目录
一.现有网络模型的使用和修改
import torchvision
from torch import nn
# train_data=torchvision.datasets.ImageNet("../torchvision_dataset_ImageNet",split="train",
# transform=torchvision.transforms.ToTensor(),
# download=True)
vgg16_false = torchvision.models.vgg16(pretrained=False)
vgg16_true = torchvision.models.vgg16(pretrained=True)
print(vgg16_true)
"""
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)
"""
# 现在我要用这个架构 训练CIFAR10
data = torchvision.datasets.CIFAR10('../torchvision_dataset',train=True,
transform=torchvision.transforms.ToTensor(),
download=True
)
# 现有模型的微调
vgg16_true.classifier.add_module('add_linder',nn.Linear(1000,10))
print(vgg16_true)
"""
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
(add_linder): Linear(in_features=1000, out_features=10, bias=True)
)
)
"""“pretrained”(预训练)是深度学习中一个非常重要的概念,指的是模型在大规模公开数据集(如 ImageNet、COCO 等)上提前训练好的状态。这些模型已经通过大量数据学习到了通用的特征(比如图像中的边缘、纹理、基础形状,或文本中的语法、语义规律等),可以直接被复用在新任务中。
以 VGG 模型为例理解 pretrained
在实际使用中,我们常看到 “pretrained VGG”,它的含义是:
这个 VGG 模型已经在 ImageNet(包含 120 万张图片、1000 个类别的大型图像数据集)上完成了训练,卷积层、全连接层的权重参数都已经通过学习优化好了。
这些权重不是随机初始化的,而是包含了 ImageNet 数据集中的通用视觉特征(比如 “边缘检测”“颜色块组合”“简单物体部件” 等)。
pretrained 的核心作用
加速新任务训练
直接使用预训练权重作为初始值,不需要从随机参数开始训练,能大幅减少新任务的训练时间(尤其是小数据集场景)。提升模型性能(尤其小数据集)
新任务的数据量较小时,模型容易过拟合(只记住训练数据,泛化能力差)。而预训练模型的权重已经学到了通用规律,能帮助模型更快抓住新任务的核心特征,减少过拟合风险。降低数据依赖
很多实际任务(如特定领域的图像分类、细粒度识别)没有足够多的标注数据,预训练模型相当于 “借” 了大规模数据的学习成果,让小数据任务也能训练出不错的模型。
如何使用 pretrained 模型?
以图像分类任务为例,通常有两种方式:
特征提取(Feature Extraction):冻结预训练模型的卷积层(只保留其学到的特征提取能力),只训练新任务的输出层(比如将 ImageNet 的 1000 类输出改为自己任务的 5 类)。
微调(Fine-tuning):解冻部分卷积层(尤其是深层,因为深层学到的特征更抽象,可能需要适配新任务),和输出层一起训练,让模型在通用特征基础上进一步学习新任务的专属特征。
二.网络模型的保存和读取
方式一:
# 模型的保存
# 保存方式1
# 不仅保存了模型,同时也保存了模型中的参数
torch.save(vgg16,"vgg16_model_save_method1.pth")# 加载模型
# 加载方式1 对应保存方式1
modul1 = torch.load("./vgg16_model_save_method1.pth", weights_only=False)
"""
在 2.6 版本之前,torch.load()默认允许加载任意类型的对象(包括自定义类),
存在安全风险(如果加载恶意文件可能执行任意代码)。
从 2.6 开始,默认只允许加载 “安全类型”(如模型权重字典),
而完整模型(包含类定义)的加载需要显式授权。
weights_only=False
"""
# print(modul1)
在 2.6 版本之前,torch.load()默认允许加载任意类型的对象(包括自定义类),存在安全风险(如果加载恶意文件可能执行任意代码)。
从 2.6 开始,默认只允许加载 “安全类型”(如模型权重字典),而完整模型(包含类定义)的加载需要显式授权。
使用weights_only=False(简单但有安全风险)
如果你信任这个.pth文件的来源(比如是自己保存的,或来自官方预训练模型),可以显式允许加载完整模型:
vgg16 = torch.load("./vgg16_model_save_method1.pth", weights_only=False)
注意:这种方式会执行文件中的代码,存在安全风险,仅建议用于可信任的文件。
加载后输出:
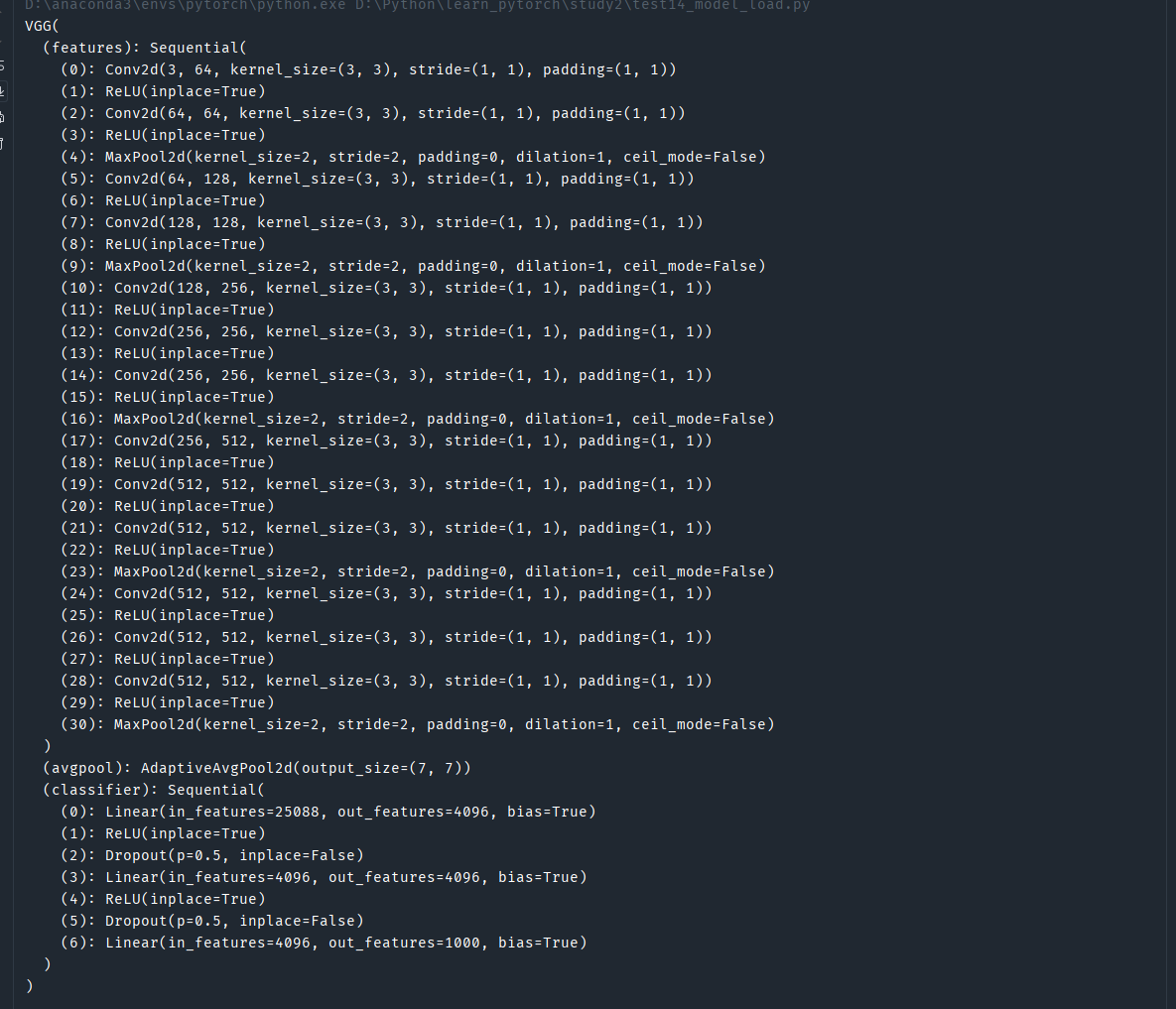
因为方法一有风险,所以
方法二:
# 模型的保存
# 保存方式2
# 只保存了模型中的参数(官方推荐的方式)
torch.save(vgg16.state_dict(),"vgg16_model_save_method2.pth")
"""
所有可训练参数(权重和偏置)的字典。
对于 VGG16 这样的预训练模型
vgg16.state_dict() 返回的是一个包含其所有卷积层和全连接层参数的 Python 字典。
"""# 加载方式2 对应保存方式2
modul2=torchvision.models.vgg16(weights=None)
modul2_weights= torch.load("./vgg16_model_save_method2.pth")
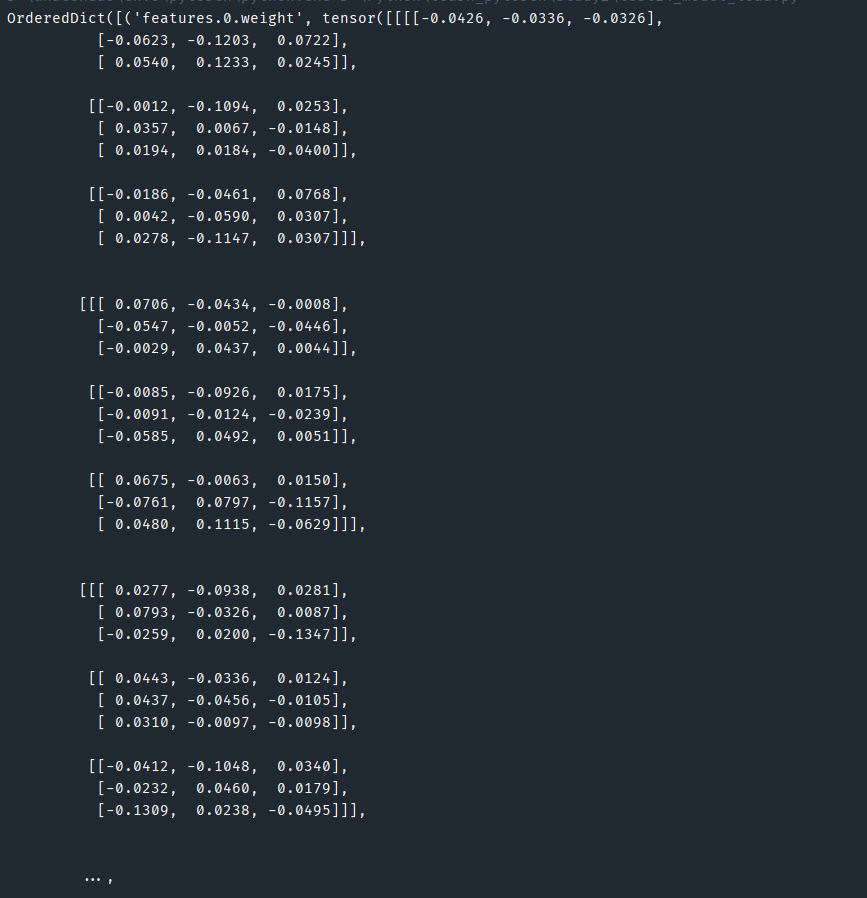
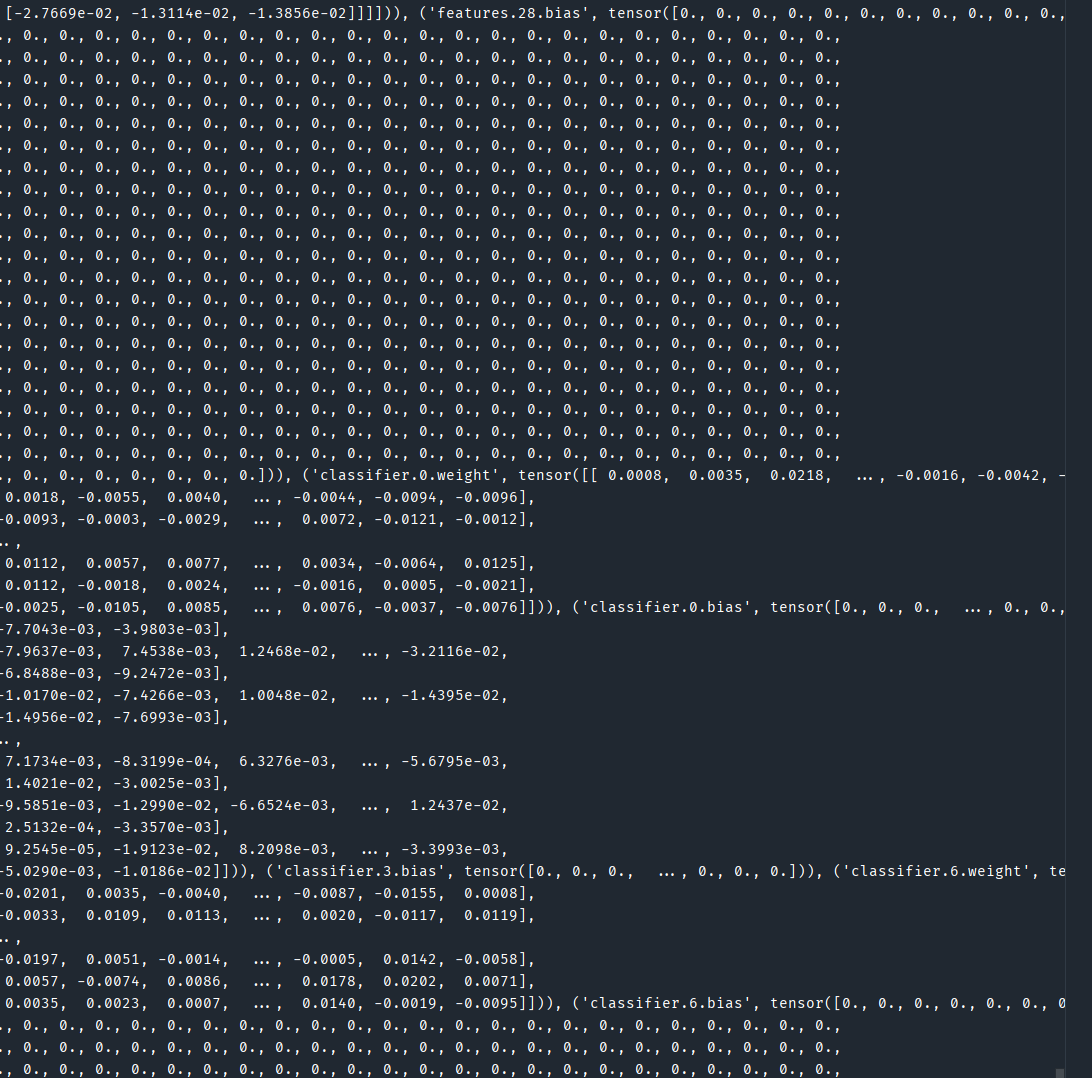
# print(modul2_weights)
modul2.load_state_dict( torch.load("./vgg16_model_save_method2.pth"))
# print(modul2)输出保存的权重:
以字典的形式存储