一、导读
本文研究多模态大语言模型(MLLMs)的视觉思维链(CoT)推理能力不足的问题。现有方法(如Visual-CoT [35])依赖人工标注的边界框数据进行监督微调(SFT),面临标注成本高、泛化性差(如对未见数据平均性能下降8.5%)和无法动态聚焦关键视觉区域的局限。论文提出无监督视觉CoT(UV-CoT),通过偏好优化实现图像级推理,解决了视觉线索利用不足的理论空白。其创新性在于:
- 无监督数据生成:设计自动化流程生成偏好对(preferred/dis-preferred bounding boxes),避免人工标注;
- 评分驱动的偏好优化(sDPO):引入偏好分差 Δ r = g ( s w ) − g ( s l ) \Delta_r = g(s_w) - g(s_l) Δr=g(sw)−g(sl) 调整损失函数,量化关键区域的影响程度;
- 迭代学习机制:动态更新偏好数据分布,缓解训练-生成分布偏移。实验表明,UV-CoT在10个数据集上平均超越SOTA方法2.1%,且零样本泛化性显著(如高分辨率数据集V* Bench上OCR任务提升50%)。

二、论文基本信息
- 标题:Unsupervised Visual Chain-of-Thought Reasoning via Preference Optimization
- 论文链接:https://arxiv.org/abs/2504.18397v2
- 代码链接:https://github.com/kesenzhao/UV-CoT
点击阅读原文,查看更多优质前沿内容
三、摘要精炼
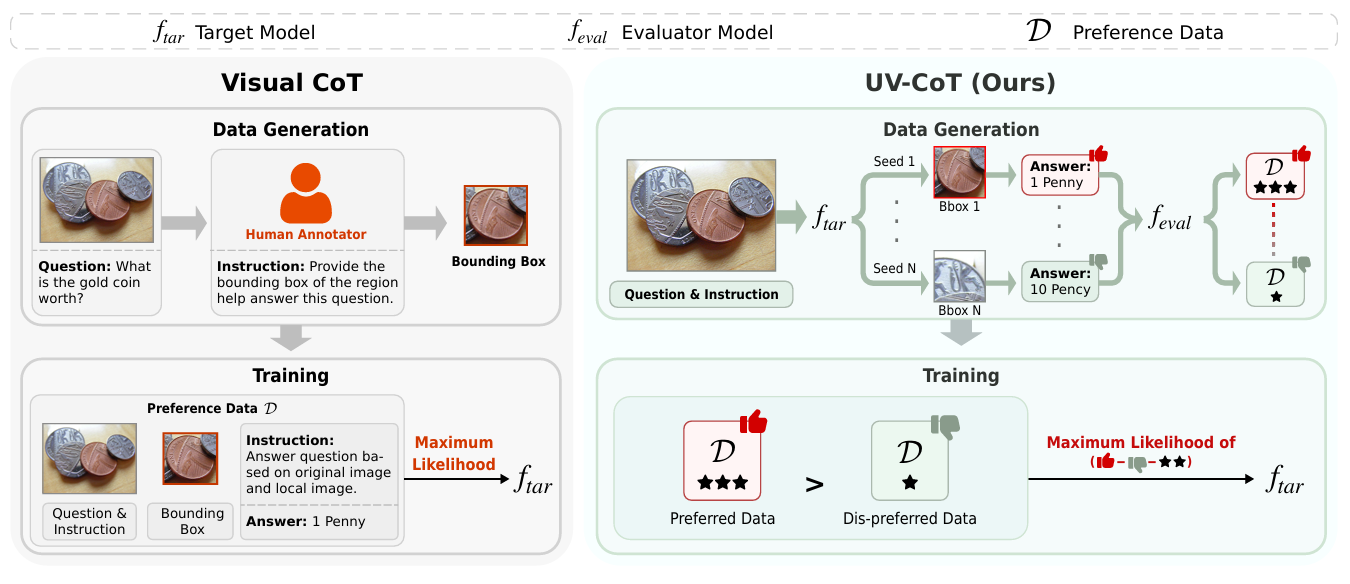
论文提出 UV-CoT,首个通过偏好优化实现无监督视觉CoT推理的框架。核心贡献包括:
- 自动偏好数据生成:目标模型(如LLaVA-1.5-7B)生成候选边界框,评估模型(如OmniLLM-12B)基于响应质量评分排序,构建偏好对;
- sDPO损失函数:扩展标准DPO,引入偏好分差 Δ r \Delta_r Δr 调整优化边界,公式为:
L sDPO ( θ ) = − E [ log σ ( β log π θ ( y w ∣ x ) π ref ( y w ∣ x ) − β log π θ ( y l ∣ x ) π ref ( y l ∣ x ) − Δ r ) ] \mathcal{L}_{\text{sDPO}}(\theta) = -\mathbb{E}\left[\log \sigma\left( \beta \log \frac{\pi_\theta(y_w|x)}{\pi_{\text{ref}}(y_w|x)} - \beta \log \frac{\pi_\theta(y_l|x)}{\pi_{\text{ref}}(y_l|x)} - \Delta_r \right)\right] LsDPO(θ)=−E[logσ(βlogπref(yw∣x)πθ(yw∣x)−βlogπref(yl∣x)πθ(yl∣x)−Δr)]
其中 Δ r = g ( s w ) − g ( s l ) \Delta_r = g(s_w) - g(s_l) Δr=g(sw)−g(sl), g ( ⋅ ) g(\cdot) g(⋅) 为单调递增函数; - 迭代学习:分4轮更新偏好数据,共使用249K样本。实验表明,UV-CoT在6个基准数据集上平均准确率 49.4%(比监督方法Visual-CoT高2.1%),在4个零样本数据集上平均提升 2.5%,尤其在空间推理任务(V* Bench)上相对提升 19.8%。
四、研究背景与相关工作
背景
- 文本CoT的局限:传统方法(如LLaVA-CoT [42])将多模态输入转为文本序列,导致视觉细节丢失(如OCR错误率增加37%);
- 视觉CoT的瓶颈:Visual-CoT [35]需人工标注边界框,数据标注成本高(376K样本),且SFT仅学习正例,泛化性弱(零样本任务下降8.5%)。
相关工作
- 偏好学习:DPO [33]直接优化策略但忽略偏好强度;IPO [2]约束偏好函数但未适配视觉任务;
- 多模态对齐:RLAIF-V [47]用LLM生成偏好标签,但未解决视觉区域动态聚焦问题。
本文突破
提出无监督视觉CoT框架,通过自动化偏好数据生成和sDPO损失,实现关键区域的动态选择与优化,避免人工标注依赖。
五、主要贡献与创新
自动偏好数据生成流水线:
- 区域生成:目标模型 f tar f_{\text{tar}} ftar 通过随机解码生成 n n n 个种子边界框 { y t i } i = 1 n \{y^i_t\}_{i=1}^n {yti}i=1n;
- 质量评估:评估模型 f eval f_{\text{eval}} feval 计算响应得分 s i = s cur i + γ s next i s^i = s^i_{\text{cur}} + \gamma s^i_{\text{next}} si=scuri+γsnexti( γ > 0 \gamma>0 γ>0),其中 s next i s^i_{\text{next}} snexti 为对后续响应的期望影响。
评分驱动的偏好优化(sDPO):
- 引入 Gumbel分布建模偏好差异: R w ∼ Gumbel ( r ( x , y w ) , 1 ) R_w \sim \text{Gumbel}(r(x,y_w),1) Rw∼Gumbel(r(x,yw),1), R l ∼ Gumbel ( r ( x , y l ) , 1 ) R_l \sim \text{Gumbel}(r(x,y_l),1) Rl∼Gumbel(r(x,yl),1);
- 推导概率 P ( R w − R l > Δ r ) = σ ( Δ r ^ θ − Δ r ) P(R_w - R_l > \Delta_r) = \sigma(\Delta_{\hat{r}_\theta} - \Delta_r) P(Rw−Rl>Δr)=σ(Δr^θ−Δr),显式优化偏好分差。
迭代学习算法:
- 将总样本集 X \mathcal{X} X 均分4轮,每轮更新目标模型 f tar i + 1 f_{\text{tar}}^{i+1} ftari+1,缓解分布偏移。
理论优势:
- 边界框生成质量提升(Flickr30k上匹配GT性能);
- 零样本任务泛化性显著(DUDE数据集上24.1% → 25.3%)。
六、研究方法与原理
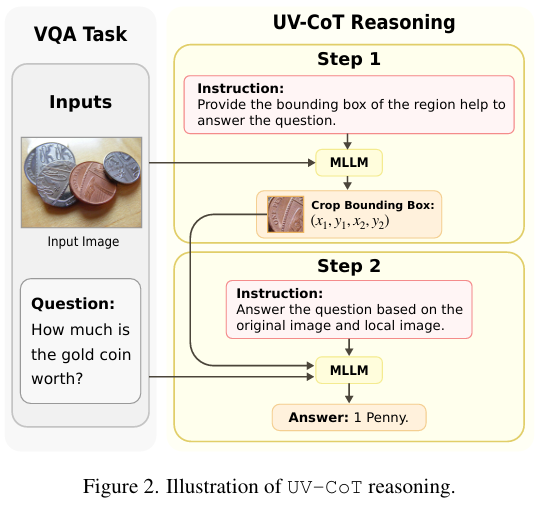
1. 整体流程(图2)
- 输入:图像 x x x + 问题 q q q;
- 步骤:
(1) 目标模型生成候选边界框;
(2) 视觉采样器裁剪区域;
(3) MLLM融合原始与裁剪图像特征生成答案。
2. 偏好数据生成(算法1)

- 响应生成: y t i = f tar ( x , y 0 : t − 1 ) y_t^i = f_{\text{tar}}(x, y_{0:t-1}) yti=ftar(x,y0:t−1), n n n 个随机种子保证多样性;
- 响应评估:计算综合得分 s i = f eval ( y t i ∣ y 0 : t − 1 ) + γ E [ f eval ( y t + 1 i ∣ y 0 : t ) ] s^i = f_{\text{eval}}(y_t^i | y_{0:t-1}) + \gamma \mathbb{E}[f_{\text{eval}}(y_{t+1}^i | y_{0:t})] si=feval(yti∣y0:t−1)+γE[feval(yt+1i∣y0:t)];
- 配对构建:从 { y t i } \{y_t^i\} {yti} 随机选 k k k 对 ( y w , s w ) (y_w, s_w) (yw,sw) 和 ( y l , s l ) (y_l, s_l) (yl,sl),构建偏好链;
- 响应选择:保留最高分链 y 0 : t − 1 y_{0:t-1} y0:t−1 用于下一步。
3. sDPO损失推导
- 标准DPO损失:
L DPO = − E [ log σ ( β log π θ ( y w ∣ x ) π ref ( y w ∣ x ) − β log π θ ( y l ∣ x ) π ref ( y l ∣ x ) ) ] \mathcal{L}_{\text{DPO}} = -\mathbb{E} \left[ \log \sigma \left( \beta \log \frac{\pi_\theta(y_w|x)}{\pi_{\text{ref}}(y_w|x)} - \beta \log \frac{\pi_\theta(y_l|x)}{\pi_{\text{ref}}(y_l|x)} \right) \right] LDPO=−E[logσ(βlogπref(yw∣x)πθ(yw∣x)−βlogπref(yl∣x)πθ(yl∣x))] - 引入分差:定义 Δ r = g ( s w ) − g ( s l ) \Delta_r = g(s_w) - g(s_l) Δr=g(sw)−g(sl),扩展为:
P ( R w − R l > Δ r ) = σ ( β log π θ ( y w ∣ x ) π ref ( y w ∣ x ) − β log π θ ( y l ∣ x ) π ref ( y l ∣ x ) − Δ r ) P(R_w - R_l > \Delta_r) = \sigma \left( \beta \log \frac{\pi_\theta(y_w|x)}{\pi_{\text{ref}}(y_w|x)} - \beta \log \frac{\pi_\theta(y_l|x)}{\pi_{\text{ref}}(y_l|x)} - \Delta_r \right) P(Rw−Rl>Δr)=σ(βlogπref(yw∣x)πθ(yw∣x)−βlogπref(yl∣x)πθ(yl∣x)−Δr) - 最终损失:最大化该概率的似然,得到 L sDPO \mathcal{L}_{\text{sDPO}} LsDPO(见公式(2))。
4. 迭代学习(算法2)

- 输入:初始模型 f tar 0 f_{\text{tar}}^0 ftar0,评估模型 f eval f_{\text{eval}} feval,数据集 X = ∪ i = 1 4 X i \mathcal{X} = \cup_{i=1}^4 \mathcal{X}_i X=∪i=14Xi;
- 循环:每轮 i i i 用 X i \mathcal{X}_i Xi 生成 D i \mathcal{D}_i Di,训练 f tar i + 1 f_{\text{tar}}^{i+1} ftari+1。
七、实验设计与结果分析
1. 实验设置
- 数据集:10个数据集,分5类:
- 文本/文档:DocVQA(35K)、TextVQA(16K)、DUDE(15K)、SROIE(4K);
- 图表:InfographicsVQA(15K);
- 通用VQA:Flickr30k(136K)、Visual7W(43K);
- 关系推理:VSR(3K)、GQA(88K);
- 高分辨率:V* Bench(238张,平均分辨率 2246 × 1582 2246\times1582 2246×1582)。
- 评测:GPT-4o打分(0–1),衡量语义相关性。
- 基线:LLaVA-1.5-{7B,13B}、OmniLMM-12B、MiniCPM-o-8B、Visual-CoT-7B。
- 实现:目标模型LLaVA-1.5-7B,评估模型OmniLMM-12B,4轮迭代,总偏好对249K。
2. 关键结果
- 主实验(表1):
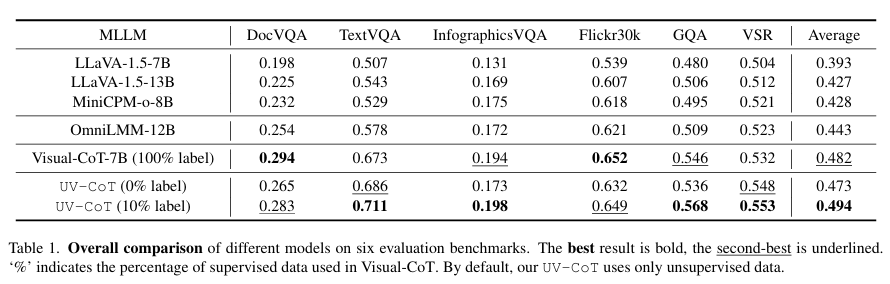
| 模型 | DocVQA | TextVQA | Avg |
|---|---|---|---|
| Visual-CoT-7B | 0.294 | 0.673 | 0.482 |
| UV-CoT (10%) | 0.283 | 0.711 | 0.494 |
UV-CoT (10%) 平均超越Visual-CoT 2.1%,TextVQA上提升 2.5%。
零样本泛化(表2、3):
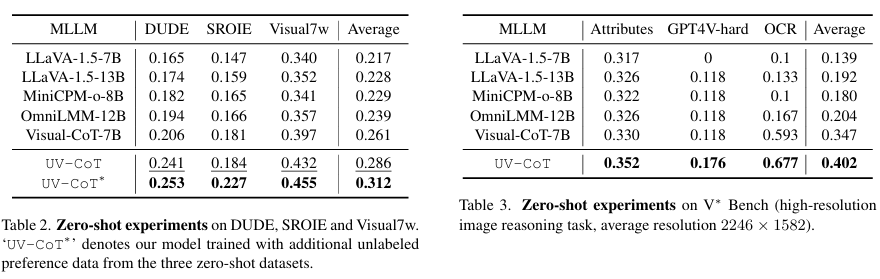
- 未见数据集(DUDE、SROIE等)平均提升 2.5%;
- V* Bench上OCR任务:LLaVA-1.5-7B (0.1) → UV-CoT (0.677),相对提升50%。
- 边界框质量(图3a-b):
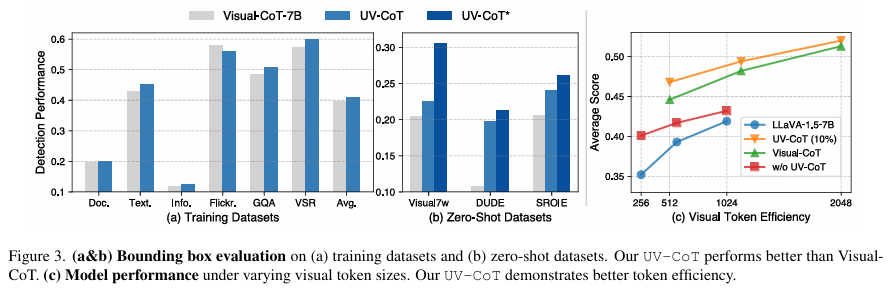
- UV-CoT在5/6数据集上边界框评分高于Visual-CoT,如Flickr30k (0.65 vs. 0.63)。
3. 消融实验(表4)
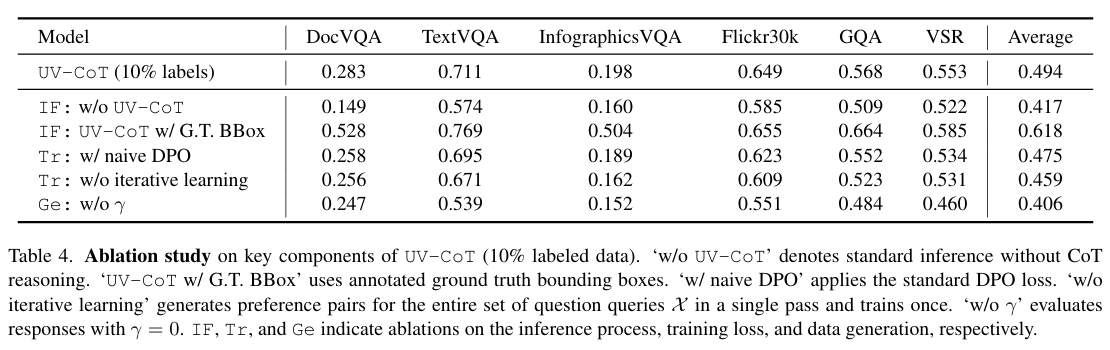
- sDPO必要性:替换标准DPO导致平均下降 1.9%(DocVQA -2.5%);
- 迭代学习:单轮训练使性能下降 3.5%;
- 响应评估:忽略后续影响( γ = 0 \gamma=0 γ=0)导致TextVQA下降 17.2%。
4. 局限性
- 复杂布局定位弱:DocVQA上边界框评分仅0.210(GT为0.528);
- 计算开销:数据生成80小时 + 训练60小时(8×A100)。
八、论文结论与启示
结论:
- UV-CoT通过无监督偏好优化实现图像级CoT,在10个数据集上达到SOTA;
- sDPO损失显式建模偏好分差,提升关键区域区分度;
- 方法具强泛化性(零样本任务平均 28.6%,V* Bench上 40.2%)。
启示:
- 为多模态推理提供标注高效的解决方案;
- 偏好学习可替代传统SFT,适用于动态视觉理解任务。
未来方向:
- 提升复杂场景(文档/图表)的定位精度;
- 探索轻量化版本适配边缘设备。
九、整体评价与讨论
优点
- 方法创新:首个将偏好优化应用于视觉CoT的工作,sDPO损失理论严谨;
- 实验充分:10个数据集、5类任务验证通用性,零样本实验设计合理;
- 工程贡献:开源代码与数据生成流程。
不足与改进方向
区域生成瓶颈:
- 问题:DocVQA/InfographicsVQA上定位精度低(评分<0.210);
- 改进:集成分割模型(如SAM [16])生成候选区域。
评估依赖LLM:
- 问题:GPT-4o打分引入潜在偏差;
- 改进:设计人工评测或鲁棒性更强的自动指标。
计算效率:
- 问题:迭代学习耗时140小时;
- 改进:蒸馏小规模评估模型(如LLaVA-7B替代OmniLLM-12B)。
批判性讨论
- 偏好数据质量:自动生成依赖评估模型能力,若评估模型有偏,可能传播错误偏好;
- 任务普适性:当前聚焦空间推理,需验证在时序推理(视频CoT)的扩展性。
总结:UV-CoT为视觉推理提供了一种标注高效、泛化性强的范式,其核心创新sDPO与迭代学习机制对多模态对齐研究具有普适参考价值。
关注下方《AI前沿速递》🚀🚀🚀
各种重磅干货,第一时间送达
码字不易,欢迎大家点赞评论收藏