| 大家好,我是工藤学编程 🦉 | 一个正在努力学习的小博主,期待你的关注 |
|---|---|
| 实战代码系列最新文章😉 | C++实现图书管理系统(Qt C++ GUI界面版) |
| SpringBoot实战系列🐷 | 【SpringBoot实战系列】SpringBoot3.X 整合 MinIO 存储原生方案 |
| 分库分表 | 分库分表之实战-sharding-JDBC分库分表执行流程原理剖析 |
【亲测宝藏】发现一个让 AI 学习秒变轻松的神站!不用啃高数、不用怕编程,高中生都能看懂的人工智能教程来啦!
👉点击跳转,和 thousands of 小伙伴一起用快乐学习法征服 AI,说不定下一个开发出爆款 AI 程序的就是你!
本文章目录
深入浅出RabbitMQ-核心概念介绍与容器化部署
在分布式系统中,服务间的通信往往面临三大挑战:耦合紧密(一个服务故障牵连全链路)、流量波动(峰值请求压垮下游)、同步阻塞(等待响应导致性能损耗)。而消息队列(MQ)作为“异步通信中间商”,完美解决了这些问题——其中RabbitMQ凭借其灵活的路由机制、丰富的功能特性,成为众多开发者的首选。
一、初识RabbitMQ
RabbitMQ是一款开源的AMQP(高级消息队列协议)实现,服务器端基于Erlang语言开发(天生支持高并发和分布式),客户端支持Python、Java、.NET、Go等几乎所有主流编程语言。它的核心优势在于:
- 灵活路由:通过多种交换器类型实现复杂消息分发;
- 隔离性强:支持虚拟主机(Virtual Host)实现多业务隔离;
- 高可用:支持集群、镜像队列,保障消息不丢失;
- 易整合:与Spring AMQP无缝对接,API简洁易用。
官网:http://www.rabbitmq.com/
入门教程:RabbitMQ官方教程
二、RabbitMQ核心组件:一张图看懂“消息流转的密码”
要掌握RabbitMQ,首先得理清它的“零件”。我们可以把RabbitMQ想象成一个“邮局系统”:生产者是寄件人,消费者是收件人,RabbitMQ则是邮局,负责消息的存储、路由和投递。以下是核心组件的详细解析:
1. 基础通信层:连接与信道
Connection(连接)
生产者/消费者与RabbitMQ服务器之间的TCP连接。建立TCP连接的开销较大(三次握手、认证等),因此通常不会频繁创建销毁。Channel(信道)
复用TCP连接的“虚拟通道”,所有消息操作(发送、接收)都通过信道完成。
✅ 为什么需要信道?
若每个操作都新建TCP连接,会导致服务器连接数暴增(比如1000个消费者各占一个连接),而信道通过“多路复用”共享一个TCP连接,大幅降低资源消耗。
2. 消息存储与路由层:从交换器到队列
Message(消息)
通信的载体,包含消息头(属性,如RoutingKey、优先级、过期时间)和消息体(业务数据,如JSON字符串)。Exchange(交换器)
消息的“第一站”,负责接收生产者的消息并按规则路由到队列。核心是路由规则,由交换器类型决定:- Direct(直连):精确匹配——RoutingKey与BindingKey完全一致才路由(如“order.create”→“order.create”)。
场景:单队列定向投递(如订单创建消息只给订单处理队列)。 - Topic(主题):模糊匹配——支持通配符“”(匹配一个单词)和“#”(匹配多个单词),如RoutingKey为“order.pay”可匹配BindingKey为“order.”或“#.pay”。
场景:多队列按规则订阅(如“order.”接收所有订单相关消息,“.pay”接收所有支付相关消息)。 - Fanout(广播):无视RoutingKey,将消息路由到所有绑定的队列。
场景:群发通知(如商品上架后,库存、搜索、推荐系统同时接收消息)。 - Headers(头匹配):通过消息头属性(而非RoutingKey)匹配,较少使用。
- Direct(直连):精确匹配——RoutingKey与BindingKey完全一致才路由(如“order.create”→“order.create”)。
RoutingKey(路由键)
生产者发送消息时指定的“路由标识”,长度≤255字节,配合交换器类型决定消息去向。Binding(绑定)
交换器与队列的“桥梁”,绑定需指定BindingKey(绑定键),用于与RoutingKey匹配。
✅ 关键逻辑:交换器通过“RoutingKey vs BindingKey”的匹配关系,决定消息是否路由到队列。Queue(队列)
消息的“仓库”,是RabbitMQ的内部对象,具有以下特性:- 先进先出(FIFO);
- 持久化(可选,避免重启丢失);
- 可被多个消费者监听,但一条消息只会被一个消费者处理(避免重复消费)。
3. 隔离与管理:虚拟主机
- Virtual Host(虚拟主机)
相当于RabbitMQ中的“命名空间”,用于隔离不同业务或环境(如/dev、/test、/prod)。
特性:- 每个虚拟主机有独立的Exchange、Queue和权限控制;
- 默认虚拟主机为“/”,生产环境建议按业务拆分(如“order-service”“user-service”)。
三、RabbitMQ工作流程
用一个“用户注册”场景举例,完整流程如下:
// 1. 建立连接(通过连接工厂)
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("rabbitmq-host");
factory.setUsername("admin");
factory.setPassword("password");
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
// 2. 声明交换器(类型为Topic,持久化)
channel.exchangeDeclare(
"user.exchange", // 交换器名称
"topic", // 类型
true // 是否持久化
);
// 3. 声明队列(邮件队列,持久化)
channel.queueDeclare(
"email.queue", // 队列名称
true, // 是否持久化
false, // 非排他(多消费者可共享)
false, // 不自动删除
null // 额外参数
);
// 4. 绑定交换器与队列(BindingKey为"user.#",匹配所有user开头的路由键)
channel.queueBind(
"email.queue", // 队列名称
"user.exchange", // 交换器名称
"user.#" // 绑定键
);
- 生产者(用户服务) 生成“用户注册成功”消息,指定:
- RoutingKey = “user.register”
- 发送到Exchange = “user.exchange”(类型为Topic)。
// 发送"用户注册成功"消息
String message = "{\"userId\":1001, \"username\":\"test\"}"; // 消息体
channel.basicPublish(
"user.exchange", // 目标交换器
"user.register", // 路由键(匹配"user.#")
MessageProperties.PERSISTENT_TEXT_PLAIN, // 持久化消息
message.getBytes()
);
System.out.println("已发送消息:" + message);
- Exchange 根据类型和绑定规则(假设Queue“email.queue”绑定BindingKey = “user.#”),将消息路由到“email.queue”。
// 发送"用户注册成功"消息
String message = "{\"userId\":1001, \"username\":\"test\"}"; // 消息体
channel.basicPublish(
"user.exchange", // 目标交换器
"user.register", // 路由键(匹配"user.#")
MessageProperties.PERSISTENT_TEXT_PLAIN, // 持久化消息
message.getBytes()
);
System.out.println("已发送消息:" + message);
- 消费者(邮件服务) 通过Channel监听“email.queue”,获取消息后发送欢迎邮件。
// 监听队列,自动确认消息(生产环境建议手动确认)
channel.basicConsume(
"email.queue", // 监听的队列
true, // 自动确认(消息处理后通知MQ删除)
(consumerTag, delivery) -> {
String msg = new String(delivery.getBody());
System.out.println("收到消息,发送邮件:" + msg);
// 业务逻辑:调用邮件API发送欢迎邮件
},
consumerTag -> {} // 取消消费的回调
);
四、为什么选择RabbitMQ?典型应用场景
异步解耦
例:用户下单后,订单系统无需等待库存、支付、物流系统同步处理,只需发送“订单创建”消息到RabbitMQ,其他系统异步消费,降低服务耦合。流量削峰
例:秒杀活动中,瞬间涌入10万请求,RabbitMQ可缓存消息,下游系统按每秒1万的速度消费,避免被压垮。可靠通信
支持消息持久化、确认机制(生产者确认消息已送达,消费者确认消息已处理),确保消息不丢失。
五、docker容器化部署
- 部署:
#拉取镜像
docker pull rabbitmq:management
docker run -d --hostname rabbit_host1 --name ccc_rabbit -e RABBITMQ_DEFAULT_USER=admin -e RABBITMQ_DEFAULT_PASS=password -p 15672:15672 -p 5672:5672 rabbitmq:management
#介绍
-d 以守护进程⽅式在后台运⾏
-p 15672:15672 management 界⾯管理访问端⼝
-p 5672:5672 amqp 访问端⼝
–name:指定容器名
–hostname:设定容器的主机名,它会被写到容器内的 /etc/hostname 和 /etc/hosts,作为容器主机IP的别名,并且将显示在容器的bash中
-e 参数
RABBITMQ_DEFAULT_USER ⽤户名
RABBITMQ_DEFAULT_PASS 密码
通过docker logs查看启动日志
- 访问管理界面:
访问自己的ip:15672
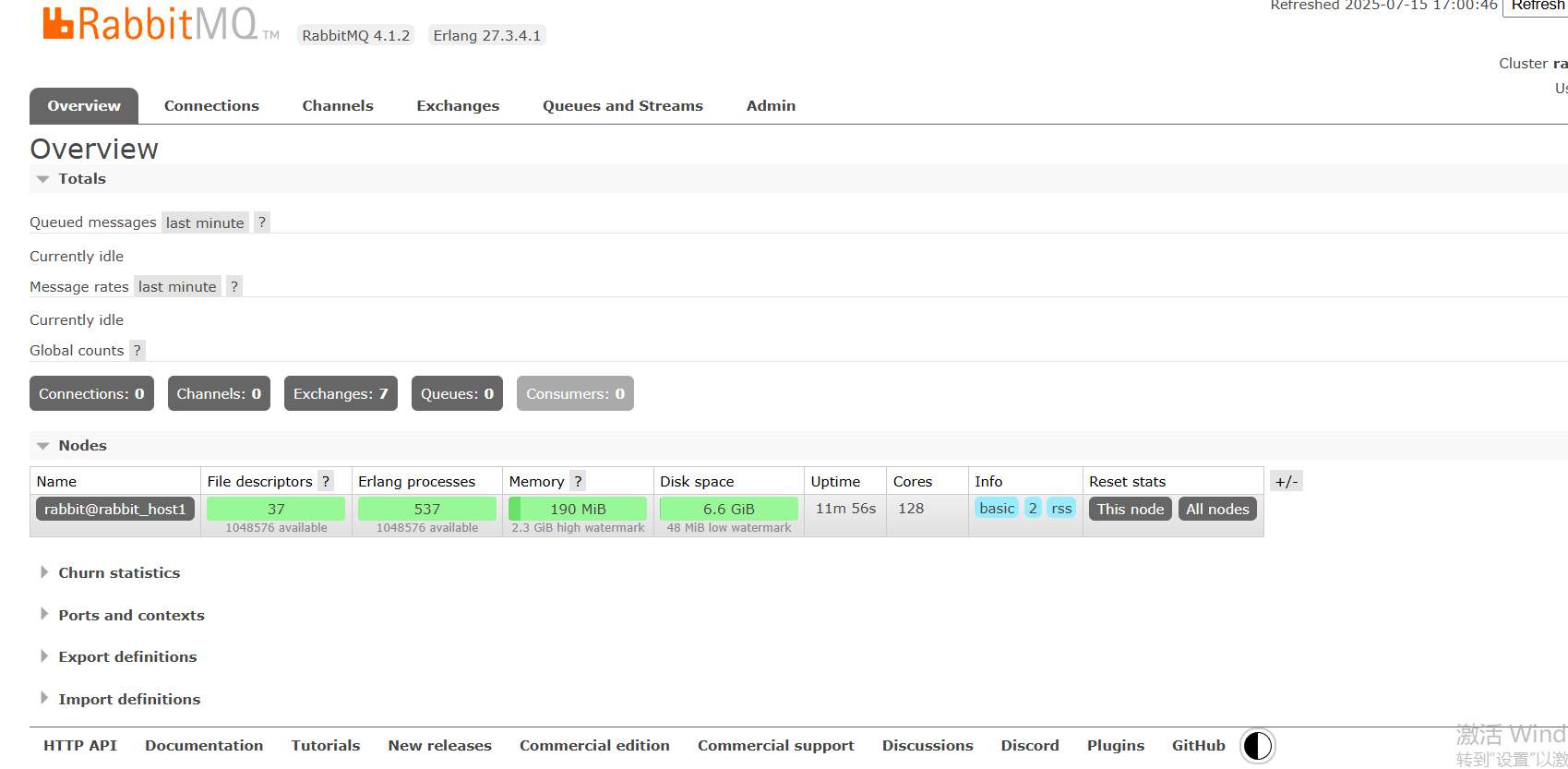
输入我们前面的用户名和密码,成功进入管理界面
六、总结
RabbitMQ凭借灵活的路由机制、强大的隔离性和丰富的功能,成为分布式系统中消息通信的首选工具。掌握核心概念(Exchange类型、信道、虚拟主机)和工作流程,能帮助我们更好地设计异步通信架构,解决服务耦合、流量波动等问题。
后续将深入讲解RabbitMQ的高级特性(持久化、确认机制、死信队列),敬请关注!
觉得有用请点赞收藏!
如果有相关问题,欢迎评论区留言讨论~