如果你是数据分析的初学者,那么本文将带你实战体验数据分析案例,本文是基于某综合型电商平台及其线下门店的3900条购物交易数据,我将会从用户画像、商品偏好、季节性趋势、地区分布等多个维度进行数据分析,掌握数据分析基本可视化方法!
数据背景介绍
数据的来源是一家综合型电商平台以及其线下门店的交易记录,是比较真实的数据很有参考价值,同时数据集一共包含了15个关键属性,特征也足够多,这里我贴出数据来源地址
数据来源地址:https://www.heywhale.com/mw/dataset/684d56eb84f1ba451bfcd699
数据分析实战
数据加载与预处理
数据分析一开始除了导入必要的依赖,就是数据处理阶段最为重要,我这里主要是去除金额字段中的空格、检查缺失值和日期格式转换
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import matplotlib
matplotlib.use('TkAgg')
df = pd.read_csv('shopping_trends.csv')
print(df.head())
print(df.info())
df['Purchase Amount '] = df['Purchase Amount '].str.strip().astype(float)
df['Date'] = pd.to_datetime(df['Date'], format='%Y/%m/%d')
print(df.isnull().sum())
用户画像分析
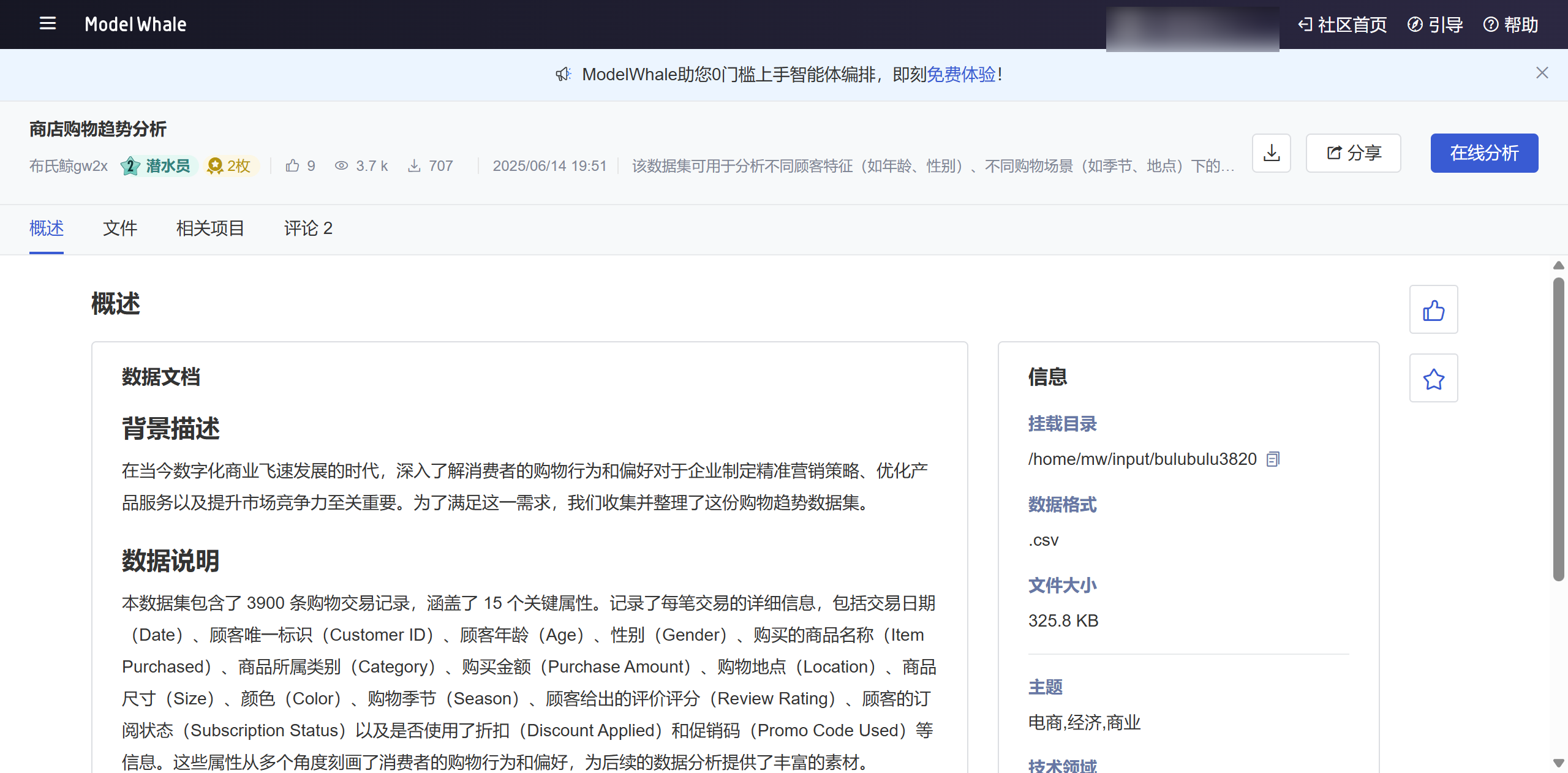
年龄分布
作为实战部分,我将通过直方图分析顾客的年龄分布
plt.figure(figsize=(8,4))
sns.histplot(df['Age'], bins=20, kde=True, color='skyblue')
plt.title('顾客年龄分布')
plt.xlabel('年龄')
plt.ylabel('人数')
plt.show()
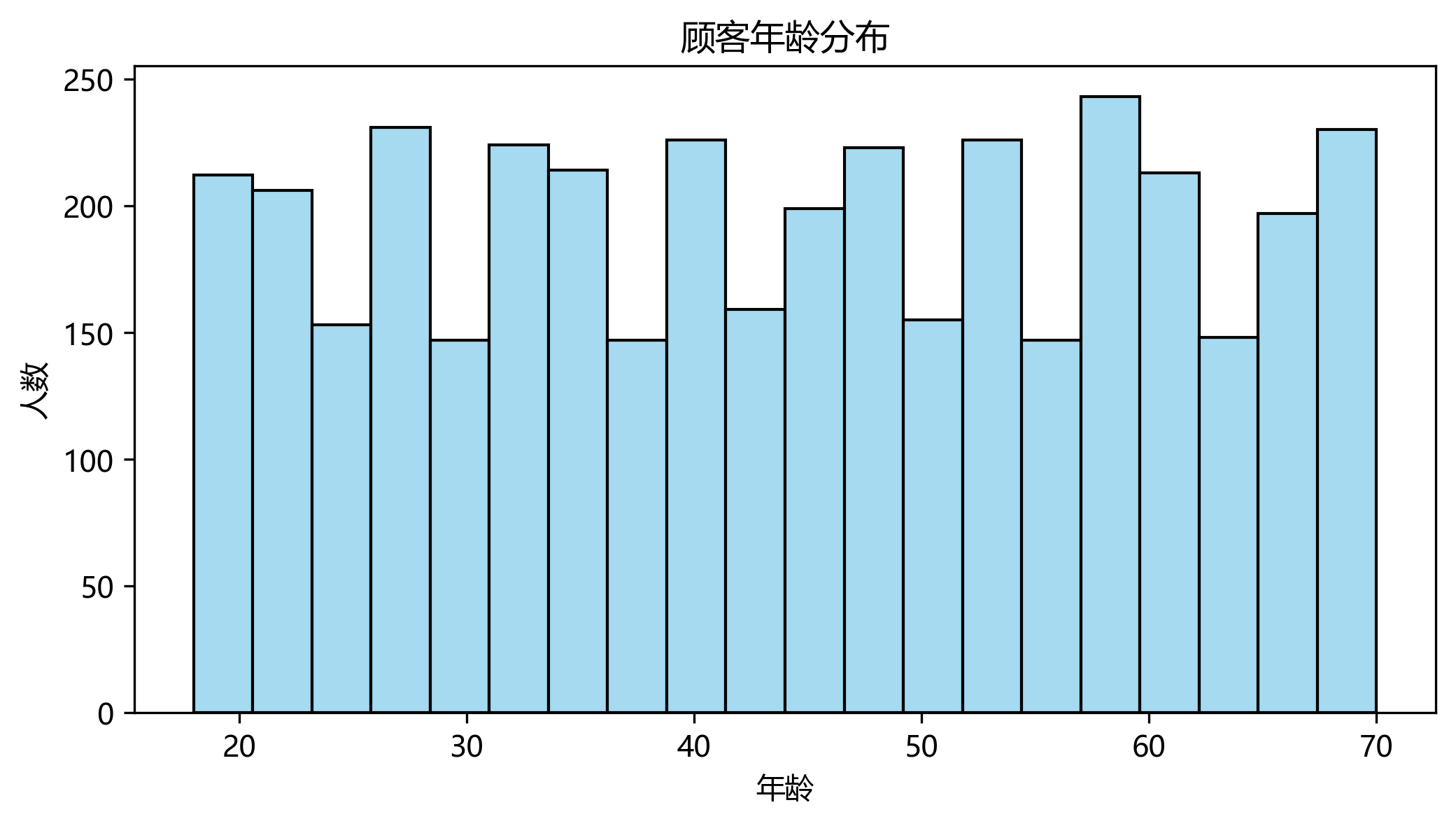
性别分布
性别分布则显示本数据集中顾客均为男性,说明数据采集或平台定位偏向男性用户,这也是通过可视化得到的
sns.countplot(x='Gender', data=df, palette='Set2')
plt.title('顾客性别分布')
plt.show()
商品偏好分析
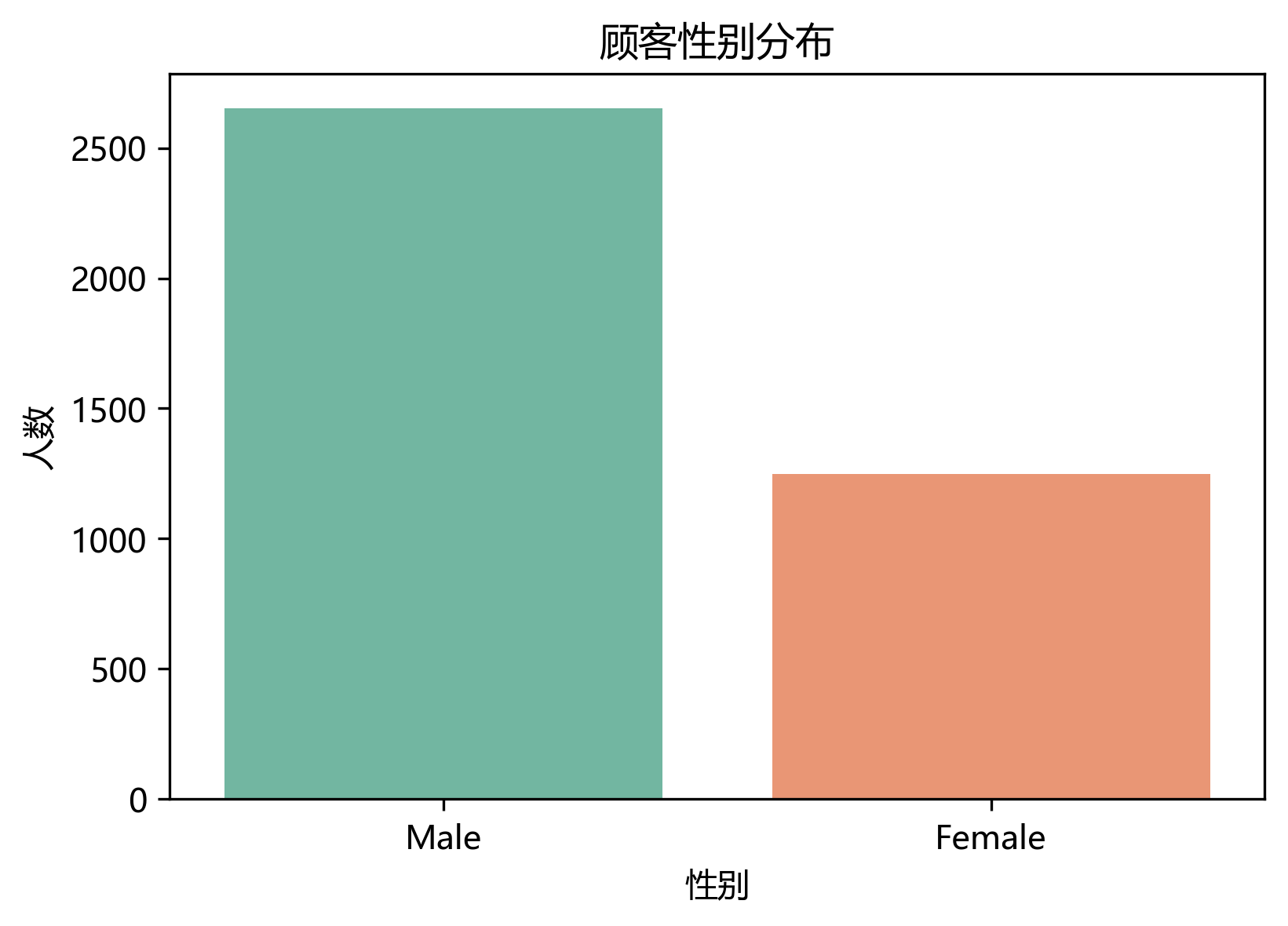
商品类别分布
从商品偏好的角度分析商品类别分布,发现服装和配饰为最受欢迎的商品类别,也就是绿色和黄色的柱状图
plt.figure(figsize=(10,4))
sns.countplot(x='Category', data=df, order=df['Category'].value_counts().index, palette='Set3')
plt.title('商品类别分布')
plt.xlabel('类别')
plt.ylabel('购买次数')
plt.show()
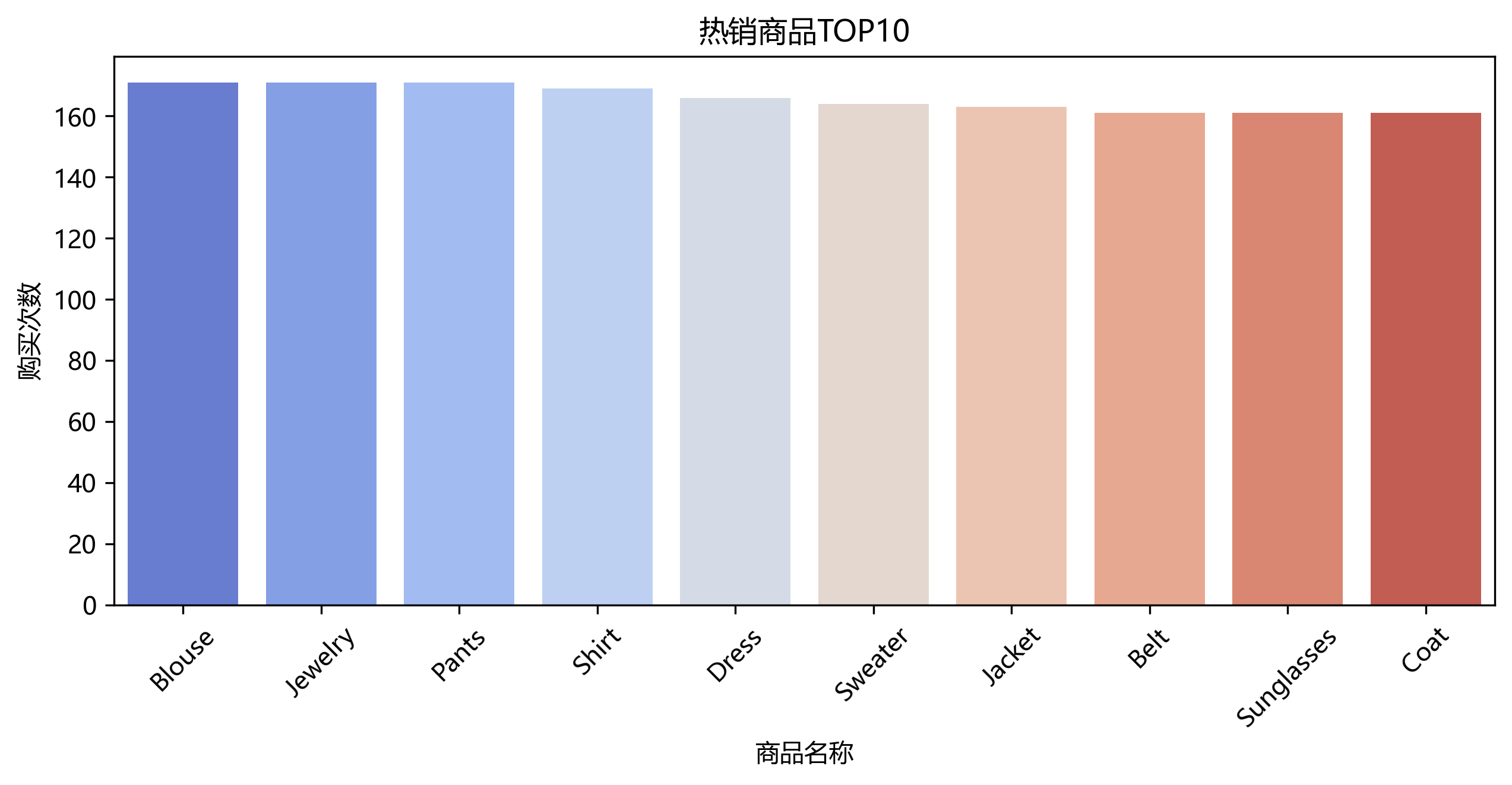
热销商品TOP10
条形图展示热销商品的前十名
top_items = df['Item Purchased'].value_counts().head(10)
top_items.plot(kind='bar', color='coral')
plt.title('热销商品TOP10')
plt.ylabel('购买次数')
plt.show()
季节性与地区趋势
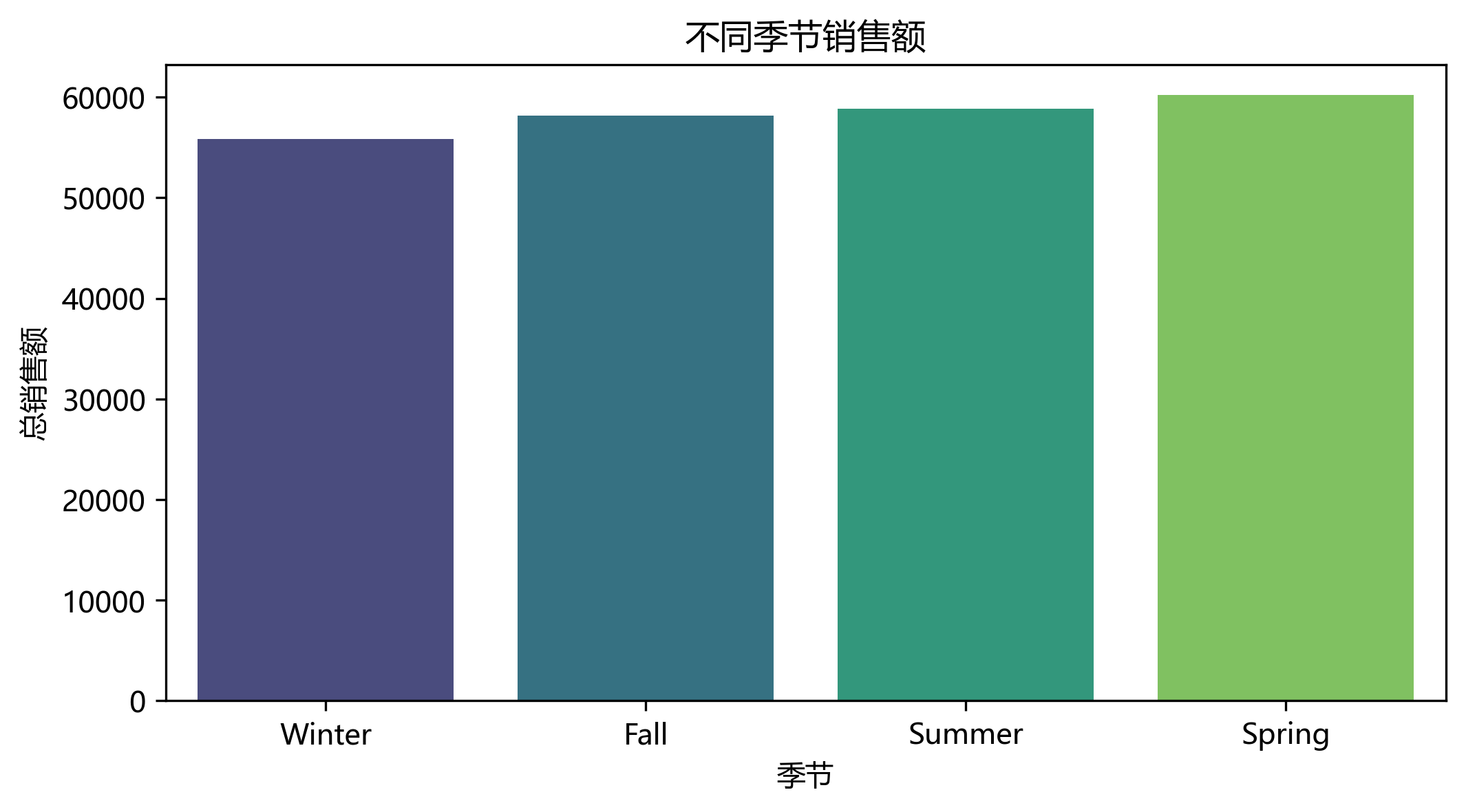
不同季节的销售额
分析不同季节的销售额,这对于企业来讲尤为重要,可以在这两个季节加大促销力度,提高整体收入
season_sales = df.groupby('Season')['Purchase Amount '].sum().sort_values()
season_sales.plot(kind='bar', color='teal')
plt.title('不同季节销售额')
plt.ylabel('总销售额')
plt.show()
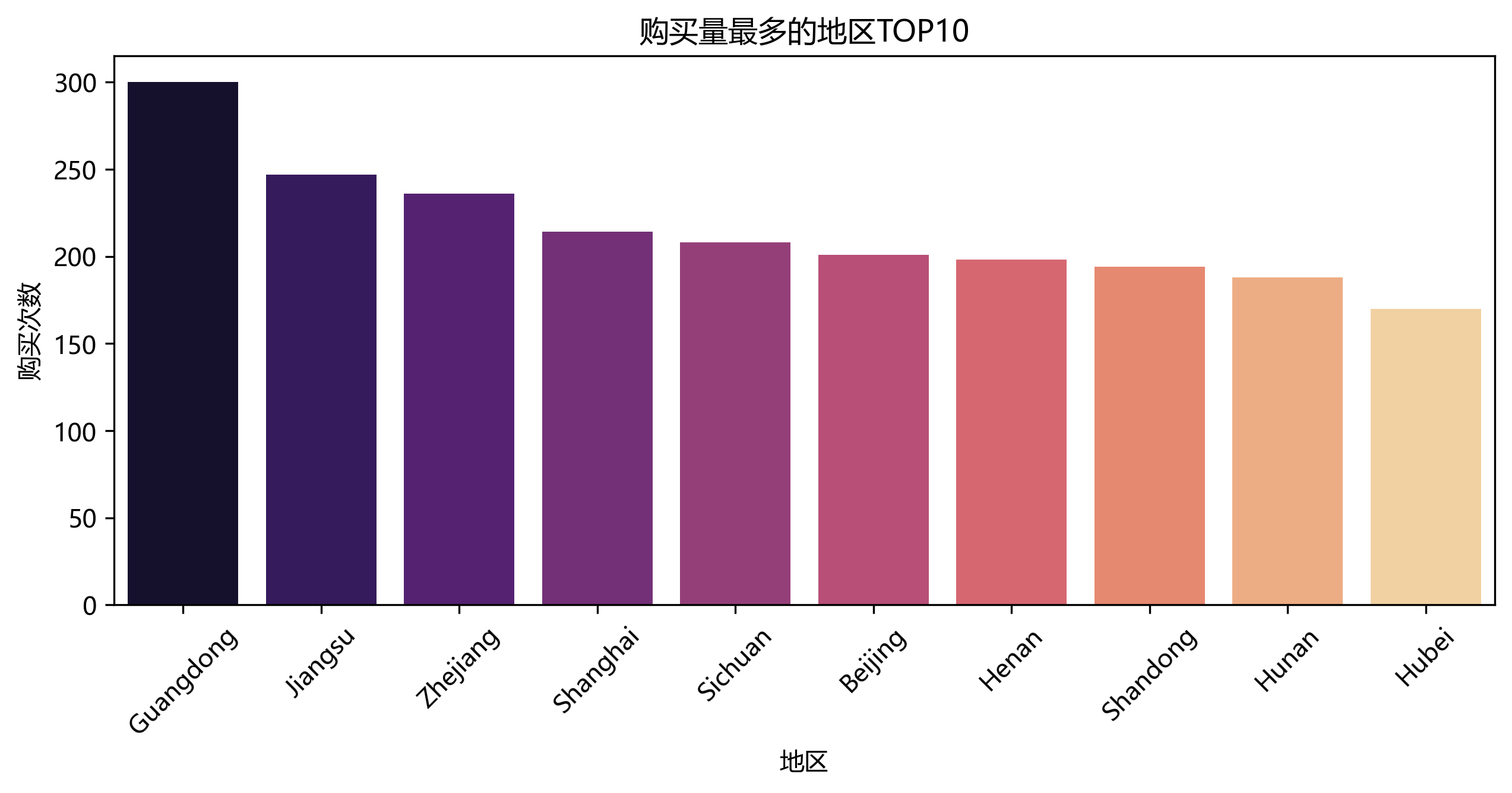
地区分布
条形图展示购买量最多的地区前十名,发现广东,江苏,浙江是前三购买量多的地区
top_locations = df['Location'].value_counts().head(10)
top_locations.plot(kind='bar', color='slateblue')
plt.title('购买量最多的地区TOP10')
plt.ylabel('购买次数')
plt.show()
价格与评价分析
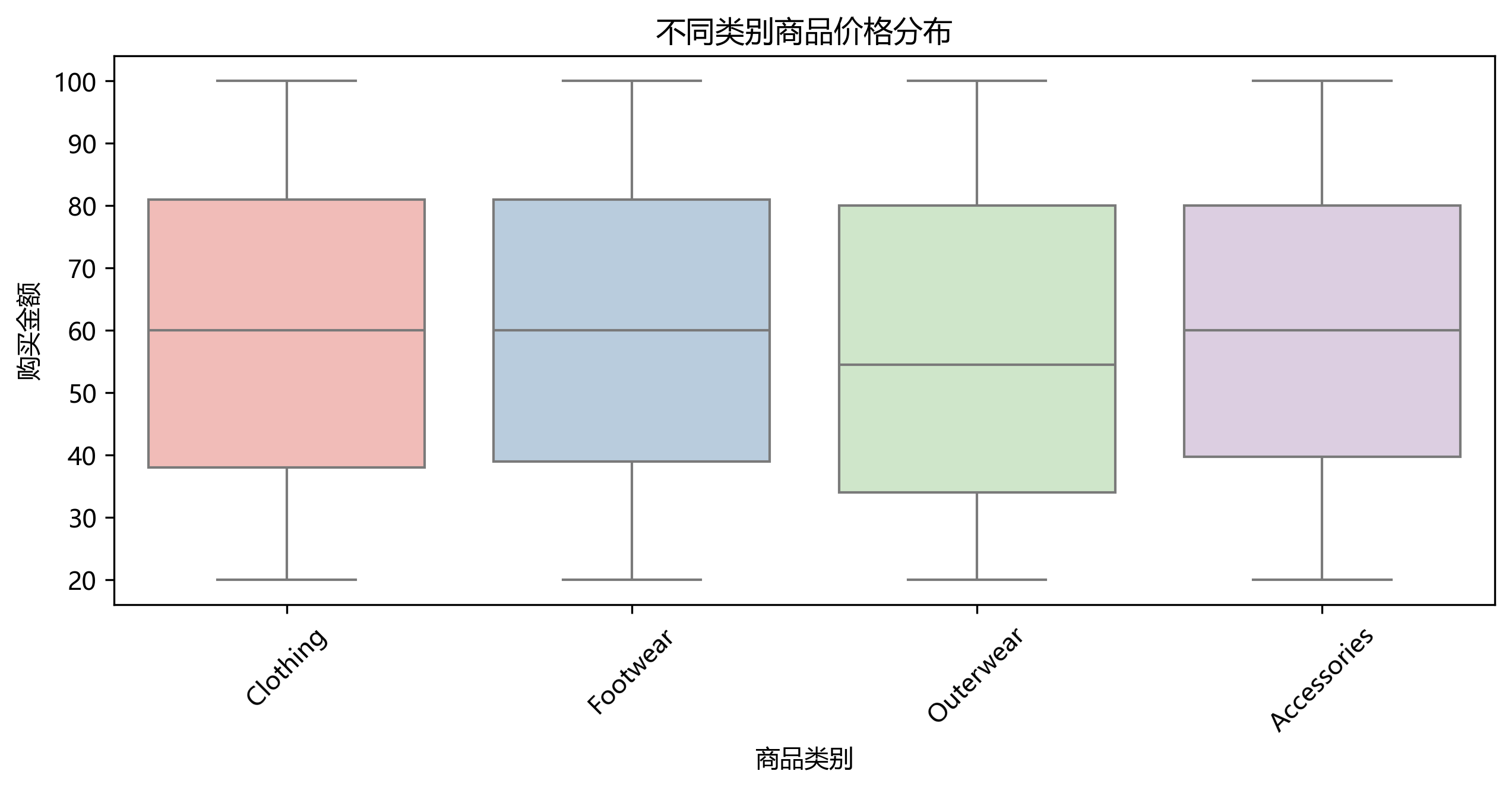
价格分布
分析不同类别商品的价格分布,发现外套和鞋类价格较高,配饰类价格波动大
plt.figure(figsize=(8,4))
sns.boxplot(x='Category', y='Purchase Amount ', data=df, palette='Pastel1')
plt.title('不同类别商品价格分布')
plt.ylabel('购买金额')
plt.show()
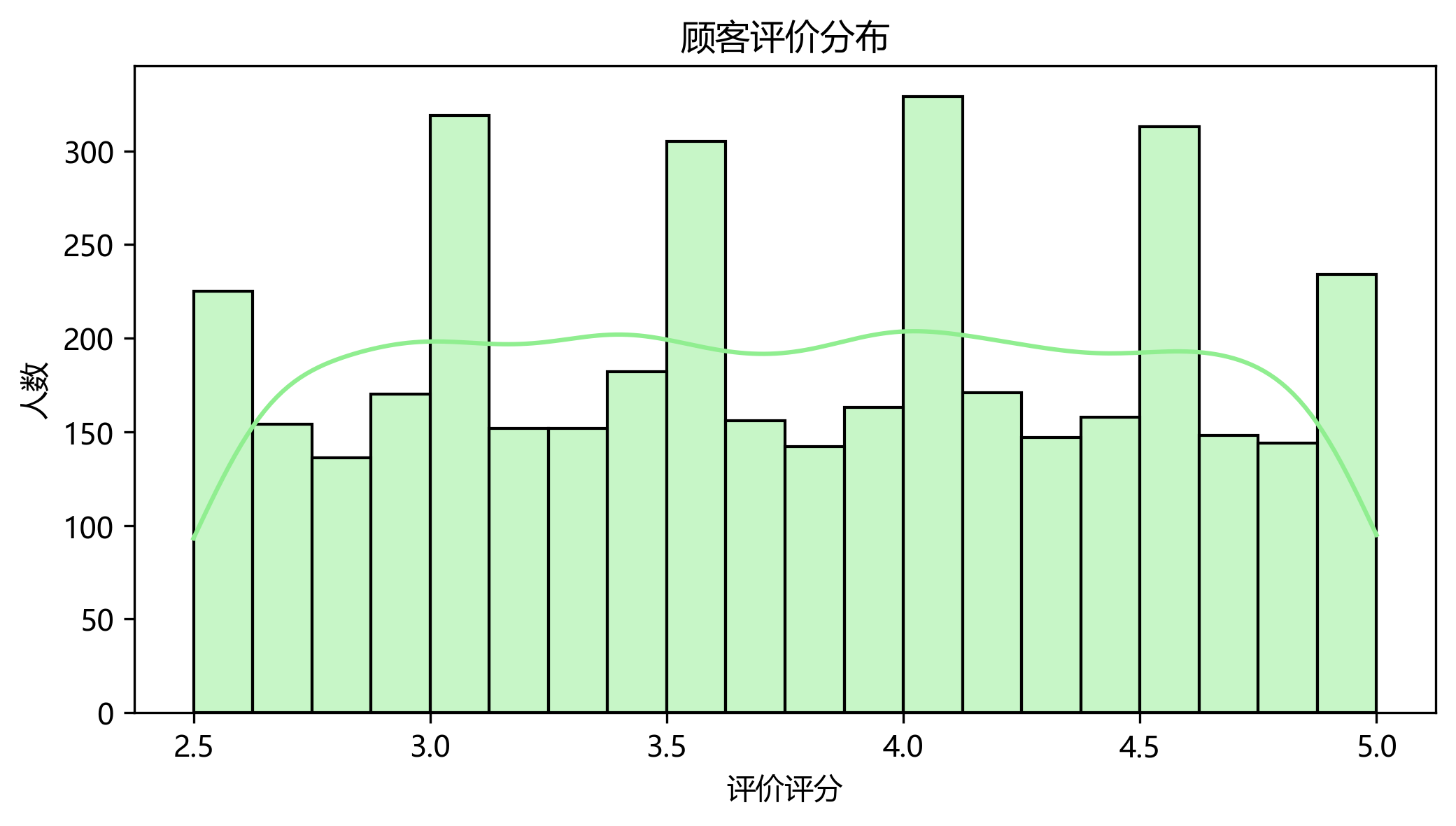
评价分布
直方图分析顾客的评价分布,总体评价还可以
plt.figure(figsize=(8,4))
sns.histplot(df['Review Rating'], bins=20, kde=True, color='lightgreen')
plt.title('顾客评价分布')
plt.xlabel('评价评分')
plt.ylabel('人数')
plt.show()
高级数据分析方法
除了基础的数据分析方法,下面介绍一个高级方法,在实战之前,可以先来了解一下聚类方法的定义
- 聚类分析是一种无监督学习方法,用于将数据集中的对象分成多个组(或簇),使得同一组中的对象在某种意义上更相似,而不同组中的对象差异更大
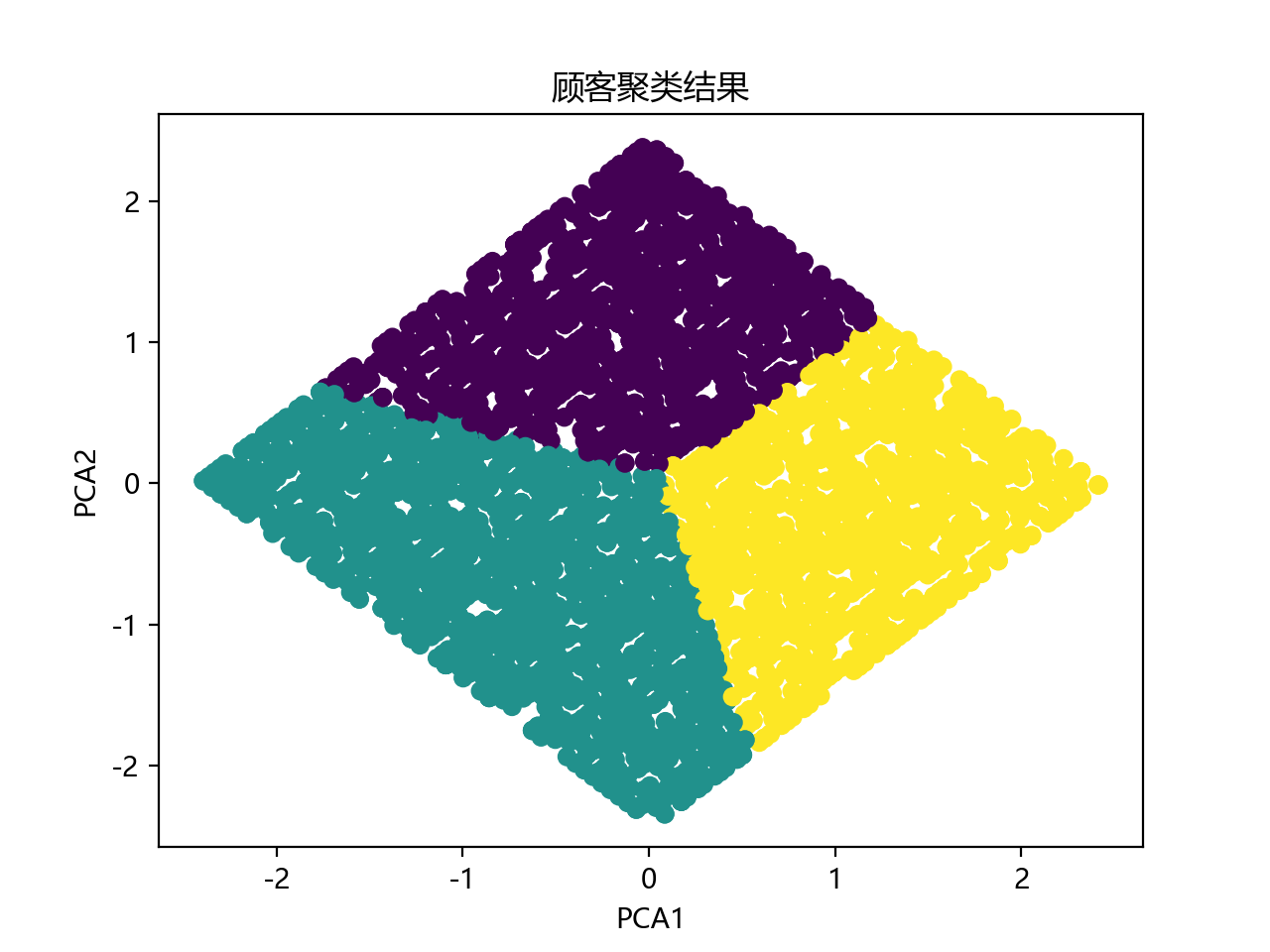
聚类分析
聚类分析,我们可以识别顾客群体的自然分组,帮助企业进行精准营销
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans
from sklearn.decomposition import PCA
scaler = StandardScaler()
scaled_data = scaler.fit_transform(df[['Age', 'Purchase Amount ']])
# K-means聚类
kmeans = KMeans(n_clusters=3, random_state=42)
df['Cluster'] = kmeans.fit_predict(scaled_data)
# PCA降维
pca = PCA(n_components=2)
pca_data = pca.fit_transform(scaled_data)
plt.scatter(pca_data[:, 0], pca_data[:, 1], c=df['Cluster'], cmap='viridis')
plt.title('顾客聚类结果')
plt.xlabel('PCA1')
plt.ylabel('PCA2')
plt.show()
总结
对于初学者而言,如果你掌握了本次数据分析小案例,你就可以在日后的数据分析学习里轻松许多,当然仅仅这点知识还是远远不够的,数据分析更多的还是在数据里挑出你认为重要的特征,并通过匹配的可视化图,最终得到一份详细准确的报告。这才是最终目标~