自然语言处理——循环神经网络
在前向神经网络中,由于相邻两层之间存在单向连接,每层的节点之间是无连接的(无循环),因此输入和输出的维数都是固定的,不能任意改变,而且也无法处理变长序列数据。
另外假设每次输入都是独立的,也就是说每次网络的输出只依赖于当前的输入。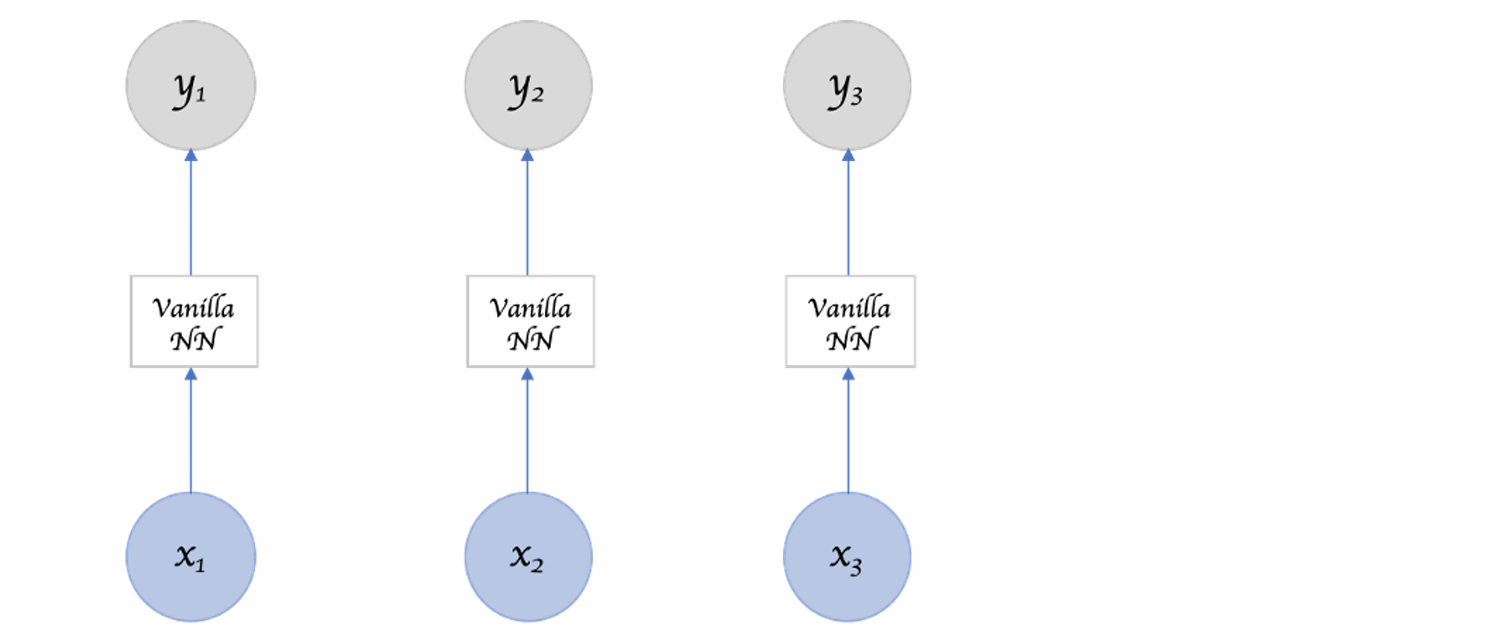
为了给网络增加记忆能力,我们提出了延时神经网络(Time Delay Neural Network,TDNN)建立一个额外的延时单元,用来存储网络的历史信息(可以包括输入、输出、隐状态等),这样,前馈网络就具有了短期记忆的能力。
h t ( l ) = f ( h t ( l − 1 ) , h t − 1 ( l − 1 ) , ⋯ , h t − K ( l − 1 ) ) \boldsymbol{h}_{t}^{(l)}=f\left(\boldsymbol{h}_{t}^{(l-1)}, \boldsymbol{h}_{t-1}^{(l-1)}, \cdots, \boldsymbol{h}_{t-K}^{(l-1)}\right) ht(l)=f(ht(l−1),ht−1(l−1),⋯,ht−K(l−1))
循环神经网络
通过使用带自反馈的神经元,能够处理任意长度的时序数据。

- 循环神经网络比前馈神经网络更加符合生物神经网络的结构。
- 循环神经网络已经被广泛应用在语音识别、语言模型以及自然语言生成等任务上
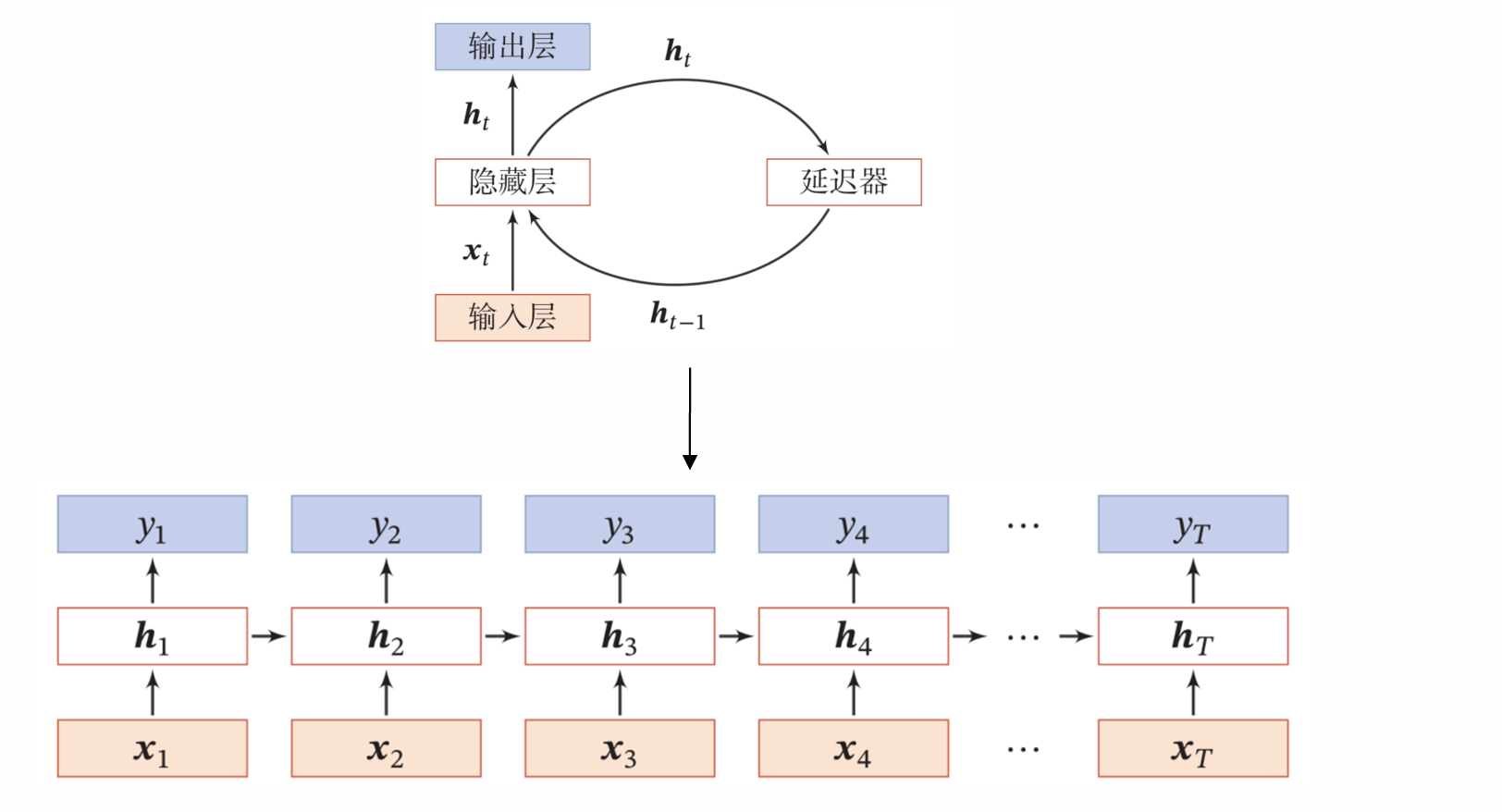
状态更新时:每一层的隐藏层依赖于当前时刻的输入和前一时刻的隐藏层表示 h t = f ( U h t − 1 + W x t + b ) \boldsymbol{h}_{t}=f\left(\boldsymbol{U} \boldsymbol{h}_{t-1}+\boldsymbol{W} \boldsymbol{x}_{\boldsymbol{t}}+\boldsymbol{b}\right) ht=f(Uht−1+Wxt+b)
应用到基于机器学习的自然语言处理任务
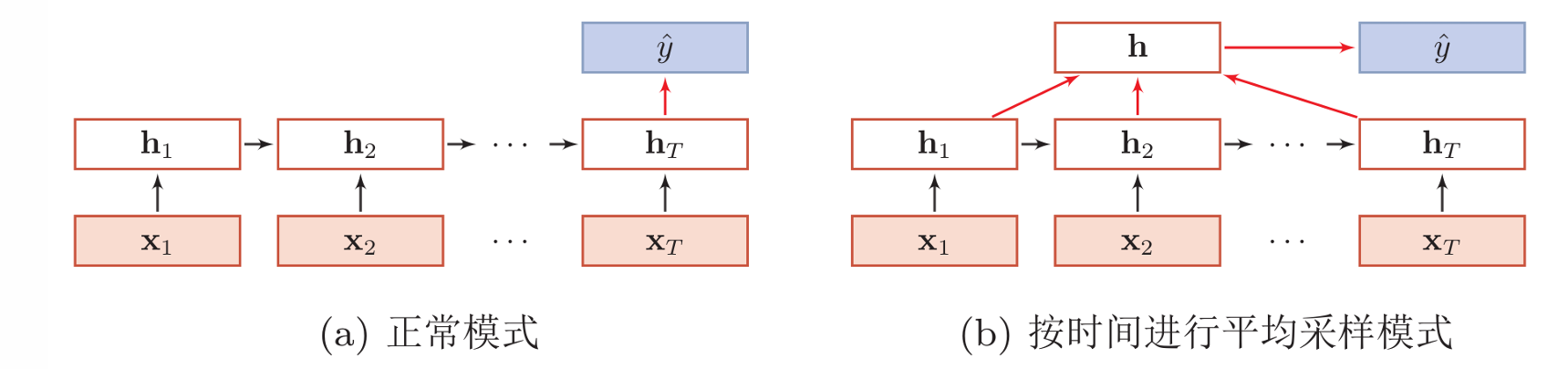
序列到类别
正常模式下最后一个隐藏层的表示作为输出(记住了前面全部的隐藏层信息)。
也可以进行AveragePooling,按照时间进行平均采样。
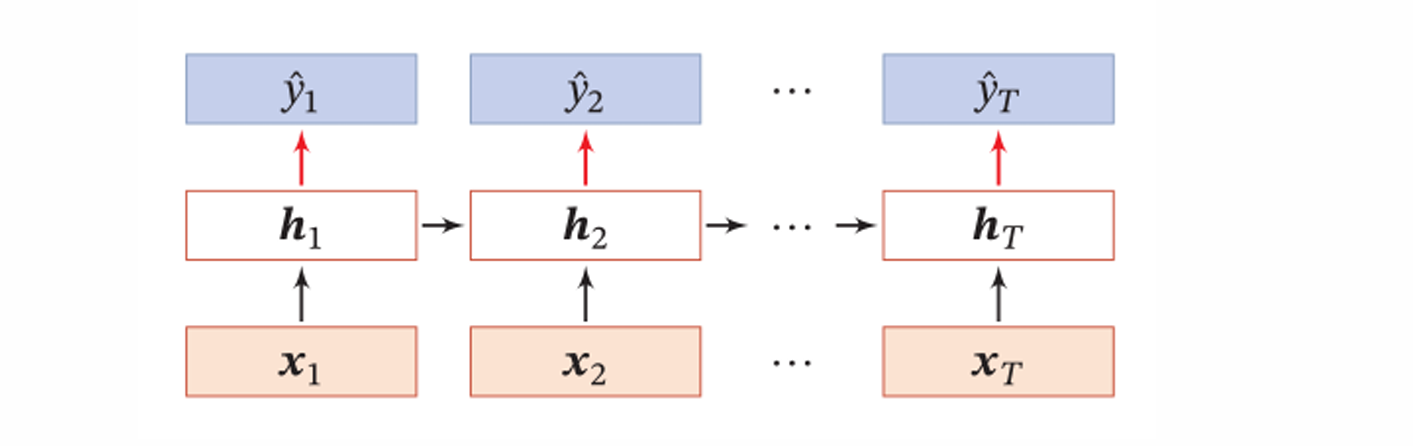
同步的序列到序列模式
中文分词就是用的就是如下图所示的模式
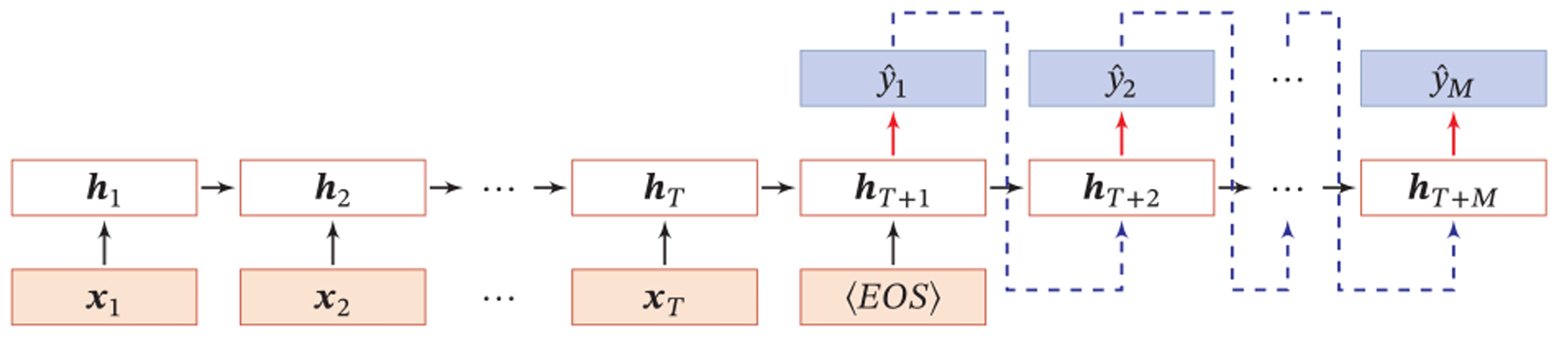
异步的序列到序列模式
先对输入句子进行隐藏层表示(Encoder)。之后预测句中第一个单词,再依次预测后面的隐藏层表示和y(Decoder),输入序列和输出序列的长度不一定一样。机器翻译就是这样子的一个典型例子。
参数学习和长程依赖问题
给定一个训练样本(𝒙,𝒚),其中 𝒙 = ( 𝒙 1 , ⋯ , 𝒙 𝑻 ) 𝒙=(𝒙_1,⋯,𝒙_𝑻) x=(x1,⋯,xT)为长度是T 的输入序列, 𝒚 = 𝒚 1 , ⋯ , 𝒚 𝑻 𝒚= 𝒚_1, ⋯,𝒚_𝑻 y=y1,⋯,yT 是长度为T 的标签序列。
时刻t的瞬时损失函数为 L t = L ( y t , g ( h t ) ) \mathcal{L}_{t}=\mathcal{L}\left(\boldsymbol{y}_{t}, g\left(\boldsymbol{h}_{t}\right)\right) Lt=L(yt,g(ht))
总损失函数为 L = ∑ t = 1 T L t \mathcal{L}=\sum_{t=1}^{T} \mathcal{L}_{t} L=∑t=1TLt
梯度:随时间反向传播算法
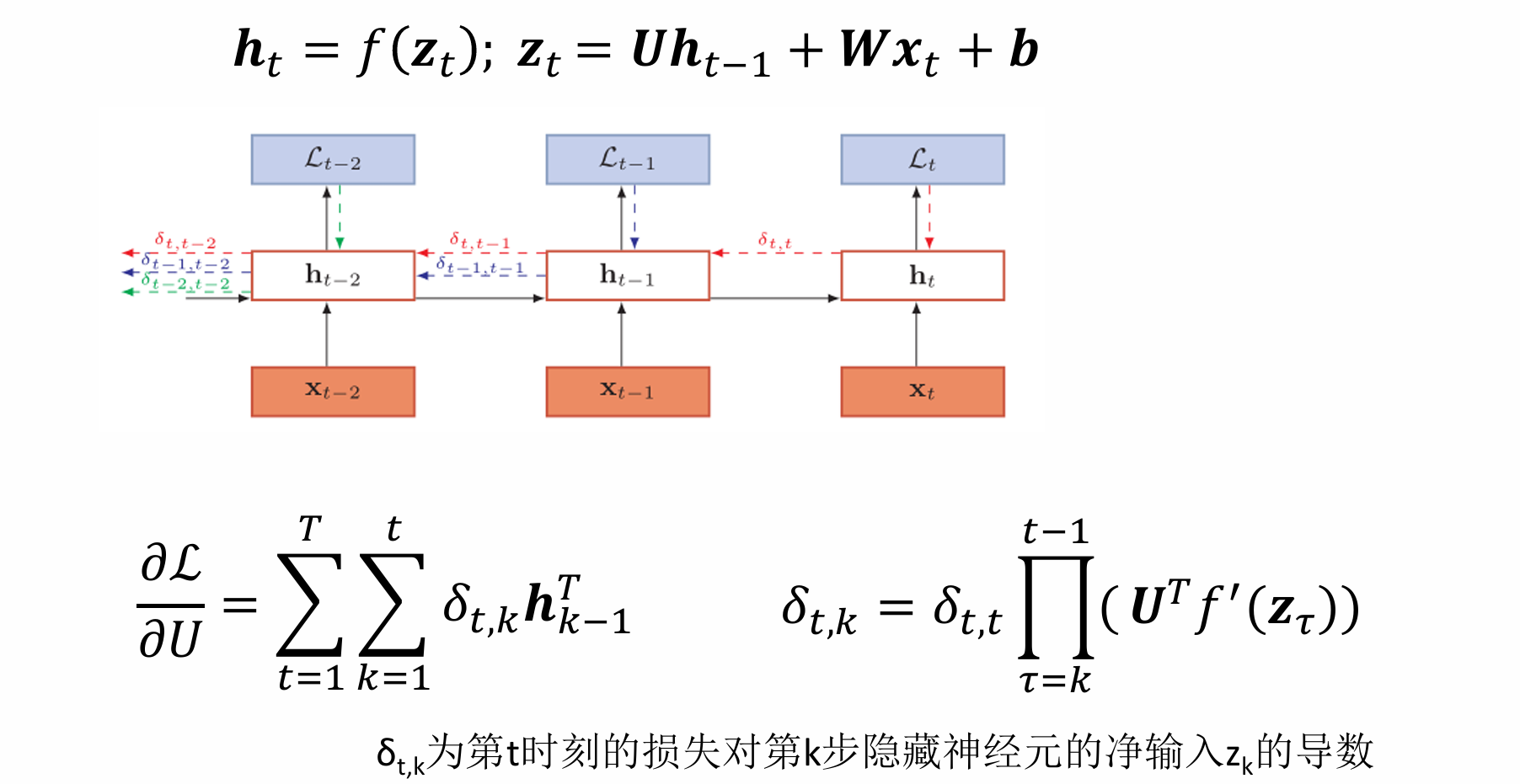
δ t , k = δ t , t ∏ τ = k t − 1 ( U T f ′ ( z τ ) ) γ ≅ δ t , t γ t − k \begin{aligned} \delta_{t, k} & =\delta_{t, t} \prod_{\tau=k}^{t-1} \frac{\left(\boldsymbol{U}^{T} f^{\prime}\left(\boldsymbol{z}_{\tau}\right)\right)}{\gamma} \\ & \cong \delta_{t, t} \gamma^{t-k}\end{aligned} δt,k=δt,tτ=k∏t−1γ(UTf′(zτ))≅δt,tγt−k
由于梯度爆炸或消失问题,实际上只能学习到短周期的依赖关系。这就是所谓的长程依赖问题(循环神经网络在时间维度上非常深)。
梯度爆炸问题
- 权重衰减
- 梯度截断
梯度消失问题
- 改进模型
改进方法:
- 循环边改为线性依赖关系
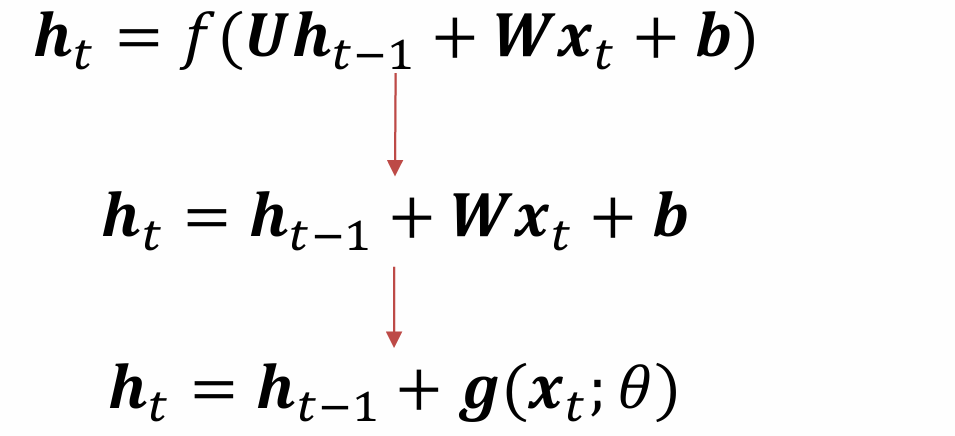
δ t , k = δ t , t ∏ τ = k t − 1 ( U T f ′ ( z τ ) γ ≅ δ t , t γ t − k \begin{aligned} \delta_{t, k} & =\delta_{t, t} \prod_{\tau=k}^{t-1} \frac{\left(\boldsymbol{U}^{T} f^{\prime}\left(\boldsymbol{z}_{\tau}\right)\right.}{\gamma} \\ & \cong \delta_{t, t} \boldsymbol{\gamma}^{t-k}\end{aligned} δt,k=δt,tτ=k∏t−1γ(UTf′(zτ)≅δt,tγt−k
将f去掉并将U变成单位阵,宗旨是为了让gamma=1 - 增加非线性
h t = h t − 1 + g ( x t , h t − 1 ; θ ) \boldsymbol{h}_{t}=\boldsymbol{h}_{t-1}+\boldsymbol{g}\left(\boldsymbol{x}_{t}, \boldsymbol{h}_{t-1} ; \theta\right) ht=ht−1+g(xt,ht−1;θ)
非线性激活函数不可以用RELU:会导致h爆炸,Sigmoid也不可以,没有负区间,同样会导致h爆炸,用tanh(-1,1)!
基于门控的循环神经网络
门控机制:控制信息的累积速度,包括有选择地加入新的信息,并有选择地遗忘之前历史累计的信息
门控循环单元(GRU)
更新门用于控制前一时刻的状态信息被带入到当前状态中的程度,也就是更新门帮助模型决定到底要将多少过去的信息传递到未来,简单来说就是用于更新记忆。
简单来说重置门就是构造一个输入(决定输入中有多少过去的成分);更新门就是决定构造的新输入有多少会传下去。
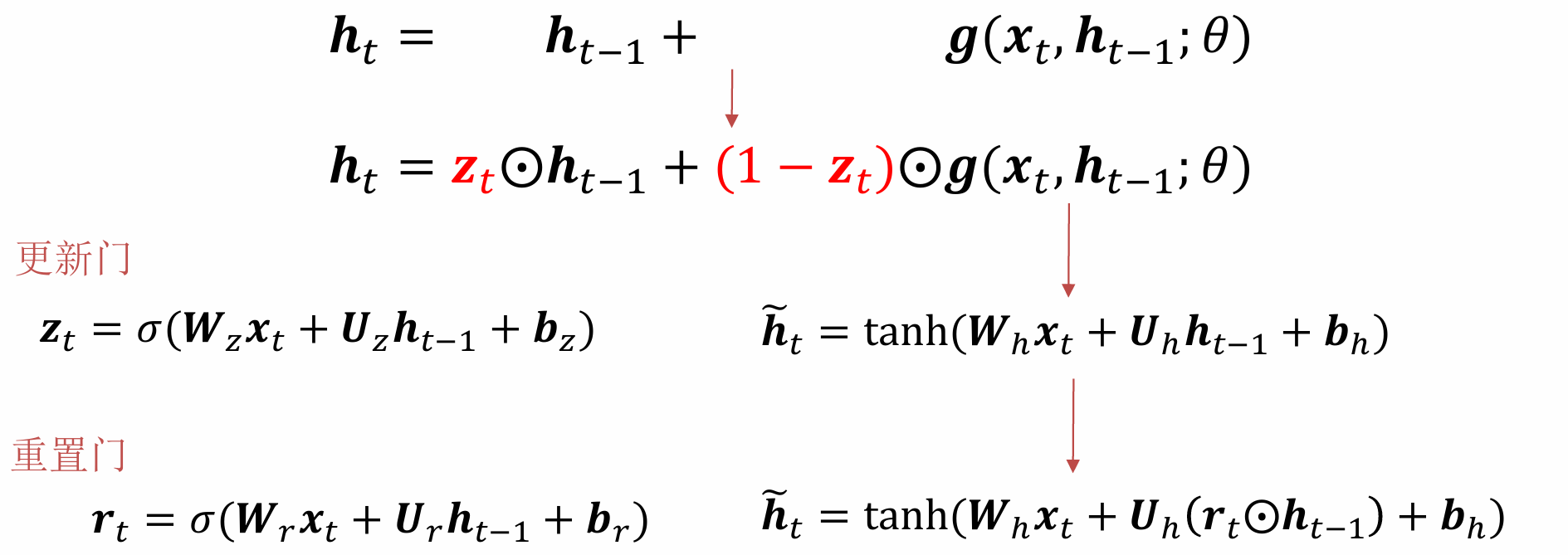
当rt的值接近0时,说明上一时刻的内容需要全部丢弃,只保留当前时刻的输入,所以可以用来丢弃与预测无关的历史信息。
当rt的值接近1时,表示保留上一时刻的隐藏状态。
重置门决定了如何将新的输入信息与前面的记忆相结合。
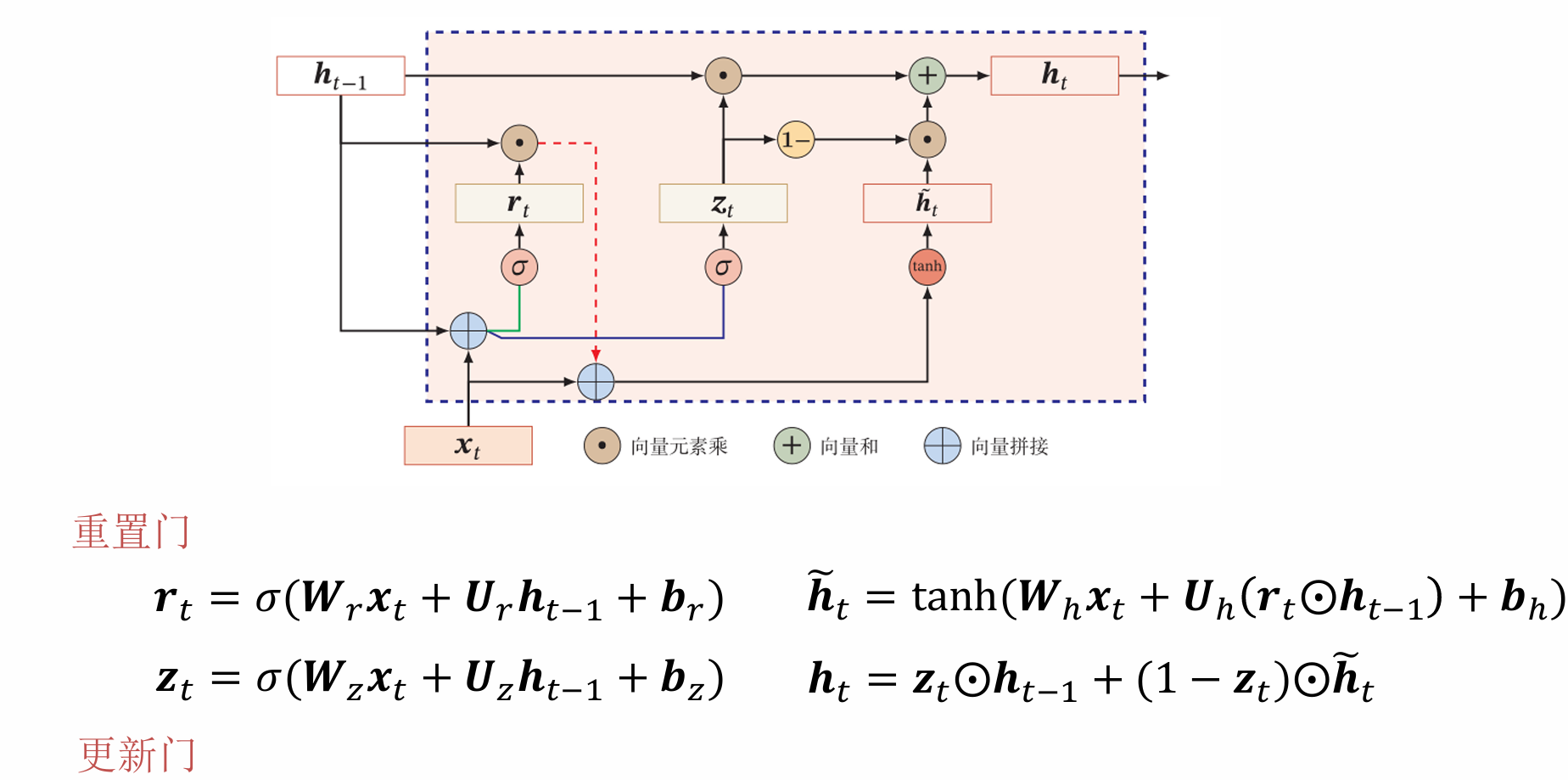
长短期记忆神经网络(LSTM)
LSTM(长短期记忆网络)是RNN的一种特殊类型,它通过引入“门”(输入门、遗忘门、输出门)来解决传统RNN在处理长序列时梯度消失或梯度爆炸的问题,从而有效捕捉长期依赖关系。这些门控机制像阀门一样控制着信息在“细胞状态”(Cell State)中的流动、添加和删除,允许重要信息在较长时间内保留,而无关信息则被过滤掉。
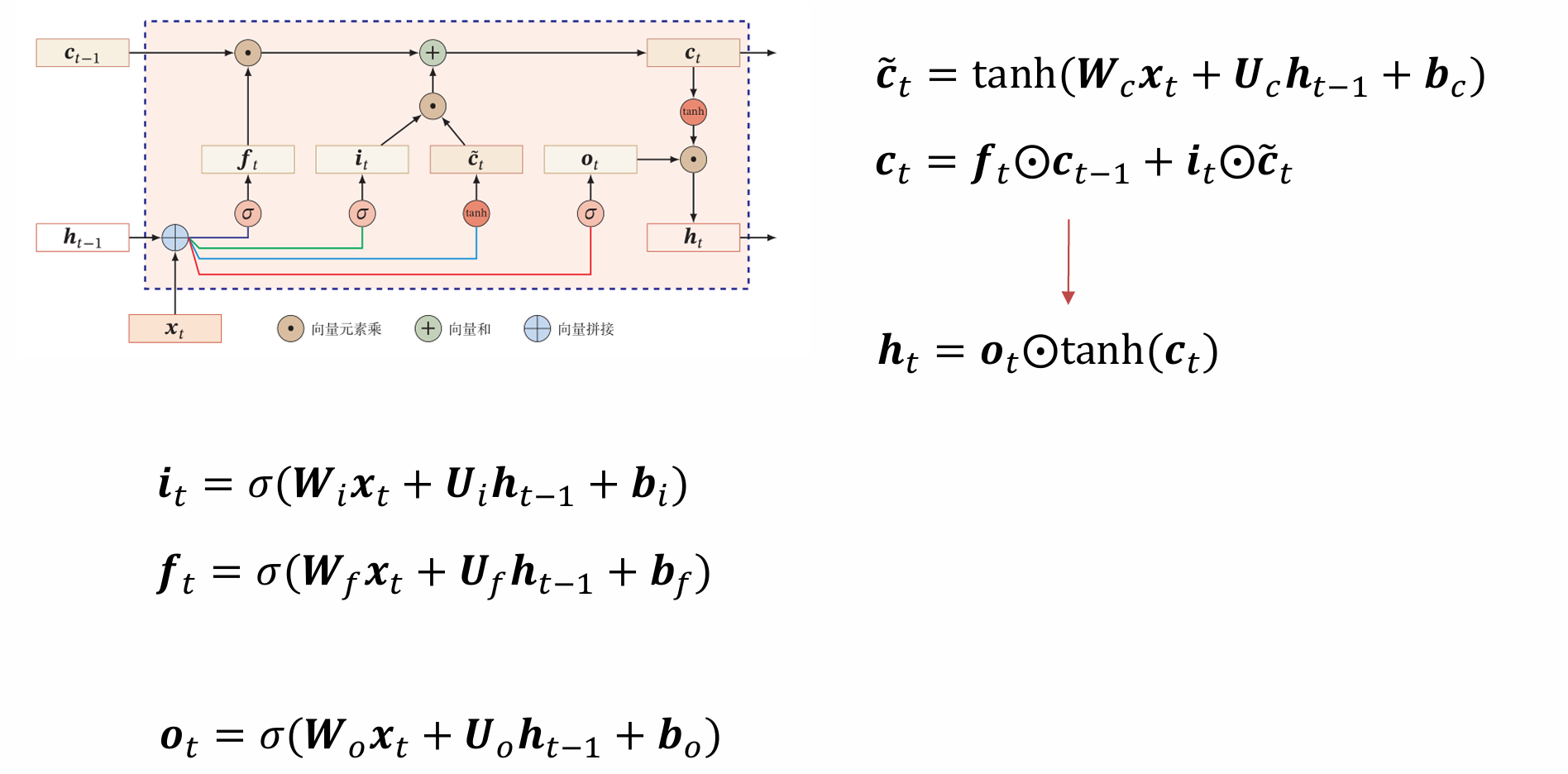
深度循环神经网络
堆叠循环神经网络
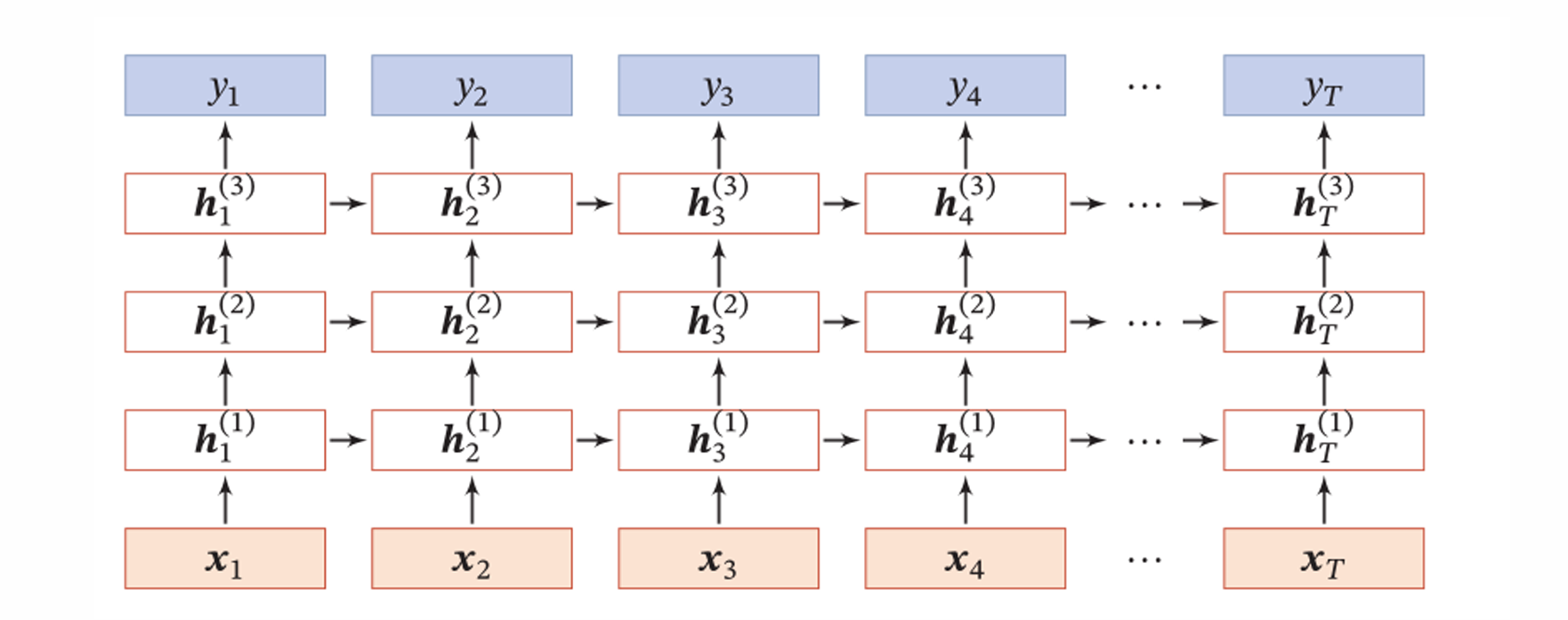
双向循环神经网络
递归神经网络
循环神经网络用于处理任意长度的时序数据,那么如何处理具有预定义结构的数据?我们需要参照程序语言的句法结构。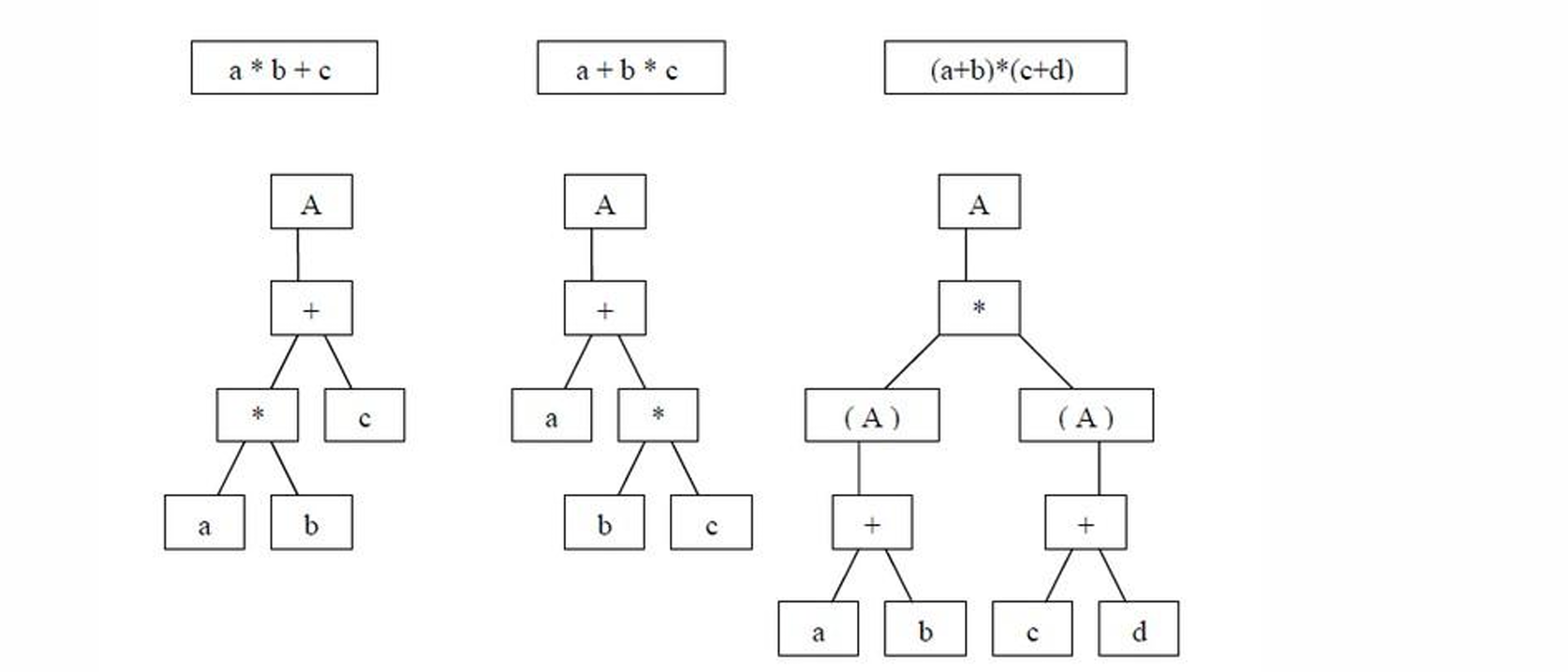
转变到自然语言的句法结构之后:
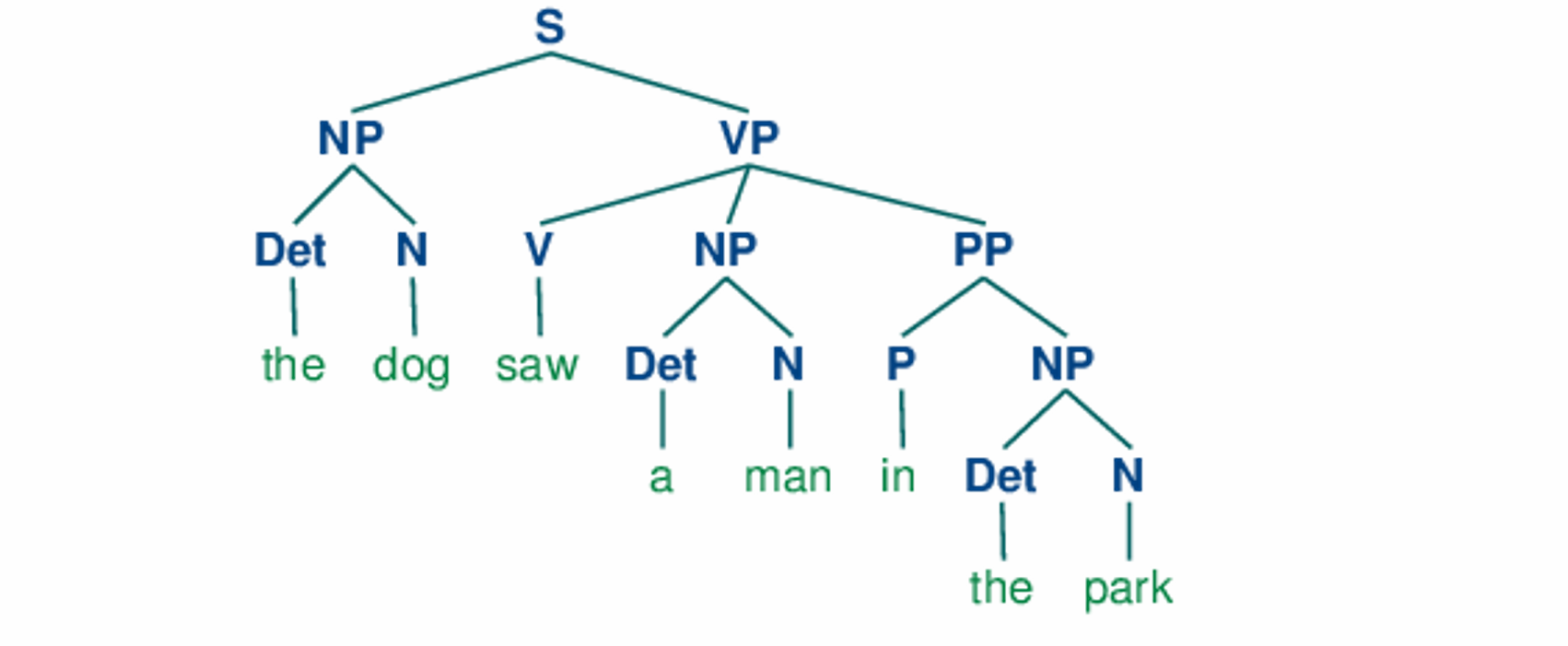
Richard Socher等人在2011年提出了递归神经网络
当然了递归神经网络也可能会退化为循环神经网络,当递归神经网络的树状结构退化为线性的链式结构时,它就退化(或者说等价于)为循环神经网络。
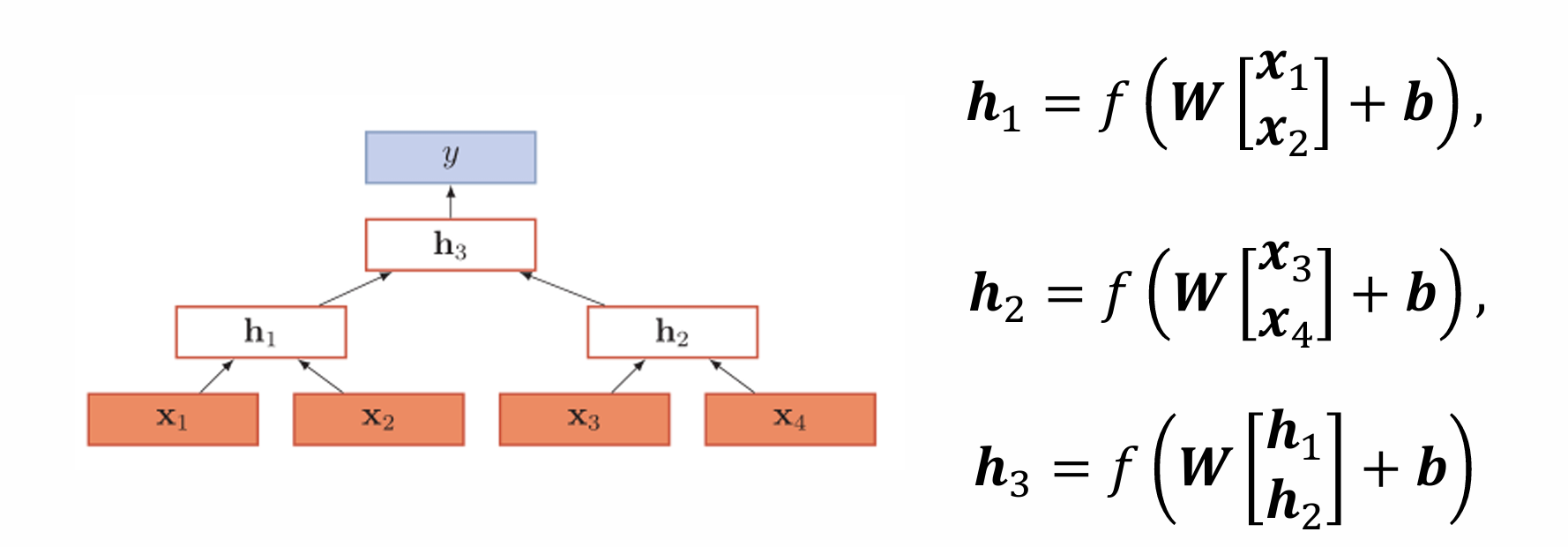
标准递归神经网络
所有的W都是共享的,无法区分叶结点的词性

Syntactically-Untied RvNN
不同的句法成分类别对应不同的聚合函数,把W改成不是全局共享的
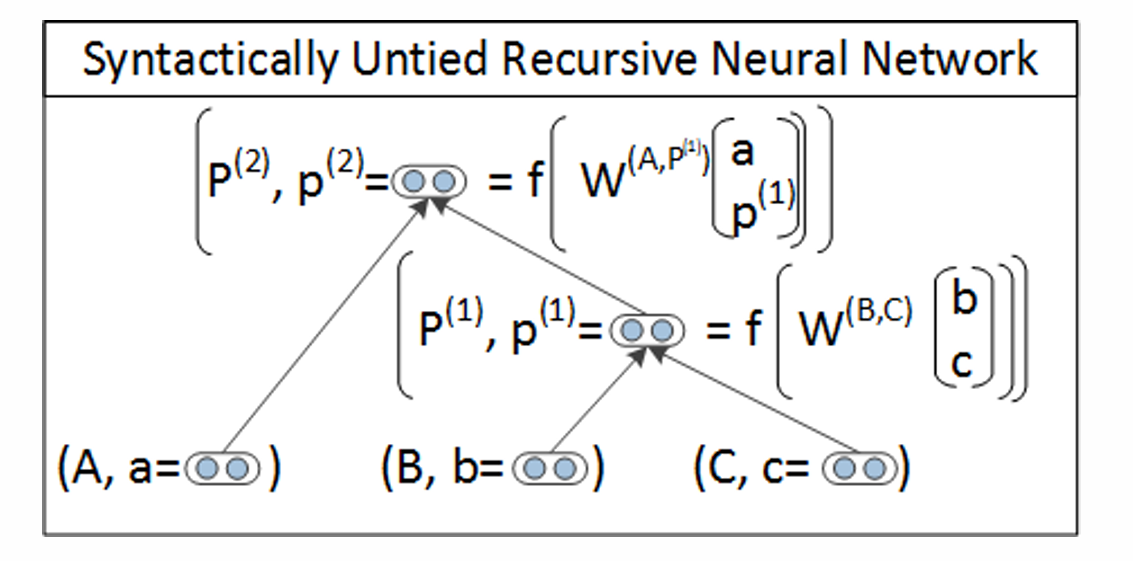
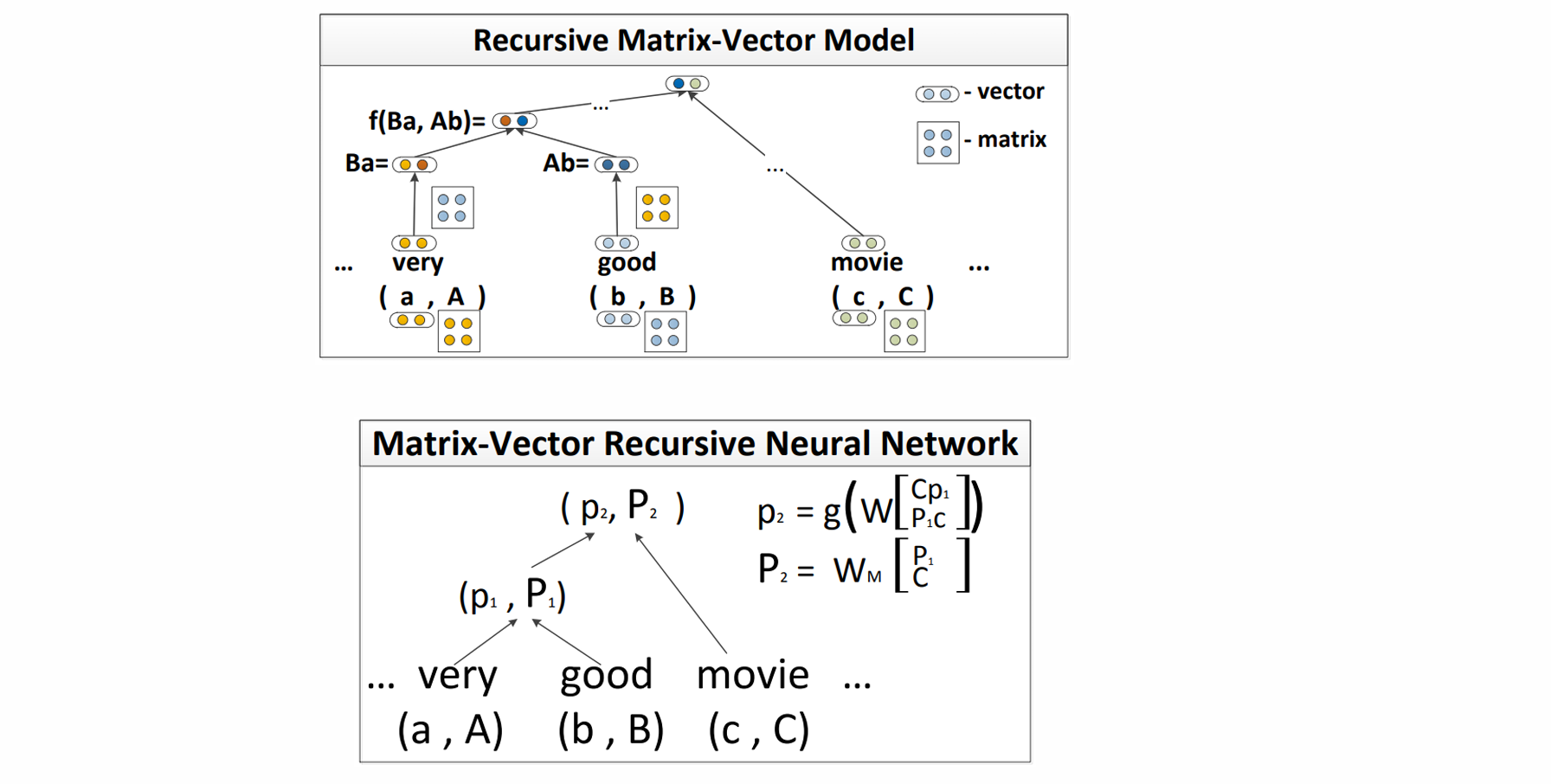
Matrix-Vector Recursive Neural Network
每个节点由一个向量和一个矩阵来共同表示,但是有一个缺点就是参数量过大。
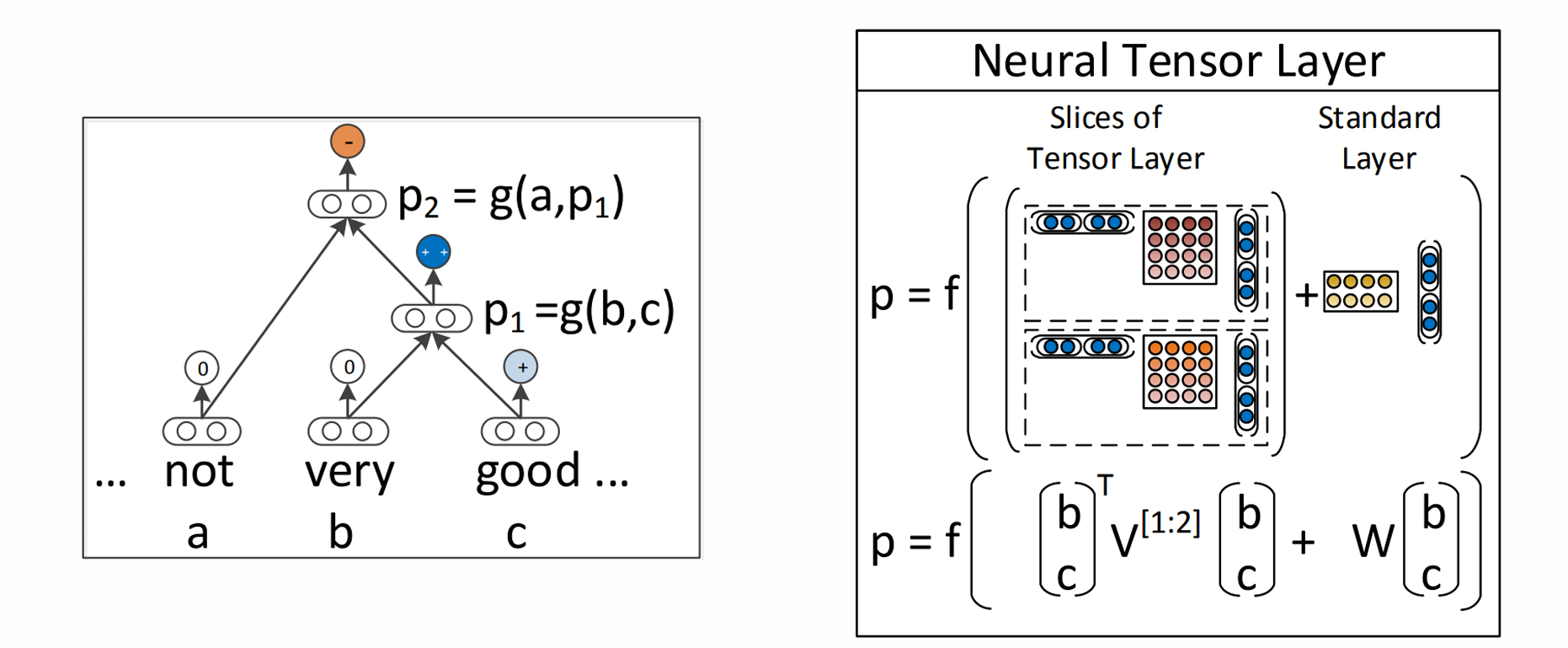
Recursive Neural Tensor Network
聚合时引入张量运算
注意力机制
人脑每个时刻接收的外界输入信息非常多,包括来源于视觉、听觉、触觉的各种各样的信息。但就视觉来说,眼睛每秒钟都会发送千万比特的信息给视觉神经系统。人脑通过注意力来解决信息超载问题。

注意力机制可以分为两步:
- 计算注意力分布 α \alpha α
α n = p ( z = n ∣ X , q ) = softmax ( s ( x n , q ) ) = exp ( s ( x n , q ) ) ∑ j = 1 N exp ( s ( x j , q ) ) \begin{aligned} \alpha_{n} & =p(z=n \mid \boldsymbol{X}, \boldsymbol{q}) \\ & =\operatorname{softmax}\left(s\left(\boldsymbol{x}_{n}, \boldsymbol{q}\right)\right) \\ & =\frac{\exp \left(s\left(\boldsymbol{x}_{n}, \boldsymbol{q}\right)\right)}{\sum_{j=1}^{N} \exp \left(s\left(\boldsymbol{x}_{j}, \boldsymbol{q}\right)\right)}\end{aligned} αn=p(z=n∣X,q)=softmax(s(xn,q))=∑j=1Nexp(s(xj,q))exp(s(xn,q))
s ( x n , q ) s(x_n,q) s(xn,q)是打分函数 - 根据 α \alpha α来计算输入信息的加权平均
att ( X , q ) = ∑ n = 1 N α n x n = E z ∼ p ( z ∣ X , q ) [ x z ] \begin{aligned} \operatorname{att}(\boldsymbol{X}, \boldsymbol{q}) & =\sum_{n=1}^{N} \alpha_{n} \boldsymbol{x}_{n} \\ & =\mathbb{E}_{z \sim p(z \mid \boldsymbol{X}, \boldsymbol{q})}\left[\boldsymbol{x}_{z}\right]\end{aligned} att(X,q)=n=1∑Nαnxn=Ez∼p(z∣X,q)[xz]
