机器学习入门核心算法:集成学习(Ensemble Learning)
1. 算法逻辑
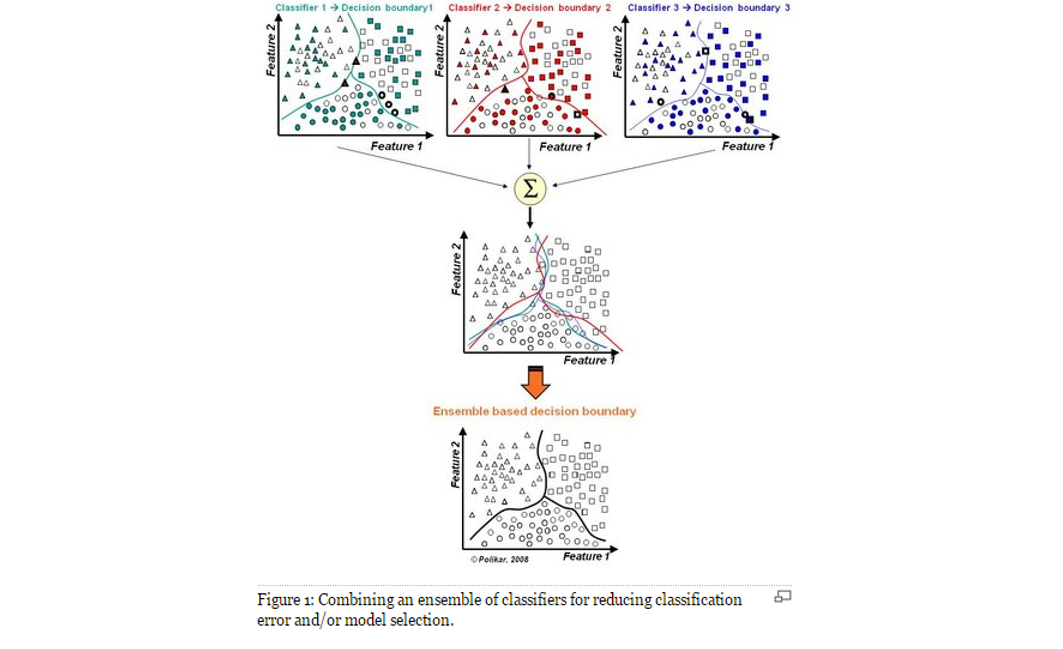
集成学习通过组合多个基学习器来提升模型性能,核心思想是"三个臭皮匠,顶个诸葛亮"。主要分为三类:
核心逻辑:
- 多样性原则:基学习器应有差异性(不同结构/数据/特征)
- 组合策略:
- 平均法(回归)
- 投票法(分类)
- 学习法(Stacking)
2. 算法原理与数学推导
2.1 Bagging(Bootstrap Aggregating)
原理:通过自助采样构建多个独立模型
- 采样率:约63.2%的样本被选中( l i m n → ∞ ( 1 − 1 n ) n = 1 e ≈ 0.368 lim_{n \to \infty} (1-\frac{1}{n})^n = \frac{1}{e} \approx 0.368 limn→∞(1−n1)n=e1≈0.368)
- 最终预测: f bag ( x ) = 1 T ∑ t = 1 T f t ( x ) f_{\text{bag}}(x) = \frac{1}{T} \sum_{t=1}^T f_t(x) fbag(x)=T1∑t=1Tft(x)
方差减少证明:
Var ( f ˉ ) = ρ σ 2 + 1 − ρ T σ 2 \text{Var}(\bar{f}) = \rho \sigma^2 + \frac{1-\rho}{T} \sigma^2 Var(fˉ)=ρσ2+T1−ρσ2
其中 ρ \rho ρ是模型间相关性,Bagging通过随机采样降低 ρ \rho ρ
2.2 Boosting
原理:顺序训练模型,后续模型聚焦前序错误
AdaBoost推导(二分类):
- 初始化权重: w i ( 1 ) = 1 N w_i^{(1)} = \frac{1}{N} wi(1)=N1
- 对 t = 1 to T t=1 \text{ to } T t=1 to T:
- 训练弱分类器 h t h_t ht
- 计算错误率: ϵ t = ∑ i = 1 N w i ( t ) 1 ( h t ( x i ) ≠ y i ) \epsilon_t = \sum_{i=1}^N w_i^{(t)} \mathbf{1}(h_t(x_i) \neq y_i) ϵt=∑i=1Nwi(t)1(ht(xi)=yi)
- 计算权重: α t = 1 2 ln ( 1 − ϵ t ϵ t ) \alpha_t = \frac{1}{2} \ln \left( \frac{1-\epsilon_t}{\epsilon_t} \right) αt=21ln(ϵt1−ϵt)
- 更新样本权重: w i ( t + 1 ) = w i ( t ) e − α t y i h t ( x i ) Z t w_i^{(t+1)} = \frac{w_i^{(t)} e^{-\alpha_t y_i h_t(x_i)}}{Z_t} wi(t+1)=Ztwi(t)e−αtyiht(xi)
- 最终模型: H ( x ) = sign ( ∑ t = 1 T α t h t ( x ) ) H(x) = \text{sign} \left( \sum_{t=1}^T \alpha_t h_t(x) \right) H(x)=sign(∑t=1Tαtht(x))
2.3 Stacking
原理:分层训练元学习器
Level 1: y ^ i ( k ) = f k ( x i ) \text{Level 1:} \quad \hat{y}_i^{(k)} = f_k(x_i) Level 1:y^i(k)=fk(xi)
Level 2: g ( y ^ i ( 1 ) , . . . , y ^ i ( K ) ) \text{Level 2:} \quad g(\hat{y}_i^{(1)}, ..., \hat{y}_i^{(K)}) Level 2:g(y^i(1),...,y^i(K))
3. 模型评估
评估指标
| 评估维度 | 指标 |
|---|---|
| 准确性 | 准确率(分类)/MSE(回归) |
| 鲁棒性 | OOB误差/交叉验证方差 |
| 多样性 | Q统计量/Kappa系数 |
| 计算效率 | 训练时间/预测延迟 |
基学习器选择策略
- 精度-多样性权衡:
- 高精度:SVM、神经网络
- 高多样性:决策树、KNN
- 数量选择:
Error ∝ e − k T ( 经验公式 ) \text{Error} \propto e^{-kT} \quad (\text{经验公式}) Error∝e−kT(经验公式)
通常取10-100个基学习器
4. 应用案例
4.1 金融风控(Stacking)
- 结构:
Level 1: Logistic回归 + 随机森林 + XGBoost
Level 2: 神经网络元学习器 - 效果:AUC=0.92,比单模型提升8%
4.2 医学影像诊断(Boosting)
- 方案:AdaBoost + CNN特征提取器
- 数据:皮肤癌ISIC数据集
- 结果:恶性黑色素瘤识别率96.3%
4.3 推荐系统(Bagging)
- 场景:Netflix视频推荐
- 技术:随机森林 + 矩阵分解集成
- 指标:RMSE降低至0.85(Kaggle冠军方案)
5. 面试题
Q1:为什么集成学习能提升性能?
A:通过偏差-方差分解解释:
E [ ( y − f ^ ) 2 ] = Bias 2 ( f ^ ) + Var ( f ^ ) + σ 2 E[(y-\hat{f})^2] = \text{Bias}^2(\hat{f}) + \text{Var}(\hat{f}) + \sigma^2 E[(y−f^)2]=Bias2(f^)+Var(f^)+σ2
- Bagging主要降低方差
- Boosting主要降低偏差
- 二者都能减少不可约误差 σ 2 \sigma^2 σ2
Q2:如何处理基学习器相关性?
A:三种方法:
- 特征随机(随机森林)
- 数据扰动(Bagging)
- 算法扰动(不同学习器组合)
Q3:为什么GBDT比AdaBoost更流行?
| 维度 | GBDT | AdaBoost |
|---|---|---|
| 损失函数 | 自定义(Huber/Quantile) | 指数损失 |
| 数据兼容性 | 支持缺失值 | 需完整数据 |
| 特征重要性 | 内置计算 | 需额外实现 |
| 超参敏感性 | 较低 | 较高 |
6. 优缺点分析
优点:
- 精度提升:Netflix竞赛中集成方案比单模型误差低28%
- 鲁棒性强:对噪声数据和异常值不敏感
- 避免过拟合:Bagging类方法天然正则化
- 灵活扩展:支持异构学习器组合(如SVM+决策树)
缺点:
- 计算成本高:
- 训练时间: O ( T × t base ) O(T \times t_{\text{base}}) O(T×tbase)
- 存储空间: O ( T × s base ) O(T \times s_{\text{base}}) O(T×sbase)
- 可解释性差:比单模型更难解释(SHAP值可缓解)
- 实现复杂度:Stacking需多阶段训练
- 边际递减:性能随学习器数量增加而饱和
7. 数学证明:为什么集成有效
分类错误率分析(假设基学习器独立):
P ( 错误 ) = ∑ k = ⌊ T / 2 ⌋ + 1 T ( T k ) p k ( 1 − p ) T − k P(\text{错误}) = \sum_{k=\lfloor T/2 \rfloor+1}^T \binom{T}{k} p^k (1-p)^{T-k} P(错误)=k=⌊T/2⌋+1∑T(kT)pk(1−p)T−k
其中 p p p为单学习器错误率。当 p < 0.5 p<0.5 p<0.5时:
lim T → ∞ P ( 错误 ) = 0 \lim_{T \to \infty} P(\text{错误}) = 0 T→∞limP(错误)=0
实际案例:
- 当 p = 0.4 , T = 25 p=0.4, T=25 p=0.4,T=25时,集成错误率 < 0.01 <0.01 <0.01
- 当 p = 0.4 , T = 100 p=0.4, T=100 p=0.4,T=100时,集成错误率 ≈ 10 − 7 \approx 10^{-7} ≈10−7
💡 关键洞察:集成学习的本质是通过多样性降低风险:
- 数据多样性:Bagging的自助采样
- 特征多样性:随机森林的特征扰动
- 模型多样性:Stacking的异构学习器
实际应用建议:
- 首选方案:从随机森林/XGBoost开始(Scikit-Learn实现)
- 调参重点:控制基学习器数量与复杂度平衡
- 工业部署:使用ONNX加速集成模型推理
- 可解释性:结合SHAP/LIME解释集成决策
⚠️ 注意事项:当基学习器精度<50%时,集成效果可能变差(需筛选合格基学习器)