)),使用3)进行重新采样;用公式表达如下:
P ( x = x ′ ) = P ( g u e s s a c c e p t e d , x = x ′ ) + P ( g u e s s r e j e c t e d , x = x ′ ) P(x=x')=P(guess \space accepted, x=x')+P(guess \space rejected, x=x') P(x=x′)=P(guess accepted,x=x′)+P(guess rejected,x=x′)
第一项表达式如下:
P ( g u e s s a c c e p t e d , x = x ′ ) = q ( x ′ ) min ( 1 , p ( x ′ ) q ( x ′ ) ) = min ( q ( x ′ ) , p ( x ′ ) ) P(guess \space accepted, x=x')=q(x')\min(1, \frac{p(x')}{q(x')})=\min(q(x'),p(x')) P(guess accepted,x=x′)=q(x′)min(1,q(x′)p(x′))=min(q(x′),p(x′))
使用 q ( x ′ ) q(x') q(x′) 进行采样, min ( 1 , p ( x ′ ) q ( x ′ ) ) \min(1, \frac{p(x')}{q(x')}) min(1,q(x′)p(x′)) 表示接受概率,其中 1 1 1 来源于采样1), p ( x ′ ) q ( x ′ ) \frac{p(x')}{q(x')} q(x′)p(x′) 来源于采样2)。
第二项表达式为:
P ( g u e s s r e j e c t e d , x = x ′ ) = ( 1 − β ) p ′ ( x ′ ) = p ( x ′ ) − min ( q ( x ′ ) , p ( x ′ ) ) P(guess \space rejected, x=x')=(1-\beta)p'(x')=p(x') - \min(q(x'),p(x')) P(guess rejected,x=x′)=(1−β)p′(x′)=p(x′)−min(q(x′),p(x′))
( 1 − β ) (1-\beta) (1−β) 是被拒绝也即重新采样的概率, p ′ ( x ′ ) p'(x') p′(x′) 是adjusted distribution,带入计算即可;
综上可得
P ( x = x ′ ) = p ( x ′ ) P(x=x')=p(x') P(x=x′)=p(x′)
证毕。
5.Speculative Sampling的优势
我们会问既然有Rejection Sampling,我们为什么要用Speculative Sampling呢?实际上Speculative Sampling在采样效率等方面是有优势的。
Speculative Sampling接受率较高,采样效率高:直观理解,目标分布和建议分布的重叠部分面积关于建议分布的面积占比代表着接受率,显然的对于Rejection Sampling来说,建议分布做了 M M M 倍的放大,面积占比通常更小,接受率不如Speculative Sampling;- 不需要求出 M M M :对于
Rejection Sampling来说,每一次解码迭代都需要计算当前时间步的 M = m a x x p ( x ) q ( x ) M=max_x \frac{p(x)}{q(x)} M=maxxq(x)p(x) ,并且一旦 M M M 较大,接受率就低了。
三、开源实现
经过前面的讲解,相信我们已经对整个Speculative Decoding有了比较完整的理解。现在我们来看代码。代码采用https://github.com/feifeibear/LLMSpeculativeSampling。
这边只贴出最核心部分的代码,对应于论文中的 Algorithm 1。

@torch.no_grad()
def speculative_sampling(prefix : torch.Tensor, approx_model : torch.nn.Module, target_model : torch.nn.Module,
max_len : int , gamma : int = 4,
temperature : float = 1, top_k : int = 0, top_p : float = 0, verbose : bool = False, random_seed : int = None) -> torch.Tensor:
"""
Args:
x (torch.Tensor): input sequence, (batch, prefix_seqlen), Note that the batch dim is always 1 now.
approx_model (torch.nn.Module): approx model, the small one
target_model (torch.nn.Module): target model, the large one
max_len (int): the max overall generated tokens number.
gamma (int): $\gamma$, the token number small model guesses.
temperature (float, optional): Defaults to 1.
top_k (int, optional): Defaults to 0.
top_p (float, optional): Defaults to 0.
Returns:
torch.Tensor: generated tokens (batch, target_seqlen)
"""
seq_len = prefix.shape[1]
T = seq_len + max_len
# 当前demo只支持batch_size = 1,后面会说batch_size > 1的情况
assert prefix.shape[0] == 1, "input batch size must be 1"
device = target_model.device
# 模型使用了KV Cache
approx_model_cache = KVCacheModel(approx_model, temperature, top_k, top_p)
target_model_cache = KVCacheModel(target_model, temperature, top_k, top_p)
# 统计数据,可用于计算接受率等指标
resample_count = 0
target_sample_count = 0
accepted_count = 0
while prefix.shape[1] < T:
# q = M_q[prefix + x_0, x_1, .., x_(gamma-2)]
prefix_len = prefix.shape[1]
# M_q进行gamma步解码,采样数据append到x中,同时也会记录每个位置上的分布(词表中每个token被采样的概率)
x = approx_model_cache.generate(prefix, gamma)
# M_p执行一次采样,这一步的目标其实是计算x中最后gamma个位置上的分布
_ = target_model_cache.generate(x, 1)
# 预估终止位置
n = prefix_len + gamma - 1
# 对每个M_q建议的token做验证
for i in range(gamma):
if random_seed:
torch.manual_seed(random_seed)
# 随机数r
r = torch.rand(1, device = device)
j = x[:, prefix_len + i]
# 执行 r < p(x) / q(x)的判断,不满足则拒绝
if r > (target_model_cache._prob_history[:, prefix_len + i - 1, j]) / (approx_model_cache._prob_history[:, prefix_len + i - 1, j]):
# reject
n = prefix_len + i - 1
break
accepted_count += 1
# print(f"n : {n}, i : {i}, prefix_len + gamma - 1: {prefix_len + gamma - 1}")
assert n >= prefix_len - 1, f"n {n}, prefix_len {prefix_len}"
# 更新prefix
prefix = x[:, :n + 1]
# 回退到n+1处,这是下一个speculative decoding step开始的位置
approx_model_cache.rollback(n+1)
assert approx_model_cache._prob_history.shape[-2] <= n + 1, f"approx_model prob list shape {approx_model_cache._prob_history.shape}, n {n}"
if n < prefix_len + gamma - 1:
# 拒绝之后adjusted distribution中重新采样
# reject someone, sample from the pos n
t = sample(max_fn(target_model_cache._prob_history[:, n, :] - approx_model_cache._prob_history[:, n, :]))
resample_count += 1
# 同样回滚
target_model_cache.rollback(n+1)
else:
# gamma个token全接受,M_p再采样下一个token
# all approx model decoding accepted
assert n == target_model_cache._prob_history.shape[1] - 1
t = sample(target_model_cache._prob_history[:, -1, :])
target_sample_count += 1
# approx_model_cache还是n+1的位置,所以下一个step,approx_model其实是缺少一个token的cache
target_model_cache.rollback(n+2)
prefix = torch.cat((prefix, t), dim=1)
return prefix
四、transformers实现
transformers中实现了类似的算法,取名为Assisted Generation,其示例代码如下,相对于常规情形只需要传入assistant_model即可,这样在源代码中会走generation_mode==GenerationMode.ASSISTED_GENERATION的逻辑。
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
prompt = "Alice and Bob"
# 如前面所说,这边两个模型尺寸差距小,所以实际上并没有加速,反而更慢了。
checkpoint = "./Qwen/Qwen2___5-0___5B-Instruct"
assistant_checkpoint = "./Qwen/Qwen2___5-3B-Instruct"
device = "cuda" if torch.cuda.is_available() else "cpu"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
inputs = tokenizer(prompt, return_tensors="pt").to(device)
model = AutoModelForCausalLM.from_pretrained(checkpoint).to(device)
assistant_model = AutoModelForCausalLM.from_pretrained(assistant_checkpoint).to(device)
outputs = model.generate(**inputs, assistant_model=assistant_model)
print(tokenizer.batch_decode(outputs, skip_special_tokens=True))
源码中核心部分为GenerationMixin的_assisted_decoding()方法,解码部分有两个分支。第一个就是采样且candidate_logits(辅助模型的)存在的情况,它使用的Speculative Decoding的算法,在代码中对应_speculative_sampling()方法(实现和前面的类似,这里就不贴出来了),这也是我们当前走的分支;另一个分支则是直接比对两个模型的 token 选择是否相同了,比较暴力。
# transformers/generation/utils.py
class GenerationMixin
# ...
def _assisted_decoding(
self,
input_ids: torch.LongTensor,
candidate_generator: CandidateGenerator,
logits_processor: LogitsProcessorList,
logits_warper: LogitsProcessorList,
stopping_criteria: StoppingCriteriaList,
generation_config: GenerationConfig,
synced_gpus: bool,
streamer: Optional["BaseStreamer"],
**model_kwargs,
) -> Union[GenerateNonBeamOutput, torch.LongTensor]:
# ...其他代码
# 3. Select the accepted tokens. There are two possible cases:
# Case 1: `do_sample=True` and we have logits for the candidates (originally from speculative decoding)
# 👉 Apply algorithm 1 from the speculative decoding paper (https://arxiv.org/pdf/2211.17192.pdf).
if do_sample and candidate_logits is not None:
valid_tokens, n_matches = _speculative_sampling(
candidate_input_ids,
candidate_logits,
candidate_length,
new_logits,
is_done_candidate,
)
# Case 2: all other cases (originally from assisted generation) 👉 Compare the tokens selected from the
# original model logits with the candidate tokens. We can keep the candidate tokens until the first
# mismatch, or until the max length is reached.
else:
if do_sample:
probs = new_logits.softmax(dim=-1)
selected_tokens = torch.multinomial(probs[0, :, :], num_samples=1).squeeze(1)[None, :]
else:
selected_tokens = new_logits.argmax(dim=-1)
candidate_new_tokens = candidate_input_ids[:, cur_len:]
n_matches = ((~(candidate_new_tokens == selected_tokens[:, :-1])).cumsum(dim=-1) < 1).sum()
# Ensure we don't generate beyond max_len or an EOS token
if is_done_candidate and n_matches == candidate_length:
n_matches -= 1
valid_tokens = selected_tokens[:, : n_matches + 1]
# ...其他代码
另外需要注意的一个细节是,与前面的代码不同,目标模型model和近似模型assistant_model的生成模式是不同的,尽管输入的时候两个模型都默认是do_sample = True,但是后面assistant_model被强制修改为do_sample = False,做的是greedy search。如下面代码所示,它给出的理由是最大化n_matches,也即提高接受率。需要注意的是,这边 q ( x ) q(x) q(x)仍然是保留了原始分布,而不是类似于top-1 的截断分布。
# transformers/generation/candidate_generator.py
class AssistedCandidateGenerator(CandidateGenerator):
def __init__(
self,
input_ids: torch.LongTensor,
assistant_model: "PreTrainedModel",
generation_config: "GenerationConfig",
model_kwargs: Dict,
inputs_tensor: Optional[torch.Tensor] = None,
logits_processor: "LogitsProcessorList" = None,
):
# ...
# Disable sampling -- this implementation of assisted generation/speculative decoding uses the assistant
# greedily to maximize matches. Disables sampling-related flags to prevent warnings
self.generation_config.do_sample = False
for attr in ("temperature", "top_p", "min_p", "typical_p", "top_k", "epsilon_cutoff", "eta_cutoff"):
setattr(self.generation_config, attr, None)
# ...
另外,这边也限制batch_size=1。
五、vLLM实现
现在已经推出了vLLM V1,相关介绍见v1_user_guide,其中有Spec Decode的最新信息。不过我比较懒(反面教材),没有安装最新版的vLLM,试了一下很久之前的vLLM==v0.5.0.post1版本,发现能跑Speculative Decoding(需要use_v2_block_manager=True),示例代码如下。
from vllm import LLM, SamplingParams
prompts = [
"The future of AI is",
"What is Bert?"
]
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
model = "./Qwen/Qwen2___5-0___5B-Instruct"
speculative_model = "./Qwen/Qwen2___5-3B-Instruct"
llm = LLM(
model=model,
tensor_parallel_size=1,
speculative_model=speculative_model,
num_speculative_tokens=5,
use_v2_block_manager=True,
)
outputs = llm.generate(prompts, sampling_params)
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
我们这里摘取源码中的部分来简单说一下:
proposer_worker:近似模型对应的 worker ,是类MultiStepWorker(Worker, ProposerWorkerBase)的实例,特点就是一个迭代执行多个 step ,也即需要跑 γ \gamma γ 次模型获得建议的 tokens;scorer_worker:目标模型对应的 worker ,是类Worker的实例,每个迭代只执行一个 step;但是需要说明的是,目标模型验证 γ \gamma γ 个 token 在一个 step 中完成;rejection_sampler:采样算法,尽管名字看着像Rejection Sampling,但实际上是Speculative Sampling,原因是在论文《Accelerating large language model decoding with speculative sampling》中它被称作modified rejection sampling;它实现了高效的 batch 采样的方法;self._run_no_spec():不是所有情况都需要做Speculative Sampling的,比如Prefill阶段就不需要验证;self._run_speculative_decoding_step():Speculative Sampling的实现,就是近似模型给出建议 token ,目标模型验证,代码这里就不展开了。
# vllm/spec_decode/spec_decode_worker.py
class SpecDecodeWorker(LoraNotSupportedWorkerBase):
"""Worker which implements speculative decoding.
Speculative decoding reduces decoding per-token latency by using a proposal
method, such as a small draft model, to speculate ahead of a larger LLM. The
probabilities of the speculative tokens are then determined by the larger
LLM, after which some verification routine determines which (if any) of the
speculative tokens are accepted by the larger LLM.
See https://github.com/vllm-project/vllm/pull/2188 and
https://github.com/vllm-project/vllm/pull/3103 for more info.
The current implementation has the following limitations:
* Only draft-model proposal is implemented (contributions for more forms are
welcome!).
* Only top-1 proposal and scoring are implemented. Tree-attention is left as
future work.
* Only lossless rejection sampling is supported. Contributions adding lossy
verification routines are welcome (e.g. Medusa's typical acceptance).
* All sequences in a batch must have the same proposal length, or zero. This
can be improved by having per-sequence speculation in the future.
* The scoring forward pass is done without an MQA kernel, which is
suboptimal especially as the batch size, proposal length, and sequence
lengths grow. Contributions to add a MQA scoring are welcome once
correctness tests pass.
More info here https://docs.google.com/document/d/1T-JaS2T1NRfdP51qzqpyakoCXxSXTtORppiwaj5asxA/edit.
"""
# ...
def __init__(
self,
proposer_worker: ProposerWorkerBase, # 对应近似模型M_q
scorer_worker: WorkerBase, # 对应目标模型M_p
rejection_sampler: RejectionSampler, # 拒绝性采样,nn.Module,实现采样功能
metrics_collector: Optional[AsyncMetricsCollector] = None,
disable_by_batch_size: Optional[int] = None,
):
# ...
@torch.inference_mode()
def execute_model(
self,
execute_model_req: Optional[ExecuteModelRequest] = None
) -> List[SamplerOutput]:
"""Perform speculative decoding on the input batch.
"""
# 此处省略部分代码
# ...
disable_all_speculation = self._should_disable_all_speculation(
execute_model_req)
# num_lookahead_slots这边对应的就是gamma,也就是上面代码中的num_speculative_tokens
# 只不过当prefill的时候是0
num_lookahead_slots = execute_model_req.num_lookahead_slots
# ...
# Speculative decoding is disabled in the following cases:
# 1. Prefill phase: Speculative decoding is not
# used during the prefill phase.
# 2. Auto-disable enabled: The running queue size exceeds
# the specified threshold.
# 3. No request: There are no requests in the batch.
# In any of these cases, the proposer and scorer workers
# are called normally.
if num_lookahead_slots == 0 or len(
execute_model_req.seq_group_metadata_list
) == 0 or disable_all_speculation:
# 常规情况下是在prefill阶段走此分支,因为prefill不需要去做验证
return self._run_no_spec(execute_model_req,
skip_proposer=disable_all_speculation)
# decode阶段,走此分支
return self._run_speculative_decoding_step(execute_model_req,
num_lookahead_slots)
六、细节
1.sampling_params适配
尽管论文中以标准的(朴素的)采样方式来讨论的,但是对于argmax、top-k、top-p等采样方式以及设置温度都是适用的,因为这些sampling_params就是对logits做输出分布调整。
2.输出分布一致性
前面提到使用Speculative Decoding是不会改变目标模型的输出分布的。需要澄清的是,这是说统计上的分布是一致的,而不代表目标模型在是应用Speculative Decoding前后生成的序列完全一致,这是初学者可能的误区。
3.batch_size > 1
【Batching】
前面已经说了,在开源实现和transformers(我的版本是 4.42.4 )实现中,都限制batch_size=1。但事实上是可以实现batch_size > 1的,我们根据[WIP] - Enable speculative decoding with batch size >1 #32189,我们总结一下它的实现思路。
- 近似模型 γ \gamma γ 次采样、目标模型做验证都使用 batch 推理,并获得
n_matches这个张量,它保存了每个序列在当前Speculative Decoding Step中被接受的 token 个数; - 由于步骤 1 中每个序列中存在一些错误(没有被接受)的 token ,所以我们需要针对每个序列丢弃这些 token ,丢弃个数为
n_matches.max() - n_matches[i],i表示序列索引。此时每个序列长度不一致,需要在序列左侧做n_matches.max() - n_matches[i]个 padding ; - 虽然步骤 2 对齐了序列长度,但是可能在最前面几列都是 padding ,需要挖掉这些冗余的列,保持最短的序列长度,此时回到步骤 1 进入下一轮。
【Sequence Packing】
除了上面的常规处理方式,还可以使用Sequence Packing的方式,也就是将多个序列 concatenate 在一起,此时batch_size=1,但是可以同时处理多个多个序列。如下图所示,两个序列拼成一个序列,只要调整每个序列的mask和position embedding(右图粉色区域)即可正常工作。
Sequence Packing本意如下:模型训练的数据序列长度差异比较大,batch 训练时会做很多padding,不能很好地利用显存进行高效训练,而使用Sequence Packing可以解决这个问题,比如ModernBERT就在训练中使用了它。现在考虑batch_size > 1的Speculative Decoding,Sequence Packing也能直接解决问题,因为它不需要像上面的Batching一样用padding做对齐。
你有没有发现上面vLLM使用Speculative Decoding是可以batch_size > 1的?实际上它推理就是使用了Sequence Packing的处理方式。

(https://huggingface.co/blog/poedator/4d-masks)
4.latency vs. temperature
在Staged Speculative Decoding中,作者测试发现随着采样温度的升高,Speculative Decoding的加速效果在减弱。同样的,在Assisted Generation博客中,也展示了相同的结果,如下图所示。直觉上,当温度较低时,draft model更倾向于选择概率更高的token,通常这些token更容易被target model所接受;当温度较高时,draft model选择概率较小的token的几率增加,而这部分(非最大概率的分布)可能align的不怎么好,被拒绝的概率可能比较高。因此,latency随着温度的升高而增加。

总结
本篇讲解了Speculative Decoding的原理,即以近似模型输出建议 tokens ,目标模型对齐进行并行验证的方式对模型推理进行了加速;同时,我们也证明了Speculative Sampling的采样方式使得其输出分布与目标模型原有的自回归输出分布保持一致。相信配合代码的解读,大家对Speculative Decoding可以有一个清晰的认识。
参考
[1] 大模型推理妙招—投机采样(Speculative Decoding) - 知乎
[2] 推测解码的拒绝采样 - 知乎
[3] Assisted Generation: a new direction toward low-latency text generation
[4] [WIP] - Enable speculative decoding with batch size >1 #32189
[5] https://github.com/feifeibear/LLMSpeculativeSampling
[6] Efficient Sequence Packing without Cross-contamination: Accelerating Large Language Models without Impacting Performance
[7] Efficient LLM Pretraining: Packed Sequences and Masked Attention