目录
十、NPU 芯片选型对比 + 模型部署流程 + 嵌入式工程模板
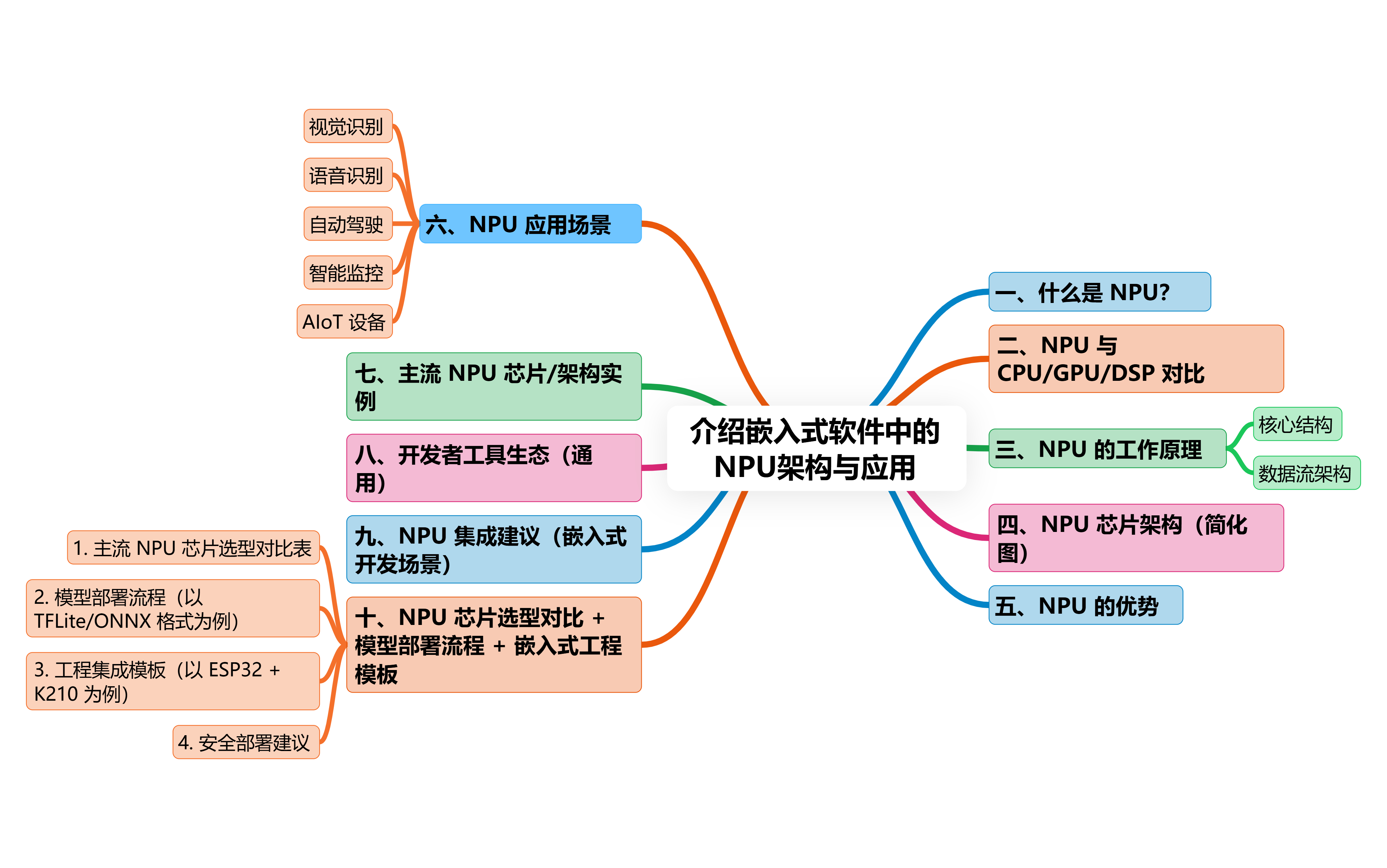
一、什么是 NPU?
NPU(Neural Processing Unit) 是专门用于人工神经网络推理与训练的处理器,具备高并行、低功耗、低延迟等特点。它是边缘 AI、自动驾驶、智能摄像头、语音识别等场景中的关键硬件。
二、NPU 与 CPU/GPU/DSP 对比
| 项目 | CPU | GPU | DSP | NPU |
| 设计目标 | 通用处理 | 图形/矩阵并行处理 | 信号处理 | 神经网络推理与训练 |
| 指令结构 | 顺序执行 | SIMD并行 | 定制指令 | 专用指令/硬件卷积引擎 |
| 并行能力 | 低 | 高(数千线程) | 中等 | 极高(面向神经元并行) |
| 能效比 | 普通 | 高功耗 | 中低 | 高性能 + 低功耗 |
| 适用场景 | 通用任务 | 图像渲染、AI训练 | 音频处理、滤波 | AI推理、图像识别、语音识别等 |
三、NPU 的工作原理
核心结构:
MAC 单元阵列:用于矩阵乘法(Multiply-Accumulate),神经网络的基本计算单元
权重缓存:高速 SRAM 缓存神经网络权重
激活函数单元:支持 ReLU、Sigmoid、Softmax 等
数据流引擎:优化读写路径,实现并行流水线
数据流架构:
采用数据驱动计算模型(Dataflow),按“张量”级别在芯片内流动,实现卷积、池化等操作的硬件加速。
四、NPU 芯片架构(简化图)
┌──────────────┐
│ 输入接口 │◀──── 图像、音频数据
└────┬─────────┘
▼
┌───────────────────────┐
│ NPU 主体结构(MAC阵列+激活+控制器) │
└────────┬──────────────┘
▼
┌──────────────┐
│ 权重缓存 │
└──────────────┘
▼
┌──────────────┐
│ 输出缓冲区 │───▶ 输出分类结果 / 特征图
└──────────────┘五、NPU 的优势
1.吞吐量高:比 CPU/GPU 更高效地完成推理任务
2.能效比高:适用于边缘设备(如摄像头、IoT终端)
3.专用优化指令集:支持 INT8、FP16 等低精度计算
4.定制性强:可结合 FPGA/SoC 嵌入式系统协同工作
5.低延迟响应:适合实时检测任务
六、NPU 应用场景
视觉识别
人脸识别、车牌识别、目标检测(如 YOLO、SSD、Mobilenet)
语音识别
本地离线语音命令识别(wake-word、ASR 模块)
自动驾驶
路况识别、避障策略、本地图像处理推理模块
智能监控
视频结构化分析(人形识别、动作检测、行为判断)
AIoT 设备
智能门锁、扫地机器人、智能门铃、安防摄像头等