多模态检索增强生成 (Multimodal RAG)!其中需要涉及到——
多模态信息处理 (Multimodal Information Processing)、向量化与检索技术 (Embeddings & Retrieval)
跨模态检索与关联 (Cross-Modal Retrieval)、大语言模型(LLM)的应用与推理 (LLM Application & Reasoning)
相关知识点及参考资料:
PDF文档解析库PyMuPDF官方教程:https://pymupdf.readthedocs.io/en/latest/
强大的中文OCR工具PaddleOCR:https://github.com/PaddlePaddle/PaddleOCR
领先的中文文本向量化模型库FlagEmbedding (BGE模型):https://github.com/FlagOpen/FlagEmbedding
经典图文多模态向量化模型CLIP (Hugging Face实现):https://huggingface.co/docs/transformers/model_doc/clip
高性能向量检索引擎FAISS入门指南:https://github.com/facebookresearch/faiss/wiki/Getting-started
简单易用的向量数据库ChromaDB快速上手:https://docs.trychroma.com/getting-started
通义千问Qwen大模型官方仓库 (含多模态VL模型):https://github.com/QwenLM/Qwen-VL
集成化RAG开发框架LlamaIndex五分钟入门:https://docs.llamaindex.ai/en/stable/getting_started/starter_example.html
Xinference官方仓库(模型推理框架):https://github.com/xorbitsai/inference
任务背景
任务背景:目前多模态信息(财报PDF)的AI利用率较低
传统的AI技术,如搜索引擎或基于文本的问答系统,在处理这类复杂文档(图文混排 ——文字、图表、照片、流程图等元素交织在一起,共同承载着完整的信息。)时显得力不从心。
它们能很好地理解文字,但对于图表中蕴含的趋势、数据和关系却是“视而不见”的。这就造成了一个巨大的信息鸿沟:AI无法回答那些需要结合视觉内容才能解决的问题,例如“根据这张条形图,哪个产品的市场份额最高?”或“请解释一下这张流程图的工作原理”。
LLM的面临的两大挑战
- 知识局限性 :LLM的知识是预训练好的,对于私有的、最新的或特定领域的文档(比如本次比赛的财报)一无所知,并且可能产生幻觉。
- 模态单一性 :大多数LLM本身只能处理文本,无法直接“看到”和理解图像。
检索增强生成(RAG) 技术的出现,通过从外部知识库中检索信息来喂给LLM,有效地解决了第一个挑战。而本次比赛的核心—— 多模态检索增强生成(Multimodal RAG)
多模态RAG任务的四大核心要素
数据源 一堆图文混排的PDF,这是我们唯一的数据。
工作的起点和唯一的信息来源,就是 财报数据库.zip 这个压缩包里的PDF文件。
我们的系统必须是一个“闭卷”系统,不允许从互联网或其他外部渠道获取信息来回答问题。
首先第一步是:文档解析 (Document Parsing)
- 不能简单地把PDF当成一个黑盒。需要设计一个流程,能自动化、结构化地从这些PDF中提取出两种核心信息: 文本块 (Text Chunks) 和 图片 (Images) 。
- 提取出的每一份信息,都必须牢牢绑定它的元数据——它来自 哪个文件 (filename) 和 哪一页 (page) 。
可溯源 必须明确指出答案的出处。
- 系统不仅要知道答案,也需要知道他的来源。
如果答案是“3500万元”,我们的系统必须能明确地指出:这个数字是从 A公司2024年财报.pdf 的第8页的某个表格里来的。 - 要求我们在整个处理流水线中实现 元数据(Metadata)的持续追踪
- 从文档解析阶段开始,每个文本块、每张图片都要携带 {filename, page_number} 的元数据标记。
- 在检索时,我们捞取的不应仅仅是内容,更要带上它的元数据。
- 最后,在生成答案的环节,需要通过提示工程引导大语言模型依据这些元数据,在生成答案的同时,也生成准确的来源信息。
多模态 问题可能需要理解文本,也可能需要理解图表(图像)。
很多关键信息,尤其是财报数据,往往存在于图表(本质是图片)中。
例如,问题“哪个季度的销售额增长最快?”很可能需要分析一个柱状图才能回答。一个只能处理文本的系统,在这种问题面前将无能为力。
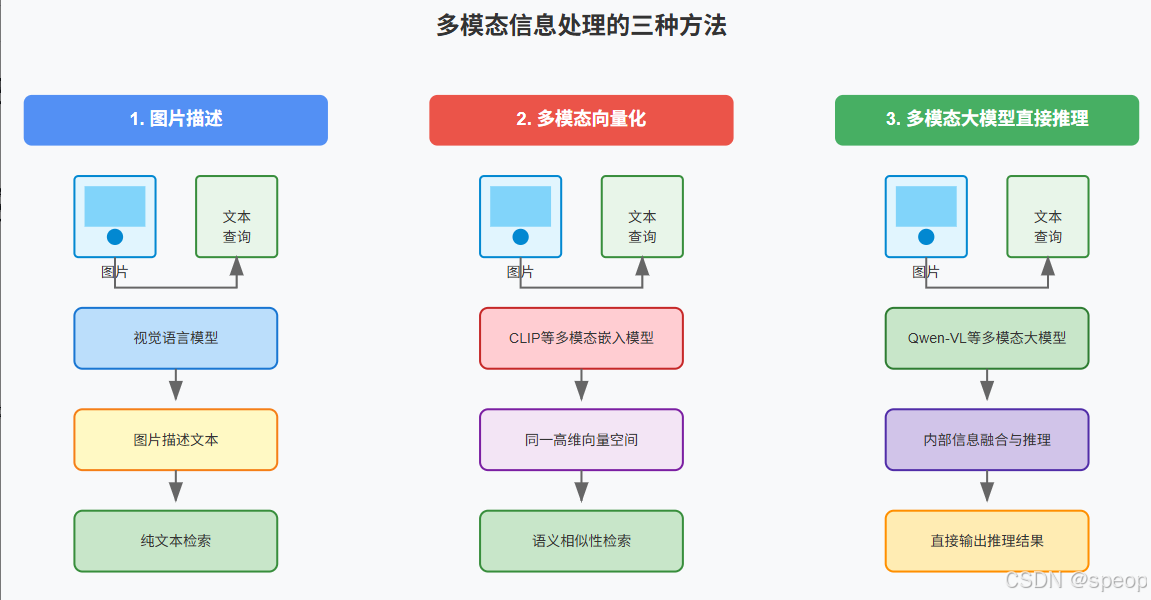
让机器看懂图片并将其与文本关联起来的三种主流建模路径
这是赛题的技术核心和难点。我们需要建立一个能让机器“看懂”图片,并将其与文本关联起来的机制。至少有三种主流的建模路径:
- 图片描述(Image Captioning)
对每张图片,使用一个视觉语言模型(如Qwen-VL, BLIP等)生成一段描述性的文字。
然后,我们将图和文的问题,统一转换成对“文本+图片描述”的纯文本检索问题。这是最简单直接的“降维”思路。 - 多模态向量化 (Multimodal Embedding)
使用像 CLIP 这样的多模态嵌入模型,将文本块和图片都转换到同一个高维向量空间。
这样,一个文本形式的提问,可以直接在向量空间中寻找到语义上最相关的文本块和 图片本身 。 - 多模态大模型直接推理
将检索到的相关文本和图片 直接 喂给具备多模态理解能力的大语言模型(如Qwen-VL),让模型自己在内部完成信息的融合与推理。
问答 根据检索的信息生成一个回答。
- 系统的最终产出是一个自然、流畅、准确的答案,而不是简单地把检索到的原文丢给用户。
- 这是我们系统的最后一个核心模块—— 生成器 (Generator) 。这个角色通常由一个大语言模型(LLM)来扮演。
- 它的任务是接收我们前面所有步骤的成果(用户的原始问题 + 检索到的、最可能相关的文本与图片信息),
- 然后对这些材料进行归纳、推理和总结,最终用自己的话生成答案,并附上来源。
- 这个环节的成败,极度依赖 提示工程 (Prompt Engineering) 的质量。
那么任务要求究竟是怎么样的、以及有哪些重难点呢?
我们需要通过财报PDF,输出对应的多模态答案
输入 (Input):我们需要处理什么?
比赛官方为我们提供了三样核心材料,它们是我们构建系统所需用到的全部信息:
- 一个包含了多个PDF文件的压缩包。这些PDF是真实世界的公司财报,内容上是典型的 图文混排 格式,包含了大量段落、数据表格以及各种图表(如条形图、饼图、折线图等)。这是我们系统的 唯一信息来源 。所有问题的答案都必须从这些PDF文档中寻找,并且不能依赖任何外部知识。
- train.json
一个JSON格式的文件,为我们提供了一系列“问题-答案”的范例。这是我们用来开发、训练和验证我们系统模型的主要依据。我们可以通过它来调试我们的算法,看看对于给定的问题,我们的系统能否找到正确的答案和出处。
[
{
"question": "根据图表显示,产品A的销售额在哪个季度开始下降?",
"answer": "产品A的销售额在第三季度开始出现下降。",
"filename": "2023年度第三季度财报.pdf",
"page": 5
},
{
"question": "...",
"answer": "...",
"filename": "...",
"page": "..."
}
]
- test.json
另一个JSON格式的文件,包含了比赛最终用来评测我们系统性能的所有问题。
这是我们需要完成的任务。文件里 只包含 question 字段 ,而我们需要预测的 answer , filename , 和 page 都是缺失的。
[
{
"filename": "xx.pdf",
"page": 1,
"question": "广联达在苏中建设集团南宁龙湖春江天越项目中,具体运用了哪些BIM技术,并取得了哪些成果?",
"answer": "广联达在苏中建设集团南宁龙湖春江天越项目中,具体运用了哪些BIM技术,并取得了哪些成果?"
},
{
"filename": "xx.pdf",
"page": 1,
"question": "广联达公司如何通过数字项目管理平台提升施工企业的数字化转型能力?",
"answer": "广联达公司如何通过数字项目管理平台提升施工企业的数字化转型能力?"
},
……
]
输出需要提交什么
我们的最终任务是为 test.json 中的每一个问题,预测出三个信息: 答案 ( answer ) 、 来源文件名 ( filename ) 和 来源页码 ( page )
提交文件格式
官方要求我们将所有预测结果整理成一个 JSON 文件 进行提交。官方提供了 sample_submit.json 作为格式参考。
这个文件应该包含以下一个列表(列名以 sample_submit.json 为准):
question:问题。
answer :你预测的答案文本。
filename :你预测的答案所在PDF文件的全名。
page :你预测的答案所在的页码。
提交文件示例 ( submit. json) :
[
{
"filename": "xx.pdf",
"page": 1,
"question": "广联达在苏中建设集团南宁龙湖春江天越项目中,具体运用了哪些BIM技术,并取得了哪些成果?",
"answer": "广联达在苏中建设集团南宁龙湖春江天越项目中,具体运用了哪些BIM技术,并取得了哪些成果?"
},
……
]
总结一下 :整个任务流程就是,
读取 test.json 里的一个问题,
驱动你的系统去 财报数据库 中查找信息,
然后生成答案和出处,
最后将这几项信息作为一行写入到最终的 submit.json 文件中。
对 test.json 中的所有问题重复此过程,即可得到最终的提交文件.
其中的train.json文件主要是用来在训练非生成式模型环节中使用的,比如训练embedding模型,或者是微调LLM。
分析一下赛题数据、探索如何处理
参与算法赛事,一定要仔细理解赛事的 输入-输出 究竟是什么,尤其是提交的格式
所以我们需要思考如何提取PDF里面的数据,主要可以考虑两个工具——
pymupdf:基于规则的方式提取pdf里面的数据,mineru:基于深度学习模型通过把PDF内的页面看成是图片进行各种检测,识别的方式提取。
其中考虑到学习者可能没有那么高的硬件成本资源条件,所以 Task1 选择的是基于pymupdf的方式给大家作为示例,基于mineru的方式会在后续为大家介绍。
下面是一个使用 PyMuPDF(fitz)提取 PDF 内容的基础代码示例。它可以提取每一页的文本内容:
import fitz # PyMuPDF
def extract_pdf_text(pdf_path):
doc = fitz.open(pdf_path)
all_text = []
for page_num in range(doc.page_count):
page = doc.load_page(page_num)
text = page.get_text()
all_text.append(text)
doc.close()
return all_text
if __name__ == "__main__":
pdf_file = "your_file.pdf" # 替换为你的 PDF 文件路径
texts = extract_pdf_text(pdf_file)
for i, page_text in enumerate(texts):
print(f"--- Page {i+1} ---")
print(page_text)
赛事的难点
难点一:多模态信息的有效融合
**一个问题的答案可能同时依赖于一段文字描述和一个数据图表。**例如,文字提到“各产品线表现见下图”,而具体数据则完全在图表中。
挑战 :如何让系统理解这种跨模态的指代和依赖关系?**如果仅将文本和图像的描述(caption)作为独立的知识块进行检索,可能会丢失它们之间的强关联。**检索模块需要足够智能,能够根据一个文本问题,同时召回相关的文本和图像信息。
难点二:检索的准确性与召回率平衡
检索是整个系统的基础,如果检索出的上下文信息就不包含答案,那么后续的LLM再强大也无法凭空生成正确结果(这被称为“大海捞针,针不在海里”)。
挑战 :
- 语义模糊性 :用户提问的方式可能与文档中的措辞差异很大,这对嵌入模型的语义理解能力提出了高要求。
- 信息干扰 :如果检索返回的Top-K个结果中,只有1个是相关的,其他K-1个都是噪音,这会严重干扰LLM的判断,可能导致它基于错误信息作答**。如何优化检索策略(如使用重排Re-ranking技术)**以提高返回结果的信噪比,是一个核心问题。
难点三:答案生成的可控性与溯源精确性
LLM在生成答案时,有时会过度“自由发挥”,产生一些幻觉(Hallucination),即编造上下文中不存在的信息。同时,它也可能错误地引用来源。
挑战 :
- 忠实度 :如何通过设计Prompt,强力约束LLM,使其回答 严格基于 提供的上下文,减少信息捏造。
- 溯源 :如何让LLM准确地从多个上下文中,定位到真正提供答案关键信息的那个来源(文件名和页码),并正确地在最终输出中引用。这需要精心设计上下文的格式和给LLM的指令。
难点四:针对性评估指标的优化
最终的评分由三部分构成:文件名匹配度(0.25分)、页面匹配度(0.25分)和答案内容相似度(0.5分)。
挑战 :这意味着,一个完美的答案文本如果来源错误,得分会很低。反之,一个内容不太完美的答案如果来源准确,也能拿到可观的分数。因此,系统优化不能只关注答案文本的质量,必须将 溯源的准确性 放在同等重要的位置。在方案迭代中,需要建立能够模拟这套评分体系的本地验证集,以准确评估每次改动对最终得分的综合影响。
参考解题
第一步:从“终点”反推“起点”——快速明确核心任务
提交格式要求我们为每一个 question ,都精准地提供 answer 、 filename 和 page 时
{ "content": "内容文本或描述", "metadata": { "filename": "来源文件名.pdf", "page": 页码 } }
同时, content 字段需要被转换成机器能够理解和搜索的形式,为了方便后续召回, 向量化(Embedding)字段选择的是content 。
其他部分的元数据是为了辅助我们后续进行回答的时候能够知道当前chunk属于什么位置。
第二步:技术方案的权衡与选择
- (baseline方法)基于图片描述 :对所有图片生成文本描述,将这些描述与原文的文本块统一处理。这能将多模态问题简化为纯文本问题,最适合快速构建Baseline。
具体工具栈调研 :
- PDF解析 :这个环节我们选择的mineru,但是task1里面为了降低大家的学习门槛,使用的是pymupdf作为平替方案。
- Embedding实现 :我最初考虑使用 sentence-transformer 库。但在进一步查阅资料时,我发现了 Xinference ,它能将模型部署为服务,并通过兼容OpenAI的API来调用。我立即决定采用这种方式,因为 服务化能让我的Embedding模块与主应用逻辑解耦,更利于调试和未来的扩展。
多模态分别嵌入 :对文本和图片分别进行向量化,检索时结合文本和图片的相似度。这更精确,但实现也更复杂,而且召回图片与召回文本存在不相关情况,也需要比较多的处理。
多模态大模型端到端处理 :将检索到的文本和原始图片一起交给多模态大模型(如Qwen-VL)进行端到端理解和生成。这是最前沿的方案,但也最消耗资源,因为一般的多模态模型推理能力要稍微差一些。
第三步:构建Baseline执行流程
- 预处理(离线完成) :
- 使用pymupdf批量解析所有PDF文档,得到结构化的JSON数据。
- 将原始的文本块,以及图片的描述文本,附带上它们的元数据( filename , page ),构造成我们第一步设计的核心数据结构。
- 调用 Xinference 部署的Embedding模型服务,将所有内容的文本部分转换为向量。
- 将最终的 { “id”:“……”,“content”: “…”, “vector”: […], “metadata”: … } 存入向量数据库,完成知识库构建。
- 在线推理 :
- 接收测试集的json文件中的一个
question。 - 调用
Xinference服务,将question向量化。 - 在向量数据库中进行相似度搜索,召回Top-K个最相关的内容块。
- 将召回的内容块及其元数据,与
question一同填入设计好的Prompt模板中。 - 将完整的Prompt交给一个大语言模型(LLM),生成最终的答案和来源信息。
遇到的卡点及解决建议
在实际操作中,最主要的瓶颈在于 时间消耗 :
pymupdf解析 :处理整个财报数据库会稍微消耗一些时间,特别是如果使用基于深度学习的方式提取内容,比如mineru,不过我们本次baseline使用pymupdf速度会有比较大的提升。
批量Embedding :将接近5000的内容块进行向量化,也会消耗不少时间,如果是基于CPU运行的话大概会慢十倍,使用A6000这样的GPU也需要消耗大概1分钟的时间。
核心痛点 :如果在处理过程中代码出现一个小错误,比如数据格式没对齐,就需要从头再来,这将浪费大量时间。
使用jupyternotebook的好处
解决与建议 : 不要在一个脚本里完成所有事 。强烈建议使用 Jupyter Notebook 进行开发调试,并将流程拆分:
第一阶段:解析 。在一个Notebook中,专门负责调用pymupdf,将所有PDF解析为JSON并 保存到本地 。这个阶段成功运行一次后,就不再需要重复执行。
第二阶段:预处理与Embedding 。在另一个Notebook中,读取第一步生成的JSON文件,进行图片描述生成、数据清洗,并调用Embedding模型。将最终包含向量的知识库 保存为持久化文件 。
第三阶段:检索与生成 。在第三个Notebook中,加载第二步保存好的知识库,专注于调试检索逻辑和Prompt工程。
来仔细了解一下Baseline方案是如何实现解题的!
SOTA(State-of-the-Art)的高性能
- baseline 构建一个能完整跑通、麻雀虽小五脏俱全的系统
- 让机器看懂图片,最直接的方式是让模型直接处理图片像素。但这会引入复杂的多模态模型调用和信息融合问题。有没有更简单、能快速融入现有RAG(以文本为中心)流程的办法?我们能不能先把图片“翻译”成文字?
- LLM需要什么样的信息? 检索模块是LLM的眼睛和耳朵。我们是应该只把和问题最相似的那一小块知识喂给LLM,还是应该提供更丰富的周边信息?例如,找到一个关键段落后,是否应该把它的上下文(前后段落、所属章节标题)也一并提供,来帮助LLM更好地理解?
如何上分
分块策略 chunking strategy
目前是按“页”分块,这样做简单但粗糙。是否可以尝试更细粒度的分块,比如按段落、甚至固定长度的句子分块?这会如何影响检索的精度和召回率?
如何处理跨越多个块的表格或段落?是否可以引入重叠(Overlap)分块的策略?
检索优化retrieval optimization
如果检索回来的5个块中,只有1个是真正相关的,其他4个都是噪音,这会严重干扰LLM。如何提高检索结果的信噪比?
可以引入重排(Re-ranking)模型吗?即在初步检索(召回)出20个候选块后,用一个更强的模型对这20个块进行重新排序,选出最相关的5个
prompt工程
rag_from_page_chunks.py 中的Prompt是整个生成环节的灵魂。你能设计出更好的Prompt吗?
如何更清晰地指示LLM在多个来源中选择最精确的那一个?如何让它在信息不足时回答“根据现有信息无法回答”,而不是产生幻觉?
多模态融合 multimodal Fusion
“图片->文字描述”的方案有信息损失。有没有办法做得更好?
可以尝试 多路召回 吗?即文本问题同时去检索文本库和图片库(使用CLIP等多模态向量模型),将检索到的文本和图片信息都提供给一个多模态大模型(如Qwen-VL),让它自己去融合信息并作答。
升级数据解析方案 从fitz到MinerU
基础方案所使用的 fitz_pipeline_all.py 仅能提取文本,会遗漏表格、图片等关键信息。
转而使用 mineru_pipeline_all.py 脚本,具体操作如下:
https://github.com/ibbd-dev/python-image-utils
需要下载库
# 安装依赖
pip3 install -r https://github.com/ibbd-dev/python-image-utils/raw/master/requirements.txt
# 安装
pip3 install git+https://github.com/ibbd-dev/python-image-utils.git
# 建议在GPU环境下运行
python mineru_pipeline_all.py